서울대학교에서 AI 여름학교를 온라인으로 공개하였다. 덕분에 너무 유용하고 좋은 강의를 들을 수 있어 감사했고, 다양한 좋은 강의가 있었지만 듣는 당시 본인에게는 너무 어려워 이해하지 못한 강의를 정리하지 못해 아쉬움이 있다.
[Day2] Learning Disentangled Visual Representations with Minimal Human Supervision : 이용재 교수님
– 강의 abstract 일부
In this talk, I will present my research in computer vision and deep learning on creating recognition systems that can learn disentangled visual representations with minimal human supervision.
[강의 관련 논문]
Disentangled 역시 강의를 들을 당시에는 약간 생소한 용어였는데 최근 김형준 연구원님이 정리해주신 Learning Disentangled Representation for Robust Person Re-identification 와 같이 본다면 좋을 것 같다.
교수님은 최근 10년간의 visual recognition 분야의 엄청난 발전에 대해 먼저 소개하시면서 그 이유를 우리가 인공지능 수업에서 배웠듯이 Big compute(GPU), Big models (DNNs), Big labeled data로 소개하셨다. 여기서 GPU와 model은 점점 발전하고 있으나 Big labeled data 는 2012년의 ImageNet 이후 큰 발전이 없었다. 이에 대해 labeled data 가 앞으로 발전의 병목이 될 수 있음을 소개하였다.
labeled data가 크게 발전하지 않은 이유 중 하나는 label을 만드는 행위가 비용이 든다는 것이다. 또한 segmentation과 같은 pixel 단위의 labeling은 더욱 그렇다. 뿐만 아니라 labeling은 모호하여 사람이 일관적으로 어노테이션 작업을 할 수 없는 경우도 있다. 예를 들어 그림1의 두 고양이 종을 가르는 특성을 어노테이션 하라면 어떻게 해야할까? 물론 귀 모양과같은 확실한 부분도 있지만 어노테이션 하기 애매한 부분도 있다.

이렇게 데이터의 부족이 병목이 되는 현상을 막기 위하여 교수님께서 소개해주신 분야는 visual data understanding with minimal human supervision 이다.
visual data understanding을 위해서 Generative model을 이용하였는데 이는 Generative model은 모든 구조를 생성할 수 있어야 하기 때문에, Discriminative model보다 cheating을 하기 어려운 구조이기 때문이라 한다. 이때 Vanilla gan도 좋지만, 이는 fine-grained control을 할 수 없다. 즉, input의 어느 특성이 생성 결과에 어떻게 영향을 끼쳤는지 확인할 수 없다는 뜻이다. input의 특성과 결과의 연관성을 확인할 수 있는 생성 모델을 위하여 계층적 생성모델을 제안하였다고 한다.
계층적 생성 모델이란 그림2 처럼 계층적으로 생성하여 input이 변화시키는 요인을 확실히 할 수 있다는 점이다.
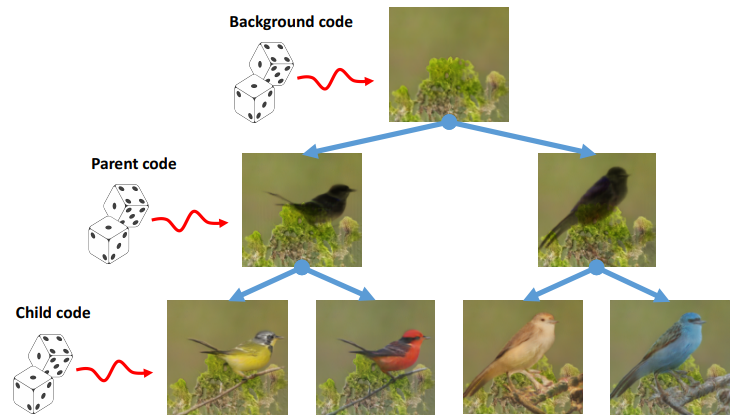
그림 3과 같은 다양하고 신기한 결과가 많이 소개되었고, 그 중에서 Cartoon과 real Image를 통한 이미지 생성 예시가 가장 신기하였는데, 공개된 논문이나 자료를 찾지못해 추가하지 못했다. 그 예시를 통해 disentangled 특징을 배우는 것이 Semantic Alignment와도 연관이 있음을 보여주셔서 신기했다.

[Day2] Neural Language Models with Knowledge Injection: 황승원 교수님
– 강의 abstract 일부
본 발표에서는 언어 이해에 있어 지식을 활용하는 연구 사례에 대해 연세대학교 Data Intelligence 연구실의 최근 2년 연구를 바탕으로 소개한다. 관련 주제의 보다 자세한 정보는 http://dilab.yonsei.ac.kr/~swhwang에 있다.
사람같은 AI를 위해서는 지식 기반의 모델이 만들어 져야 한다는 말을 들어본 적이 있는데 지식 기반이라는 말이 어떤 뜻인지 이해가 어려웠는데 마침 관련 강연이 있어서 좋았다. 본 강연은 NLP 모델에서 어떻게 지식을 주입하는지에 대한 내용이다.
– Knowledge Modality
우선 지식의 표현형태로는 text, graph, table, embedding의 방법이 있으며, Modality 간에 전이 가능하다. 우리가 영상 데이터 셋으로 부터 임베딩할 스페이스와 도메인 변환 생성자 등을 이용할 수 있는데(ex. knn) 이도 지식의 한 표현 방법이다. 지식이라 해서 그래프 관계등을 이용하는 어려운 개념인줄 알았는데 생각보다 익숙하고 직관적인 개념이였다.
지식의 필요한 경우는 예를 들면 다음과 같다.
모델은 데이터셋을 충분히 잘 이해하고 있으나 배경 지식이 부족하여 (즉, 데이터셋으로만 학습할 수 있는 지식이 부족하여) 모델의 작동이 정상적이지 않은경우
위와 같은 경우에 기존에 구축된 데이터베이스나, wiki와 같은 이미 존재하는 정보를 이용하여 표현력을 강화 할 수 있다.
그렇다면, 이러한 knowledge를 어디에 주입해야할까?
– input을 augment
– 중간 feature의 표현력 강화
– 새로운 objecteve 생성
등으로 지식을 이용할 수 있다.
이외에도 매우 중요하고 재미있는 강의를 해주셨다. 모델이 데이터셋을 충분히 이해하고 있으나 배경지식이 부족하다는 말을 언뜻 들어는 보았으나 구체적으로 이해하지 못하였는데 교수님께서 잘 설명해 주셔서 이해가 되었다.
참조
그림1