arxiv 구경하다 새로운 VTR 연구가 나와서 리뷰해보려고 합니다.

- Conference: X
- Authors: Bowen Yang, Yun Cao, Chen He, Xiaosu Su
- Affiliation: Chinese Academy of Science
- Title: GAID: Frame-Level Gated Audio-Visual Integration with Directional Perturbation for Text-Video Retrieval
1. Introduction
텍스트-비디오 검색(T2VR)은 텍스트 쿼리에 맞는 영상을 찾아내는 기술로, 비디오 검색과 추천, 요약 등 다양한 서비스에서 활용 가능한 기술입니다. CLIP 같은 대규모 사전학습 모델의 등장으로 놀라운 성능 개선이 있었지만, 모달리티 간 격차와 시간적 복잡성 때문에 여전히 어려움이 존재합니다.
첫째, 대부분의 기존 연구는 오디오를 활용하지 않고, 비주얼 정보에만 의존하고 있습니다. 이로 인해 대화나 배경 소리 등 맥락 정보가 빠져 검색 정확도가 떨어질 수 있습니다. 예를 들어, 교실에서 한 남자가 이야기하는 장면은 시각적으로는 조용한 교실 장면과 유사하게 보일 수 있지만, 오디오가 없으면 구분이 어렵습니다.
둘째, 오디오를 사용하는 연구가 있긴 하지만, 아직 coarse 수준으로 통합하는 상황입니다. 다시말해, 대부분은 샘플 단위의 coarse 수준에서만 정보를 통합하고, 프레임별 의미 변화를 반영하지 못합니다. 비디오 속 오디오는 프레임마다 의미가 달라질 수 있는데(대화나 효과음 등), 이를 무시하면 부정확하거나 잡음이 많은 표현으로 이어질 수 있기 때문이죠.

Figure 1은 저자가 언급한 문제를 보여줍니다. (a) 프레임마다 의미가 변하는 오디오 대화나 특정 소리 효과가 들어있는 경우, 프레임마다 오디오의 중요도가 달라집니다. 이때는 오디오가 의미를 구분하는 데 큰 도움이 되기 때문에, 모델이 오디오에 높은 가중치를 주도록 학습해야 합니다. (b) 의미가 거의 없는 오디오 배경 소리나 주변 잡음처럼 의미 없는 소리가 지속되는 경우에는 오디오가 검색 정확도를 방해할 수 있습니다. 이럴 땐 오디오의 비중을 줄여야 하죠. 즉, 오디오가 항상 중요한 것은 아니며, 프레임마다 오디오의 중요도를 조절하는 게 필요하다는 점을 확인할 수 있습니다.
이 문제를 해결하기 위해 저자들은 GAID라는 새로운 프레임워크를 제안합니다. GAID에는 다음의 두 가지 모듈이 큰 핵심인데, Frame-level Gated Fusion (FGF)으로 프레임마다 오디오와 비주얼 정보를 동적으로 결합하고, Direction Adaptive Semantic Perturbation (DASP)으로 텍스트 임베딩을 안정화해 높은 강건성을 확보했다고 합니다. 본격적인 내용 설명 시작하겠습니다
2. Method
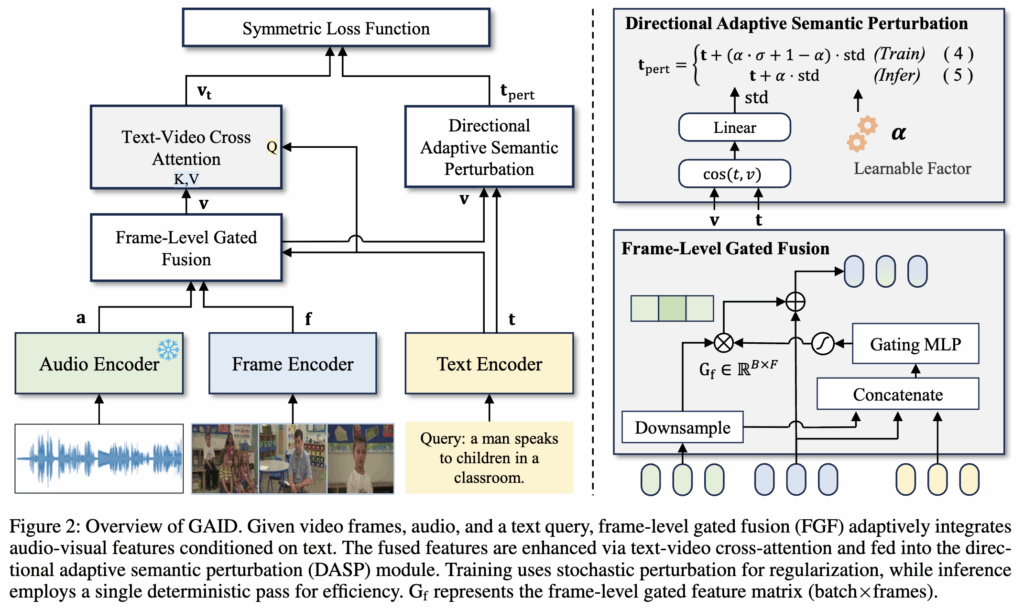
저자들은 제안하는 GAID의 목표는 오디오-비주얼 정보의 상호보완성을 충분히 활용하면서도 시간적 정렬(temporal alignment)과 표현의 강건성(representation robustness)을 유지하는 것입니다. 상단 그림에 GAID의 전체 구조를 보여주며, 두 가지 핵심 모듈로 구성되어 있습니다:
Frame-level Gated Fusion (FGF)
쿼리 텍스트를 조건으로 각 프레임의 오디오와 비주얼 특징을 동적으로 융합
Directional Adaptive Semantic Perturbation (DASP)
텍스트 임베딩에 구조적 정보를 반영한 방향성 노이즈를 주입해 강건성을 높임
2.1 Frame-level Gated Audio-Visual Fusion
앞서 말한 것처럼 오디오와 비주얼 정보는 시간에 따라 기여도가 크게 달라집니다. 예를 들어 일부 프레임에서는 대화나 특정 소리 효과는 중요한 의미를 제공하지만, 배경 잡음이나 침묵은 거의 도움이 되지 않습니다.
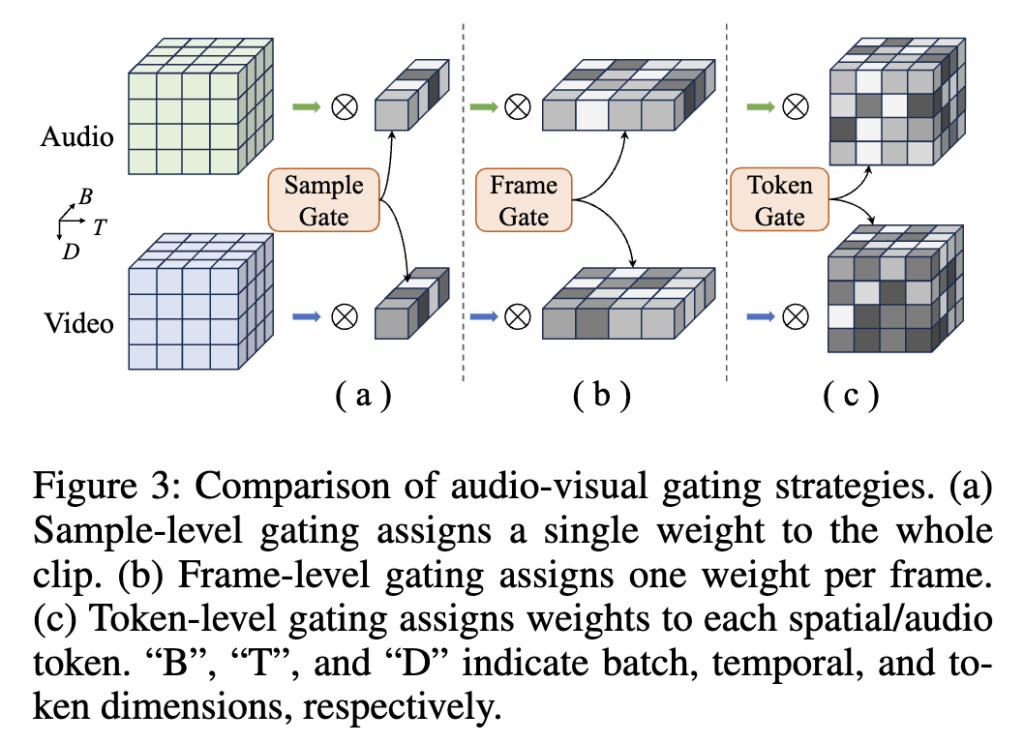
기존 연구에서는 비디오 전체에 동일한 가중치를 주는 sample-level fusion이나, 모든 패치나 스펙트로그램 토큰마다 가중치를 계산하는 token-level fusion 방식을 사용했습니다. 상단 그림 3이 바로 그 차이를 설명하는 그림입니다.
(a) Sample-level fusion은 연산은 가볍지만 프레임별 의미 변화를 반영하지 못합니다.
(b) Frame-level fusion은 프레임마다 하나의 게이트를 학습해 오디오와 비주얼의 웨이트를 조절합니다.
(c) Token-level fusion은 더 작은 단위로 연산하기 때문에 세밀한 표현을 얻을 수 있으나 계산량이 매우 크고, 텍스트 조건화 시 토큰 수준의 정보 누출(data leakage) 위험이 있다고 합니다
다시 frame-level fusion에 대한 설명으로 돌아가겠습니다. 비디오 프레임 임베딩과 오디오 임베딩, 그리고 텍스트 임베딩을 결합해 각 프레임의 게이트 값 g_i \in [0,1]을 계산합니다. 이후 이 게이트를 사용해 프레임별 오디오와 비주얼 특징을 가중합하여 최종 비디오 임베딩 v를 생성합니다.

이 방식은 계산량을 줄이면서도 프레임 단위의 시간적 변화를 반영할 수 있고, 모델이 쿼리 텍스트를 참고해 각 프레임에서 오디오와 비주얼 정보의 비중을 조절할 수 있다고 합니다. 마지막으로 이렇게 얻은 비디오 임베딩은 텍스트 임베딩과의 경량 cross-attention을 거쳐 멀티모달 상호작용을 한층 강화한 후 DASP 모듈로 전달됩니다.
2.2 Directional Adaptive Semantic Perturbation (DASP)
Frame-level Fusion이 오디오-비주얼 간의 격차를 줄여주지만, 텍스트 임베딩(text embedding)은 여전히 noise나 누락된 시각 정보에 영향을 받아 검색 정확도가 떨어질 수 있습니다. 이를 보완하기 위해 기존 T-MASS(CVPR24)라는 논문에서는 STP(Stochastic Text Perturbation)라는 방식을 사용했는데, 이 방법은 텍스트 벡터에 Random Noise를 추가해 모델이 입력 변화에 덜 민감하게 만드는 기법이라고 합니다.
하지만 STP에는 두 가지 큰 한계가 있습니다. (1) 노이즈가 아무 방향으로나 무작위로 추가되기 때문에, 실제로 중요한 의미를 강화하지 못하고 오히려 불필요한 차원까지 섞어버릴 수 있다. (2) 여러 번 샘플링을 해야 해서 추론 속도가 느려진다.
저자들은 이 문제를 해결하기 위해 DASP를 제안했습니다. 비디오와 텍스트 간의 상호작용으로 계산한 의미 있는 방향(variance direction)을 따라 노이즈를 추가하고, 학습 과정에서는 random성을 유지하지만 추론 시에는 단 한 번 계산으로 처리할 수 있도록 설계한 것이죠.
즉, DASP는 “아무 방향으로나 노이즈를 넣는 대신, 비디오와 텍스트가 실제로 차이가 나는 방향에만 노이즈를 주입”해 더 정밀하고 효율적인 정규화 효과를 주고자 하였다고 합니다.
DASP 동작 방식
먼저, 텍스트 임베딩t과 멀티모달 정보로부터 계산한 분산 벡터 \text{std}를 구합니다. 이 때, \text{std}는 노이즈를 추가할 방향을 나타내는 벡터입니다
기존 STP:
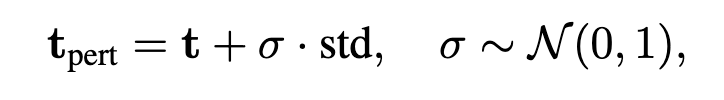
DASP 학습 시:
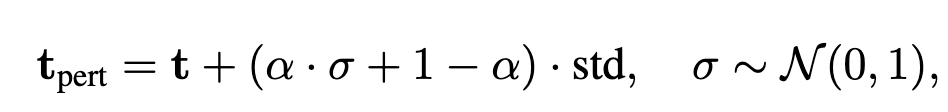
DASP 추론 시:
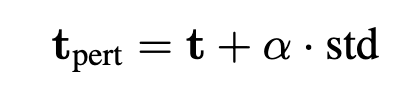
(\alpha는 learnable 파라미터)
Geometric Interpretation
아래 Figure 4는 DASP가 기존 방식보다 더 “방향성 있는” 정규화를 수행함을 보여줍니다.

DASP는 콘(cone) 모양의 방향성 영역 안에서만 노이즈를 넣어, 의미를 해치지 않으면서 필요한 변화만 반영합니다.
이 덕분에 모델이 텍스트와 비디오의 실제 의미 차이에 집중할 수 있습니다. 그에 반해, 기존 STP는 구(hypersphere) 상에서 모든 방향으로 동일하게 노이즈를 추가해 의미와 상관없는 변화가 많았다고 하네요.
2.3 Loss function
GAID는 모델의 robustness과 discriminability (구분 능력) 을 함께 높이기 위해 Dual-Branch Contrastive Loss를 사용했습니다.
Perturbation Branch (Robustness 확보)
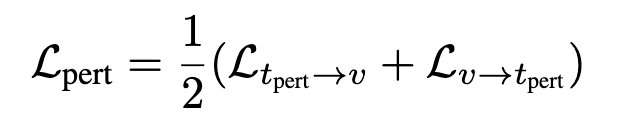
DASP로 생성한 노이즈가 추가된 텍스트 임베딩을 사용해 학습합니다. 의미가 조금 변해도 검색 결과가 안정적이도록 모델을 정규화하는 역할을 합니다.
Support Branch (결정 경계 강화)
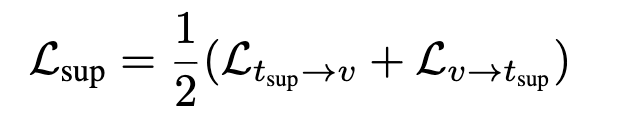
크로스모달 분산 방향으로 계산한 support embedding을 사용합니다. 이로 인해, 모델이 구분하기 어려운 샘플(worst-case positive)도 잘 구분할 수 있도록 한다고 합니다.
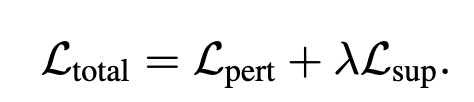
최종 Loss는 두 가지를 합쳐서 계산하였습니다. 지금까지 저자가 제안한 DASP를 기반으로 설계한 Loss function까지 알아보았습니다.
3. Experiments
3.1 Setting
Dataset
MSR-VTT, LSMDC, DiDeMo, VATEX
Evaluation Metric
Recall@K (R@1/5/10), Median Rank (MdR) and Mean Rank (MnR)
Backbone
CLIP (ViTB/32, ViT-B/16)
3.2 Benchmarks
(Table 1) MSR-VTT & DiDeMo: Text -> Video
GAID는 MSR-VTT, DiDeMo, VATEX, LSMDC 등 주요 벤치마크에서 기존 오디오 활용 기법(AVIGATE)이나 오디오 비활용 기법(T-MASS, ViCLIP)보다 일관되게 더 높은 성능을 보였다고 합니다.
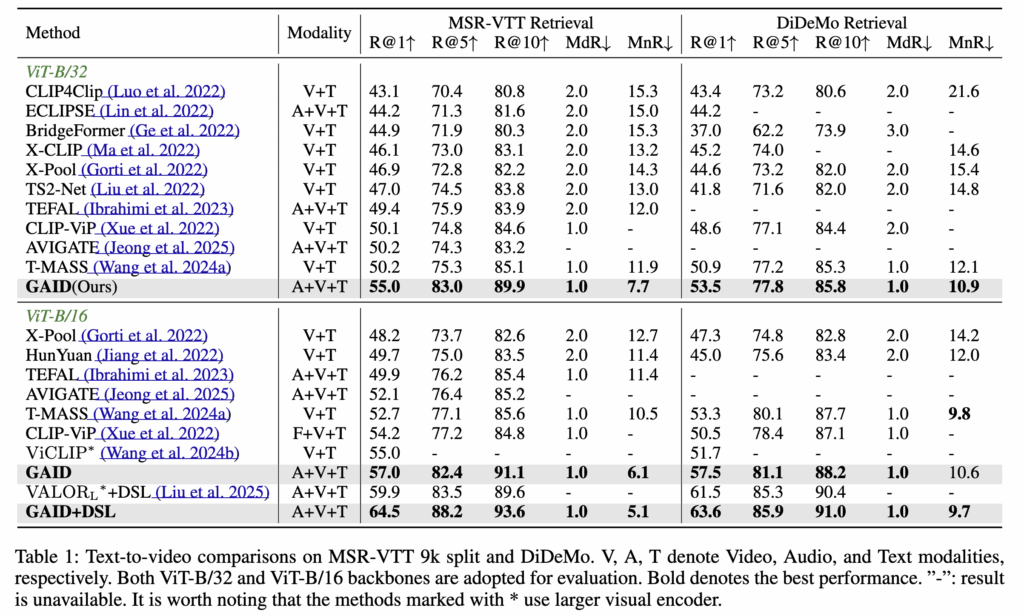
MSR-VTT
ViT-B/32 백본 기준 R@1에서 +4.8%, R@5에서 +7.7% 향상을 기록했습니다. ViT-B/16에서는 R@1 성능이 추가로 +2% 더 개선되었습니다.
DiDeMo
R@1에서 +2.6% 향상을 기록하며 R@5, R@10 지표에서도 일관된 성능 개선을 보였습니다.
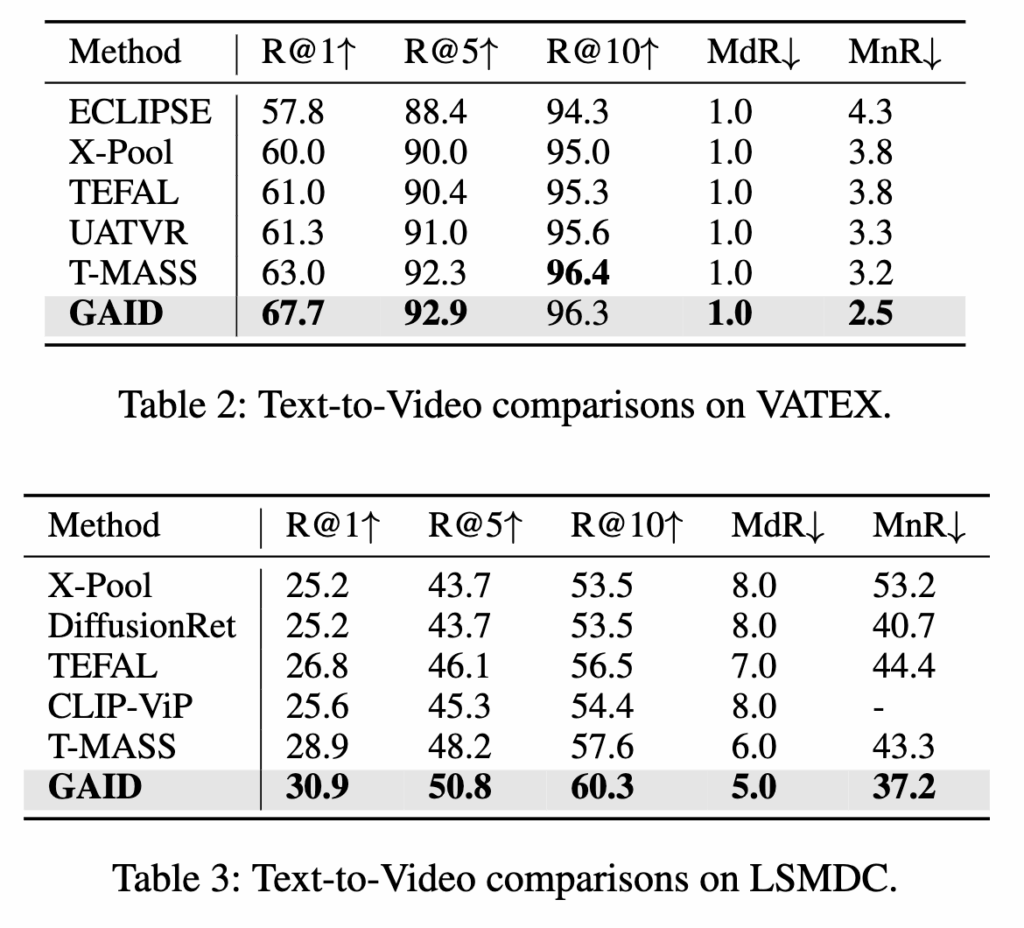
VATEX, LSMDC
R@1에서 각각 +4.7%, +2.0% 향상을 달성했습니다.
또한 CLIP-ViP처럼 프레임별 텍스트 설명을 추가한 모델보다도 GAID가 모든 지표에서 더 나은 성능을 보여 저자가 제안하는 모듈의 개선을 확인할 수 있었다고 합니다.
(Table 4) MSR-VTT: Video -> Text
보통 성능 리포팅 시 Text->Video, 그리고 Video->Text 를 동시에 리포팅하는데.. 왜 일부만 했는지…
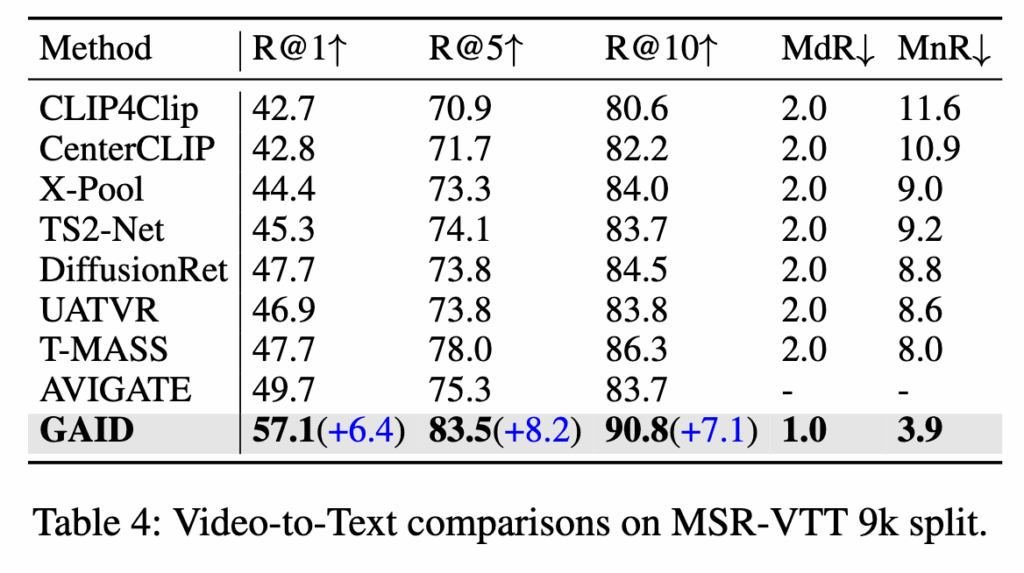
영상-텍스트 실험에서도 GAID는 AVIGATE 대비 R@1 +6.4%, R@5 +8.2%, R@10 +7.1% 향상하는 결과를 보였습니다.
3.2 Ablation Study
GAID는 오디오-비주얼 정보를 결합하는 세 가지 수준인 샘플 단위(Sample-level), 프레임 단위(Frame-level), 토큰 단위(Token-level) 융합을 비교했습니다.
(Table 5) Fusion Level Comparison
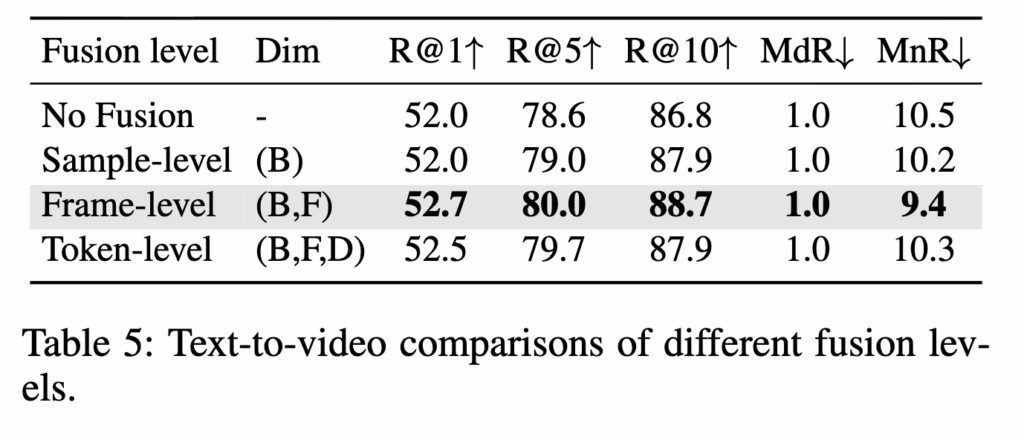
그 결과는 Frame-level Fusion이 계산 효율성과 모델링 세밀함 사이에서 가장 좋은 균형점을 제공한다는 점을 확인시켜줍니다.

Figure 5에서는 프레임 단위 게이트의 동작에 대한 정성적 결과입니다. 대화나 중요한 소리가 있는 구간에서는 게이트 값이 높아지고, 의미 없는 배경 소음이 많은 구간에서는 게이트 값이 낮아지며 오디오를 억제하였다고 합니다. 이를 통해 프레임 단위 융합이 오디오의 중요도를 동적으로 조절해 비디오-텍스트 정렬을 강화한다는 점을 확인할 수 있습니다.
(Table 6) DASP Ablation Study
저자가 제안하는 DASP 모듈의 효과를 확인하기 위해 기본 모델(no perturbation), 기존 STP(Stochastic Text Perturbation), DASP를 비교했습니다.
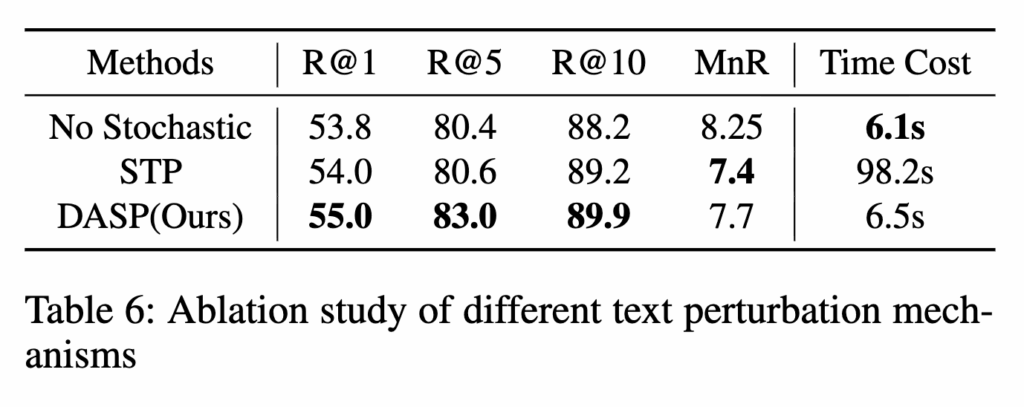
DASP가 55.0%로 가장 높은 검색 정확도를 달성했습니다. 또한 STP는 여러 번 샘플링(예: 20회)이 필요해 98.2초가 걸린 반면, DASP는 단일 패스로 6.5초에 처리가 가능합니다. 이는 STP 수준의 강건성을 유지하면서도 속도를 대폭 단축시켰음을 보여줍니다.
4. Summary
GAID는 텍스트-비디오 검색에서 오디오 정보를 활용하고 노이즈를 추가하여 텍스트 임베딩을 안정화함으로써 검색 성능을 향상시키는 프레임워크입니다. 기존 연구들은 대부분 시각 정보에만 의존하거나 오디오를 단순히 합치는 수준에 머물러 있어 중요한 맥락 정보를 놓칠 수 있었습니다. 또한 텍스트 임베딩은 누락된 프레임이나 잡음에 쉽게 영향을 받아 검색 성능이 불안정했습니다. 이를 극복하고자, 첫째 Frame-level Gated Fusion (FGF)에서 프레임 단위로 오디오와 비주얼 정보를 동적으로 조합하여, 중요한 대화나 소리 구간에서는 오디오에 더 높은 가중치를 주고, 불필요한 잡음은 억제하도록 설계했습니다. 둘째 Directional Adaptive Semantic Perturbation (DASP)에서 비디오와 텍스트 간의 차이를 분석해 의미 있는 방향으로만 노이즈를 추가하는 기법으로, STP보다 훨씬 적은 연산량으로도 강건성을 확보했다고 합니다.
논문에서의 문제정의인 오디오의 중요성은 프레임마다 달라질 수 있다는 점을 명확히 문제로 정의한 것은 설득력있었습니다. 즉, 프레임 단위로 오디오-비주얼 융합을 설계한 부분은 납득이 되는 문제정의였습니다.
그치만 아쉬운 점도 있습니다. 실험에서 제안 기법의 장점만 강조하고, 한계나 부작용에 대한 검증은 다소 부족했던 것 같습니다. 예를 들어, 프레임 단위 오디오 게이팅이 실제로 어떤 상황에서 실패하는지, DASP가 지나치게 방향을 제한했을 때 의미 있는 표현을 놓치지는 않는지에 대한 내용이 없지 않았나….
안녕하세요, 주영님. 좋은 논문 리뷰 공유 감사드립니다.
프레임 단위로 오디오와 비주얼 정보를 융합하는 방식이 흥미롭게 느껴졌습니다.
리뷰를 읽으면서 두 가지 궁금증이 생겼는데,
첫번째로는, 프레임 단위로 fusion을 진행할 경우 장면 전환(scene change)과 같이 맥락이 급격히 바뀌는 구간에서는 모델이 안정적으로 학습하기 어려울 수 있다는 생각이 드는데, 이에 대한 고려가 있었는지 궁금합니다.
둘째, DASP 모듈에서 의미 있는 방향으로 노이즈를 추가하는 방식은 강건성을 높이는 데 효과적일 것으로 보이지만, 반대로 특정 방향에 집중하게 되어 오히려 표현 공간을 과도하게 제약하거나 overfitting을 유발할 가능성은 없는지도 알고싶습니다.
다시 한번 좋은 리뷰 공유해주셔서 감사드립니다. 🙌
좋은 질문 감사합니다.
Q1. 장면 전환 문제는 프레임 게이트가 단순히 연속성만 보지 않고 텍스트 쿼리에 조건부로 학습되기 때문에, 전환 구간에서도 텍스트와 관련된 프레임을 우선적으로 반영하도록 설계되었습니다. 다만, 별도의 장면 전환 실험은 진행되지 않아 실제로 실험을 통해 검증이 필요할 것 같습니다.
Q2. DASP는 무작위 교란(STP)과 달리 비디오-텍스트 분산을 따라 의미 있는 방향으로만 노이즈를 주입하기 때문에 불필요한 차원 교란을 줄이고 강건성을 확보할 수 있다는 것이 기존 방법론 대비 장점입니다. 학습 시 다양성을 유지하면서도 추론 시 단일 패스로 동작해 과도한 제약을 피하도록 설계했지만, 지적하신 overfitting 부분은 더 넓은 데이터셋에서 검증이 필요할 것 같네요! 좋은 지적인 것 같습니다
안녕하세요 좋은 리뷰 감사합니다.
저자가 제안한 DASP와 관련해, 원래 이 모듈로부터 얻고자 한 효과는 ‘학습 때 최대한 다양한 방향의 텍스트 feature를 봄으로써 추론 때 들어올 수 있는 여러 텍스트 쿼리에 강인하게 동작한다’가 맞나요?
맞다면 혹시 저자가 강인성을 갖추고자 하는 그 ‘다양한 문장’은 기존과 어느 정도의 차이인지 자연어 레벨에서 알고싶어 여쭈어보았습니다. 혹시 평가 때 DASP에서 개선해준 강인성을 확인해볼만한 데이터셋 벤치마크는 없었으려나요?
학습 때 다양한 텍스트 feature를 봐서, 텍스트 쿼리에 강인하게 동작이 맞나?
-> 네, 말씀하신 대로 저자가 DASP를 통해 얻고자 한 핵심 효과는 학습 시 텍스트 임베딩에 다양한 방향의 변형을 주입함으로써, 실제 추론 시 들어올 수 있는 여러 형태의 텍스트 쿼리에 더 강인하게 대응하는 것입니다. 구체적으로는 같은 문장이더라도 임베딩 공간에서 조금씩 다른 방향으로 표현되도록 노이즈를 추가하는 것이죠. 즉, 문장 자체를 새롭게 생성하거나 패러프레이징(paraphrasing)하는 수준은 아니고, 표현 공간에서의 분산을 넓혀 작은 의미 변화나 잡음에도 흔들리지 않게 만드는 설계입니다.
평가 측면에서는 DASP의 강인성이 특정 자연어 패러프레이징 벤치마크로 직접 검증된 것은 아닙니다. 대신 논문에서는 MSR-VTT, DiDeMo 등 기존 Video-Text Retrieval 벤치마크에서 R@1, R@5 성능 개선을 통해 간접적으로 효과를 보여준 것이 전부인 것 아닐가 싶네요.
또한 STP 대비 단일 추론 패스로 강건성을 확보하면서 효율성까지 유지했다는 점을 정량적으로 제시했지만, 말씀 주신 것처럼 “다양한 문장 표현”에 대해 자연어 레벨에서 강인성을 평가하는 실험은 아쉽게도 포함되어 있지 않았습니다.