
이번 Visual Localization과 관련된 창의학기제를 진행하면서 읽게된 논문입니다. VLAD 논문을 읽고 리뷰 한 후 NetVLAD를 리뷰하고 싶었지만, 저에게 VLAD 논문이 읽는게 조금 어려워 바로 NetVLAD로 넘어가 읽고 리뷰하게 되었습니다.
우선 NetVLAD의 발전 과정에 대해 설명드리겠습니다. NetVLAD는 VLAD를, VLAD는 BoVW를 발전시킨 방법론인데요, 순서대로 간략히 설명드리겠습니다.
BoVW (Bag of Visual Word == Bag of Word == Bag of Feature)는 SIFT 등으로 전체 이미지의 local descriptors를 뽑고 K-means 알고리즘을 통해 k개의 cluster center를 갖도록 정렬 후, 다시 각 이미지마다의 descriptors와 가장 가까운 cluster center의 histogram을 global descriptor로 사용합니다.
VLAD는 여기서 단순히 histogram을 쌓는것이 아니라, cluster center와의 거리를 구한후 더한 벡터를 global descriptor로 사용합니다.
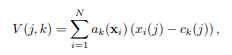
Net VLAD는 거리 vector를 구할 때, 오직 가장 가까운 cluster center만이 아니라, 모든 cluster center와의 vector를 구하는데, 이때, softmax를 가중치로 곱하여줍니다. 또 다른 차이점들이 존재하는데, local descriptors를 SIFT 등의 방법이 아닌, CNN을 통해 추출하며, cluster center또한 k-means가 아니라 CNN을 통해 학습하여 점차 개선해 나갑니다.
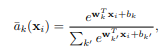
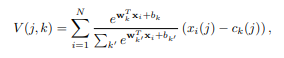
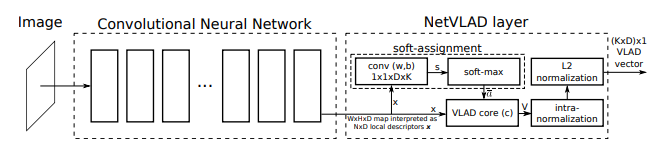
NetVLAD의 학습 과정에 대해 설명해 드리겠습니다.
1. input image가 들어오면, 전처리 (resize, normalize 등)후 Back bone network( VGG 16, ResNet 등)에 태웁니다.
2. fc layer 전 까지의 layer를 통과한 feature를, cluster center로 정할 수를 out dimension으로 하는 conv 2d layer를 통과시킵니다.
3. feaure를 1D로 펼치면 식3.의 x(j) 가 됩니다. 그 feature를 softmax 계산을 하면, 식 2.의 ak 가 됩니다. centroid인 c(j)는 처음에 임의로 정해준후, 학습을 통해 개선시킵니다.
4. 식3.을 통해 descriptor를 만듭니다.
Loss function은 아래와 같습니다.
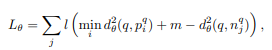
q는 query, p는 query 에 대해 positive인 descriptor, n은 query에 대해 negative인 descriptor 입니다. input image에 대해 positive와 negative를 함께 주고, 셋 모두의 vlad를 뽑은 후, 거리를 구한 값이 positive와 query는 가까워지도록, negative와 query는 멀어지도록 loss를 계산하여 학습시킵니다.
그러면 모델은 위 그림처럼, 최적의 centroid를 찾도록 학습된다.
netvlad의 metric learning을 이용한 대표적인 방법론 중 하나이며, data의 positive와 negative 정의가 까다로운 문제인데요. netvlad 저자는 어떠한 기준으로 data를 나눴다고 하는지에 대한 내용이 추가 되었으면 좋겠습니다. 그리고 본인이라면 어떻게 나누고 싶은지 의견이 궁금합니다.
NetVLAD Layer에서 intra-normalization 후 L2 normalization을 하는데 이 것에 대한 이유나 의미를 알려주실 수 있을까요?? 그리고 식 (1),(2),(3)에 대한 표기가 있으면 좀 더 보기 편할듯 합니다!