안녕하세요. 박성준 연구원입니다. 최근 ICCV2025에 공개된 Video Question Grounding 연구입니다.
Introduction
최근에 제가 관심가지고 서베이 중인 분야인 Video Question Grounding은 기본적으로 Video Question Answering이지만, 모델이 생성하는 답변의 근거가 되는 구간을 답변과 함께 출력하는 task입니다. 기존의 VideoLLM은 주로 장면 수준의 포괄적인 이해에 초점을 맞춰 학습되기에 세밀한 객체 단위의 시공간적 질문을 다루는 데에는 한계가 있습니다. 이는 사전학습될 때에 메모리와 편의성 등의 이유로 비디오 전체의 특징을 문장 전체의 특징과 Contrastive Learning을 수행하기 때문입니다. 아무튼, 이러한 한계가 있기 때문에 저자는 이를 해결하기 위해 Refer and Ground Anything Anytime at Any Granularity(RGA3)를 제안합니다. RGA3는 관심 있는 객체를 설정하고 그 객체에 대한 질문을 답변할 수 있는 object-centric한 모델입니다. 구체적으로는 마스크, 경계상자, 점 등의 다양한 시각적 프롬프트를 텍스트 입력과 통합하여 특정 객체에 대한 복잡한 추론을 가능케하고, 질문에서 언급된 객체에 대한 마스크를 생성하여 객체 중심의 추론을 가능하게 모델링했습니다. 자세한 방법론은 Method에서 다루겠습니다.
추가로 저자는 VideoInfer라는 객체 중심 비디오 데이터셋을 제안합니다. 데이터셋은 수작업으로 직접 만들어진 질문과 추론 과정이 포함되는 답변으로 구성되었습니다. 기존 데이터셋과 다르게 추론할 때 장기적인 시공간적 이해를 요구하며 약 3만개 가량의 QA 쌍을 포함하고 있어 규모면에서도 경쟁력을 갖추고 있습니다. 당연하지만, RGA3는 해당 데이터셋에서 SOTA를 달성했습니다.

Figure 1.은 RGA가 referring(질문에서의 중요 객체를 지목하는 것)과 grounding(질문의 답변에 대한 근거되는 구간을 제시하는 것) 모두 가능한 모델이라는 것을 보여주는 그림입니다. 기존 VideoLLM들이 텍스트 기반 응답에만 제한되며, 마스크 참조 정도만 가능했지만, RGA3는 기존의 한계를 넘어 시각적 프롬프트를 활용하여 객체를 지목(referring), segmentation mask 생성 그리고 구간을 출력하는 것까지 가능합니다.
Method
먼저, task에 대한 설명과 notation에 대한 설명입니다. 해당 연구의 목표는 임의의 시각적 프롬프트 P_t와 함께 특정 시점 t에서 질문 Q에 대답할 수 있는 모델 \phi_b(\cdot)을 구축하는 것입니다. 해당 task의 notation은 다음과 같습니다. A, M = \phi_b(V, Q, P_t)
V \in \mathbb{R}^{T \times H \times W \times 3}은 T개의 프레임으로 이루어진 비디오 입력이고, P_t \in \mathbb{R}^{H \times W \times 4}는 RGBA 형식으로 표현된 시각적 프롬프트입니다. A에 해당하는 정보는 마스크, 경계상자, 점 등이 있습니다. Q와 A는 텍스트로 주어진 질문과 답변이며 M \in \mathbb{R}^{T \times H \times W}는 객체 지목(referring)할 때에 생성된 마스크입니다.
즉, RGA3모델은 텍스트 입력과 시각 프롬프트 입력을 모두 처리할 수 있으며 시공간적 관계를 추론하여 텍스트 응답과 마스크를 생성합니다. 아래의 Figure 2.는 RGA3의 아키텍쳐입니다.
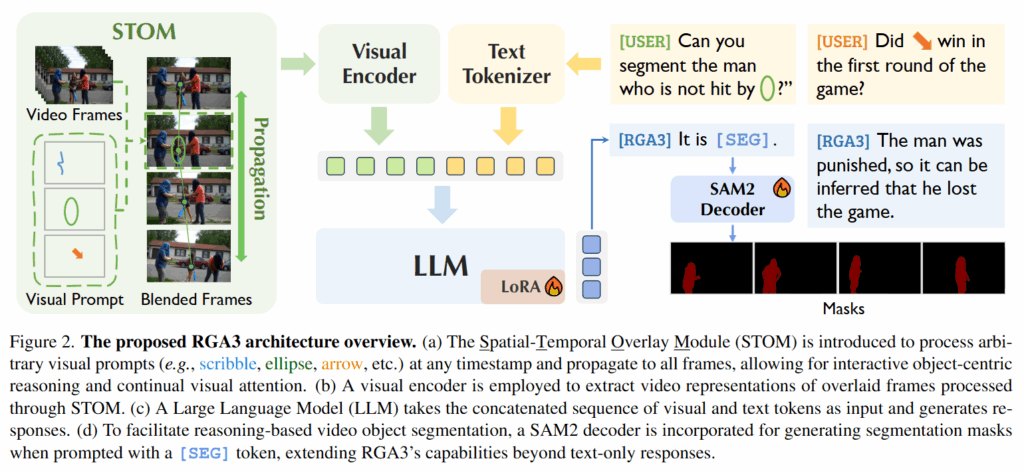
(a) Spatial-Temporal Overlay Module (STOM)은 비디오 프레임에 입력된 시각 프롬프트를 입력받아 프롬프트를 전체 프레임에 전파(propagation)시킵니다. 이를 통해 전체 프레임에 Blended Frame을 생성합니다. (b) Visual Encoder는 STOM을 통해 blended된 프레임들을 입력받아 feature 추출합니다. (c) LLM은 Tokenizer를 통해 질문을 입력 받아 feature를 추출하고 Visual Encoder를 통해 추출된 feature와 concat하여 LLM에 입력합니다. (d) SAM2 Decoder는 LLM이 생성한 토큰을 통해 마스크를 더 상세하게 설명합니다. 위 과정을 통해서 저자는 referring, grounding 등의 task를 모두 수행할 수 있습니다.
STOM부터 설명드리면, 영역 기반 객체 referring을 수행할 수 있게 하기 위하여 프롬프트를 다른 프레임으로 전파시키는 역할입니다. 사실 방법론 자체는 별거 없고 입력 받은 시각적 프롬프트를 여러 프레임에 적용시키는 것입니다. 특정 프레임에서 객체를 표기하게 된다면 그 정보를 전체 비디오 시퀀스 내에 전파시켜서 비디오 전반에 해당 객체를 추적하고 지목할 수 있습니다.
다음으로 Visual Prompt입니다. 시각 프롬프트 P_t는 RGBA로 표현되며, A(alpha)는 opacity를 나타냅니다. 시각 프롬프트 P_t는 off-the-shelf point tracker를 활용하여 시각 프롬프트 경계 안에서 픽셀을 추적합니다. 추적한 픽셀은 프레임에 표현되며, alpha blending을 통해 원본 프레임과 합성됩니다. 이 과정에서 비디오 전반에 걸쳐서 객체를 지목할 수 있습니다.
Visual Prompt를 STOM으로 전파시킨 이후에는 Qwen2.5-VL이라는 VideoLLM의 인코더에 입력됩니다. T개의 프레임으로부터 시각적 특징을 임베딩으로 인코딩되고 시각적 임베딩과 텍스트 임베딩과 결합되어 LLM에 입력됩니다. LLM은 이 두 모달리티를 결합하여 object-centric한 비디오 이해를 위한 응답을 생성합니다. 정리하면 기존에는 비디오 프레임만을 활용했었지만, 시각 프롬프트를 추가하는 것으로 해결했다고 볼 수 있습니다.
마지막으로 답변 생성과 grounding을 위한 단계입니다. 출력에 만약에 [SEG] 토큰이 포함되어 있다면 마스크도 생성합니다. 이때는 LLM이 생성한 텍스트 임베딩이 SAM2 디코더로 전달되고 SAM2는 최종 마스크를 생성합니다. 이를 통해서 RGA3는 텍스트 응답과 마스크까지 모두 생성할 수 있게 됩니다. 생각보다 단순한 방법이고 off-the-shelf 모델들을 많이 사용했지만, 기존의 문제를 잘 해결한 방법론으로 의미 있는 연구인 것 같습니다.
학습은 CrossEntropy loss를 통해 QA답변을 학습하고, BCE loss와 DICE loss를 통해 생성됩니다. DICE loss는 segmentation에서 널리 사용되는 loss로 (1 – DSC )이고 DSC는 \frac{2 \times | A \cap B|}{|A| + |B|}입니다.

다음으로 VideoInfer 데이터셋입니다. RGA3 학습을 위한 데이터셋을 구축하는 것이 저자가 말하는 어려움 중에 하나였다고 합니다. 좋은 문제정의로 시작해서 연구를 시작했지만, 결국 기존에는 존재하지 않은 데이터를 통해 학습을 해야했고 이를 위해 직접 구축한 데이셋이 VideoInfer 데이터셋입니다. Object-centric VideoQA를 위한 데이터셋으로 복잡한 semantic understanding, temporal reasoning, discrimination over video content를 요구하는 질문들로 구성되어 있습니다.
저자는 데이터셋을 구성하기 위해 기존에 존재하는 데이터셋을 선별합니다. TAO, LVOS, LVVIS, VIPSeg, UVO, MOSE, OVIS 총 7개의 데이터셋을 선별했으며, 실내/실외 활동, 동물 행동, 사람 상호작용 등 다양한 시나리오를 포괄하는 데이터셋을 구성하고자 했습니다. 일반화 능력을 키울 수 있는 데이터셋이기도합니다. 특히 TAO와 LVOS 데이터셋은 long-form 비디오를 활용한 데이터셋으로 시각적 정보를 모델링하는 데에 있어 효과적인 데이터셋입니다. 저자는 8개의 시각적 프롬프트를 무작위로 생성했습니다. mask, mask contour(마스크의 외곽선으로 지목 혹은 추적하고자하는 객체의 외곽선을 의미합니다.), rectangle, ellipse(타원), triangle, scribble(낚서같이 추적하고자하는 객체를 칠한 것입니다.), arrow, point입니다. 각각의 비디오에는 하나의 프롬프트만 생성했다고 합니다.
선별한 모든 데이터셋이 QA데이터셋이 아니기때문에 몇몇 QA쌍 또한 저자가 직접 생성했습니다. 저자는 두가지 규칙에 따라 라벨을 생성했으며, indirectness, dynamism입니다. 간접적으로 비디오에 드러나지는 않았어도 추론하는 능력과 시간적 추론을 요구하는 질문을 말합니다. 추가로 저자는 교차검증을 통해서 QA쌍을 생성하였습니다. 실제 라벨은 위의 Figure 3.을 참고해주시기 바랍니다.
데이터셋은 총 1,620개의 비디오와 28,811개의 QA쌍으로 구성됩니다. Instruction tuning set과 Challenging set이 존재하며, 각각 950/670개의 비디오, 2,555/1,572개의 객체, 20,320/8491개의 QA쌍이 존재합니다.


Figure 4.와 5.는 RGA3 모델의 실제 예측 결과입니다.
Experiments
학습 데이터셋은 VideoInfer 데이터셋으로 학습하고 평가 또한 진행합니다. 추가로 저자는 QA데이터셋과 Segmentation 데이터셋을 활용하여 평가하는 것으로 저자가 제안하는 RGA3 모델의 강력함을 보입니다.
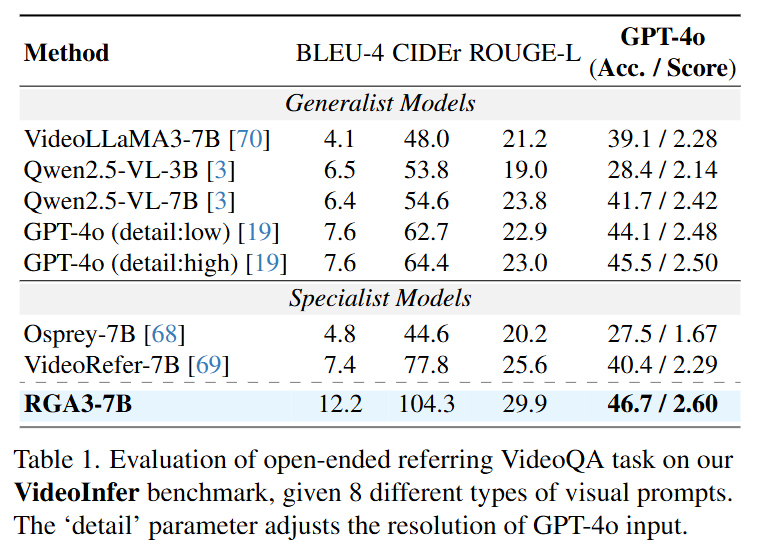
Table 1.은 open-ended VideoQA 평가입니다. open-ended 평가는 VideoQA를 객관식으로 해결하는 것이 아니라 자유형태의 대답을 생성하고 그것을 평가하는 것을 의미합니다. 따라서 평가지표 또한 자연어 평가지표를 사용합니다.
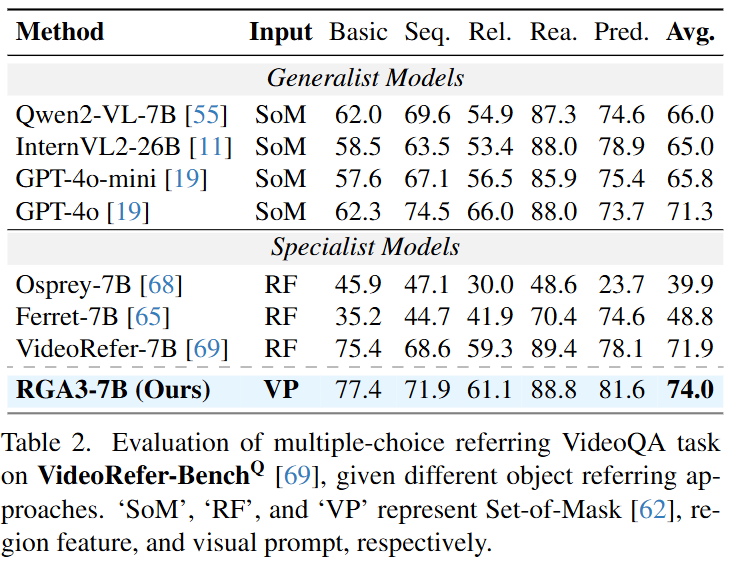
Table 2.는 VideoQA의 성능으로 위 성능은 객관식 답변에 해당합니다.
평가할때는 선행연구와 동일하게 평가하여 BLEU-4, CIDEr, ROUGE-L을 평가지표로 사용합니다. 모두 생성형 모델을 평가하기 위하여 사용되는 지표이며, BLEU-4는 연속되는 4개의 단어가 Reference 중에 한 곳에라도 포함되면 점수로 인정하는 방식이고 n-gram precision을 사용하는데, BLEU-4는 4gram을 사용합니다. 연속된 4개의 단어를 고려한다는 것인데 예를 들어서, 정답이 “The man is playing football in the park”이고 예측이 “The man is playing soccer in the park”이라고할 때, “The man is playing”이 일치하게 됩니다. Reference와 예측에 4개의 연속된 단어가 동일하기 때문에 점수가 좋아집니다. 물론 실제로는 오답이어도 정답으로 인정되는 경우도 생기고, 정답인데 오답으로 생기는 경우도 생길 수 있겠지만, 생성형 모델을 평가하는 방법 중에 하나로 실제로는 꽤나 정확하게 평가된다고 합니다. 추가로 길이보정(짧으면 점수가 깎입니다.)이 들어가며, 일반적으로 4-gram이라고하면 1-gram, 2-gram, 3-gram을 통합한 평가방식이라고 합니다. 본 논문에서의 방식은 코드를 확인해봐야하겠지만, 같은 방식을 사용했을 것으로 생각됩니다. CIDEr은 단순 단어 일치율을 보는 BLEU와 다르게 사람이 쓴 여러개의 정답 후보군과 비교하여 평가하는 방식으로 얼마나 비슷한지를 측정합니다. TF-IDF 기반의 n-gram 벡터로 표현하여 코사인 유사도를 계산합니다. 흔한 단어에는 낮은 가중치를, 흔치 않은 단어에는 높은 가중치를 두는 것으로 모델이 특정 단어에 편향되는 것을 방지합니다. TF-IDF는 텍스트 데이터에서 단어의 중요도를 나타내는 통계적 수치을 말합니다. ROUGE-L은 summarization에 자주 사용되는 평가 지표로 LCS(Longest Common Subsequence, 최장 공통 부분 수열)를 기반으로 예측과 정답 사이의 단어 순서를 고려하는 지표압니다. LCS의 길이를 평가합니다. 3가지 지표에서 RGA3는 SOTA를 달성했습니다.
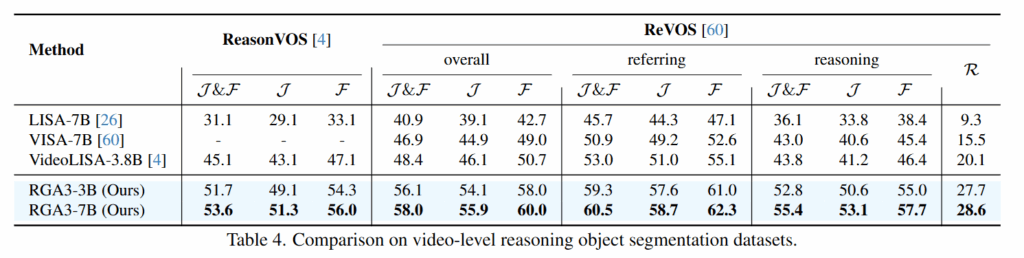
ReasonVOS와 ReVOS는 video-level reasoning 데이터셋으로 RGA3데이터셋인 QA뿐만 아니라 reasoning에도 훌륭함을 확인할 수 있습니다. 여기서 J는 IoU입니다. Jaccard overlap으로 예측 마스크와 정답 마스크 사이의 IoU를 의미합니다. F는 마스크의 경계선의 정확도를 평가하는 지표입니다. J&F는 둘 모두를 고려한 평가지표입니다. 마지막으로 R은 Robustness인데 모델의 환각정도를 평가하는 지표입니다. 즉, 잘못된 객체의 마스크를 생성한다면 성능이 낮아지게됩니다.
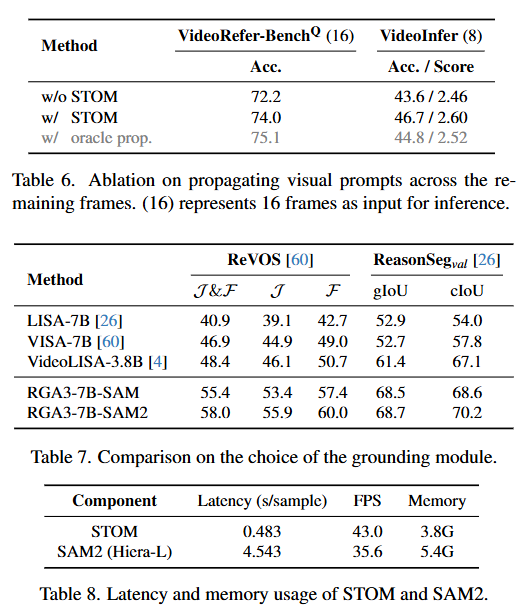
마지막으로 Ablation Study입니다. Table 6. 을 확인하면 저자가 제안하는 STOM 모듈을 통한 프롬프트 전파가 효과적으로 성능을 개선하고 있음을 확인할 수 있습니다. 회색으로 된 oracle prop.은 완벽하게 GT를 전파했을 때로 upper bound입니다. upper와도 유사한 성능을 보이며 저자가 제안하는 STOM이 효과적임을 강조하는 표입니다. Table 7.은 SAM2의 효과로 복잡한 비디오 추론 상황에서 SAM2를 사용하는 것이 효과적임을 보이고 있습니다. Table 8.은 메모리와 지연속도를 보여주게되는데, SAM2의 성능이 좋은만큼 SAM2에서 모델이 높은 메모리와 지연시간을 갖게 되는 것을 확인할 수 있습니다. 저자는 그럼에도 불구하고 SAM2를 사용하는 것이 성능에 큰 도움이 되기에 반드시 필요하다고 설명하고 있습니다.
감사합니다.
안녕하세요 성준님 좋은글 감사합니다.
세미나때 듣고 약간 간단하게 생겼던 질문은 gpt의 답변생성 및 채점 얘기였는데, 사람의 annotation이 기준이라면 만점이 안나올 수 있지 않나? 라는 생각을 했었습니다. 흠 그리고 추가적인 질문으로 이 논문뿐만 아니라 요즘 논문을 읽으면서 드는 생각이, 해당 논문에서 사용한 방법 (gpt api 사용 혹은 여러 평가방식 검증) 등이나 생각해낸 매트릭이 내가 생각해낼 수 있었을까? 나 혹은 생각해냈더라도 어디까지 내가 실험할 수 있었을까 하는 생각들이 들곤 합니다. 성준님이 관심있어하는 VQA 분야 논문들을 읽으며 비슷한 생각을 한게 있을까요? 감사합니다.
안녕하세요. 신인택 연구원님 좋은 댓글 감사합니다.
연구를 진행하다보면 기존 연구들의 metric의 한계점을 느낄때가 가끔 있긴합니다. 그럴때마다 어떻게하면 더 잘 평가할 수 있을까를 생각해보긴 하지만, 제가 직접 metric을 제안해본 적은 없는 것 같네요. 본 연구는 open-ended 답변을 생성하기에 정량적으로 평가하는 것에 어려움이 있었을 것 같기는 합니다. 제가 관심있게 보던 VQA 연구들은 사실 multiple-choice 기반 즉, 다지선다 객관식이기에 새로운 metric의 필요성을 느끼지는 못했지만, 상황에 따라 연구에 유리(?)하면서 논리적인 metric을 제안하는 것도 괜찮을 것 같습니다.
감사합니다.