Video LLMs을 통한 비디오 요약이 가능할까요?
해당 질문에 대한 답을 위해 분석을 진행한 논문이 여기 있습니다. 리뷰를 시작하겠습니다.
본 논문은 Zero-shot으로 비디오 요약을 수행하려할때 확인하게 되는 문제점을 발견(Detecting)하고 이를 프롬프트 개선이라는 임시적(ad hoc) 이지만 효율적인 방법으로 완화(Mitigating)하는 방법을 다룬 논문입니다. VLLMs이 비디오를 잘 요약하려면 모델이 시간적 정보에 대해 다룰 수 있는지, 공간적 정보를 다룰 수 있는지 두 가지 요소에 대한 능력이 보장되어 있어야 합니다. 본 논문은 VLLMs이 이러한 능력이 있는지를 검증하기 위해 1) 데이터셋을 구축하고 2) 최신 모델을 평가하며 3) 확인된 문제점에 대한 완화전략을 소개합니다.
데이터셋 구축의 목적과 구성
논문의 저자들은 VLLMs의 비디오 요약 가능성을 확인하기 위해 모델들이 시간과 공간에 대한 이해나 조작이 가능한지를 확인하고자 했습니다. 그러나 기존 데이터셋의 경우 주제와 관련있으며 중복없는 출력을 생성하는것을 목표로 했고, 맥락이나 이벤트에 대한 고려를 하지 않았기 때문에 실험에 활용하기에 적합하지 않았다고 합니다.
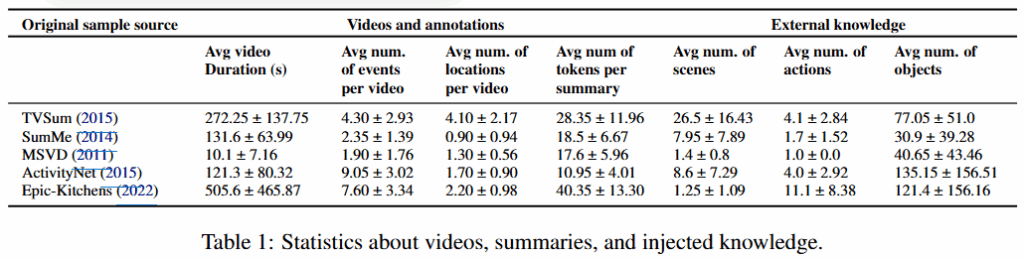
따라서 저자들은 Table1에 명시된 5가지 데이터셋을 기반으로 데이터셋 당 20개의 비디오를 무작위 선별하고 가공하여 데이터셋을 구축하였습니다. 구축한 데이터셋은 저자들의 깃허브(https://github.com/VaianiLorenzo/video-summarization-with-LLMs)에서 확인할 수 있다고 합니다.
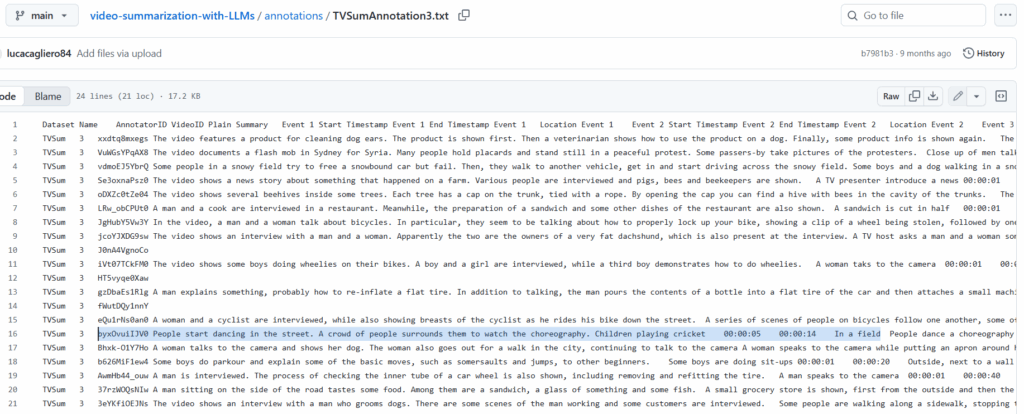
가공 방법은 우선 벤치마크당 샘플링한 20개의 데이터에 대하여 3명의 PhD 학생들이 직접 라벨링을 했습니다. 비디오를 2~3줄의 문장으로 요약하는 일반적인 GT와 유사한 Plain text summary와 비디오를 1~10개의 이벤트로 시간순으로 나누어 라벨링을 수행하는 Salient Events, 각 주요 이벤트에 대한 시간정보와 공간정보를 라벨링하는 Temporal and Spatial Information(ex, [HH:MM:SS], 회의실)을 수행했습니다. 논문이 제공하는 라벨의 예시는 아래와 같습니다.
구축된 데이터셋의 라벨의 통계적 정보는 Table1의 Video and annotation 부분에서 확인할 수 있으며, 평균적으로 한 비디오당 10개 이하의 이벤트와 5개 이하의 location, 40개 내외의 토큰으로 요약할 수 있음을 확인할 수 있습니다.
Model Evaluation, Issue Detection
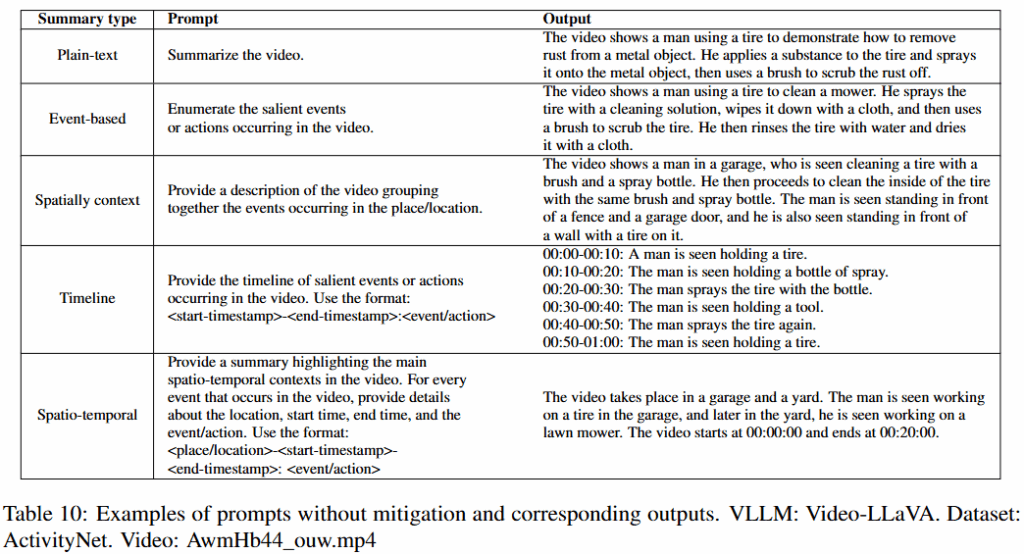
논문에서는 GPT4o나 Google Gemini 1.5와 같은 상업용 모델이나, 비디오에 대한 이해능력을 리포팅하지 않은 모델을 제외한 당대 SOTA Open-source VLLMs인 VideoChatGPT(2023), Vide- oLlAMA2(2024), VideoLLaVA(2023), VTimeLLM(2023)를 실험에 사용했습니다. VLLMs들이 시공간적, 맥락적 이해 능력을 확인하기 위해 5가지의 요약 문제를 나누어 평가하였는데, 제시한 테스크는 아래와 같습니다.
- Plain text Summary (PS)
- 형식의 제약 없이 자유롭게 텍스트로 요약하는 테스크 (템플릿 강제 없음)
- “Summarize the video” -> 자유 Text 요약
- Event-based Summary (ES)
- 주요 사건을 나열하는 방법으로 요약하는 테스크 (템플릿 강제 없음)
- “Enumerate the salient events or actions occurring in the video” -> N개의 이벤트와 그에대한 자연어 텍스트로 요약
- Timeline Summary (TS)
- 시간의 흐름에 맞추어 이벤트가 발생하는 순간의 타임스템프로 요약하는 테스크 (템플릿 강제)
- 템플릿 제공 -> Q개의 타임스템프 (이때 Q<=N)
- Spatially Contextualized Summary (SCS)
- 이벤트가 발생한 공간을 요약하는 테스크 (템플릿 강제 없음)
- “Provide a description of the video by grouping information by location..” -> R개의 공간 (R<=N)
- Spatio-Temporally Contextualized Summary (STCS)
- 장소와 시간쌍을 동시에 요약 (템플릿 강제)
- 템플릿 제공 -> K 시간, 공간 쌍
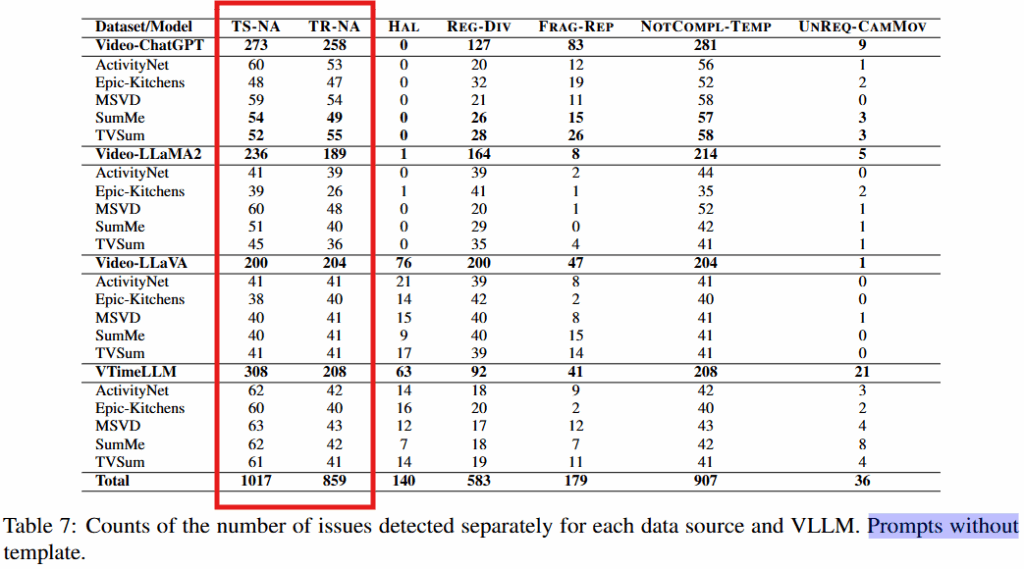
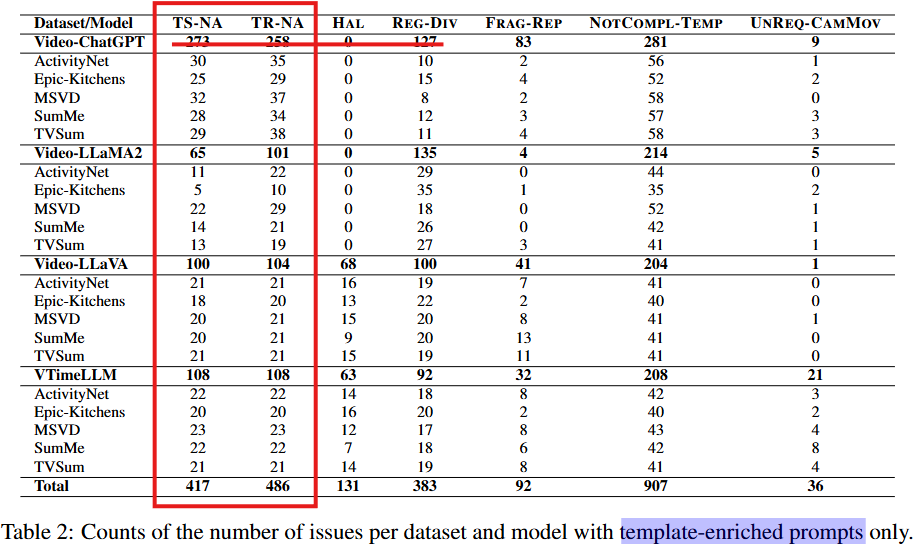
논문은 위의 테스크에 대해 모델 별로 아래의 문제의 발생 여부를 검증하여 VLLMs의 문제 현황을 파악하고자 했으며, 논문이 정의한 문제(Issue)는 아래와 같습니다.
- Unavailable timestamp (TS-NA)
- 타임스템프 없음
- Unavailable time range (TR-NA)
- 타임스템프는 있을 수 있으나, Range를 제공하지 않음
- Hallucinated time content (HAL)
- 잘못된 결과 (예를 들어 오후 10시 65분)
- Regular time division (REG-DIV)
- 시간을 기계적으로 나눔 (2초경에는 …, 4 초경에는 …, 6 초 경에는…)
- Time Fragmentation or repetition. (FRAG- REP)
- 동일 이벤트 반복 (1초까지 이벤트 x, 5초까지 이벤트 x, 6초까지 이벤트 x)
- Not compliant template (NOTCOMPL-TEMP)
- 지정한 템플릿을 지키지 않음
- Focus on camera movements (UNREQ-CAMMOV)
- 사건의 맥락이 아닌, 카메라의 시점 변동등에 집중
실험은 템플릿을 명시적으로 지정한 template-enriched와 템플릿을 지정하지 않은 without template을 나누어 리포팅 되었습니다. without template의 경우 타임스템프 혹은 타임 범위(Time-Range)를 누락하는 경우가 허다하여, 본문에서는 template-enriched 결과를 메인으로 리포팅했습니다. 아래에서 확인할 수 있듯이 논문이 정의한 Issue들이 다수 발견되어 해결이 시급함을 확인할 수 있습니다.
문제(Issue) 완화 방법
논문에서는 zero-shot setting에서 효율적으로 문제를 완화하는 방법으로 추가적인 모델을 사용해서 지식을 프롬프트에 주입하는 in-context learning with Chain-of-Thougt(CoT) 방식을 활용했습니다. 이때 주입할 정보는 비디오의 씬 변화(PySceneDetect 활용), 액션(MMAction2 Toolbox), 객체 정보(Yolo V2)입니다. 데이터셋 당 추가 주입된 정보의 분포 정보는 Table1의 External Knowledge와 같으며, 프롬프트로 정보를 제공하는 방법의 예시는 아래와 같습니다.

실험의 평가 지표는 NLP 분야에서 구문적 유사도를 측정하는 Syntactic similarity(R1/R2/RL Precision/Recall/F1-Score)와 BERTScore 그리고 LLM(LLaMA 70B 이용)을 기반으로 평가하는 LLM-as-a-judge 방식으로 진행되었으며, 본문에 메인으로 다루어진 실험 결과는 아래의 LLM-as-a-judge 방식입니다.
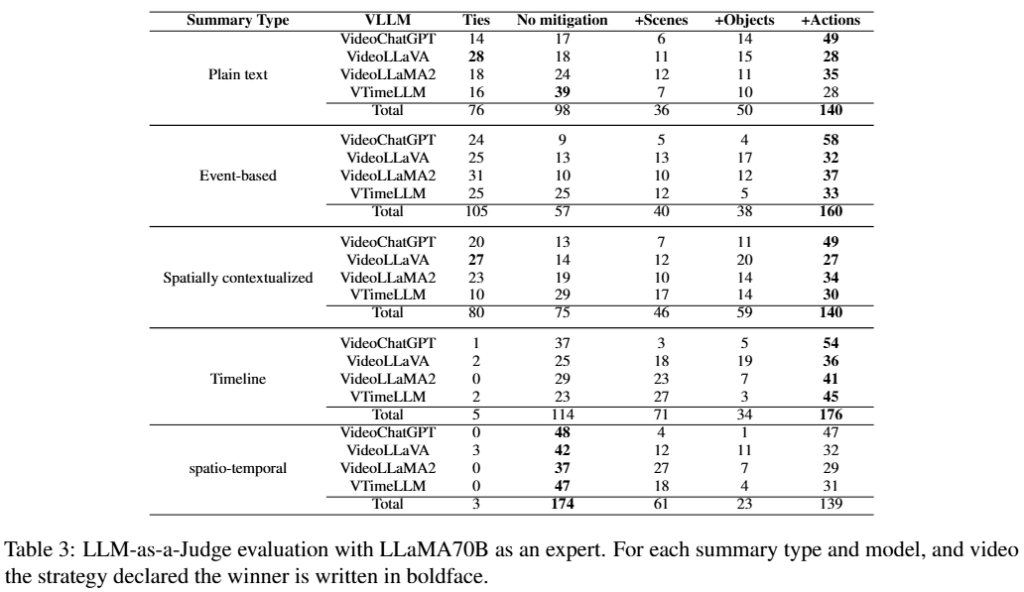
실험 결과는 Table3와 같으며 No mitigation은 제시한 완화전략을 사용하지 않은 베이스라인입니다. 최종적으로 Action에 관한 정보를 추가적으로 제공할때, 성능 개선에 가장 효과적이였음을 확인할 수 있습니다. 그러나 spatio-temporal 테스크와 같이 복잡도가 높은 경우에는 정확한 추론이 여전히 어려움을 확인할 수 있습니다. 한편 장면 분할과 객체 정보 역시 베이스라인 대비 성능 개선을 보였으나, Action 정보 대비해서는 미미한 개선을 보였다고 합니다.
추가 인사이트
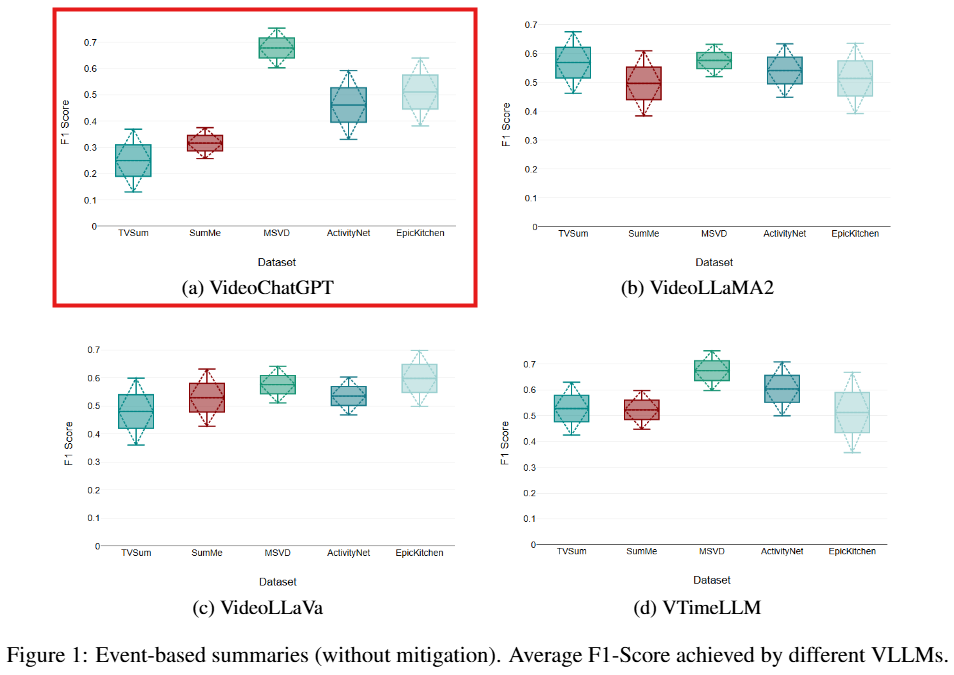
아래는 실험에 사용된 모델 별로 요약에 대한 F1 score 결과 입니다. 모든 데이터셋에 대해 완화전략을 사용하지 않은 베이스라인 성능은 Figure1과 같으며 VideoChatGPT가 가장 덜 안정적인 성능을 보임을 확인할 수 있습니다. 따라서 VideoChatGPT를 기준으로 액션과 장면분할 정보를 주입하는 완화전략을 취했을때, 이러한 데이터셋 별 성능 분산이 낮아지며 안정적인 성능을 보일 수 있음을 Figure2 (a, b)에서 확인할 수 있습니다. 또한 객체정보를 주입한 Figure2 (c)를 통해 확인할 수 있다고 합니다.
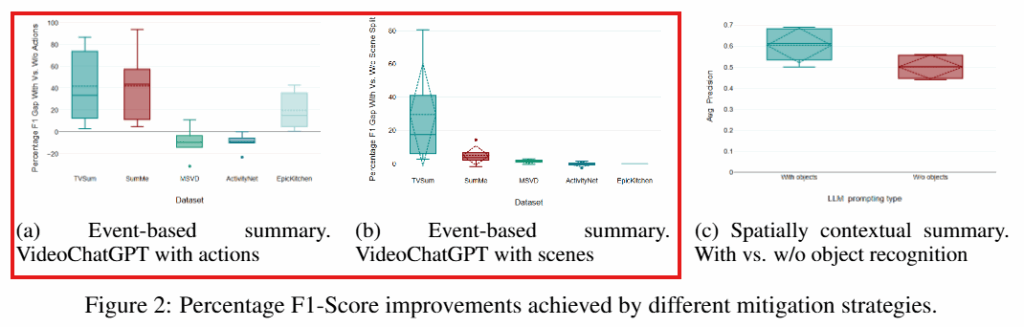
앞서 언급하였듯이 비디오 맥락을 테스트하기위해 적절한 데이터셋을 구성했다는 점에서 살펴보면 좋을것 같은 논문입니다. 아쉬운 점은 몇몇 실험의 디테일입니다. 예를 들어 Figure2의 a, b, c의 실험 구성이 다른데 그 이유는 Table3에서 확인할 수 있듯이 객체 인식 정보 주입에 성능 개선이 미미하거나 오히려 성능이 하락하여 Figure c에서 생략한 것으로 보입니다. 또한 Table2에 대한 분석으로 Frag-Rep 문제가 짧은 비디오에서는 적게 발생한다는 분석을 제시하였으나, 이는 4개중 2개의 모델에서만 명확히 드러난 현상입니다.

그외에도 일반적으로 보조적으로 사용되는 지표(LLM-as-judge)를 메인으로 사용하거나, 특정 실험 결과(templed enriched)만 활용하는등, 저자들이 제공하고 싶은 인사이트를 기준으로 체리 피킹과 결과 가공을 티가나게 많이 한것처럼 느껴지는 논문이였습니다. 그럼에도 실험이 제공하는 (추가 정보 주입의 비디오 요약에서 유의미성과, 기존 VLLMs의 비디오 요약 능력 불충분성 제시)인사이트와 문제정의의 필요성이 높다고 생각하여 공유드리며, 이상으로 리뷰를 마치겠습니다. 감사합니다.
안녕하세요, 황유진 연구원님. 좋은 리뷰 감사합니다.
리뷰를 읽다보니, LLM모델들이 출력한 자연어 텍스트의 경우 평가 방식에 대한 궁금증이 있어 질문 드립니다. NLP쪽에는 Synthetic similarity, BERTSscore, LLM-as-a-judge 방식 등이 있다고 했는데, 여기서 LLM-as-a-judge의 경우 어떻게 평가가 진행되는것인가요? 정답 문장과 예측값 문장을 특정 프롬프트와 함께 LLM에 입력하여 수치를 얻는 방식인가요? 뭔가 수치가 LLM 모델에 굉장히 의존적일 것 같아 객관성에 문제가 없는 지표인지 궁금합니다.
안녕하세요 질문 감사드립니다
LLM-as-a-judge는 예상하신것처럼 LLM에 의존적인 지표이지만 평가에서 많이 사용되고 있습니다. 본 논문에서는 LLM을 통해 예측값 문장을 특정 프롬프트와 함께 제공한 후 Wins/Ties/Losses로 분류하도록 하여 평가합니다.
이상입니다
안녕하세요. 리뷰를 읽고 궁금한 부분이 있어 질문드립니다.
저자들이 5가지의 요약문제를 정의해서 평가를 진행하였는데 이중 3가지의 요약문제가 템플릿이 강제되지 않는다고 하셨습니다. 근데 템플릿이 강제되지 않는다면 모델마다 엄청 자유분방하게 내용을 요약할 수 있을텐데 실제 GT와 어떤식으로 비교해서 평가를 하게 되나요? 즉 평가 메트릭이 궁금합니다.
감사합니다.
안녕하세요 질문 감사드립니다
본 논문에서는 1)NLP 분야에서 두 문장(정답/예측)간의 단어적 겹침 정도를 평가하는 Syntactic similarity 지표인(R1/R2/RL/Recall/F1-score)와, 2)LLM을 기반으로 맥락적 유사도를 평가하는 LLM-as-a-judge 그리고 3)NLP 분야에서 두 문장(정답/예측)간의 맥락적 유사도를 산출하는 Sementic similarity 지표인 BERTScore로 평가되었습니다. 3)은 1) 대비 큰틀의 맥락적 유사도를 기반으로 산출하는 지표이며 1)은 Word2Vect와 같이 유사한 의미의 단어의 겹침 정도를 기반으로 유사도를 산출하는 메트릭 입니다. 본 논문에서는 LLM-as-a-judge 을 중심으로 리포팅하였으며, 모든 메트릭이 NLP를 염두한 메트릭으로 자유분방한 출력에 대한 대응력이 있습니다.
이상입니다