안녕하세요, 허재연입니다. 이번에도 video 기반의 Scene Graph Generation(SGG) 논문을 들고 왔습니다. 오늘 다룰 논문은 IEEE TRANSACTIONS ON MULTIMEDIA(TMM)에 게재된 논문으로, object의 식별에 집중한 논문입니다. 리뷰 시작하겠습니다.

Scene Graph Generation은 scene understanding을 위한 task로, 주어진 장면 내의 물체들을 찾고 이들 간의 관계(relationship) 식별하는 것을 목표로 합니다. Video Scene Graph Generation(Dynamic SGG나 Spatio-Temporal SGG라고도 합니다)은 이를 video로 확장한 task로, 주어진 video의 각 프레임에서 물체 및 이들간의 관계를 찾습니다. 보통 Action Genome이라는 charades dataset을 Video SGG에 맞게 새로 annotation한 데이터셋을 사용하기 때문에, 본 논문에서는 사람과 active object 간의 관계를 찾는 문제로 정의합니다.
기존 많은 Video SGG 방법론들은 Faster RCNN을 사용해서 각 비디오 프레임에서의 object proposal을 생성하고, 이들의 object class와 relation을 예측하는 방식으로 수행되었습니다. 비디오의 경우 이미지에 추가적인 temporal 축이 생기기에 이 부분은 각 방법론마다 다양한 방법으로 처리해왔습니다. 저자들은 video sgg가 일반적으로 사람 및 사람과 상호작용하는 물체의 관계가 중요하기에 다수의 관련 없는 객체 사이에서 이런 active object를 찾아야 하는 점에 집중합니다.
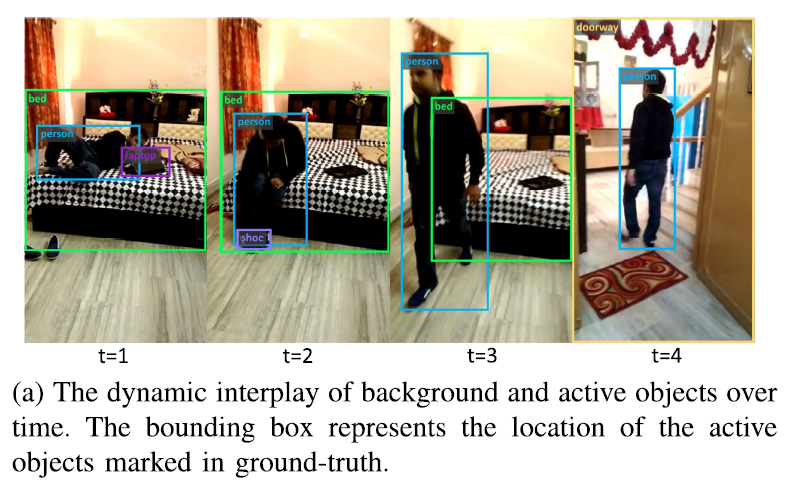
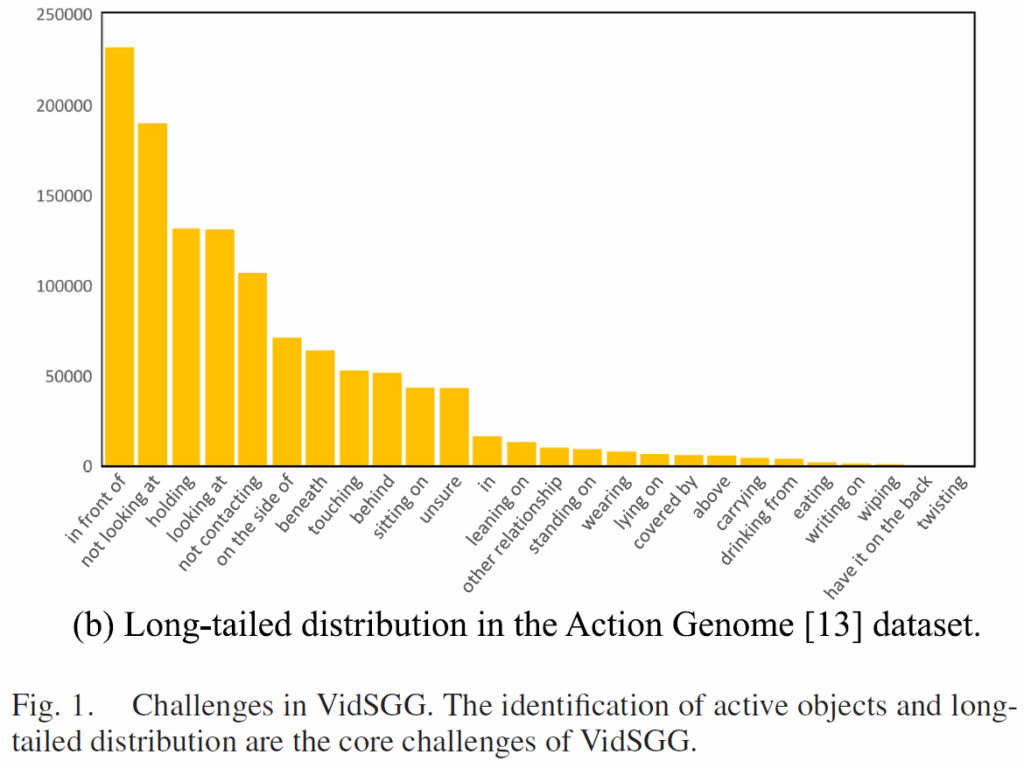
위 Fig1(a)에서 나타나듯 active object와 background object 간 구분에는 시간에 따른 관계 및 정보 변화, 인간과의 상호작용 변화, 촬영 시점의 변화 등 고려해야 할 점이 많습니다. 이 뿐만 아니라, 아래 Fig1(b)에서 확인할 수 있 Video SGG 벤치마크에 사용되는 Action Genome 데이터셋의 경우 relation class가 뚜렷한 long-tailed distribution을 보입니다. 분포의 tail class(wiping, twisting ..)에 속한 술어들이 head class(touching, holding)보다 더 풍부한 의미를 내포하는 경우가 많은데, 학습 과정에서 효과적인 학습 supervision이 없다면 빈도가 높은 head class에 편향된 예측을 하게 될 가능성이 높습니다.
기존 연구들의 경우 주로 시공간 문맥 정보를 효과적으로 처리하는 데 집중해왔고 일부는 relation의 long-tailed distribution을 해결하는데 집중해왔습니다. 저자들은 이런 기존 방법론들이 데이터셋에서 active한 물체를 식별 능력이 제한적이라는 점에도 집중해서, VidSGG를 위해 STABLE(Spatial-Temporal sAliency guided unBiased contrastIve LEarning)이라는 새로운 프레임워크를 제안합니다. 우선 사람이 비디오를 인식할 때 active object에 우선적으로 집중하는 경향에 착안하여 salient 개념을 도입하고 추가적으로 temporal 정보 처리를 수행할 수 있는 Active Object Retriever(AOR)을 도입합니다. 추가적으로 relation class의 long-tail 분포 문제를 완화하기 위해 URRL(Unbiased Relationship Representation Learning) 모듈을 추가하였습니다. 각 방법론의 세부 사항은 아래에서 살펴보겠습니다.
저자들이 주장하는 contribution은 다음과 같습니다 :
- STABILE 프레임워크 제시: motion cue를 활용한 saliency fusion과 시간적 일관성 인코딩을 결합하고, 여기에 추가적으로 active object 필터링 전략을 더해 active한 객체 인식 정확도를 향상시켰다.
- unbiased relation 표현 학습 강화 : supervised contrastive learning에 UML contrastive loss와 logit 보정 BCE를 통합하여 long-tail 분포 문제를 완화했다.
- Action Genome 데이터셋에서 다양한 실험 및 검증을 통해 제안하는 프레임워크 STABILE의 효과를 입증하였다.
Method
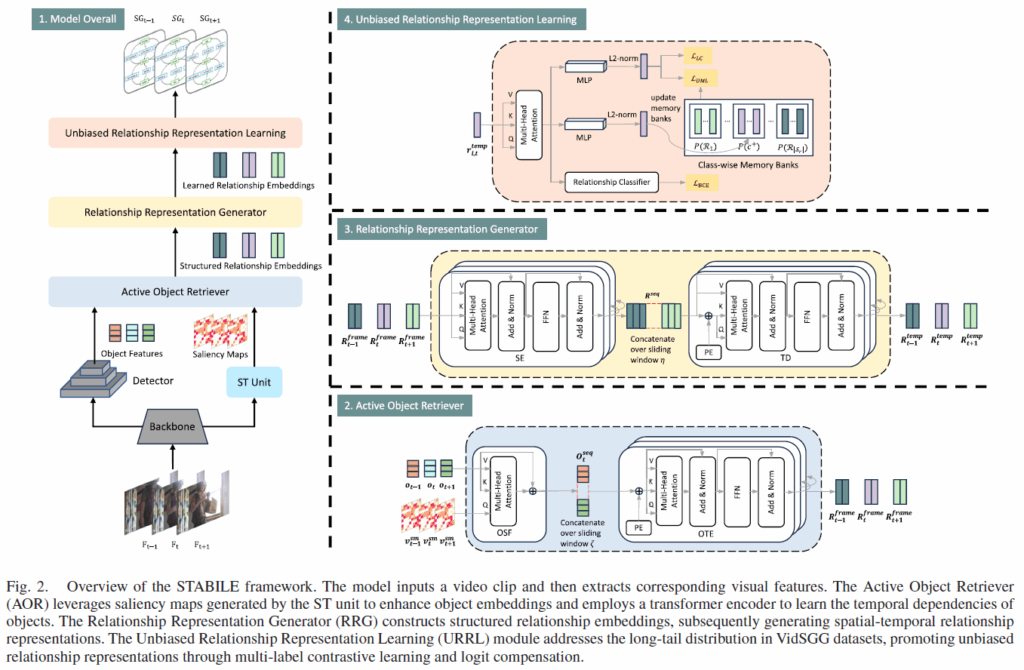
Video Scene Graph Generation(VidSGG)에서는 비디오 클립이 주어지면 각 프레임마다 적절하게 물체를 인식하고 이들 간의 관계를 식별하는 것을 목표로 합니다. 일반적으로 Action Genome dataset을 사용하는데, 해당 데이터셋은 사람과 물체 간 관계를 인식하는데 초점이 맞추어져 있어 저자들은 사람과 active object를 잘 검출하고 이들 간의 관계 예측 정확도를 높이고자 합니다. 아래 Figure 2는 제안하는 STABILE의 전체 프레임워크를 보여줍니다.
STABILE은 크게 1. Relationship Representation Generator(RRG), 2. Active Object Retriever(AOR), 3. Unbiased Relationship Representation Learning(URRL) 모듈로 구성됩니다. RRG는 STTran의 spatial-temporal transformer를 기반으로 설계되었고, AOR은 활동 객체를 식별하도록 설계되었으며, 마지막으로 URRL 모듈은 long-tail bias를 완화하기 위해 설계되었습니다.
Object Detection and Active Object Retriever
우선 비디오 클립이 주어지면 먼저 ResNet backbone으로 각 프레임의 임베딩({v}_{t})을 뽑아닙니다. 이후 Faster RCNN을 기반으로 각 프레임의 object embedding, bounding box, 물체 클래스 예측값을 출력합니다. 비디오가 아닌 정적 이미지로 학습한 object detector는 시공간 정보를 모두 활용해 active object를 식별하는 능력이 부족하기 때문에, 저자들은 active object를 식별하고 temporal consistency를 유지할 수 있도록 Active Object Retriever(AOR)을 설계했습니다. 위 Fig.2의 오른족 아래에 보이듯 AOR에서는 CA block으로 객체 임베딩과 saliency map을 fusion하고, spatial-temporla dependency를 포착하기 위해 트랜스포머 기반 object encoder를 사용합니다. 추가적으로, 다수의 background object 중에서 활동 객체(active object)를 선별하기 위해 필터링을 수행합니다.
ST Unit
저자들은 video saliency detection 분야의 SCAM 이라는 방법론에서 ST Unit을 활용하여 video frame의 saliency map을 생성한다고 합니다. 구체적인 연산은 다음 수식 (1)과 같습니다.
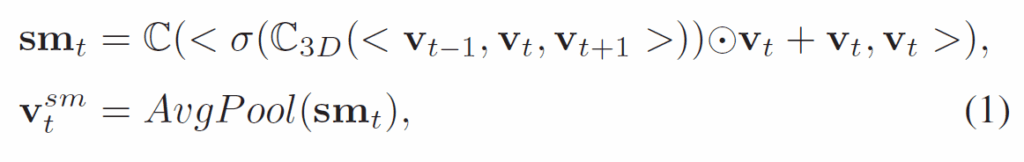
수식 (1)에서 {sm}_{t}은 t번재 프레임의 saliency map이고, {v}^{sm}_{t}는 t번째 프레임에 대한 motion cue 정보가 첨가된 enhanced frame embedding입니다. <,>는 concatenation, σ는 sigmoid 함수, ⦿는 element-wise multiplicative 연산이고 C(·)와 C_3D(·)는 각각 convolution, 3D convolution을 의미합니다. AvgPool(·)은 당연히 average pooling입니다. ST Unit은 Binary Cross Entropy Loss {L}_{ST}로 학습합니다.
saliency map이 나름 중요한 요소인데, AG 데이터셋이나 SGG에 알맞게 새로 제안하기보다는 기존에 제안된 프레임워크를 그대로 가져와서 생성한 것 같네요. 추가적인 자세한 언급은 없습니다.
Saliency Fusion for Object Embeddings
위에서 얻은 saliency map은 이제 active object를 강조하는 효과를 주기 위해 feature에 통합되어야 합니다. 이는 Object Saliency Fusion(OSF)에서 수행됩니다. Fig2에서 확인할 수 있듯 OSF블록은 Multi-head cross attention로 수행되며, OSF 모듈의 입력값은 각각 Q = {v}^{sm}_{t}, K = V = {o}_{i,t}입니다. 이 때 t번째 프레임의 object proposal i에 대한 fused object embedding {o}^{fused}_{i,t}은 다음 수식 (2)와 같습니다.
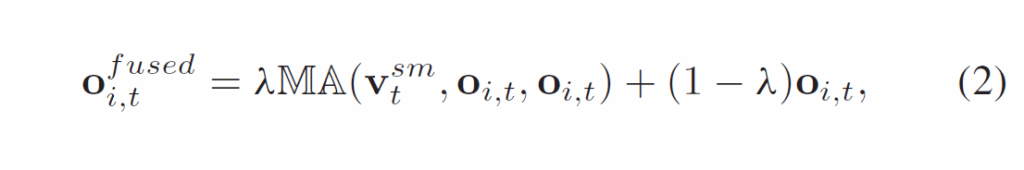
여기서 {o}^{fused}_{i,t}∈{R}^{2048}입니다.
Object Temporal Encoder
video 데이터에서 물체의 feature를 처리할 때는 비디오 안의 여러 프레임에 걸쳐 temporal dependency를 포착할 필요가 있습니다. 저자들은 이를 위해 transformer encoder 구조를 기반으로 프레임 별 object sequence를 처리하는 Object Temporal Encoder(OTE)를 사용하였습니다. 처리 과정은 다음 수식 (3)과 같습니다.
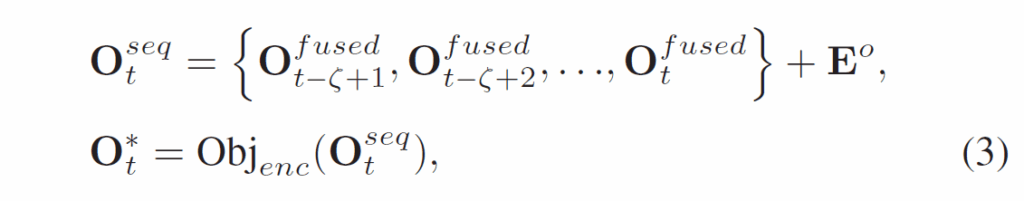
{O}^{fused}_{t}는 t번째 프레임의 frame-wise object embedding 벡터 집합을 의미하고, {E}^{o} = {{e}^{o}_{1}, {e}^{o}_{2}, ... , {e}^{o}_{ζ}}는 각 물체의 시간적 위치 정보를 주입하기 위한 positional encoding입니다. Ojb_enc(·)는 object temporal encoder입니다.
Object Classification and Active Object Filtering
각 물체의 클래스는 OTE에서 최종 출력된 object embedding으로 수행되며, 분류기는 CA loss {L}_{o}로 학습됩니다. 여기에 Active Object를 더 잘 식별하기 위해 Active Object Filtering(AOF)를 추가합니다. 간단한데, 학습 단계에서 object cateogory 집합에 background label을 포함시켜서 배경과 전경을 구분할 수 있게 하고 이후 validation / test 단계에서는 분류기 출력해서 background category를 제외하게 됩니다. 이런 필터링 전략을 추가하면 object classifier의 성능이 상당히 좋아진다고 하네요.
Relationship Representation Generator
물체를 인식했다면, 이제 이들 간의 관계를 정밀하게 예측해야 합니다. 관계 표현 생성기(RRG)에서는 relation embedding을 받아 물체 간 relation representation을 생성합니다. 저자들은 기존 TEMPURA라는 연구의 접근법을 참고하여 STTran의 Spatial-Temporal Transformer와 유사하게 RRG를 구성하였다고 합니다.
Structured Relationship Embedding
우선, subject-object pair의 relationship embedding을 다음과 같이 정의합니다.
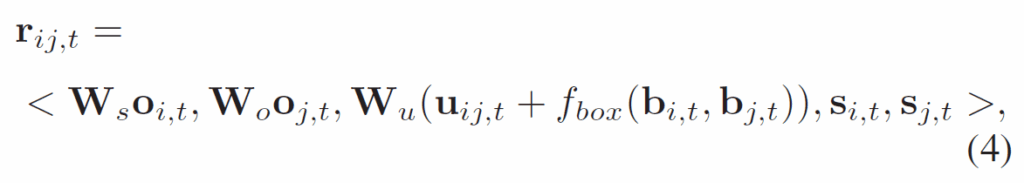
여기서 {r}_{i,j,t}는 t번째 프레임에서 주어 i와 목적어 j 의 relationship embedding이고, {u}_{i,j,t}는 후보 객체 i, j에 대해 RoIAlign을 적용한 union box의 feature map입니다. 각 {W}_{s}, {W}_{o}, {W}_{u}는 차원 압축을 위한 linear matrix입니다. {f}_{box}(·)는 bounding box -> feature map으로 매핑하는 projection이고, {s}_{i,t}, {s}_{j,t}는 {c}_{i,t}, {c}_{j,t}의 semantic glove embedding이라고 합니다.
Relationship Representation Generator
RRG는 공간 인코더(spatial encoder)와 시간 디코더(temporal decoder)로 구성됩니다. 공간 인코더는 프레임 내 시각적 관계 및 공간적 문맥을 포착하고, 시간 디코더는 이후 여러 프레임에 걸쳐 관계의 temporal dependency를 포착합니다. 공간 인코더는 다음과 같이 각 프레임의 relationship spatial context를 입력으로 받아 처리합니다.
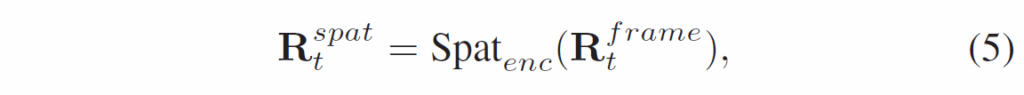
여기서 Spat_enc는 트랜스포머 인코더 구조의 공간 인코더입니다.
이후 시간 디코더의 입력값은 다음과 같이 구성되어 입력됩니다.
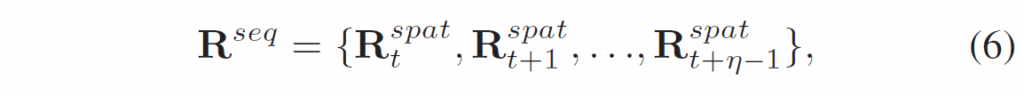
여기서 t는 각 프레임을, η는 sliding window 크기를 의미합니다. 이후 이 값들은 temporal decoder에 입력되어 처리됩니다.
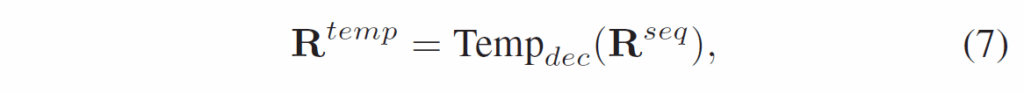
여기서 {R}^{temp} = {{R}^{temp}_{t}, {R}^{temp}_{t+1}, .. {R}^{temp}_{t+η-1}}이고, {R}^{temp}_{t}는 각 프레임의 relation representation 집합입니다. 시간 디코더의 이름이 디코더이긴 하지만, 기본적인 구조는 transformer encoder라고 생각하시면 됩니다.
Unbiased Relationship Representation Learning(URRL)
VidSGG에는 기본적으로 relation class의 long-tail 문제가 있기에 URRL 모듈로 이를 완화합니다. Unbiased Multi-Label(UML) contrastive loss와 logit-compensated binary cross-entropy loss로 구성됩니다.
Contrastive Learning
기본적으로 supervised contrastive loss는 다음과 같이 구성됩니다.
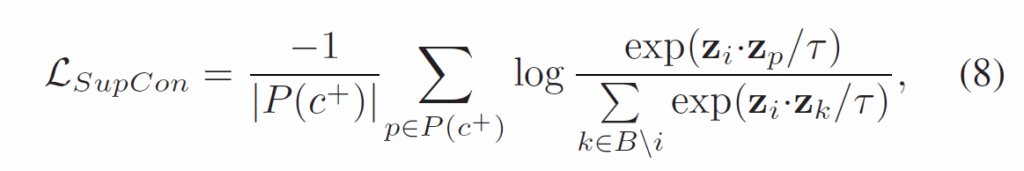
저희가 자주 만나볼 수 있는, positive sample끼리 거리는 가깝게, negative sample끼리 거리는 멀어지게 만드는 loss입니다. 문제는 이 loss 가 단일 라벨 문제 상황에서는 효과적이지만, Action Genome은 기본적으로 다양한 relation이 동시에 라벨링되어있는 multi-label 환경이기에 그대로 적용할 수는 없습니다. 이에 저자들은 기존의 multi-label contrastive learning을 다룬 선행 연구들을 바탕으로 다음과 같은 multi-label contrastive loss를 사용했다고 합니다 :
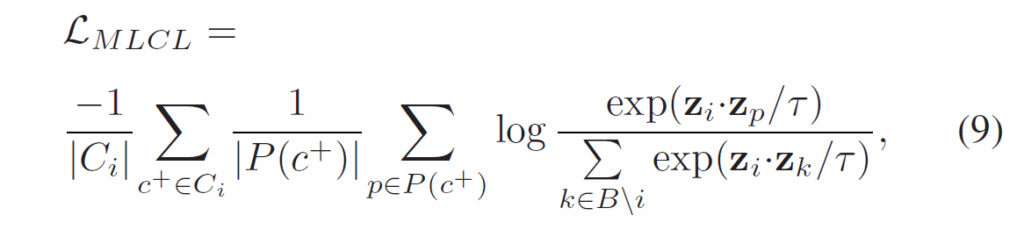
{C}^{i}는 instance i와 연관된 multiple class label 이고, P(c)는 배치 B에서 클래스 c로 라벨링된 샘플 집합입니다.
Unbiased Multi-Label Contrastive Loss
위 {L}_{MLCL}을 멀티라벨 과제에 적용할 수는 있으나, 바로 적용할 경우 1. 배치 내 모든 샘플들을 동일하게 취급하기에 long-tail 분포로 head class의 영향이 과도해질 수 있고, 2. 단일 배치만 사용할 경우 모든 클래스가 등장한다고 보장할 수 없어 샘플 다양성 확보에 제약이 있다고 합니다. 이를 극복하기 위해 {L}_{MLCL}에 class-wise averaging을 도입해 다음의 unbiased multi-label contrastive loss를 도입했다고 합니다.
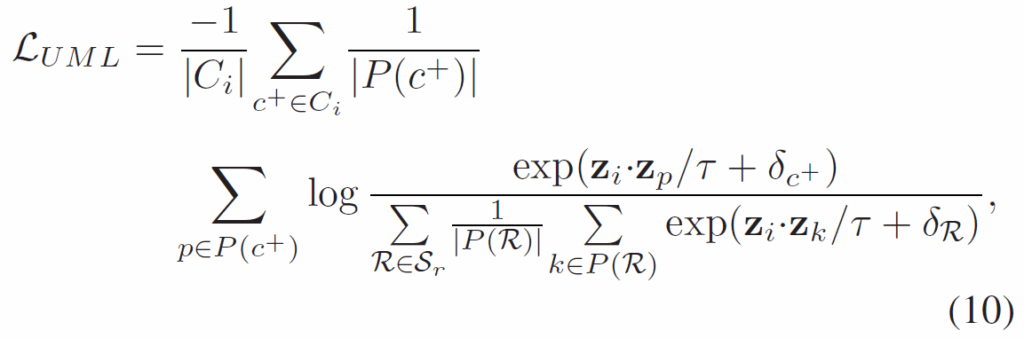
여기서 P(R)은 모든 대조 샘플 중 클래스 R로 annotation된 annotaed 샘플 집합, {S}_{r}은 모든 relation category 집합입니다.
Logit Compensation
기존 연구들에서 단일 라벨 long-tail classification에서 logit compensation을 도입해 문제를 완화했던 것을 참고해서, Video Scene graph generation에 이를 위한 binary cross-entropy loss를 추가적으로 적용시킵니다.
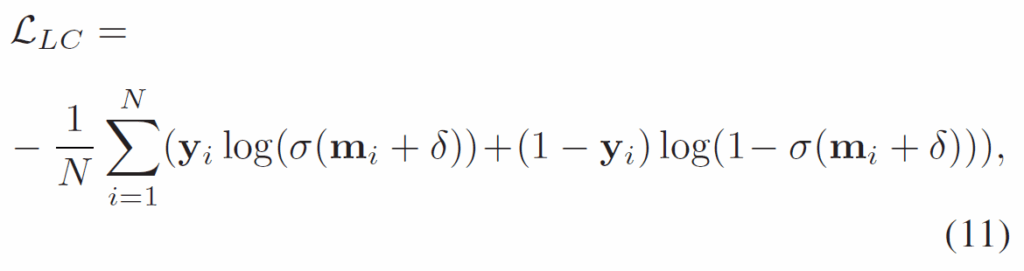
여기에 relation classification loss로 binary cross entropy {L}_{r} 을 추가하여 최종적으로 다음 loss 식을 사용해 학습을 진행합니다.
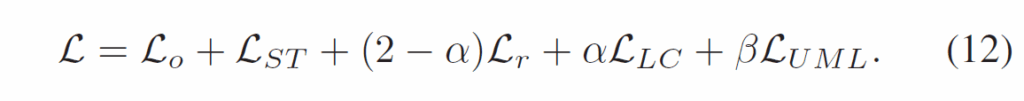
Experiment
기존 연구들과 동일하게 데이터셋은 Action Genome이 사용되었으며, 지표도 R@K 및 mR@K가 사용되었습니다. 세팅도 동일하게 SGDET, SGCLS, PREDCLS를 리포팅하였습니다. 본래 이것들을 모두 리포팅해야 하는데, 일부만 리포팅한 논문들을 몇 개 보다보니 이렇게 모든 결과를 보여주면 꽤나 experiment 부분이 충실하게 작성됐다고 느껴집니다. 실험은 학습까지 모두 Tesla V100 GPU 한장에서 진행되었다고 합니다. 전반적으로 Video SGG쪽 연구들이 GPU 한장, 많아 봤자 4장 정도인 것으로 파악되는데, 오히려 Visual Genome을 사용하는 Image SGG쪽보다 학습 리소스가 적게 드는 것 같습니다. 사실 요즘 연구 분야를 정할 때 요구 GPU 스펙이 굉장히 중요하기 때문에 한번씩 체크하게 되네요.
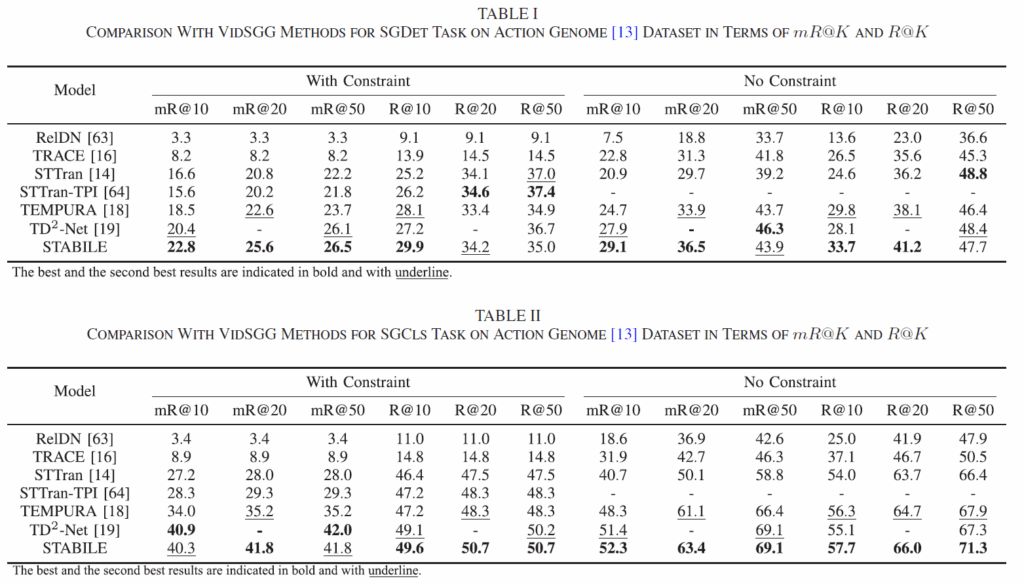
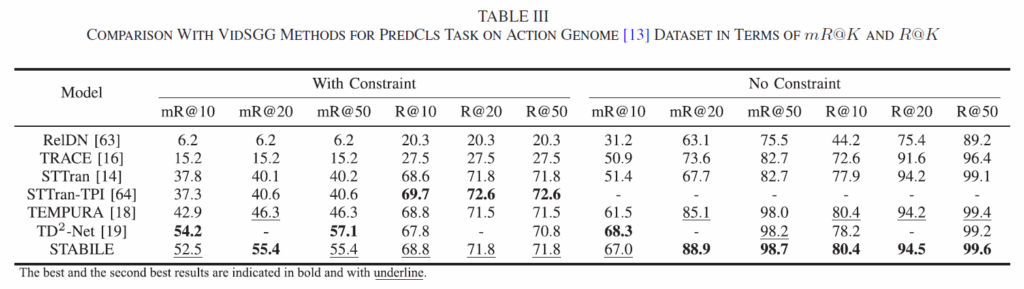
비교한 논문들을 보면 2023-2024 논문들이 보이고, 2025 방법론은 없습니다(Transaction이니 리뷰 및 리비전 기간을 고려해야겠죠) 전반적으로 with constraint, no constrait, mR@K, R@K, SGDET, SGCLS, PREDCLS 전반에서 아주 뛰어난 결과를 보여주고 있습니다. TD2-Net의 경우 mR@K가 좋은 대신 R@K를 상당히 희생함에 비해 STABILE은 다른 방법들과 유사하거나 더 뛰어난 R@K를 기록하였습니다.
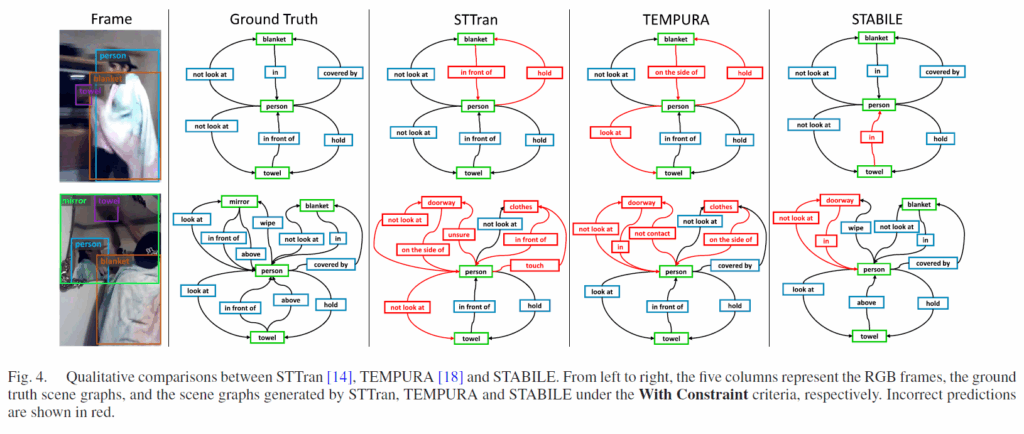
정성적 결과를 몇개 보자면 STABLE이 STTran이나 TEMPURA와 비교해 술어 분류 성능이 더 뛰어납니다(tempura는 stabile과 동일하게 faster rcnn으로 물체를 검출합니다).
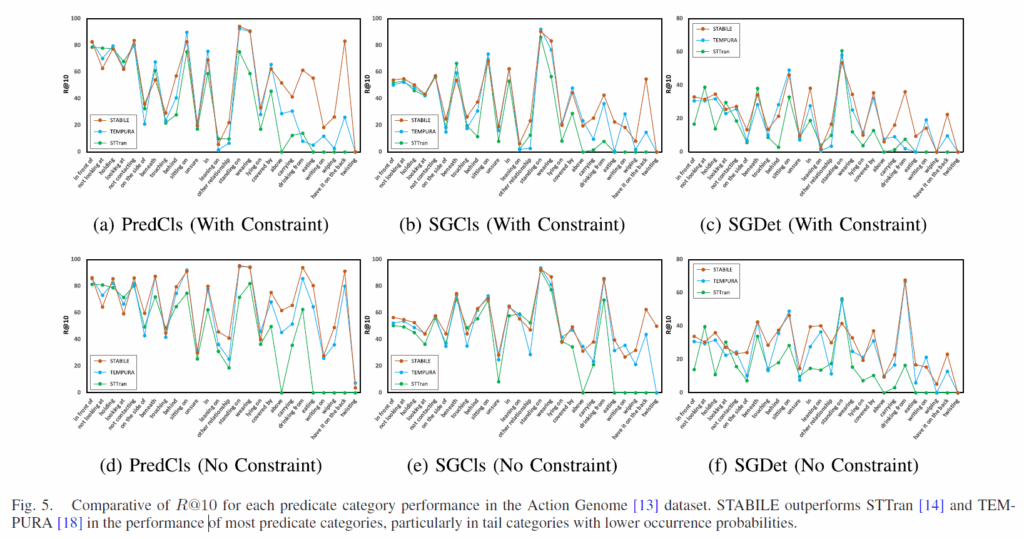
위 Fig.5는 STABILE이 long-tail 분포를 얼마나 완화시켜주는지 보여주기 위해 각 술어 카테고리에 대해 R@10 을 나타내었습니다. 결과적으로 대다수 술어 클래스에서 TEMPURA보다 좋은 성능을 보여주고, 특히 빈도가 낮은 카테고리에서 좋은 결과를 보였습니다.
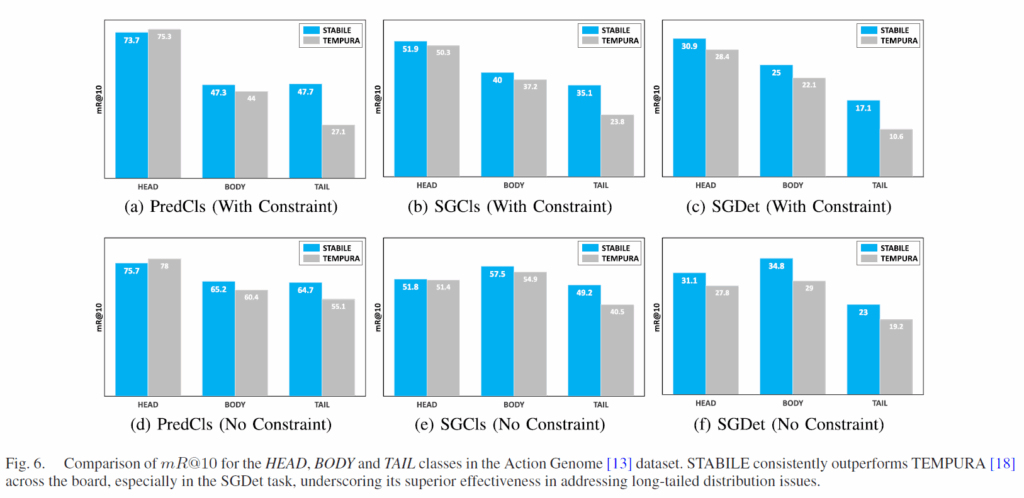
추가적으로 head, body, tail 클래스에 대해 TEMPURA와 비교하여 나타냈습니다 이 때 head는 학습 데이터 샘플이 100,000개 이상의 5개 관계 클래스, tail은 학습 샘플 개수가 8,000개 미만인 11개 관계 클래스이고, body는 그 이외의 카테고리 클래스입니다. HEAD-PredCls-mR@10에서의 소폭 하락을 제외하고, 전 범주에서 TEMPURA보다 좋은 결과를 보였습니다. long-tail 분포 완화에 TEMPURA보다 STABILE이 더 좋은 효과를 보인다는 뜻이죠.
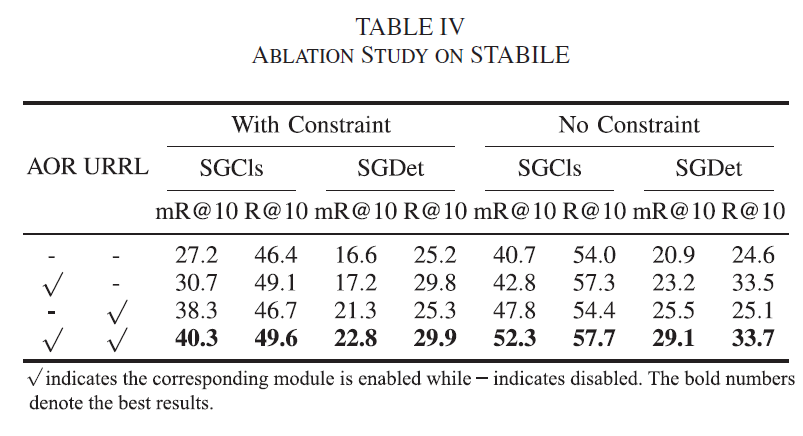
마지막으로 Ablation 결과 보고 마무리하겠습니다. AOR 및 URRL 모두 sgcls, sgdet, R@K, mR@K에서 유의미한 성능 향상을 보였습니다.
이상 리뷰 마무리하도록 하겠습니다.
감사합니다.
안녕하세요 허재연 연구원님 좋은 리뷰 감사합니다.
URRL에 관련하여 궁금한 점이 있습니다. multi-label contrastive learning을 통해 학습하는 것이 Ablation을 확인하지 꽤 효과적이었던 것 같습니다. longtail문제를 해결에 어느정도 도움은 되겠지만, tail쪽 relation의 분포가 적기 때문에 결국 분포가 많은 “and”, “of”와 같은 빈도수가 높은 relation의 학습 영향이 더 클 것 같은데 URRL보다 기존 연구들이 사용한 Logit Compensation이 long-tail 문제에는 더 도움이 된 것 아닐까하는 생각이 듭니다. 혹시 UML loss와 Logit Compensation을 따로 분석한 Ablation이 논문에 있는지 궁금합니다.
감사합니다.
좋은 분석인 것 같습니다. UML에서 class-wise average를 취하기에 head class의 영향력이 더 크다기보다는 다양성에서 이점이 있을 수 있을 것 같네요. UML은 long-tail을 직접적으로 해결하기보다는 tail class의 영향력이 사라지는걸 방지하는 목적이 더 크고, long-tail을 직접적으로 다루는 loss는 logit compensation의 영향이 더 크지 않나 생각합니다. loss term의 α, β 에 대한 추가 분석도 있었는데, α가 커질수록(당연하게도) PredCls, SGCls, SGDet의 mR@20의 성능은 증가했고, R@20의 성능은 감소했습니다. β값의 경우 0.3 까지는 그 값이 커질수록 mR@20이 증가했는데 , 0.3을 넘어서자 mR@20 성능이 감소하는 경향을 보였습니다.
안녕하세요 재연님 좋은 리뷰 감사합니다.
UML contrastive loss에서 class-wise averaging을 도입했다고 했는데, 이게 구체적으로 어떻게 long-tail 문제를 완화하는지가 조금 추상적으로 느껴져서 답글 드립니다!
제가 수식을 잘 이해하지 못해서 드리는 질문일 수 도 있겠는데요, 예를 들어, head class가 많아도 샘플별로 균등 가중을 주는 것인지 아니면 tail class가 상대적으로 더 큰 가중치를 갖게 되는 구조인지가 궁금합니다!
감사합니다.
수식 (9)와 (10)의 차이에 집중하시면 이해하기 더 쉬울 것 같습니다. class R에 대해 라벨링된 sample set P(R)을 각 class마다 나눠주기 때문에, 각 class의 sample 별로 균등 가중을 주는 것으로 이해하면 될 것 같습니다. 기존에는 클래스별 샘플 수의 크기가 많이 다른 것을 반영해주지 못했으니 각 클래스 별 샘플 수로 나누어서 loss에 기여하는 정도를 보정한 것이죠.