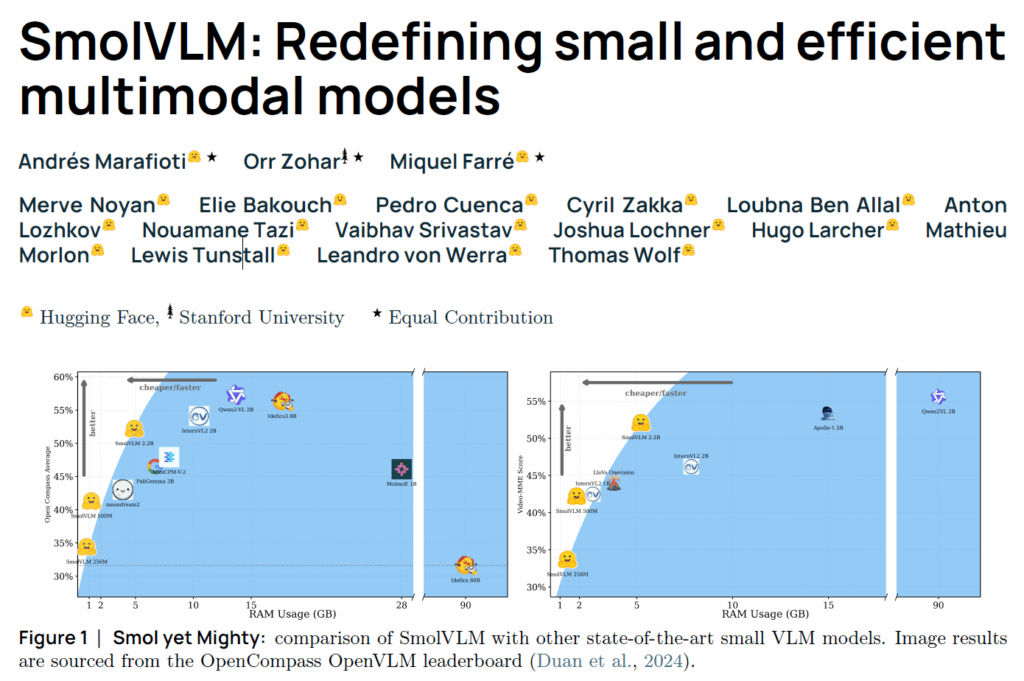
이번에 소개드릴 논문도 어쩌다보니 VLM 관련 논문입니다. 근데 이제 efficiency를 고려한. 무언가 의도한건 아니지만 자꾸 효율성을 강조하는 논문들을 찾아읽게되는 것 같네요 허허. 해당 논문은 아직 arxiv에만 공개된 것 같은데 Hugging Face에서 작성한 논문입니다.
Intro
인트로에서 다룰만한 내용이 크게 없어서요. 저자들의 contribution을 요약하면 다음과 같습니다.
Compact yet Powerful Models: 강력한 소규모 멀티모달 모델 제품군인 SmolVLM을 소개하며, 세심한 아키텍처 설계를 통해 성능 저하 없이 리소스 요구사항을 크게 줄일 수 있음을 보여줌.
Efficient GPU Memory Usage : 저자들의 가장 작은 모델은 1GB 미만의 GPU RAM을 사용하여 추론을 실행하며, 이는 온디바이스(on-device) 배포의 장벽을 크게 낮춤을 시사함.
Systematic Architectural Exploration: 저자들은 인코더-언어모델(LM) 파라미터 균형, 토큰화 방법, 위치 인코딩, 훈련 데이터 구성 등 아키텍처 선택이 미치는 영향을 실험하였고, 소형 VLM에서 성능을 극대화하는 핵심 요소를 분석함.
Robust Video Understanding on Edge Devices : 저자들은 SmolVLM 모델이 비디오 작업에도 효과적으로 일반화되어 Video-MME와 같은 어려운 벤치마크에서 SOTA 방법론들과 비교하여 경쟁력 있는 점수를 달성하였고 이는 다양한 멀티모달 시나리오와 실시간 온디바이스 애플리케이션에 대한 적합성을 강조함.
Fully Open-source Resources: 모든 모델 가중치, 데이터셋, 코드, 그리고 스마트폰에서 추론을 시연하는 모바일 애플리케이션 등을 다 오픈소스로 공개함.
How to assign compute between vision and language towers?
우선 VLM은 다들 아시다시피 Vision Encoder와 Text token embedding을 수행하는 tokenizer 그리고 이들의 modality를 정합시키는 projector, 마지막으로 해당 멀티모달 토큰들을 입력으로 하여 최종 결과물을 추론하는 LLM으로 구성되어있습니다.
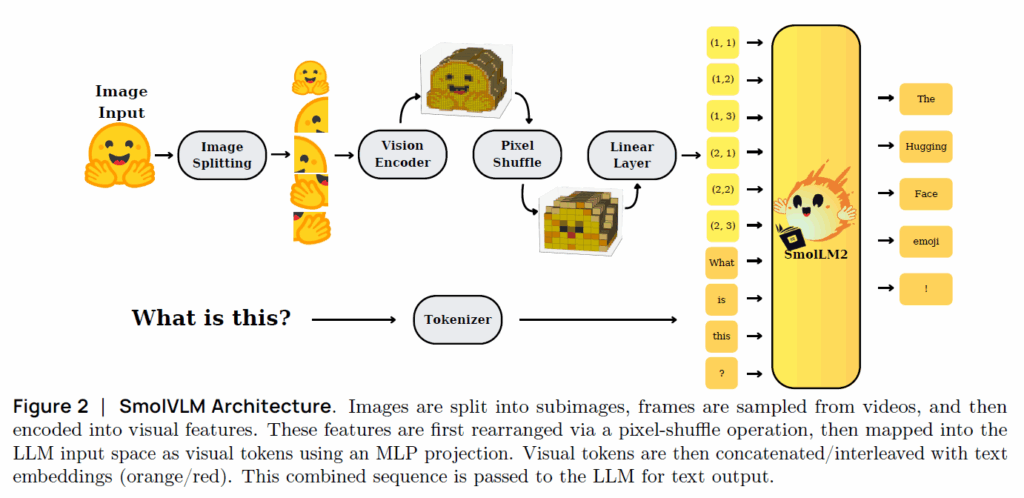
저자들의 목적은 효율적인 VLM을 설계하는 것이 목표이기 때문에 이러한 목표 달성을 위하여 다양한 실험들을 진행하게 됩니다. 그 중에서 첫번째로 수행한 실험은 Vision Encoder와 Language Model(LM)의 연산양을 각각 얼만큼 배정할 것인지에 대한 실험입니다.
구체적으로, 저자들은 (허깅페이스에서 제안한) language model 중 하나인 SmolLM2의 3가지 사이즈(135M, 360M, 1.7B params)에 2개의 SigLIP Encoder를 조합하여 각각 파라미터 증가 대비 성능 향상이 얼마나 커지는지에 대하여 실험을 진행하였습니다.
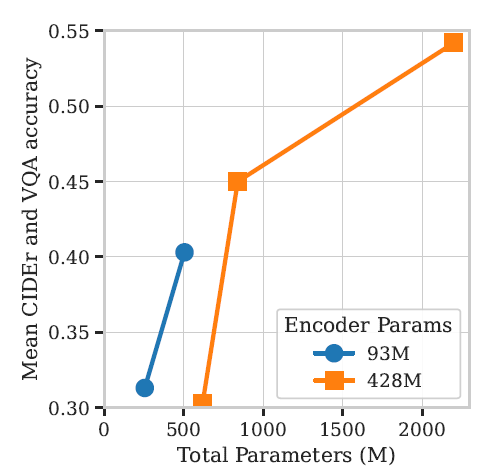
그 결과가 위의 그래프인데, x축은 VLM의 전체 파라미터 수를, y축은 Captioning task와 VQA task에 대한 CIDEr 및 accuracy metric을 평가한 것으로 CIDEr이 정확히 어떤 지표인진 모르겠지만 높을수록 모델이 잘 맞춘다고 이해하시면 될 것 같습니다. 그리고 동그라미는 SigLIP Vision Encoder의 ViT-B(93M)을 의미하며, 네모는 이보다 더 큰 파라미터수를 지닌 SigLIP-SO400M (428M) 모델이라고 합니다.
우선 그래프의 결론부터 말씀을 드리면, Vision Encoder의 크기가 크고 Language model의 사이즈가 작으면 성능이 떨어진다라는 점입니다(좌측 하단 동그라미와 네모의 성능 차이 참고)
물론 LM의 크기가 점차 커질수록 성능이 향상되며 이 성능 향상의 폭은 Vision Encoder의 사이즈가 클수록 더 좋아집니다. 물론 그만큼 파라미터수의 증가도 크게 늘어나게 되긴 합니다.
결과적으로, 저자들이 해당 실험에서 보여주고 싶었던 것은 작은 크기의 multi-modal model은 vision encoder와LM 간의 균형 잡힌 매개변수 할당을 해주어야 큰 이점을 볼 수 있으며(즉 두 모델의 파라미터 수가 차이가 심하게 나면 모델의 무게 대비 성능 이점을 보기 어렵다는 의미인듯?), 효율성을 위해 (LM을 작은 모델을 사용할거면) 더 작은 비전 인코더를 사용하는 것이 좋겠다는 것이죠.
How can we efficiently pass the images to the Language Model?
보통 VLM에서의 LM은 Vision Encoder의 visual token과 text token들을 서로 concatenation한 뒤 이들을 입력으로 받아서 self-attention 연산을 수행하게 됩니다. 원래의 LM의 경우에는 text 토큰만을 입력으로 고려했기 때문의 context의 길이가 2K token으로 제한되었지만, Visual token까지 함께 고려해야하는 VLM 특성상 기존에 사용했던 context 길이 제한을 더 크게 늘려야할 필요가 있습니다.
실제로 512×512 해상도의 영상에 대하여 SigLIP-B/16의 경우 1024개의 visual token을 생성하기 때문에 더 큰 이미지 해상도를 처리하거나 입력으로 주어진 텍스트의 길이가 긴 경우 2K는 훌쩍 넘길 수 있기 때문이죠. 그래서 저자들은 RoPE를 10K에서 273K로 크게 증가시킴으로써 context length를 확장하였다고 합니다.
저자들이 기존 LM을 더 긴 context에 대해서 fine-tuning을 할 때 1.7B 크기의 LM에서는 16K 길이의 token에서도 안정적으로 학습이 진행되었으나, 이보다 더 작은 사이즈인 135M과 360M 모델에서는 context length가 8K 이후로는 학습에 어려움을 겪었다고 합니다.
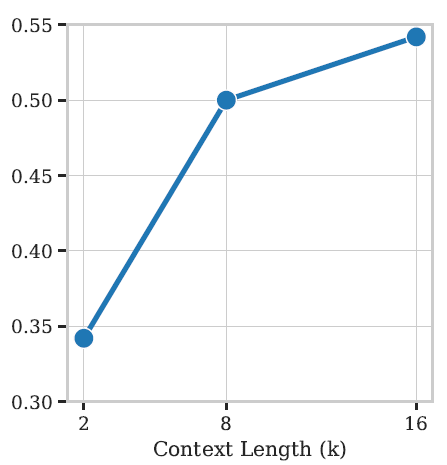
그래서 우선 2.2B정도의 크기를 가지는 SmolVLM의 경우에는 Context Length를 2->8->16k로 늘리면 늘릴수록 성능이 개선되었다는 점을 토대로 16K token capacity를 최종으로 하였으며, 이보다 더 작은 사이즈의 모델의 경우 8K의 캐파를 지니도록 학습시켰다고 합니다.
정리하면, VLM은 context의 길이가 확장됐을 때 성능이 크게 개선될 수 있지만 LM의 사이즈를 고려해서 늘려야한다는 점이겠네요.
근데 이렇게 context length를 늘려버리게 되면 더 많은 token을 사용하게 되므로 연산량이 비약적으로 증가할 수 밖에 없습니다. 따라서 늘어난 token 수를 효과적으로 처리할 수 있는 기법들이 필요로 하기에 저자들은 token compression technique에 대하여 실험을 진행합니다.
token compression이라고 해서 대단한 기법이 들어간 것은 아니고, Nvidia에서 제안한 VLM인 NVILA라는 모델과 동일하게 pixel shuffle 기반으로 토큰을 merging합니다. Pixel Shuffle이란 super-resolution에서 처음 사용된 방식으로 spatial feature를 channel axis로 재배열하는 것을 의미합니다. 즉 H와 W가 2배씩 줄어드는 대신에 채널축이 4배로 증가한다? 라고 이해하시면 되겠습니다.
pixel shuffle에서는 이를 shuffle ratio라고 명명하는데, shuffle ratio 값이 크면 클수록 더 많은 spatial token들이 channel axis로 배열되어서 더 많은 압축을 진행하게 됩니다. 이는 곧 효율성의 증대를 의미하지만 반대로 많은 지역적 정보의 압축으로 인하여 정확한 localization을 수행하는데 있어서는 단점으로 다가옵니다.
즉 정확도와 효율성 사이에서 적절한 ratio 값을 결정해야하는데, 이전의 연구들에서는 r 값을 2정도로 세팅하였다고 합니다. 즉 절반정도 토큰을 줄인 것이죠? 하지만 저자들이 실험해보니 1B 미만의 작은 크기의 VLM에서는 ratio 값을 4로 하는 등 보다 공격적인 압축이 생각보다 성능 하락 폭이 작거나 오히려 성능이 개선되는 결과등을 보여주었다고 합니다.
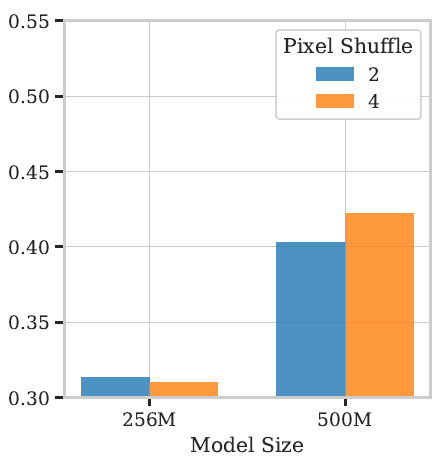
이를 통해 저자들은 작은 모델의 경우에는 visual token 압축을 보다 공격적으로 수행하는 것이 더 좋다라고 결론지었습니다.
How can we efficiently encode images and videos?
다음은 이미지와 비디오 사이의 연산 분배의 관한 것입니다. 보통 이미지는 더 고해상도 일수록 더 많은 토큰을 얻을 수 있고 이를 통해 더 정확히 컨텍스트를 판단하고 task를 수행할 수 있는 반면 비디오의 경우 프레임 별로 더 적은 수의 visual token수를 가져야만 더 긴 흐름의 비디오 프레임을 처리할 수 있다는 관점이 존재합니다.
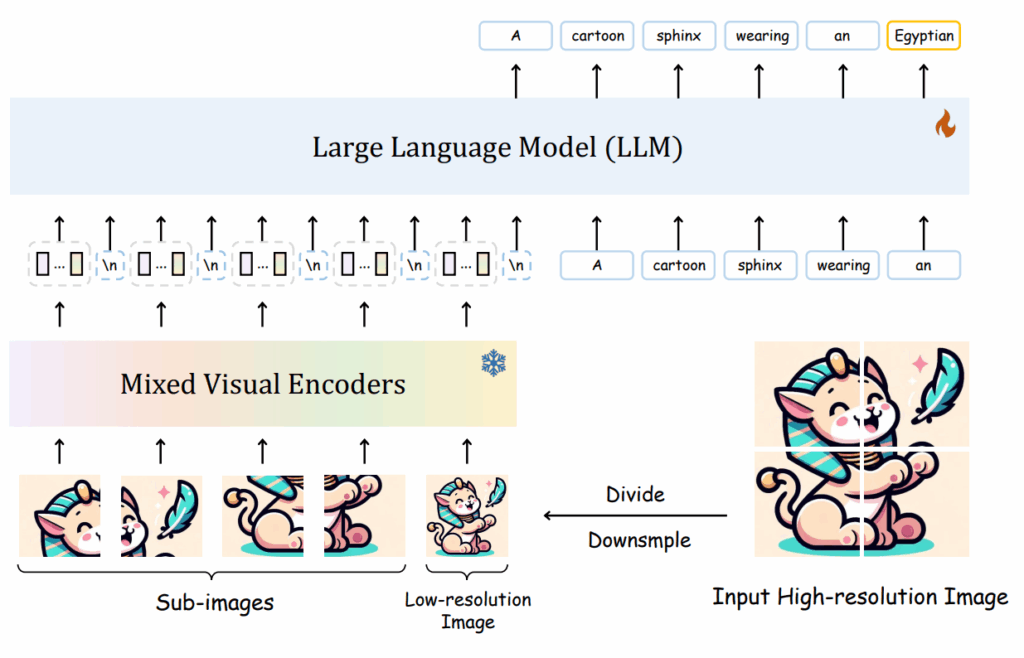
그래서 저자들은 위의 방식처럼 하나의 고해상도 이미지를 4등분하고 또 전체 이미지에 대해서 crop된 영상과 동일 사이즈로 resize하는 방식을 취합니다. 사실 이 방식은 VLM에서 흔하게 사용되는 방식인가봐요. 제가 보았던 VLM 논문들 한 4~5편정도가 다 이방식을 채택했던 것 같습니다.
아무튼 이렇게 고해상도 이미지를 crop하는 방식을 통해 연산량은 줄이면서도 고해상도 이미지의 이점을 살릴 수 있게 됩니다.
그리고 비디오에 대해서는 기존 VLM들의 경우 그냥 frame 축에 대해 average하는 방식을 통해서 효율성을 가져가려고 합니다. 그래서 저자들도 동일한 방식을 취해보았으나 성능에 너무 부정적이었다고 하네요.
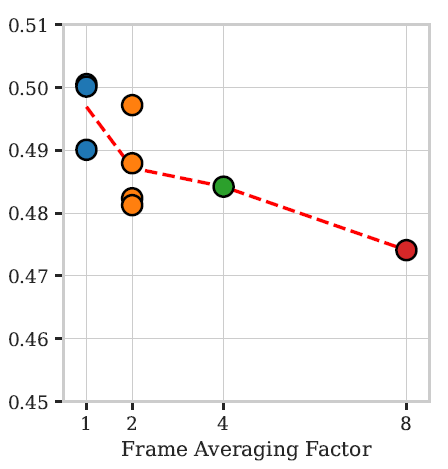
위에 그림은 비디오 프레임을 몇프레임 마다 평균을 취할 것인지에 대한 실험인데 평균을 취하지 않은 것 대비 (1), 2, 4, 8프레임 압축을 수행할때마다 성능의 하락이 발생합니다. 그래서 저자들은 결국에는 Frame averaging 전략은 채택하지 않았다고 합니다. 근데 저자들은 논문에서 하락폭이 매우 크다는 식으로 표현을 하였는데 결과적으로 1 frame vs 8 frame 성능 비교를 해보면 약 3% 미만의 차이가 있는 것 같아서 이정도가 엄청 큰건가?라는 생각이 들긴 하네요. 8프레임으로 평균 냈을 때의 모델의 효율성이 얼마나 증대되는지도 같이 보여줬으면 좋았을텐데 라는 생각이 듭니다.
Smol Instruction Tuning
위에서 저자들의 SmolLM은 image를 4등분해서 visual token을 추출한다고 말씀드렸습니다. 그 4등분의 이미지가 각각 하나의 이미지로써의 역할을 수행하는 것이기 때문에 하나의 이미지 내에서의 positional encoding 뿐만 아니라 지금이 어느 등분의 이미지인지도 positional encoding을 지정해주어야합니다.
저자들은 처음에 아주 간단한 문자열 토큰을 도입했다고 합니다. 예를들어 row_1_col_2와 같이 말이죠. 첫번째 행의 2번째 열 이미지라는 단순하면서도 명료한 방식은 아쉽게도 작은 크기의 모델에서는 부정적인 영향이 발생했다고 합니다.
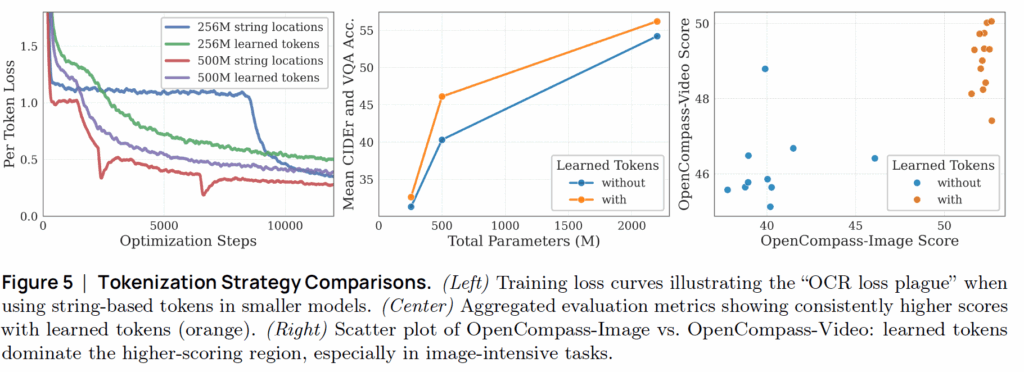
위에 그림5 좌측에서 파란색 선이 작은 크기 모델의 문자 기반 토큰 적용시 추론되는 loss값을 시각화한 것인데 loss가 학습 초기에 뚝 떨어지다가 더이상 내려가지않고 일정하게 수렴해있다가 다시 또 급격하게 loss가 떨어지는 모습입니다. 저자들은 이를 OCR loss plague라고 표현하였는데 loss가 갑작스럽게 하락함에도 불구하고 정작 OCR의 성능은 그에 맞춰서 향상되지 않음을 의미합니다.
500M의 큰 모델의 경우에는 상대적으로 작은 모델보다는 string location 방식이 OCR loss plague 현상이 발생하지는 않지만 여전히 아쉽기도 하고 작은 모델에서는 크게 문제가 되기 때문에 새로운 방법을 찾아야만 했습니다. 그래서 저자들은 그냥 학습 가능한 토큰 방식을 적용했다고 합니다.
이 학습 가능한 토큰을 사용하게 될 경우에 그렇지 않은 경우와 비교해서 성능 폭이 유의미하게 나타납니다 (그림5 가운데 그래프 참조). 물론 모델의 크기가 커지면 커질수록 그 폭이 줄어들긴 하지만 500M 수준의 모델 크기에서는 성능 차이가 많이 나타나는 모습이네요.
그리고 그림5 제일 우측 그래프를 살펴보더라도 learned token을 사용하는 경우가 그렇지 않은 경우보다 Image와 Video 모두에서 성능이 좋은 모습입니다. 정리하면 학습 가능한 위치 토큰은 작은 크기의 VLM에서 텍스트(스트링) 기반 토큰보다 우수한 성능을 보인다는 것이겠네요.
Structured Text Prompts and Media Segmentation
다음은 모델의 성능을 ‘점진적으로(incrementally)’ 끌어올리는 방법을 찾기 위해 아래와 같이 2가지의 실험을 진행했습니다.
- System Prompts: 모델에게 본격적인 질문을 하기 전에, 일종의 ‘역할’이나 ‘기본 지침’을 미리 알려주는 방식입니다. 예를들어, 대화 데이터셋을 활용할 때, “You are a useful conversational assistant”라는 프롬프트를 넣어준다거나, 비전 중심의 task를 수행시에 “You are a visual agent and should provide concise answers.”라는 프롬프트를 넣어줌으로써 역할을 보다 명확히 하는 것을 의미합니다.
- Media intro/outro prefixes: 이미지나 비디오 데이터의 시작과 끝을 명시적으로 정해주는 텍스트 꼬리표입니다. 구체적으로, “Here is an image…” and “Here are N frames sampled from a video…”) 라는 식으로 이미지 또는 비디오 토큰의 시작 또는 끝을 명시하는 것이죠.
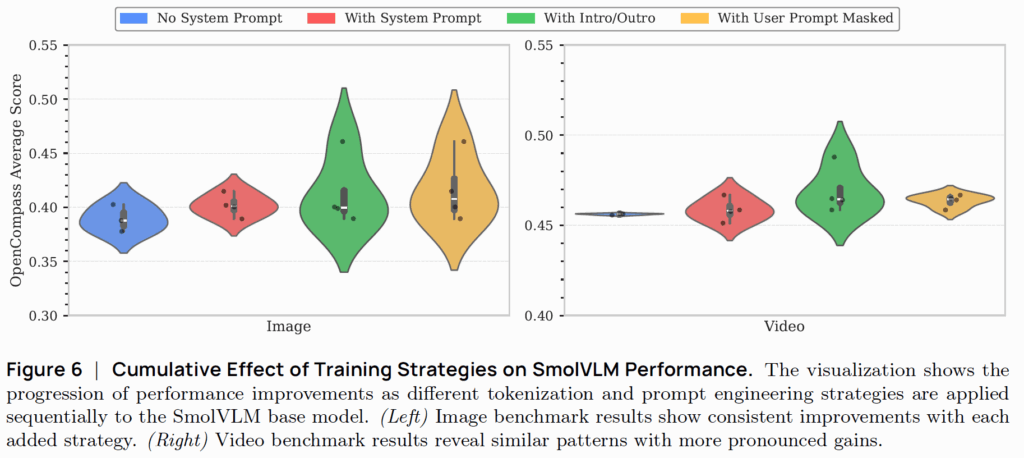
위에 그림6은 시스템 프롬프트와 미디어 인트로/아웃트로 관련 실험 결과를 나타낸 것입니다. 결론부터 말씀드리면 아무런 프롬프트를 제공하지 않았을 때 보다 시스템 프롬프트 또는 인트로/아웃트로 정보를 제공하는 것이 이미지/비디오 레벨에서 모두 성능 향상을 보여줄 수 있다고 합니다.
그리고 노란색으로 표기된 User Prompt Mask의 경우에는 이전 연구에서 사용된 User Prompt Masking 기법으로 유저의 query 값을 마스킹하는 방법이라고 하는데 구체적인 설명은 나와있지 않네요. 아무튼 유저의 쿼리 중에는 종종 반복되는 내용들이 등장하게 되는데 이러한 것들은 모델의 메모리만 차지하고 정작 중요한 정보는 아닌지라 모델의 추론의 방해가 되는 요소?로 동작한다고 합니다. 따라서 유저의 쿼리 값을 마스킹하는 전략 역시 모델 성능에 기여를 할 수 있음을 나타냅니다.
Impact of Text Data Reuse from LLM-SFT
보통 Large VLM의 경우에는 최종 학습 단계에서 매우 고품질의 text data로 fine-tuning하는 관습?이 있습니다. 그래서 저자들도 마찬가지로 Small VLM의 마지막 학습 단계에서 고품질의 text data로 학습을 수행하였습니다. 그런데 기존의 경향과는 달리 Small Model의 경우에는 이러한 supervised fine-tuning 과정이 모델의 성능에 큰 하락을 가져옴을 발견했습니다(아래 그림7 좌측 참고)
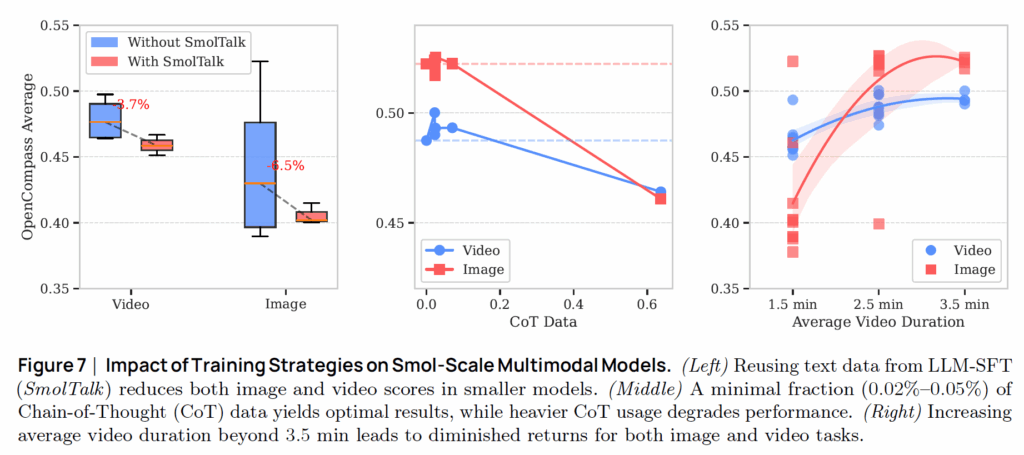
저자들은 이러한 성능 감소에 대하여 다음과 같은 평가를 하였는데, LLM의 미세조정 데이터는 매우 특정한 목적을 위해 정제되었기 때문에 데이터의 다양성이 심하게 감소되어있어 small model에게는 오히려 부정적인 영향을 주었다는 것이 그 결론입니다. 저자들은 기존의 관행대로 수행하였던 large-scale SFT text adoption을 작은 크기의 모델에게는 바로 적용할게 아니라 신중하게 접근할 필요가 있다고 경고합니다.
Optimizing Chain-of-Thought Integration for Compact Models
Chain-of-Thought(CoT)는 일반적으로 모델의 reasoning 성능 향상에 도움이 된다고 잘 알려져있습니다. 하지만 이는 대부분 7B 이상의 큰 모델에 대해서만 연구가 이루어졌으며 작은 모델에 대해서는 아직 연구가 많이 진행되지 않았다고 합니다. 그래서 저자들은 작은 VLM에서도 CoT가 큰 모델만큼 이점을 줄 수 있는지에 대해서 실험을 진행합니다.
그림 7이 그 결과인데, 결론부터 말씀드리면 CoT를 사용하는 경우 이미지와 비디오에서 모두 모델의 성능이 하락하는 모습입니다(그림7 중앙 참고). 물론 CoT Data의 비율을 매우 작게(0.02%~0.05%) 가져가면 성능 향상을 미약하게나마 볼 수는 있습니다만 그 이상의 비율을 활용하는 경우에는 모델의 성능이 점점 더 크게 떨어지는 것을 볼 수 있습니다.
저자들은 아마 이러한 현상을 reasoning 중심의 텍스트 데이터가 과도한 경우 제한된 캐파를 가지고 있는 small VLM에서는 이들을 처리하기 위해 visual representation에 대한 캐파를 어쩔 수 없이 희생하는 방식으로 타협하기 때문에 그런 것이 아닌가 라고 추측하고 있습니다.
요약하면, 과도한 CoT data는 오히려 작은 모델의 성능에 해가 된다라고 볼 수 있겠네요.
Impact of Video Sequence Length on Model Performance
학습 때 사용하는 비디오의 길이가 길면 길수록 더욱 풍부한 temporal context를 활용할 수 있지만, 학습에 사용되는 비용 역시 크게 증가하게 됩니다. 저자들은 최적의 video duration을 찾기 위해서 평균 비디오의 길이를 각각 1.5분과 3.5분에 맞추어서 SmolVLM을 학습시켰습니다.
그림7의 우측이 그에 대한 실험 결과인데, 비디오의 길이가 3.5분으로 갈수록 이미지와 비디오 레벨에서 모델의 성능이 모두 분명하게 개선된 것을 확인하실 수 있습니다. 3.5분 이상으로 비디오 길이를 늘리게 될 경우에는 모델의 성능이 오르기는 하는데 학습에 사용되는 비용 대비 성능 향상 폭이 미미하기 때문에 저자들은 3.5분까지를 최대 길이로 설정해서 실험을 진행하였다고 합니다.
요약하면, 작은 크기의 VLM을 학습시킬 때 적절하게 비디오 길이를 늘리는 것은 이미지와 비디오 레벨 추론에서 모두 성능 향상에 도움이 되며, 너무 짧거나 길어서는 안된다라고 볼 수 있습니다.
Experimental Results
지금까지의 분석들을 토대로 저자들은 3가지 타입의 SmolVLM을 만들게 됩니다.

아래 표는 다른 VLM과의 성능 비교 결과표입니다.
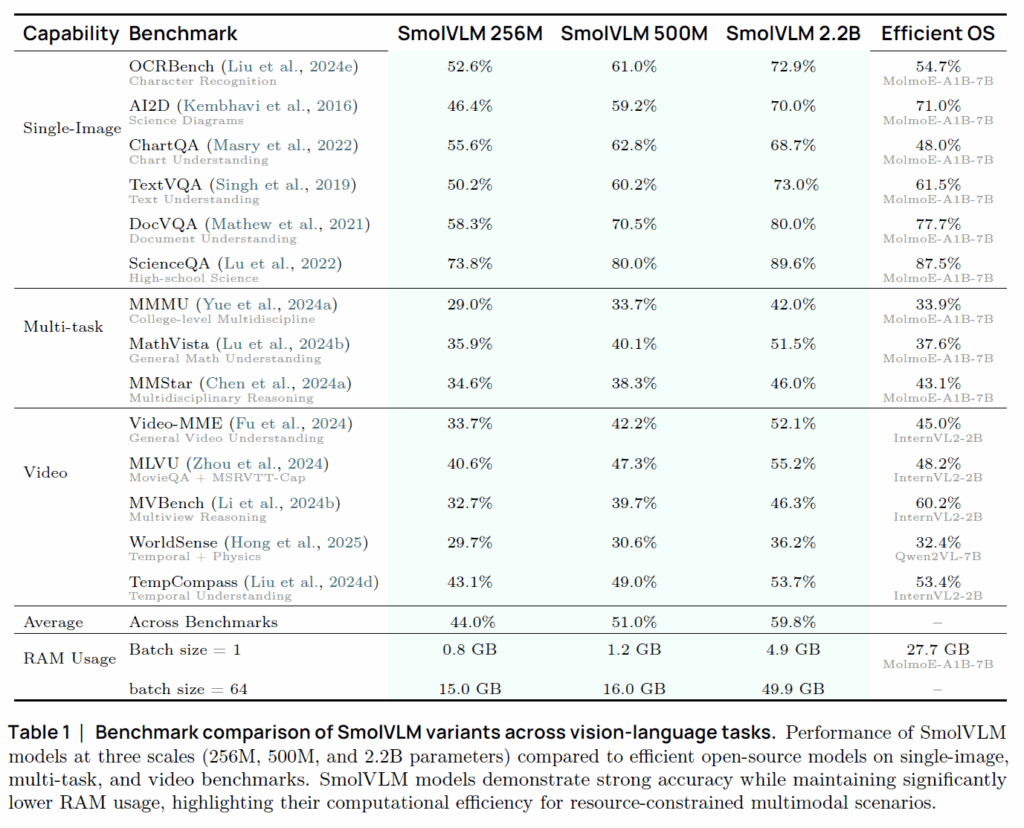
이미지/multi-modal/Video 각각의 대한 벤치마크를 수행하였으며, 비교대상으로는 MolmoE-A1B와 InterNVL, Qwen2와 비교를 수행합니다. 흥미로운 점은 저자들의 제일큰 모델이 2.2B 수준의 파라미터를 가지고 있는데 7B 크기를 지니는 MolmoE와 InterVL보다 대부분의 task에서 성능이 더 좋다는 점입니다.
그리고 저자들이 제안한 모델은 파라미터수가 작은 만큼 매우 효율적인데, single-image inference 시에 256M 크기의 모델은 0.8G, 500M 모델은 1.2G, 2.2B 모델은 4.9G의 메모리만을 차지하며 이는 MolmoE-A1B-7B가 27.7GB 차지하는 것에 비하면 상대적으로 매우 작은 메모리를 차지하고 있음을 보여줍니다.
MolMoE의 경우 7B 모델이라서 직접적인 비교가 어렵다고 생각하실까봐 저자들이 비슷한 크기의 다른 VLM도 언급을 하는데 Qwen2VL-2B와 InternVL2-2B는 각각 13.7G, 10.5G의 용량이 든다는 점에서 저자들의 4.9G 용량은 확실히 적은 것을 확인할 수 있습니다.
물론 이미지의 해상도가 어떻게 되는지 이런 구체적인 환경 설명은 없어서 보다 자세한 분석은 어렵지만 기존의 쟁쟁한 VLM들과 비교하였을 때는 상대적으로 효율적임을 분명하게 보였다는 점에서 의미가 있다고 생각합니다.
결론
다양한 실험을 하고 그 결과를 설명하는 식으로 글이 전개되는지라 무언가 기술리포트?에 가깝다고 생각이 들긴합니다. 그리고 제가 개인적으로 느꼈을 때는 저자들의 설명을 뒷받침하기에는 중간중간에 실험이 하나씩 빠져있는 느낌도 들어서 읽다가 멈칫멈칫했던 경우가 종종 있었던 것 같습니다.
하지만 그럼에도 불구하고 정말 다양한 방향에 대해서 실험을 진행하고 이것이 small VLM에 어떠한 영향을 끼치는지를 분석하였기 때문에 VLM을 개발해야하는 사람들 입장에서는 상당히 도움이 되는 문서가 아닐까 라는 생각이 드네요.
좋은 리뷰 감사합니다. 읽으면서 VLM의 다양한 요소에 대해 고민해볼 수 있었습니다.
한가지 간단한 질문이 있습니다. image의 경우 Figure 2처럼 VLM에 입력되는데, video의 경우에는 어떻게 VLM에 입력되나요? 비디오 내부의 여러 프레임들에 대한 토큰들을 한번에 입력하게 되는건가요?