안녕하세요, 허재연입니다. 오늘 리뷰할 논문은 Video Object Detection(VOD) task를 다룬 논문으로, 모델 외부에 추가적인 Memory Module을 두어 VOD 추론 시 활용하는 컨셉을 제안하였습니다. 보통 Video Scene Graph Generation(VidSGG)쪽 논문을 많이 리뷰하는데, SGG가 잘 되려면 기본적으로 detection이 잘 되어야하기에 비디오 진영에서 detection을 어떻게 다루나 파악하다 읽어보았습니다. 컨셉이 재밌어서 공유 드리고자 합니다. 리뷰 시작하겠습니다.

object detection은 저희에게 매우 익숙합니다. 이제 image 기반 object detection 기술이 많이 발전되어 실제 실생활 다양한 곳에 사용되고 있습니다. 그런데, 실세계에 object detection을 적용하는 상황 중 입력 데이터가 video 형태로 들어오는 경우가 꽤나 많습니다. Robot Navigation, autonomous driving, video surveillance와 같이 이미지가 연속적으로 online으로 입력되는 경우를 대표적으로 꼽을 수 있겠죠. video 데이터에는 image 데이터에 없는 시간적 정보가 담겨 있으므로, 이를 활용할 수 있으면 예측을 보정하는데 큰 도움이 될 것입니다.
예를 들어, 잘 큐레이팅 되지 않은 이미지나 비디오의 중간 프레임들은 motion blur나 occlusion이 쉽게 발생합니다. 이런 저품질의 단일 이미지에서는 의미있는 feature를 추출하기도, object를 잘 검출하기도 어렵습니다. 하지만 해당 이미지 뿐만 아니라 앞뒤 프레임의 정보를 함께 활용할 수 있다면 부분적으로 가려진 물체가 무엇인지, 흐릿하게 번진 물체가 무엇인지 판단하기 훨씬 쉬워지겠죠. 이런 motivation으로 object detection 수행 시 temporal 정보를 잘 활용해서 성능을 개선해보자는 시도가 계속 있어왔습니다.
Video Object Detection(VOD)은 비디오 데이터가 입력되었을 때, 검출을 수행하고자 하는 특정 target frame에서 object detection을 잘 수행하는 걸 목표로 합니다. 단일 이미지에서의 OD 성능은 이미지 기반 OD쪽에서 연구가 잘 이루어지고 있기에, VOD 논문들은 보통 ‘어떻게 temporal 정보를 잘 활용해서 detection 성능을 높일까’라는 고민을 합니다. 이전에는 LSTM 같은 RNN 모델을 사용하거나 optical flow, 인접 프레임 간 residual 정보 등을 활용해 시간적 정보를 포착하려는 시도가 있었다고 합니다. 하지만 transformer가 나오고, detection쪽에서도 DETR이 많이 사용되니 VOD진영에서도 DETR을 기본 detector로 채용하고, 시간적 정보도 temporal transforemr로 처리하려는 흐름으로 많이 넘어온 것으로 보입니다. 아래 Figure 1과 같이, 기존의 Transfomer 기반 VOD 모델들(TransVOD 등)은 OD를 수행하고자 하는 target frame과, 예측에 함께 활용하는 reference frame들을 입력 받아서 spatial attention을 수행한 이후 다시 temporal attention을 수행하는 방식으로 동작했습니다.
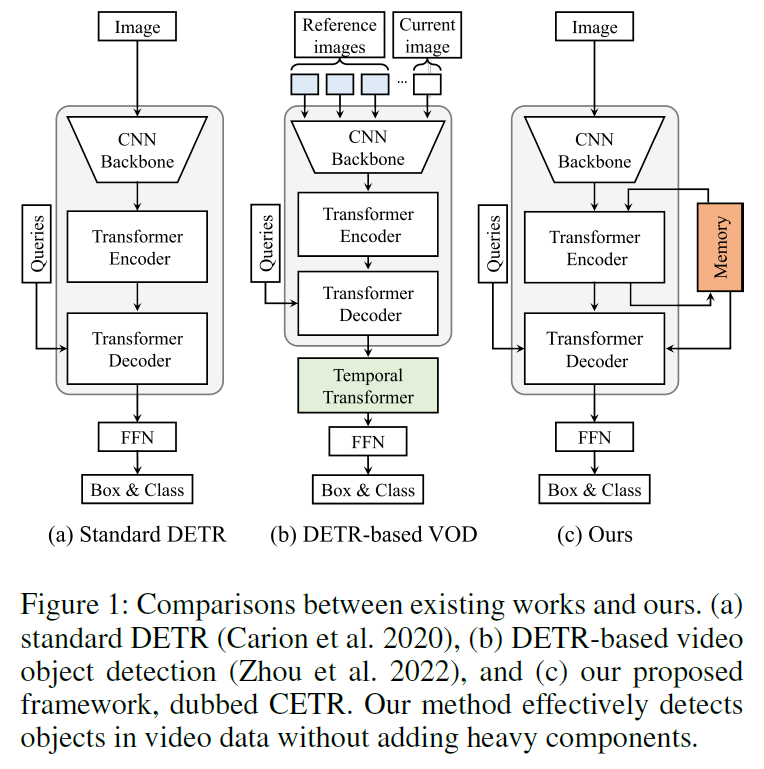
저자들은 여기에 문제를 제기합니다. 가뜩이나 attention 구조는 연산량이 많아서 처리 속도를 크게 저하시키는데 기존 DETR 구조에 temporal attention 모듈까지 더해지면 연산량 부담이 커지기 때문입니다. 그리고 reference frame들을 모두 입력받아서 이들 데이터 및 피쳐를 메모리에 들고 있어야 하기 때문에 메모리적 부담도 컸습니다.
저자들은 1. single-image 기반 detector들은 motion blur, occlusion등의 상황에서 temporal 정보를 이용하지 못하고), 2. 기존 DETR 구조 기반 VOD 모델들은 메모리 및 연산량 측면에서 부담이 크다는 단점이 있으니 이들의 단점을 절충하는 CETR(Context Enhanced TRansformer) 모델을 제안합니다.
CETR의 컨셉은 간단합니다. 모델 외부에 추가적인 context memory module (CMM)을 두어 학습 시에는 데이터들의 각 클래스별 정보를 잘 저장해두고, 추론 시 (추가적인 reference frame을 입력받지 않고) 단일 target frame 을 입력받아 context memory module에 저장되어 있는 정보를 참고하여 예측을 보강하는 것입니다. 이를 위해서는 3가지 구조를 잘 만들어야 합니다.
- 기본적으로 외부 메모리(CMM)를 잘 구축하고, 학습 과정에서 CMM에 클래스별로 품질 좋은 정보를 저장한다.
- 모델 예측 시, 메모리에 있는 모든 정보를 전부 반영하면 과도한 노이즈가 섞일 수 있다. 모델에 입력된 이미지의 정보와 관련 있는, 유용한 정보만을 잘 추출해야 한다.
- 모델의 예측 과정에서 외부 메모리의 정보를 잘 반영해준다.
CETR은 이들을 위해 각각 1. Context Memory Module(CMM) 2. Score-based Sampling 3. Memory-guided Transformer Decoder 을 설계하였습니다. 이러한 구조로 CityCam 및 ImageNet VID 데이터셋에서 비교적 빠른 속도로 SOTA 모델보다 좋은 성능을 보이거나, 이에 근접한 결과를 보였다고 합니다.
더 자세한 설명은 Method 부분에서 하도록 하겠습니다.
Method
제안하는 CETR은 기본적으로 DETR 구조를 기반으로 하고 있습니다. DETR은 이제 기본 상식이고 다들 잘 아실테니 자세한 설명은 생략하겠습니다.
introduction에서 설명했듯, CETR은 크게 3가지 요소로 구성됩니다. 각각 1. 전체 데이터셋에서 문맥 정보를 추출해 저장해두는 고정된 크기의 context memory module(CMM), 2. 현재 입력된 target frame data을 예측하는데 필요한 정보를 추출하는 전략인 score-based sampling(SS), 3. 샘플링한 spatio-temporal memory 정보로 object query의 피쳐 정보를 강화해주는 memory-guided Transformer decoder(MGD)입니다. 전체적인 구조는 아래 Figure 2.와 같습니다.
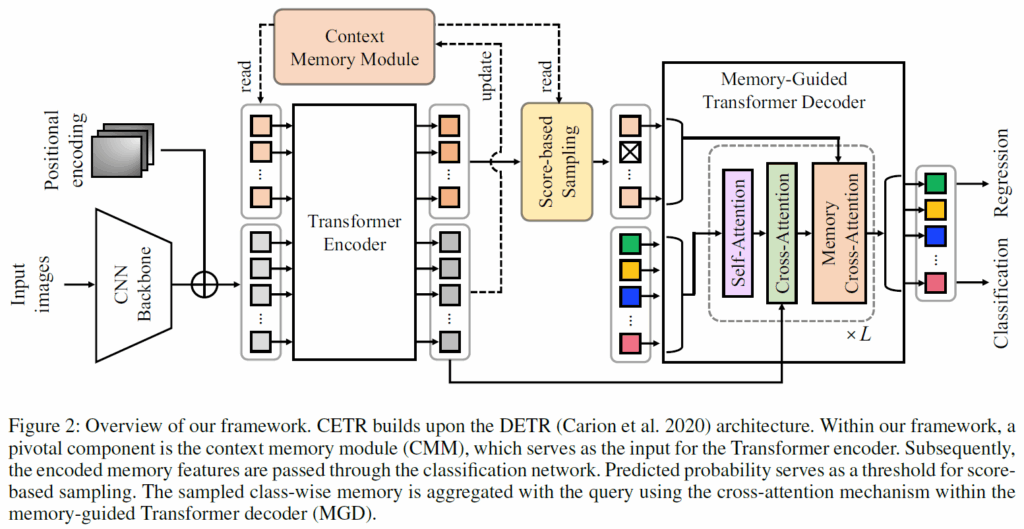
Context Memory Module
Context Memory Module은 class마다 K개의 prototype을 가지는 벡터들의 집합으로 생각하시면 됩니다. d차원의 벡터가 C·K개 저장되어 있는 거죠. 이 때 prototype 개수 K는 하이퍼파라미터입니다.
모델의 입력을 살펴보겠습니다. 일단 가장 먼저 DETR과 동일하게 이미지를 CNN backbone을 거치게 한 다음 positional encoding을 더해줍니다. 원래 DETR이라면 이후 이미지 피쳐를 트랜스포머 인코더에 입력해 SA을 거쳐주겠지만, CETR에서는 Momory module에서 읽어온 메모리 정보 M을 feature F와 concat하여 함께 입력해줍니다. 그럼 주어진 이미지 피쳐와 메모리 정보가 함께 self-attention을 수행한 다음 인코더에서 출력될 것입니다.
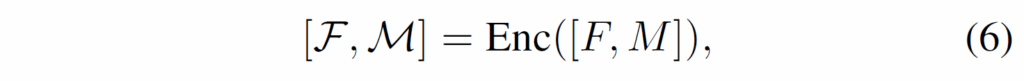
출력된 피쳐맵에는 메모리의 정보가 반영되어 시각 정보다 보정될 것이고, 메모리 정보에는 ‘지금 입력된, 처리해야하는 이미지가 어떤 이미지인지’ 정보를 반영해 줄 수 있을 것입니다. 현재 들어온 이미지 정보를 메모리 정보에 반영해주는 이유는, 이후 이 정보를 바탕으로 메모리 모듈에서 어떤 정보를 샘플링해야 할지 결정하는 데 활용하기 위함입니다.
학습 과정에서 메모리 모듈은 non-paramatic하게 유지됩니다. gradient 역전파 받아서 학습되는게 아니라, 모델과 별개로 momentum update 방식으로 데이터셋의 정보를 순차적으로 업데이트하게 됩니다. 세부적으로는 아래 수식 (7)처럼 기존 메모리 정보와 입력된 프레임 정보 간 weighted sum을 해주면서 정보를 반영해줍니다.
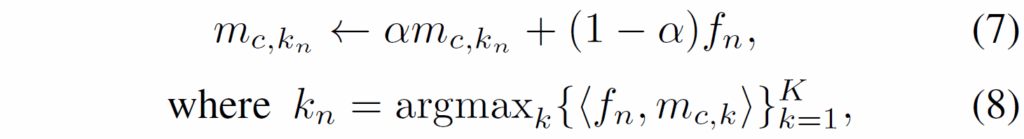
수식 (7)에서 M={{m}_{c,k}}는 class-wise memory이고, F={{f}_{n}}은 트랜스포머 인코더를 거친 image feature입니다. 이때 모든 메모리가 아니고 {k}_{n}에 해당하는 memory만 업데이트하게 되는데, 수식 (8)번에서 확인할 수 있듯 {k}_{n}은 {f}_{n}과 가장 correlation이 높은 메모리 정보의 index입니다. 수많은 instance feature 중 연관 있는 녀석들만 반영해주겠다는 뜻이죠(무턱대로 모든 feature를 반영하다보면 원지 않은 noise가 많이 섞이게 될 것입니다). 이 과정을 통해, CMM 모듈은 전체 데이터셋에서 각 instance의 분포 다양성을 반영해 저장할 수 잇게 됩니다.
Score-based Sampling
메모리가 잘 구축되었다고 하더라도, 메모리의 모든 정보를 반영해주는 것은 좋지 않습니다. 모델에 현재 입력된 이미지 정보와 연관이 없는 정보도 많이 저장되었기 때문에, 전체 메모리를 반영해주거나 메모리에서 random sampling하여 정보를 반영해주면 예측에 방해가 되는 noise 정보가 반영될 수 있기 때문입니다. 따라서 현재 입력된 프레임의 예측에 도움이 될 만한 정보만 메모리에서 샘플링하는 전략이 필요합니다. 저자들은 이를 score-based sampling으로 구현했습니다.
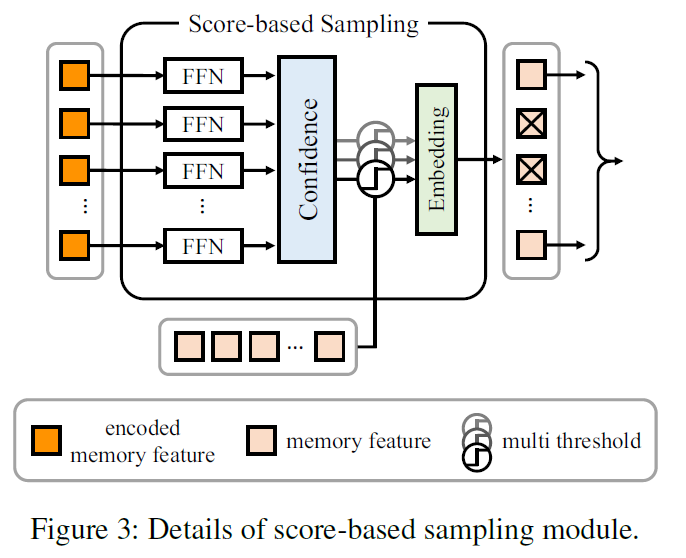
일단, 앞서 인코딩된 memory feature M={{m}_{c,k}}을 각각 classification head {FFN}_{c,k}에 태운 후 sigmoid를 거쳐 0~1 범위의 confidence score {p}_{c,k}를 얻습니다.
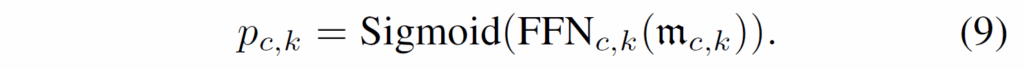
이후에는 다음 수식 (10)과 같이 sampled memory \tilde{M} ={{\tilde{m}}_{c,k}}를 구축하여 multi-threshold sampling을 수행한다고 합니다 .
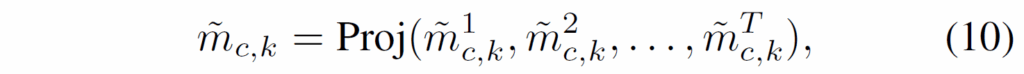
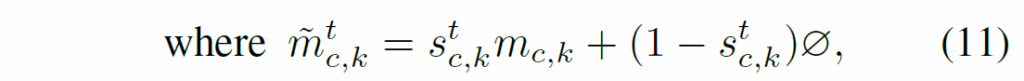
여기서 T는 sampling index {s}^{t}_{ck}의 수를, ∅는 학습 가능한 no-class embedding을 의미합니다. 여기서 {s}^{t}_{ck}는 {p}_{ck}를 T threasholds {τ}_{t}를 사용하여 이진화화하여 도출합니다(confidence score를 threshold 기준으로 1,0으로 나눈겁니다). projection layer Proj(·)는 multi-threshold를 수행한 메모리 정보를 다양한 confidence와 결합하여 최종 sampled memory를 생성해냅니다. classification head는 학습 과정에서 asymmetric loss로 학습시킨다고 하네요.
Memory-guided Transformer Decoder
이후는 간단합니다. 원래 DETR에서는 decoder에서 image feature와 object query를 입력받아 object query를 한번 SA 연산 수행하고 feature와 query 간 cross-attention을 수행합니다. CETR에서는 여기에 추가로 memory 정보를 주입하기 위해 cross-attention 모듈을 한번 더 거치도록 하였습니다.
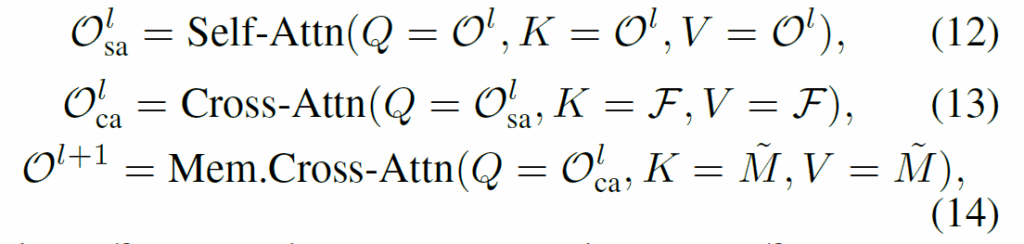
수식 (12), (13)은 기존 DETR의 decoder 연산과 동일합니다. object query가 self-attention을 거치고, 이후 feature와 query 간 cross-attention을 수행합니다. 추가된 부분은 수식 (14)로, 앞서 샘플링한 메모리 정보를 주입하기 위해 object query와 Cross-Attention을 수행해줍니다.
이렇게 출력된 object query는 이제 DETR과 완전히 동일하게 예측 및 학습을 수행합니다. 각각 classification head, localization head를 거쳐 예측을 수행하고, 학습 시에는 hungarian matching 및 loss 로 학습하는 과정을 DETR과 동일하게 설정했다고 하네요.
Test-time Memory Adaptation
메모리 모듈이 non-parametic하기 때문에, 학습했던 데이터셋과 실제 모델이 동작하는 데이터의 분포가 다를 수 있습니다. domain gap을 다루기 위해 test-time adaptation이 필요합니다. 학습했던 메모리는 그대로 두고, 독립적으로 target domain의 문맥적 정보를 따로 저장해둡니다. target domain의 메모리와 학습 데이터셋에서의 source domain 메모리는 다음과 같이 weighted sum하여 업데이트하고 사용한다고 합니다.
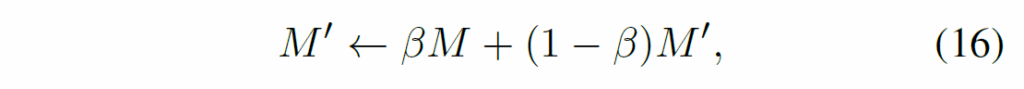
β ∈ [0,1]는 source domain의 가중치입니다. adaptation을 통해 source domain의 문맥적 정보를 잘 활용하면서 target domain의 데이터 분포를 반영할 수 있다고 하네요. 다양한 특정 카메라 상황에 맞춰서 memory 사용법을 tailoring하면 다양한 카메라 시스템에서 보다 강건하게 동작할 수 있다고 합니다.
Experiment
실험은 CityCam, ImageNet VID라는 데이터셋에서 진행되었습니다. CityCam은 약 6만개의 labeled frame, 90만개의 object annotation으로 구성되며, class는 10개의 차량(vehicle)입니다. ImageNet VID는 30개 object class에 대해 3,862개의 학습용 비디오 및 555개의 validation video로 구성된 데이터셋이라고 합니다.
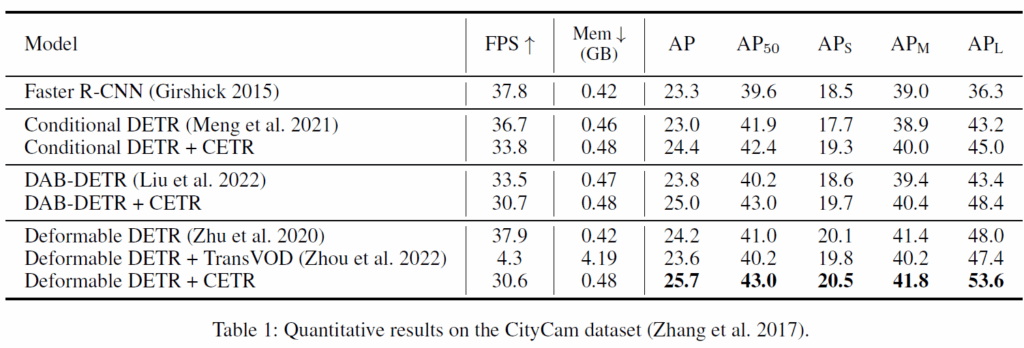
Table 1에서는 다양한 DETR 구조에서 CETR 을 추가했을 때 성능 향상을 벤치마크했습니다. Deformable DETR에서는 TransVOD와 함게 비교했는데, detection 성능은 TransVOD보다 좋으면서 FPS, 메모리 측면에서도 개선된 모습을 보였습니다.
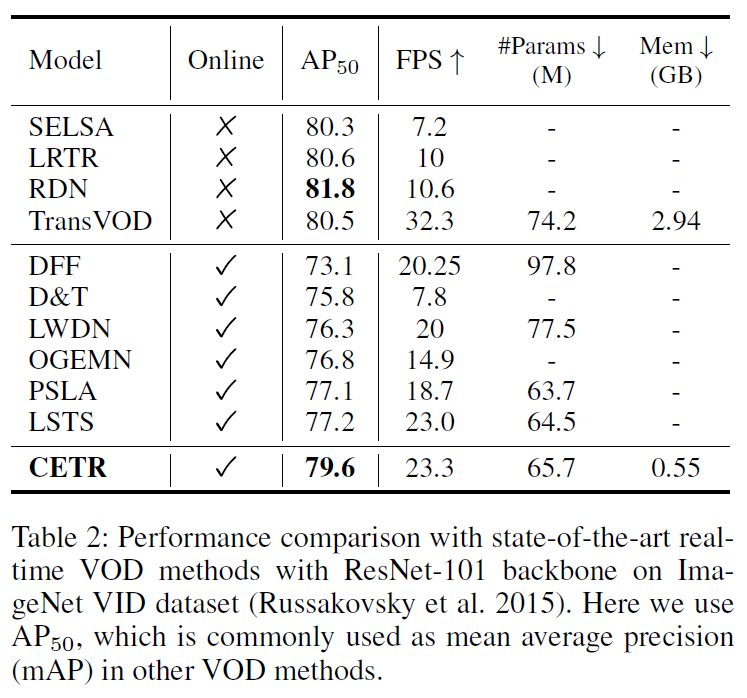
Table 2는 ImageNet VID에서의 벤치마크 결과입니다. CETR은 예측에 미래 프레임을 사용하지 않기 때문에 online으로 동작 가능하며, online VOD 방법론들중에서는 가장 좋은 AP50 결과를 보였습니다. online으로 동작하지 않는다는 것은 모델 예측 시 미래 frame을 사용하는 세팅이라고 합니다.
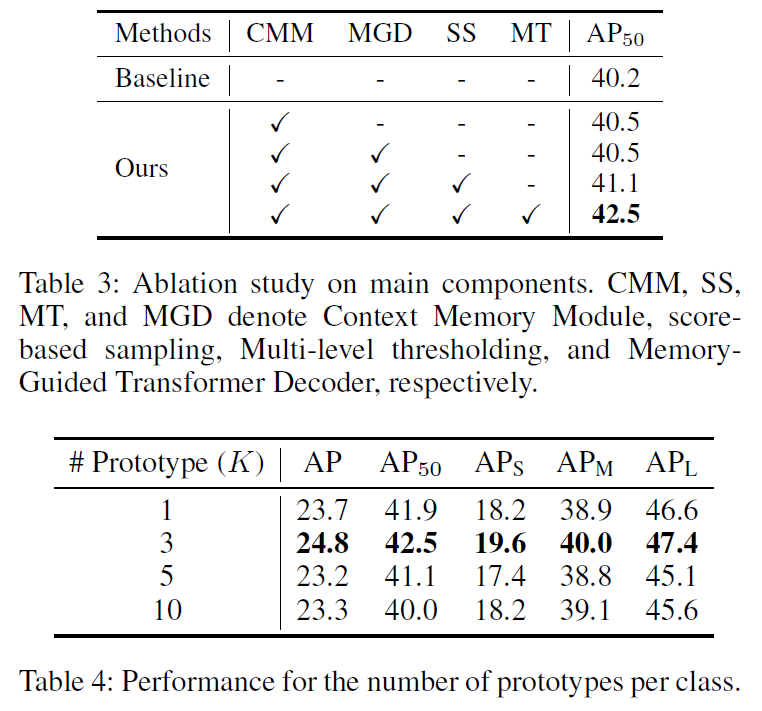
Table 3,4는 ablation 및 하이퍼파라미터 세팅에 대한 실험 결과입니다. 저자가 제안하는 모듈들(Context Memory Module, Memory-Guided Decoder, Score-based Sampling, Multi-level thresholding)을 추가할수록 성능이 오르는 것을 확인할 수 있습니다. 메모리 모듈의 구성에서는 class-wise prototype 개수 K를 지정해주어야 하는데, K=3일때 가장 좋은 성능을 보였다고 합니다.
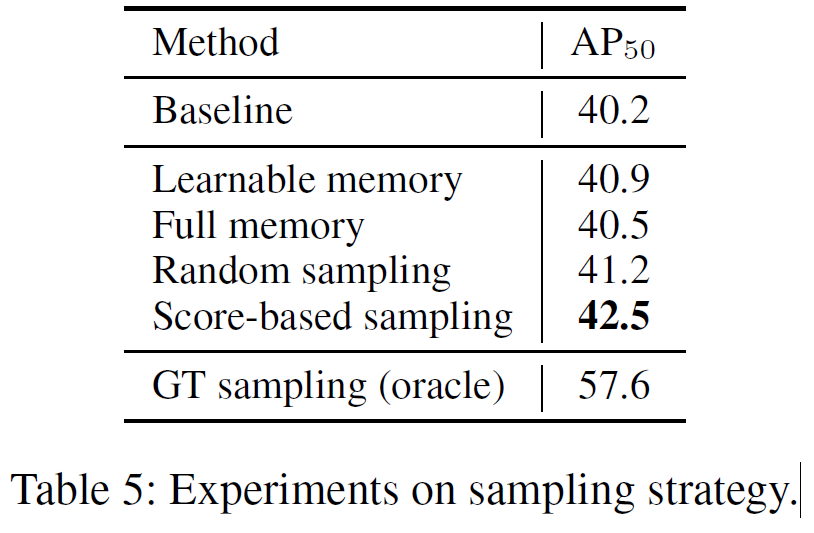
Table 5에서는 메모리의 sampling 전략에 대한 결과를 나타내었습니다. 기존 방법론들은 random으로 정보를 샘플링하기도 하고, 모든 메모리를 다 사용하던지 아니면 learnable하게 사용했다고 해서 이들과 비교한 것 같은데, 제안하는 score-based sampling 방법이 가장 좋은 성능을 보였습니다.
마지막으로 정성적 결과를 보겠습니다.

Figure 4는 제안한 메모리와 이미지 피쳐 간 correlation을 시각화 한 것입니다. 인코더의 4번째 layer의 attention map을 사용했다고 합니다. 측정 클래스에 해당하는 object에 반응하는 것을 확인할 수 있습니다. 이를 통해 저자는 제안하는 메모리 모듈이 각 클래스의 정보를 잘 저장하고 있으며, 해당하는 object에 의미 있는 정보를 부여할 수 있다고 합니다.

다음은 CityCam dataset에서 일반 detector와 CETR의 정성적 비교입니다. 도로에서 달리는 자동차들 중 일부는 약간 motion blur가 있고, occlusion(다른 차량에 가린다던지, 프레임 바깥으로 일부가 짤린다던지)도 일부 보입니다. 위쪽의 baseline 모델은 일부를 놓치는 반면, 아래쪽의 CETR은 정확하게 모든 vehicle들을 잘 검출해내는것을 확인할 수 있습니다.
개인적으로 컨셉이 간단하고 재미있는 아이디어라고 생각하긴 하지만, 결국 모델 예측 과정에서 인접한 reference frame 정보를 활용하는 것이 아니라 그냥 memory에 저장되어 있던 정보를 샘플링하여 반영해주는 방법론이기 때문에 Video Object Detection 방법으로 분류하는게 맞나? 그냥 image object detection 방법론으로 생각해도 되지 않나.. 라는 생각이 드는 방법론이었습니다.
이만 리뷰 마무리하도록 하겠습니다.
감사합니다.
안녕하세요 재연님, 좋은 리뷰 감사합니다.
세미나랑 리뷰를 읽으면서 Context Memory Module이라는 아이디어가 되게 신선하게 느꼈던 것 같습니다. 그래서 해당 모듈의 동작 방식에 대해 궁금한 점이 생겨서 댓글 드립니다.
제가 이해한 바로는, CMM은 이전 프레임들의 temporal 정보를 저장해두었다가 샘플링 시 활용하고, 이후 Transformer의 출력 피처를 바탕으로 momentum update 방식으로 업데이트 한다고 이해를 했는데, 여기서
CMM에 처음 저장되는 벡터들은 랜덤 초기화로 시작되는지 아니면 학습 초기에 Transformer encoder의 output feature를 기반으로 초기화되는지 궁금합니다. 그리고 말씀하신 momentum update는 프레임 단위로 이루어지는지,
아니면 비디오 단위 혹은 배치 단위로 이루어지는지도 궁금합니다!
마지막으로, CMM이 class prototype 형태로 고정되어 있다면, 새로운 instance나 도메인 변화 상황에서도 얼마나 유연하게 적응할 수 있는지 (test-time adaptation 외의 일반적 상황에서) 궁금합니다.
감사합니다.
안우현 연구원님 안녕하세요, 하나씩 답변 드리도록 하겠습니다.
1. 논문에 백본 네트워크와 트랜스포머 인코더/디코더 모듈의 초기화 방법은 설명되어 있지만, CMM module의 초기화 관련해서는 딱히 언급이 없습니다. 코드도 공개되어있지 않아서 어떻게 초기화되는지는 알 수 없네요.
2. CETR은 target frame 예측 시 해당 비디오 클립의 다른 reference frame 정보를 직접적으로 사용하지 않습니다. momentum update는 단일 이미지로 구성된 배치 단위로 수행될 것 같네요.
3. domain adaptation을 고려하면 학습된 instance class가 그대로 있는 target domain이라면 적용이 가능하겠지만, 처음 보는 class/category instance가 등장하면 (애초에 CMM 구축할 때 class-wise로 prototype을 업데이트했으니) 이에 맞춰 새로 학습해야 할 것 같습니다.
감사합니다.