안녕하세요. 이번 X-Review에서는 25년도 CVPR에 게재된 논문 <Object-aware Sound Source Localization via Audio-Visual Scene Understanding>을 소개해드리고자 합니다. Sound Source Localization이라는 task를 다루는 논문은 처음 읽어보는데요. 제가 보고있는 Audio-Visual Question Answering에서도 간접적으로 필요한 기술이기에 실제 SSL task에서는 어떤 식으로 문제에 접근하고 해결하는지 알아보는 차원에서 읽게 되었습니다. 자세한 내용은 바로 시작되는 리뷰에서 이어 말씀드리겠습니다.
1. Introduction
가장 먼저 Sound Source Localization (SSL)이라는 task에 대해 간단히 설명드리겠습니다. SSL은 어떤 비디오가 입력되면, 비디오에 포함되어있는 시각 정보와 오디오 정보를 활용해 지금 소리가 나고 있는 객체의 위치를 잘 찾아내는 것이 목표인 task입니다.
찾아보니까 대략 2020년도부터 SSL 연구가 활발히 이루어진 것 같은데, 그간 graph-based modeling, hard positive mining, negative-free learning 등 다른 task들 못지않게 다양한 방향의 학습 방법론들이 등장해왔다고 합니다. 그럼에도 불구하고, 저자는 아직 이 방법론들이 ‘complex scene’에서는 정확한 source localization을 찾아내지 못하고 있다고 주장합니다. 실제로는 여러 ‘complex’가 있겠지만, 여기서 저자가 이야기하는 ‘complex’란 실제 소리를 내는 object와 동일하지만 소리를 내지 않는 object가 동시에 등장할 때를 의미합니다. 예를 들어 영상에 2개의 기타가 등장하지만 왼쪽 기타만 실제 소리를 내고 오른쪽 기타는 연주되지 않는 상황을 말하는것이죠.
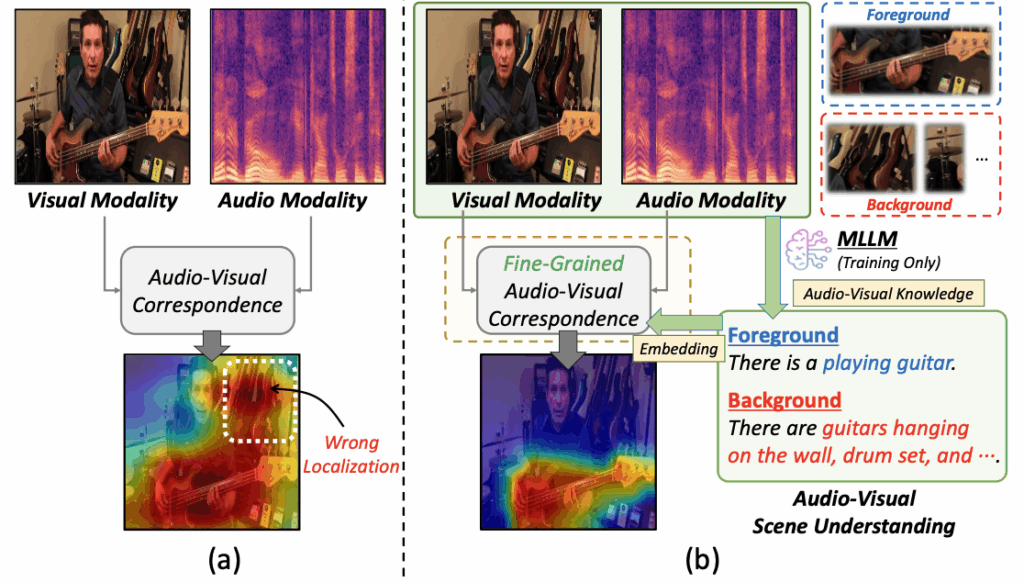
저자는 위와 같은 문제의 원인이 기존 방법론의 단순한 Audio-visual correspondence에 있다고 이야기합니다. 위 그림 1-(a)는 기존 방법론들의 흐름을 보여주는데, 흐름이랄 것도 없이 단 하나의 ‘Audio-Visual Correspondence’라는 박스로 그려두었습니다. 일부러 그림을 굉장히 간단하게 그린 것도 있겠네요. 좀 더 자세히 설명드리면, 기존 방법론들은 보통 audio로 기타 소리가 들어오고, 위 그림 1의 예시와 같은 이미지가 들어오면 ‘기타 소리’와 ‘기타’에만 집중하여 둘을 매칭하게 된다고 합니다. 즉 sound source를 찾기 위해서는 소리를 낼 수 있는 물체가 실제로 연주되거나 소리가 나도록 상호작용하는 부분까지 잡아낼 수 있도록 fine-grained하게 correspondence가 만들어져야하는데, 지금은 그냥 ‘기타 소리’가 나면 모델은 바로 ‘기타’에만 집중한다는 것이죠.
다음으로 그림 1-(b)에서는 기존 방법론들의 문제를 극복하기 위해 저자가 제안하는 Fine-grained audio-visual correspondence 방법을 간단하게 설명해줍니다. 핵심은 audio-visual scene understanding을 통해 더욱 상세한 맥락을 파악한 다음에 SSL을 수행하는 것입니다. 1) 첫번째로 주어진 시각 정보에서 얻을 수 있는 물체를 모두 파악합니다. 예시 이미지에선 기타와 사람 왼쪽에 있는 드럼셋이 있음을 먼저 인식하는 것이죠. 2) 두번째로는 실제 ‘소리가 나는’ foreground 물체를 선별하기 위해 전체 물체중 foreground와 background를 구별해내는 것입니다. 이와 같은 목적을 달성하기 위해 저자는 Multimodal LLM (MLLM)의 지식을 빌려오고자 합니다.
사실 MLLM의 지식을 기존 방법론에 단순히 추가하기만 해도 성능은 오르겠지만, 그렇게하면 방법론의 novelty는 좀 부족하겠죠. 이때 저자는 MLLM으로부터 추출한 정보를 SSL에 잘 녹여내기 위한 두 가지 loss를 함께 제안합니다.
- Object-aware Contrastive Alignment (OCA) Loss
- MLLM은 눈에 보이는 기타와 드럼셋 등을 찾고, 실제 sound-making object까지 분리해냅니다.
- OCA loss는 이 정보를 활용해 소리를 내는 객체와 내지 않는 객체 간 임베딩 공간 상에서의 차이를 주는 것이 목적입니다.
- Object Region Isolation (ORI) Loss
- OCA loss를 통해 소리 나는 객체와 그렇지 않은 객체는 잘 분리가 되지만, 소리 내는 객체끼리 또한 각자의 구별력을 갖출 필요가 있습니다.
- 예를 들어 바이올린과 첼로가 동시에 연주되고 있다면 두 악기가 비슷하게 생겼기 때문에 localization map이 겹쳐서 만들어질 수 있다는 것입니다.
- ORI loss는 이렇게 겹치는 sound source 영역을 각각 잘 분리하도록 학습하는 loss입니다. 이렇게 잘 분리해줌으로써 localization이 더욱 뚜렷해지고 성능도 올라가게 된다고합니다.
2. Method
Introduction 내용을 간단히 정리하고 방법론을 자세히 살펴보겠습니다.
저자는 기존 SSL 방법론들의 audio-visual correpondence 수준이 너무 coarse하여 물체에 등장하는 객체 중 실제 소리를 내는 객체와 내지 않는 객체를 잘 구별해내지 못한다고 주장하였습니다. 이 문제점을 해결하기 위해 MLLM을 활용해 먼저 audio-visual scene의 문맥을 전체적으로 이해하고, 이를 바탕으로 소리 내는 객체와 내지 않는 객체를 분리하는 OCA loss, 소리 내는 객체끼리도 뚜렷하게 분리하는 ORI loss를 제안하고자 합니다. 전체 파이프라인은 아래 그림 2와 같습니다.
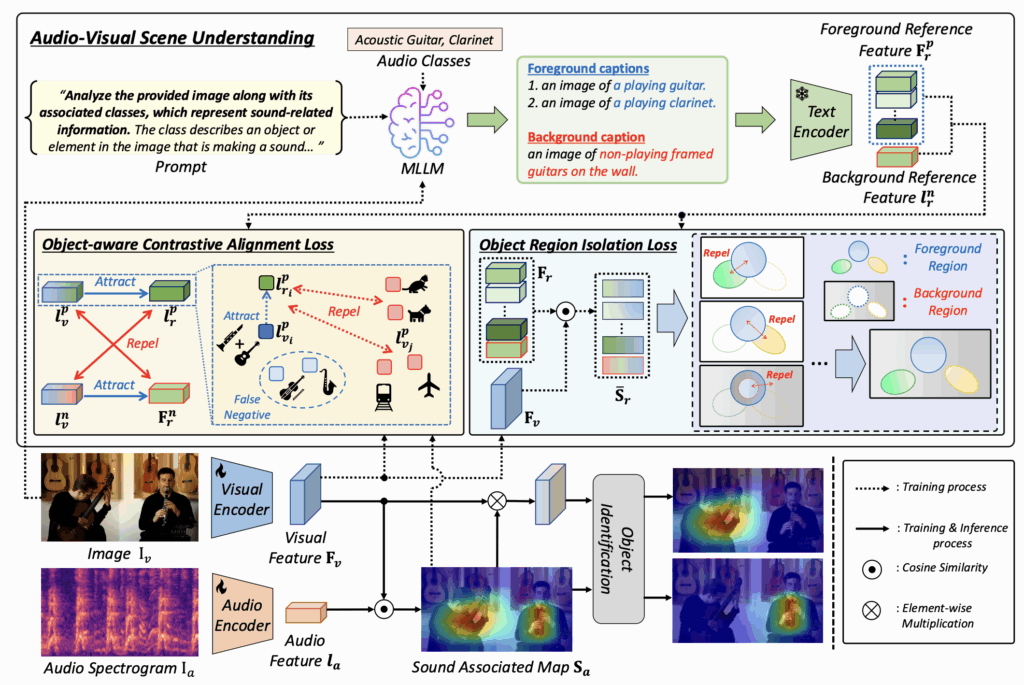
2.1 Preliminaries
보통 SSL 방법론의 평가를 위해서는 아래 두 가지 단계를 거쳐 최종 sound-source object 예측을 만들어냅니다.
Sound-associated Region Localization
이 단계에서는 먼저 audio-visual feature 간 alignment를 수행해줍니다. Visual feature \mathbf{F}_v \in \mathbb{R}^{B \times w \times h \times c}와 audio feature \mathbf{l}_a \in \mathbb{R}^{B \times c}를 입력받고 잘 처리한 뒤 sound-associated map S_a = \text{Sim}(\mathbf{F}_v, \mathbf{l}_a)를 생성하는 것이 목표입니다. 제가 ‘잘 처리’라고 쓴 이유는, 바로 이 부분이 각 SSL 방법론들이 제안하는 기법에 달려있기 때문입니다. 즉 유사도 계산에 관여되는 두 feature를 잘 만들어내는 것이 각 방법론의 contribution입니다.
Object Identification
만약 K개의 sound source가 존재한다고하면, 학계의 기존 평가 프로토콜인 Iterative Object Identification 알고리즘을 K번 반복해 최종 물체를 찾아냅니다. 이 과정에서 앞서 각 방법론이 만들어낸 S_a가 활용되고, 그 결과가 평가 대상이 됩니다.
정리하자면 SSL 평가를 위해 필요한 두 가지 단계 중 본 논문의 contribution은 첫번째, 즉 fine-grained한 audio-visual correspondence learning을 통해 좋은 sound-associated map을 만드는 데에 있는 것입니다.
2.2 Audio-Visual Scene Understanding
앞서 설명드렸듯 복잡한 visual scene에 대한 전반적인 문맥 이해를 위해 MLLM을 활용합니다. MLLM은 InternVL2-8B 모델을 사용했다고 합니다. 여기서 저자는 MLLM에 이미지와 오디오 클래스 정보를 입력해주고, 현재 이미지에서 어떤 객체가 소리를 내고 있는지, 내고있지 않은지에 대한 정보를 묻게 됩니다. 결국 소리 내는 객체에 대한 foreground 캡션 K개와 소리 내지 않는 객체에 대한 background 캡션 한개를 얻어줍니다. 그림 1 상단에서 MLLM에 입력되는 프롬프트 및 오디오 클래스, 출력 예시를 확인하실 수 있습니다.
다음으로는 MLLM이 만들어낸 foreground, background 캡션을 텍스트 인코더에 입력하여 각각의 feature \mathbf{F}_r^p \in \mathbb{R}^{B \times K \times c}, \mathbf{l}_r^n \in \mathbb{R}^{B \times c}를 얻어줍니다. 이렇게 추출한 캡션에 대한 feature들이, 뒷단에서 소리를 내는, 내지 않는 객체 간 구분과 소리내는 객체끼리의 구분까지도 guide해주게 됩니다.
2.3 Object-aware Contrastive Alignment Loss
여기서부터는 앞서 추출한 feature를 어떻게 활용하는지에 대한 내용입니다. 기존 방법론들이 silent object를 제대로 인지하지 못하는 단점을 극복하기 위해 제안된 loss입니다. 가장 먼저 visual feature \mathbf{F}_v와 audio feature \mathbf{l}_a 간 유사도 맵 \mathbf{S}_{a} \in{} \mathbb{R}^{B \times{} w \times{} h}를 아래 수식 (1)과 같이 계산해줍니다.
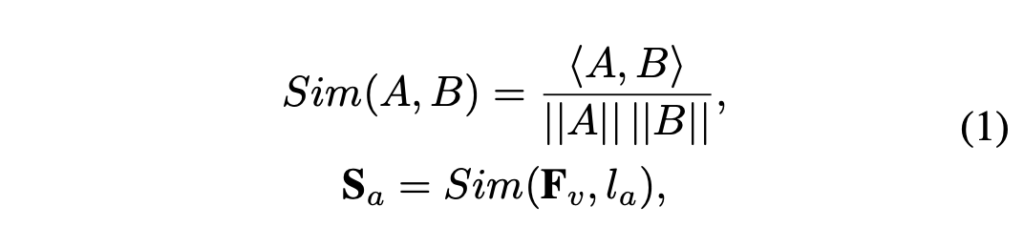
다음으로는 기존 연구(Localizing visual sounds the hard way)를 따라 Foreground map M^p와 Background map M^n를 아래 수식 (2)와 같이 만들어줍니다. 아래 수식에서 \sigma는 sigmoid 함수, \alpha_p, \alpha_n, \omega는 하이퍼파라미터입니다.
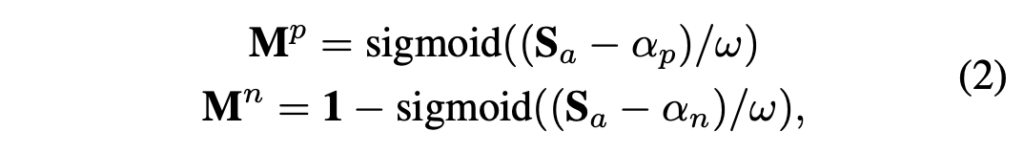
여기서 얻은 foreground, background map은 단순 스케일링 후 sigmoid에 태워 0~1로 조정해줌으로써 유사도를 기반으로 각 픽셀이 foreground, background에 해당할 일종의 확률 값을 표현하는 것을 알 수 있습니다.
다음으로는 M^p와 M^n을 활용해 foreground, background feature를 아래 수식 (3)과 같이 만들어줍니다. 수식에서 GAP는 Global Average Pooling이고, 각 feature shape은 \mathbb{R}^{B \times{} c}입니다. 여기서는 일종의 masking을 통해 각각 foreground, background feature만 살린 뒤 GAP로 feature aggregation을 했다고 볼 수 있겠네요.
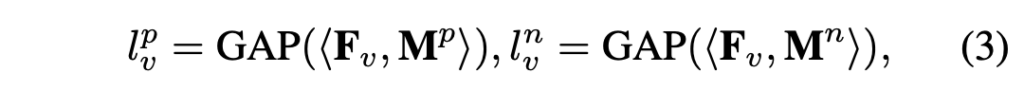
여기서부터 위 값들을 활용해 본격적인 OCA loss를 설계합니다. OCA loss는 \mathcal{L}_{frg}와 \mathcal{L}_{bkg}로 구성되며, 그 중 전자는 아래 수식과 같습니다.
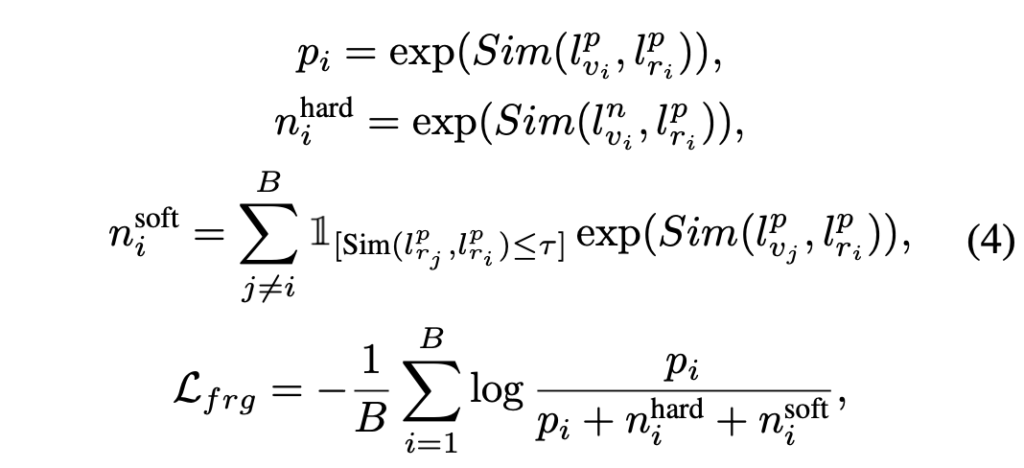
여기서부터 수식이 좀 나오는데, 최대한 간단한 개념 위주로 설명드리겠습니다. \mathcal{L}_{frg}는
- foreground visual feature l_{v}^{p}와 MLLM으로부터 얻은 평균 풀링된 foreground reference feature l_{r}^{p}가 가까워지도록
- background visual feature l_{v}^{n}과 MLLM으로부터 얻은 평균 풀링된 foreground reference feature l_{r}^{p}가 멀어지도록
학습하게 됩니다.
위 수식 (4)에서 n_{i}^{soft}는 false negative issue를 다루기 위해 들어가는 항으로, 일반적인 contrastive learning에서 한 배치 내 다른 샘플은 모두 negative로 들어가는 점을 보완하기 위해 포함됩니다. 배치 내 foreground reference feature 중엔 실제로 서로 positive인 샘플이 들어있을수도 있는데, 기본 contrastive learning은 이를 negative라 두고 학습할 것이고 이런 악영향을 줄이기 위한 것이죠. 결국 배치 내 타 positive reference feature와 현재 anchor의 positive reference feature 간의 유사도를 계산한 후 일정 threshold 이상을 갖는 샘플은 negative에서 제외시켜주게 됩니다.
위 \mathcal{L}_{frg}를 통해 소리나는 객체의 시각 feature가 foreground reference feature와는 가까워지도록, 소리 나지 않는 객체의 시각 feature가 foreground reference feature와는 멀어지도록 학습하게 됩니다. 다음으로 \mathcal{L}_{bkg}는
- background visual feature l_{v}^{n}이 background reference feature l_{r}^{n}과 가까워지도록
- foreground visual feature l_{v}^{p}가 background reference feature l_{r}^{n}과 멀어지도록
학습하게 됩니다.
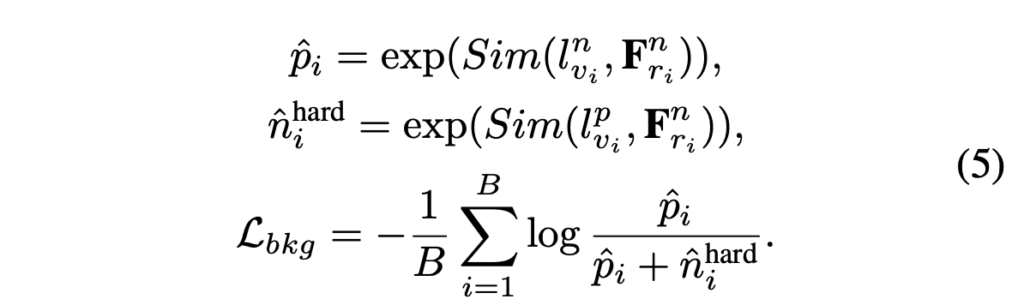
여기까지 하여 loss \mathcal{L}_{oca}는 아래 수식 (6)과 같이 정리할 수 있습니다. \mathcal{L}_{oca}를 통해 MLLM으로부터 얻은 지식을 활용해 실제 소리가 나는 객체와 소리나지 않는 객체를 feature-level에서 구분할 수 있게 됩니다.
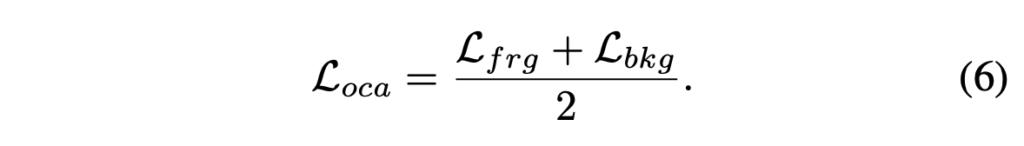
2.4 Object Region Isolation Loss
이제부터 설명드리고자 하는 \mathcal{L}_{ori}는 영상의 여러 객체가 동시에 소리를 낼 때, 소리 나는 그 여러 객체들간의 source를 명확히 분리하고자 하는 의도를 가지고있습니다. 예를 들어 바이올린과 첼로가 동시에 소리내고 있다면, 기존 방법론들은 두 악기에 걸치도록 겹치는 associated map을 만들어내곤 한 것이죠. 명확한 localization을 위해 각 object를 분리하는 것이 본 loss의 목표입니다.
먼저 처음에 MLLM으로부터 뽑은 foreground, background ference feature \textbf{F}_{r}^{p}와 l_{r}^{n}을 concat하여 reference feature \textbf{F}_{r} \in{} \mathbb{R}^{B \times{} (K+1) \times{} c}를 만들어줍니다.
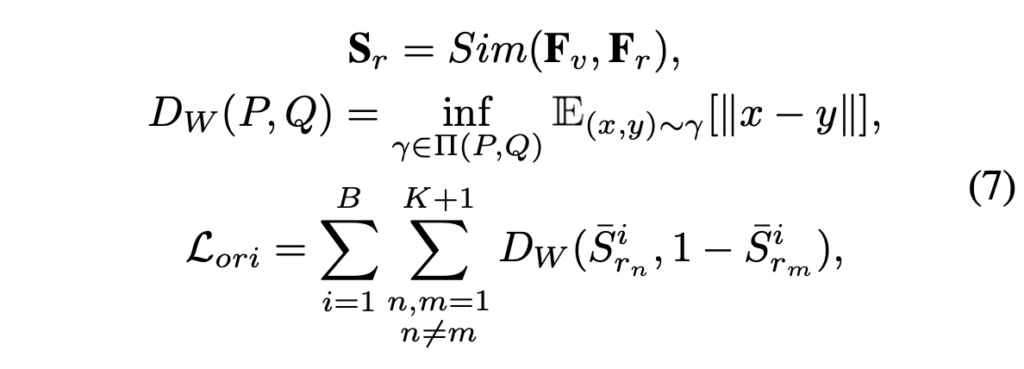
이후에는 위 수식 (7)을 이어 거치게 되는데요. 다음엔 유사도를 기반으로 K+1개의 Reference-associated map S_r = \{\textbf{S}_{r_k}\}_{k=1, \cdots{}, K+1} \in{} \mathbb{R}^{B \times{} (K+1) \times{} w \times{} h}을 만들어줍니다. 여기서 각각의 S_{r_k}는 visual feature와 K개의 객체 영역 간 유사도 또는 visual feature와 1개의 배경 영역 간 유사도를 의미하겠죠.
또 다시 MLLM으로부터 얻은 정보를 활용해 객체 하나하나에 대한 유사도 맵은 구했으니, 이제 각각이 구별력을 갖출 수 있도록 만들어주면 될 것입니다. 앞서 얻은 object별 associated map \textbf{S}_{r}을 1차원으로 펴 확률 분포 형태로 만들어주게 됩니다. 즉 \bar{\textbf{S}}_{r} \in{} \mathbb{R}^{B \times{} (K+1) \times{} wh} 형태로 펴주는 것입니다.
이후 수식 (7)의 두번째 줄은 Wasserstein Distance를 의미하며, 결국 마지막 줄의 \mathcal{L}_{ori}는 각 객체 간의 Wasserstein Distance를 크게 만들어주는 역할을 수행합니다. Wasserstein Distance의 개념은 P, Q 두 분포가 있을때 P 분포를 Q 분포로 옮기는데에 드는 최소 이동량을 의미합니다. 해당 거리에 대한 자세한 설명은 블로그에 잘 설명되어있어 이를 참고하였습니다.
여기서 거리를 구할때 한 샘플은 1에서 뺀 값을 넣어줌으로써 n번째 객체가 존재하는 영역과, m번째 객체가 존재하지 않는 영역 분포가 유사해지도록 학습합니다. 결국 두 객체가 겹치는 상황을 최소화할 수 있게 만들어주는 역할입니다. 위 loss를 통해 localization과 object identification 정확도를 올릴 수 있게 됩니다.
2.5 Training Objective
최종 loss는 아래 수식 (8)과 같습니다. 아무래도 실제 평가 객체는 뒷단의 Object Identification 과정에서 생성되다보니 저자가 설명한 feature alignment만 나타나있습니다.
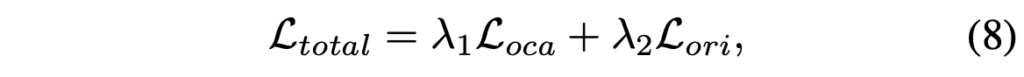
3. Experiment
3.1 Datasets and Evaluation Metrics
SSL task의 평가는 처음 보는지라 간단히 데이터셋 및 지표를 정리해보겠습니다.
MUSIC Dataset
MUSIC 데이터셋은 448개 유튜브 비디오로 이루어져있고, 11개의 악기가 솔로 혹은 듀엣으로 연주된다고 합니다. 이 중에서도 악기가 동시에 하나만 연주되는 비디오로 구성된 MUSIC-Solo, 두 악기가 동시에 연주되는 비디오로 구성된 MUSIC-Duet 두 가지로 구성됩니다.
VGG-Sound Dataset
200K개 이상의 영상과 221개의 sound category로 구성되어 규모가 굉장히 큰 데이터셋입니다. 학습엔 약 144k개의 image-audio pair를 활용하며 MUSIC과 마찬가지로 Single, Duet으로 나눠져있다고 합니다.
Evaluation Metrics
평가지표는 Single SSL과 Multi-source(=Duet) SSL 세팅에 따라 조금 달라집니다. 기본적으로 최종 출력물은 detection과 같은 bbox입니다. 따라서 Single SSL일땐 클래스가 1개인 OD와 유사하게 AP, IoU, AUC를 사용합니다. 다음으로 Multi-source SSL 세팅에선 Class-aware AP (CAP), Class-aware IoU (CIoU), AUC를 활용합니다. 여기서 Class-aware라는 단어가 붙어 무슨 지표인가하고 찾아보니, 여러 클래스를 detection 해야하는 일반 Object Detection에서의 mAP 등등과 사실 동일하나, Single SSL과의 차이를 명시하기 위해 의도적으로 “C”를 붙이는 것으로 확인하였습니다.
3.2 Implementation Details
입력 비디오와 오디오가 어떻게 샘플링되는지 정리해보겠습니다.
비디오는 먼저 224*224 해상도로 resize되고, 3초짜리 클립으로 나뉘게 됩니다. 프레임은 한 클립의 중간 프레임을 선택하고, 오디오는 3초짜리 음성을 log-scale spectrogram으로 만들어줍니다. 백본은 기존 방법론들과 동일하게 ResNet-18을 사용하고, visual encoder는 ImageNet으로 사전학습된 ResNet-18, audio encoder는 입력 채널을 1채널로 바꿔 학습하기 시작합니다. 그림상에서도 알 수 있듯 두 인코더는 학습 중 모두 trainable합니다. 다른 모듈 없이 백본을 finetuning 하는 것이죠.
앞서도 말씀드렸듯 MLLM은 InternVL 2.0-8B, MLLM의 출력 문장의 텍스트 인코더는 BERT를 사용합니다. 두 모델은 다 freeze 된 채로 출력을 만들어냅니다.
3.3 Comparison to Prior Works
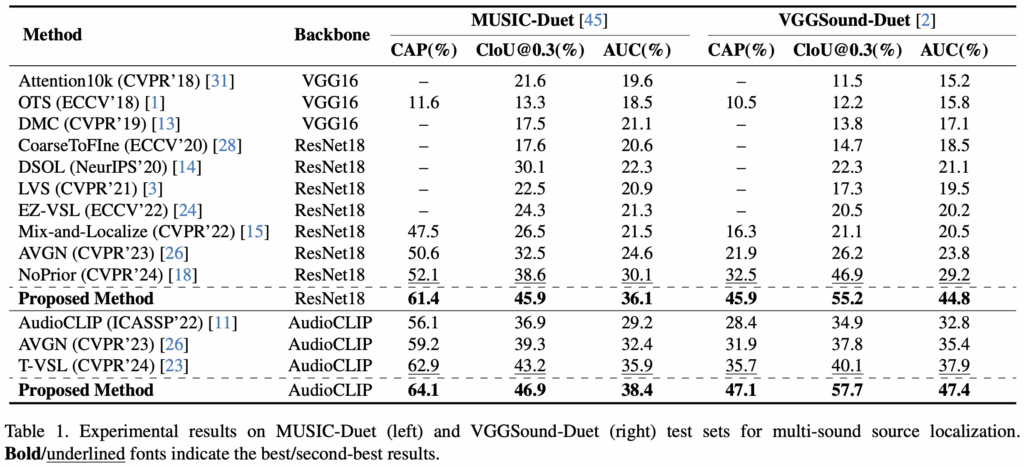
Multi-Sound Source Localization
표 1은 MUSIC-Duet에서의 벤치마크 표입니다. 멀티 소스이기에 Class-aware 지표들이 사용되는 것을 볼 수 있습니다. 저자도 성능에 대해 별다른 분석을 하고있진 않지만, MLLM을 써서그런지 성능 향상 폭이 굉장히 인상적입니다. 특히 조금 더 난이도가 높다고 볼 수 있는 VGGSound에서의 성능 향상폭이 굉장히 큰데, 확실히 MLLM의 외부 지식을 가져와 잘 사용하는 것이 제대로 작용했음을 알 수 있었습니다.
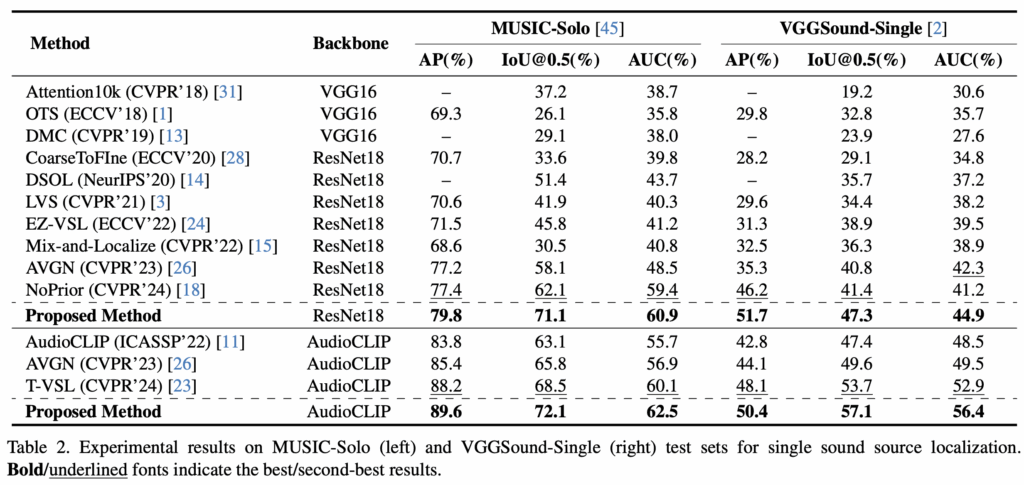
Single Sound Source Localization
표 2는 단일 소리만이 비디오에 등장하는 세팅을 기준으로 측정한 성능 표입니다. 마찬가지로 기존 방법론들과 큰 격차로 이기는 것을 볼 수 있습니다. 벤치마크 성능에 대해서는 저자의 분석이 딱히 없기도 하고, 제가 추가적인 분석을 해보기도 어려워 Ablation으로 넘어가겠습니다.
3.4 Ablation Study
본 절에서는 Loss별 ablation과 하이퍼파라미터에 따른 성능 결과를 살펴보겠습니다.
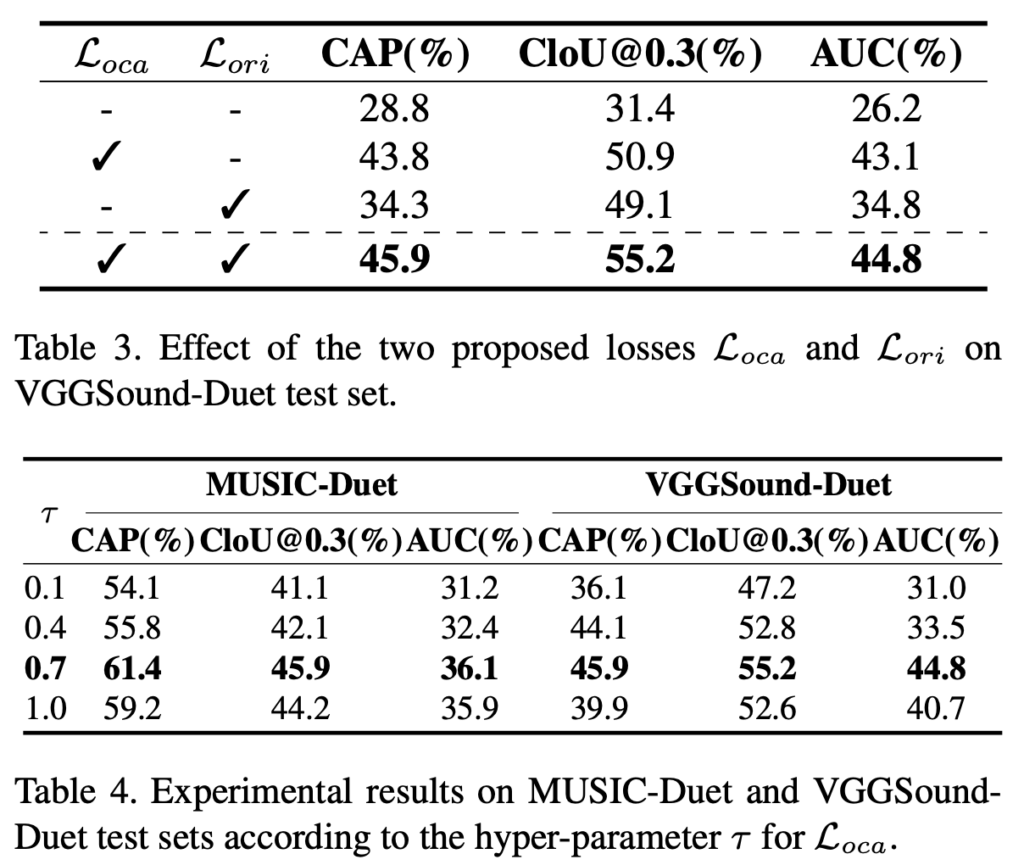
우선 표 3은 저자가 제안한 두 가지 loss \mathcal{L}_{oca}, \mathcal{L}_{ori}에 대한 ablation 성능입니다. 당연히 MLLM으로부터 나온 지식을 활용하여 foreground와 background 객체 간 분리도를 개선해주는 \mathcal{L}_{oca}의 향상 폭이 더욱 컸습니다.
개인적으로는 단순히 \mathcal{L}_{oca}의 on/off 여부에 추가로, 조금 다른 방식으로 feature aggregation을 얻어내거나 간단한 버전의 \mathcal{L}_{oca}을 썼을 때 성능은 어느정도인지를 보여주는 추가 분석 실험이 있었으면 좋았을 것 같습니다. 저자의 의도대로 두 loss를 모두 썼을 때 잘 융합되며 가장 높은 성능을 달성하고 있습니다.
3.5 Visualization Results
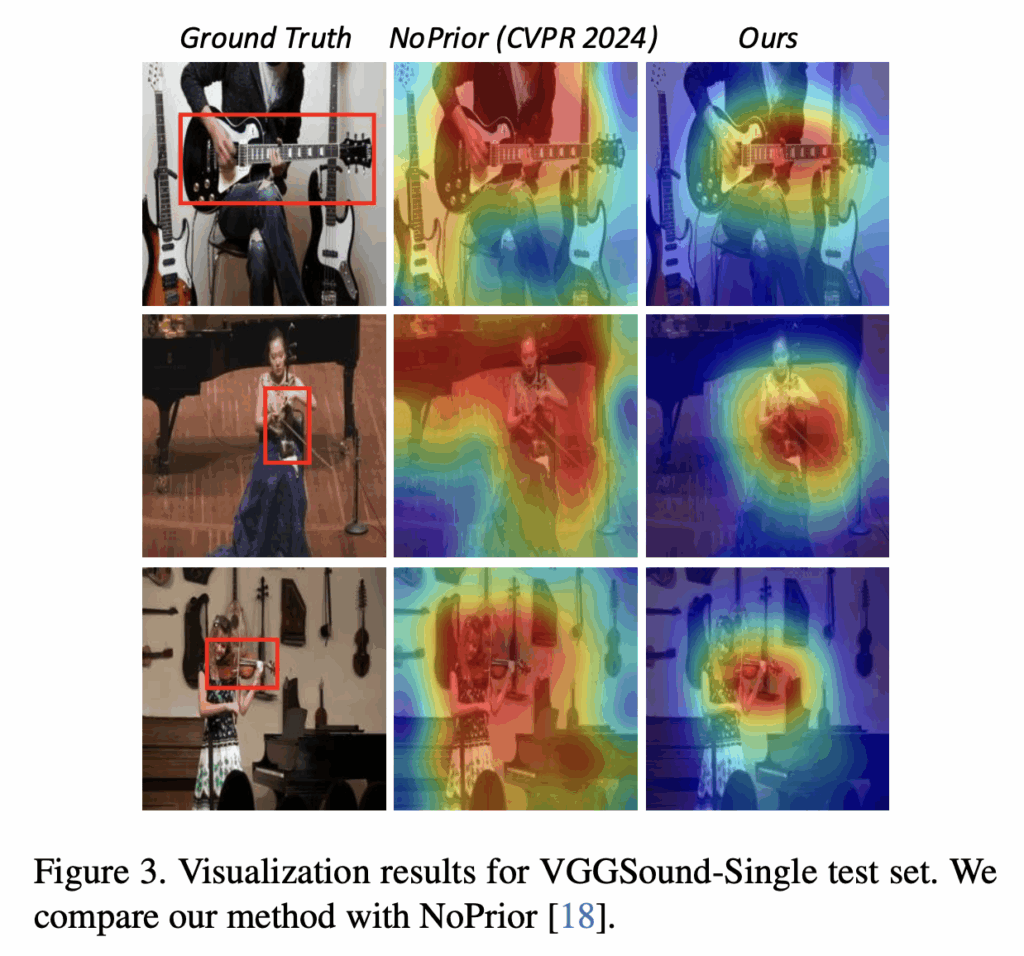
그림 3은 단일 소스 환경에서, 24년도 CVPR에 게재된 기존 방법론 NoPrior과의 association map 정성적 결과 비교입니다. 확실히 저자의 방법론이 다른 물체와 헷갈리지 않으며 정말 소리를 내는 객체에 유사도가 큰 픽셀이 집중되어있는 것을 볼 수 있습니다.
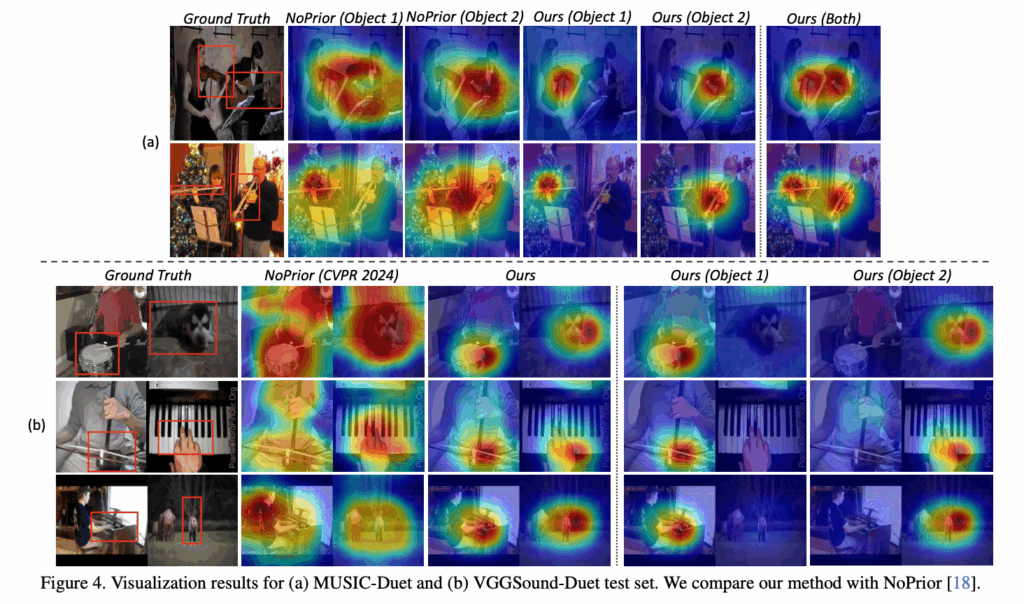
위 그림 4는 2개의 소리 객체가 동시에 존재할때의 association map 비교 결과입니다. 마찬가지로 2개의 source가 존재할때에도 더욱 높은 객체 분리도를 보여주는 것을 볼 수 있습니다.
이상으로 리뷰 마치겠습니다.
리뷰 잘 읽었습니다.
Q1. 듀엣(2개)에서의 ORI 효과는 확인된 것 같은데, 3개 이상의 동시 음원(트리오/쿼텟)으로 K가 커질 때 분리 성능과 계산량은 어떻게 스케일하나요?
Q2. 논문의 Motivation을 보니 좀 별개의 궁금증이 생겼는데…
화면 밖 음원, 벽 반사 등 소리는 있지만 화면 객체가 없는 경우에 모델이 어떻게 행동하는지, 그에 대한 평가가 있었는지 궁금합니다.. 그리고 현우님 연구인 VQA 에서는 이런 경우를 고려할 필요 없을까요?