안녕하세요 이번에 리뷰로 들고온 논문은 ICLR 2018년에 게재된 Semi-Parametric Topological Memory For Navigation이라는 논문입니다. 비록 나온지 오래된 논문이지만 navigation중에서도 visual navigation 그 중에서도 기하학적인 지도를 활용하는 것이 아니라 위상지도(topology graph)를 활용하여 딥러닝으로 이를 풀어나가는 연구입니다. 처음에 단순히 목표 이미지 달랑 하나만 가지고 네비게이션을 수행한다는 게 도저히 와닿지 않았는데 해당 논문이 이러한 문제를 해결하는데 있어서 직관적으로 이해하기 좋다고 생각하였습니다. 특히 시각적인 정보만을 가지고 딥러닝 기반위상 그래프를 활용하여 이 문제를 풀어나가는 큰 흐름이나 핵심 컨셉을 이해하기 가장 좋은 논문이라고 개인적으로 생각하고 이를 리뷰로 들고 왔습니다.
바로 리뷰 시작하도록 하겠습니다.
Introduction
먼저 연구의 기반이 된 배경을 보면, 먼저 로보틱스 분야의 전통적인 내비게이션은 기하학적 지도(metric map) 기반의 SLAM이 주류였습니다. 하지만 이런 시스템들은 센서 캘리브레이션 문제에 민감하고, 또 조명이나 시각적 조건이 바뀌면 불안정하기도 하고, 동적인 환경에서는 대응이 어렵고, 무엇보다 대규모 환경으로 확장하기 힘들다는 한계를 가지고 있습니다. 또는 복잡한 환경에 대해 적응적으로 유연하게 대처하기 위해 SLAM기반으로 생성한 기하학적인 지도에 딥러닝 시스템을 결합하여 내비게이션을 수행하는 방식도 나오게 됩니다. 이후에는 센서 의존도를 낮추기 위해서 아무런 지도 정보 없이 오로지 단순히 바라보는 시각정보 하나를 가지고 딥러닝 기반으로 네비게이션을 수행하는 방식이 존재합니다. 즉 카메라 입력을 바로 제어로 연결하는 방식이라고 보시면 좋을 것 같습니다.
기존에 이러한 시각정보만을 활용한 방식들은 단순히 입력이미지 하나만 보고 바로 Action을 취하는 방식인데 당연히 지금 보고있는 순간에 대한 액션만 취하기 때문에 장기적인 목표 수행은 불가합니다. 그래서 더나아가서 LSTM과 같은 단기 메모리를 쓰는 구조를 활용하여 연속적인 이미지 시퀀스 정보에서 이전 시퀀스 일부를 참고 하여 액션을 취하는 그러한 방법도 나왔는데, 이 방식도 여전히 장기적인 정보를 기억하는 구조는 아니기 때문에 마찬가지로 장기 목표 수행은 어렵다는 한계가 있습니다. (물론 핵심은 SPTM이 앞서 언급한 내비게이션 방법론들이 가지는 문제를 해결하기 위해 등장한 논문은 아닙니다.)
하지만 심리학 연구들에서는 동물이나 인간들이 이동할 때 정확한 거리나 좌표 기반의 기하학적 표현보다는 랜드마크(기억에 남는 장소)나 랜드마크 사이들에 대한 경로 정보를 사용한다는 근거가 많다고 합니다. 즉, 사람이나 동물은 단순히 좌표 기반의 지도를 머릿속에 만드는 것이 아니라, 주변 환경의 연결 관계나 상대적인 위치정보를 기반으로 한 위상적인 구조를 형성하여 내비게이션을 수행 한다는 겁니다.
즉, 우리가 처음 보는 장소에 놓여졌다고 하면 5분정도 탐색하는 과정에서 앞선 연구처럼 모든 장소의 3차원 지도를 머릿속에 저장하면서 탐색하지 않고 기억에 남는 장소들과 그들의 관계만을 머릿속에 저장하면서 탐색을 합니다. 또한 주어진 목적지를 향해 갈때 보여지는 장면에 대한 즉각적인 행동을 취하는 것이 아니라 머릿속에 저장해놓은 익숙한 장소들간의 관계를 생각하면서 내비게이션을 수행하게 됩니다.
이 논문에서 제안하는 SPTM 은 바로 이런 인간의 내비게이션 수행 방식에서 아이디어를 가져온 것으로 이해하면 좋을 것 같습니다.
이때 해당 방법론에서 사용하는 랜드마크들간의 관계를 표현한 위상 그래프는 거리나 좌표 같은 기하학적 정보를 전혀 포함하지 않고, 단지 “이 위치에서 저 위치로 갈 수 있는가” 하는 연결성(도달 가능성)정보만을 담고 있다고 보시면 좋을 것 같습니다.
자세한 내용은 Method 파트에서 다루도록 하겠습니다.
Method
먼저 전체적인 흐름을 설명드리자면 실제 deployment 과정에서 에이전트는 인간처럼 탐색을 진행하고 해당 탐색한 정보를 바탕으로 위상그래프를 생성합니다. 위상 그래프를 생성하는 과정에서 Retrieval network를 활용하게 되며 이를 기반으로 생성된 위상그래프를 바탕으로 자신의 위치와 목적지를 localization을 수행하며, Localization을 수행한 후에 최적의 경로 탐색을 하고, 이후에 Locomotion Network를 통해서 Action을 뽑아냄으로써 실제로 에이전트가 움직이는 방식으로 동작합니다. 그래서 Deployment이전에 각각 핵심이 되는 2가지 네트워크가 어떻게 학습이 되며 어떠한 데이터로 학습이 되는지 설명드리도록 하겠습니다. 그리고 모든 학습과 실험은 실제 환경(real world)이 아니라 시뮬레이션 환경의 미로에서 수행됩니다.
Train
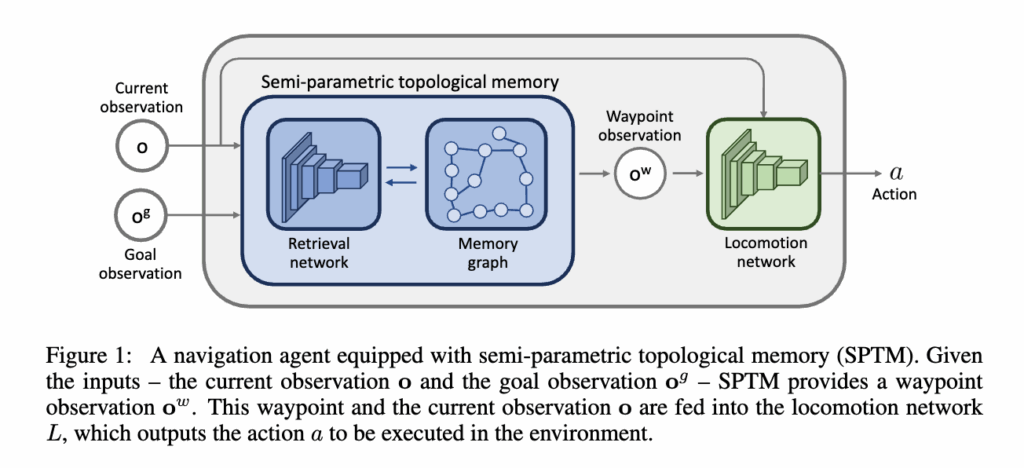
먼저 SPTM의 전체 프레임워크는 그림처럼 구성되어 있습니다.
크게 보면, Retrieval Network (R) 과 Locomotion Network (L) 이 핵심 역할을 담당하고 있고 이 두 네트워크가 서로 맞물리면서 에이전트가 실제로 환경을 인식하고 이동하게 됩니다. 이제 이 두 네트워크가 각각 어떤 역할을 하는지, 그리고 어떻게 학습되는지를 순서대로 설명드리겠습니다.
Retrieval Network (R)
먼저 Retrieval Network, 줄여서 R 네트워크를 간단하게 설명드리면 두 관찰 (o_1, o_2) 간의 시각적 유사도(similarity)를 학습하는 네트워크입니다. 쉽게 말하면, 이 두 장면이 서로 얼마나 가까운 위치에서 찍힌 것인가를 판단하는 역할이라고 보시면 됩니다. 이 두 관찰이 공간적으로 얼마나 가까이 있는가를 판단하는 네트워크라고 이해하시면 좋을 것 같습니다. 이 R 네트워크는 self-supervised 방식으로 학습됩니다. 별도의 라벨이나 보상 없이, 무작위로 움직이는 에이전트가 만들어낸 데이터를 인간이 라벨링 하지 않고 그대로 활용합니다. 그리고 해당 네트워크의 인코더는 ResNet18을 사용합니다.
데이터 생성 과정은 다음과 같습니다. 먼저, 에이전트를 환경 안에 두고 아무 행동이나 하게 합니다.
이 과정에서 관찰 시퀀스 \{o_1, o_2, ..., o_N\} 와 이에 대응하는 행동 시퀀스 \{a_1, a_2, ..., a_N\} 이 자동으로 쌓입니다.
그 다음, 이 데이터를 가지고 시간적으로 가까운 프레임 쌍과 먼 프레임 쌍을 구분하는 학습 데이터를 만듭니다.
예를 들어, 두 관찰이 20 step 이내라면 가까움(positive)으로, 100 step 이상 떨어져 있으면 멀다(negative)로 라벨을 붙입니다. 이렇게 만들어진 샘플은 \langle o_i, o_j, y_{ij} \rangle 형태로, 두 관찰 이미지와 이들이 가까운지/먼지를 나타내는 라벨 y_{ij} 로 구성됩니다.
결국 R 네트워크는 시간적으로 가까운 두 장면을 유사도가 높게, 멀리 떨어진 두 장면은 유사도가 낮게 예측하도록 학습됩니다.
이걸 통해서 모델은 시각적 특징을 기반으로 이 위치가 그래프의 어디쯤인지를 구분할 수 있게 됩니다.
네트워크 구조는 시암(Siamese) 형태로 구성되어 있습니다. 저 시암 형태가 샴 쌍둥이에서 나오는 샴을 뜻하는 것 인데, 그냥 단순히 두개의 관찰을 독립적으로 처리하되 동일한 네트워크로 처리하는 구조입니다. 사실상 인코더 인풋은 이미지 하나지만 뒤에 유사도를 계산하는 네트워크에서는 각각 동일한 인코더를 타고 나온 두 관찰에 대한 벡터를 처리하기 때문에 프레임워크 그림에서는 Input이 두개인 것 처럼 표시한 것입니다.
구체적으로는 두 입력 이미지 o_1, o_2를 각각 ResNet-18 인코더에 통과시켜 각각 512차원 임베딩 벡터로 변환합니다. 이 두 벡터를 이어붙여 5층 fully-connected layer 에 입력하고, 마지막에는 2-way softmax를 통해 가깝다, 멀다를 분류합니다. 학습은 cross-entropy loss로 진행됩니다. 이 R 네트워크는 환경의 시각적 거리를 학습하는 역할을 하고 이후에는 그래프를 생성하고 그래프 상에서 자기 위치를 인식(localize)하는 핵심 모듈이라고 보시면 될 것 같습니다.
Locomotion Network (L)
다음은 Locomotion Network, 줄여서 L 네트워크입니다. 마찬가지러 인코더 부분은 R 네트워크와 마찬가지로 ResNet18을 사용합니다. 이 네트워크는 그럼 실제로 어떻게 움직일 것인가를 배우는 역할을 합니다.
입력으로는 현재 관찰 o_1 과 목표 관찰 o_2 가 주어지고, 출력으로는 가능한 행동 집합 A에 대한 확률 분포가 나옵니다. 즉, L(o_1, o_2) = p \in \mathbb{R}^{|A|} 로 표현되며, 이 확률 분포를 기반으로 가장 높은 확률의 행동을 선택하게됩니다. 단순히 7개 클래스 분류 문제를 푸는 방식이라고 생각하시면 좋을 것 같습니다. 가능한 행동은 7개로 아래와 같습니다.
- 아무것도 하지 않기 (do nothing)
- 앞으로 이동 (move forward)
- 뒤로 이동 (move backward)
- 왼쪽으로 이동 (move left)
- 오른쪽으로 이동 (move right)
- 왼쪽으로 회전 (turn left)
- 오른쪽으로 회전 (turn right)
L 네트워크의 학습 방식 역시 무작위로 탐색하는 에이전트의 trajectory 으로부터 데이터를 생성합니다. 무작위 탐색 데이터를 보면 마찬가지로 각 시점마다 현재 관찰, 몇 step 뒤의 관찰, 그때 취했던 행동이 모두 들어 있습니다.이걸 이용해서 ((o_i, o_j), a_i)[latex] 형태의 학습 데이터를 만듭니다. 즉, 두 관찰 사이가 20 step 이내로 떨어져 있다면 이 두 장면을 연결하기 위해 어떤 행동을 취해야 했는가?를 학습한다고 보시면 좋을 것 같습니다. 이렇게 학습된 L 네트워크는 주어진 현재 시점의 관찰과 목표 관찰을 보고,둘 사이를 잇기 위한 행동 분포 [latex]P(a | o_t, o_{t+k}) 단순히 그냥 가장 적합한 액션를 추정하게 됩니다. k가 프레임 간 스텝 차이라고 했을 때, k=1이면 바로 인접 프레임 간 이동(즉, 한 걸음 전진 같은 행동)을 배우게 되고, k>1이라면 다소 노이즈가 섞이지만 여전히 유용한 학습 신호가 남는다고 합니다. 당연히 너무 멀면 이는 노이즈로 작용하기 때문에 positive 데이터쌍으로만 학습을 시키게 됩니다. 결국 이렇게 단순한 데이터만으로도 내비게이션에 필요한 제어 패턴을 충분히 학습할 수 있다는 게 핵심입니다.
정리하면 Retrieval Network (R) 은 두 관찰이 시각적으로 얼만큼 가까이 있는지 유사도를 학습하고 Locomotion Network (L) 은 내가 보는 장면에서 주어진 장면까지 가려면 어떻게 움직여야 하는가를 학습합니다. 이 두 네트워크가 결합되어, 에이전트는 별도의 지도나 보상 없이도 시각 정보만으로 새로운 환경을 이해하고 목표까지 이동할 수 있도록 하는 것이 바로 SPTM의 핵심 아이디어라고 보시면 될 것 같습니다.
Deployment
앞에서 학습된 Retrieval Network (R) 과 Locomotion Network (L) 을 기반으로, SPTM은 이제 실제 내비게이션 상황에서 사람이 길을 찾는 방식과 비슷하게 동작하게 됩니다. 즉, 단순히 하나의 행동 정책을 학습한 게 아니라, 탐색 중 생성한 그래프를 이용해 계획(planning) 과 위치 추정(localization) 을 반복하며 움직이는 구조입니다.
이제 실제 운용 과정에서 SPTM이 어떻게 동작하는지를 단계별로 설명드리겠습니다.
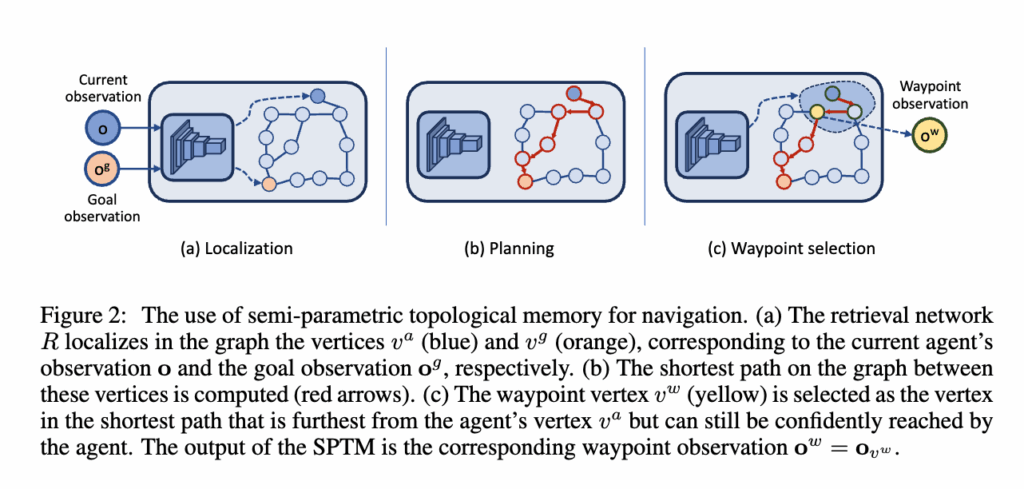
1. 탐색 및 그래프 생성 (Exploration & Graph Building)
먼저, 에이전트는 주어진 환경을 일정 시간(대략 5분) 동안 탐색합니다. 에이전트가 처음 보는 환경에 대해서 쓱 훑는 과정이라고 보시면 됩니다. 이는 인간이 직접 수행합니다. 이때 얻은 관찰 시퀀스들을 기반으로 위상 그래프를 생성합니다. 먼저 각 시점에서의 관찰은 그래프의 노드로 저장이 되고 이를 edge로 잇는 과정이 필요한데 2가지 경우에 대해서 각 노드간 연결을 합니다. 이 연결이 갖는 의미는 노드에서 이어진 노드까지 도달 가능한지를 이 edge로써 표현한다고 이해하시면 좋을 것 같습니다. 먼저 edge를 잇는 2가지 경우에 대해서 설명드리도록 하겠습니다.
1. 시간적으로 인접한 경우
당연히 시간적으로 연속된 프레임끼리는 한번의 action으로 도달할 가능성이 높습니다 따라서 연속된 프레임끼리 엣지로 연결합니다.
2. 시각적으로 유사한 경우 (지름길 연결, Shortcut Connection)
Retrieval Network R이 두 관찰이 매우 비슷하다고 판단할 때, 즉, 다른 시점에서 같은 장소를 다시 본 경우에도 엣지를 추가해야합니다. A-B-C-D-A' 와 같이 노드가 연결 되어있다면 에이전트가 A에서 A'까지 B-C-D를 거쳐가는 것은 비효율적이기 때문에 A-A'간에 지름길을 연결해 주는 단계라고 이해하시면 좋을 것 같습니다. 이때 유사도가 일정 기준 s_{\text{shortcut}} 이상일 때만 연결을 만듭니다. 하지만 인접한 노드들에 대해서는 당연히 유사도가 일정 기준 s_{\text{shortcut}} 이상이기 때문에 인접한 노드들에 대해서 shortcut이 다 생성이 된다면 그래프가 너무 복잡해지고 shortcut을 활용하는 의미가 희석이 될 수 있기 때문에 논문에서는 그래프의 품질을 높이기 위해 두 가지 개선을 적용했습니다.
1.Trivial edge 방지
시간적으로 너무 가까운 프레임들끼리는 지름길을 만들지 않도록 |i-j| > \Delta T_\ell 조건을 둡니다. 거의 연속된 장면이 불필요하게 shortcut으로 연결되는 걸 막는 장치라고 보시면 됩니다.
2.시퀀스 기반 매칭
그리고 단순히 한 장면에 대해서만 유사도를 비교해서 그래프를 연결하게 되면 그 장면이 실제로 시각적으로는 유사하나 공간적으로는 다른 위치일 수 있는 경우에 문제가 생길 수 있습니다. 즉 단일 프레임 간 유사도만 보면 시각적 노이즈에 약하기 때문에, 하나의 이미지가 아니라 연속된 구간을 비교합니다.양쪽 구간의 유사도들을 계산한 후 median 갑이 이 일정 임계값을 넘을 때만 연결을 추가합니다. 현재 본 장면은 시각적으로 유사하지만 공간적으로 다른 위치에 있다면 이전 이후 프레임들과 비교했을 때 시각적으로 유사할 확률이 당연히 낮습니다. 따라서 이전 이후 일정 구간의 프레임의 중간 값을 고려해서 shortcut을 연결하게 됩니다. 이렇게 하면 좀 더 안정적으로, 진짜 같은 장소일 때만 shortcut이 만들어집니다. 결국 이 단계에서는 환경의 위상적 구조가 그래프로 표현됩니다. 즉 이 장소에서 저 장소로 갈 수 있다라는 연결 정보만을 가지고 환경의 지도를 대략적으로 구성한다고 보시면 될 것 같습니다.
2. Localization (Global)
그래프가 만들어진 이후, 새로운 에피소드가 시작되면 에이전트는 현재 관찰 o와 목표 관찰 o_g를 입력으로 받아서 각각 그래프 상의 노드 v_a (현재 위치)와 v_g (목표 위치)를 찾습니다. 이때 Retrieval Network R이 사용되며, 각 관찰을 임베딩 공간으로 매핑한 뒤 형성한 위상그래프 내 모든 노드들과의 유사도를 계산하여 가장 가까운 노드를 선택합니다. 즉, 지금 내가 그래프 상 어디쯤 있고 내가 가여하는 곳은 어디에 위치해 있는지를 R네트워크를 기반으로 찾아내는 단계입니다. 이게 바로 Global Localization이라고 보시면 됩니다.
3. Planning
현재 위치와 목표 위치가 결정되면, SPTM은 위상그래프 위에서 이 둘을 잇는 최단 경로를 계산합니다. 이때는 전통적인 다익스트라(Dijkstra) 알고리즘을 사용합니다.
4. Waypoint Selection
이제 앞서 구한 최단 경로를 바탕으로 경로를 따라가야 하는데, 문제는 바로 다음 노드로 가는 게 좋을까, 좀 더 먼 곳을 목표로 잡는 게 좋을까 하는 점입니다. 가장 단순한 방법은, 경로 상에서 일정 거리 D 만큼 떨어진 노드를 웨이포인트로 정하는 겁니다. 하지만 이렇게 하면, 어떤 경우엔 웨이포인트가 너무 가까워서 거의 제자리걸음이 되거나, 반대로 너무 멀어서 실제로 닿지 못하는 문제가 생깁니다. 그래서 저자들은 좀 더 adaptive한 방법을 사용했습니다.
즉, 현재 관찰 o와 경로 상 노드 v^{sp}_i 들의 유사도 R(o, o_{v^{sp}_i}))를 계산한 뒤, 확실히 도달 가능하다고 판단되는 노드 중 가장 먼 노드를 웨이포인트로 선택하는 방식입니다.
v_w = v^{sp}_, \quad l = \max_i { i \;|\; R(o, o{v^{sp}<em>i}) > s</em>{\text{reach}} }여기서 s_{\text{reach}}는 도달 가능성을 판단하는 유사도 임계값이고, 경로에 존재하는 모든 노드에 대해 유사도를 계산하는 것은 비효율 적이므로 최소범위 노드와 최대 범위의 노드를 정해서 실제로는 탐색 범위를 [H_{\min}, H_{\max}]로 제한해서 계산 효율을 높였습니다.
결국 이렇게 선택된 웨이포인트에 대응되는 관찰 o_{v_w}를 중간 경유지로써 사용하게 됩니다.
위처럼 현재 위치에서 가장 멀지만 확실히 도달 가능한 중간 지점을 동적으로 계산한 후 현재 관찰과 웨이포인트를 L 네트워크로 전달합니다. 이후 L 네트워크는 그에 대응하는 액션을 ouput으로 뱉게 되고 에이전트는 해당 액션에 맞게 움직이게 됩니다. 이제 또 장소가 바뀌었으므로 다시 Localization(local)을 수행하고 (이때는 Global localization처럼 모든 노드에 대해서 R네트워크를 태우는 것이 아니라 이전 노드에서 근접한 몇개의 노드에 대해서만 유사도를 계산하고 여기서 가장 높은 노드로 localization을 수행합니다.) 다시 Planning을 수행하고 waypoint selection을 수행하고 L네트워크를 통해 실제로 움직이는 방식의 루프로 이 과정이 반복되면서 에이전트는 단계적으로 목표 지점에 도달하게 되는 구조입니다.
Experiment
실험파트는 사실 적어놓은 방법론에 비해 많이 비교하지는 않은 것 같습니다. 어떻게 보면 기하학적인 지도를 사용하지 않으면서 학습 기반이면서 위상 그래프를 기반으로 시각정보만을 바탕으로 내비게이션을 수행한 사례가 없었기 때문이지 않았나 싶습니다.
논문에서는 3D 시뮬레이션 환경에서 제안한 SPTM 구조를 검증했습니다. 환경은 마인크래프트와 비슷한 고전 게임 Doom기반으로 만들어졌다고 합니다. 에이전트가 이 안에서 목표 지점까지 내비게이션을 수행하는 형태로 실험이 진행되었습니다.

그림 3을 보면, 실제로 SPTM 에이전트가 미로 안에서 목표(goal)를 향해 이동하는 모습이 시각적으로 나타나 있습니다.
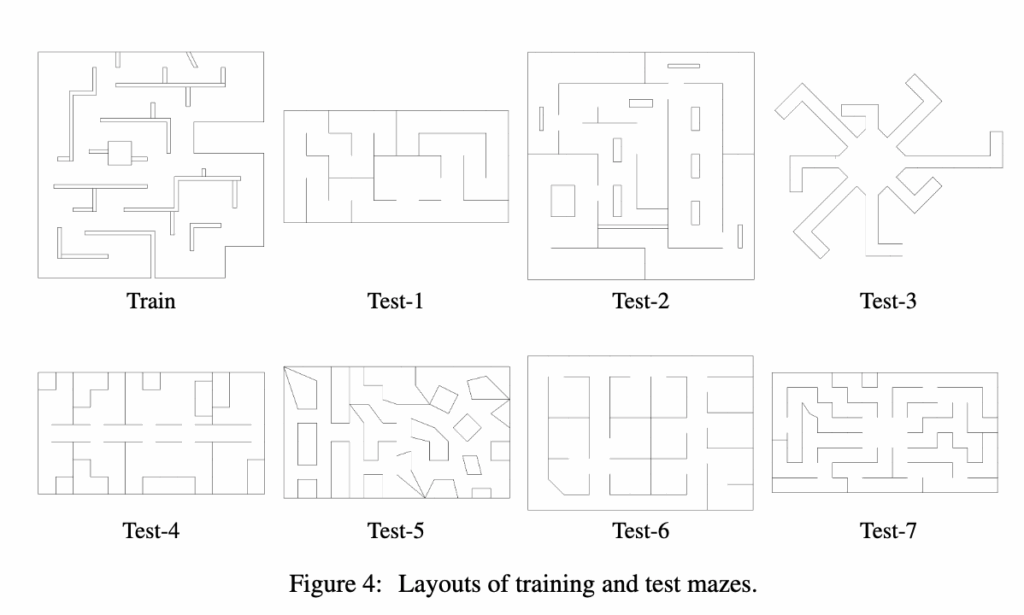
그리고 실험은 위와 같이 테스트용 미로 7개를 따로 제작해 훈련-테스트 간에 환경이 겹치지 않도록 했다고 합니다.
각 미로에는 4개의 목표 지점이 있습니다.
새로운 미로가 주어지면, 에이전트는 약 5분 분량(10,500 step) 의 탐색 시퀀스를 받습니다. 이 영상은 사람이 에이전트를 조작하면서 직접 미로를 돌아다니며 찍은 시퀀스로, 에이전트는 이를 기반으로 위상 그래프를 구성합니다.
그리고 실험시에는 각 미로마다 4개의 시작 지점 4개의 목표 지점, 그리고 각 조합을 6회 반복해서 수행합니다. 즉, 한 미로당 4×4×6=96회의 시도가 이루어집니다.그리고 에이전트가 5,000 step (약 2.4분) 안에 목표에 도달하면 성공으로 간주되는 방식으로 평가가 진행됩니다.
SPTM은 visual navigation중에서도 기하학 지도를 사용하지 않는 강화학습 기반 내비게이션 알고리즘과 성능을 비교했습니다. 결국 비교된 모델들은 모두 순수한 시각 정보만을 이용해 탐색과 내비게이션을 수행할 수 있는 구조입니다.
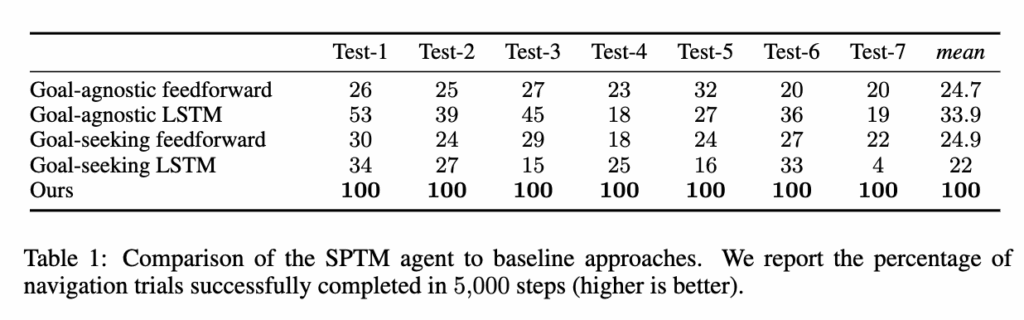
먼저 Goal-agnostic agent에 대해서 설명드리면 목표(goal)에 대한 정보가 전혀 주어지지 않는 에이전트라고 보시면 좋을 것 같습니다. 강화학습 기반의 A3C 알고리즘으로 학습되고 미로 안에 숨겨진 비콘을 하나 수집할 때마다 보상 1을 받고, 목표는 없기 때문에 순전히 탐색 능력만으로 움직입니다.결과적으로 보상만 보고 탐색을 반복하는 강화학습 기반 정책. 즉, 무작정 주변을 탐색하며 보상 신호를 높이는 행동만 학습하게 됩니다. 반면에 Goal-Seeking agent 같은 경우는 현재 관찰과 목표 이미지를 동시에 입력받고 마찬가지로 강화학습 기반으로 동작하고 이때는 목표 지점에 도달하면 보상 800을 주는 방식으로 학습이 진행됩니다. 그리고 feedforward 방식같은 경우는 목표가 시야에 있으면 그쪽으로 움직일 수 있지만, 메모리가 없기 때문에 탐색 단계에서 얻은 정보를 활용하지 못합니다. 여기서 LSTM기반의 agent같은 경우에는 LSTM 구조를 추가해서 탐색 중 얻은 정보를 기억할 수 있도록 설계했다고 합니다.
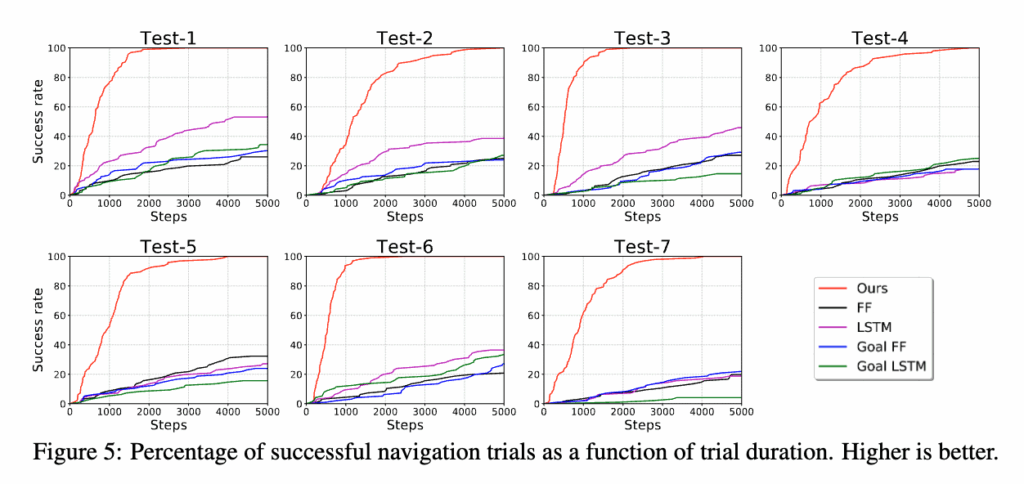
먼저 결과를 보면, SPTM이 모든 기준선을 압도적으로 뛰어넘는 성능을 보입니다. table 1을 보시묜 SPTM의 평균 성공률은 기존 최고 성능 모델보다 약 3배 높고, figure 5에서는 목표에 도달하는 속도 역시 훨씬 빠른 것으로 나타났습니다.
또한 feedforward와 LSTM 간의 성능 차이는 크지 않았습니다. 이건 LSTM이 단기 기억에는 유용하지만 탐색 단계의 긴 시퀀스(10,000 steps)의 장기 정보를 효과적으로 저장하기엔 한계가 있다는 걸 보여줍니다. 반면 SPTM은 구조적으로 모든 관찰을 명시적으로 저장하기 때문에 이런 문제에 대해서는 자유롭다는 점은 보여줍니다.
그리고 개인적으로 가장 신기했던 부분은 베이스라인들 중에서 가장 높은 성능을 보인 게 오히려 goal-seeking모델이 아니라 goal-agnostic모델이었다는 점입니다.
저자들은 그 이유를 두 가지로 설명하는데 첫번쨰로는 해당 모델이 환경의 구조를 진짜로 이해했다기보다 단순히 외관상의 패턴에 반응했을 가능성이 있다고 언급합니다. 그리고 또다른 한가지는 목표 도달 시 보상이 기존 보상에 비해 너무 커서 강화학습이 불안정해졌을 가능성도 있다고 분석합니다. 근데 보상을 낮춰서 한 실험은 따로 보여주지는 않았습니다.
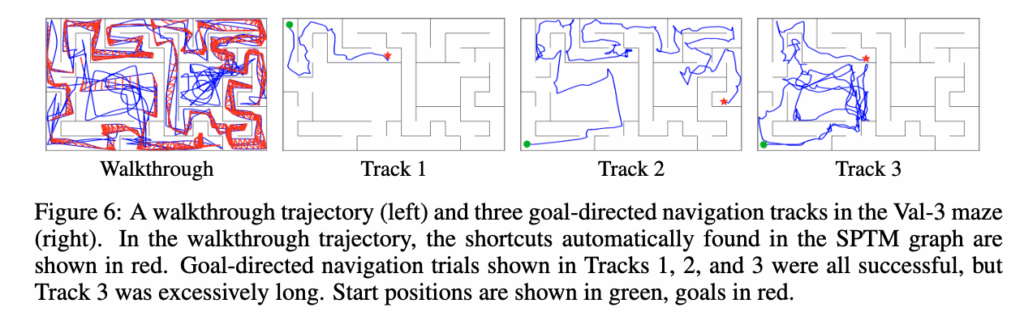
그리고 위 그림중에서 가장 왼쪽 그림은 탐색과정 이후 SPTM 그래프 내에 자동으로 추가된 지름길(shortcut) 연결이 빨간색으로 표시되어 있습니다. 이 지름길들이 그래프의 연결성을 크게 개선시켰다고 합니다. Track1,2 같은 경우 사실 shortcut이 없었다면 빙글 빙글 돌아서 오랜시간에 걸쳐 도착했을 수 도 있지만 shortcut 덕분에 단번에 짧은 경로로 에이전트가 움직인 모습을 보입니다. 하지만 Track 3에서는 불필요한 루프가 나타나는 모습을 보이긴 합니다.
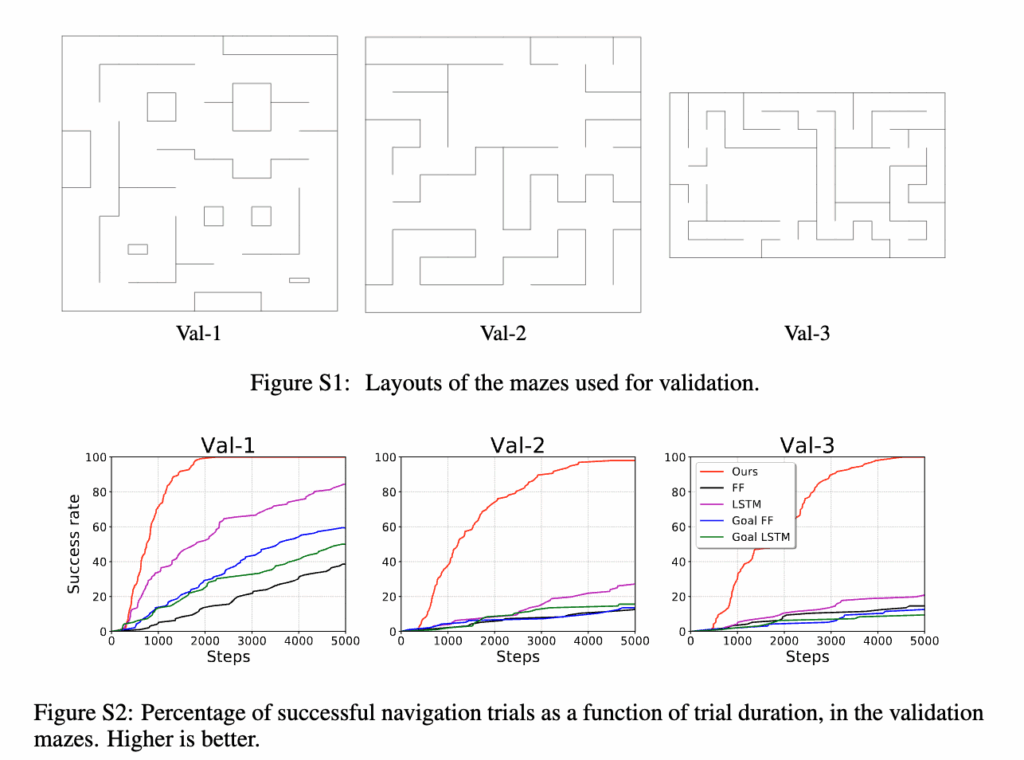
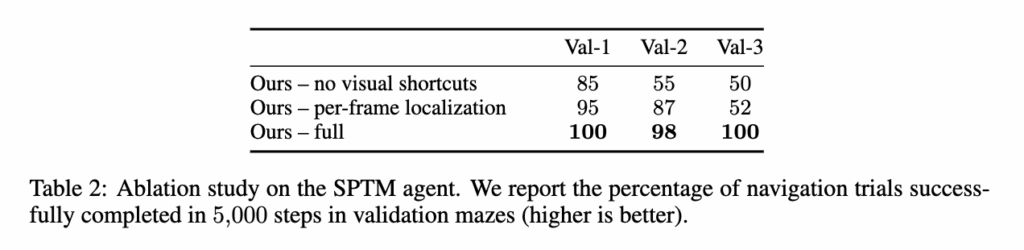
마지막으로, Ablation 실험을 통해 구성 요소의 중요성을 검증했습니다. 그래프에서 지름길 연결을 제거하면 성능이 급격히 떨어졌고, 매 localization시 Global localization만 수행한 경우에는작은 미로에서는 괜찮았지만, 복잡한 Val-3 미로에서는 성능이 크게 하락했습니다. 시각적으로 비슷한 장소 혼동 문제 때문에 오히려 전체 노드에 대해서 유사도를 비교하는 것은 노이즈 발생을 유발한다는 것을 보입니다.
conclusion
이번 논문은 SPTM라는 구조를 제안하고 탐색 데이터를 바탕으로 환경의 위상적 구조를 생성해 인간처럼 이를 실제 내비게이션 과정에서 계획-위치추정-제어로 연결할 수 있음을 보여줍니다. 단 5분의 탐색 영상만으로도 이전에 보지 못한 환경에서 안정적으로 목표를 찾아갈 수 있음을 실험으로 보여주었는데, 물론 시뮬레이션이면서 비록 전체적인 접근이 다소 휴리스틱하고 구조적으로 단순해 보일 수 있지만, 2018년 당시만 해도 단일 이미지만으로 즉각적인 행동을 예측하는 수준에 머물던 시점이었음을 고려하면 시각 정보만으로, 기하학적 지도 없이 내비게이션을 수행하는 이 방향성을 처음으로 구체화한 의미있는 연구라고 생각합니다. SPTM은 이후의 위상 그래프 기반 비주얼 내비게이션 연구들이 발전할 수 있는 기반을 마련한 한 논문이라는 생각이 듭니다. 이상 리뷰를 마치도록 하겠습니다. 감사합니다.
안녕하세요 우현님, 좋은 리뷰 감사합니다!
정밀한 기하학적 지도 기반의 SLAM과 단기 메모리 구조를 쓰는 대신, SPTM은 랜드마크와 연결 관계로 구성된 topological 그래프를 사용한다는 점이 흥미로웠습니다.
tolological map은 한번 만들어지면 변화하지 않는 구조인 것 같은데, 이후 연구들에서는 navigation실패가 발생했을 때 이를 어떻게 처리하는지 궁금합니다. 연구 흐름이 더 정확한 map을 구축하려는 방향으로 발전하는지, 아니면 실패를 인식한 뒤 재계획을 통해 복구하는 방향으로 더 발전하고 있는지 궁금합니다!
감사합니다.
안녕하세요 예은님 댓글 감사합니다.
먼저 navigation의 실패의 정의를 보통은 어떤 step 내에 원하는 목표지점까지 도달했는지에 대해서 success여부를 판단합니다. 그렇기 때문에 원하는 step 내에 목표 지점까지 도달 하기 위해서는 저 개인적으로도 이 topology map을 잘 만드느냐가 중요하다고 생각합니다.
저도 최신 논문들을 많이 읽은 것은 아니지만 기본적으로 예은님께서 말씀하신대로 더 정확한 map을 구축하기 위해서 실제 운행 과정에서 동적으로 그래프를 수정하는 경우도 존재합니다. 실패를 인식한 뒤 재계획을 통해 복구하는 방향도 기본적으로 SPTM에 사용되지만(실패를 직접적으로 인식하지 않지만 매번 localization시 일정 스레시홀드 아래면 다시 글로벌 localization하고 planning 수행) 이후에 더 발전하는 방향으로 나아가고 있지 않을까 싶습니다!
감사합니다.
안녕하세요 우현님 좋은 리뷰 감사합니다.
우선 옛날 논문인만큼 엄청 나이브한 접근방식처럼 느껴지긴 하네요. 동시에 저자가 말한 심리학적으로 인간이 위치를 기억한다는 내용에 저도 평소에 그렇게 생각하고 있었다는걸 앍게되었습니다.. 엄청 와닿네요. 궁금한점은 거리가 멀고 가깝고에 대한 2진 분류만으로 진행한 이유가 있을까요? 더 세분화하거나 할수도 있었을텐데, 최대한 단순하게 구현하려고 한 이유가 있는지 궁금합니다.
감사합니다.
안녕하세요 인택님 댓글 감사합니다.
일단 기본적으로 R 네트워크는 정확한 거리 추정(regression)보다는 시간적으로 얼만나 근접한지 자체를 학습시키는 것이 목적이었고 데이터도 postive 쌍 negative 쌍으로 만들기 때문에 가깝다 / 멀다라는 2진 분류를 학습했다고 보시면 됩니다. 근데 이후 논문들은 개념을 확장해서 인택님꼐서 말씀해주신 것 처럼 비슷하게 50개의 이산 구간으로 쪼개서 거리를 예측한다거나(예측한 거리는 위상그래프 간선의 가중치 값으로 됨) 아니면 직접적으로 step을 예측한다거나 다양하게 발전되는 것 같습니다.
감사합니다.
안녕하세요. 안우현 연구원님 좋은 리뷰 감사합니다.
기하학적인 지도 없이라고 언급해주셨는데, 지도에 대한 정보는 없이 1인칭 시각 정보 만으로 해결한 건가요? 그리고, 5000 스텝 안에 도달해야 성공이라고 했는데 논문의 성능이 100이라서 모든 시도가 성공이라는 것 같은데, 혹시 평균적으로 몇 스텝이 걸렸는지에 대한 분석도 있나요?
감사합니다.