이번에 소개드릴 논문은 2023 ICCV에 게재된 논문으로 애플에서 쓴 논문입니다. 원래는 애플에서 MobileCLIP2가 나왔다는 소식을 듣고 해당 논문을 읽으려고 했는데, 해당 논문에서 Reinforced training이라는 기법을 언급하여 지금 리뷰할 논문을 알게 되었습니다.
처음에는 Reinforced training이라 해서 뭐 강화학습의 한 종류인가 했는데 그런건 아니구요. 모델 학습에 사용되는 Dataset을 좀 보강한다? 향상시킨다? 이런 개념입니다.
Intro
일단 애플이나 퀄컴같은 회사에서 논문을 내면 보통 모델 경량화쪽이 상당히 많습니다. 그래서 모델을 직접적으로 경량화하는 것이 아니더라도 가벼운 모델의 성능 개선을 위한 여러 연구들을 많이 진행하는 편이죠.
이번 논문도 결이 조금 비슷하다고 저는 생각이 듭니다. 우선 본 논문에서는 이제는 한물이 갔다고 생각이 들지도 모르는 ImageNet에서의 성능 개선을 다룬 논문입니다. 이건 이제 CLIP과 같은 방법론들이 거대한 모델에 방대한 양의 데이터 때려넣고 스케일링하던 흐름에서 여전히 ImageNet 기반으로 실험하고 성능 평가하는 부분을 의식해서 언급한 내용인 것 같은데, 아무튼 저자들의 주장을 좀 정리해보면 작을 모델들에 대한 수요도 여전히 매우 중요하고, 또 데이터셋 규모가 작은 경우에는 새로운 데이터를 수집하고 어노테이션하는데 코스트도 많이 들고 해서 스케일 업하는 것이 여간 쉽지 않다 라고 합니다.
그래서 저자들은 무작정 모델의 크기를 키우고, 방대한 양의 데이터로 학습을 해서 성능을 개선시키는 방향성이 아닌 데이터의 수가 어쩔 수 없이 제한적인 경우에 그리고 모델의 사이즈도 크지 않은 상황에서도 모델의 성능을 개선시킬 수 있는 방향에 대해서도 중요하다는 주장을 하고 있습니다.
그래서 저자들이 해결하는 방향은 상대적으로 큰 모델들을 활용해서 새로운 모델을 학습시킬 때 그들의 지식을 활용해보자 라는 관점입니다. 이러면 이거 완전 Knowledge Distillation 아니야?라고 생각하실 수 있는데, 그건 아니고 저자들이 하고자 하는 것은 Dataset Reinforcement입니다.
이 개념이 좀 생소할 수 있는데 저도 이 논문 보기 전까지는 처음들어보는 개념이라서요. 그래서 저자들도 자신들이 주장하는 Dataset Reinforcement가 어떤 방법론과 결이 비슷한지에 대해서 소개를 간단하게 하는데, 저자는 크게 2가지 task를 언급합니다. 바로 Data augmentation과 Knowledge Distillation 입니다.
우선 Data augmentation에 대해서는 사실 크게 설명할 것도 없죠? 말그대로 데이터에 밝기나, 대조, colorjitter 등을 적용하거나 rotation, affine 등 기하학적인 변환을 적요할 수도 있고, Mixup이나 Cutmix같이 semantic한 부분들을 조정할 수도 있습니다. 그래서 이러한 data augmentation 방법론들은 5년전까지만 해도 많은 인기를 모은 연구 흐름 중 하나였으며 백본 모델을 학습시킬 때 많이 활용했었죠.
근데 저자들이 말하길, data augmentation 방법론들은 학습시키는 모델의 구조에 대한 일반화가 잘 안된다고 합니다. 가령 CNN은 Inception-style augmentation(random resized crop/ random horizontal flip 등등)에서 잘 동작하지만, ViT 계열은 이 standard 기법들 뿐만 아니라 한층 더 진보된 augmentation 방법론들을 선호한다고 하네요 (논문에서는 더 진보된 augmentation 방법론들이 뭔지 구체적으로 언급은 안되어있는데 뒤에 실험을 좀 살펴보니 RandAugmentation 등을 의미하는 듯 합니다).
또 다른 저자들과 결이 비슷한 연구로는 Knowledge Distillation 방식이 존재한다고 했었죠. Knowledge Distillation은 많이들 알고 계실테지만 성능이 더 좋은 teacher model의 knowledge를 성능이 상대적으로 떨어지는 student model에게 전이하는 개념입니다.
이러한 Knolwedge distllation은 이점은 명확하고 컨셉도 직관적이어서 여전히 많은 관심을 받고는 있지만 사실 해보신 분들은 아시다시피 이 Knolwedge distllation이 학습 비용이 제법 많이 들어갑니다. 이는 거대한 teacher 모델을 학습 iteration마다 매번 추론해야하기 때문이죠.
그리고 저자들이 생각하는 KD의 문제점 중 하나로 학습 코드에서 모델의 forward를 2번씩 진행해주어야 한다는 점에서 학습 코드 수정이 불가피하다는 부분이 있습니다. 이건 저는 딱히 이걸 왜 문제라고 생각하는지는 모르겠지만, 학습 코드를 수정해야한다는 점에서 번거롭고 단점이라고 이야기를 하더라구요. 즉 Teacher model을 학습시키는 코드가 있으면 거기서 원래 백본만 작은걸로 바꾸면 그게 student model이 되거든요. 근데 이제 KD를 적용하기 위해서는 Teacher model과 student model을 둘다 선언하고, 이들을 둘다 forward하고, loss function 추가로 계산하고 이런 코드 흐름으로 은근 짜잘하게 바꿔야할 내용들이 많다라는 거에요. 이런 것들이 KD의 단점 중 하나다라고 하는데 일단 그렇게 알고 넘어갑시다.
아무튼 이렇게 Data Augmentation과 KD에 대해서 알아보았는데, 저자들이 제안하는 Data Reinforcement는 이런 문제점들을 없애야만 하겠죠? 자신들의 data reinforecement는 Knolwedge distllation과 dataaugmentation의 이점을 모두 활용하면서 동시에 KD의 학습 overhead 단점은 없애버렸다고 합니다.
그래서 학습 때는 그냥 student model만 forward 태워서 학습시키면 되는지라 학습 속도에도 teacher model로 인한 느려지는 현상이 딱히 없고, 코드 변경도 그냥 자신들의 강화된 학습 데이터를 읽어오는 dataloader만 있으면 돼서 코드 수정도 크게 바꿀 부분이 없다고 하더라구요. 결과적으로 저자들의 기법을 ImageNet에 적용시켜 만든 ImageNet+는 기존 ImageNet과 동일한 학습 이터레이션 수를 가졌음에도 다양한 모델에서 성능 향상을 보여줄 수 있었다고 합니다.
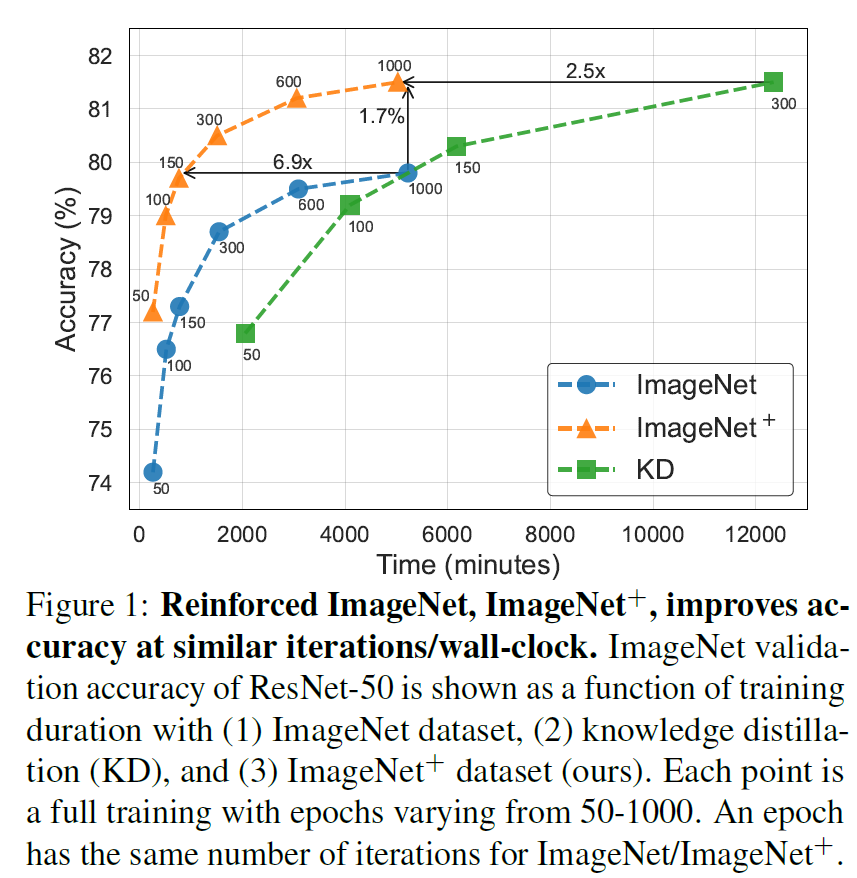
실제로 그림1의 결과 보시면 ResNet50에 대해서 ImageNet보다 자신들의 기법을 통해 향상된 ImageNet+로 학습시킬 경우 1.7% 이상의 성능 향상을 보였다는 점이고, 기존 ImageNet과 동일한 학습 성능에 달성할 때 무려 7배 더 적은 학습 시간으로 도달할 수 있었다는 겁니다. 그리고 기존의 Knowledge Distillation 방법론과 비교해서도 비슷한 성능 대비 2.5배 더 빠른 학습 시간을 가졌다라는 점에서 좋다고 하네요.
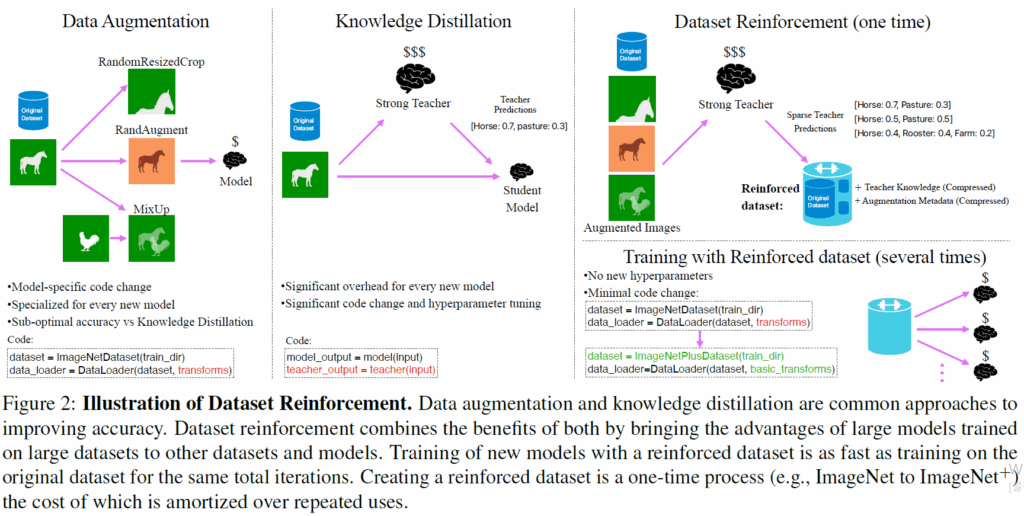
위에 Intro 소개드린 Data augmentation, Knoweldge Distillation, 그리고 저자들이 제안하는 Dataset Reinforcement에 대한 차별점? workflow?에 대한 그림입니다. 앞에서 Data Augmentation Knowledge Distillation에 대해서는 장단을 설명드렸으니 저자들의 Dataset Reinforcement에 대해서만 더 간략하게 소개드리면, 결국 저자들은 Teacher model을 사용하긴 해요. 근데 이제 여러개의 Teacher model한테 다양한 augmentation 영상을 보여주어서 그 정답값을 앙상블해 저장해둡니다.
그리고 실제 augmentation image에 대한 메타데이터도 같이 저장을 해요. 그리고나서 실제 student model을 학습시킬 때는 앞서 구해놓은 teacher model들의 soft label 값을 같이 불러와 KD를 수행한다고 하네요. 사실 이 부분만 보면 그냥 output level에서 knowledge distillation 한거 아닌가? 라는 생각이 드는데 이게 teacher model의 output들을 뽑을 때 data augmentation을 정말 다양하게 한다 라는 점 그리고 이 방식이 online이 아니라 offline으로 딱 한번만 진행하여 학습 때 드는 비용을 최소화하였다는 점? 이런 것들이 기존과는 조금 다르다는 점 같아요.
What is good teacher?
dataset reinforcement 과정에 대해서 사실 방금 다 설명드리긴 했는데 방법은 간단하지만 저자들이 이렇게 설계를 하게 되기까지 실험을 정말 다양하게 하고 해당 결과들을 통해 여러 통찰들을 제공을 합니다. 이 부분들이 해당 논문에서 가장 중요하다고 보여서요 지금부터 다룰 내용은 저자들이 어떤 실험을 했고, 어떤 결과를 도출했는지를 살펴보려고 합니다.
우선 저자들의 Dataset Reinforcement 과정은 사전에 학습된 strong teacher에게 다양한 augmentation을 보여주고 이에 대한 output값을 저장해서 student model 학습 시 dataloader에 같이 불러와 활용한다고 말씀드렸습니다.
그러니 결국 좋은 teacher model을 선정해서 student model 학습에 좋은 output을 만들어내는 것이 가장 중요하다고 볼 수 있습니다. 그럼 좋은 teacher model이란 무엇일까요? 종종 teacher model을 선정할 때는 이용가능한 사전학습된 모델들 중 가장 높은 성능의 모델을 선정하는 경우가 흔합니다. 하지만 몇몇 논문들에서 밝히길 가장 모델의 성능이 정확하다고 해서 이게 student에게 knowledge distillation 했을 때도 가장 좋은 teacher이다 라고 단정할 수는 없다고 합니다.
그래서 저자들도 일단 좋은 teacher가 무엇인지를 찾기 위해 knowledge distillation에 대한 실험을 진행합니다. 실험 세팅에 대해서 구체적으로 말씀을 드리면 우선 student model로는 크게 3가지 MobileNetv3, Resnet-50, ViT-small을 활용했습니다. 이들은 각각 Light-weight CNN, Heavy-weight CNN, Transformer를 대표한다고 보시면 되겠네요.
그리고 Knowledge Distillation을 위한 Teacher 모델들도 다양하게 가져왔는데, ResNet, EfficientNet NS, Swin Transformer, DeiT, IG ResNext, ConvNext 계열들을 가져왔습니다. 여기서 계열이라고 표현한 것은 해당 모델들의 family를 언급을 하는데 즉 ResNet 계열이다 하면 Resnet 34-50-101-152 를 의미하는 것이고, Swin-Transformer 계열이면 Swin-Tiny, small, base, large를 의미하는 것입니다.
이 teacher model들이 무슨 데이터셋으로 사전학습 되었는지에 대해서는 아래 논문의 본 글을 읽으시면 감사하겠습니다.

자 이렇게 사전학습된 Teacher model들의 knowledge를 가지고 student model들을 ImageNet에서 학습시켜서 평가해본 결과가 아래 그림3과 같습니다.
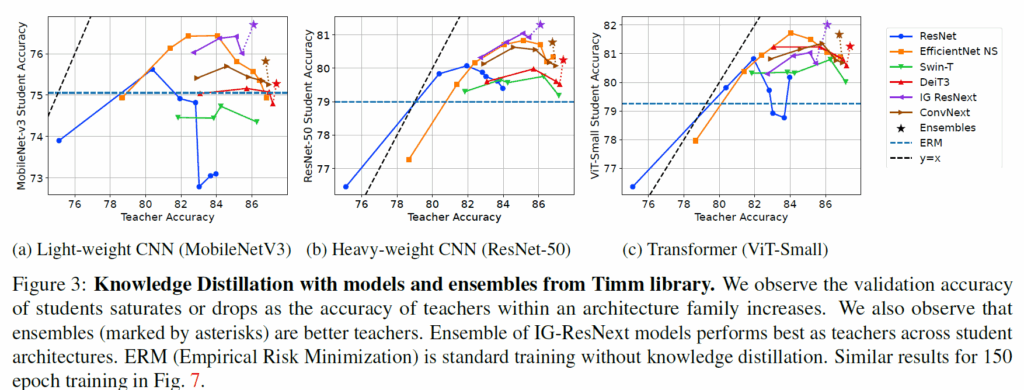
y축은 student model의 정확도를 의미하고, x축은 teacher model들의 정확도를 의미합니다. 일단 눈여겨 보실 점 중 하나는 아까 이야기했듯이 Teacher model의 정확도가 아무리 높다고 해서 distillation 되는 student model의 성능도 같이 linear하게 좋아지는 것이 아니다라는 점입니다.
즉 중간 사이즈 크기의 모델들까지는 teacher model의 성능이 오를수록 student model의 성능도 같이 오르긴 하는데, 그 이상 크기로 가버리면 student가 일정 성능에서 saturation되거나 혹은 drop이 발생하는 것이죠.
그리고 저 그래프 잘 살펴보시면 별 모양이 하나 있어요. 이 별모양이 뭐냐면 해당 계열들의 모델들 output을 앙상블한 것을 의미합니다. 즉 별모양 쳐진 부분이 IG-RexNext, ConvNext, DeiT 등 CNN과 Transformer 모델들의 family들 4개 정도를 모아서 결과값을 앙상블해서 distillation 했을 때의 성능인데 이 경우에는 student model의 성능 향상이 유의미하게 있었다고 하네요.
특히 저자들은 IG-ResNext 계열이 앙상블 했을 때 student model이 CNN이든 Transformer이든, Light하든 Heavy하든 상관없이 distillation 했을 때 가장 좋은 성능을 보여주더라 라는 점에서 IG-ResNeXt 계열을 dataset reinforcement를 위한 teacher model로 채택합니다.
ImageNet+: What is the best combination of reinforcements?
자 그러면 좋은 teacher model은 일단 다양한 크기의 계열들의 앙상블이더라 라는 것은 알게 되었구요. 그 다음은 이제 reinforcements를 하기 위한 dataset의 combination은 무엇인지 그 조합을 찾아야만 합니다. 즉 Data augmentation을 어떻게 해서 teacher 한테 주어야만 student model 학습에 도움이 되는 soft-label을 뱉어내는 것이냐 라는 것이죠.
우선 위에서 말씀드렸다시피 저자들은 앙상블 모델로 IG-ResNext 계열들을 사용했습니다. 그리고 학습 샘플 당 400개의 augmentation 적용한 다음 해당 샘플들에 대한 teacher model의 top10에 해당하는 확률값을 저장합니다. 고려 대상으로 사용된 augmentation은 다음과 같습니다.
- Random-Resize-Crop (RRC)
- MixUp & CutMix (Mixing)
- RandomAugment & RandomErase(RA/RE)
- combine mixing RA & RE (M*+R*)
일단 1번은 말 그대로 무작위로 영상 내 영역을 crop해서 해상도를 학습 사이즈에 맞게 resize한다는 것이고, 2번의 Mixup과 CutMix는 모르시는 분들이 혹시 있을까봐 각각이 어떤 이미지 합성 기법인지 아래 그림에서 보여드립니다. (가운데 Cutout이라는 기법도 예전이 나온 방법론인데 해당 논문에서는 사용하지는 않았다는 점 참고)

그리고 RandAugment는 2019년에 게재된 논문에서 나온 기법인데 진짜 말그대로 온갖 종류의 augmentation을 랜덤하게 다 적용하는거에요. 그래서 한장에 이미지 샘플에 대해서도 정말 다양한 생김새로 데이터 증강이 되는데 해당 예시는 19년도 논문의 예시로 보여드리겠습니다.

해당 논문에서 수도코드도 제공되어있는데, 아래 보시면 그냥 아 정말 다양하게 적용한다는 거구나 라는 것을 확인하실 수 있습니다.

그리고 위에는 Random Erase의 예시입니다.
제가 4번에 표기한 M*+R*는 하나의 영상에 RandomAug와 Random Erase를 모두 적용한다는 의미로, 이게 적용된 샘플 이미지는 상당히 이해하는데 어렵겠구나 라고 생각하시면 될 것 같습니다.

저자들의 ImageNet+를 구성하는 세팅은 위에 테이블을 통해서 확인할 수 있습니다. 일단 4개의 앙상블 모델에 대해서 10개의 output 확률값을 저장한다는 점에서 총 38기가 용량을 차지하고 있는 모습이고, 또 augmentation에 사용된 이미지 자체를 저장하는 것은 많은 용량을 차지하기 때문에 저자들이 augmentation을 수행했을 때 사용된 파라미터들 (즉 좌표값 또는 세기, 이미지 id 등등)을 저장했더니 그것들이 각 augmentation 조합마다 8기가, 15기가 13기가 등을 차지한다는 내용입니다.
저자들은 모델 학습으로 MobileNet, ResNet과 EfficientNet, ViT와 Swin Transformer에 대해 평가하며, 기존 연구들이 사용하는 learning recipe을 그대로 사용하고 그 어떠한 하이퍼파라미터 튜닝은 하지 않았다고 합니다. 즉 기존 오리지널 이미지넷으로 학습했을 때와 차별점이 자신들이 제안하는 ImageNet+만 바뀌었다는 것이죠.
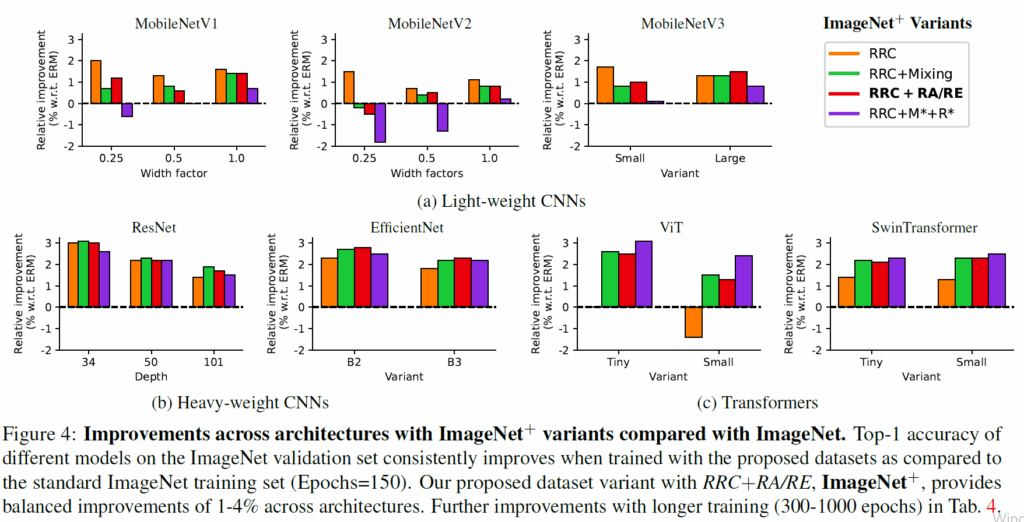
augmentation 조합에 따른 실험 결과는 다음과 같습니다. 우선 mobileNet 계열의 가벼운 CNN 방법론들은 어려운 reinforcement(즉 data augmentation이 복잡해지는 경우)에서는 성능 향상 이점을 보지 못하는 모습입니다. 저자들은 그 이유를 해당 모델들의 제한된 캐파시티 때문이라고 가정하고 있습니다.
반면에 상대적으로 무거운 CNN들과 ViT 계열들은 RRC+Mixing, RRC+RA/RE, RRC+M+R 등 어려운 reinforcement에서 성능 이점을 보는 모습입니다. 재밌는 점은 transformer 계열 모델들은 가장 어려운 reinforcement (RRC + M* + R*)에서 가장 좋은 성능을 보여주고 있는데, 이에 대하여 저자들은 transformer 계열 방법론들이 CNN과 비교해 inductive bias가 없다보니 data regularization에 더 많은 이점을 보는 것이 아닌가 라는 결론을 내리는 모습입니다.
아무튼 저자들은 RRC+RA/RE 조합이 모델의 크기와 종류 및 이들의 성능 향상 지점을 봤을 때 가장 적합한 reinforcement 방식이라고 생각하고 이를 ImageNet에 적용한 것을 ImageNet+라고 명칭하였습니다.
이러한 ImageNet에서의 ablation study를 통해 dataset을 refinement하는데 있어 저자들은 다음과 같은 가이드라인을 제공합니다.
1) 방대하고 다양한 데이터로 학습된 strong teacher의 앙상블을 활용할 것. 2) 모델의 복잡성과 reinforcement의 어려움 사이의 밸런스를 조정할 것.
저자들은 CIFAR-100, Flowers-102, Food-101에 대해서 자신들의 ImageNet+로 사전학습된 Resnet-152를 가지고 reinforcement를 추가로 진행합니다. 저자들은 ImageNet과 동일하게 RRC+RA/Re로 reinforcement를 수행하였다고 하네요. Student model은 MobileNetV3-Large였으며 최종 결과는 다음과 같습니다.
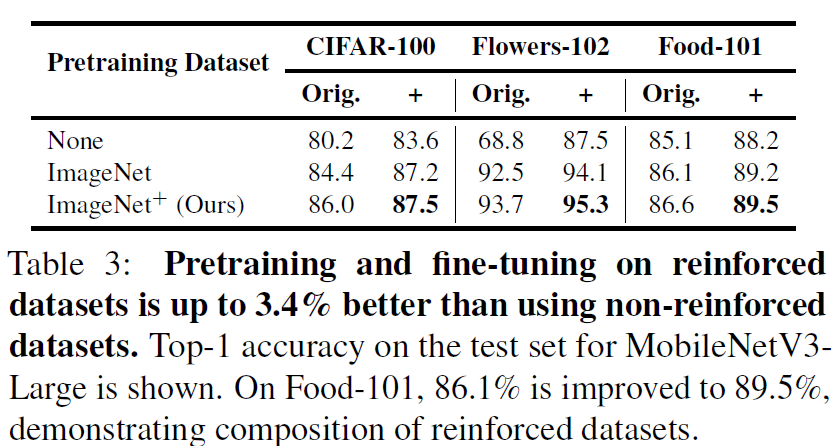
일단 실험 결과를 살펴보면 Pretraining Dataset에 None, ImageNet, ImageNet+로 표기가 되어있는데 이는 각각 Student model이 scratch level로 학습하는지, 또는 ImageNet으로 사전학습이 된 것인지 그리고 저자들이 제안한 ImageNet+로 사전학습된 모델인지에 대한 실험 세팅을 의미합니다.
그리고 CIFAR, FLowers, Food 각각의 데이터셋 열 안에는 Orig와 +가 표기되어있는데 Orig는 말그대로 기존 데이터셋을 의미하고 +는 저자들의 기법을 통해 해당 target dataset을 reinforcement한 것을 의미합니다. 결과적으로 reinforcement된 데이터셋으로 사전학습해서 target data도 reinforcement로 학습하는 경우가 가장 좋은 성능을 보여주더라 라는 점이고, pretraining과 fine-tuning 과정 둘 중 하나만이라도 자신들의 data reinforcement가 적용이 되면 큰 성능 향상을 볼 수 있다 라는 점이 있네요.
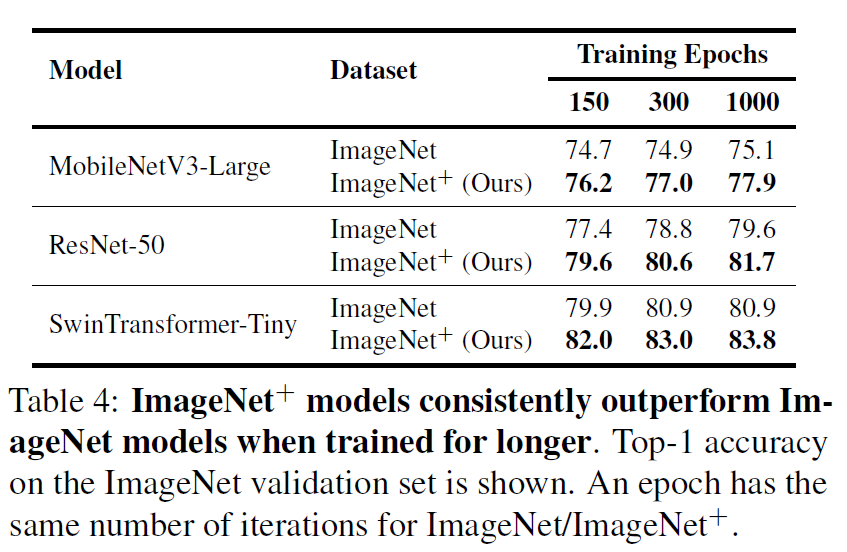
다음 실험은 저자들의 dataset reinforcement가 MobileNet 같은 light-weight이든 ResNet같이 Heavy-weight이든 Swin Transformer같은 ViT 계열이든 상관없이 다 성능 향상을 보인다라는 결과를 보여줍니다.
이 표4번에서 저자들이 강조하는 것은 자신들의 data reinforcement가 student model 자체를 학습 시킬 때 드는 비용이 거의 없다라는 점입니다. 구체적으로 MobileNetV3-Large와 ResNet-50, Swin-Tiny model에 대해서 각각 기존 original imageNet으로 학습했을 때 대비 1.12x, 1.01x, 0.99x배의 학습 시간이 소모되었다는 점이며, 여기서 MobileNet은 왜 학습 시간이 1.12배 더 늘었냐 한다면 original ImageNet으로 학습시킬 때는 어떠한 data augmentation도 적용하지 않았기 때문에 늘어났다고 하네요.
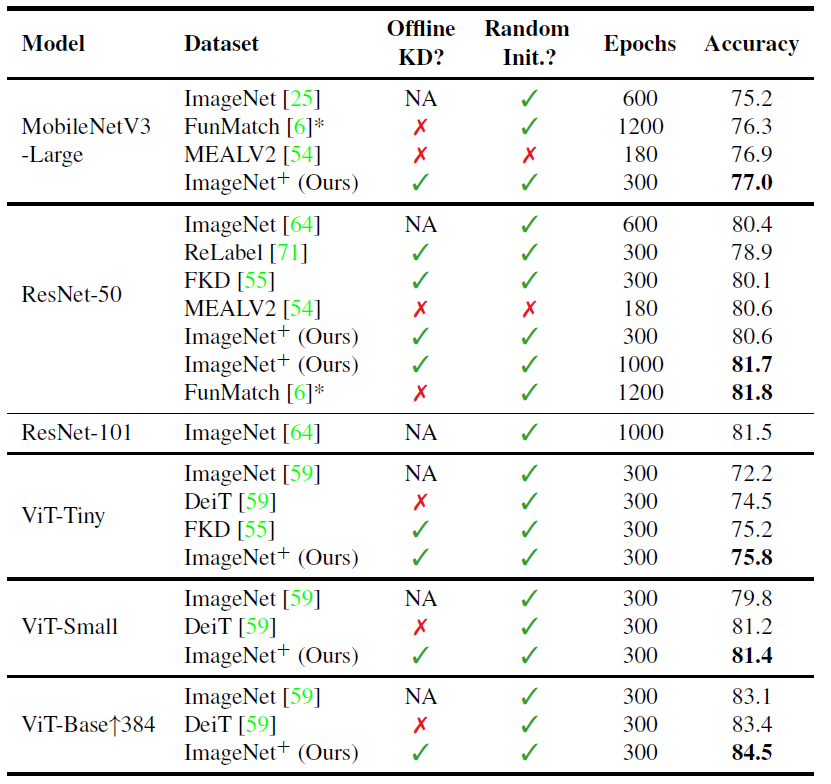
다음은 다른 방법론들과의 ImageNet에서의 비교 실험 결과입니다. 해당표에서 봐야될 주요 부분들은 다음과 같습니다.
- ImageNet+로 학습된 동일 family의 small model들이 ImageNet으로 학습된 large model들과 유사한 성능을 보여준다는 점. ImageNet+ Resnet50 (81.7) vs ImageNet Resnet101(81.5)
- 자신들과 결이 비슷한 FKD (즉 offline KD를 통해 학습 때 드는 비용을 최소화하는 것)와 비교해서 자신들의 방법론이 더 좋은 성능을 보여준다는 점.
- online distillation 방법론들과 유사한 성능을 보여주지만 더 적은 epoch와 훨씬 빠른 학습 속도를 가진다는 점.
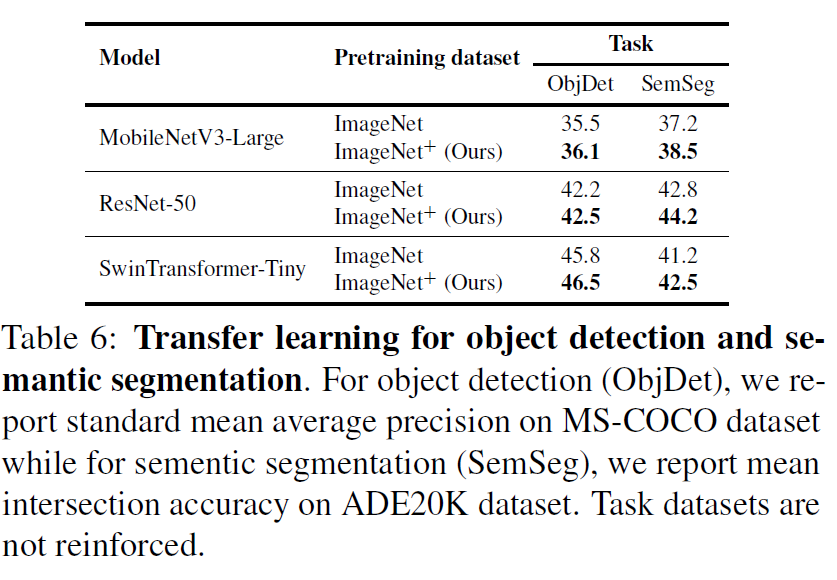
그리고 어찌보면 좀 당연할 수도 있긴한데, 자신들의 reinforced dataset으로 사전학습된 모델이 Object Detection이나 Semantic Segmentation과 같은 downstream task로 fine-tuning할 경우 성능이 더 오른다고 합니다.
결론
일단 Dataset reinforcement라는 개념을 거의 처음 제안한 것 같아서 흥미롭게 읽었던 논문입니다. 그리고 저자들의 소속도 애플이라는 점에서 신뢰성이 많이 올라가긴 했구요(물론 애플이 요즘 AI쪽으로 부진하곤 있지만 한번씩 나오는 논문들의 퀄은 좋다고 생각합니다).
근데 이정도면 파급력이 있을 것 같다 생각했는데 생각보다 논문 인용수가 상당히 적었어요. 지금 시각 기준으로 15회밖에 인용이 안되었길래 뭔가 하자가 있나 라는 생각을 했는데 supplementary 쪽을 좀 살펴보니깐 그 이유를 알겠더라구요.

대충 ImageNet+를 만드는데 A100 64개를 병렬로 돌려서 2080분 걸린다고 하네요. 시간으로 환산하면 34시간 걸린다는 건데 문제는 A100 64개가 문제죠. 이걸 하나의 A100으로 돌린다고 했을 때 대략 2219시간 정도 걸리고 이는 92일 정도더라구요ㅎㅎ..
그래서 아무도 이쪽 연구를 활용하거나 개선해볼려고 안한 것 같다는 생각이 들었습니다. 물론 prediction 값을 앙상블로 뽑아야해서 시간이 많이 걸리는 것 같고, 또 사실 이 작업을 딱 한번만 하면 되거든요? 즉 데이터셋이 바뀌지 않는 이상 딱 한번만 dataset reinforcement를 진행해놓으면 이제 student model을 학습시킬 때는 어떤 모델을 학습시키더라도 데이터셋 읽어오듯이 large model들의 knowledge를 가져올 수 있는 것이죠.
매번 다른 구조의 student model을 설계해 학습할 때마다 teacher model들을 같이 forward해야하는 것에 비하면 제가 생각했을 때도 상당히 비용효율적이라고 볼 수 있겠다 라는 생각이 들긴 하네요 유지 보수 관점에서. 근데 논문을 써야하는 관점에서는 학교 레벨에서 적용하기 쉽지 않겠다 라는 생각이 같이 들고 그래서 인용 수가 적었던 것이 아닐까 추측해봅니다.
아무튼 이런 dataset refinement를 단발성으로 연구하고 애플이 버린 것 같지는 않구요. 최근에 나온 MobileCLIP2를 학습할 때에도 이러한 컨셉을 multi-modal로 확장해서 적용해보려고 한 것 같더라구요. 저도 아직 mobileCLIP2 논문을 읽지 않아서 모르겠지만 아무튼 흥미로운 주제의 논문이었던 것 같습니다.
안녕하세요 정민님. 좋은 논문 리뷰 감사합니다.
단순한 알고리즘적 augmentation을 넘어, teacher model의 ensemble로 reinforcement하는 방식이 신기했습니다.
“transformer 계열 방법론들이 CNN과 비교해 inductive bias가 없다보니 data regularization에 더 많은 이점을 보는 것이 아닌가 라는 결론”이라고 본문에서 얘기하였고, 실제로 CNN은 그래프 상에서 성능이 일부 하락한 지표까지 확인할 수 있었습니다.
그런데 inductive bias가 없는게 왜 data regularization에서 더 이점을 얻는지 이해가 되지 않아 질문드립니다. 제가 생각하기로는 단순히 augmenation 과정에서 random erase 같은 방법은 locality를 훼손하기 때문에, 오히려 inductive bias를 가지는 CNN계열 방법론이 성능이 하락했다라고 생각하는게 맞을까요?
안녕하세요 정민님 리뷰 잘 읽었습니다
연산량을 제외하고 좋은 아이디어 같은데요,
reinforceement dataset으로 학습하는 경우 이미지 분류 방식으로 학습하는걸로 이해했습니다.
그렇다면 유니버셜 인코더와 같이 이미지 통합 인코더를 하나 상정하고, 해당 featuer에 augmentation (예를 들어 feature에 feature mixing)을 적용하는 방식으로 reinforceement dataset을 구축해놓으면 연산량이 조금은 줄어들것같은데, 이러한 방식은 적용이 어려울까요?
감사합니다