안녕하세요, 허재연입니다. 오늘 리뷰할 논문은 DETR 구조 기반 Video Scene Graph Generation을 수행하는 모델을 제안한 모델입니다. 기존 방법론의 경우 <subject-object> pair 예측을 수행한 이후 이 representation을 기반으로 relation을 예측했었는데, 이번 논문에서는 object와 relation을 예측하는 branch를 분리하였습니다. 리뷰 시작하도록 하겠습니다.

Introduction
Scene Graph Generation(SGG)은 입력 데이터로부터 물체들을 찾고 이들 간의 관계를 예측해서 장면 내부 물체 간의 관계를 구조적으로 표현하는 task로, 모델은 <subject-relation(predicate)-object> triplet을 잘 예측하는 것을 목표로 합니다. Video Scene Graph Generation(VidSGG. Dynamic SGG로도 표현합니다) 은 비디오 입력에 대해 프레임 단위로 SGG을 수행해서, 각 프레임에서의 물체들 및 이들 간의 관계를 정교하게 예측하고자 합니다. 저자의 문제 정의를 정리하면 ‘현실적인 시나리오를 고려하면 모델이 이전에 보지 못했던 triplet을 잘 예측할 수 있어야 하는데, 기존 방법론들은 학습 과정에 등장하지 않은 triplet에 대한 예측력이 떨어진다’ 입니다. 이는 기존 방법론들의 예측 프레임워크가 주로 ‘물체 검출 -> 물체 검출 결과(보통 검출한 물체들의 feature representation)를 기반으로 relation 예측’하는 구조로 설계되어 물체의 feature representation에 굉장히 의존적이기 때문입니다. 저자는 이 문제를 완화하기 위해 decoupled dynamic scene-graph, DDS를 제안합니다.
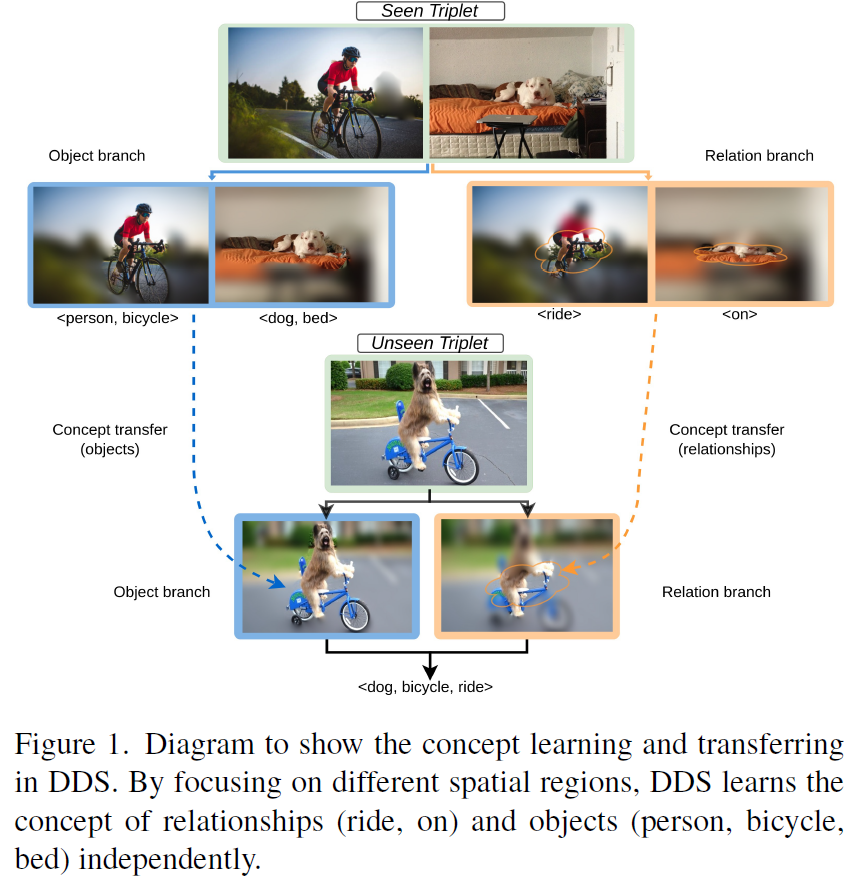
제안하는 DDS의 개념은 위 Figure 1.에 나와있습니다. DDS에서는 object와 relation의 특징 학습을 분리하기 위해 두개의 다른 branch를 구성하여 학습 및 예측을 수행합니다. 기존에는 물체 representation을 기반으로 관계를 예측해서 relation 예측이 물체에 bias되었는데(예측이 물체->관계 병렬구조), relation과 object 처리 branch를 분리해서 병렬적으로 예측을 수행해 처음 보는 triplet 조합을 기존보다 잘 예측할 수 있도록 하였습니다. 사실 핵심 아이디어는 이게 전부입니다. 간단하죠.
DETR 구조를 기반으로 이미지의 feature extraction 이후 object/relation의 각 branch에서 encoder-decoder를 순차적으로 거치면서 object/relation 예측을 수행하며, 비디오의 temporal 정보 반영은 각 decoder에서 이루어지도록 하였습니다. object / relation 각각을 예측하는 decoder가 분리되어있으므로 각각 예측을 담당하는 decoder query(DETR의 object query입니다)들도 분리되어 있어 각 query가 담당하는 object / relation 예측에만 집중할 수 있게 하였습니다.
Method
Problem Formulation & Overview
방법론으로 바로 들어가기 전에, 구체적으로 task가 어떻게 수행되는지 간단히 리뷰하고 대략적인 모델 구조를 소개하겠습니다.
Video Scene Graph Generation에서 T개의 frame으로 구성된 입력 비디오 V= {{I}_{1}, {I}_{2}, ..., {I}_{T}} 가 주어지면 모델은 모든 프레임에서 relation triplet 집합 {{R}_{1}, {R}_{2}, ... , {R}_{T}}를 예측하게 됩니다. 이때 각 relation triplet은 <subject, predicate, object>로 표현되며, subject, object는 이름 그대로 relation의 주어, 목적어에 해당하는 물체의 위치와 클래스(object detection입니다)이고, predicate(relation)은 카테고리 레이블이 됩니다.
기존 video scene graph generation에서 메인스트림 프레임워크들은 Faster RCNN과 같은 기존 object detector로 모든 프레임의 물체를 예측하고, 이들의 정보를 모아서 temporal 정보를 반영해 relation 예측을 수행하는 2-stage로 수행되었습니다. 2024년부터는 transformer(특히 DETR구조) 기반의 1-stage 방법론들이 좋은 성능을 보여주었고, 많은 흐름이 이쪽으로 넘어왔습니다. DDS도 기본적으로 DETR 구조를 기반으로 하고 있습니다.
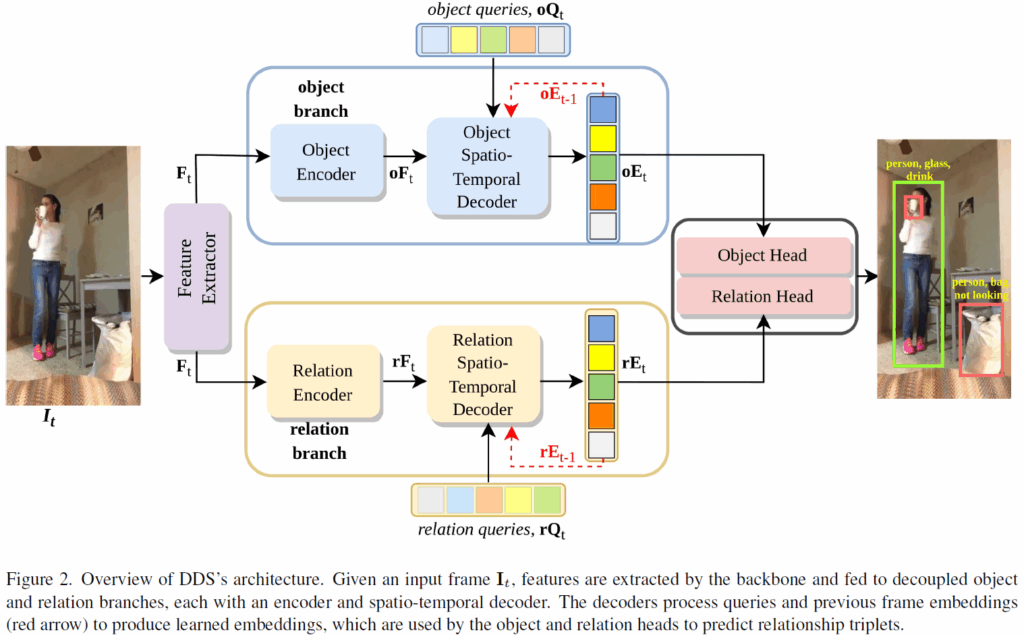
DDS 구조는 아래 Figure 2. 와 같습니다. 우선 비디오 프레임이 입력되면 CNN으로 특징 추출을 수행하고, 이렇게 추출된 특징들을 객체 인코더와 관계 인코더에 각각 입력해 특징을 강화합니다(학습을 통해 object / relation 예측에 특화되도록 강화되겠죠). 이후 object / relation 각 시공간 디코더(spatio-temporal decoder)는 해당 인코더로부터 전달된 embedding feature와 이전 프레임으로부터 전달된 embedding feature를 받아 query로 예측을 수행하도록 정보를 주고받습니다. 이후 디코더 출력(object / relation spatio-temporal embedding)을 relation head와 object head에 입력하여 최종 예측을 수행합니다.
Feature Extraction & Encoders
입력 형태는 video V의 t번째 frame인 {I}_{t}입니다. CNN backbone(ResNet50)으로 일차적으로 특징 추출을 수행하고 이후 1×1 convolution 및 flatten 한 뒤 positional embedding을 더해주어 이를 relation과 object branch에 공동 feature로 사용합니다.
object / relation branch 모두 Multi-Head Self-Attention 및 feedforward network를 쌓은 인코더 구조를 사용하여 object, relation 예측에 사용하는 feature r{F}_{t}, o{F}_{t}를 각각 만들어냅니다.
Input Queries
CNN backbone – encoder 를 거친 feature는 이후 decoder에 입력됩니다. 디코더는 object / relation branch에는 각각 독립적으로 두어 object branch decoder는 object 예측을, relation branch decoder는 relation 예측을 담당하게 됩니다. 각 디코더는 DETR decoder 처럼 랜덤 초기화된 쿼리를 입력받고 2단계에 걸쳐 시간, 공간적 특징을 추가적으로 반영하게 됩니다. 우선 temporal decoder로 여러 프레임에 걸쳐 시간적 정보를 집계하고, 이어서 spatial decoder로 현재 프레임의 문맥을 더욱 정제하게 됩니다. 보통 공간적 정보를 처리하고 이후에 시간적 정보를 반영하는 식으로 많이 구현하던데, DDS는 특이하게도 반대 순서로 구성되었네요.
Spatio-Temporal Decoders
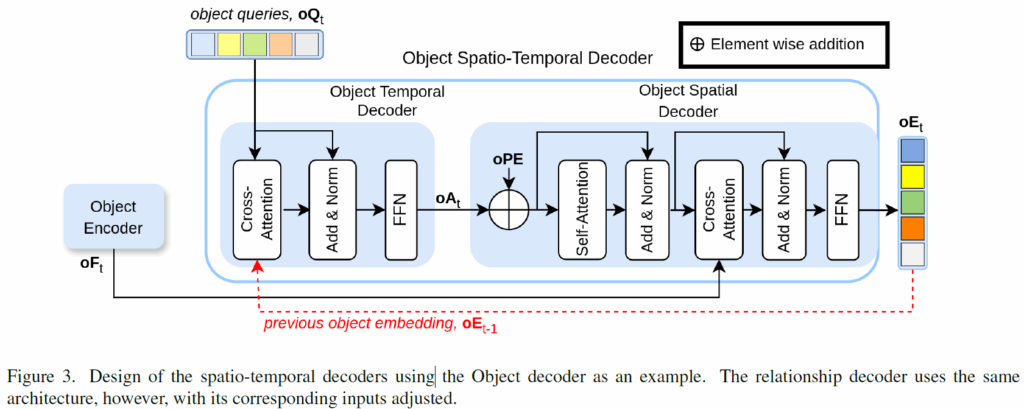
트랜스포머 인코더 구조로 feature encoding을 수행한 후 디코더에서 시공간 문맥을 추가해주는데, 각 branch의 decoder 구조는 아래 Figure 3.과 같습니다. 그림에서 확인할 수 있듯, temporal deocder -> spaitla decoder 로 이어집니다.
Temporal Decoder
temporal decoder는 현재 프레임 쿼리와 이전 프레임 임베딩을 입력받습니다. {I}_{t} frame에 대해 현재 frame의 relation/object 쿼리 집합을 r{Q}_{t}, o{Q}_{t}라고 하고, 이전 프레임의 임베딩을 r{E}_{t-1}, o{E}_{t-1} 라고 하겠습니다. 위 Figure 3을 보면 relation / object temporal decoder에 현재 프레임의 query set r{Q}_{t} / o{Q}_{t}과 이전 프레임의 임베딩 r{E}_{t-1}, o{E}_{t-1}가 입력되어 쿼리와 임베딩 간 Cross-Attention이 수행됩니다. 현재 프레임의 쿼리의 예측에 이전 프레임 정보를 반영해주는 것이죠. 이후 relation / object branch의 temporal decoder에서 시간 정보가 반영된 query feature(r{A}_{t}, o{A}_{t})는 spatial decoder에 입력됩니다. 첫 번째 프레임의 경우에는 이전 프레임이 없기 때문에 temporal decoder를 거치지 않고 바로 spatial decoder에 입력했다고 하네요.
Spatial Decoder
spatial decoder는 일반적인 트랜스포머 디코더의 구조와 비슷하게 구성됩니다. FFN, self-attention, cross-attention을 거치에 되는데, 각 브랜치마다 temporal deocder의 출력 query와 (r{A}_{t} or o{A}_{t})과 앞의 인코더에서 인코딩된 feature map (r{F}_{t} or o{F}_{t})를 입력받아 이들 간 CA를 수행합니다. 이후, temporal, spatial decoder를 거쳐 시간적, 공간적 문맥이 반영된 object query들은 relation / object 예측을 위한 embedding으로 사용됩니다. 이후 object / relation head로 입력되어 각각 최종 예측을 수행하게 됩니다.
Object & Relation Heads
spatial-temporal decoder를 거친 출력 임베딩들은 이후 각각 예측을 위한 head에 입력됩니다.
object branch에서는 각 프레임마다의 subject bounding box, objet bounding box, subject prediction vector, object prediction vector를 수행합니다. 각각 4개의 별도 FFN에 입력되어 주어 / 목적어의 localization, classification을 수행하죠.
relation branch에서는 출력 임베딩이 각각 2개의 별도 FFN으로 입력되어 relation region bounding box와 relation prediction vector를 출력한다고 합니다. SGG task에서 relation은 classification인데 왜 갑자기 relation의 bbox를 예측하지? 라고 의문이 들었는데, 주어 물체와 목적어 물체의 bbox 합집합으로 학습 과정에만 활용한다고 합니다.
Training & Inference
추론 시에는 위에서 말한 object / relation head의 output을 활용해 가장 주어, 목적어 confidnece score가 높은 쌍들을 활용해 relationship pair들을 만든다고 합니다. 이렇게 구성된 모든 relation pair들에 대해, 최종 relation score는 각 신뢰도 점수의 곱으로 계산합니다.
DDS 학습 시에는 Qpic이라는 방법론과 유사한 손실 함수를 사용했다고 합니다. loss 계산은 두 단계로 이루어집니다.
첫 번째 단계에서는 t번째 프레임에 대한 예측값과 GT값 사이 bipartite matching을 수행하는데, 이 때 subject, object box의 합집합으로 relation box를 정의하고 학습 시에만 사용합니다. matching cost metric은 다음 수식 (3)과 같이 정의됩니다.
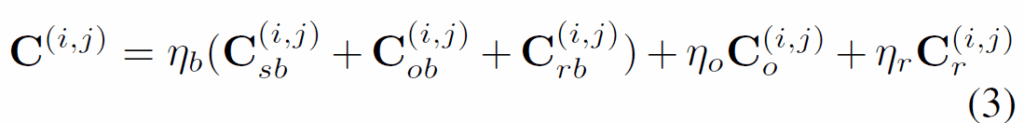
{C}_{sb}, {C}_{ob}, {C}_{rb}은 각각 subject, object, relation 영역의 matching cost이고, {C}_{o}, {C}_{r}은 각각 object, relation label matching cost입니다. DETR과 동일하게 예측값과 GT 간 최적의 매칭을 찾는데는 헝가리안 알고리즘을 사용합니다. 이후 학습이 진행될 때 다음 (4) 수식과 같이 loss가 계산됩니다.
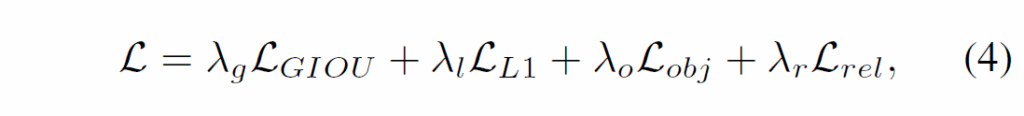
GIou, L1 loss는 box regression을 위한 loss이고, obj, rel은 각각 물체 / 관계 분류를 위한 cross-entropy입니다.
이제 실험 내용을 살펴보겠습니다.
Experiments
실험은 Action Genome(AG), HICO-DET, UnRel 이란 데이터셋들에서 이루어졌습니다.
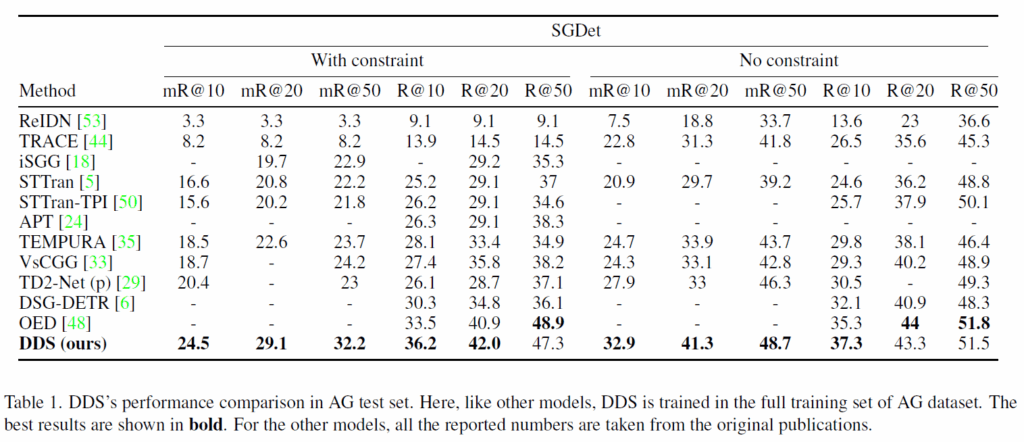
Table 1은 action genome dataset에서의 결과를 나타내었습니다. 리포팅된 성능에 대해서는 기존 모델들과 비교해 대부분 SOTA를 달성하거나, 그렇지 않더라도 좋은 결과를 보여주었습니다. SGdet에서만 결과를 보여준것은 좀 아쉽네요. SGCLS나 PredCLS 결과가 좋지 않았나 봅니다.
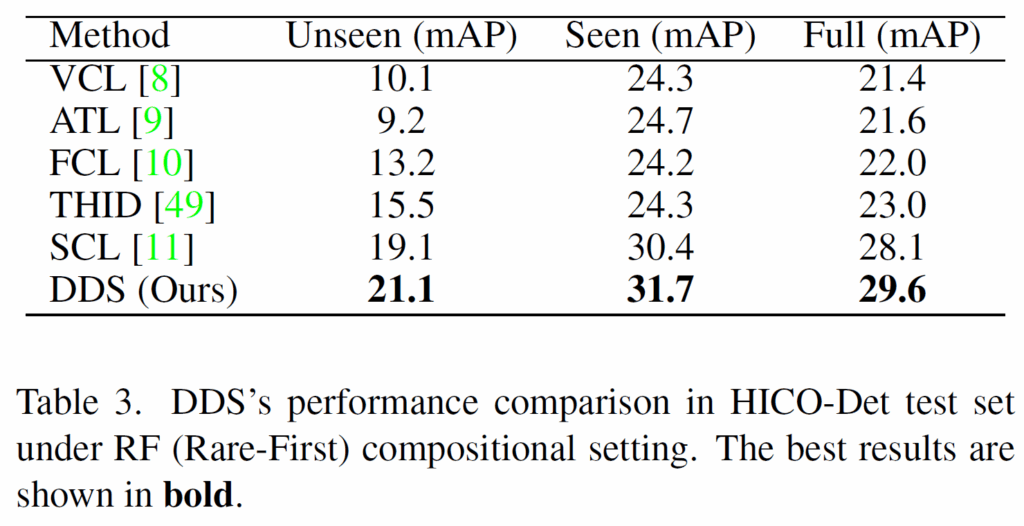
Table 3에서는 HICO-Det에서의 벤치마크 결과를 보였습니다. HICO-Det이라는 데이터셋은 거의 보기 힘든 데이터셋인데, 해당 데이터셋에서도 제안하는 DDS가 좋은 결과를 보여주었습니다. (HICO-Det과 UnRel 데이터셋에서는 지표로 Recall@K가 아닌, mAP가 사용되었습니다 )

이어서, Table 4에서는 UnRel 데이터셋의 평가 결과를 나타내었습니다. 처음 보는 굉장히 마이너한 데이터셋인데, 어찌됐건 해당 벤치마크에서도 기존 방법론들보다 개선된 결과를 보였습니다.
다음은 Ablation study입니다.

single-branch 구조인 비교군은 unseen 조합(처음 보는 <s-p-o> 조합)에서 낮은 성능을 보여, object와 relation 예측 브랜치를 쪼갠 DDS의 이점을 강조하고 있습니다. unseen, seen 모두 multi-branch가 낫긴 하네요. 이후 설계의 요소들을 ablation 비교하여 프레임워크 설계의 타당성을 주장하고 있습니다.
‘object와 relation 예측을 이어서 수행하면 bias가 생기니, unseen 조합을 고려하면 이를 예측하는 branch를 쪼개야 한다’는 문제의식을 가지고 프레임워크를 설계한 논문이었습니다. AG데이터셋에서 SGDet만 리포팅했다는 점이 좀 아쉽긴 한데.. 그래도 병렬 구조 설계에 대한 궁금증이 있었는데 참고할만한 지점들이 있었습니다. 사실 temporal 정보 처리하는 부분에서 이전 프레임 쿼리를 CA하는게 전부라 이를 ablation 해서 효과를 보고 싶었는데, 이 부분은 확인하지 못해서 아쉽네요.
이만 리뷰 마무리하도록 하겠습니다.
감사합니다.
안녕하세요 재연님 좋은리뷰 감사합니다
궁금한점이 있어 댓글 남깁니다
제가 이해한바로는 기존 물체-relation 의존성(편향)을
이미지 분포-relation 의존성(편향)으로 바꾼것으로 이해될 수 있을것 같습니다
궁금한점은 보통 이미지의 모든 정보를 llm 등에 입력하면 노이즈가 되기에 객체정보로 변환해 입력하는 연구가 있는것으로 압니다.
이처럼 오히려 이미지 분포(=이미지 자체, 원본 이미지)를 활용했을때 편향이 개선되는 이유는 문제의 난이도가 어려워짐으로 발생하는 부수적 효과로 해석할 수 있는지 궁금합니다
감사합니다
황유진 연구원님, 안녕하세요.
말씀주신 ‘이미지 분포-relation 의존성’이 정확히 어떤 의미인지 와닿지가 않는데, 기존의 물체-관계와의 편향을 깨기 위해 물체와 관계의 예측을 별도로 수행했다는 의미로 말씀 주신것이라면 그게 맞습니다.
기존 프레임워크들은 일반적으로 object detection을 먼저 수행하고, detection 결과를 기반으로 relation 추정을 하는 방식으로 구현되었기에 relation 예측에 object detection 결과가 강력한 사전 정보로 작용했습니다. bias로 해석할 수 있겠죠.
detection 결과가 아닌 원본 이미지를 활용했을때 개선되는것은 단순히 detection의 결과인 위치 및 클래스 정보 분만 아니라 이외에 다양한 시각적 문맥을 함께 사용할 수 있기에 생기는 효과가 아닐까 합니다. 참고할 수 있는 정보가 많으니 편향이 완화되는 것이죠. 문제의 난이도가 어려워진다고 해석할 수도 있을 것 같습니다.
안녕하세요, 재연님. 좋은 논문 리뷰 감사합니다.
DDS의 decoupled 구조가 학습되지 않은 triplet에 대해 일반화할 수 있다는 점이 흥미로웠습니다.
한 가지 궁금한 점은, 인코더와 디코더 단계에서는 object branch와 relation branch가 완전히 분리되어 있는 것으로 보입니다. 그렇다면 두 branch 간의 정보 교환이나 연관은 존재하지 않고, 최종적으로 object head와 relation head 단계에서만 결과를 매칭하여 triplet을 구성하는 구조인지 궁금합니다.
좋은 리뷰 감사합니다.🎥
김기현 연구원님, 안녕하세요.
결론부터 말하자면, 이해하신 게 맞습니다. 두 object branch와 relation branch는 각각의 예측 과정에서 서로 정보 교환이나 상호참조는 없고, 이후 각각 branch의 출력값들을 조합(매칭)하여 모델의 최종 예측에 사용합니다.
감사합니다.