본 논문은 비디오 연구에서 Sampling Dilemma 문제를 수면 위로 올리며, 이를 위한 벤치마크 데이터셋을 공개하는 논문입니다. Sampling Dilemma란 무엇인지에서 부터 논문이 어떻게 벤치마크를 구성했는지 리뷰를 통해 다루어보겠습니다.
#Problem Setting.
Sampling Dilemma: Too few and Too much!
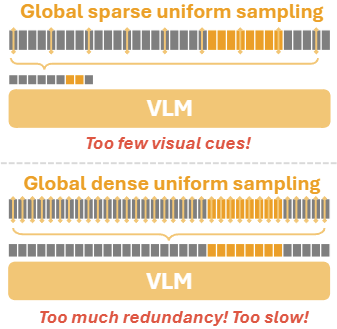
Large Vision-Language Models (LVLMs)이 발전하면서 Video understanding 역량을 향상시키고 있습니다. 그러나 비디오를 다룰때 항상 논의되는 문제는 중복 정보나 노이즈에 따른 연산량 문제인데요, 이를 해결하기 위해 통상 일정 간격으로 프레임을 선택하는 Uniform Sampling이 사용됩니다.
유사 연구간의 비교를 위해 Sampling 사용이 일반화 되었지만, 해당 방법에 문제점이 없을까요? 원본 데이터를 축소하는 과정에서 우리는 Sampling Dillemma 즉, 너무 많은 정보를 없애면 중요한 정보를 누락할 위험성이 높아지고(Too few) 그렇다고 없애는 정보의 수를 줄인다면 샘플링의 효과인 중복 정보 제거 등의 이점을 갖지 못한다(Too much)는 딜레마에 빠지게 됩니다.
—
Then, what we have to do?
현 시점에서 Sampling Dillemma는 지금 long-video를 다루는 테스크에서는 발생할 수 밖에 없는 문제입니다. 그렇다면 해결 방법은 무엇일까요?
단순합니다. Random sampling이 아니라 중요한 부분만 잘 선택할 수 있는 Sampling 전략을 도입하여 중복은 줄이고 LLM에게 입력할 컨택스트는 유지하도록 하는것입니다.
#The strategy.
Sampling Dillemma의 해결책은 단순했습니다. 단순한 해결책이 왜 여지껏 구현되지 못했을까요? Uniform sampling으로 대체되었던 이유가 무엇일까요? 원인은 Necessary Sampling Density (NSD) 입니다.
Necessary Sampling Density: The reason makes the task challenging.

최신 Video understanding 연구는 이러한 Samling Dillemma에 대해 보통 Uniform sampling 전략을 적절하게 활용하는것으로 대응합니다. 그러나 Uniform sampling을 아무리 적절히 조절하더라도 Trade off를 해결할수는 없습니다.
예제를 통해 살펴봅시다. 위의 그림1은 Video understanding의 대표적인 테스크인 VQA의 시행 예시인데요, 질문에 따라 집중해야하는 영역(영상의 노란색 바)이 다르며, 그 밀도도 다릅니다. 어떤 질문은 영상에서 전역적인 정보가 중요하고, 다른 질문은 영상에서 해당하는 지엽적인 정보가 밀도있게 중요하며, 테스크를 수행하기 위한 필수(Necessary) 샘플링 밀도(Sampling Density)가 상이하다는 것입니다.
즉, Sampling Dillemma를 해결하기 위해서는 NSD를 고려한 샘플링 전략을 제시해야한다는 것입니다. 논문에서는 이러한 필요성을 말하며 연구를 위한 벤치마크를 제시하고 있습니다.
—
The Benchmark. LSDBench.
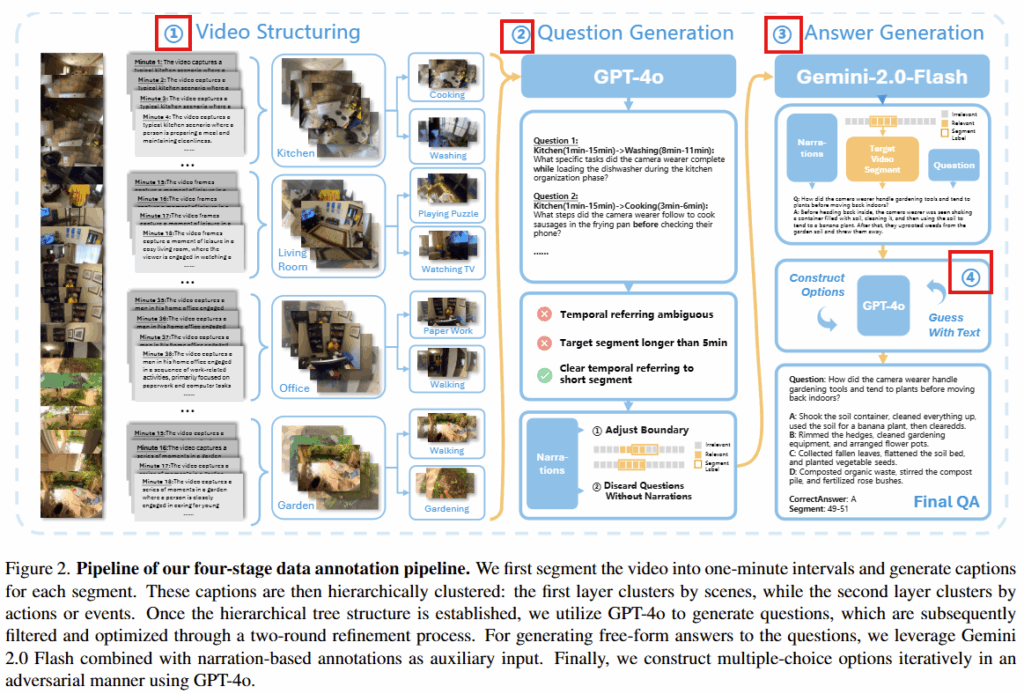
논문은 기존 Video Understanding을 위한 데이터셋의 경우 이러한 NSD를 고려해 구축한 데이터셋의 부재함을 언급하며 데이터셋인 LSDBench를 제시합니다. LSDBench는 HourVideo 비디오셋의 서브셋에 대한 추가 어노테이션을 통해 구축되었으며, 가공 방식은 그림2와 같습니다.
논문은 Long video에 대해 다양한 NSD를 필요로하는 질의응답셋을 구축하기 위해 4단계 파이프라인을 제시하였습니다: Video Hierarchical Structing, Questioin Generation, Answer Generation, Multiple-choice Question Construction
(1) Video Hierarchical Structing
긴 비디오에 대해 LLM을 활용한 효과적인 어노테이션 구축 파이프라인을 위해 논문은 먼저 비디오를 계층적으로 나누는 단계를 수행하였습니다. 이는 가장 먼저 GPT-4o를 통해 캡션을 생성하고 캡션을 clustring 하는 순서로 수행되었습니다. 특히 장소를 기반으로 한번 클러스터링하고, 다음단계로 event나 action 단위로 클러스터링 하여 트리구조를 구축했다고 합니다.
(2) Question Generation
비디오에 대한 질문 생성은 앞서 구축한 트리 계층 구조를 활용하여 5분 이하의 (원본영상 평균 45.39분) 콘텍스트를 활용해 LLM(GPT-4o)을 활용해 자동으로 질문이 생성하고 이후 필터링 하는 방법으로 진행되었습니다. 필터링 또한 2 단계로 진행했는데, 첫번째 단계에서는 LLM을 활용하여 명확하지 않거나 모호한 단어를 포함한 질의를 제거하였으며 두번째 단계에서는 LLM을 활용할때, 나레이션 정보를 활용하도록 하여 비디오 컨텍스트와 관련이 없다고 판단되는 질문을 제거하는 과정을 수행했습니다.
(3) Answer Generation
정답 생성의 경우 Gemini-2.0-Flash를 이용하여 비디오와 비디오에 세그먼트에 대한 나레이션 정보, 비디오와 정답 세그먼트, 쿼리까지 모두 입력으로 하여 정답을 생성하도록 했습니다.
(4) Multiple-choice Question Construction
생성된 답변을 활용하여 다지선다형의 질의응답 세트를 구축하기 위한 과정입니다. 비전 정보 누락없이 답변을 수행하지 못하도록 적대적 최적화 방법을 활용했다고 합니다. 즉, 초기에 다지선다 질문을 생성한 후, 정답을 영상없이 선택하는 과정 시뮬레이션을 반복했습니다.
—
The Baseline. Sempling strategy.
Sampling Dillemma를 해결하기 위해 논문은 2 stage 기반의 training-free 샘플링 전략인 Reasoning-Driven Hierarchical Sampling (RHS)와 plug and play로 동작할 수 있는 보조 전략인 Semantic-Guided Frame Selector를 제안합니다.
(1) Reasoning-Driven Hierarchical Sampling (RHS)
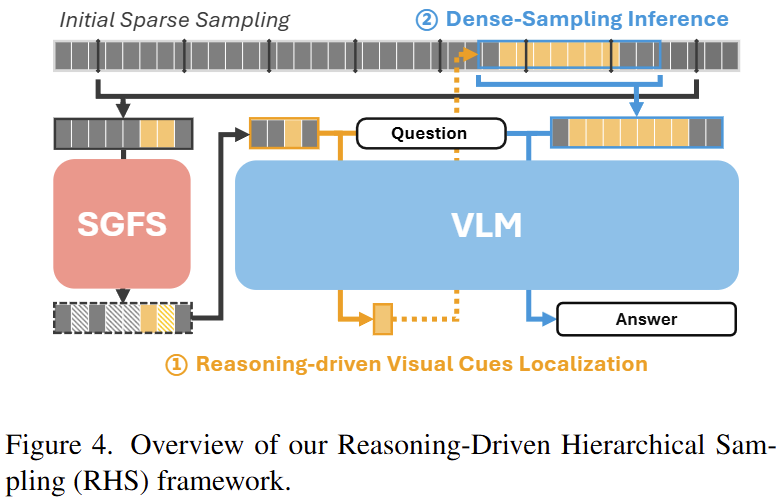
논문은 질의에 대한 NDF를 찾기 위하여 먼저 대략적인 위치를 특정하는 1단계와 Dense-Sampling을 진행하는 2단계로 구성된 RHS(Reasoning-driven Visual Cues Localization) 전략을 제안하며 개요는 그림3과 같습니다.
먼저 첫번째 스테이지에서는 전체 비디오를 전반적으로 희소 샘플링(그림3의 Initial Sparse Sampling)합니다. 해당 값을 키프레임으로 하여 VLM에 입력합니다. VLM은 질의와 시간적 정보를 고려하여 질의와 관련있는 영역을 특정합니다(그림3의 상단 원본 영상에서 파란 괄호로 표시된 영역)
다음 스테이지에서는 특정된 영역을 조정하는 단계로, 선택된 구간에서 더욱 밀도있게 샘플링합니다. 이렇게 검색과 재샘플링이라는 2stage 접근법으로 NDS에 효과적인 샘플링 전략을 제시합니다.
(2) Semantic-Guided Frame Selector

앞선 전략은 Uniform sampling에 비해 필요되는 프레임을 효과적으로 줄일 수 있지만, 초기 sparse한 샘플링을 통해 핵심 정보를 누락할 가능성이 있습니다. 이를 막기위해 초기 sampling에서 단순하게 uniform sparse sampling이 아닌, 선별적 전략인 SGFS(Semantic-Guided Frame Selector) 제안했습니다. 해당 전략은 비디오에서 정보량이 가장 많은 영역을 선별해 내는 것으로 프레임들을 SigLIP2와 같은 VLM으로 임베딩하며, 임베딩된 Feature간의 Cosine similarity를 최대화할 수 있는 k개의 쌍을 다이나믹프로그래밍 방식으로 선별합니다. 이때, 단순히 Cosine similarity 뿐 만 아니라, 프레임간의 거리를 고려하는 페널티 전략도 합산하여 사용하며 수식은 위의 그림4와 같습니다.
#The proof.
Results on Benchmark.
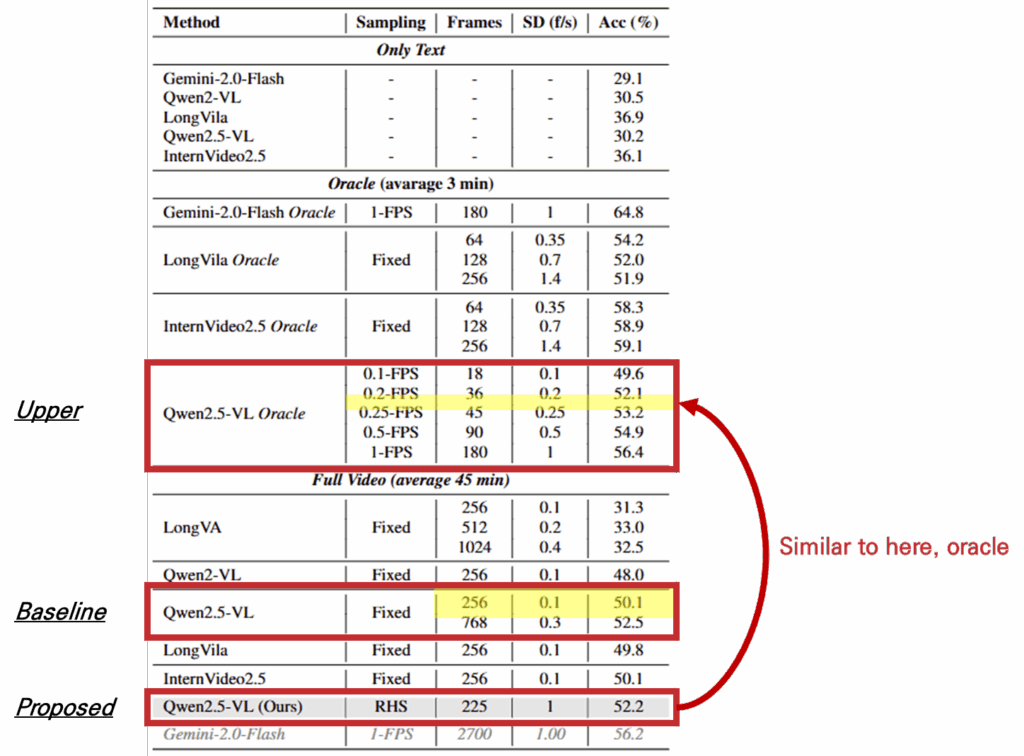
표1의 벤치마크 실험 결과는 Sampling Dilemma가 실제로 존재하며 중요한 문제임을 시사할 수 있는 결과입니다. 실험은 표에서 확인할 수 있듯이 Gemini-2.0-Flash, Qwen-2.5VL, Qwen-2VL, LongVA, LongVila, InternVideo2.5에 대해 진행되었으며 Uniform sampling으로 1FPS를 기준으로 하였으나, 제안된 데이터셋이 long video이기 때문에 해당 입력을 수용하지 못하는 모델의 경우 모델에 고정된 입력에 맞추어 샘플링(Fixed)하여 실험을 진행했다고 합니다.
실험의 상한을 제공하기 위한 Oracle 실험과 전체 비디오를 활용하는 Full video에서 알 수 있듯이 쿼리 등에 적합한 영역에서 샘플링을 진행하는것이 Uniform sampling 보다 유용하며 NSD를 고려한 샘플링이 필수적임을 확인할 수 있습니다. 또한 Qwen2.5-VL 모델에 대해 기존 샘플링 기법을 사용하여 256개의 프레임을 선정한것에 비해 제안하는 RHS 전략으로 225개의 프레임을 선정하는것이 유의미했으며, 이는 Upper에서 0.2 FPS로 샘플링한것보다 높은 성능으로 영상의 주요 위치를 Uniform sampling 대비 잘 특정하고 있음을 알 수 있습니다.
Ablation Study
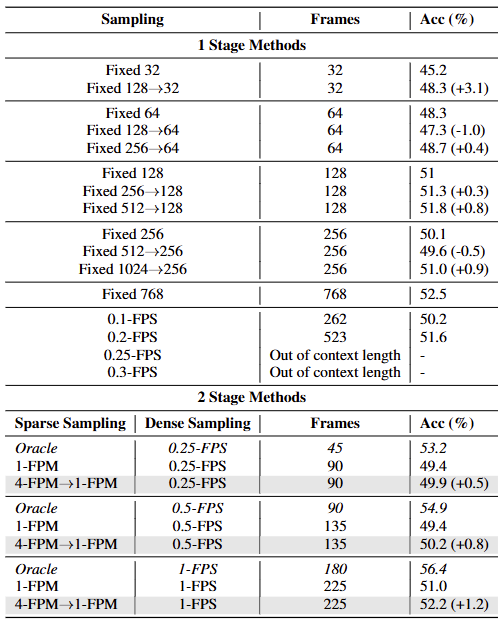
표2는 논문이 제안한 샘플링 전략에서 plug and play로 동작하는 SGFS가 유의미한지 보이고 있습니다. 해당 분석 실험은 Qwen2.5-VL를 VLM 모델로 실험했습니다. 먼저 1 Stage Methods는 uniform sampling 대비 단순 SGFS로 샘플링한 결과의 정확도를 비교하고 있습니다. 해당 결과의 첫 행을 보면, Uniform sampling을 통해 32개의 프레임을 선택했을때 보다, 128개의 프레임을 초기 샘플링하고 제안하는 SGFS로 쿼리기반 의미가 높은 영역에서 밀집되도록 32개의 프레임 샘플링을 하였을때 성능이 3.1정도 개선되었음을 확인할 수 있으며, 다양한 세팅에서 전반적으로 성능이 개선되는것으로 제안 방법이 유의미했음을 확인할 수 있습니다.
다음으로 완전한 RHS에 대한 결과인 2 Stage Methods입니다. 전체 영상에 대해 uniform sampling으로 입력하였을때 최대 정확도는 0.2-FPS로 523개의 프레임을 선별해 추론한 51.6%에 해당합니다(표2의 6행 참조) 그러나 2 Stage가 모두 적용된 RHS의 경우 225개의 프레임으로 52.2의 성능을 달성함을 통해 제안 방법의 효과를 확인할 수 있습니다.
본 논문은 현재는 arXiv 2025에 올라와있으며 깃허브를 통해 ICCV 2025 게제 예정임을 알 수 있는 논문입니다. 게제가 된 이후에 instruction 등을 제공하지 않을지 기대해 봅니다. 현재로서는 찾을 수 없어 어노테이션 등에서 VLM 활용에 있어 설명이 약간은 구체적이지 않은 부분이 있는점 양해 부탁드립니다. 이상으로 논문에 대한 소개를 마치겠습니다. 감사합니다.
유진님 좋은 리뷰 감사합니다.
기존의 video 연구에서 어떻게 샘플링을 해야 하는지에 관한 논문으로, 해당 논문은 NSD를 고려한 샘플링 전략을 제안하며, 벤치마크를 함께 제안한 연구로 이해하였습니다.
video hierarchical structing과정은 gpt-4o로 구한 캡션을 기준으로 진행이 되다보니, 이 캡션의 퀄리티가 굉장히 중요할 것 같습니다. 장소에 대한 정보 뿐만 아니라, event와 action에 대해서 따로 평가하거나 신뢰성을 어떻게 이야기하지는 않는지 궁금합니다.
또한, 비디오에서 정보량이 가장 많은 영역을 선별하는 과정에 대하여 궁금한 것이 있습니다. cosin similarity와 프레임간 거리를 함께 고려하여 쌍에 대한 가중치를 구한 뒤, 이 값이 큰 프레임들을 선별하는 것으로 이해하였는데, 그렇다면 유사한 프레임들만 뽑는것이다보니, 중복으로 볼 수 있지않을까 하는 생각이 들었습니다. 혹시 이에 대해 설명 부탁드려도 될까요?
안녕하세요 질문 감사드립니다.
먼저 event와 action 관련하여 답변드리겠습니다. 이를 활용하는 이유는 자동 question generation을 용이하게 하기 위함입니다. question generation이후 추가 2단계의 필터링 과정이 있기 때문에 해당 추론에 신뢰성평가는 따로 진행하지 않은 것 같습니다.
다음질문에 대해서는 우선 논문에서는 그림4의 프레임 거리 기반 패널티로 대응하고 있습니다. 즉 특정 영역에서 많은 정보를 뽑지 못하게 하므로서 중복 정보를 추출하지 않으려는 것인데, 멀리있지만 동일 장면이 반복된다면 허점으로 작용할 수 있을것 같기는 합니다.
이상입니다.
굉장히 흥미로운 논문 리뷰인 것 같네요.
로봇 러닝 측에서는 반드시 비디오 데이터를 입력으로 받을 수 밖에 없는 상황에서 중요한 정보만을 샘플링 할 수 있고 해당 정보만 예측하도록 유도한다면 정말 좋을 것 같다는 생각이 들어 집중해서 읽게된 것 같습니다.
간단한 질문 몇 가지하고 가도록 하겠습니다.
Q1. (2) Question Generation에서 나레이션 정보는 어떤 정보를 말하는 것일까요?
Q2. (4) Multiple-choice Question Construction에서 “적대적 최적화 방법을 활용”라고 하였는데 구체적인 수행 방법에 대해서 궁금합니다.
Q3. (1) Reasoning-Driven Hierarchical Sampling (RHS)에서 파란색 괄호의 크기는 하이퍼파라미터로 적용하는 것인가요?
Q4. 그림 3의 비디오의 크기는 40분대의 크기의 비디오가 아닌 5분대의 비디오가 입력으로 들어가는 걸까요? 만약에 맞다면 5분으로 샘플링하는 방법은 무엇인가요?
Q5. fixed는 어떤 방식으로 샘플링하는 건가요?? oracle이랑 차이가 무엇인지 궁금합니다.
안녕하세요 질문 감사드립니다.
하나씩 답변드리면 아래와 같습니다
Q1. 나레이션 정보란 논문에서 활용한 EGO4D 데이터셋에서 제공하는 액션에 대한 라벨입니다. (예를 들어 C가 병을 연다)
Q2. Multiple-Choice Question Construction이란 다중선지가 너무 쉬워서 LLM이 혹여 비디오 정보를 활용하지 않고도 답을 알 수 있는 상황을 예방하기 위한 것으로, 논문에 “To prevent scenarios where the correct answer can be easily guessed based on the question and options alone, we incorporate an adversarial option optimization process”로 언급되어 추가 설명은 어려우나, GAN loss처럼 GPT-4o가 생성한 답이 정답이 아니게 하도록 추가 모듈을 두어서 설계하지 않았을까 추측합니다.
Q3. 해당 파라미터 또한 확인하지 못했는데요, These keyframes and their indices are fed into VLM, which reasons over the question and spatiotemporal context (e.g., chronological order, causal logic, co-occurrence of objects) to identify segments that has visual cues relevant to the question.로 언급되어있으며 threshold등을 이용하지 않았을까 합니다..
Q4. 40분대의 비디오에서 쿼리 기반 유용한 정보를 샘플링하는 방법으로 이해하시면 될 것 같습니다.
Q5. Fixed는 Uniform sampling으로 보시면 됩니다. Oracle과는 별개입니다. 예를들어 표1을 보시면 쿼리와 직접적으로 연관있는 3분 영역대에서 Fix sampling을 한 결과값은 Oracle-Fixed로 써있으며, 전체 영상에서 Fix sampling한 결과값은 아래의 Full video-Fixed로 리포팅되어 있습니다.
이상입니다.