안녕하세요. CoRL 2025 Oral, Planning & Safety & Robustness 세션에서 발표될 논문이라고 하여 관심을 가지고 읽어보게 되었습니다. 해당 세션에 유독 oral paper가 적었는데요. 이 논문은 특히 planning 태스크 중 multi-obejct rearrangement 라는 manipulation planning task에 맞춰, 기존의 방법론들이 symbolic한 제약조건들을 기반으로 연속적인 행동을 이산화시켜 planning하던 것을, 연속적으로 planning하게 만든 방법론입니다. 특히 point cloud 인풋 기반으로 관측 내의 다음 장면에서 움직일 가능성이 있는 object의 movable probability를 예측하고, 현재 장면과 특정 object를 기준으로 다음 장면의 action이란 것을 object point cloud에 대한 연속적인 transformation 변환으로 정의하고 이를 샘플링해서 특정 위치로의 배치를 제안하는 방식입니다. 즉 객체를 다음 장면의 어디에 둘 수 있는 지에 대한 예측까지 진행하고, 이를 토대로 연속적인 planning과 execution을 가능하게 한다는 컨셉입니다. 기존에 제가 알던 LLM 기반 planning과 달리 뭔가 전통 로보틱스 관점에서의 문제정의 접근이 들어간 것 같아서, 본 논문의 contribution이 옛날 방법론 대비 잘 와닿지 않아서 그 역사를 따라가는 데 시간을 좀 투자하느라, 논리나 방법론 설명 등에서 와닿지 않는 표현이나 다소 미약한 점이 있을 것 같습니다. 이해 안되는 부분 댓글 남겨주시면 감사하겠습니다.

Introduction
로봇이 여러 물체를 재배치하는 long-horizon manipulation task에서는 3D 물리 환경에 대한 이해와 연속된 액션 시퀀스의 결과에 대한 추론이 필요합니다. 예를 들어, 식탁 위의 그릇, 접시, 컵 등을 정리하는 table bussing이라는 태스크에서는 단순히 접시를 올려놓기 전에 위에 올려져있던 컵이나 그릇을 먼저 치워야한다는 순서를 지켜야합니다. 또 선반에 물건을 차곡차곡 쌓는 경우처럼, 공간 제약이 있을 때는 각 물체의 정확한 배치가 전체 성공 여부를 결정하게 됩니다. 결국 이 모든 것들을 잘하려면 high-level 단에서 먼저 로봇의 planning부터가 잘 되어야하고 중요하고 필수적인 문제가 됩니다.
이런 high-level planning에 관한 논문들을 저는 주로 리뷰를 해왔었는데요. code as policies나 voxposer, moka, copa 등등 주로 LLM의 자체 reasoning에 의존한 code generation이나 planning 기반의 그런 high-level planning 방법론들을 쭉 보다가 이 논문을 보니, 이 Long-horizon manipulation task 의 역사를 TAMP(Task and Motion Planning) 문제와 이를 풀기 위한 Symbolic planning이라는 방법론의 역사로 소개를 해나가는 것 같았습니다. 그동안 제가 LLM 기반의 논문들을 리뷰하면서는 이런 것들이 크게 언급이 되진 않았거나 좀 짧게 생략하고 넘어갔던 것 같구요. 원래 전통 로보틱스 분야에서는 이 역사를 introduction이나 related work에서 꽤나 중요하게 다루고 있었던 것 같습니다. TAMP의 문제정의는 본 논문에서는 소개가 없었지만 뭔지 짧게 다루면, 고수준의 순서(작업, symbolic) 결정과 저수준의 연속적 궤적/운동(motion)의 실현 가능성(kinematics, collision, dynamics, 시간 제약 등)을 동시에/연계하여 해결하는 문제라서 planning 태스크의 오랜 역사 중 뼈대가 됩니다. 그리고 Symbolic planning이라는 태스크는 오래전(2007년~2013년 정도)에 연구된 long-horizon manipulation 태스크를 풀기 위해 제안된 고전적 방법론으로, 물체, 관계, 행동, 전제조건, 후속조건 등등을 기호 즉 symbolic으로 정의하는 planning 방법론입니다. 하지만 실제환경에서는 scene 내의 상태와 동역학적 요소에 대한 완전한 정보나 지식을 얻기 어렵고, 태스크별로 매번 사람의 annotation이나 ontology에 대한 정의가 필요해지게 됩니다. 따라서 실제환경의 open-set 상황에서는 문제에 대응하기가 매우 어려워집니다.
본 논문에서는 SPOT(Search over Point cloud Object Transformations)이라는 새로운 방법론을 제안하는데, 고차원 continuous action space에서의 searching 과정을 guide하기 위해 domain-specific하게 사전학습된 모델을 활용하는 하이브리드 학습 및 planning 방식입니다. 구체적으로는 partially-observed point를 인풋으로 받는 사전학습된 suggester 모듈(작업 가능 object나 action에 대한 suggestion을 주는 모듈)로부터 planning에서 후보가 되는 action을 샘플링하여 행동 또는 객체 관계를 이산화할 필요성을 제거한다는 것에 옛날 방법론에 비해 contribution을 두는 것 같았습니다. (근데 꽤나 오래전 연구들인 symbolic planning이란 태스크를 끌고 와서 기존 한계를 비교한 것이 대체 얼마나 큰 의미가 있었던 건지는 잘 모르겠네요.)
저자들은 다중 객체 재배치를 순차적인 부분 점군 재배치 문제로 공식화하고, 목표를 만족하는 구성이 발견될 때까지 장면의 객체 수준 공간 변환을 계획하기 위해 A* 탐색을 사용합니다. 연속 상태-행동 전이 상에서의 탐색을 효율적으로 유도하기 위해 SPOT은 두 가지 학습된 구성 요소인 object suggester와 placement suggester를 활용합니다. object suggester는 현재 장면에서 어떤 객체가 실행 가능하게 이동될 수 있는지를 예측하고, placement suggester는 선택된 객체가 주어졌을 때 모션 플래닝을 통해 실행 가능한 잠재적 변환을 샘플링하는 역할을 합니다. 이 두 suggester는 “어떤 객체를 움직여야 하는가?”와 “그 객체를 어디에 두어야 하는가?”라는 두 가지 high-level 질문에 답함으로써 A* search에서의 노드 확장을 이끕니다.
또한 학습된 모델 편차 추정기(Model-Deviation Estimator, MDE)는 예상 상태와 실제 상태 사이의 편차를 추정하여, 가능성이 낮은 transition을 억제합니다. 여기서 MDE는 주어진 transition model(scene 내 변화를 예측하는 모델)이 현실의 point cloud와 비교했을 때 얼마나 deviation, 즉 오차가 발생할지를 예측하는 추정기입니다. 이를 통해 특정 action이나 transformation을 수행했을 때, 예측된 state가 실제 상태와 많이 달라질 가능성이 있는지 판단할 수 있게 됩니다. 즉, MDE는 예측 모델의 신뢰도 또는 불확실성(uncertainty)을 사전에 측정하여, search 나 planning 과정에서 덜 신뢰할 수 있는 transition(state 전이)들을 억제하거나 피하도록 돕는 역할을 합니다.
이러한 모듈들을 결합하여, SPOT은 point 관찰로부터 직접 복잡한 작업을 해결하는 search 기반 planning을 가능하게 하며, 작업 온톨로지를 수동으로 정의하거나 시뮬레이터 특화 지식에 의존할 필요를 제거합니다.
contribution은 다음과 같습니다:
- 이산화 없이 재배치 작업을 해결하기 위한 새로운 패러다임을 제시, 즉 raw 3D observation의 3D transformation을 A*로 planning하는 방법을 도입.
- A* search에서의 노드 확장을 돕기 위해 video demonstration으로부터 object suggestor와 3D relative placement suggestor를 학습.
- 여러 실제 및 시뮬레이션 작업에서의 포괄적인 실험을 통해, 제안한 하이브리드 planning-learning 접근법이 다중 객체 재배치 작업을 해결하는 데 효과적임을 입증.
Problem Statement and Assumptions
해당 문제의 목표는 주어진 goal을 달성하기 위해 object pose를 재구성하는 일련의 과정을 찾는 것으로 정의합니다.
먼저 observation S \subseteq \mathbb{R}^{n \times 3} 은 scene 내에서 partially observed 3d point cloud인 o \in S 로써 정의하고, 이는 곧 M개의 객체 집합 X = { x_1, x_2, \ldots, x_M } 으로 segmentation 한다고 합니다. 이 땐 SAM2와 Grounding DINO, Grounded SAM을 결합한 방식으로 각 point에 semantic class를 할당하게 되고, object pose와 같은 어떠한 gt 정보도 쓰지 않았다고 합니다.
저자들이 정의한 action space는 object-centric하고 continuous한데, 하나의 action은 객체 x에 대한 SE(3) 변환인 T \in \mathbb{R}^{4 \times 4}, 저희가 아는 R,t 변환을 적용하는 것으로 정의합니다. 즉 x의 point cloud에 T를 적용하는 것으로 시각화할 수 있는데, 이 때문에 시점 t에서의 action a_t 는 객체와 변환 T의 쌍으로 정의되고, a_t = \langle x_t, T_t \rangle 이렇게 정의할 수 있다고 합니다.
그리고 task는 scene 내 point cloud가 goal condition을 만족할 때 완료되는데, o \in S 에 대해 작동하는 goal function G : S \mapsto {0, 1} 에 접근할 수 있다고 가정하면, 여기서 G(o) = 1 이면 해당 point cloud가 goal condition을 만족한다는 것을 의미합니다.
초기 segmented point cloud o_1 이 주어졌을 때, 저자들의 목표는 실행 시 최종 point cloud o_T 에 도달하여 G(o_T) = 1 을 만족하게 하는 plan인 P = (a_1, a_2, \ldots, a_{T-1}) 을 계산하는 것이 목표라고 합니다.
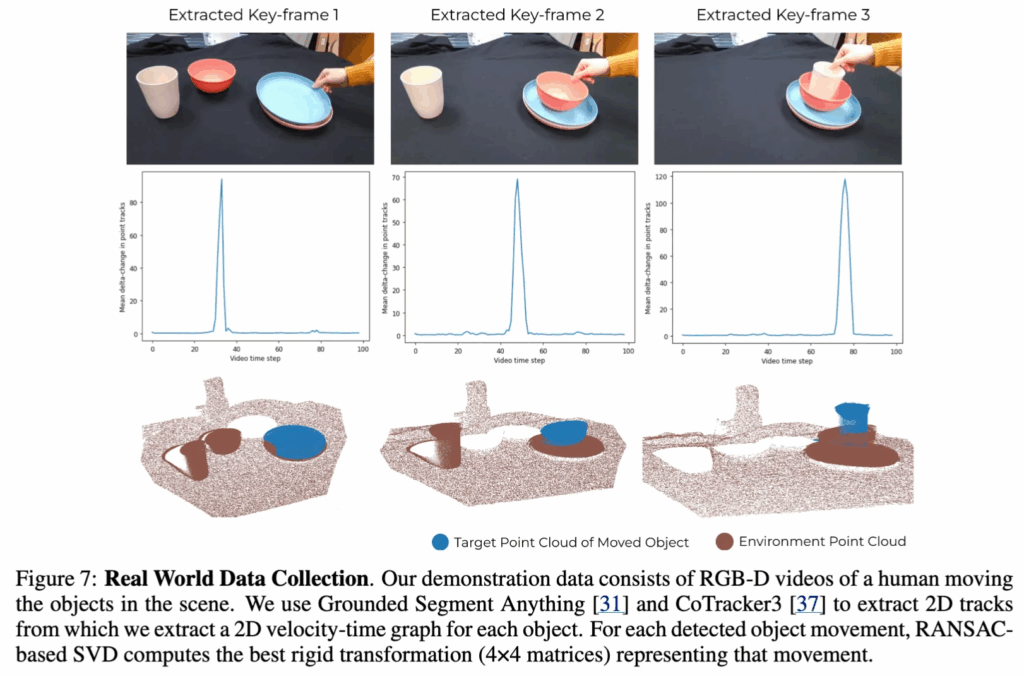
또한 위의 figure 7처럼, domain-specific point cloud transition들로 이루어진 제한된 demonstration dataset인 D = \{ o_i, a_i, o_{i+1} \}_{i=1}^{N_D} 에 사용하는 전제를 깝니다. 이 때의 데이터는 사람이 찍은 RGB‑D 비디오에서 뽑은 domain-specific 데모 데이터라는 전제가 있지만, 그 데이터들이 반드시 저자들이 풀고자 하는 특정 goal에 맞춘 task-specific 데이터는 아니라고 부연 설명합니다.
SPOT: Search over Point Cloud Object Transformations
저자들이 새롭게 제안하는 SPOT 방법론은 A* 탐색과 3D 상대 배치 예측을 통합하여 연속적인 상태와 행동 공간에서 계획을 수행합니다.
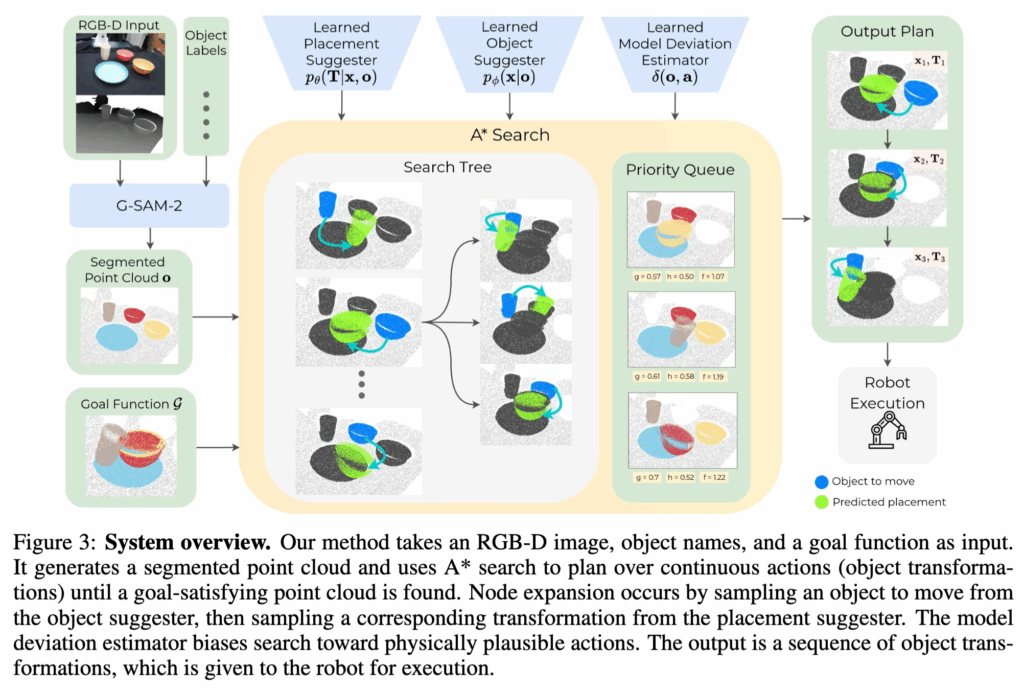
위의 figure 3 왼편에서 G-SAM-2 즉 VFM을 타고 나온 상태로 segmented된 initial point cloud obs인 o_1과 goal 함수인 G가 주어졌을 때, 해당 파이프라인의 최종 목표인 output plan은 객체에 대한 point cloud 간 변환을 통한 A* search로 point cloud plan P = (a_1, a_2, \ldots, a_{T-1}) 를 계산하는 것입니다. (여기서 a는 앞서 말했듯 저자들의 정의 하에 a_t = \langle x_t, T_t \rangle 이렇게 정의되었습니다.)
해당 plan인 P를 기반으로 robot execution하면 point cloud obs sequence인 O = (o_2, o_3, \ldots, o_T) 가 생성되고, 이 때 G(o_T) = 1 을 만족하게 되는 식입니다.
저자들은 이를 강화학습에서 보통 많이 언급되는 그 Markov decision model로 아래처럼 공식화해서, 관찰 o_{t+1}이 이전 관찰 o_t와 행동 a_t에만 의존하도록 합니다.
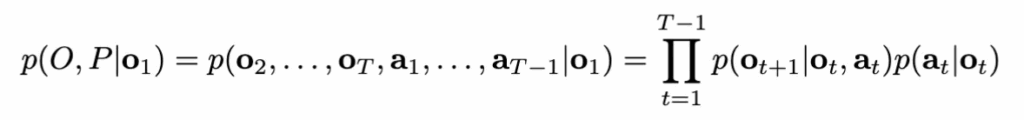
여기서 p(o_{t+1} \mid o_t, a_t) 는 point cloud dynamics를 나타내며, 이는 point cloud 관찰 o_t의 객체 x_t에 변환 T_t를 적용하는 것으로 모델링됩니다. 확률 p(a_t | o_t) 는 아래와 같이 분해될 수 있는데,
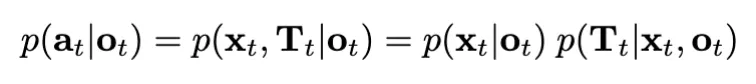
맨 오른쪽의 식을 보면 단순히 확률의 연쇄법칙에 의해 결국 두 확률로 분해됩니다.
여기서 저자들은 각각을 다음과 같이 정의합니다.
- 객체 제안자 (object suggester): p_\phi(x_t \mid o_t)
- 배치 제안자 (placement suggester): p_\theta(T_t \mid x_t, o_t)
이 쪼개진 파트별로 저자들은 객체 제안자(object suggester)와, 배치 제안자(placement suggester) 를 정의하고 그 둘 모듈 각각을 앞서 정의한 domain-specific point cloud transition 데이터셋 D로 학습하며, 그 학습된 object & placement suggester 들로부터 action을 샘플링하여, 초기 point obs o_1 으로부터 유한한 상태 집합을 통해 search graph를 확장합니다. 그 search 과정은 하나 이상의 goal 노드가 발견되거나, 최대 노드 확장 한계에 다다르면 끝나게 됩니다.
계획 P를 찾아 목표 함수가 만족되는 점군 o_T에 도달하면, 로봇 매니퓰레이터는 결과 계획의 각 행동 a = \langle x, T \rangle를 순차적으로 실행합니다. 실제 환경에서는 각 객체 x의 grasp pose를 Contact-GraspNet (ICRA 21’, Nvidia)을 통해 검출하거나, 시뮬레이션에서는 grasp 휴리스틱을 사용합니다. 객체가 파지되면, 로봇 제어기를 통해 변환 T를 적용하여 객체를 이동시킵니다. 저자들의 방법은 RGB-D 카메라 입력과 장면 속 객체들의 이름만으로 동작할 수 있으며, 그 외 다른 ground-truth 정보는 필요하지 않다고 합니다.
하지만 실행된 계획은 환경 동역학(environmental dynamics)으로 인해 출력된 계획과 다를 수 있습니다. 이를 해결하기 위해, 모델 편차 추정기(Model Deviation Estimator, MDE)을 학습한다고 하며, 이 모듈은 탐색 트리에서 계획된 행동과 실제 실행 간의 편차(deviation)를 추정합니다. 이 추정값을 사용해 A* 탐색이 더 낮은 편차를 가진 행동들을 향하도록 유도합니다.
정리해서 큰 틀에서 모듈 흐름도를 요약하면, 객체 제안자 → 배치 제안자 → A* 탐색 → MDE 보정 → 실행 의 큰 형태를 띕니다.
4.1. Learned “Object Suggester”
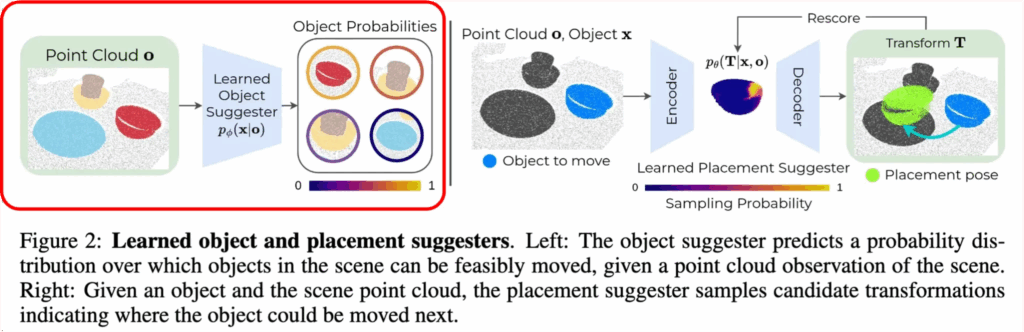
Object Suggester는 단순히 현재 scene 내에서 어떤 객체가 다음 장면에서 이동 가능한지를 학습된 확률 분포 p_\phi(x \mid o) 로 예측하는 모듈입니다. 학습은 앞서 말한 데이터셋 D로 진행되며, 인풋은 point cloud와 이진 query mask(특정 객체에 대한 3D point mask)입니다. 해당 객체가 실제 시연 내에서도 이동되었다면 라벨은 1, 이동되지 않았다면 라벨은 0으로 설정되어 supervised 학습이 이루어집니다. 모델 구조는 PointNet++을 사용하며, 아웃풋은 객체별 이동 가능성에 대해 0~1 범위로 정규화된 확률 분포가 됩니다.
추론 시에는 장면의 모든 객체 집합 X에 대해, 앞서 VFM을 기반으로 segment한 객체들 각각을 Query Mask로 만들어 object suggester에 입력하고, 확률 분포를 출력하는 방식으로 동작합니다.
4.2. Learned “Placement Suggester”
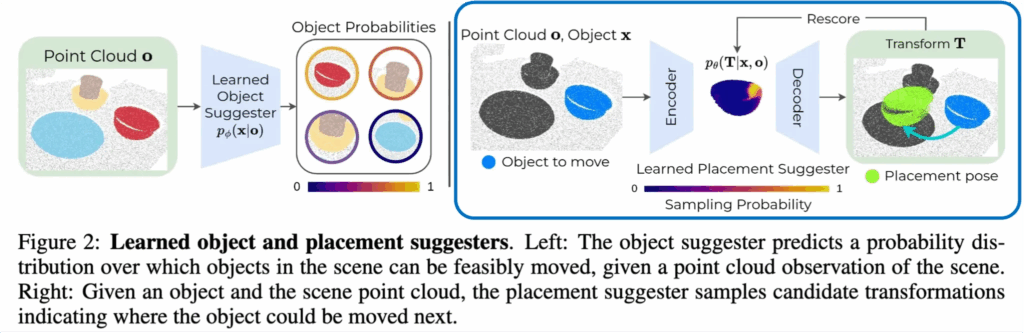
Placement Suggester는 특정 객체 x_t와 장면 o_t가 주어졌을 때, 객체를 다음 장면에 어디에 둘 수 있는지에 대한 잠재적인 SE(3) 변환 T_t들을 샘플링하여 제안하는 모듈입니다.
여기서도 학습 데이터셋은 D를 사용하는데, 각 point cloud transition은 (o_i, a_i, o_{i+1})로 구성되며, 여기서 a_i = \langle x_i, T_i \rangle 입니다. Placement Suggester는 분포 p_\theta(T \mid x, o)를 학습하고, 추론 시에는 scene 속 객체마다 여러 개의 T 후보를 샘플링하여 가능한 하위 노드 집합을 생성합니다. 예를 들어 위 figure처럼 table bussing 상황에서 객체 x가 bowl이라면, Placement Suggester는 bowl을 납작 접시 위에 두거나 다른 그릇 안에 두는 변환을 제안할 수 있습니다. 즉 두 가지 다른 하위 노드를 생성하게 되는 셈입니다.
모델 구조는 TAXPose-D [CoRL 23’]의 기존 연구를 활용했다고 합니다. cVAE(Conditional Variational AutoEncoder) 구조를 사용하여 인풋 포인트 클라우드 o와 이동 대상 객체 x를 받아, latent 분포 \tilde{p}(z \mid x, o)로 매핑해 학습하는 방식입니다. 이후 샘플링된 z는 변환 T로 디코딩되어 relative placement를 수행하게 됩니다.
latent space는 이산 다항 분포로 표현되어 multi-modal placement를 효과적으로 처리합니다. 즉 컵을 그릇 안에 넣는 것과 접시 위에 두는 것을 전혀 다른 모드로 표현하게 되며, 이산 분포 기반으로 각 모드 간 경계를 피하고 유효한 placement 포인트를 학습할 수 있습니다.
또 다양한 placement를 샘플링하기 위해(중복되는 placement 샘플링을 막기 위해) iterative rescoring 기법을 사용합니다. 매 반복마다 이전에 샘플링된 latent vector 주변의 샘플링 확률 분포를 줄이는 방식으로 rescoring을 적용합니다. 이는 아래 식으로 표현됩니다.
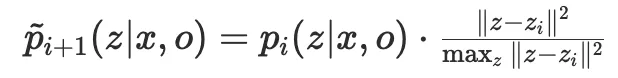
여기서 d(z, Z_{1:k})는 현재까지 샘플링된 latent 집합 Z_{1:k}와의 거리 함수이며, \lambda는 rescoring 강도를 조절하는 파라미터입니다.
데이터셋은 RGB-D 비디오 시연으로부터 각 객체를 강체로 가정하여, 객체의 강체 변환 시퀀스를 추출함으로써 구성됩니다.
4.3. Model deviation estimator
앞선 4.2.에서의 Placement Suggester는 특정 객체 x에 대해 변환 T를 제안하고, 그 결과 다음 point cloud 상태로 전이될 것이라고 가정했습니다. 하지만 이는 환경의 실제 동역학과 항상 일치하지 않는다는 문제가 있습니다. 예를 들어 Placement Suggester가 컵이 올려진 접시를 움직이도록 제안할 수도 있지만, 실제 환경에서는 컵이 접시에서 떨어질 가능성이 높습니다.
저자들은 이를 해결하기 위해 MDE(Model Deviation Estimator)라는 학습된 모듈을 도입합니다. MDE는 특정 행동이 실행될 때, 예상된 next state와 실제 true next state 간의 차이를 deviation, 즉 편차값으로 예측합니다.
동작 방식은 구체적으로 입력이 현재 관찰치, 즉 point cloud o_t와 제안된 액션 a = \langle x, T \rangle입니다. 출력은 해당 행동 실행 시 발생할 편차값을 실수값으로 내뱉게 됩니다.
이렇게 추정된 편차값은 이후의 A* search에 통합되어, 탐색 과정 중 더 신뢰할 수 있는 후보 액션만 선택되도록 합니다. 이를 통해 계획의 실행 가능성과 안정성을 높이는 역할을 하게 됩니다.
4.4. A* search over scene configuration
저자들은 initial scene point cloud o_1 에서 goal point cloud o_T 까지의 최단 계획을 찾는 문제를 search 문제로 정의했습니다. search 문제이므로 탐색 공간과 노드 정의가 핵심인데, 탐색 공간은 가능한 모든 객체 rearrangement 조합이 됩니다.
노드 n은 다음과 같은 조합으로 정의됩니다.
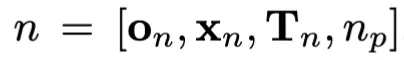
- 현재 점군 상태 o_n
- 선택된 객체 x_n
- 적용된 변환 T_n
- 부모 노드 n_p
자식 노드로의 확장은 다음과 같이 진행됩니다.
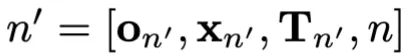
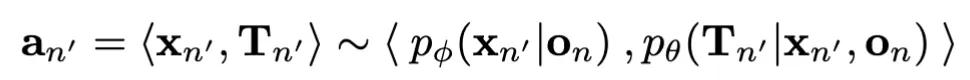
현재 노드 n에서 Object Suggester p_{\phi}(x_n' \mid o_n)로부터 움직일 객체 x_n'를 샘플링하고, Placement Suggester p_{\theta}(T_n' \mid x_n', o_n)로부터 해당 변환 T_n'를 샘플링하여 자식 노드 n'를 생성합니다.
각 객체에 대해 k개의 잠재적 변환을 제안하며, 실험에서는 k = 3, 5, 10을 사용했습니다.
Value Function
A* 탐색은 비용 함수 f(n) = g(n) + h(n) 을 최소화하는 방향으로 노드를 확장합니다.
여기서 g(n)은 지금까지 누적된 비용, h(n)은 현재 상태가 목표에 얼마나 가까운지를 추정하는 휴리스틱 함수입니다.
누적 비용 g(n)은 네 가지 항목의 가중합으로 정의됩니다.
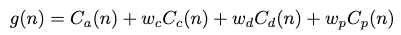
- Action cost C_a(n): 루트 노드에서 현재 노드까지 도달하는 데 필요한 단계 수를 의미합니다.
- Collision cost C_c(n): 충돌 가능성을 줄이기 위한 항목으로, 예를 들어 컵을 그릇과 겹치게 두는 잘못된 배치를 방지합니다.
- Deviation cost C_d(n): 모델 편차 추정기(MDE)에 기반하여, 실제 환경 동역학과 맞지 않아 실행 시 실패할 가능성이 큰 전이를 억제합니다.
- Probability cost C_p(n): 시연 데이터셋 D에서 더 자주 관찰된 전이일수록 낮은 비용을 부여하는 항목으로, 객체 및 배치 제안자의 출력에 기반합니다.
휴리스틱 함수 h(n)은 특정 작업(task)에 특화된 함수로, 주어진 노드의 점군 o_n이 목표 조건을 얼마나 만족하는지 또는 얼마나 가까운지를 추정합니다. 이를 통해 A* 탐색은 단일 목표만 고려하는 것이 아니라, 여러 가능한 목표 후보를 탐색할 수 있도록 유도됩니다.
즉, SPOT에서의 A* 탐색은 네 가지 비용 요소와 작업 특화 휴리스틱을 결합하여, 충돌을 피하고 현실적으로 실행 가능한 전이를 선호하며, 데이터에서 자주 등장한 경로를 따라가도록 설계되어 있습니다.
Results
저자들은 제안한 SPOT을 검증하는 과정에서 다음 2가지 질문에 대한 답을 얻기 위해 실험을 진행합니다.
- point cloud 시연 데이터만으로 학습한 후, 목표를 만족하는 계획(goal-satisfying plan)을 생성할 수 있는가?
- 이렇게 생성된 계획이 실제 로봇 실행 시 안정적으로 성공하는가?
Evaluation Env setting
- 블록 쌓기(Block Stacking, 시뮬레이션)
- 목표: 큐브들을 올바른 순서(빨강-초록-파랑, 위에서 아래로)에 맞춰 쌓기.
- 초기 상태: 블록들이 무작위로 쌓여 있거나 흩어져 있음.
- 요구 사항: 잘못된 순서의 블록은 먼저 unstacking(분리) 후 올바른 순서로 restacking(재배치) 해야 함.
- 난이도: 위치와 자세(orientation)가 랜덤 → 로봇이 정렬을 잘해야 넘어지지 않음.
- 제한된 공간 패킹(Constrained Packing, 시뮬레이션)
- 목표: 물체들을 제한된 공간(예: 찬장) 안에 배치.
- 조건: 모든 객체가 찬장 내부에 들어가야 하며, 물체들이 서로 위에 쌓이지 않아야 함.
- 필요 요소: 공간 제약을 고려한 정밀한 배치 계획.
- 테이블 치우기(Table Bussing, 실제 환경)
- 목표: 식탁 위의 접시, 그릇, 컵 등을 치워서 하나의 접시 위에 모두 정리.
- 초기 상태: 물체들의 위치가 무작위, 종종 겹쳐 쌓여 있음.
- 요구 사항: 겹쳐진 물체들을 먼저 분리(unstacking) 후 목표 상태로 재배치.

초기 장면 구성 (Figure 4)
- 난이도를 다양하게 설정:
- 4-step Table Bussing: 컵을 접시에서 치운 뒤 정리 → 4단계 필요.
- 3-step Table Bussing: 더 단순한 초기 상태 → 3단계 필요.
- 4-step Block Stacking: 블록 4개를 올바른 순서로 쌓기.
- 3-step Block Stacking: 더 단순한 초기 블록 배치.
- 4-step Shelf Packing: 제한된 공간(선반)에 블록 4개 배치.
5.1. Evaluation
SPOT은 task planning success rate라는 것을 평가지표로 삼습니다. 한 태스크는 현재 장면의 모든 객체가 저자들의 목표 함수에 따라 원하는 목표 구성을 만족할 때 완료된 것으로 간주합니다. plan의 효과성을 보여주기 위해, SPOT을 task execution success rate, 저희가 흔히 아는 SR에 대해서도 평가합니다. 시뮬레이션과 실제환경 태스크 모두에서, 예측된 액션들은 Franka 를 사용하며, 대부분 pick&place primitive 기반으로 진행됩니다. 특히 실제환경에서는 Contact-GraspNet을 사용합니다.
5.2. Baseline and Ablation
평가에서는 SPOT의 성능을 기존 기법(Points2Plans, 3D Diffusion Policy)을 베이스라인 삼아 비교하고, 또한 각 구성요소(Object suggester, A* search 등)의 기여도에 대해 ablation study를 진행했습니다.
- Points2Plans:
- partially observed point cloud 인풋으로부터 long-horizon manipulation 태스크 접근.
- SPOT과 달리, 관계적 상태 추상화(relational state abstraction) 를 사용해 point cloud를 기호적 표현(symbolic representation)으로 변환 후 계획 수행.
- SPOT과의 비교를 위해 Points2Plans의 제한된 패킹 환경(constrained packing environment) 에서 실험했다고 합니다.
- 3D Diffusion Policy:
- end-to-end 모방 학습 정책.
- 인간 전문가가 제공한 블록 쌓기(block stacking) 23개의 과제 특화 시연 데이터셋으로 학습.
- 모든 시연은 동일한 goal set을 따르며, 3D Diffusion Policy는 goal-conditioned가 아님.
- Beam Search:
- beam width = 1.
- 각 단계에서 후보 중 휴리스틱 값이 가장 높은 child node를 선택하는 방식.
- SPOT의 A* 탐색 구성요소를 제거한 대신, task-specific guidance(작업 특화 휴리스틱) 만 받음.
ablation은 다음과 같습니다.
- Random Rollouts:
- A* 탐색을 무작위 rollout으로 대체.
- 개선이 단순히 노드 확장 수 때문인지 검증.
- 가능한 child node 중 무작위 선택을 반복, SPOT과 동일한 노드 확장 한계에 도달할 때까지 진행.
- No Object Suggester:
- A* 비용 함수의 확률 비용은 p_\phi(x|o) (객체 제안자가 예측한 확률)에 기반.
- 객체 제안자를 제거하고, 모든 객체에 대해 균일한 확률 분포를 사용.
5.3. Results & Discussion
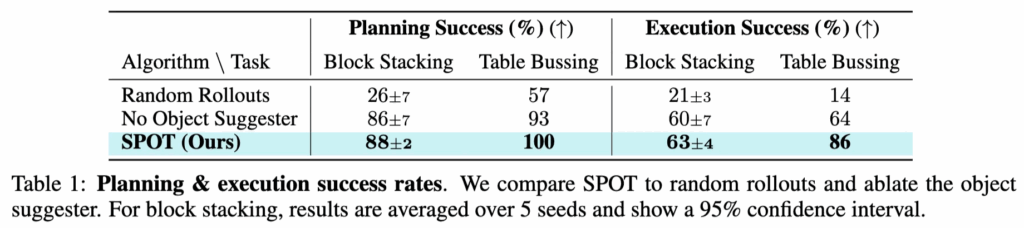
Table 1에서 SPOT은 블록 쌓기와 테이블 bussing 태스크 모두에서 높은 Planning Success와 Execution Success 을 기록했습니다. 특히 블록 쌓기에서 기존 방식인 Random Rollouts는 단순히 무작위 탐색에 의존했기 때문에 성공률이 26%에 불과했고, 객체 제안자(Object Suggester)를 제거한 경우에도 성능은 86% 정도에 머물렀습니다. 반면 SPOT은 88%의 안정적인 성능을 보여주며, 탐색과 객체 제안자의 결합이 효과적임을 보였습니다. 실제 실행 단계에서도 블록 쌓기에서 Random Rollouts는 21%에 불과했지만, SPOT은 63%까지 끌어올리는 모습이고, 테이블 bussing도 SPOT은 86%로, 다른 방법들과 큰 폭의 차이를 냈습니다.
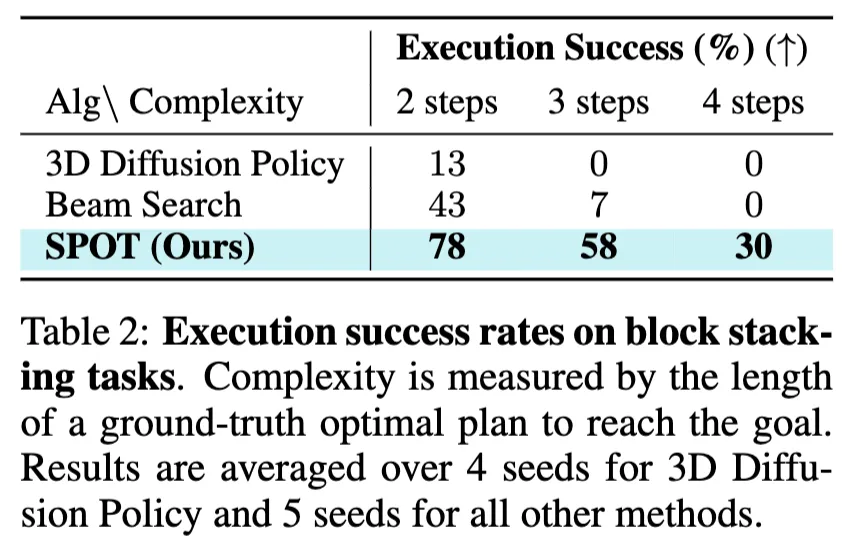
Table2는 블록 쌓기 태스크의 복잡도 즉 long-horizon manipulation에 대한 성능을 보여줍니다. 좀 신기한 건 단계 수가 늘어날수록 기존 기법들이 거의 0에 가깝게 실패한다는 것입니다. 3D Diffusion Policy는 2steps에서조차 13%에 불과했고, 3steps 이상에서는 전혀 성공하지 못했습니다. Beam Search 역시 3steps에서 7%, 4steps에서는 0%로 사실상 불가능에 가까웠습니다. 하지만 SPOT은 높은 성능을 보이는데요. 이는 long-horizon 태스크에서도 SPOT이 확실히 차별화된 강점을 가진다는 점을 보여줍니다.
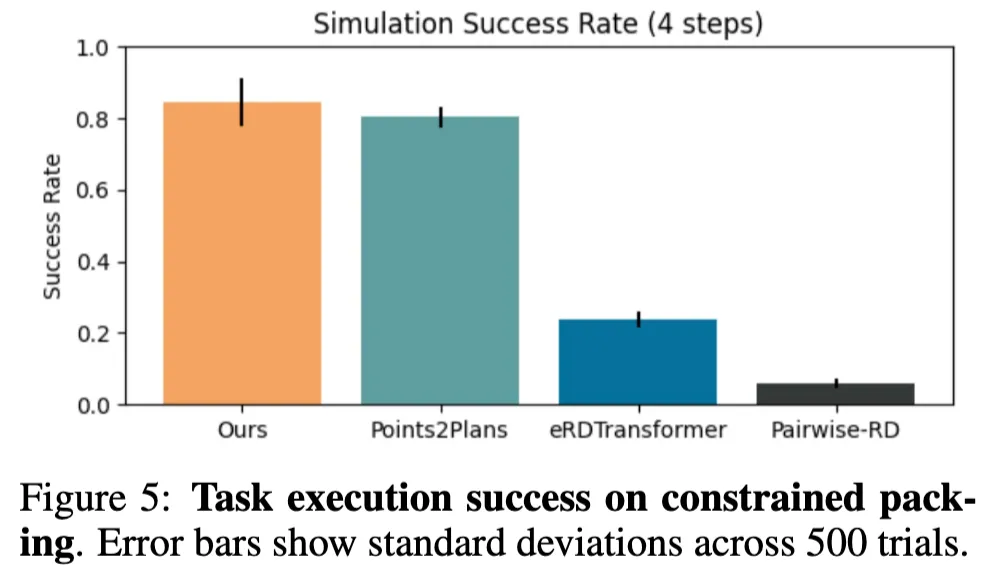
Figure 5를 보면 제한된 공간 패킹 과제에서 SPOT의 성능이 두드러집니다. SPOT은 약 84%의 성공률을 기록하며 Points2Plans를 소폭 앞질렀습니다. 반면 eRDTransformer나 Pairwise-RD 같은 기존 방법들은 각각 20%와 5% 미만으로 사실상 유효한 성능을 내지 못했습니다. 이 결과는 SPOT이 단순히 블록 쌓기 같은 구조화된 작업에만 강한 것이 아니라, 공간 제약이 큰 환경에서도 안정적으로 작동할 수 있음을 의미합니다.
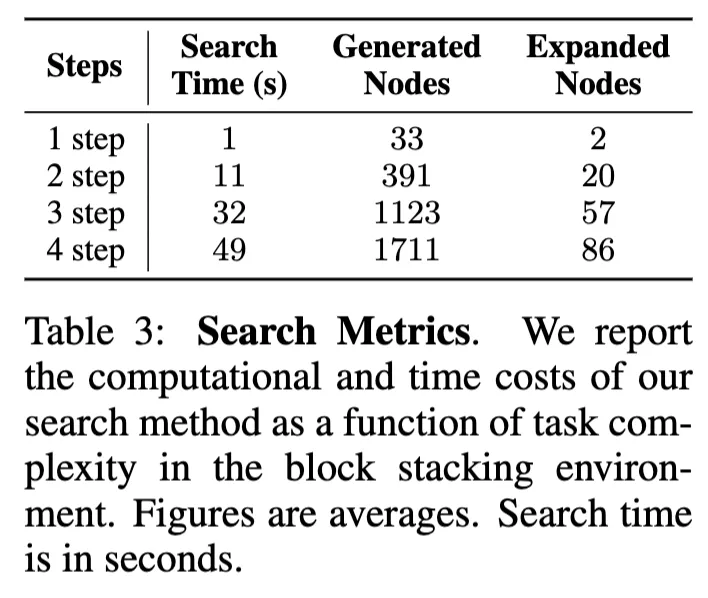
물론 이런 높은 성능에는 탐색 비용이 뒤따랐습니다. Table 3은 과제 복잡도가 높아질수록 탐색에 필요한 시간과 노드 수가 기하급수적으로 늘어난다는 사실을 보여줍니다. 1step 에서는 1초 만에 33개의 노드를 생성하고 그 중 2개만 확장하면 충분했지만, 4step에서는 49초가 소요되었고 1700개 이상의 노드를 생성해 86개를 실제 확장해야 했습니다. 이는 SPOT이 여전히 효율적인 탐색을 수행하지만, 복잡한 과제에서는 계산 비용이 만만치 않음을 보입니다.

마지막으로 Figure 6은 특이하게 SPOT의 efficient한 path-finding을 보여주는 정성적 결과입니다. 테이블 bussing 태스크에서 인간의 시연은 컵을 치운 뒤 그릇을 차례로 쌓고 다시 컵을 올리는 방식으로 총 4단계가 필요했습니다. 하지만 SPOT은 컵을 접시 옆으로 옮겨 공간을 확보한 뒤 바로 그릇들을 쌓는 방식으로 단 3단계 만에 동일한 목표를 달성했습니다. 이는 SPOT이 단순히 인간 시연을 그대로 따라 하는 것이 아니라, 학습된 객체·배치 제안자에서 얻은 일반적인 분포를 활용해 더 효율적인 대안을 스스로 탐색할 수 있다는 점을 보여줍니다. 이 점이 좀 신기했던 점입니다. 사전학습 때 사용된 시연에서의 action 경향성을 따라가지 않으면서 효율적인 task 수행과정을 planning한다는 점에서 의미가 큰 것 같습니다.
재찬님 좋은 리뷰 감사합니다.
해당 논문은 기존의 long-horizion manipulation을 위한 planning 연구 흐름 중 하나인 symbolic planning 태스크에 대하여 SPOT이라는 새로운 방법을 제안하여 open-set으로의 확장이 가능하도록 한 연구이며, 이를위해 object suggester와 placement suggester를 통해 대상 물체와 이후 목적지를 예측하고, 실제 작업과의 planning 사이의 차이를 고려하는 MDE를 활용한다고 이해하였습니다. 해당 논문을 보며 궁금한 점이 몇가지 있습니다.
먼저, observation에 대하여 M개의 객체 집합을 segmentation할 때, SAM2와 GroundingDINO, Grounded SAM 3가지를 모두 결합하는 방식인 가요? 어떻게 3가지를 결합하는 지 설명이 나와있지 않아 궁금합니다. 최대한 놓치지 않기 위해 3가지 모델의 결과를 모두 활용한다는 것 일까요?
또한, 사용하는 데이터가 잘 이해가 되지 않아서 질문드립니다. 즉, 로봇이 실제 작업이 이루어질 공간에서 촬영된 데모면 어떤 task에 대한 데모 데이터인지 상관 없다고 이해하면 될까요?
마지막으로 실험 시나리오가 상당히 어려운 케이스인 것 같은데, 성공률이 상당히 높은 것 같습니다. 이러한 고난이도 작업도 학습에 사용된 시연 데이터는 다른 데이터라 이해하였는데, 어떤 작업으로 학습되었는지는 함께 확인이 어려운 것 같아 이에 대한 정보가 있었는 지 궁금합니다.
안녕하세요 승현님, 리뷰 읽어주셔서 감사합니다.
1. 코드 확인해보니 Grounded-SAM-2 를 사용한 것으로 확인됩니다.
2. 데모 데이터 취득은 동일한 물리적 도메인(같은 테이블/선반 환경, 같은 종류의 객체/상호작용, 같은 센서 셋업)에서 이루어져야 하며(domain-specific), 그 도메인에서 흔히 발생하는 객체 이동·배치 전이들을 포함해야하는 구성을 띄고 있습니다. 여기서 task-specific이란 워딩때문에 혼동이 오신 것 같은데, task-specific은 해당 domain 구성은 모두 똑같이 갖춘채로 특정 task로만 취득하지 않고, 다양하게 취득한 것을 의미합니다. 근데 그릇 거꾸로 뒤집어놓기 등 같이 좀 더 어려운 것도 될지는 모르겠네요.
3. 각 실험 시나리오마다 각각의 object suggester, placement suggester, MDE 모듈을 그 각 실험 시나리오의 데모 데이터에 맞게 각각 학습해서 평가한 것으로 저는 이해했습니다. 즉 각 실험 시나리오마다 데모 데이터를 따로 취득한 것입니다. 예를 들어 A 실험 시나리오에 대한 데이터로 학습된 SPOT 파이프라인이 B 실험 시나리오에 대해서는 작업이 불가능할 것 같습니다.
감사합니다.
안녕하세요 재찬님 리뷰 감사합니다.
전체적으로 제가 잘 아는 분야는 아니지만 읽으며 궁금했던 점을 질문드리자면
본문에서 MDE 가 searching 과정에서 불확실성이 큰 transition 을 억제하는 역할이라고 언급해주셨는데, 그렇다면 MDE를 사용하는 경우, 로봇이 항상 신뢰도 높은 쉬운 동작들만 연속적으로 선택하게 된다고 이해하면 될까요?
혹은 모든 transition의 불확실성이 높게 예측되는 경우 해당 동작을 아예 수행하지 않는 방향으로 중단되는 경우도 있는지 아니면 그래도 덜 불확실한 선택을 선택해서 진행하는 구조인지 궁금합니다.
감사합니다.
안녕하세요 인택님, 리뷰 읽어주셔서 감사합니다.
1. 저는 우선 신뢰도 높은 동작 == 쉬운 동작 이 성립하지는 않는다고 생각합니다. 또 항상 신뢰도 높은 동작들만 연속적으로 선택한다고는 볼 수 없을 것 같습니다. 결국은 MDE 자체가 어려운 동작임에도 불확실성이 낮아서 동작가능하다고 판단하여 tree search 시 cost function에 soft한 weight를 주는 매커니즘이고 이걸 기반으로 A* tree searching이 이루어지기 때문에, 쉽고 신뢰도 높은 동작만을 ‘항상 연속적으로 선택한다’고는 볼 수 없을 것 같아요.
2. 그래도 덜 불확실한 선택을 고려하는 구조라고 보시면 됩니다. 추가로 이번 CoRL 가서 poster 세션에서 저자에게 MDE가 always reliable한거냐 물어보니, 정말 자신있게 그렇다고 하더라구요. 제가 그래서 oral 발표하실 때 failure case로 bowl과 bowl사이 겹친 bowl꺼내기는 실패한다고 했는데 그건 그럼 어떻게 설명되는 거냐 하니까. 그건 그냥 MDE한계가 아니라, 해당 방법론의 한계 중 occlusion의 한계라고 짚고 어쩔수없다며 넘어가더라구요. CoRL Oral 페이퍼에서는 확실히 vision 관점에서 해결하려하지 않는 문제들이 몇 있었습니다.