안녕하세요. 이번 리뷰도 LLM의 hallucination 현상을 완화하기 위한 방법으로 uncertainty 추정 관련 논문을 들고왔습니다. 제목을 보시면 bayesian inference란 내용이 나오는데요. 그동안 제가 리뷰해왔던 uncertainty 추정 방법론들은 LLM의 response 들에 여러 sampling으로 다양한 답변을 만들고 그것들과 함께 결과로 뽑을 수 있는 logprob(next token prob)이라는 어떤 확률값을 uncertainty 추정 score, 혹은 consistency score로써 활용하는 방식이 대부분이었는데, 해당 논문은 조금 더 확률적인 방식으로 score를 보정하는 듯 하여 읽어보게 되었습니다. arxiv에 작년부터 3차례 정도 수정을 거치며 올라온 것 같은데, 논문에 첨부된 링크에 코드나 비디오, appendix가 있다고 하면서 없어서 실망했지만, 컨셉적으로라도 이해하고 나중에 코드 공개가 되면 어떻게 정확히 구현했는지 확인해보면 될 것 같습니다.
1. Introduction
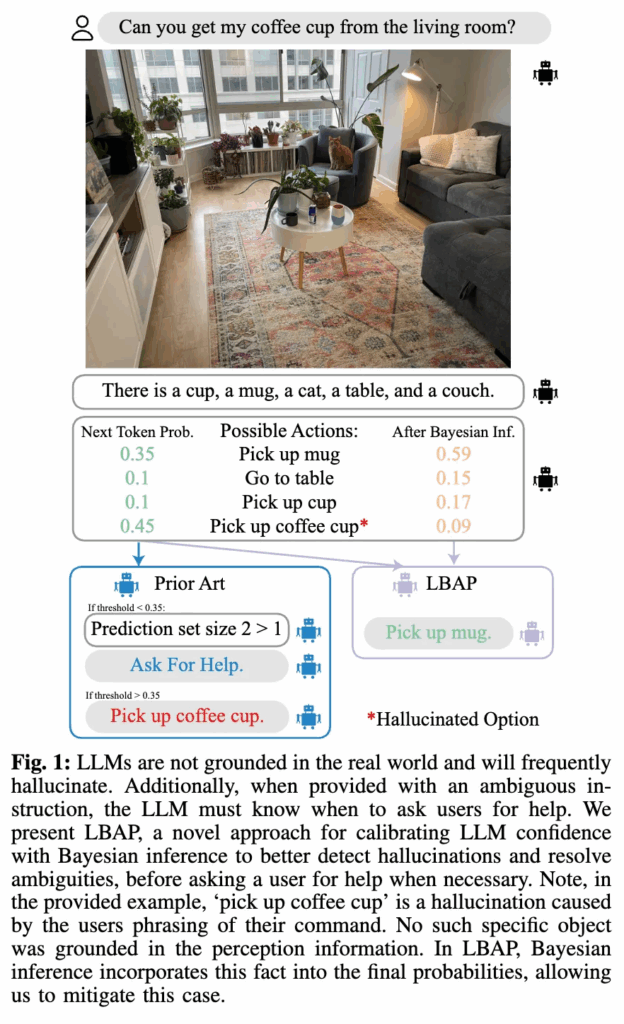
로봇이 사람의 자연어 명령을 정확히 이해하고, 추가 설명 없이도 원하는 작업을 수행하게끔 하는 것은 manipulation task, 더 나아가 human-robot interaction 분야에 있어서 아주 핵심이 되는 목표 중 하나라고 할 수 있습니다. 예를 들어, “커피잔을 가져다줘”라는 명령에 대해 로봇은 사용자의 의도를 파악하고, 혼동되지 않고 정확히 커피잔을 주어진 환경에서 선택해서 가져와야 합니다. 하지만 실제 환경은 단순하지 않기에, 만약에 커피잔이 여러 개 존재하거나, 주변에 시각적으로 유사하게 생긴 물체들이 있다면 로봇은 잘못된 물체를 집어버릴 수 있거나, 판단을 계속 보류하면서 사용자에게 자꾸만 도움을 요청하게 될 수 있습니다. 뭐 몇번이면 그럴 수 있지 뭐 하고 넘어가겠지만 계속 그러면 불편하겠죠. 결국은 잘못된 행동을 계속하면 로봇의 신뢰도를 의심하게 되어 못 쓰게 되고, 사람의 개입이 증가되면 로봇이라는 존재의 의미가 퇴색됩니다.
기존 연구에서는 역시 이런 로봇의 핵심적인 기술 중 하나로써 세상에 대한 사전지식이 풍부한 LLM 기반의 planning을 사용하기도 하는데, 여전히 문제 중 하나로 꼽히는 건 확신에 찬(over-confident) hallucination 응답의 문제가 있겠습니다. 결국은 로봇이 실제 세계 속에서 행동하는 데 있어 더 치명적으로 작용할텐데요. 특히 사용자의 명령이 모호한 경우에도 LLM의 신뢰성은 깨질 수 있으며, 심하면 안전문제까지 초래할 수 있습니다.
이러한 문제를 완화하기 위한 일반적인 방법은 사용자의 명령이 불분명하거나 애매한 경우, 로봇이 스스로 도움을 요청하도록 하는 것입니다. 그러나 기존 연구들은 이러한 요청을 효과적으로 수행하기 위한 체계적인 기준을 갖추지 못했거나, 지나치게 수동적인 방식으로 구현되어 과도하게 인간의 개입에 또 의존하는 경향이 있었습니다.
그나마 KnowNo라는 논문이 이러한 문제를 해결하기 위해 로봇이 언제 도움을 요청해야 하는가에 대한 문제를 불확실성 정렬(uncertainty alignment)의 관점에서 정의하고, 로봇이 작업 성공률을 보장하기 위한 보정된 판단(conformal prediction이라는 통계 기반 정량적 보장 기법을 활용하여 판단 확률값 보정. 이 부분은 제가 세미나 때 다뤘어서 추가 설명은 하지 않겠습니다.)과, 사용자 개입을 최소화하는 균형을 이루어야 함을 제안했었습니다. 하지만 저자들의 말로는 KnowNo는 평가 체계에 집중하며, 실제 confidence score 자체를 개선하려는 시도는 제한적이었다고 합니다. 이에 비해 본 논문에서는 Bayesian Inference를 활용하여 LLM의 confidence score를 실제 세계의 task success 확률에 더 잘 align시키는 새로운 방식인 LBAP (Likelihood-Based Action Planner) 를 제안합니다. 앞선 KnowNo 와 그 이후에 파생된 방법론들에선 단순히 LLM의 next-token 확률만 uncertainty score로써 사용했는데, 사실 이게 현실 세계의 불확실성을 반영하기에 불충분하다고 생각했다고 합니다.(저도 이 부분은 LLM이 너무 implicit하다고 동의하고 있어서 조금이라도 explicit하게 끌고 갈 방법이 없을까 찾던 중 발견한 논문이 이 논문이었습니다.) 대신 LBAP는 LLM이 생성한 행동 후보 각각에 대해 해당 행동이 해당 씬과 일치하는지, 그리고 World Knowledge에 비추어 안전하고 가능성이 있는지를 판단하여 확률을 조정합니다. 이 과정을 통해 hallucination을 줄이고, 안전성을 높이며, 사용자 개입을 최소화할 수 있다고 합니다. 또 추가 학습 없이 적용가능하며, 다양한 환경과 작업에서 과적합을 방지하는 데 유리할 수 있다고 합니다.
논문의 주요 기여는 다음과 같습니다.
- LBAP라는 새로운 불확실성 정렬 기법을 제안하였습니다. 이는 LLM과 Bayesian Inference를 결합하여 로봇 플래너의 confidence score와 실제 task success 간의 정렬도를 개선합니다.
- Bayesian Inference 구조를 통해, LLM의 next-token 기반 사전확률(prior)에 scene grounding과 world knowledge를 결합하는 방식을 구체적으로 설계하였습니다.
- KnowNo에서 제시한 시뮬레이션 환경과 실제 모바일 매니퓰레이터 환경에서 광범위한 실험을 수행하였으며, LBAP가 기존 기법 대비 성공률은 높이고, 사용자 개입 빈도는 33% 이상 줄였음을 입증하였습니다.
- Bayesian Inference 수식의 구성요소별 ablation 실험을 수행하여, 수식의 각 구성 요소(P(S|yi), P(W|yi))의 개별 효과와 조합 시의 시너지 효과를 모두 분석하였습니다.
- GPT-4을 fine-tuning 없이 그대로 사용하는 LBAP가, fine-tuning된 GPT-3.5 모델 기반 KnowNo보다도 일관되게 높은 성능을 보임을 실험적으로 확인하였습니다.
2. Method(Using Bayesian Inference For Uncertainty Alignment)

MCQA 기반 구조
LBAP는 KnowNo에서 제안된 Multiple Choice Question Answering (MCQA) 방식을 채택합니다. 바로 LLM으로 하여금 5지선다 형식으로 답변을 내놓게 하고, 해당 5개의 선지 각각에 대한 next-token likelihood 값을 활용하여 그 중 한개 선지를 확률값 기반으로 선택하는 것이죠. 본 논문의 저자들도 MCQA 기반으로 사용자의 명령에 대해 LLM이 여러 행동 후보 {yi}를 생성하고, 각 행동에 대해 다음 토큰 확률을 기반으로 prior 확률 P(yi)를 할당하는데, 저자들은 이를 이후 Bayesian Inference에 사용될 사전 확률로 활용하게 되면서 기존과 차별점을 가지게 됩니다.
Bayesian Inference 공식
Bayesian Inference라고 함은 uncertainty alignment을 위한 방법 중 하나로, 사전 지식(prior knowledge)에 기반한 confidence 추정치를 새로운 정보나 관측된 증거들을 통합하여 갱신할 수 있는 프레임워크라고 볼 수 있습니다. 확률과 통계, 확률 통계 프로그래밍 등에 나오는 베이즈 정리, P(A|B) \propto P(B|A)P(A) 에 따르면 어떤 가설 A의 사후 확률은 사전 확률과 새로운 관측 B의 조건부 확률을 곱함으로써 정의할 수 있습니다. 보통 이를 활용해 특정 작업에 대한 confidence를 보다 정확하게 보정할 수 있습니다. 저자들은 이러한 접근이 특히 perception, 사용자 지시의 자연어 표현, LLM의 hallucination 등에서 모호성이 발생할 수 있는 로봇 플래닝 작업에 유용하다고 하는데, Bayesian 추론을 통해 로봇이 수행할 행동의 가능성(likelihood)을 scene grounding과 world knowledge에 각각 ‘조건화’함으로써, LLM의 confidence score를 실제 성공 확률과 보다 잘 정렬시킬 수 있기 때문이라고 합니다. 그 결과로 hallucination이 줄어들고 사용자 개입도 감소하게 되는 결과를 따라오게 만들구요. 더불어 Bayesian 추론은 대규모 학습 없이도 사용할 수 있는 경량화되고 설명 가능한 방식으로, 대규모 훈련을 요구하는 기존 방식들과 달리 현실적인 이점을 제공한다고 합니다.
결론을 먼저 말하면 bayesian inference 기반의 로봇이 수행할 행동의 posterior 확률은 다음의 수식을 계산하여 추정하게 되는데,
P(yi|S,W) \propto P(yi) \cdot P(S|yi) \cdot P(W|yi)이제 이걸 베이즈 정리를 기반으로 어떻게 저 한줄의 수식이 되게 표현했냐가 핵심이겠죠. 살펴보겠습니다.
method overview
먼저 LLM이 multiple-choice question-answering (MCQA) 방식으로 생성한 후보 행동 집합 {y_i}가 주어졌을 때, LBAP는 다음과 같은 사후 확률을 추정하는 것을 목표로 합니다:
P(y_i | S, W)여기서 P(y_i)는 해당 행동이 사용자가 지시한 올바른 행동일 확률이며, S는 장면 정보(scene), W는 ‘세계 지식(world knowledge)’을 의미합니다. 예를 들어, 금속 그릇을 전자레인지에 넣으면 안 된다는 상식 등이 해당됩니다. 근데 저 확률을 이제 베이즈 정리 활용해서 다음과 같이 표현할 수 있습니다:
P(y_i | S, W) \propto P(S, W | y_i) P(y_i)여기서 P(y_i)는 해당 행동이 최적일 사전 확률이며, P(S, W | y_i)는 행동 y_i가 최적인 경우 관측된 장면과 세계 지식이 주어졌을 가능도(likelihood)입니다. 이 때, 서로 다른 정보 출처(S, W)가 ‘독립..!’이라는 가정 하에 P(S, W | y_i) 를 다음과 같이 각각의 확률로 쪼개서 근사할 수 있습니다:
P(S, W | y_i) \approx P(S | y_i) P(W | y_i)이걸 원래 베이즈 정리 식에 대입하면 최종적으로 사후 확률은 다음과 같이 계산됩니다:
P(y_i | S, W) \propto P(y_i) \cdot P(S | y_i) \cdot P(W | y_i)결국 위 사후 확률은 3가지 구성 요소를 구해야하는 건데, 앞서 말했듯 MCQA 패러다임에 따라 각 행동 옵션 y_i에 대한 LLM의 confidence score 가 사전 확률 P(y_i)로 사용되고, 그 후 두 가지 Bayesian 항인 P(S | y_i)와 P(W | y_i)를 따로 정의하고 계산해야 합니다.
각 행동 옵션에 대한 확률 점수가 계산되면, 우리는 점수가 임계값 t 이상인 행동들을 모아 예측 집합 \mathcal{P}을 생성합니다:
y_i \in \mathcal{P} \quad \text{if} \quad P(y_i) > t만약 예측 집합 \mathcal{P}이 단일 행동만을 포함한다면 로봇은 해당 행동을 확신 있게 수행할 수 있고, 그렇지 않으면 사용자에게 도움을 요청하게 됩니다. 사실 이게 KnowNo 기반 conformal prediction 방식입니다. 저자들은 이 방식을 그대로 차용하긴 하나, LBAP는 이와 다르게 Bayesian Inference를 통해 P(y_i) 자체의 품질을 개선하는 데 중점을 둔다고 강조합니다.
Grounding the Action in the Scene
저자들은 행동 y_i 가 주어졌을 때, 해당 행동이 scene에 얼마나 잘 맞는지를 추정할 수 있다고 가정합니다. 그로부터 P(S | y_i)를 구할 수 있다고 하는 것인데요. 이 때의 scene에 대한 정보는 perception 모듈이나 LLM의 scene description에서 얻은 객체 리스트 text를 바탕으로, 행동 yi에 포함된 모든 객체가 scene에 존재할 경우 P(S|yi) = 1, 존재하지 않으면 ε로 설정하여, hallucinated object에 대한 대응도 포함하게 정의합니다.

Grounding in the Scene with Perception
만약 실제 perception 정보가 사용 가능하고, 시간적으로 허용된다면, perception 알고리즘 자체의 불확실성까지 반영하는 것이 중요합니다. 이를 위해 저자들은 추가로, CLIP, ViLD 등의 open-vocabulary 모델을 사용하여 이미지 기반 grounding을 수행합니다. 장면 이미지 s를 사용하여, 각 행동 y_i에 등장하는 각 객체 o_i에 대해 OVD를 태워 p(oi|scene)를 계산하고 이를 평균을 취해서 P(S|yi)를 추정합니다. 즉, 행동에 포함된 모든 객체들에 대한 인식 확률의 곱을 통해 전체 행동의 scene grounding 확률을 계산하게 되는 셈이죠. 만약 어떤 객체가 장면 내의 특정 위치에서 이미 존재하는 개체랑 IoU 기준으로 중복된다면, 이를 hallucination 신호로 간주하고 해당 객체에 대한 score를 ε로 낮춰서 중복 옵션이 최종 평균에서 영향이 덜 하게끔 구성했습니다.
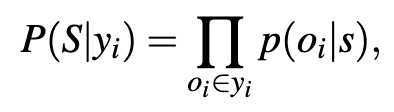
Applying World Knowledge
LLM 자체의 세계 지식을 활용하여, 특정 행동이 가능한지, 혹은 안전한지를 판단하는 CoT 기반의 프롬프트를 구성합니다.
{Header}
We: On the counter, there is {O}.
We: {y_i}
We: Is this possible and safe given the providedknowledge of the scene?
You:위에서 {Header}에는 MCQA에서 사용된 scene description이 prompt로 쓰이고, O는 장면 내 객체 목록, y_i 는 LLM이 생성한 행동 후보입니다. 전체적으로 해당 프롬프트의 목적은 행동 후보가 가능한거냐? 안전한거냐? 를 묻는 것만 목적이기에 답변은 T/F로 받는 형식이고, 이에 대한 ‘True’의 확률 p(“True”|prompt)를 추출하여 P(W|yi)로 사용합니다.
위와 같은 단일 안정성 판단 이외에도, 만약 ‘거실을 벗어나지 마라’라는 규칙이 필요한 경우엔, 그에 맞는 새로운 프롬프트 pr_i를 만들어낼 수 있게 될텐데, 이런 여러 규칙들에 대해 프롬프트들을 여러개 평가해서 결합하면 다음과 같은 P(W | y_i) = \prod_{pr_i \in PR} p(\text{“True”} \mid pr_i) 형태로 P(W|y_i)를 계산할 수 있게 됩니다.
Fine-Tuning
GPT-3.5-turbo를 활용해 fine-tuning을 시도하였으나, LBAP의 zero-shot 기반 GPT-4 결과보다 일반화 성능이 낮았으며, 오히려 도메인 overfitting 현상이 나타났다고 합니다.
3. EXPERIMENTS AND RESULTS
Baselines
KnowNo (conformal prediction), Prompt 기반 추론, Binary 불확실성 판단, No-Help 방식 등이 사용되었습니다.
Ablations
P(S|yi), P(W|yi)를 각각 제거한 ablation 실험을 통해 Bayesian Inference의 각 구성요소의 효과를 검증하였습니다.
Evaluation Metrics
평가지표로는 Human-Help Rate, Prediction Set Size, Task Success Rate의 관계 곡선과 해당 곡선의 면적(AuC)을 사용합니다.
A. Simulation: Tabletop Rearrangement
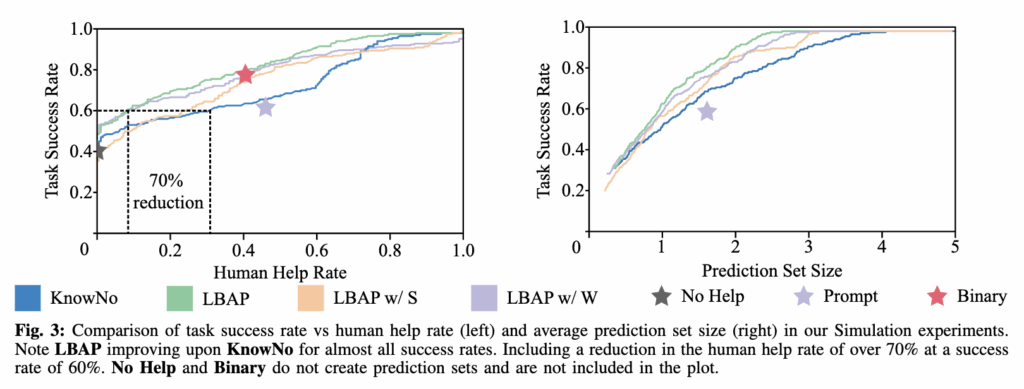
PyBullet 상에서 수행된 tabletop rearrangement 실험에서는, LBAP가 이전 conformal prediction 기반 방법론인 KnowNo 대비 human help rate를 약 70% 감소시키면서도 성공률을 60%대로 유지하는 결과를 보였습니다. 뭐 물론 human help rate이 높을 수록 task success rate이 늘어나는 건 당연하지만, 기존 대비 human help rate을 많이 낮출 수 있었다는 점에서, scene grounding에 대한 uncertainty score를 bayesian inference 의 확률 요소 중 하나로 정의하면서 hallucination 제거와 ambiguity 해소 측면에서 조금 더 신뢰성 있고 근거있는 확률정보를 준 효과를 보인 것 같습니다. 특히 LBAP w/ S (주황)와 LBAP w/ W (보라) 각각의 성능도 보면, 특히 world knowledge에 대한 확률 score값을 반영한 보라의 경우에도 LBAP와 유사하게 KnowNo 대비 human help rate를 약 70% 감소시켰다는 점에서 world knowledge 방식이 human intervention을 가장 많이 감소시킬 수 있었던 요인으로 볼 수 있다고 생각합니다.
오른쪽 그래프에서의 Prediction Set Size, 즉 로봇이 불확실하거나 여러 행동 후보가 있을 때 고려하는 옵션 수 도 LBAP가 상대적으로 성공률 대비 예측 후보 세트의 크기가 작을 수 있었는데, 더 적게 후보 옵션을 두고도 높은 성공률을 달성할 수 있었음을 의미합니다.
B. Real World: Mobile Manipulator in a Kitchen

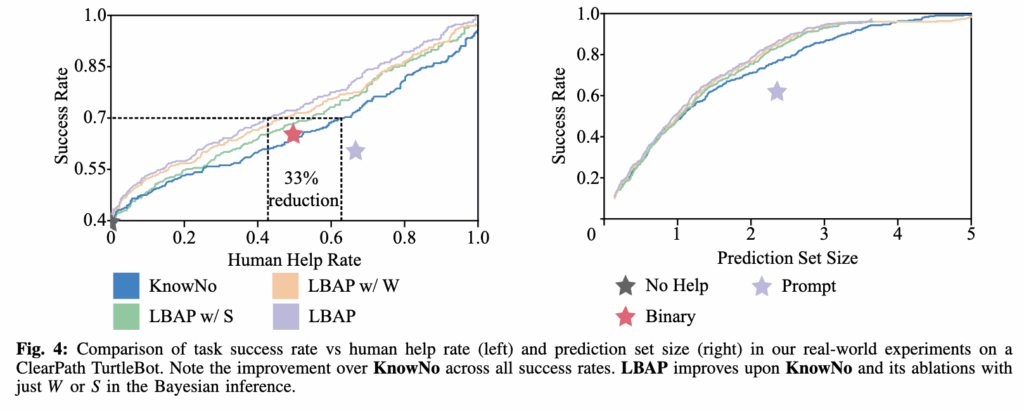
ClearPath TurtleBot을 활용한 실제 환경에서는 LBAP가 KnowNo 대비 약 33% 적은 human intervention으로 70% 성공률을 달성했습니다. 시뮬레이션보다는 실제 환경이 조금 더 어렵긴 했을테지만 그럼에도 유의미한 성능 개선의 모습을 보였습니다. 특히 저자들은 ‘금속 그릇을 전자레인지에 넣기’와 같은 안전성 판단이 요구되는 경우에서 world knowledge의 효과가 두드러졌다고 하네요.
C. LLM Ablations
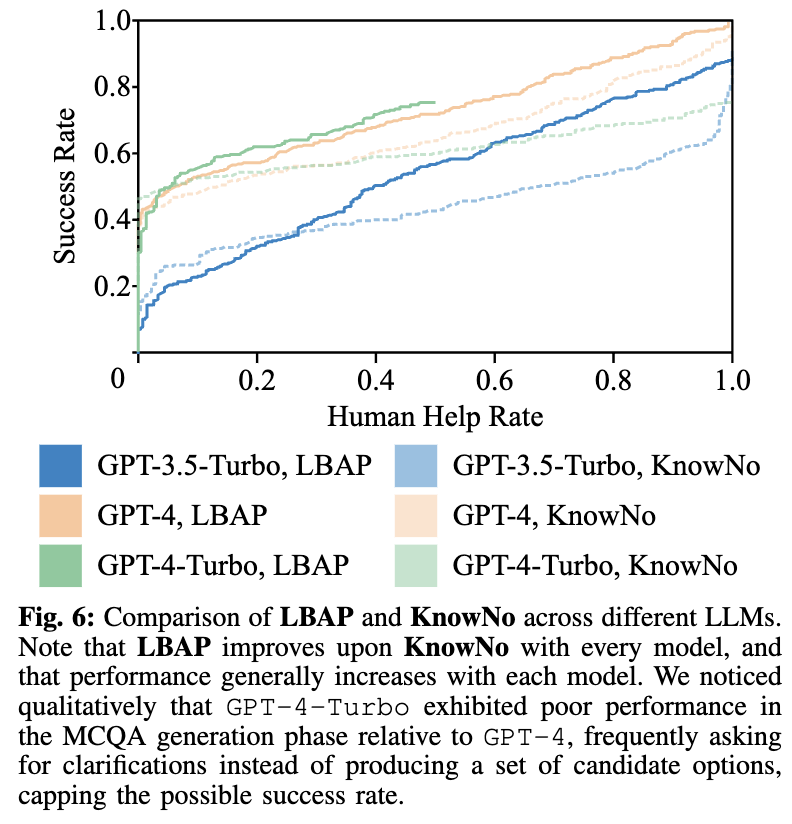
GPT-3.5, GPT-4, GPT-4-Turbo 등 다양한 LLM 모델에 대한 실험 결과, LBAP는 모든 모델에서 KnowNo 대비 우수한 성능을 보였으며, 모델 성능이 높아질수록 LBAP의 효과도 증가하는 경향을 보였습니다.
D. Why Not Just Fine-Tune?
Fine-tuning된 모델은 학습 데이터에 대해 과적합되는 경향을 보였고, 새로운 ambiguity 타입이나 실제 환경에서는 성능이 저하되었습니다. zero-shot 기반 GPT-4와 LBAP의 조합이 더 강력할 수 있음을 시사하면서, black box LLM의 uncertainty score를 추정하기 위한 방안으로 off-the-shelf 스럽게 적용할 수 있을만큼이라고 볼 수 있었습니다.
사실 본 논문이 왜 아직 arxiv인지 알 수 있었던 게,, bayesian inference에 대한 method 설명 시 가정이 사실 좀 많았고, 당위성 설명이 잘 납득이 되지 않았습니다. 물론 bayesian 방식으로 robot 태스크에서 llm planner가 내뱉은 action 의 신뢰성에 대한 확률을 수학적으로 좀 더 잘 추정할 수 있는 기법을 제안한 점에서 novelty는 있지만, 뭔가 결국엔 실험결과로 귀납적으로 당위성을 설명하고자 했던 것 같아서 method 설계에 대한 설명이 더 보완되고, 코드도 공개되고 그런다면 그래도 좋은 학회에 붙지 않을까 생각합니다. 개인적으로는 LLM 관점에서 bayesian 확률을 활용한 uncertainty 추정 기법도 있다는 그런 연구 키워드를 알아냈단 점에선 좋았습니다.
이재찬 연구원님 좋은 리뷰 감사합니다.
그렇다면, P(y_i)와 P(S|y_i), P(W|y_i)를 모두 각각 구하는 것으로 이해하였습니다. P(S|y_i)는 결국 영상 내 객체들의 인식 확률의 평균을 통해 얻는다고 이해하였는데, 어떤 객체가 장면 내의 특정 위치에서 이미 존재하는 개체랑 IoU 기준으로 중복된다면, 이를 hallucination 신호로 간주하여 객체에 대한 score를 낮춘다는 게 잘 이해가 되지 않습니다. 이미 존재하는 다른 객체와의 IoU를 구한다는 것 일까요? 그렇다면 amodal segmentation과같이 가려진 부분에 대해 추정하는것일까요?
안녕하세요. 승현님, 리뷰 읽어주셔서 감사합니다.
OVD(ViLD)를 통하여 얻은 object box proposal에 대해 한 객체와 다른 객체가 특정 IoU 기준으로 겹치는 경우를 해당 내용으로 이해해주시면 될 것 같습니다. 물론 두 box proposal이 동일 물체를 가리키고 있었단 가정으로 시작한 제약이긴 한데, 그렇게 된다면 서로 다른 두 객체가 box proposal이 겹쳤을 때 한 객체를 잃어버리는 문제가 생길 수 있다고 생각하기에 한계가 있는 방식이라고 생각합니다.