안녕하세요 이번에 소개할 논문도 Text-Video Retrieval 분야의 연구 논문입니다. 저는 최근 CLIP 모델에 Mixture-of-Experts(MoE)를 결합하여 모델을 확장하고, 동시에 CLIP 백본에 시간적 정보를 추가하는 방법에 대해 연구를 진행하고 있습니다. 시간 정보를 어떻게 반영할 수 있을지 논문을 서베이 하던 중, 이번 논문을 접하게 되어 자세히 살펴보게 되었습니다. 그럼 바로 리뷰 시작하겠습니다.
1.Introduction
Text-Video Retrieval은 텍스트 쿼리와 일치하는 가장 관련성이 높은 비디오를 찾는 태스크 입니다. 텍스트와 비디오 데이터셋을 구축하는 것은 cost가 많이 들기 때문에 일반적으로는 CLIP과 같이 대규모의 이미지-텍스트로 사전학습된 모델을 활용하여 비디오 도메인에 맞게 파인튜닝하는 방식으로 연구가 되고 있습니다. 예를 들어 CLIP을 인코더로 사용한 대표 모델로는 CLIP4Clip이 있습니다. CLIP4Clip 모델은 CLIP을 사용하여 추출한 프레임을 각각 임베딩 시키고 이들을 mean pooling 하여 하나의 비디오 임베딩을 얻어 텍스트 임베딩과 코사인 유사도를 계산하여 학습을 진행하는 방법론입니다. 하지만 이렇게 프레임을 독립적으로 처리한 후에 mean pooling하는 방식은 비디오의 시간에 대한 정보를 포함할 수 없을 뿐만 아니라 의미론적인 디테일 정보를 잃어버릴 수 있어 결과적으로 검색 성능에 악영향을 끼칠 수 있습니다. 따라서 CLIP4Clip 이후 방법론들은 cross-modal temporal fusion을 사용하여 시간정보나 디테일 정보를 포함하도록 비디오 임베딩을 생성합니다. 하지만 이러한 방식은 성능이 좋기는 하지만 매번 각 프레임과 단어를 서로 비교해 이 텍스트의 어떤 부분이 어느 프레임과 더 관련이 깊은지를 보고 그 정보들을 종합해 비디오와 텍스트를 다시 결합하기 때문에 계산량과 메모리 사용량이 증가할 수 밖에 없습니다.
예를 들어, CLIP4Clip은 비디오의 모든 프레임을 평균한 뒤 텍스트 임베딩과 단순 내적을 수행합니다. 이렇게 하면 연산 복잡도는 O(Nv⋅Nt) 로, 비디오 수(Nv)와 텍스트 쿼리 수(Nt)에만 비례합니다. 반면, X-Pool이나 X-CLIP과 같은 text-conditioned temporal fusion 방식은 비디오 특징을 합칠 때 텍스트 정보까지 함께 고려합니다. 이 방식은 성능 향상에는 유리하지만, 쿼리마다 모든 비디오의 프레임 특징을 텍스트와 함께 다시 계산해야 한다는 단점이 있습니다. 예를 들어 Nv=16,384, Nt=512, 비디오당 프레임 수 Nf=12, 쿼리당 단어 Nw=10인 상황에서, text-conditioned temporal fusion 방식은 O(Nv × Nt × Nf × Nw)의 연산 복잡도를 가져 latency과 메모리 사용량이 기하 급수적으로 증가합니다. 따라서 성능 측면에서 약간의 손해가 있더라도, 오프라인에서 비디오 표현을 미리 계산해 저장하고, 쿼리 시에는 단순 매칭만 수행하는 방식이 대규모 검색 환경에서는 훨씬 효율적이라고 할 수 있습니다.
따라서 CLIP 기반 Text-Video Retrieval은 cross-modal interaction은 가능한 단순하게 유지하고 backbone의 표현 능력을 향상시키는 데 중점을 두어야 합니다. 이를 motivation 삼아 저자는 CLIP에 대해 비디오의 전반적인 의미와 세부적인 의미를 인코딩할 수 있는 기법을 제안합니다. 구체적으로는 시간 × 공간 × 채널의 크기를 가진 프롬프트 큐브(Prompt Cube)를 토큰을 도입하여 이미지 패치와 함께 concate하여 CLIP의 이미지 인코더에 입력됩니다. 또한 서로 다른 프레임 간의 시간적 정보를 학습하기위해 self-attention layer에 들어가기 전 프롬프트 큐브의 시간 축과 공간 축을 서로 바꿔 영상 전체에 대한 global semantics 정보를 더 잘 모델링 할 수 있도록 해줍니다.
또한 저자는 X-Pool, TS2-Net, X-CLIP 기법과 같이 fine-grained cross-modal interaction modules을 사용하지 않고 fine-grained한 정보를 학습하기 위해 Auxiliary Video Captioning objective을 적용합니다. Auxiliary Video Captioning objective란 CLIP 이미지 인코더 위에 light한 captioning head를 추가하고 비디오 임베딩을 입력으로 해서 해당 비디오의 텍스트 캡션의 시퀀스를 재구성 하면서 학습하는 기법입니다. 택스트-비디오 검색에 사용되는 Contrastive learning 배치내에 있는 negatives가 부족하여 모델의 학습이 상대적으로 쉬울 수 있습니다. 그래서 Video Captioning objective도 추가를 하여 모델이 단순히 비디오와 텍스트가 일치하는지 아닌지를 학습할 뿐만 아니라 비디오 내용에 대한 세부적인 의미(detailed semantics)도 학습하도록 유도합니다.
2. Method
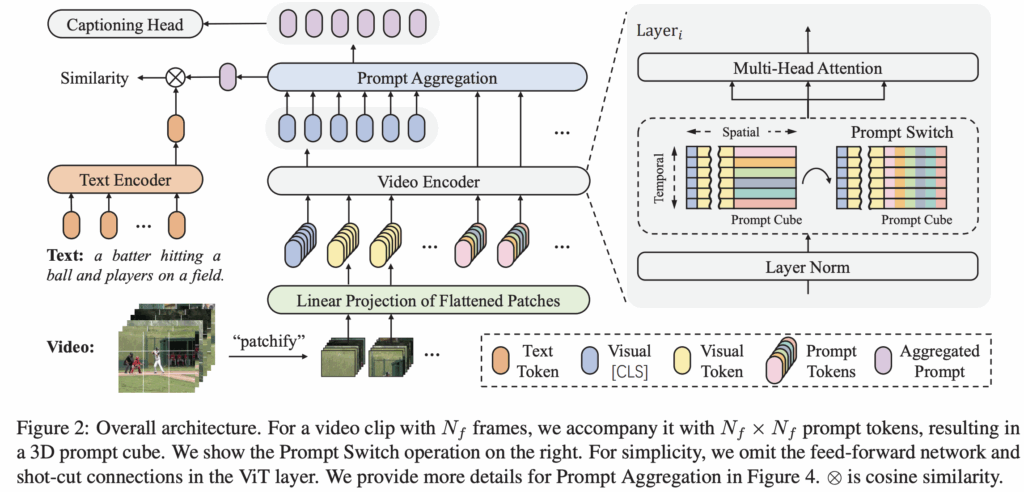
먼저 저자가 제안하는 모델의 아키텍쳐는 그림 2에 나와있습니다. 연산 과정을 간략하게 소개하면, 이 모델은 사전학습된 CLIP을 기반으로 하고 입력 비디오가 주어졌을 때 먼저 각 비디오 프레임에 대해 고정된 크기의 패치로 분할하여 패치 임베딩을 생성하고 여기서 CLS 토큰을 concat하여 frame 임베딩을 생성합니다. 그다음 저자가 제안하는 프롬프트 큐브는 Prompt Switch 연산을 통해 모든 프레임의 패치 임베딩에서 global 정보를 연결합니다. 그 후에 비디오 프레임의 CLS 임베딩과 최종 프롬프트 큐브를 Prompt Aggregation 모듈에 입력되고, 또한 Auxiliary Captioning Objective을 통해 fine-grained 한 정보도 학습되도록 구성을 했습니다.
2.1. Prompt Cube for Bridging Global Semantics
Prompt Cube는 비디오의 전체적인 temporal 정보를 포함하도록 설계되었습니다. 먼저 입력 비디오가 Nf 프레임을 가지고 있을때 각 프레임을 나눈 패치 임베딩 V∈RNf×L×D를 구합니다. 여기서 L은 spatial dimension의 크기를, D는 임베딩 차원을 의미합니다.
다음으로, 프롬프트 큐브는 P∈RNf×Nf×D 형태의 3D 텐서로 구성됩니다. 이후 VIT Layer입력 될때 V와 P를 spatial dimension을 축으로 하여 concat 하여 [V;P]∈RNf×(L+Nf)×D로 만들어 입력합니다.
또한 프롬프트 큐브의 첫 두 차원(temporal, spatial 축)은 크기가 같아서 서로 위치를 바꿔도 텐서 모양이 변하지 않습니다. 이를 이용해, 저자는 프롬프트 스위치(Prompt Switch)라는 연산 기법을 제안합니다. 이 연산은 각 프레임의 로컬 spatial 정보와 의미와 비디오 전체의 temporal 정보를 프롬프트 큐브를 통해 교환합니다.
프롬프트 스위치는 다음과 같은 수식으로 정의할 수 있습니다:
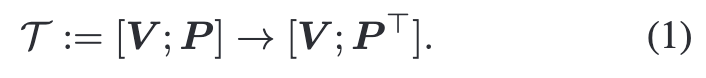
그림 2 오른쪽에 나와있듯이 ViT 인코더의 각 self-attention 전에 이 연산을 적용합니다. 그 후 self-attention은 [V;P] 의 spatial 차원에서 연산되며, 프롬프트 큐브의 i-번째 행 (pi∈R1×Nf×D)과 i-번째 프레임의 패치 임베딩 (vi∈R1×L×D)이 서로 정보를 주고받습니다.
Prompt Cube는 pi,j∈RD 형태로, 여기서 i는 현재 프레임 위치를, j는 대상 프레임 위치를 나타냅니다. 즉, pi,j는 i번째 프레임에서 j번째 프레임으로 정보를 전달할 때 사용하는 프롬프트로 생각할 수 있습니다. 이 프롬프트 큐브는 ViT 인코더의 두 연속 레이어에서 적용되는데, 첫 번째 레이어에서는 pi,j를 i번째 프레임의 벡터 vi와 결합하여 처리한 후, spatial과 temporal 축을 교환하여 연결 방향을 바꾸고, 동일한 pi,j 를 j번째 프레임의 벡터 vj에 결합해 연산합니다. 이러한 절차를 거치면 pi,j는 i프레임과 j프레임 모두를 통과하며 각 프레임 간 특징을 연결하는 매개체 역할을 수행할 수 있습니다. 이 과정을 모든 프레임 쌍에 대해 반복함으로써 비디오 클립 내 모든 프레임-프레임 조합이 프롬프트를 통해 1:1로 연결되고, 결과적으로 한 프레임의 정보가 다른 모든 프레임에 직접적으로 전파됩니다.
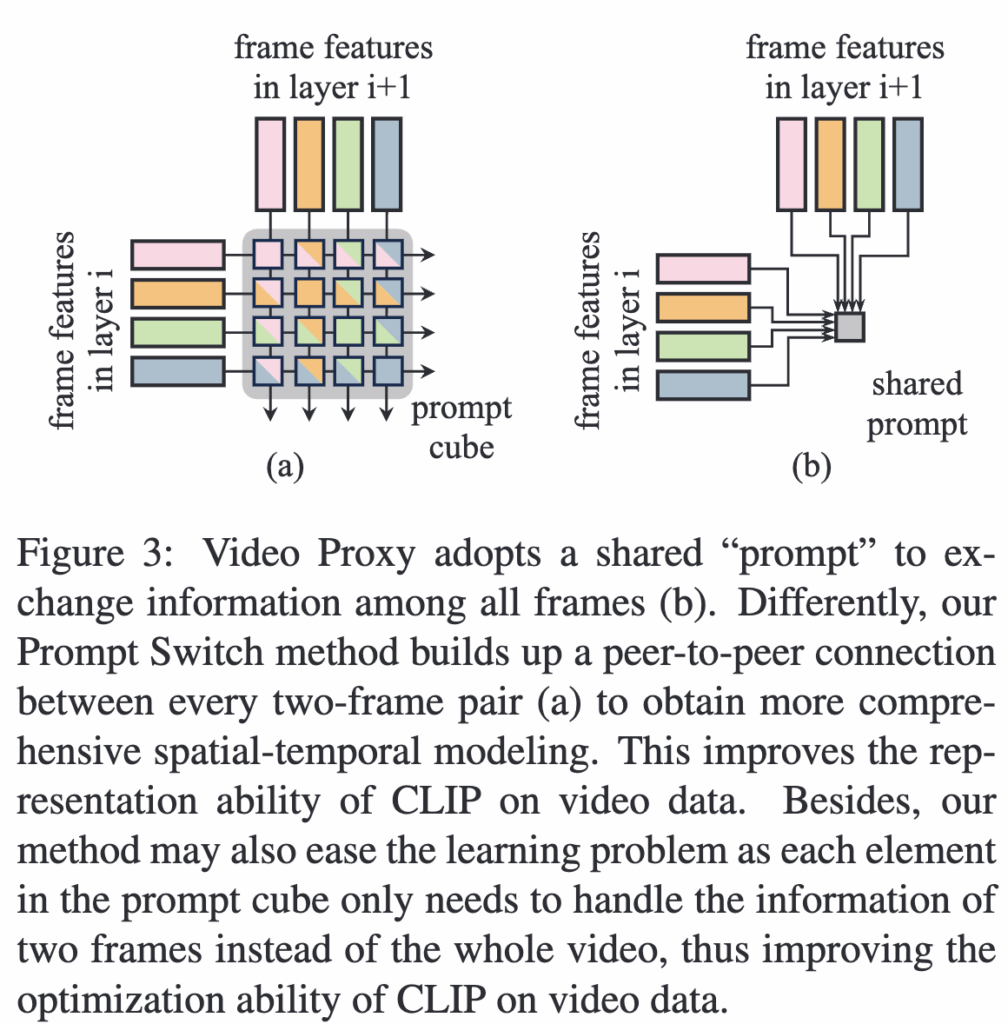
기존 연구들 중 Token Shift와 Video Proxy는 CLIP ViT 인코더의 백본에 temporal adaptation을 적용했으나, Token Shift는 한 프레임의 일부 토큰을 바로 옆 프레임으로 이동시켜 때문에 글로벌한 temporal 의미를 제대로 모델링하지 못하고, spatial 모델링 능력도 손상시킵니다. Video Proxy는 여러 프록시 임베딩을 통해 모든 프레임 정보를 교환하지만 프레임 간 1:1 연결이 없어 temporal 모델링 성능이 떨어질 수 있습니다(그림 3.a). 반면 저자의 Prompt Switch 방법은 모든 프레임 쌍마다 1:1 연결(그림 3.b)을 만들어 더 포괄적으로 시간 정보를 학습할 수 있습니다.
Prompt Aggregation
Prompt Cube는 모든 프레임의 모든 패치 임베딩과 상호작용하며 비디오의 전역 의미를 얻으므로, 기존 CLIP처럼 [CLS] 토큰만 사용하는 대신 이를 기반으로 최종 표현을 생성합니다. 구체적으로, 입력으로는 각 프레임의 [CLS] 임베딩 ci∈R1×D과, 프레임 쌍 단위로 구성된 Prompt Cube를 temporal·spatial 차원으로 펼친 벡터 집합 P^∈RNf2×D 이 사용됩니다. 연산 과정에서 각 프레임의 [CLS] 임베딩 ci 는 Query로, P^는 Key와 Value로 사용되며, Multi-Head Attention(MHA)을 통해 각 프레임은 Prompt Cube 안에서 자신과 관련 있는 정보를 추출합니다. 이렇게 얻은 결과는 원래의 ci와 더해지고 Layer Normalization을 거쳐 프레임별 프롬프트 벡터 pˉ 가 생성됩니다.
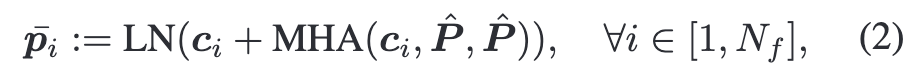
최종 비디오 벡터는 모든 pˉ 정규화한 뒤 mean-pooling하여 계산됩니다.
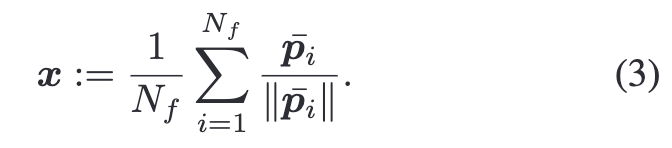
2.2 Learning Detailed Semantics via Captioning
이 방법은 retrieval을 수행할때 CLIP처럼 추론 속도를 유지하면서 훈련 시 비디오 표현이 fine-grained한 의미 정보를 잘 학습하도록 설계되었습니다. 핵심 아이디어는 추론 단계에서는 텍스트와 비디오 벡터 간 코사인 유사도만 계산해 효율성을 높이고, 훈련 단계에서만 Auxiliary Captioning을 추가해 표현력을 높이는 것입니다.
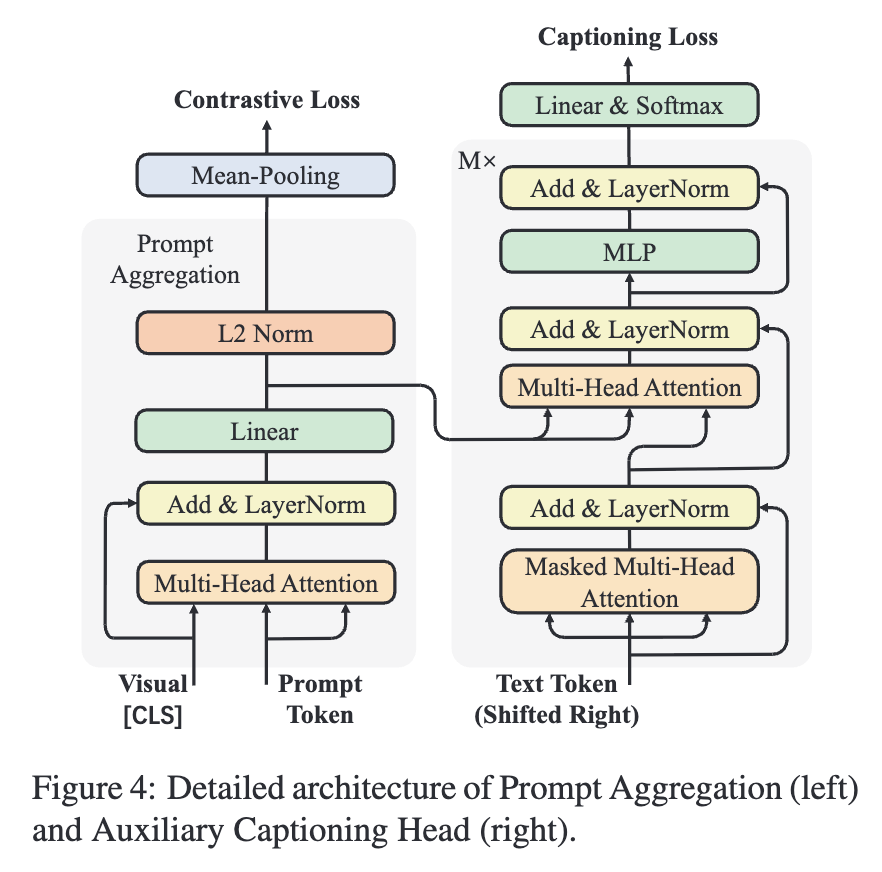
이를 위해 M개의 Transformer Decoder로 구성된 캡셔닝 모듈 H를 사용합니다.(그림 4). 동작 방식은 먼저 텍스트 토큰을 오른쪽으로 한 단계 이동시킨 뒤 Masked Multi-Head Attention으로 각 단어가 앞선 단어만 참고하게 하고, 두 번째 단계에서는 프레임별 프롬프트 벡터 pˉ를 입력받아 MHA를 수행합니다. 이 모듈은 autoregressive Teacher Forcing를 통해 훈련되는데 이는 각 단계의 예측이 다음 단계에서 토큰의 likelihood를 최대화하도록 학습이 진행됩니다. 그리고 이를 수식으로 나타내면 다음과 같습니다.
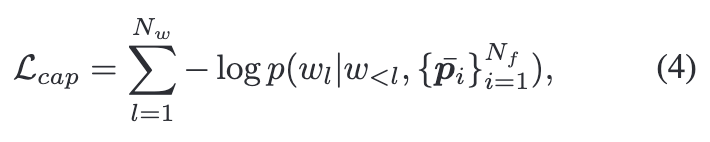
여기서 wl는 텍스트에서 l번째 토큰을 나타내고, w<l 는 wl 이전에 나온 토큰들, Nw는 전체 토큰의 개수를 의미합니다. 따라서 전체 학습 Loss는 contrastive loss와 captioning loss으로 구성되고 수식으로는 다음과 같이 표현할 수 있습니다.
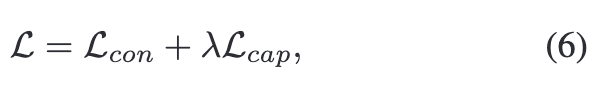
3. Experiment
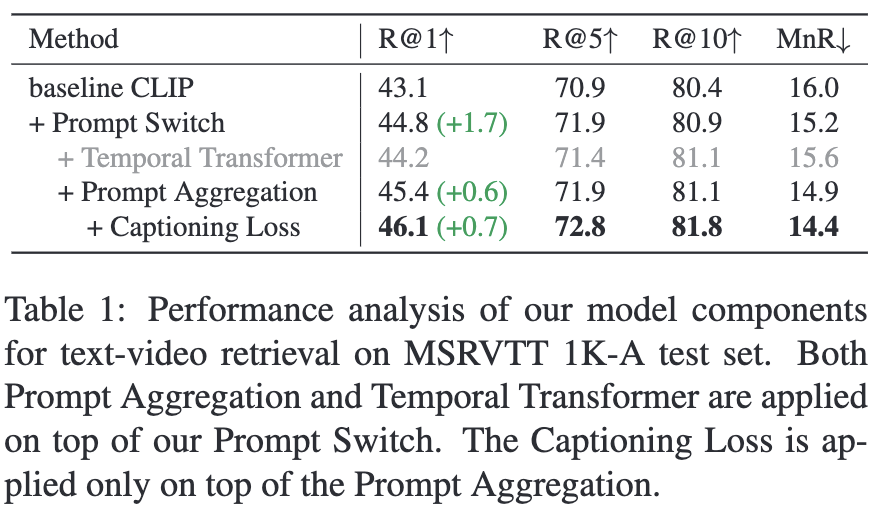
먼저 저자는 제안하는 기법들(Prompt Switch, Prompt Aggregation, Auxiliary Captioning Objective)에 대해 ablation study을 먼저 진행했습니다. 기본 베이스라인인 CLIP 모델은 비디오 프레임들의 [CLS] 임베딩을 평균 풀링하여 최종 비디오 벡터로 사용하며, contrastive loss만으로 학습됩니다.
먼저 Prompt Switch 메커니즘을 도입했을 때 R@1 성능이 크게 상승했고, Prompt Aggregation을 추가하면 R@1이 다시 0.6 향상되어 45.4를 기록했습니다. 마지막으로 Auxiliary Captioning Loss를 포함한 최종 모델은 R@1, R@5, R@10, MnR 모든 지표에서 크게 성능이 개선된 것을 확인할 수 있습니다. 이를 통해 제안한 모든 기법들이 최종 성능에 기여 한다는 것을 보여줍니다.
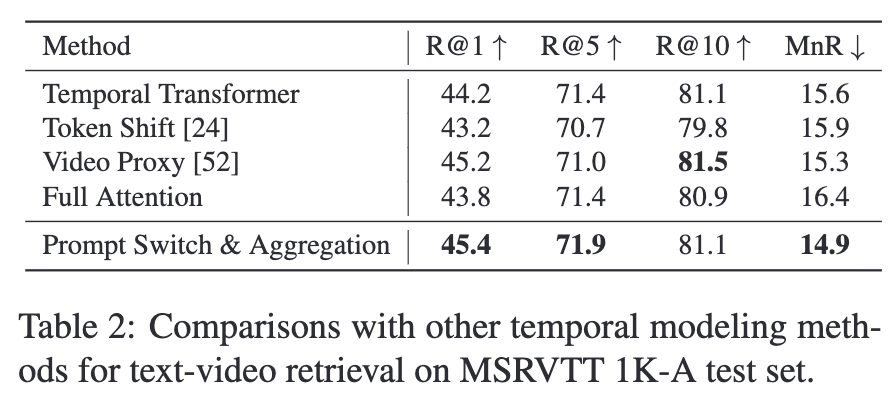
또한, [CLS] 임베딩에 추가 트랜스포머 층을 적용한 대안적인 시계열 집계 방법인 Temporal Transformer와 Prompt Aggregation을 비교했는데, 표 1에서 모든 평가 지표에서 Prompt Aggregation이 Temporal Transformer보다 우수함을 확인할 수 있습니다.
Comparison with the State-of-the-arts
이번 실험에서는 MSRVTT, MSVD, LSMDC (표 4,5,6)데이터셋에서 제안한 방법을 다른 기법들과 비교합니다.
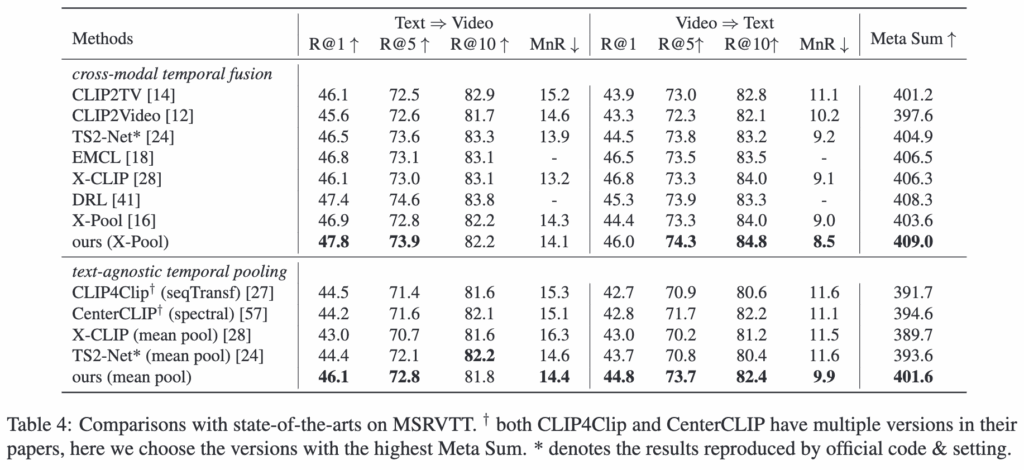
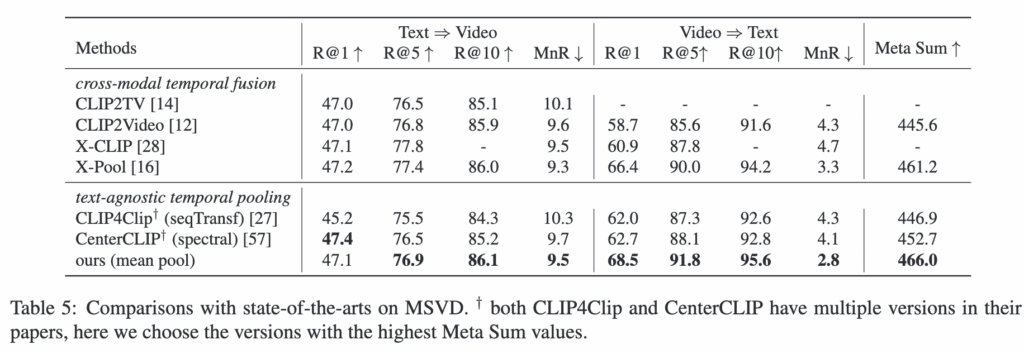
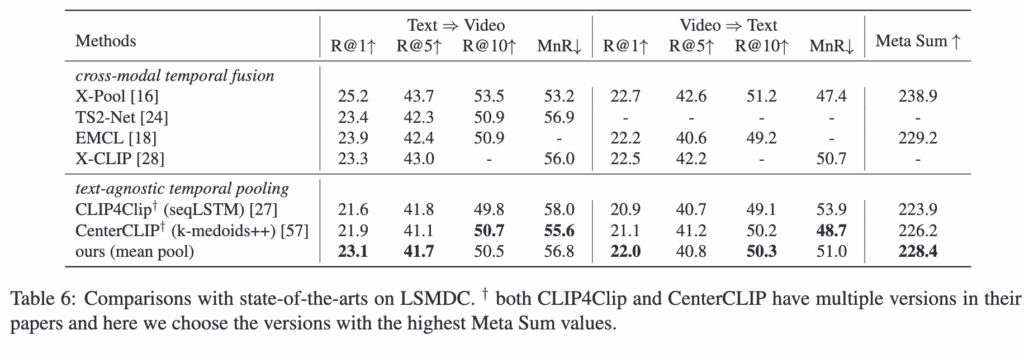
표들을 보면, text-agnostic temporal fusion setting에서 저자의 모델은 대부분의 평가 지표에서 기본 베이스라인 모델들을 뛰어넘었고, 특히 Meta Sum 지표에서 세 데이터셋 모두 최고 성능을 기록했습니다.
구체적으로, MSRVTT에서는 저자의 모델이 Meta Sum이 두 번째로 좋은 모델보다 7점 높고, MSVD에서는 CenterCLIP 보다 13.3점 더 높은 결과를 보여주었습니다. 또한, cross-modal temporal fusion 방법과 비교해도, 평균 풀링을 사용하는 저자의 모델은 Meta Sum 기준으로 높은 성능을 유지하면서도 훨씬 더 효율적이라는 것을 알 수 있습니다.