안녕하세요. 박성준 연구원입니다. 오늘 리뷰할 논문은 CVPR 2025 Highlight 논문으로 Video Question Grounding(VQG)을 다룬 논문입니다.
Introduction
Video Question Answering(VideoQA)는 비디오와 자연어 질문을 입력 받아서 해당 질문에 대한 올바른 답변을 비디오를 기반으로 생성하는 task입니다. 기존 VideoQA 연구는 주로 답변을 올바르게 생성하는 것에 집중하느라 정답의 신뢰성 혹은 정답의 근거를 설명할 수 없다는 단점이 있었습니다. 따라서, 본 연구는 사용자가 VideoQA 모델이 생성하는 답변을 신뢰하기 위해서는 어떤 비디오 구간 혹은 어떤 시각적 근거를 기반으로 모델이 답변을 생성했는 지를 확인할 필요가 있음에 집중했습니다. 본 task를 Video Question Grounding(VQG)라고 부릅니다. 본 연구는 CVPR2024 highlight 연구인 [CVPR 2024] Can I Trust Your Answer? Visually Grounded Video Question Answering 연구를 기반하고 있습니다. 추가로 VQG에 대한 자세한 설명을 이전 리뷰에 작성했으니 참고바랍니다. 즉, VQG는 질문에 대한 답변을 생성하는 동시에 답변의 근거가 되는 구간을 예측(temporal grounding)도 예측하는 것을 목표로 하는 task입니다.
저자는 기존 VQG가 두가지 문제가 있다고 설명합니다. 하나는 Weak-Supervision의 어려움이고, 다른 하나는 Cross-modal Causal Confounding입니다. 첫번째 Weak-Supervision의 어려움의 경우, 학습할 때 정확한 temporal boundary 라벨이 없이 학습을 진행하기 때문에 모델이 직접적으로 올바른 근거가 되는 구간을 학습하기 어렵다는 점입니다. 이로 인해 모델이 답변을 맞추더라도 근거로 제시하는 구간은 부정확하거나 불필요한 장면을 포함하고 있을 가능성이 높습니다. 두번째 Cross-modal Causal Confounding은 비디오와 자연어 질문이 서로 다른 모달리티이지만, 모델 내부에서는 특정 배경, 질문의 의도, 등장 인물 등 spurious correlation(거짓 상관관계)가 정답 예측에 영향을 미친다는 문제입니다. 무슨 말이냐면, 특정 질문이 학습할 때에 항상 같은 배경에서 등장하기 때문에 실제 비디오의 시각적 정보가 아닌 배경의 패턴에 의존하여 답변할 가능성이 높으며, 이는 모델이 특정 패턴에 편향되어 잘못된 근거의 선택을 할 수 있다는 것입니다.
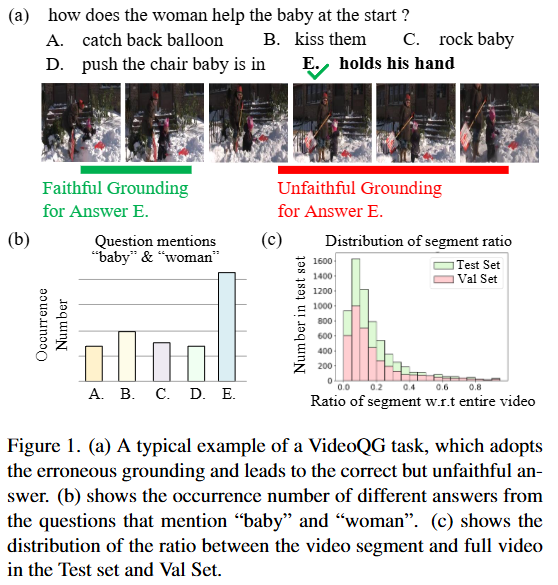
Figure 1은 위에서 설명한 기존 VQG가 갖고 있는 문제점을 보여주는 그림입니다. (a)는 VQA에서 시각적 근거에 기반하지 않고 답변을 생성하는 기존 VideoQA 및 VQG의 문제를 보여주는 그림이고, (b)와 (c)는 기존 데이터셋의 편향된 정답 분포를 보여주고 있습니다. 특히, (b)는 baby 혹은 woman을 언급하는 질문을 하는 경우에는 E 답변으로 편향되어 있는 것을 확인할 수 있습니다.
이러한 문제를 해결하기 위해서 저자는 Cross-modal Causal Relation Alignment(CRA)라는 VQG 프레임워크를 제안합니다. CRA 모델은 앞선 문제를 해결하기 위해 정확한 시간적 근거를 추출하고, 서로 다른 모달 간 인과 관계를 정렬하고 설명 가능성을 향상하는 것을 목표로 합니다. 이를 위해 3가지 모듈을 제안합니다. 하나는 Gaussian Smoothing Grounding(GSG)로 비디오와 질문 사이의 attention를 통해 시간적 근거를 예측하고 Gaussian 필터를 통해 노이즈를 제거합니다. 두번째는 Cross-modal Alignment(CMA)로 예측 시간 구간과 질문-답변 표현 사이의 양방향 contrastive learning을 통해 의미적으로 정렬합니다. 마지막으로 세번째는 Explicit Causal Intervention (ECI)는 인과 추론을 통해 서로 다른 모달 사이의 혼동을 제거합니다. 시각 모델에는 front-door intervention, 언어 모델에는 back-door intervention을 사용합니다. front-door intervention과 back-door intervention은 causal intervention(인과추론)에서 사용하는 개념으로 원인으로부터 결과를 추정할때, 중간에 mediator(매개체)를 통해 결과가 나오는 중간 경로를 확인하는 방법입니다. front-door는 mediator를 통해서 추측하는 방법이고, back-door는 confounder(혼란변수)를 통해서 추정하는 방식으로 결과를 토대로 원인을 추청하는 역방향 경로로 추정하는 방법입니다. 위 3가지 모듈은 Method에서 더 자세하게 설명하겠습니다.
이에 따른 저자의 Contribution은 다음 3가지입니다. Weakly-Supervised VideoQG를 해결했고, 이 과정에서 Causal Relation을 기반하여 모델의 신뢰성을 강화하고, 다양한 벤치마크에서 우수한 성능을 입증했습니다.
Method
저자가 제안하는 Cross-modal Causal Relation Alignment(CRA)는 VQG를 위해 설계된 프레임워크로 Gaussian Smoothing Grounding (GSG)와 Cross-modal Alignment (CMA) 그리고 Explicit Causal Intercention (ECI)로 구성되었습니다.
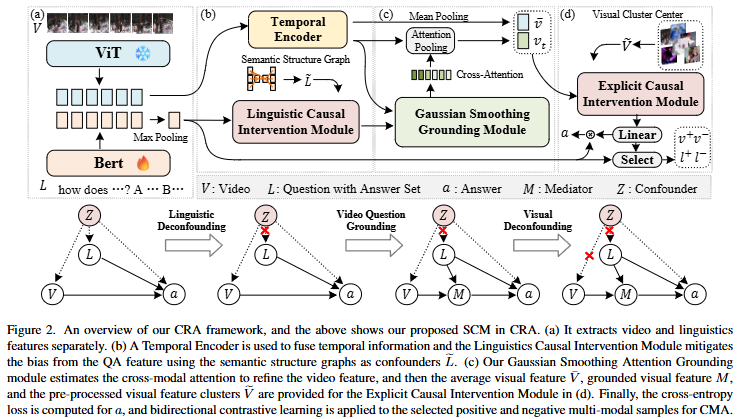
Figure 2는 CRA의 전체 구조를 보여주고 있습니다. (a)는 Feature Extraction 단계로 비디오 V와 자연어 질문 L의 특징을 추출합니다. 비디오 프레임은 ViT를 통해, 자연어 질문은 BERT 인코더를 통해 특징을 추출하고 맥스 풀링을 통해 문장의 특징을 얻습니다. (b)는 Linguistic Causal Intervention으로 Temporal Encoder를 통해 시간 정보를 모델링하고 semantic structure graph를 활용해 QA에 내재된 편향을 제거합니다. 이를 통해 텍스트의 표현과 비디오의 표현이 인과적으로 정합할 수 있습니다. (c)는 Gaussian Smoothing Grounding으로 비디오와 질문 사이의 cross-modal attention을 통해 시간 구간별 관련도를 얻습니다. 이때 gaussian smoothing을 통해 노이즈를 제거합니다. 이 과정에서 비디오 특징에 평균 풀링을 통해서 비디오 전체의 표현을 얻습니다. (c)는 Explicit Causal Intervention으로 시각 특징에는 front-door intervention, 언어 특징에는 back-door adjustment를 적용하는 것으로 causal relation을 학습합니다. 과정이 좀 복잡하지만, 정리하자면 비디오와 언어의 특징을 추출하고 비디오의 특징은 가우시간 연산을 통해 노이즈 제거하고 attention 연산과 인과관계 모델링을 통해서 grounding을 학습하게 됩니다.
Gaussian Smoothing Grounding (GSG)
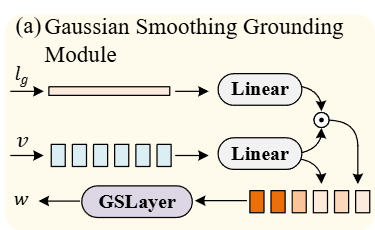
먼저, 가우시안 스무딩입니다. 가우시안 스무딩은 영상처리에서 노이즈를 제거하기 위해 많이 사용되는 기법입니다. 저자는 cross-attention 연산을 통해서 비디오와 텍스트가 얼마나 관련있는 지를 계산 한 후에 가우시안 스무딩 연산을 하는 것으로 노이즈를 제거합니다. 이 과정이 필요한 이유는 자연어 질문에 따른 시각적 근거를 추론할 때 단발성 고점이나 노이즈로 인해서 예측의 신뢰도가 떨어질 수 있기 때문입니다. 가우시안 스무딩을 통해서 연속적인 근거 구간을 노이지하지 않고 부드럽게 만들어줍니다.
attention 연산은 다음 수식으로 표현됩니다.
\alpha_t = softmax(\frac{q^TW_av_t}{\sqrt{d}})W_a는 학습가능한 가중치 행렬이고, \alpha_t는 t번째 클립이 질문과 관련될 확률을 의미합니다. 여기서 상위 K개를 선택하여 임시로 질문의 근거가 될 수 있는 구간을 임시로 여러개 생성합니다.
가우시안 연산은 다음 수식으로 표현됩니다.
\tilde{\alpha}_t = \sum_{k=-K}^{K} \alpha_{t+k} \cdot G(k)여기서 G(k)는 가우시안 커널로 아래의 수식과 같습니다.
G(\tau) = \frac{1}{\sqrt{w\pi}\theta}exp(-\frac{\tau^2}{2\theta^2})\theta는 스무딩 정도를 조절하는 하이퍼파라미터입니다.
Cross-modal Alignment (CMA)
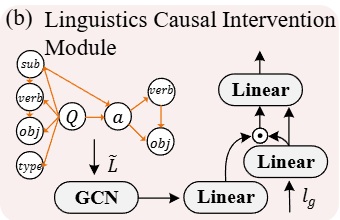
GSG로부터 얻은 비디오 특징과 자연어 질문 특징을 bidirectional contrastive learning으로 정렬하는 단계입니다. 추출된 특징은 각각 다음과 같습니다.
v^g = \frac{1}{|G|}\sum_{t \in G}v_t, q^a = f(q,a)
G는 GSG에서 선택된 근거 구간의 시간 인덱스를 의미하고 f는 자연어 중요도에 따른 특징을 추출하는 모듈입니다.
위 특징들을 contrastive learning을 통해 양방향에서 매칭해 가장 높은 유사도를 갖도록 학습합니다.
\mathcal{L}_{\mathrm{CMA}} = -\frac{1}{N} \sum_{i=1}^{N} \log \frac{\exp(\mathrm{sim}(\mathbf{v}_i^g, \mathbf{q}_i^a)/\tau)}{\sum_{j=1}^{N} \exp(\mathrm{sim}(\mathbf{v}_i^g, \mathbf{q}_j^a)/\tau)}sim(\cdot)는 코사인 유사도, \tau는 temperture 하이퍼파라미터입니다.
Explicit Causal Intervention (ECI)
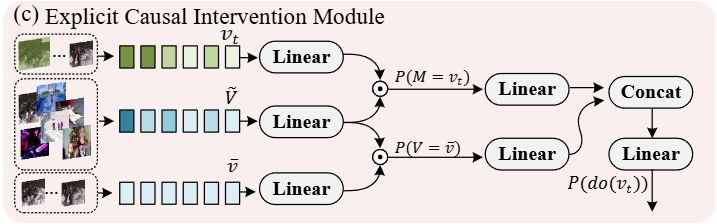
Introduction에서 설명했듯이 VideoQA 데이터셋들에는 특정 배경, 질문의 의도, 등장 인물 등 spurious correlation(거짓 상관관계)이 정답과 높은 상관관계를 가질 수 있고, 이는 잘못된 선택을 야기할 수 있습니다. 이를 해결하기 위해서 저자는 인과관계를 이해할 수 있도록 모델링했습니다.
시각적 특징에는 Front-door criterion을 적용하여 원본 비디오의 특징을 매개를 통해 우회 경로로 전달합니다. 이 우회 경로를 통해 거짓 상관관계를 제거하고 인과적으로 의미 있는 경로를 강화합니다.
VQG의 목표는 기본적으로 P(a|V,L)이지만, 혼돈 변수 Z로 인해서 V -> a, L -> a 경로가 약해되고 Z가 개입해서 가짜 상관관계가 생기게 됩니다. 이를 해결하기 위한게 front-door, back-door입니다.
시각 혼동인 Z_v front-door개입은 다음과 같이 표현됩니다.
P(a \mid do(V), do(L)) = \sum_{v_t} P(a \mid do(M = v_t), do(L)) \, P(M = v_t \mid V, do(L))back-door 개입은 다음과 같이 표현됩니다.
P(a \mid V, do(L)) = \sum_{Z_l} P(a \mid V, L, Z_l, Z_v) \, P(Z_l) \, P(Z_v \mid V)마지막으로 Normalized Weighted Geometric Mean (NWGM)을 통해 근사합니다.
P(a \mid do(V), do(L)) \approx \mathrm{Softmax}\big(g(V, L, \theta(\tilde{L}), \theta(\bar{V}))\big)로 계산됩니다. 자연어 질문 편향은 back-door로, 시각 편향은 front-door로 제거합니다. 이를 통해 P(a|do(V), do(L))를 근사할 수 있습니다.
causal relation을 위해 사용되는 front-door, back-door 학습 전략은 처음보는 개념이라 아직 제대로 파악을 하지 못했습니다. 공부하면서 내용 파악할 예정이라 댓글로 궁금하신 점 남겨주시면 공부한 후에 답변하겠습니다.
아무튼, 최종 손실은 일반적인 답변의 Cross Entropy Loss와 Contrastive Loss로 구성되어 학습합니다.
Experiments
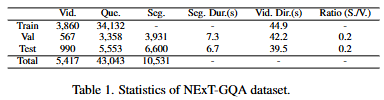
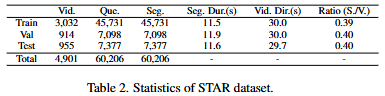
저자는 NExT-GQA 데이터셋과 STAR 데이터셋에서 CRA를 평가합니다. NExT-GQA 데이터셋은 1만개 이상의 Segment가 존재하고 STAR 데이터셋은 6만개 이상의 Segment가 존재합니다. STAR은 상대적으로 NExT-GQA보다 긴 영상이며, 다중 정답이 존재합니다. QA정확도는 전체 QA 중 정답의 비율이고, Grounding 성능은 IoU와 IoP를 사용합니다. IoP는 IoU지만 분모가 예측입니다. 즉, 모델의 예측이 실제 정답의 근거라면, 정답으로 생각하는 것을 의미합니다.
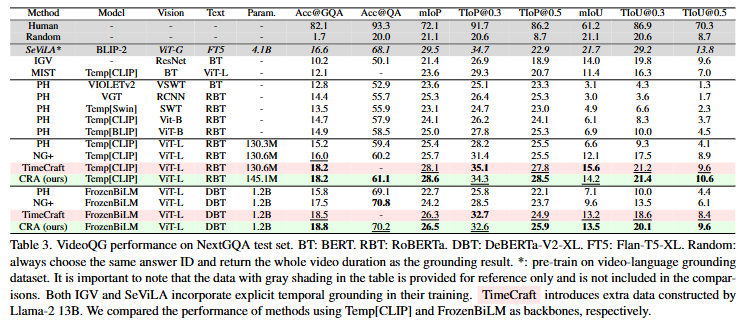
Table3는 NExT-GQA에서의 성능입니다. CRA는 NExT-GQA에서 기존 SOTA모델보다 더 높은 성능을 보였습니다. 정답을 예측하는 것뿐만 아니라 Grounding에서도 SOTA를 달성했습니다.
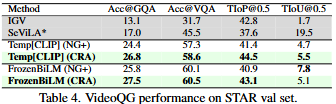
Table4는 STAR 데이터셋에서의 성능입니다. 마찬가지로 CRA의 성능이 가장 높은 것을 확인할 수 있습니다.
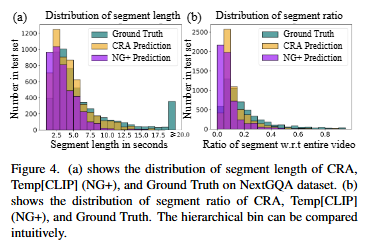
Figure 4는 GT와 CRA 방법론 그리고 기존 모델 (NG+)의 segment 길이 비교입니다. 짧은 segement를 생성하는 기존 모델에 비해 CRA는 GT와 더 유사한 분포를 가지는 것을 확인할 수 있습니다. 이는 같은 데이터셋으로 학습했음에도 CRA가 데이터셋에 편향되지 않고 일반적인 특징을 잘 학습했음을 보여준다고 해석할 수 있습니다. 저자는 이 그림을 통해 CRA가 저자가 의도한대로 weakly-supervised 상황에서도 데이터셋에 편향되지 않고 정답의 근거를 신뢰도 있게 예측한다고 주장하고 있습니다.

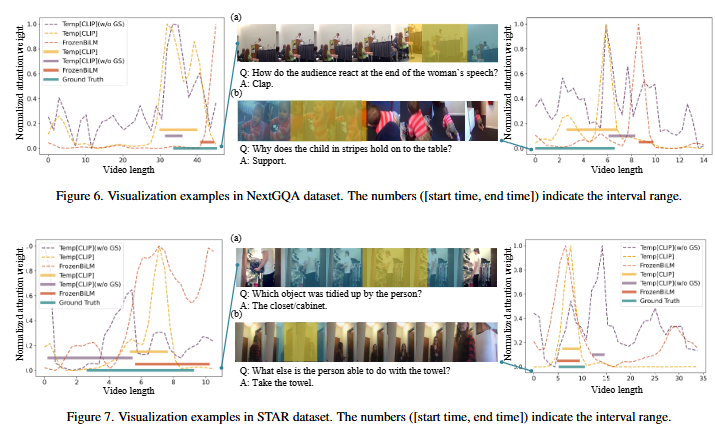
Figure 5는 CRA 모델의 예측을 정성적으로 분석한 결과입니다. 실제 정답의 근거가 되는 구간을 잘 찾고 있는 것을 확인할 수 있습니다. Figure 6 또한 정성적 분석 결과입니다. 다만, 이때는 예측의 근거가 되는 구간을 잘 찾고 있지만, 실제 GT와는 조금 다른 양상을 보이고 있습니다. 저자는 이와 같이 예측이 전부 GT 안에 포함된 경우에는 모델의 예측이 근거가 되는 구간 안에 포함되고 있는 것이라 할 수 있으므로 IoP에서는 정답으로 인정되고 실제로도 모델이 잘 판단하고 있다고 생각할 수 있다고 주장합니다.
Ablation Study
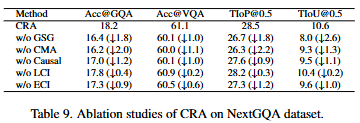
ablation study입니다. GSG를 제거한 경우에는 시간적 연속성을 잃게 되기에 성능이 하락하는 것을 확인할 수 있고, CMA가 제거된 경우에는 시각 정보와 자연어 정보 사이에서 의미 정렬이 잘 되지 않기에 성능이 하락하는 것을 확인할 수 있습니다. 이를 통해 contrastive learning이 grounding에 큰 도움이 된다는 것을 알 수 있습니다. ECI를 제거한 경우에는 인과관계를 잘 이해하지 못함으로 인해 정답에 따른 근거를 정확한 근거를 댈 수 없기에 grounding 능력이 하락하여 성능이 낮아집니다.
저자는 weakly-supervised 상황에서 정확한 시각적 근거 예측과 시각,자연어 모달 사이에서 인과관계 정렬을 목표로 했고, 실제 실험 결과를 통해서 저자의 CRA이 이 두가지 목표를 잘 달성했음을 보이고 있습니다. 이를 통해 기존 모델이 가지고 있던 데이터셋 편향 혹은 다른 이유로 생기는 정답의 근거가 되는 구간을 찾지 못하는 문제르 해결했다고 주장합니다.
감사합니다.
리뷰 잘 읽었습니다. 궁금한 점 댓글 달아두겟습니다.
작성해주신 것에 따르면 ECI 모듈에서 시각적 편향 제거에는 front-door, 언어 편향 제거에는 back-door 개입을 사용한다 한 것 같습니다. 그런데 두 개입이 실제 네트워크 내부에서 어떤 구조적 차이로 구현되는지, 그리고 학습 중 어떤 Loss를 통해 영향이 넘어가는지 궁금합니다.
다음으로 CMA에서 비디오-질문 표현을 양방향 contrastive learning으로 정렬한다고 하셨는데, 혹시 단방향(예: video→text만) 학습과 비교한 실험이 있는지 궁금합니다. 양방향 학습이 실제 grounding 성능 향상에 얼마나 기여했는지도 궁금하네요