오늘은 앞서 리뷰한 VLM is biased? 라는 질문을 다룬 논문의 이전 논문을 소개하려합니다. 본 논문은 VLM이 이미지를 보고 대답할때 실제로 보고있는것인지 확인하기 위한 벤치마크를 제시합니다.
* 논문에서 보고있다의 정의는?
인공지능이 생각한다는것은 튜링 테스트를 통해 검증합니다. 기계가생각할 수 있는가? 라는 철학적일 수 있는 질문에 대해 정의를 내린 시도이죠. 본 논문은 VLM이 볼 수 있는가?에 대해 나름대로의 정의를 내리고자 합니다. 어떻게 인공지능의 시력을 정의할 수 있을까요? 가장 직관적으로는 인간의 시력을 테스트하는 시력검사표를 이용하는것입니다. 그러나 해당 정보는 인터넷에서 쉽게 구할 수 있으므로 인공지능이 보는것이 아닌 기억해서 대답할 여지가 생기게 됩니다. 또한 GPT-4o의 경우 시력검사표와 같은 구분된 알파벳이나 심볼에 대해 상당히 정확한 예측을 이미 하고있기에, 시력검사표를 이용한다면 LLM 시력을 이미 가졌다라고 평가할 수 밖에 없었습니다. 따라서 해당 지표를 이용한다면 “VLM이 이미지를 실제로 보고 있는가”에 의문을 갖는 것 부터 성립될 수 없습니다.
따라서 본 논문에서는 인터넷에 존재하지 않으면서 시력을 평가하기 위한 지표로 기본 기하학 요소들이 가까이있거나 겹치거나 교차하는 것 과 같은 상태를 구별해내는 것을 통해 시력을 정의하고자 했습니다. 글자 인식과 같은 명확한 것이 아닌 추상적인 관계를 시각적으로 판별하는 능력을 시각으로 정의한 것입니다.
* 그들의 가설
그렇다면 왜 VLM이 보고있는지 검토해야 했을까요?
논문은 VLM이 ‘late fusion’ 방식에 의존하기 때문에 이미지에 대한 완전한 “봄”이 불가능하다고 가정했습니다. late fusion이란 VLM이 이미지 시각적 표현을 우선 저차원의 벡터로 임베딩 한 후, 이를 통해 LLM하여 나중에 답변으로 생성하기 때문에 발생하는 현상입니다. 쿼리를 고려하지 않고 이미지를 저차원으로 임베딩하는 과정에서 정보의 손실이 있기때문에 VLM이 실제로 보지않고 학습에서 암시적으로 학습된 일종의 prior에 따라 행동할 가능성이 있는 것입니다.
정리하면, 논문은 VLM이 late fusion 때문에 실제로는 보지않고 응답하고 있을 가능성을 제시합니다. 이를 검토하기 위해 BlindTest라는 기하학적 요소들의 관계(가까이 있음, 겹침, 교차)를 파악하도록 하는 벤치마크를 설계하였고 최신 SOTA VLMs에 대한 평가를 진행했습니다.
* 당대의 SOTA VLMs
실험에서는 4개의 공개되지않은 상업모델(GPT-4o, Gemini-1.5 Pro( Gemini-1.5), Claude-3 Sonnet(Sonnet-3), Claude-3.5)과 8개의 오픈소스 모델(LLaVA OneVision-qwen2 ( LLaVA-OneV), Phi-3.5-vision-instruct(Phi-3.5), InternVL-2)에 대해 0.5B/72B), 2개의 slow-thinking model(A closed-source Gemini 2.0 Flash-Thinking, open-source QVQ-Preview (QVQ))이 실험되었습니다.
* 벤치마크 설명: BlindTest, 7 very simple, yet novel tasks.
7개의 테스크의 대략적인 설명은 위와 같습니다. P1은 얇은 두선이 교차하거나 만나는 점의 갯수를 새는것입니다. P2는 두 선의 인식률을 높이기 위해 더욱 두껍고 먼 원에 대해 교차하거나 만나는 것에 대해 여부를 확인합니다. P3는 비교적 쉬운 글자 인식 대신에, 도형을 결합하여 붉은 원을 친 알파벳을 구분해내도록 하는 테스크이고, P4는 속이 빈 도형이 겹쳐진상황에서 도형의 갯수를 구별하며, P5는 겹처진 사각형의 갯수를 P6은 표 모양 구조의 행과 열의 갯수를 새도록 한다. 마지막으로 P7의 경우는 지하철 노선도의 일부를 통해 두 지점을 잇는 선로의 갯수를 새는 것입니다. 그럼 이제, 각 테스크에 대한 성능을 통해 VLM이 실제로 보고있는지 확인해보겠습니다.
* P1: VLMs cannot reliably count line intersections

위는 첫번째 테스크의 예시이다. 두 선이 몇번 닿는가에 대해 다양한 VLMs 들이 예측 수행 결과를 확인할 수 있습니다. 아래의 실험 결과 두 선의 거리가 가까울수록 닿거나 겹치는 것에 대한 구분력이 떨어지며 chartQA와 같은 기존 벤치마크에서 잘 동작하는데 비에 P1에 대해서는 잘 동작하지 않는것으로 보아 VLM이 전반적인 추세는 잘 인식하나, 특정 지점에 확대된 정보등 zoom in 정보에는 손실이 있었음을 확인할 수 있습니다.

* P2: VLMs cannot clearly see if two circles overlap or not

다음은 P2의 수행 예시입니다. P2는 P1의 조금 더 쉬운 버전이라고 생각하면 좋습니다. 선 대신 인공지능이 인식하기 좋은 넓적한 원 도형을 이용한 것입니다. 실험 결과에 대해 논문은 이렇게 쉬운 테스크에서도 perfectly하게 동작하는 VLM이 없으며, 그 중에서도 GPT의 경우 도형간의 거리가 원의 반지름보다 넓은 매우 쉬운 테스크에 대해 100%의 정확도를 달성하고 있지 않음을 지적했습니다. 정리하면, 해당 실험에 결과에서도 디테일한 정보에 대한 손실이 있었음을 확인한 것입니다.

* P3: VLMs do not always see the letter inside the red circle

기존 VLMs이 붉은 원이나 OCR 능력이 있는것을 기반으로 이들이 진짜 보고있다면 두 테스크의 결합인 체크한 알파벳 읽기가 가능할것이라는 가정으로 위와같이 문제를 설계했습니다. 특히 사전 지식의 관여 정도를 판단하기 위해 일반 단어인 Acknowledgement와 중복되는 알파벳이 없는 단어(Subdermatoglyphic), 단어가 아닌 무작위 문자열인 tHyUiKaRbNqWeOpXcZvM에 대해 실험을 진행했습니다. 실험 결과 단어가 가까운 경우 인접한 알파벳과 혼동하는 경우가 있었으며(지엽적 정보의 일부 손실) 실제 단어인 Acknowledgement와 Subdermatoglyphic에 대한 오차율이 tHyUiKaRbNqWeOpXcZvM에 대한 오차보다 적은것을 통해, 기존에 학습했던 정보가 판단에 일부 관여함을 암시했습니다.

* P4&P5: VLMs struggle to count overlapped and nested shapes

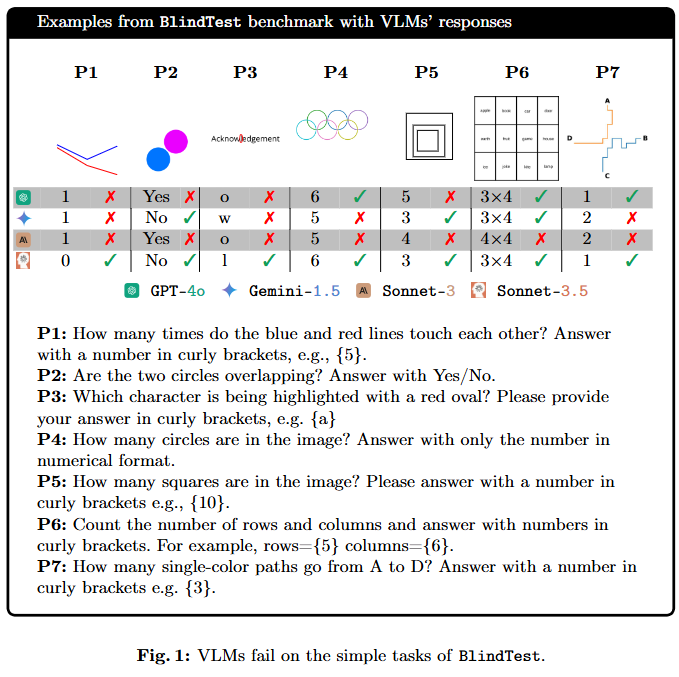
다음은 겹치는 도형의 갯수세기에 대한 능력 평가입니다. 실험 결과 특이한 현상이 발생했는데요, 원과 오각형의 경우 5개 이상의 도형이 있을경우 정확도가 급격하게 하락함을 아래의 성능표를 통해 확인할 수 있습니다. 그 원인은 Figure34에서 확인할 수 있는데요, 제미나이가 모든 입력에 대해 도형의 갯수를 5개로 예측하고 있습니다. 저자들의 분석결과 웹상에 올림픽의 오륜기가 많이 등장하여 이에 편향된 학습을 하였다고 합니다.
다음으로 P4보다 적은 도형 갯수(2~4)로 겹쳐진 사각형의 갯수를 판단하는 테스크에 대해서도 온전히 수행하지 못했으며, 도형이 단 2개밖에 없는 상황에서도 100%가 아닌 성능을 보이며 late fusion을 통한 디테일한정보의 손실이 있었음을 예측할 수 있습니다.

* P6: VLMs cannot reliably count rows and columns in a grid

다음으로 사각형들이 붙어있는 표와 유사한 형태에서 행과 열을 셀 수 있는가에 대한 평가입니다. 평가 방식(질문표)는 위와 같습니다.
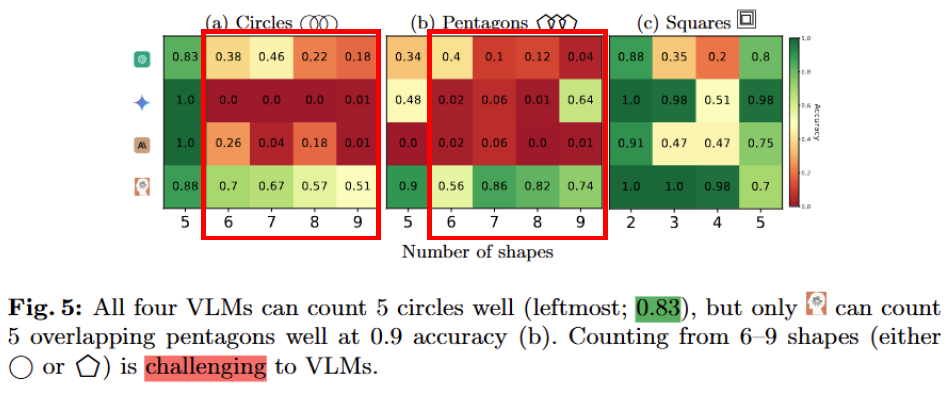
실험결과는 놀랍게도 사각형의 내부가 비어있을때(a)보다 텍스트로 채워져있을때(b) 행과 열을 정확하게 샘을 확인할 수 있었다고 합니다. 저자들은 이러한 현상이 발생이유가 아마 학습과정 중에서 일반적인 문서에는 내용이 찬 표를 통해 이러한 구조를 학습하기 때문일 것이라고 말합니다. 즉 VLM이 고수준의 텍스트에 대한 이해능력은 있으나, 기하학적 구조에 대한 직접적인 이해는 없는 상태로 저자들이 정의한 “본다”의 정의엔 부합하지 않음을 확인할 수 있습니다.
* 파란 글씨는 제 생각입니다
* P7: VLMs struggle to count single-colored paths
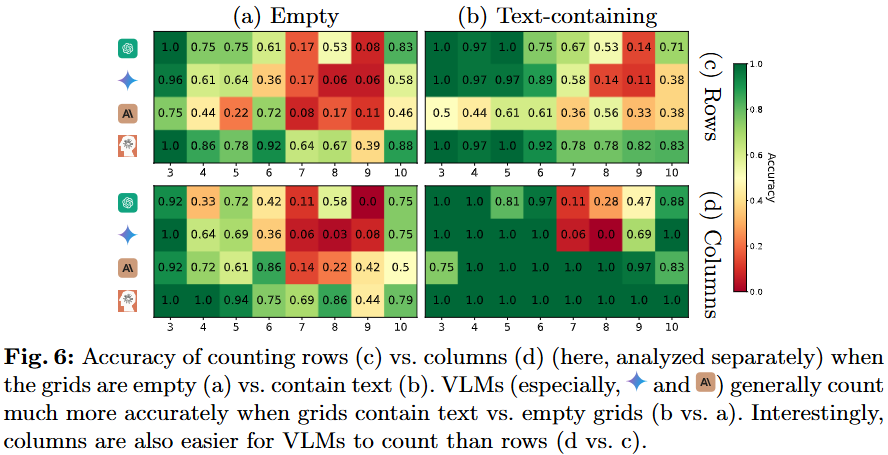
마지막으로 P7은 지하철 노선도의 일부를 가져온 데이터로, A부터 C 지점까지 가는 경로의 개수를 세도록 요청하는 테스크로 설계되었습니다. 실험 결과 예시의 가장 왼쪽과 경로가 하나만 존재하는 간단한 경로에서도 VLM들이 100% 정확도에 달성하지 못했으며 복잡도가 증가함에 따라 성능이 크게 하락함을 Figure 42를 통해 확인할 수 있습니다. 그러나 아래에서 확인할 수 있듯이 경로의 꺽임수가 더욱 단조로워지면, VLMs의 예측이 더욱 정확해지면서 시각 정보가 단순화되면 모델의 시각 능력(기하학 정보의 해석 능력)이 개선됨을 확인할 수 있었습니다.
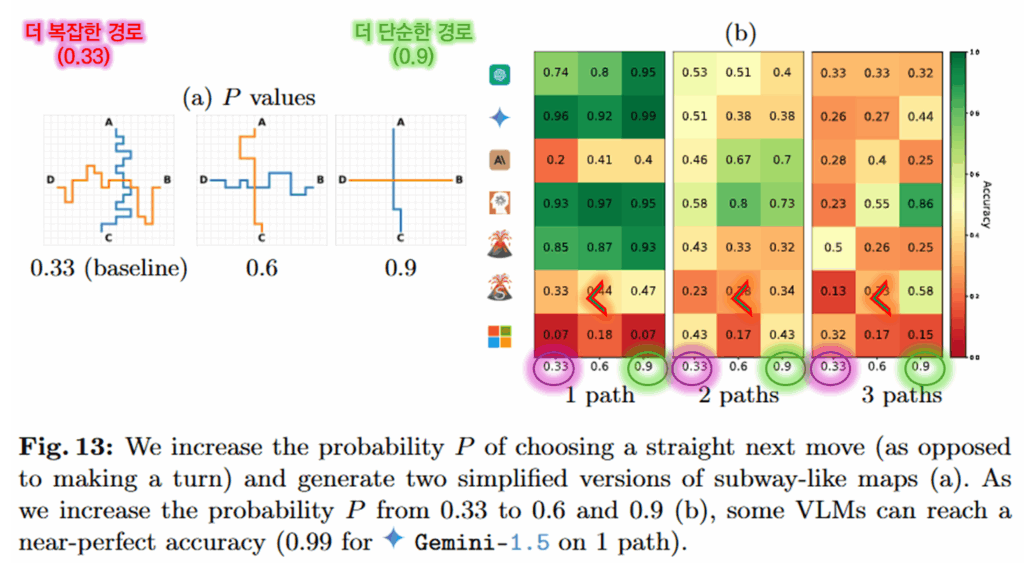
앞선 실험을 통해 VLMs이 다양한 기하학적 정보에 대해 단순화 된다면 시각적 이해능력을 지니지만, 정보가 복잡해진다면 이런 시각 능력을 손실한다고 분석했습니다. 그렇다면 이런 손실은 chain-of-thought나 meta prompting과 같은 slow-thinking model을 통해 개선이 가능할까요? 이를 위해 일반 모델인 Gemini 2.0 Flash, Qwen2-VL과 slow-thinking model인 Gemini 2.0 Flash-Thinking, QVQ 모델의 성능을 비교해 리포팅한 결과는 아래와 같습니다.
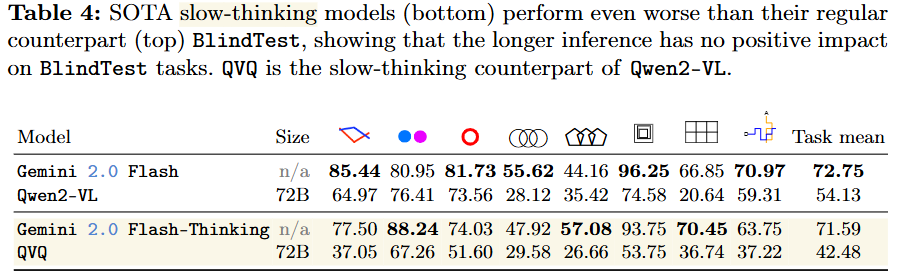
실험 결과 slow-thinking은 기본 모델과 유사한 성능으로 기하학적 정보 해석 오류를 통한 성능 하락을 개선할 수 없음을 확인할 수 있습니다. 저자들은 slow-thinking은 추론과 같은 고수준의 테스크에서 효과있는것으로 BlindTest와 같은 직관적인 테스크에는 효과가 없는것이라고 말했습니다. 즉, 추론으로는 해결할 수 없는 시각적 정보의 손실이 있었음을 명확히 할 수 있는 결과였습니다. 아래는 실험결과의 예시로 이미 손실된 정보로 생성한 결과를 정당화하려고 시도할 뿐, 예측이 개선되고 있지는 않음을 확인할 수 있습니다. 또한 제공된 정보 내에서 추론을통해 점검하고 놓친 정보를 재검토했음에도 답변이 개선되지 않았음을 통해, 디코딩 이전 확실히 정보의 손실이 있었음을 예상할 수 있습니다.

* 파란 글씨는 제 생각입니다
* 그렇다면 이러한 Blind 현상(시각 정보 손실)의 원인은 이미지 인코더에서부터 잘못된 것일까요?
BlindTest와 slow-thinking모델에 대한 실험결과로, 우리는 VLMs이 예측과정에 시각정보 손실이 있었음을 예상할 수 있습니다. 또한 이는 입력 이미지의 전반적인 정보는 이해하나 Zoom-in 된 정보에 대해 손실된 것으로 처음에 저자들이 상정한 시각 정보 손실의 원인인 last fusion 때문일 확률이 높습니다.
그렇다면 Late-fusion을 할때, 질문에 대한 고려없이 이미지를 저차원으로 임베딩하므로서 발생하는 정보손실이 이러한 현상의 원인일까요? 이를 알아보기 위해 저자들은 linear-probing classifer를 설계하여 실험하였습니다.
- 실험 설계
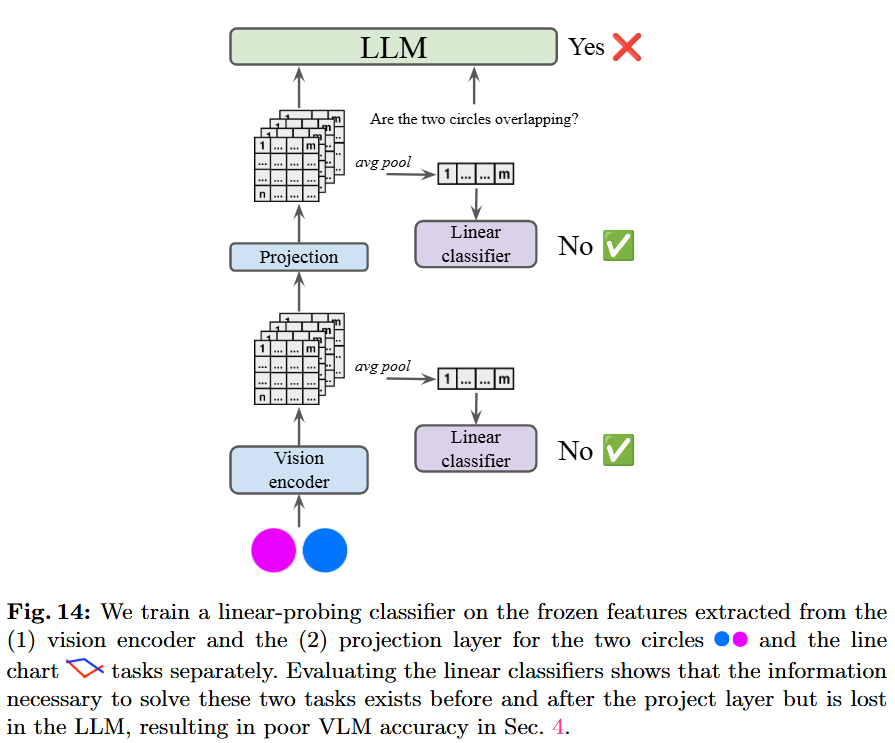
저자들은 해당 분석을 위해 visual encoder와 LLM에 접근할 수 있는 open-source VLM에서 LLaVA-OneV-S(0.5B)와 Phi-3.5(4.2B)를 활용했습니다. 그 이유는 첫째로는 두 모델의 visual encoder인 SigLIP과 CLIP은 VLMs 모델이 활용하는 가장 대표적인 encoder로 VLMs에서 encoder로 인한 시각 정보 손실을 평가하기에 알맞기 때문이고, 둘째로는 두 모델은 가장 작은 VLMs으로 해당 모델의 encoder로 추출된 임베딩 특징량이 시각적 정보를 포함한다면, 이보다 더 큰 모델이나 상업 모델은 당연히 이러한 정보를 포함할 수 있을것으로 예측하기 때문이라고 합니다. (아직은 모델 크기로 인한 임베딩 특징량의 편향가능성까지는 고려하지 않은것이지요) 또한 실험 테스크는 직선의 교차 판별(P1)과 원의 교차 판별(P2)로 가장 쉬운 테스크로 진행하였다고 합니다.
저자들의 linear-probing classifer 실험 프레임워크는 Figure 14와 같습니다. 각 visual encoder로 추출한 특징량에 대해 선형분류기를 학습하였고 LLM은 학습을 진행하지 않았습니다.
- 실험 결과
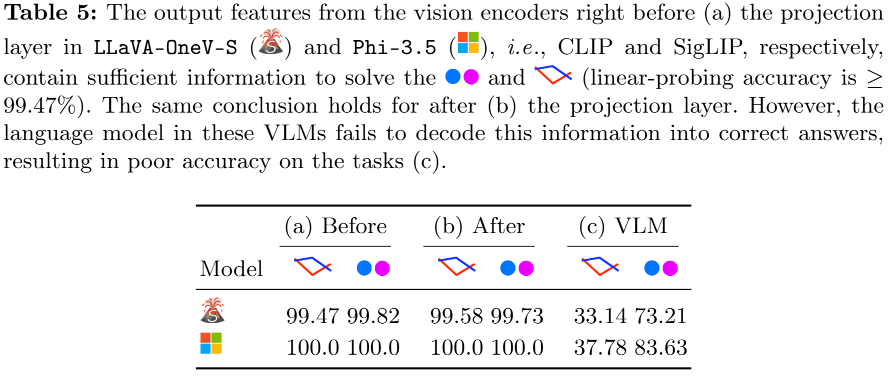
실험 결과는 Table5와 같습니다. 실험 결과 encoder로 임베딩한 feature 값을 linear classifer를 통해 학습하였을때 충분히 구분 능력이 있었다는 것 입니다. 즉 시각적 정보의 손실은 encoder에서 발생한 것이 아니며 VLMs의 언어모델들이 임베딩된 특징량에 “존재하는” 시각적 정보를 활용하지 못하고 있다는 것을 확인할 수 있는 흥미로운 결과입니다.
실험이 다양한 리뷰였는데요, 세미나때 해당 논문과 VLM is biased 논문을 함께 언급하며 일부 혼란을 드린것 같아, 제 생각과 논문의 내용에 대한 파트를 구분하여 작성해 보았습니다. 특히 VLM is biased에 대한 언급을 모두 뺏기때문에, 세미나에서 헷갈리셨던 분은 해당 리뷰가 도움이 될 것 같습니다. 세미나에서는 BlindTest 벤치마크의 의미에 대한 질문이 많았었는데요, 이건 LLM의 학습 데이터셋의 문제가 아닌가, 학습하지 않아서 발생한 문제 아닌가? 하는 질문들이었습니다. 그러나 대형 모델의 학습이 어려워진 지금, CoT 기법과 같은 추론단의 아이디어로 학습없이 이러한 현상을 해결하는 방법론을 고려해보는것도 유의미할것 같습니다. 이상으로 리뷰를 마치겠습니다. 감사합니다.
유진님 안녕하세요. 좋은 리뷰 감사합니다.
결국 VLM 시장을 이끌어갈법한 거대 모델들도 간단한 기하나 OCR 문제 앞에 무너지는 현상과 이유를 잘 분석해준 논문으로 이해하였습니다.
대부분의 오픈소스 모델이 보통 학습때 이미지 또는 비디오 캡션 매칭, 수학문제 풀이, OCR 등등 다양하게 학습함에도 불구하고 late fusion으로 인해, 디코더에서 시각 정보가 소실되어 간단한 문제도 풀지 못함을 보여주었습니다. 혹시 만약 학습 리소스와 시간이 충분한 누군가가 이걸 해결하고자 한다면, 어떤 방식으로 해결할 수 있을지에 대한 저자의 의견이 있었는지 궁금합니다.
추가 reasoning으로도 해결이 불가했다고 하면, 저자의 분석대로 기존 모델들이 decoder 단에서 feature를 건드리는 방식 자체가 지금 해결하고자 하는 벤치마크와 안맞는다는 의미인 것 같은데, 그렇다면 디코더 구조를 변경하여야 한다는 것인지? 아니면 다른 fusion 방식으로 좀 개선해볼 수 있을지에 대한 답이 떠오르지 않아 혹시 언급이 있었는지 궁금하여 여쭈어봅니다.
안녕하세요 질문 감사드립니다
먼저 윗 질문에 대해서는 확인하지 못한 것 같습니다. 다음 질문에 대해서도 말씀드리자면 본 논문은 기존에 지각하지 못했던 문제에 대한 이슈라이징과 새로운 벤치마크 제공 자체에 의의를 둔 논문으로 완전한 해결책까지는 다루지 않았습니다. 오히려 제시한 벤치마크에 대해 2-shot, chain-of-thought, meta-prompting와 같은 기존의 VLM 모델 출력 개선 방식이 오히려 악영향을 끼치거나 약한 개선을 보이는 결과(본문 Appendix D.1 참조)에 제한되었다고 밝히며 어떻게 개선해볼 수 있을지에 대해 논의해봐야한다는 문제 제기 연구로 이해해주시면 좋을것 같습니다.
이상입니다
안녕하세요 유진님 좋은 리뷰 감사합니다.
세미나에서도 들으면서 되게 생각지도 못한 실험들을 볼 수 있어서 흥미롭게 봤던 것 같습니다.
서두에 이제 VLM이 late fusion 방식에 의존하기 때문에 이미지에 대한 완전한 “봄”이 불가능하다고 가정한다라고 가설을 세운 것 같습니다! 근데 P4&P5에서 Gemini가 모든 답을 5개 라고 한 건 웹 학습 데이터(올림픽 오륜기) 편향 때문이라 설명해주셨는데 그렇다면 이 BlindTest 결과가 정말 late fusion 구조 한계 때문인지 아니면 단순히 학습 데이터 편향 때문인지 아직 구분이 명확하게 되지가 않는데, 이부분에서는 어느 부분에서 late fusion 구조 한계가 드러나는지 설명해주시면 감사하겠습니다!
안녕하세요 질문 감사드립니다
우선 해당 결과는 학습 데이터 편향으로 보시면 좋을 것 같습니다. late fusion 구조의 한계란, VLM 모델이 질문에 대한 답변을 생성하는 과정에서 이미지를 임베딩한 Visual Feature를 레퍼런스로 활용하는데, 해당 Visual Feature를 생성하는 encoder(주로 CLIP이나 SigLIP)이 이미 쿼리 해결을 위한 정보를 삭제했기 때문에, 문제 해결, 즉 완전한 “봄”이 불가능한것 아니냐? 라는 의문에 대한 것이였습니다. 그러나 Fig14에서 확인하였듯이 이는 late fusion구조의 한계라기 보다는 디코더 등의 학습에서, 학습데이터의 편향으로 발생하는 한계일 가능성이 높음을 알 수 있습니다. 따라서 학습 데이터 편향으로 보시는게 좋을 것 같습니다.
이상입니다