안녕하세요. 이번 주도 지난번 토큰 프루닝 관련 주제에 이어서 현재 제가 실험 중에 참고했던 논문 한 편을 소개해드리려고 합니다. 고해상도 이미지를 다루는 Vision-Language Model(VLM)이 점점 많아지고 있는데, 다들 아시다시피 해상도가 높아질수록 모델의 정확도는 올라가지만 그만큼 처리해야 할 시각 토큰(visual token)의 수가 기하급수적으로 늘어나서 연산량과 메모리 사용량이 엄청나게 증가하는 문제가 있습니다. 특히 제한된 리소스를 가진 환경에서는 이런 모델을 돌리는 것 자체가 부담이 될 수밖에 없습니다.
이번에 리뷰할 HIRED (High-Resolution Early Dropping) 라는 논문은 바로 이러한 문제를 해결하기 위해 제안된 기법이라고 보시면 될 것 같습니다. 이름에서 알 수 있듯이, LLM에 토큰이 들어가기 전에, 즉 LLM모델에 들어가기 전 이른 단계에서 중요하지 않은 시각 토큰을 효과적으로 버려서 연산 효율을 극대화하는 데 초점을 맞춘 연구라고 보시면 될 것 같습니다.
또 중요한 특징으로는 기존 고해상도 VLM에 별도의 추가 학습 없이 기존 모델에 바로 적용할 수 있는 plug-and-play방식이라는 점과 , 단순히 토큰을 줄이는 것을 넘어 어떤 이미지 영역에 token budget을 더 할당할지까지 동적으로 결정한다는 점이라고 볼 수 있습니다. (token budget 이라고 표현한 것은 각 이미지에 dynamic하게 프루닝 비율을 어떻게 결정할 것인지 각 이미지에게 토큰을 얼만큼 할당할 것인지 어떤 예산이라는 용어로 표현했다고 보시면 좋을 것 같습니다.)
이후에 자세하게 설명드릴 예정이지만 서두에 간단하게 설명드리면 고해상도 이미지를 여러개의 서브 이미지로 분할을 하게 되고, 원본 이미지를 다운 샘플링한 버전도 포함해서 모델에 태우우게 되는데 이때 Vision Encoder의 초기 레이어의 어텐션 정보를 활용해서 각 이미지 파티션의 시각적 중요도를 평가하고 이에 따라 토큰 예산을 분배하는 방식으로 동작한다고 보시면 좋을 것 같습니다. 그리고 난 후 최종 레이어의 어텐션 정보를 활용해 각 파티션에서 가장 중요한 visual 토큰을 선택하고 나머지는 제거하는 식으로 작동을 합니다.
바로 리뷰 들어가도록 하겠습니다.
Introduction
GPT-4나 LLaVA와 같은 Vision-Language Model(VLM)은 시각 정보와 텍스트 정보를 함께 학습하는 좋은 멀티 모달 모델로 많이들 알고 계실 텐데요, 이런 VLM은 본질적으로 트랜스포머의 연산량의 문제나 리소스의 문제로 저해상도 이미지 인코딩에 의존하고 있기 때문에 고해상도 이미지 처리가 어렵고 결과적으로 fine grained한 시각 정보의 손실이 발생하는 문제가 있습니다. 당연히 고해상도 이미지는 세밀한 정보를 잘 보존하기 때문에 이를 잘 활용하게 된다면 VLM에서 정확도 면에서 큰 이점을 가질 수 있게 됩니다.
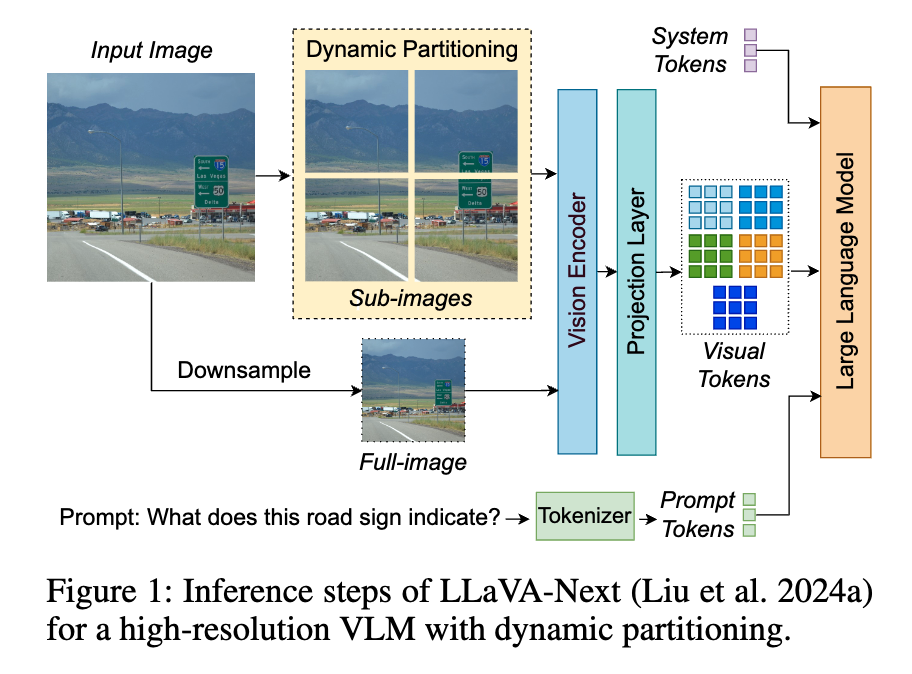
그래서 이러한 문제를 해결하기 위해서 최근 등장한 VLM들은 보통 고해상도 이미지를 위에 보이시는 figure 처럼 여러 개의 저해상도 서브 이미지(sub-image)로 나누고, 전체적인 맥락을 파악하기 위한 저해상도 풀 이미지(full-image)를 함께 인코딩하는 Dynamic Partitioning 방식을 사용합니다.
여기서 이미지의 각 파티션은 예를들어 sub-image 같은 경우에는 해당 영역에 대한 더 세밀한 local 표현을 더 담고 있지만 VIT에 각각 따로 들어가기 때문에 각 sub image 간에 정보는 교환하지 못합니다 그래서 full image를 같이 넣어줌으로써 원본 이미지의 전역적인 context를 포착할 수 있도록 해서 저해상도 단일 이미지를 처리했을 때보다는 시각적으로 좀더 세밀한 한 정보를 포착 할 수 있도록 합니다.
물론 고해상도를 한번에 ViT를 태워서 처리하는 것 보다는 연산량은 덜 하겠지만 그래도 이 방식은 일반적인 저해상도 단일이미지를 처리하는 VLM과 비교했을 때 보다는 3배에서 10배나 많은 시각 토큰을 생성하게 되고 이는 곧바로 추론 속도 저하, 지연 시간 증가, GPU 메모리 부족 문제로 이어질 수 밖에 없습니다.
근데 사실 기존에도 모델 경량화나 양자화 같은 최적화 기법들이 있긴 했습니다. 하지만 고해상도 이미지를 처리해야하는 입장에서 이 친구들은 과도한 토큰 수라는 근본적인 문제를 해결해주지는 못했습니다. 그래서 연구자들은 불필요한 토큰을 버리는 방향으로 눈을 돌렸는데, 기존 연구들은 몇 가지 한계가 있었습니다. 예를 들어, 토큰을 LLM단에서 뒤늦게 버리거나 , 특정 태스크(ex> 문서 이해, classification)에만 국한되거나 등등 한계가 존재 했습니다.
(사실 인트에 메소드를 간단하게 설명하고 넘어가려고했으나 분량이 많아져 그냥 메서드로 옮겼습니다..)
Method
이러한 프루닝 관련 논문들은 관찰과 분석을 굉장히 많이 하는 것 같은데 해당 논문에도 저자는 의문점을 가지면서 많은 실험을 통해 분석을 하고 통계를 내고 이를 기반으로 어떻게 프루닝을 할지 전략을 내세웁니다. 그래서 저자들은 LLM에 들어간 수많은 시각 토큰들이 모두 동등하게 중요할까라는 질문을 던졌고 그 궁금증을 해결하기위해서 LLM 디코딩 단계에서 각 토큰이 받는 어텐션 스코어를 분석합니다.
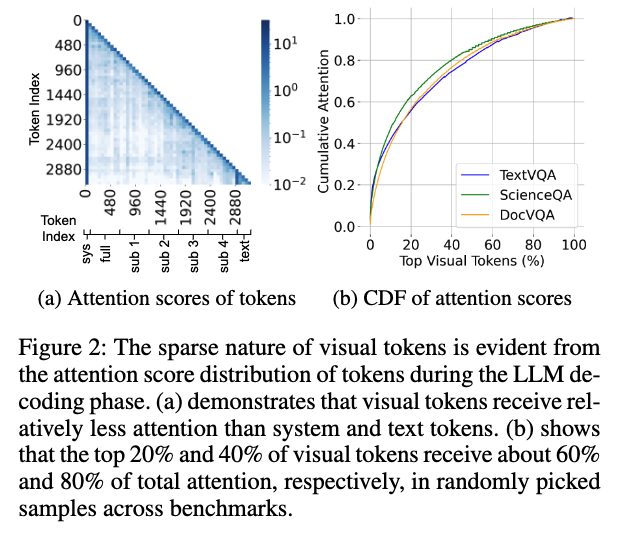
LLaVA-Next-7B 모델을 가지고 실험해보니 그래서 위 표를 보시면 전체 입력 토큰의 80~90%를 차지하는 압도적인 양의 시각 토큰들이 실제로는 텍스트나 시스템 토큰에 비해 훨씬 적은 어텐션 점수를 받고 있었다는 것을 확인하실 수 있씁니다. 그럼 주목받는 소수의 시각 토큰들이 얼마나 큰 영향력을 가지는지 누적 분포 함수(CDF)로 확인했는데 상위 20%의 핵심 시각 토큰들이 전체 어텐션의 약 60%를, 상위 40%의 토큰들이 80%를 차지하고 있었습니다. 즉, 소수의 에이스 토큰들이 이미지의 주요 문맥을 LLM에 전달하고 있었던 셈이라고 볼 수 있습니다.
그래서 정리하면 시각 토큰수는 많은데 LLM 단계에서 실제로 중요한 토큰은 소수에 불과하다 라는 것을 발견하고 아 그렇다면 중요도가 낮은 대다수의 토큰은 정확도에 큰 손실 없이 과감하게 버려도 괜찮겠구나! 라고 생각하고 어떻게 버릴 수 있을까를 고민하게 됩니다.
앞서 설명드렸는데 고해상도 이미지는 동적 분할로 전체 이미지(글로벌 표현)와 세부 영역(로컬 표현)을 함께 인코딩한다고 말씀드렸습니다. 이때 각 파티션 이미지들(full + 4 sub)가 LLM 디코딩 과정에서 얼마나 영향이 있는지 아래의 표처럼 정리를 했는데,
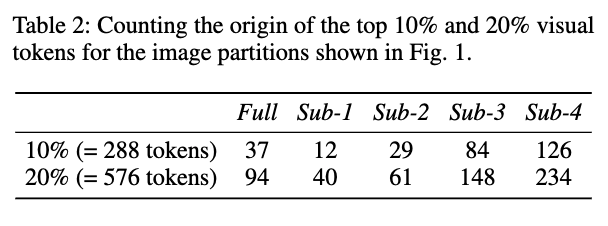
상위 10%,20%의 top visual token이 각각 어느 파티션에서 유래했는지를 세어본 결과를 나타낸 표라고 보시면 될 것 같은데 결과적으로 상위 visual token의 분포가 이미지 파티션 마다 서로 다르다는 것을 알 수 있습니다.
예를 들어(위 table을 예시로) 상위 10% 시각 토큰 중 Sub-4가 126개 Sub-3가 84개,반면 Sub-1은 12개에 불과하다면 이는 sub-4 sub-3의 이미지 영역이 LLM에게 더 중요한 visual 정보를 줬다라는 것을 뜻하고, 또 Full image 보다 특정 sub image 가 더 중요한 경우도 많은 것을 알 수 있습니다.-Full 이미지 (전체를 다운샘플한 요약 이미지)에서 유래된 토큰은 10%에서 37개,20%에서 94개 인 것을 보실 수 있습니다. Full image는 전체적인 문맥을 제공하지만 실제 중요한 정보는 Sub-3, Sub-4 같은 로컬 영역(sub-images)에 더 많이 존재하는 경우도 있습니다.
그래서 위와 같은 관찰로 모든 파티션에 동일한 토큰 budget을 주는 것보다는 좀더 대상 객체가 많고 콘텐츠가 많은 파치션에 더 많은 토큰을 할당해줘야한다, 각 파티션에 대해서는 중요도가 불균형적이기 때문에 동일한 예산 분배보다는 다이나믹하게 분배해여 된다 라고 HiBRED를 설계를 합니다.
그래서 다시 정리하면
첫번 쨰 관찰 LLM의 생성 단계에서 실제로 중요한 시각 토큰은 소수에 불과하고 두번 째 관찰에서는 이미지 파티션마다 중요도가 다르다는 점을 분석을 했습니다.
위 분석을 바탕으로 HIRED는 early dropping 전략을 이 두 가지 관찰을 기반으로 설계를 합니다.
일단 멀티모달 모델에서 일반적으로 사용되는 ViT를 사용합니다. 이때 CLS 토큰과 각 이미지 패치 사이의 어텐션 값, 어떤 패치가 이미지 전체를 이해하는 데 더 중요한지를 파악할 수 있는 이 정보를 활용하게 됩니다.
결과적으로 제일 중요한 핵심은 LLM 이전 단계에서 최종 응답 생성을 위해 꼭 필요한 토큰은 어떻게 식별할지가 제일 중요하고 이에 대한 답을 얻기 위해서 저자들은 3번째 분석을 진행합니다.

위 그림은 ViT의 여러 레이어에 걸친 CLS-to-path attention map을 시각화 한것이고 저자들을 두가지를 발견했다고 합니다.
첫 번쨰 초기 레이어에서의 CLS 토큰의 어텐션 맵은 이미지의 주요 객체나 어떤 대상이 있는 영역을 집중적으로 본다고 합니다. 약간 우리가 사진을 처음 볼 때 주요 피사체부터 눈에 들어오는 것처럼, 초기 레이어의 어텐션은 배경 같은 부수적인 정보는 무시하고 이미지의 핵심 객체(논문의 예시에서는 새)가 있는 영역에 집중되는 모습을 보였습니다.
그리고 두 번째 마지막 레이어같은 경우는 정보량이 많은 영역을 보여줍니다. 이 단계에서는 단순히 객체뿐만 아니라, 모델이 이미지 전체의 관계를 학습하고 그 핵심 특징들을 압축해놓은, 정보 밀도가 높은 영역들이 활성화되었다고 합니다. 그래서 초기 레이어에서 학습한 지역적 특징들을 종합해 전역적 특징으로 만드는 과정에서, 일부 배경 패치에 이러한 정보들이 들어가서 객체뿐만 아니라 관계성을 학습한 배경 영역도 함께 활성화되는 모습을 보입니다. 최종 레이어에서 활성화된 패치는 이미지의 알짜배기 정보를 담고 있다고 보시면 될 것 같습니다.
그래서 위에서 분석한 CLS Attention map의 두 가지 주요 특성 바탕으로 토큰 budget 분배를 어떻게 할지 전략을 세웁니다. 초기 레이어의 어텐션 맵 같은 경우에는 어떤 파티션에 중요한 내용물이 많은가? 를 판단하는 기준으로 삼아 토큰 예산을 차등 분배하고,최종 레이어의 어텐션 맵은 각 파티션 안에서 어떤 토큰이 가장 핵심적인 정보를 담고 있는가? 를 판단하여 실제로 남길 토큰을 최종 선택하도록 설계를 합니다.
좀더 구체적으로 설명드리면 아래와 같이 두단계로 동작을 합니다.
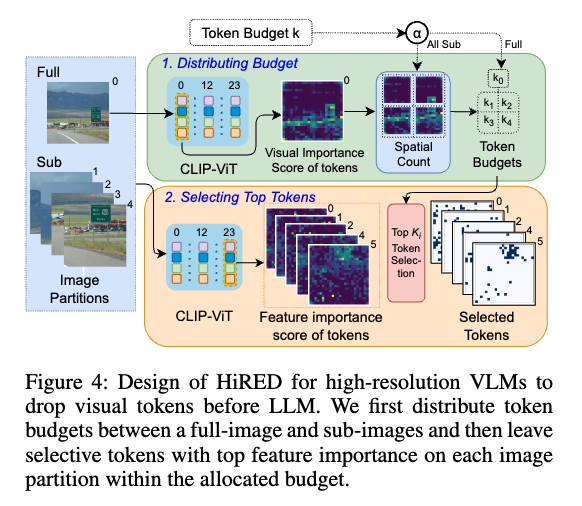
1. 토큰 예산 분배 (Token Budget Distribution)
먼저 사용자가 전체 토큰의 20%만 사용하겠다와 같이 총 토큰 예산을 정하면, HIRED는 이 예산을 각 이미지 파티션(풀 이미지, 서브 이미지들)에 나눠주는 작업부터 합니다. 먼저 전체 예산의 일정 비율(α)을 풀 이미지(full-image)에 할당합니다. 이 비율은 하이퍼파라미터로, 논문에서는 실험을 통해 0.5가 가장 좋았다고 합니다. 그리고 나머지 예산은 서브 이미지(sub-image)들에 나눠주어야 하는데, 이때 ViT의 초기 레이어(0번 레이어) 어텐션 맵을 사용합니다. 각 서브 이미지 영역에 해당하는 어텐션 맵의 활성화 정도(visual content score)를 계산해서, 중요한 콘텐츠가 많다고 판단되는 이미지 조각에 더 많은 토큰 예산을 할당하는 방식입니다. 즉, 중요한 객체가 있는 이미지 조각에서는 토큰을 덜 버리고, 배경만 있는 조각에서는 더 많이 버리게 되는 셈입니다.
추가적으로 visual content score 계산에 대해서도 구체적으로 설명드리면 ViT의 0번 레이어에서 CLS Attention Map을 모든 헤드에 대해 합산해서 visual importance score를 계산하게 되고 입력 이미지에 적용한 것과 동일하게 dynamic partitioning을 Attention Map에도 적용합니다. 그래서 각 이미지 파티션에서 활성화된 패치 수를 기반으로 visual content score를 구해게 됩니다. 마지막으로,이 점수들을 기반으로 full에 할당하고 남은 토큰 예산을 서브 이미지 파티션에 분배하는 방식으로 동작한다고 보시면 좋을 것 같습니다.
2. 상위 토큰 선택 (Token Dropping)
각 이미지 파티션별로 예산이 할당되었다면, 이제 그 예산만큼 가장 중요한 토큰들만 남기고 나머지는 버려야 합니다. 이때는 ViT의 마지막 레이어(22번 레이어) 어텐션 맵을 활용하게 됩니다. 마지막 레이어의 CLS 어텐션 맵을 기반으로 각 토큰의 feature importance score를 계산합니다. 이 점수가 높을수록 모델이 최종적으로 이미지를 이해하는 데 더 중요한 정보를 담고 있는 토큰이라고 볼 수 있습니다. 그리고 각 이미지 파티션 내에서 이 중요도 점수가 높은 순서대로, 이전에 할당받은 예산 개수만큼 토큰을 선택하고 나머지는 모두 버립니다. 그다음 모든 이미지 파티션에서 선택된 토큰들을 하나의 단일이미지 배치로 묶어서 최종 시각 토큰 세트로 구성해서 LLM에게 전달하게 됩니다.
이렇게 선택된 소수의 정예 토큰들만 모아서 LLM에 전달하는 것이 HIRED의 전체적인 흐름이라고 보시면 좋을 것 같습니다. 결과적으로 이 모든 과정이 ViT 인코더 내부에서 일어나기 때문에 LLM의 연산 부담을 줄일 수 있게 됩니다.
이제 실험파트입니다.
Experiments
비교 대상으로는 비슷한 조기 드롭핑(early-dropping) 기법인 PruMerge와 PruMerge+를 선정했다고 합니다. 일단 가장 먼저 궁금한 것은 토큰을 그렇게 많이 버리는데, 정확도는 괜찮을까? 하는 의문점이라는 생각이 드는데 이에 대한 실험 결과가 아래입니다.
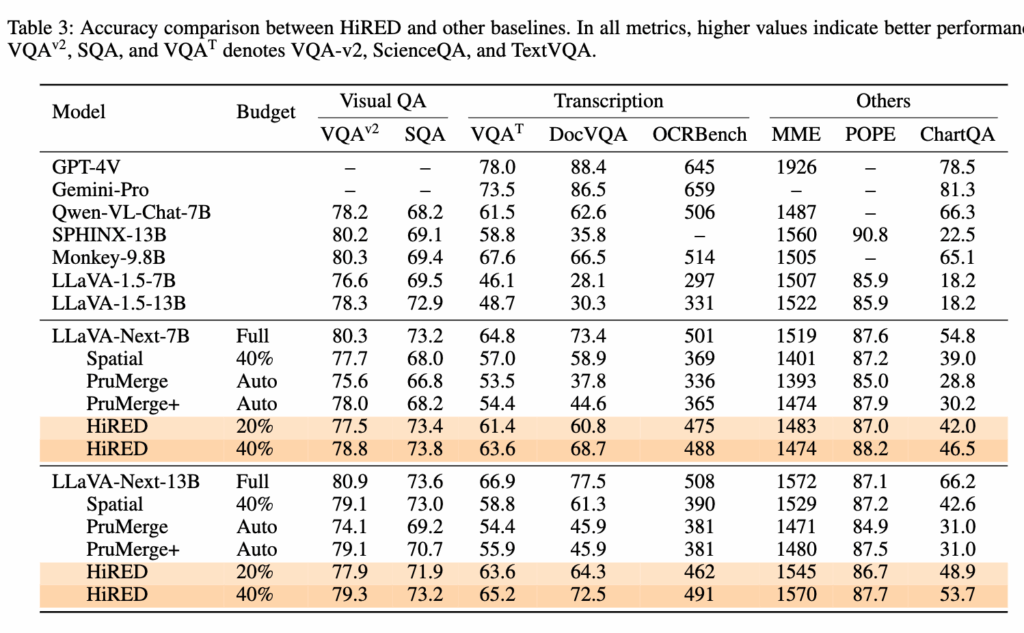
위의 table 3은 HIRED와 다른 모델들의 정확도를 종합적으로 비교한 결과입니다. HIRED는 20%의 토큰 예산만으로도 Visual QA 태스크에서 원본 모델과 거의 동일한 성능을 보였습니다. 글자를 읽어내는 것처럼 더 세밀한 정보가 필요한 Transcription 태스크에서도 40%의 토큰으로 비슷한 정확도를 유지했습니다.
개인적으로 저번 ToSA 리뷰에 이어서 비슷하게 신기했던 부분은, ScienceQA와 POPE 같은 일부 벤치마크에서는 오히려 토큰을 줄였을 때 정확도가 소폭 상승했다는 점입니다. 아마도 불필요한 노이즈 토큰을 제거하면서 모델이 더 중요한 정보에 집중하게 되는 일종의 regularization 효과가 나타난 것으로 보입니다. 경쟁 모델인 PruMerge+와 비교하면 HIRED의 효율성이 더 돋보이는데, PruMerge+가 평균 55%나 되는 토큰을 썼음에도, 20%만 쓴 HIRED보다 TextVQA 같은 태스크에서 정확도가 최대 26%나 낮았다는 점은 HIRED의 토큰 선택 방식이 효율적이다라고 볼 수 있습니다.
위에서 정확도는 확인했으니 가장 중요한 효율성에 대한 결과도 확인해보겠습니다.
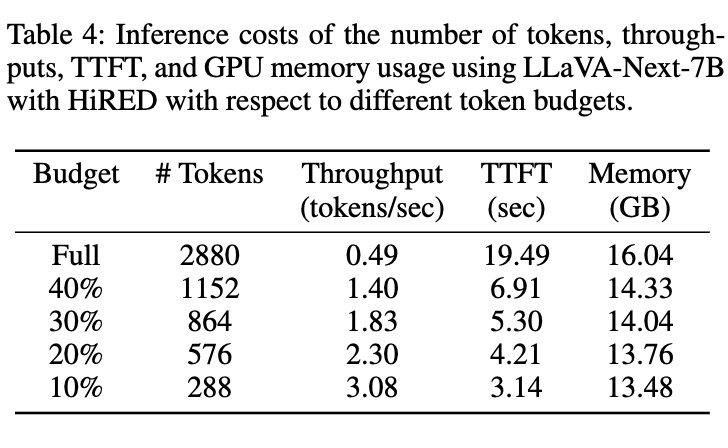
위의 table 4는 HIRED의 효율성을 확인할 수 있는데요 20% 토큰 예산만으로도, 전체 토큰을 사용했을 때보다 처리량(Throughput)은4.7배나 증가했고, 첫 토큰이 생성되기까지 걸리는 시간(TTFT)은 15초 가량 단축되었습니다. GPU 메모리도 2.3GB나 절약할 수 있었습니다.
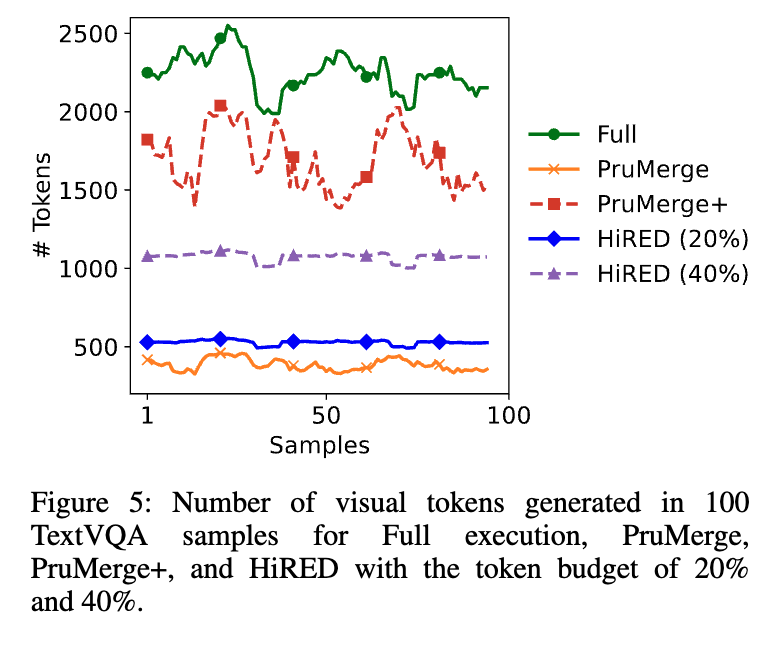
위는 샘플별 생성 토큰 수 비교하는 그림인데 HIRED는 정해진 예산(20% 또는 40%) 내에서 항상 일관된 수의 토큰을 사용하는 반면, PruMerge 계열은 이미지에 따라 사용하는 토큰 수가 크게 요동치는 모습을 보입니다. PruMerge 및 PruMerge+의 경우, 이미지를 더 많은 시각 정보가 포함될 때 더 많은 토큰을 adaptive하게 선택하는 특성 때문입니다.이렇게 되면 자원 사용량을 예측하기 어려워 배포 단계에서 안정적인 운용이 어렵다고 합니다. 그래서 HiRED는 배포 단계에서 엄격한 리소스 제약 환경 하에서도 예측이 가능하고 안정적인 운용이 가능합니다.
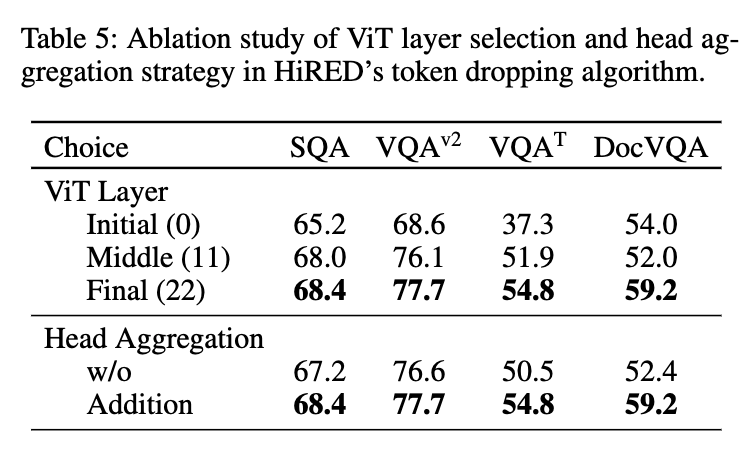
위는 ablation 스터디 입니다. table 5의 결과를 보면 초기나 중간 레이어보다 최종 레이어(22번)를 썼을 때 모든 태스크에서 정확도가 가장 높은 것을 확인할 수 있습니다. 결과적으로 저자들의 3번째 관찰이 맞았다는 것을 입증했다고 볼 수 있습니다.
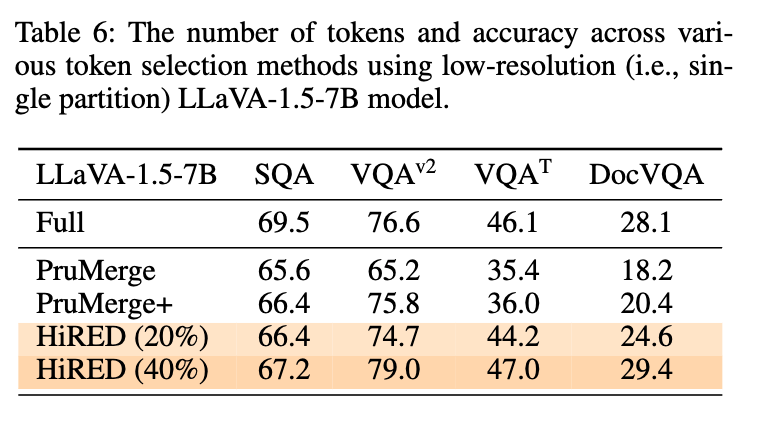
마지막으로 talble 6은 저해상도 모델(LLaVA-1.5-7B)에 HIRED의 토큰 선택 알고리즘만 단독으로 적용해본 결과입니다. 여기서도 20% 예산만으로 경쟁 모델보다 더 좋거나 비슷한 성능을 내는 것을 확인 할 수 있습니다.
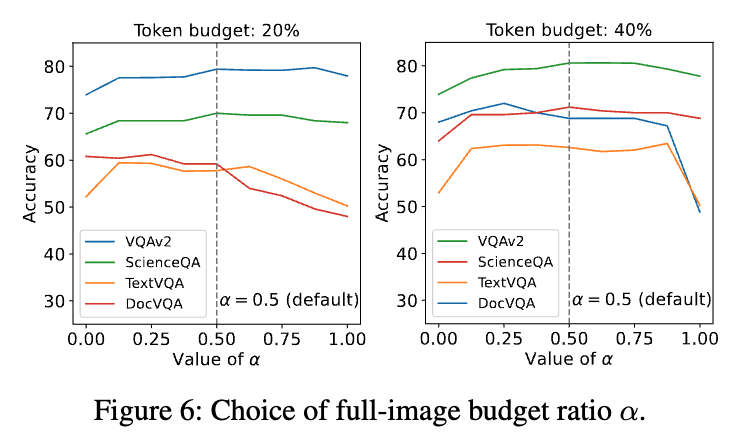
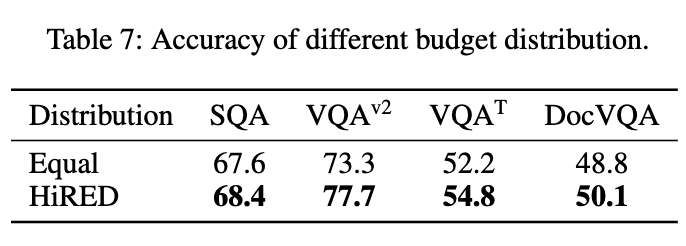
fig 6이랑 table 7같은 경우는 토큰 budget 분배 전략을 평가하는 실험입니다. fig 6 은 풀 이미지와 서브 이미지 간의 예산 비율(α)을 조절해본 결과인데, 어느 한쪽에 예산을 몰아주기보다는0.5로 균형을 맞췄을 때 전반적인 성능이 가장 안정적이고 좋았다고 합니다. table 7은 HIRED의 동적 예산 분배 방식이 그냥 모든 파티션에 예산을 똑같이 나눠주는 것(Equal)보다 얼마나 더 나은지를 보여줍니다. 10%라는 아주 빠듯한 예산 하에서도, HIRED의 다이나믹한 분배 방식이 더 높은 정확도를 보이는 것을 알 수 있습니다.
Conclusion
저는 이 논문을 읽고 pretrained된 ViT 모델의 내부 어텐션 맵을 다른 깊이에서의 특성을 분석하고 이를 토큰 프루닝에 활용했다는 점이 매우 직관적이면서도 좋은 접근이라고 생각했습니다. 지난번에 다루었던 ToSA가 다음 레이어의 어텐션 맵을 예측해서 토큰을 선택했다면, HIRED는 이미 존재하는 어텐션 맵을 콘텐츠 파악용(초기 레이어)과 특징 중요도용(마지막 레이어)으로 나누어 활용했다는 점에서 차별점이 느껴졌습니다.
근데 물론 이 방식이 ViT의 CLS 토큰 어텐션에 강하게 의존하기 때문에, CLS 토큰이 없는 다른 아키텍처나 다른 종류의 Vision Encoder에는 어떻게 적용할 수 있을지에 대한 고민은 필요해 보입니다.
이만 리뷰 마치도록 하겠습니다. 감사합니다.
안녕하세요 우현님 좋은리뷰 감사합니다.
읽기 쉬워서 흠 생각보다 드는 의문점들이 내용에 다 반영되어 있네요.
그리고 token pruning 에서 궁금했던건데 어느정도 반영되어 있었던 내용은 pruning을 하면 사실 성능이 드랍 될 거라고 일반적으로 추측하지만, 사실 불필요한 토큰을 제거하면 성능이 오르는 task들이 있을 수 있어서 성능 향상과 성능 감소가 둘다 반영되어 최종 score가 나올거라고 생각했습니다.
20% 40% token 만 사용헀을때 성능이 월등히 좋아서 리포팅한 것 같은데, 뭔가 다른 방법론의 55프로랑 같은 성능도 보여주거나 70 80 90 프로 토큰을 사용헀을때의 성능도 보여줬다면 분석할 점이 좀 더 생기지 않았을까 싶습니다.
더 많은 토큰을 사용했으면 어떤 경향성을 보였을지 생각해보신게 있을까요?
감사합니다.
안녕하세요 인택님 댓글 감사합니다.
20% 40% token 만 사용헀을때 성능이 월등히 좋아서 리포팅한 것일 수 도 있고 아닐 수도 있습니다. 프루닝을 하는 목적을 생각해보시면 성능만 보는 것이 아니니깐요. 그리고 개인적으로는 10%~90% 등등 모두실험 저자는 했었을 거라고 생각합니다. 성능과 효율성의 트레이드 오프 관계를 생각했을 때 그것들의 교점을 선택해서 리포팅을 한 것이 아닐까 생각을 합니다! 그리고 더 많은 토큰을 사용하면 성능을 올라가지만 효율은 떨어지지 않을까 생각합니다.
감사합니다.
안녕하세요 우현님 리뷰감사합니다.
마지막레이어의 어텐션 맵을 활용해서 중요한 토큰을 남기는 방식으로 이해를 했는데요
결국에는 cls토큰을 이용하고 pruning이 진행될건데 혹시 이를 다른 vision encoder에도
적용이 가능한가요?
안녕하세요 우진님 댓글 감사합니다.
일단 제가 우진님의 질문의 의도를 파악하지를 못하였는데 제가 이해한대로 최대한 답변 드리자면 해당 논문에서는 cls 토큰을 활용하지만 다른 태스크에서는 cls 토큰을 활용안 할 수 도있습니다. 그리고 토큰을 활용하는 ViT 기반 다른 vision encoder라면 적용이 당연히 가능합니다!
감사합니다.