이번 리뷰는 새로운 주제인 Colorization 관련 논문입니다. Colorization이란 간략하게 설명하면, gray image를 color image로 변화시키는 작업을 말하는데, 1채널 영상을 3채널 영상으로 바꾸기 위해서, 2개의 채널을 predict하는 것이 가장 큰 목표입니다.
Motivation
기존의 colorization은 어수선한 배경과 다수의 물체가 존재하는 영상에 대해서는 정확하고 선명한 colorization 결과값이 나오지 못하고 아래 그림처럼 색상이 잘 맞지 않는 문제가 발생했습니다.

input 영상에 대해서 colorization을 했을 때 다수의 물체 및 특정 background에서는 해당 논문의 기법(제일 우측)을 제외한 다른 방법론들은 물체의 정확한 colorization이 안됨.(특히 2번째 column)
해당 논문에서는 그 이유를 바로 기존의 model들은 영상 전체에 대해서 colorization을 했기 때문이다고 합니다.
즉 영상 전체에 대해서 colorization을 하려고 하다보니, 다수의 물체가 나오는 경우, 각각의 물체에 정확한 색상을 씌우는게 아닌, 영상 전체를 대표하는 컬러를 입히게 되는 것이지요.
이를 해결하고자 해당 논문에서는 pre-trained 된 object detector를 사용하여, 영상 속 물체를 검출 및 crop 하고, 해당 crop된 영상을 network에 태워서 colorization을 하고자 합니다.
이를 통해 영상 내에 다수의 물체가 나와도, 각 물체를 정확히 표현하는 색상이 나타날 수 있는 것 입니다.
Overview
먼저 해당 논문의 큰 흐름은 다음과 같습니다.
- Gray image를 input으로하여 pre-trained된 object detector를 이용해서 multiple object bounding box들을 추출한다.
- 1번에서 추출한 bounding box들을 resize함으로서, 즉석 이미지(instance images) set을 생성한다.
- 각각의 즉석 이미지와 제일 초기 gray scale image를 instance colorization network와 full-image colorization network에 태운다.(두개의 네트워크는 구조가 같으며 weight만 서로 다르다.)
- 마지막으로, Fusion module을 통해 각 instance feautre들을 full-image feature와 함께 fusion 시킨다.
- 이렇게 fusion된 j번째 full-image feature는 j+1번째 layer의 input으로 들어가며 다시 3번과정부터 시작하여 제일 마지막 layer에 도달할 때까지 반복한다.
- 제일 마지막 layer에 도착하면 color를 예측한다.
큰 흐름에 대해서 알아봤으니 조금 더 디테일한 부분에 대해 알아봅시다.
Object Detection
먼저 해당 논문에서 사용된 pre-trained object detection은 바로 Mask R-CNN 입니다. 해당 detector를 통해 나온 각 object의 bounding box를 통하여, input 영상의 gray scale image와 GT 영상(학습시)인 color 영상에서 해당 박스 영역만큼을 crop한 후 256 × 256으로 resize 합니다.
Image colorization backbone
위에 그림은 Image colorization network의 전체적인 architecture 입니다. 그림을 보면 알 수 있듯이, 네트워크가 크게 2가지 branch로 나뉘어져 있습니다.
각 branch별로 설명을 드리면, 먼저 하나는 instance image(bounding box를통해 crop 후 resize 된 영상)을 colorization하는 네트워크이며, 나머지 하나는 전체 입력 영상(full image)를 colorization하는 네트워크를 말합니다.
두 branch가 서로 동일한 수의 layer를 가진 것을 보실 수 있는데, 이를 통하여 보다 용이하게 feature를 fusion 할 수 있습니다.
colorization network의 backbone으로는 [ SIGGRAPH 2017]에 올라온 Real-Time User-Guided Image Colorization with Learned Deep Priors 모델을 사용했다고 합니다.
Fusion module
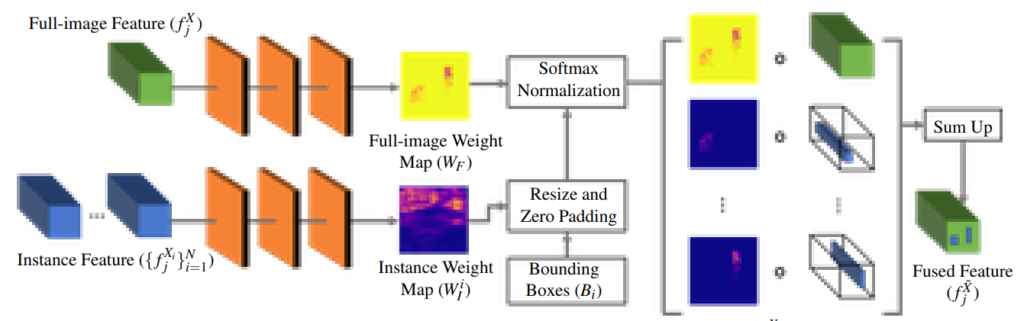
그렇다면 해당 논문에서는 어떤 방식으로 multiple instance feature를 full image feature와 fusion 했을까요?
해당 논문에서는 다중 레이어에서 fusion을 진행할 때 보다 간단하게 하기 위해서, fusion module이라는 것을 추가하였다고 합니다.
fusion module은 2개의 input을 필요로합니다. 먼저 첫번째는 full-image feature를 나타내는 f_{j}^{X}, 두 번째는 instance feature bunch(set)과 그에 대응되는 object bounding boxes\{f^{X_{i}}_{j},B_{i}\}입니다.
먼저 각 종류 별 feature들은 3개의 컨볼루션 레이어를 통과함으로써, full-image wieght map인 W_{F}와 per-instance weight map인 W^{i}_{j}를 구하게 됩니다.
그리고 나서 각 instance feature( f^{X_{i}}_{j}를 full-image feature(f^{X}_{j})와 fusion하게 됩니다. 이 때 instance feature의 크기와 위치를 정의해주는 bounding box(B_{i})를 input으로 사용하게 됩니다.
또한 instance feature를 resize 할 뿐만 아니라, weight map(W^{i}_{I})을 zero padding 함으로써 full image와 동일한 사이즈가 되게끔 합니다.
이렇게 resize된 instance feature와 zero padding 된 weight map을 각각 f^{\hat{X}_{i}}_{j}, \hat{W}^{i}_{I}라고 명칭합니다.
그 이후에 모든 weight map을 쌓아서, 각 픽셀별로 softmax를 적용시킨 다음, weighted sum을 통하여 fusion된 feature를 아래 수식과 같이 표현할 수 있습니다.
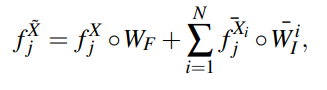
여기서 N은 instance feature의 개수입니다.
Loss Function
Loss function은 위에서 언급했던 backbone인 Time User-Guided Image Colorization with Learned Deep Priors 의 loss를 그대로 사용하여서인지, 수식 만 하나 나와있고 설명이 나와있지 않습니다.
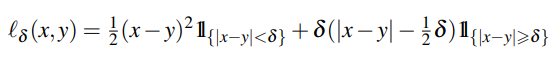
Loss function
해당 부분에 대해서는 Time User-Guided Image Colorization with Learned Deep Priors 논문을 읽고 내용을 추가 및 보충하고자 합니다.
Experiments
먼저 평가에 사용된 데이터 셋은 크게 3가지로 다음과 같습니다.
- ImageNet – ImageNet은 기존에 존재하는 수 많은 colorization method에서 사용되는 데이터 셋으로, 성능을 평가할 때 많이 사용된다고 합니다.
- COCO-Stuff – Object centric image인 ImageNet과 대조적으로, COCO-Stuff 데이터 셋은 다수의 물체가 존재하는 넓고 다양한 자연 장관 영상들을 가지고 있다고 합니다.(보다 현실적이고 복잡한 데이터 셋)
- Places205 – 모델이 잘 학습됐는 지를 판단하기 위해 평가만을 위한 데이터 셋으로 Place205를 사용했다고 합니다. 그래서 해당 데이터 셋으로는 학습을 전혀 하지 않았다고 하네요.
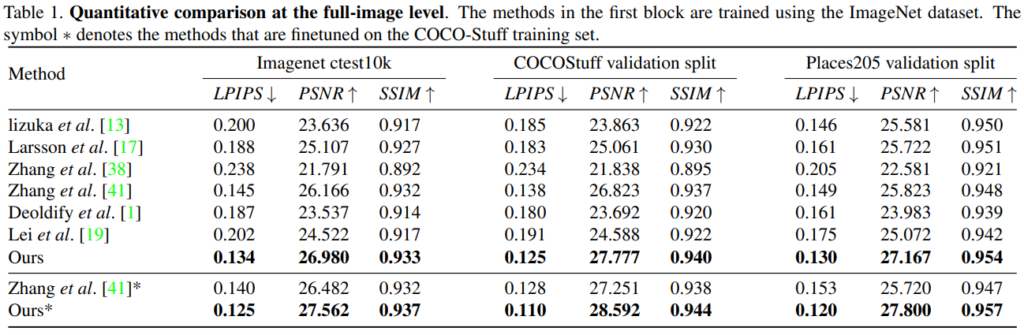
위에는 정량적인 표로, LPIPS는낮을수록 좋고,PSNR과 SSIM은 높을수록 좋은 것입니다. 각 평가 메트릭에 대해서도 추후에 공부해서 정리하도록 하겠습니다.
일단 해당 논문에서 제안된 방법론이 CVPR2020에 나온 논문답게 다른 방법론들에 비해 제일 좋은 성능을 보이고 있네요.

위에 그림은 정성적인 그림으로, 다수의 물체 및 혼잡한 배경에서도 선명하게 colorization이 된 모습입니다.
그럼 모델이 이미지 컬러를 예측할 때, 픽셀 단위인가요?
end-to-end 방식의 colorizations은 train DB에서 물체의 컬러 정보를 학습하고 예측하는 것으로 보이는데 맞나요?
그럼… DB의 경향성을 많이 받는 방법론 같은데, 실험 결과 중 train DB와 평가 DB가 다른 실험 내용이 있나요?
ㅖ