안녕하세요. 이번에는 아카이브에 있지만 현재 창의학기제에서 CLIP 모델에 LoRA를 적용해보는게 어떨지 좀 서베이 해보다가 읽게된 논문을 들고왔습니다. 제가 생각했던 문제점을 실제로 다뤄줘서 들고왔고, 최초 LoRA 논문을 들고올까 하다가 ViT나 CLIP에서 LoRA를 적용한 실험을 들고오고 싶었습니다. 뭔가 CLIP 을 전부 파인튜닝하는 것이 GPU 적 한계점도 있고, fine-grained 레벨에서의 새로운 도메인을 재학습 시키는 과정에서 기존 지식을 까먹지 않고 새로운 도메인에서의 성능도 어느정도 나오게 할 방법들을 조금 생각해보다가, FLYP 방식과 LoRA를 동시에 적용해볼? 방법을 생각했었는데, 그걸 아예 그대로 실험한 논문이 존재해서 좀 반가웠습니다. 리뷰 시작하겠습니다.
Abstract
딥러닝모델을 새로운 도메인으로 재학습 하는 것은 엄청나게 많은 연산량이나 catastrophic forgetting같은 리스크를 가지게 된다고 합니다. 파인튜닝을 진행하는 것은 새로운 도메인에 대한 적응을 가능하게 하지만, 모델의 강건성을 줄이거나 distribution shift, 혹은 OOD 성능의 변화를 가져오게 만듭니다. 이는 제가 이전에 작성했던 리뷰인 FLYP 논문에서 언급했던 문제입니다. 저자는 특히 이러한 문제가 CLIP 같은 대규모 모델이 zero shot 성능에서 강인함을 보이다가 파인튜닝 후 강건성을 잃는 문제를 언급합니다. 해당 논문에서는 TAPS(Task Adaptive Parameter Sharing) 에 기반한 LoRA 블록을 선택적으로 활성화하는 PEFT(parameter-efficient fine-tuning) 기법을 제안한다고 합니다.
해당 방법론은 앞서 말한 일반화 성능을 낮추는 문제를 해결하고 전통적인 파인튜닝 기법보다 연산량도 줄였다고 어필하고 있습니다. 심지어 전체 LoRA 블록중 5%만 활성화해도 효과적인 파인튜닝이 가능하다는 것을 보였다고 합니다.
Introduction
앞서 말했듯이 딥러닝 모델은 대규모 데이터셋을 기반으로 학습되어 다양한 클래스와 응용 분야에 대해 강력한 일반화 성능을 보여왔습니다. 그러나 이러한 모델을 새로운 도메인에 적응시키는 과정에서 신규 객체 인식이나 자율주행같은 특수 환경에서는 막대한 재학습 비용이 생기고 catastrophic forgetting(기존 지식을 까먹는 현상) 같은 문제를 야기할 수 있습니다. (CLIP같은 zero shot 모델들도 파인튜닝시 강건성과 zero shot 성능이 떨어지 문제가 존재합니다.)
이러한 상황에서 PEFT 같은 전략이 학습해야할 파라미터를 선택적으로 제한하여 계산량도 적고 지식 보존도 동시에 할 수 있어 연구되어 왔는데, 처음 LLM 에서의 학습 비용을 줄이기 위해 연구되던게 비전-언어 모델에서도 성공적으로 적용되는 추세라고 합니다.
기존 연구중 TAPS는 사전학습 모델을 다양한 task에 적응시키기 위해 task 특화 적응 레이어와 indicator 함수를 결합한 기법으로, STE(straight-through estimator) 를 사용해 학습된 지표를 기반으로 일부 레이어만 선택적으로 활성화하는 기법이라고 합니다. 선행 연구가 있어서 링크를 첨부합니다. (Task Adaptive Parameter Sharing for Multi-Task Learning)
간단하게 TAPS를 설명하면 여러 task를 위해 공통 모델로 학습하는 경우 각 task에 어느 layer의 가중치를 얼마나 줄지를 선택하는 방법이 TAPS 입니다. 여기서 indicator 함수는 단순하게 step function 같은거라 생각하시면 되는데, 어떤 파라미터를 어떤 task 에 쓸지 결정하는 binary mask의 역할을 합니다. 이러한 binary mask는 이산값이기 때문에 gradient가 흐르지 않지만, STE 방법을 쓰면 학습이 가능해진다고 합니다. 즉 forward에서는 gradient가 끊기는 우리가 아는 연산을 그대로 하되 backward에서는 identity function처럼 gradient를 흘려준다고 하네요.
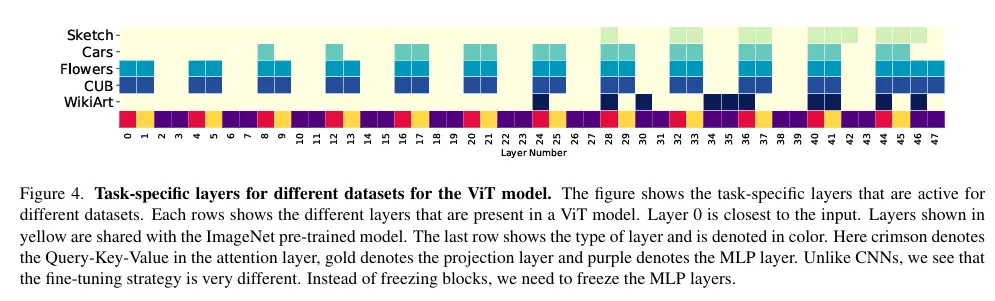
위의 TAPS 논문에서 가져온 figure 인데 동일 모델에서 각 dataset에 따라 활성화되는 layer 들의 분포를 보여줌으로써 모델이 task별로 파라미터를 적응적으로 선택했다는 증거라고 생각하시면 될 것 같습니다.
다시 본론으로 돌아와서 본 논문은 TAPS의 아이디어를 확장해서 LoRA 기반의 PEFT 구조에 적용할 수 있도록 새로운 적응 기법을 제안합니다. 저자는 CLIP이나 DINO 와 같은 비전-언어 모델을 대상으로, 지표함수 기반 특정 LoRA 블록만 선택적으로 활성화 하는 방식으로 학습을 진행한다고 합니다. 이 방식은 다양한 PEFT 기법 (LoRA, DoRA) 등에 적용될 수 있으며 일반화 성능과 zero-shot 능력을 유지하면서도 in-domain 적응 성능을 개선한다고 합니다.
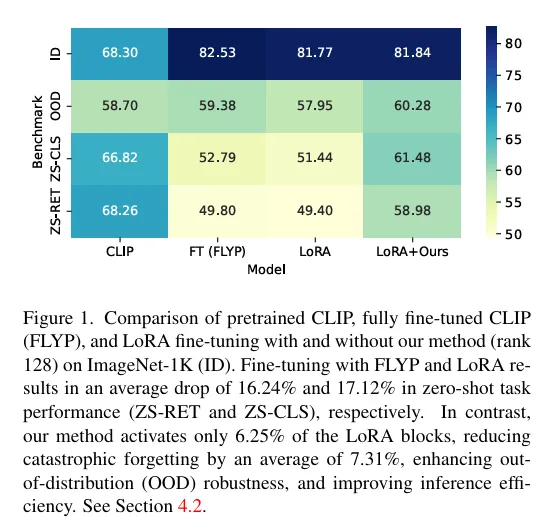
해당 이미지를 보게되면 기존 CLIP에서 FLYP 방식으로 파인튜닝하게 된 것과 기존의 LoRA를 사용한것의 zeroshot retrieval 성능, zeroshot classification 성능, OOD, ID 성능 변화를 보여주는데 FLYP 와 LoRA 방식 모두 ID OOD에 대한 성능개선이나 유지가 가능했지만, RET CLS 성능은 꽤나 감소하는 경향을 보여줍니다. 저자의 방식은 ID OOD 성능은 물론 다른 taks에서도 성능 하락폭이 매우 적은 것을 볼 수 있습니다.
저자의 방식은 PEFT 기법이 multi task learning이나 이미지생성과 같은 응용 분야에서도 유용함을 확인했다고 하고 LoRA 블록을 선택적으로 활성화함으로써 기존 가중치에 직접 병합하는 방식에서 발생할 수 있는 성능 저하를 방지하고, 모델 구조의 일관성을 유지하면서도 계산량을 줄이는 데 성공했다고 합니다.
Methodology
problem setup
기본적으로 자기지도학습 기반 모델이 존재하고, 이는 사전학습 데이터로 학습됩니다.
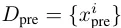
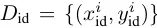
D_pre 는 사전학습 Dataset, D_id는 라벨이 있는 데이터셋 입니다. 여기서 P_pre는 D_pre의 입력분포이고 P_id는 라벨이 있는 파인튜닝시 사용할 데이터셋의 분포입니다.
Domain shift:
입력 분포는 다르지만 클래스는 동일한 상황에서의 평가를 진행합니다. ( P_id ≠ P_ds , C_id 동일) ID성능은 유지되고 OOD에 대한 강건성을 평가하기 위합입니다.
Zero-shot classification:
훈련에 없던 새로운 클래스들을 평가합니다. C_zsc ( C_id ∩ C_zsc = ∅)
Zero-shot Retrieval :
이미지-텍스트 쌍으로 구성된 데이터셋으로 평가합니다.
목표는 ID성능은 높이되, domain shift / zero-shot 환경에서도 일반화 성능을 유지하는 것입니다.
Indicator Function for LoRA-Variant Methods
기존의 LoRA는 사전학습된 가중치 W0 을 그대로 두고 저차원 보정행렬을 추가로 학습하는 방식입니다.
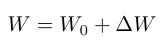
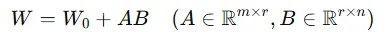
(where the residual ∆W is factorized as ∆W = AB. Here, A ∈ Rm×r and B ∈ Rr×n, with the rank r ≪ min(m,n) to ensure that memory usage remains minimal.)
저자는 TAPS 에서 영감받아 LoRA방식에 지표함수를 도입하게 되는데, 각 블록 ℓ 에 대해 스코어 si 를 부여하고 임계값 τ 이상일 때만 해당 LoRA 블록을 활성화하는 방식입니다.
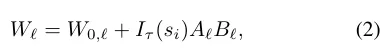
W0ℓ 은 사전학습된 가중치이고 임계값 이상일때만 블록을 활성화 시킬 수 있게끔 지표함수를 추가한 형태입니다.
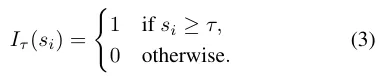
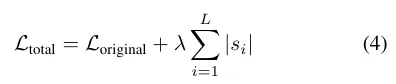
전체 loss에 다음과 같은 L1 정규화 항을 추가하여 λ 값이 커질수록 더많은 블록이 비활성화 되게끔 설정했습니다.
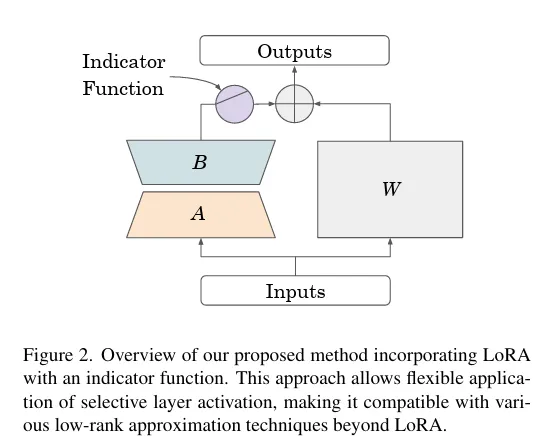
이 도식도는 기존 LoRA 구조에 indicator function을 추가한 모습입니다. 각 블록마다 켤지 말지를 유연하게 선택할 수 있게하는 해당 방식이 LoRA 이외의 다른 저차원 근사 방법들에도 사용될 수 있음을 어필합니다.
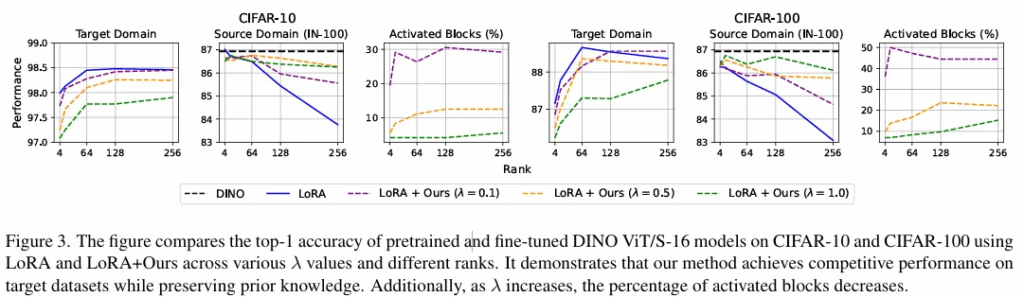
해당 표로 LoRa 방식과 저자의 indicator LoRa방식의 성능비교를 할 수 있습니다. LoRA의 rank수를 늘리면 target domain에서의 성능은 올라가고 사전학습때의 성능은 더 많이 떨어지는 것을 확인할 수 있습니다. 이때 λ 값이 커지면 활성화되는 블록수가 적어지고, target domain의 성능은 조금 낮아지지만 기존 지식을 덜 잃는 경향성을 확인할 수 있습니다.
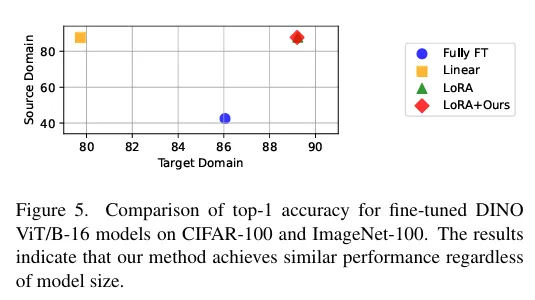
모델의 크기를 ViT/S-16 에서 ViT/B-16 으로 늘려도 성능 유지가 가능해서 스케일 확장성이 있다고 합니다. CIFAR-100 에서는 기존의 LoRA만큼의 정확도, ImageNet-100 에서는 catastrophic forgetting도 LoRA보다 덜하다고 합니다. ViT/S-16 에서는 20~40%의 LoRA 블록을 사용했고, ViT/B-16 에서는 43프로만 사용했습니다.
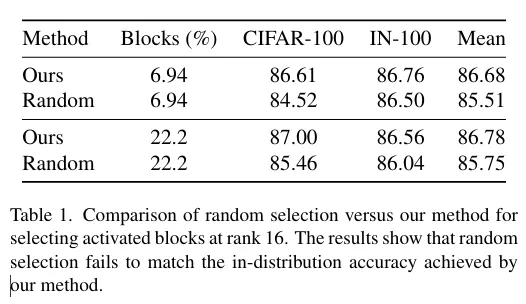
해당 Table로 random으로 블록을 활성화했을때보다 저자의 방식이 CIFAR에서는 2%, IN-100에서는 0.5% 정도 성능이 더 좋았음을 보여줍니다.
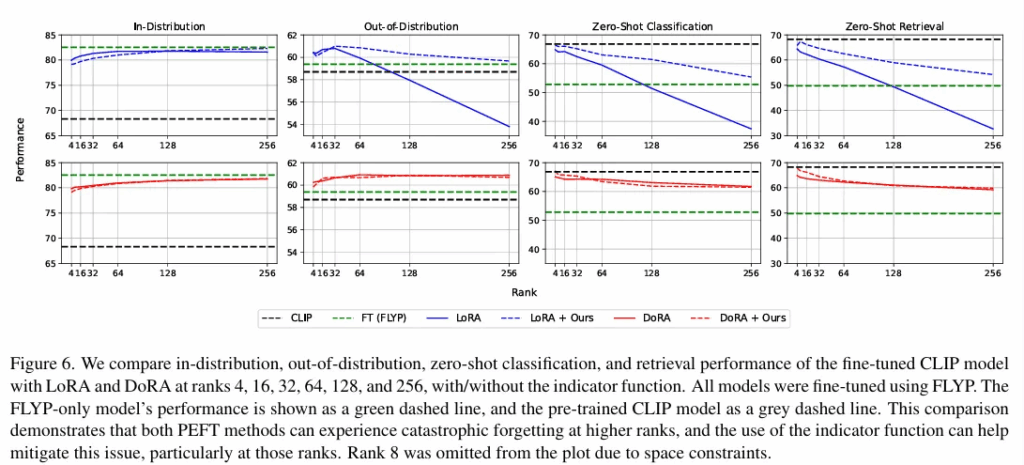
CLIP 기반 모델을 ImageNet-1k 에 파인튜닝한 후 ID 성능, OOD 성능, zero shot 성능과 retrieval 성능을 보여줍니다. 확실히 LoRA 방식보다 저자의 방법론에서 catastrophic Forgetting이 억제되는 모습이 보입니다. DoRA는 이미 자체적으로 LoRA보다 안정적이라 저자의 방법론과 크게 성능차이가 나지 않는 모습도 확인할 수 있습니다. ( 저자의 방법론이 블록을 덜쓰긴 합니다.)
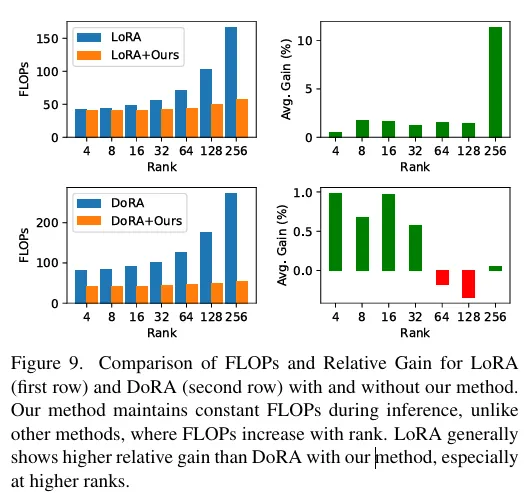
해당 이미지는 rank 별 LoRA와 DoRA의 FLOPs 가 증가하는 것에 비해 저자의 방법론은 거의 동일한 연산량을 필요로하고, 우측은 저자의 방식으로 LoRA와 DoRA를 활용했을때 얻을 수 있는 Gain 값으로, LoRA로 높은 rank를 사용했을때 FLOPs는 낮지만 이득을 많이 볼 수 있다고 합니다. 다만 DoRA는 이미 성능이 더 높아서 그만큼의 gain이 안나오는 것이긴 합니다.
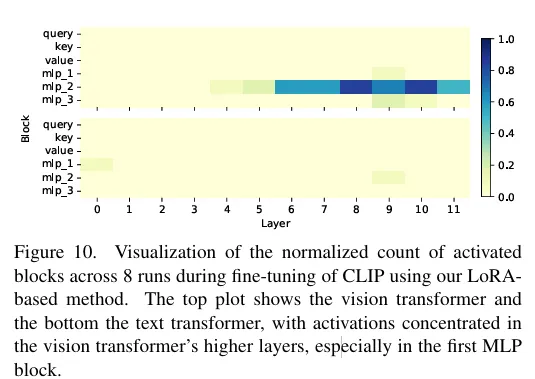
해당 이미지는 CLIP 모델을 저자의 방법론으로 파인튜닝할때 8번의 반복실험에서 어떤 레이어가 자주 활성화 되었는지를 시각화한 것입니다. 위쪽 그래프는 ViT이고 아래는 Text Transformer 입니다. ViT가 훨씬 많이 활성화되고, 뒷단의 레이어일수록 선택될 확률이 높은 것을 알 수 있습니다. Text Transformer는 거의 선택되지 않고 사전학습된 표현을 대부분 유지해도 문제가 없다고 합니다.
Conclusion
기존 PEFT 기법인 LoRA나 DoRA는 효과적이지만 high-rank 에서 catastrophic forgetting이 발생 가능합니다. 저자는 여기에 TAPS 를 확장한 indicator function 기반 selective LoRA 방식을 제안했습니다. 기존의 5%정도되는 LoRA 블록만 학습해도 competitive한 성능을 확보할 수 있음을 보였고 OOD 에 대한 강건성도 유지되는 것을 보였다고 할 수 있습니다.
저자는 한계점으로 명시적으로 catastrophic forgetting을 해결한 것은 아니고 부수적으로 줄이는 구조라고 설명했고, 활성 블록 수를 정확히 제어할 수 없고 λ 값으로 조절해야 하는 것이 한계점이라고 합니다. 향후 domain adaptation 관점에서 PEFT 를 더 깊게 이해하고 사전학습된 모델을 효과적으로 적응시킬 수 있는 contributes가 될 수 있다고 언급했습니다. 감사합니다.
안녕하세요. 리뷰 잘 읽었습니다. 궁금한 게 몇개 있어서 질문을 드리자면, rank수를 늘린다는 게 학습가능하게 두는 파라미터수를 늘린다는 걸로 이해했는데 그게 맞을까요? 그리고 indicator function은 사전 가중치에 추가적으로 더해지는 보정행렬에 대한 활성화 여부를 나타내는 것이라고 이해했는데 맞을까요?
안녕하세요 지연님 답글 감사합니다.
rank 수는 LoRA 같은 방법론에서 저차원 행렬의 크기라 보시면 될 것 같습니다.
indicator function에 대한 설명도 맞게 이해하셨습니다. LoRA같은 추가행렬에 대한 활성정도를 랜덤으로 선택하는 것이 아닌 STE 방법론을 통한 학습가능한 방식으로 구현했다고 이해하면 될 것 같습니다.
안녕하세요 인택님 좋은 리뷰 감사합니다.
단순한 질문인데요 리뷰 서두에서 “FLYP 방식과 LoRA를 동시에 적용해볼 방법”을 언급해주셔서 해당 논문에서의 실험은 뭔가 FLYP loss 기반 파인튜닝 과정에서 LoRA를 적용한 구조 같아서 두가지 방식을 동시에 적용한다기 보다는 LoRA가 메인인 느낌이 강했는데, 창의학기제에서 인택님이 두가지 방법론을 어떻게 적용시키고 싶은지가 개인적으로 궁금합니다.
그리고 추가 질문인데 Vision Transformer 쪽 수정이 우선적으로 선택되고 Text Transformer는 거의 선택(활성화)되지않는다고 하는데 이 부분에 대한 이유가 궁금합니다.
감사합니다.
안녕하세요 우현님 답글 감사합니다.
뭔가 저도 아직 지식이 넓지는 않아서 LoRA가 메인인지 FLYP 가 메인인지에 대한 답변은 너무 주관적이라 생각이 드는데요.. FLYP 방식이 매우 직관적이고 이해하기 쉬워서 그렇지 loss 함수를 아예 바꿔버리는 형태에 이미지 인코더와 텍스트 인코더 모두에 영향을 줄 수 있는 방법론이라 서브 느낌은 또 아닌 것 같습니다. LoRA는 우선 CLIP의 모든 layer를 학습시키는 것이 GPU적 한계가 있으니 한번 적용해봐야겠다 정도에서 서베이를 시작했는데, 기존 LoRA 보다 훨씬 적은 파라미터를 사용하면서도 OOD 에 대한 강건성과 ID 성능유지가 가능해서 리뷰로 가져오게 되었습니다. fine grained level 에서의 OVOD 모델을 학습시키는 과정에서 두가지 방법론 모두 적용할 생각입니다. 아마도 지도학습, 약지도학습에서의 ID OOD 성능비교를 하지 않을까 싶습니다.
추가로 Text Transformer 부분이 덜 선택되는 경향은 이미 사전학습때 사용된 표현력을 그대로 사용하더라도 성능에 크게 변화가 없어서 그런 것 같습니다. 뭔가 LoRA같은 방법론이 초기에 LLM 같은곳에서 효과적이었던 것과 비교하면 좀 흥미로운 부분인 것 같네요. 감사합니다.
좋은 리뷰 감사합니다. 대규모 사전학습 모델의 지식을 어떻게 하면 목표 task에 잘 쓸 수 있을까 궁금해서 재밌게 읽어보았습니다. 일반적으로는 regularization을 많이 쓰는 것 같던데, 다양한 방법이 있네요. 평가가 너무 쉬운 task와 데이터셋에서 이루어진 점은 약간 아쉽습니다.
질문 남기자면, 분류 말고 detection이나 segmentation 등 다른 task로의 적용에 대한 언급이 있었나요? 있었다면 관련 내용이 궁금합니다. 그리고 중간에 DINO는 meta에서 나온 SSL dino 말하신 것 맞죠? VLM이라고 언급하셔서 확인 질문 드립니다.
안녕하세요 재연님 답글 감사합니다.
우선 detection segmentation 등과같은 다른 task 에대한 실험은 없었습니다. 그리고 dino 는 확인해보니 VLM이 아니고 self supervised learning 된 DINO로 이해하신게 맞습니다. 감사합니다.