안녕하세요, 예순 여덟번째 X-Review입니다. 이번 논문은 2025년도 ICLR에 올라온 MMAD: A COMPREHENSIVE BENCHMARK FOR MULTIMODAL LARGE LANGUAGE MODELS IN INDUSTRIAL ANOMALY DETECTION 입니다. 바로 시작하도록 하겠습니다.
1. Introduction
본 논문은 industrial anomaly detection 문야에서 mllm 모델들의 성능을 평가하고자 MMAD라고 하는 새로운 벤치마크 데이터셋을 제안한 논문입니다. 기존 industrial anomaly detection(이하 IAD) task에서 주로 연구되던 모델들은 discriminative model이라고 볼 수 있는데요. 이런 모델들은 단시 학습한 그 detection task 작업만 가능하고, 그 제품에 대한 디테일한 설명은 하지 못했습니다. 또, 약간의 세팅이 바뀌는 경우에는 전체 모델을 다시 학습하거나 다시 개발해야 한다는 단점을 갖고 있었습니다. 하지만, 최근에는 MLLM이 발전되고 있고, 이를 IAD task에 적용해볼 수 있겠죠. 따라서 본 논문 저자들은 이런 질문을 던지게 됩니다. “How well re current MLLMs performing as industrial quality inspectors?” 직역하자면 현재 MLLM들이 산업 현장에서의 품질 검사 모델로 사용하기에 어느 정도의 성능을 보이냐는 것이죠.
최근에는 이런 MLLM들을 IAD task에 적용하고자 하는 연구가 있어 왔습니다. 다만, 이들은 기존 방식(discriminative model들이 사용하던)을 사용했기에 MLLM의 성능을 평가하는게 아니라 그 expert model의 성능을 보이는데 그쳤습니다. 즉, image level에서 이 영상이 anomaly인지 아닌지나, pixel level에서 이 pixel이 anomaly region인지 아닌지 평가하였고 mllm 자체에 대한 성능 측정은 없었다는 것이죠. 또 이들 모델들간의 output 형식이 다 다르고 평가 데이터셋도 다르기에 다른 일반적인 MLLM들과의 비교를 하기도 어려웠습니다.
따라서, 본 논문에서는 MLLM들의 IAD 성능을 정량적으로 비교할 수 있는 벤치마크가 필요하다고 판단하여 MMAD라고 하는 벤치마크를 제안합니다. 이를 위해서 구축한 데이터 생성 파이프라인을 간단하게 설명드리면, 먼저 GPT-4V를 사용해 기존 visual annotation과 language interaction을 통해 semantic한 annotation을 자동으로 생성하였습니다. 이렇게 생성한 semantic annoationa을 바탕으로 다양한 question과 그에 해당하는 선택지들을 자동으로 생성하고 이후 사람이 manually하게 검수해서 적절한 질문과 정확한 데이터를 확보할 수 있도록 하였습니다.
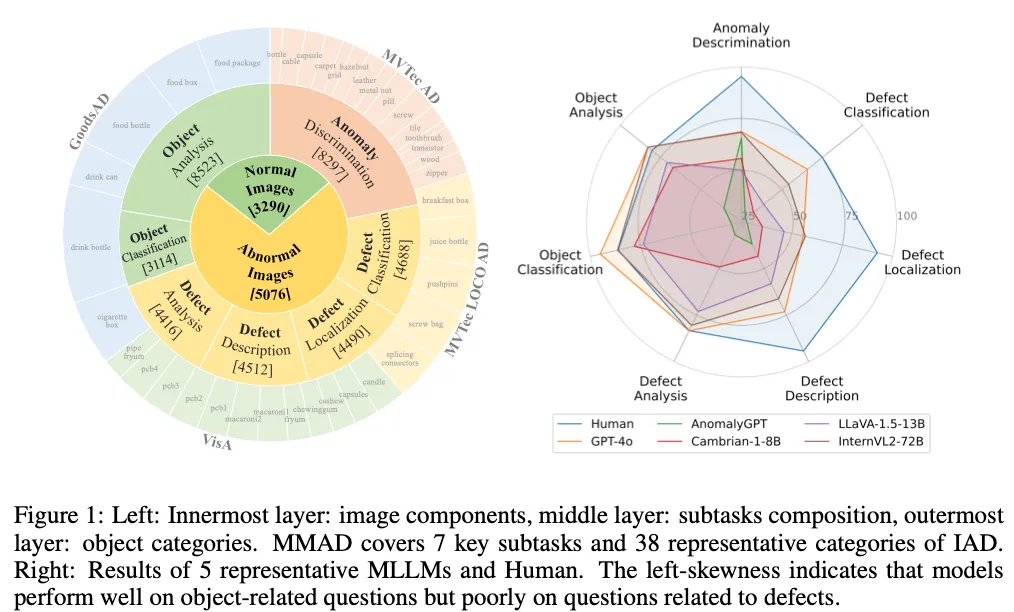
최종적으로 위 그림1의 왼쪽에서 보이는 것처럼 기존에 공개 되어 있던 데이터셋인 GoodsAD, MVTecAD, MVTecLOCOAd, VisA라고 하는 4개의 데이터셋을 기반으로 총 8,366개의 sample과 38개의 산업 제품 class를 수집하여 총 39,672개의 question을 생성하였습니다. 이 제안된 MMAD 데이터셋을 가지고 Fig1 오른쪽에 보이는 것처럼 현존하는 MLLM 모델들을 가지고 평가를 수행했는데, 산업 현장에서는 아주 높은 정확도가 요구됨에도 불구하고 현재의 MLLM들 성능이 아직 한참 기준에 못 미친다는 점을 확인할 수 있었습니다. (그림에서는 정량적인 성능이 안보이지만,, 실험 파트에 표가 있습니다..) 따라서 본 논문에서는 추가적으로 기존 MLLM들에 대해 추가 학습 없이 성능을 향상시킬 수 있는 두가지 기법까지 제안하고 있습니다. 이에 대해서는 method 단에서 자세히 살펴보도록 하겠습니다.
2. The MMAD Dataset
2.1. Data Collection
먼저 MMAD 데이터셋에 대해 자세하게 살펴보도록 하겠습니다. 산업 환경에 품질 검사를 위해 적용될 모델이라고 하면, 제품의 종류가 다르다고 하더라도 시각적인 검사에 필요한 skill이 유사하기에 다양한 제품의 검사 업무에 유연하게 적용할 수 있어야 한다고 합니다. 따라서 MMAD 벤치마크는 여러 IAD 시나리오를 포괄하도록 설계가 되었습니다. 구체적으로, 서로 다른 4개의 IAD 데이터셋에서 데이터를 수집하고 샘플링하여 총 38개의 제품 class와 이에 대한 244개의 결함 유형을 포함하도록 구성을 하였는데 디테일하게는 아래 table1을 참고하시면 됩니다.
2.2. Question Definition
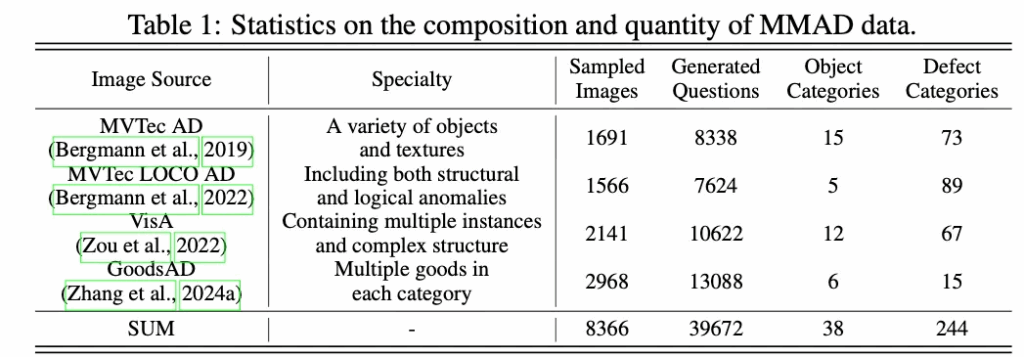
다음으로는, MMAD 벤치마크의 question 유형들을 살펴보도록 하겠습니다. 이 부분은 실제 산업 현장에서의 생산 라인에서 품질 검사를 할 때는 단순 결함 유무만 확인하는 것이 아니라, 결함의 종류도 분류하고, 그 정도를 판단해 원인을 분석하거나 그 결함에 대한 진단도 수행한다고 합니다. 이런 점을 고려하여 MMAD에서도 단순 이상 탐지 외에 아래 Fig2에 나와있듯이 총 7가지 subtask를 설계하였습니다.

보시면, 총 Anomaly Discrimination, Object Classification, Object Analysis, Defect Classification, Defect Localization, Defect Description, Defect Analysis이렇게 구성이 되어 있습니다. 하나씩 간략하게 살펴보면 Anomaly Discrimination같은 경우에는 단순 anomaly인지 아닌지 판단하는 binary classification 문제라고 보면 되구요.
오른쪽에 있는 노란색 박스들은 Defect에 관련된 것들로 결함이 어떤 결함인지 묻는다거나, 그 위치, 외형 묘사, 그에 대한 영향을 분석하는 것과 관련된 질문들입니다. 마지막으로 왼쪽 아래 초록색 박스들은 object에 관련된 질문들로, what kind of product is in the image? 처럼 이미지 속에 있는 object 가 뭔지부터, 이 object의 구성 요소나, 외형 기능에 대해 묻는 Analysis로 구성이 되어 있습니다.
이런식으로 question과 그 보기를 구성할 때 특정 위치의 보기에 답이 bias되지 않도록 선택지 순서를 랜덤으로 섞었으며, 모델이 정답의 번호 대신에 문장으로 output을 뱉을 경우에는 text matching을 통해 가장 가까운 선택지를 정답으로 간주하였습니다.
2.3. Data Generation
다음으로는 데이터 생성 과정에 대해 살펴보도록 하겠습니다.
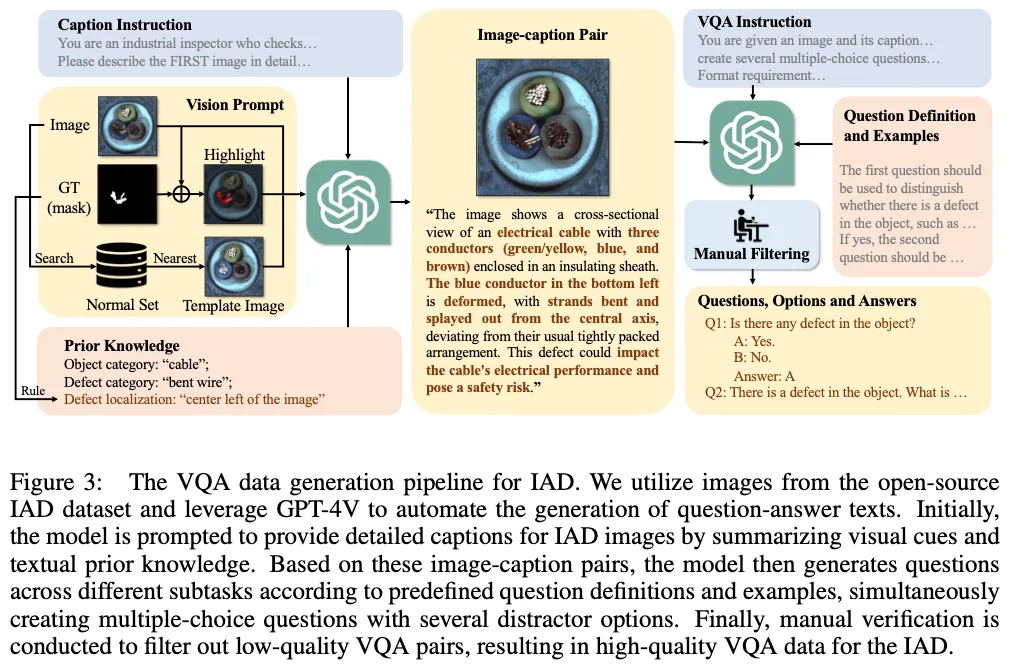
위 Fig3에 전반적인 과정이 도식화 되어 있는데요. 보시면 GPT-4V를 사용해서 text를 generation하도록 한다음 language prompt와 사람의 검수 과정을 통해 신뢰 가능한 question-answer 데이터를 생성하였습니다.
구체적으로 살펴보면, 먼저 각각의 영상에 대해 text description을 생성하게 됩니다. 이때 GPT-4V를 사용하게 되는데, GPT-4V가 주로 natural image를 사용해서 학습했다보니 industrial image에 좀 약할 수 있기 때문에 추가적으로 visual prompt와 text 기반의 prompt를 함께 입력으로 넣어줍니다. vision prompt라고 적힌 부분을 보시면 원본 영상에다가 gt mask 부분을 빨간색으로 표시해서 모델이 해당 영역이 확실하게 anomaly라고 인식할 수 있도록 유도를 하였구요. 또, 비교용 이미지로 사용하기 위해서 가장 유사한 normal set을 찾아 사용하게 됩니다. Language prompt에서는 (그림에서 좌하단 prior knowledge 부분) object의 이름이나 그 defect 이름, 그리고 이미지 내에서의 defect 위치 설명이 포함이 됩니다.
이렇게 vision prompt와 caption instruction, prior knowledge를 GPT-4V에 입력으로 넣어서 Caption이 생성된다면, 사전에 정의했던 7개의 subtask(2.2에서 언급했던 subtask들)에 따라 질문과 보기, 정답을 생성합니다. 이때 일반적인 natural image와는 다르게 각각의 IAD image에는 여러 질문이 동시에 생성된다고 하며, 이 샘플들은 모두 사람이 manually하게 filtering하는 작업을 거쳤다고 합니다.
2.4. Boost Methods
마지막으로 MLLM들이 IAD task에서 추가적인 학습 없이 성능을 개선하기 위해 본 논문에서 제안된 두 가지 기법을 설명드리도록 하겠습니다.
Retrieval-Augmented Generation (RAG).
먼저 IAD에 특화된 RAG 방식을 제안하였습니다.
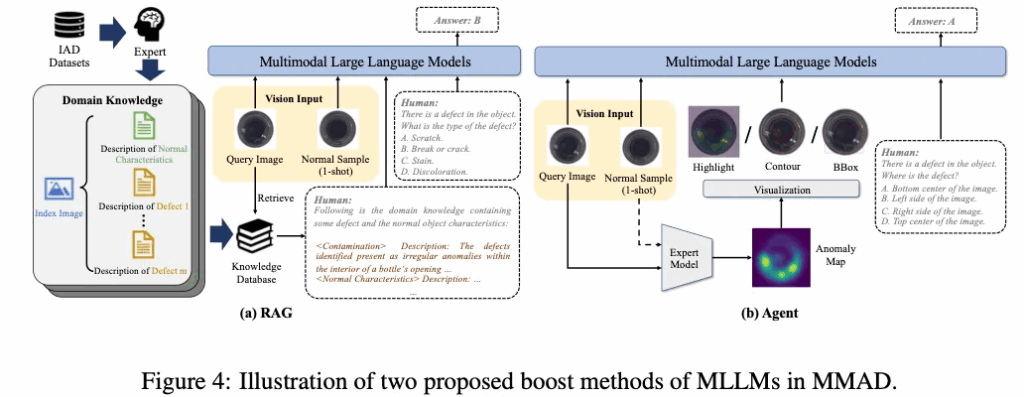
이 부분은 위 Fig4의 (a)부분에 나와 있는데, 보시면 먼저 expert들이 LLM을 통해 기존 IAD 데이터셋들을 정리하고 각 class 별로 normal sample의 특징과, 이 class 별 가능한 defect 들의 특성을 요약합니다. 이렇게 정리된 정보는 retrieval DB를 구성하게 되구, Test 시에 query image에 해당하는 category knowledge를 검색한 다음 이를 text prompt에 넣음으로써 MLLM이 보다 풍부한 정보를 바탕으로 답할 수 있게 하는 기법입니다. 사실 좀 나이브한데, 이걸 제안한게 메인 contribution은 아니라고 보심 됩니다..
Expert Agent.
다음으로는 expert agent인데요. 이는 Fig4(b)에 나와있습니다. 보시면, 여기서는 기존 IAD 모델을 visual expert로 간주를 했는데, 이 IAD 모델이 output으로 뱉는 anomaly map 자체는 MLLM이 직접적으로 이해하기 어렵기 때문에 이를 시각적으로 보인 다음에 input image로 넣는 부분입니다. 즉, anomaly map 자체는 anomaly가 있는 영역을 highlight하고 있으니, 이를 원본 이미지에 합쳐 highlight하거나, contour하거나 bbox로 표시해서 MLLM input으로 넣는다는 것이죠. 이에 대한 실험은 아래 실험단에서 살펴보도록 하겠습니다.
3. Experiments
실험에서 사용한 상용 모델은 API를 통해 평가했으며, 구체적인 버전은 Claude-3.5-sonnet, Gemini 1.5 flash/pro, GPT-4o, GPT-4o-mini입니다. 평가 subtask중에 anomaly discrimination 같은 경우 단순 normal인지 anomaly인지 판단하는 binary classification이라고 보면 되는데 이 샘플 비율이 불균형하기 때문에 각 class에 대해 별도로 정확도를 측정한 다음 평균을 내어 최종 성능으로 사용하였습니다.
3.1. Experimental Results
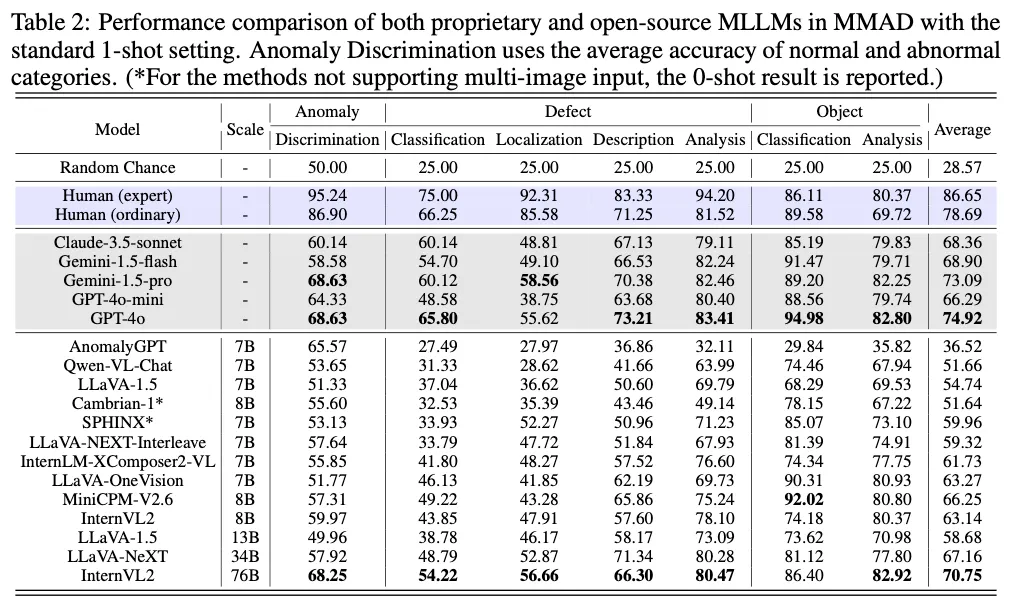
먼저 MMAD 벤치마크 table입니다. 위 표를 보시면, 회색 처리된 부분이 상용 모델이며, 아래쪽 흰색 모델들이 오픈소스 모델들입니다. 보시면 우선 모든 모델들이 맨 윗행에 있는 random baseline보다는 좋은 성능을 보이고 있습니다. 이 중 가장 높은 성능을 보인건 GPT-4o와 Gemini-1.5-pro가 되겠구요, 이와 비슷하거나 혹은 더 높은 성능을 보이는 오픈 소스 모델들도 몇 보입니다. 여기서 흰색 오픈소스 모델들 중에 맨 위에 있는 AnomalyGPT라고 하는 모델은 IAD task에 특화되어 개발된 유일한 모델이라고 보면 되는데 유독 전체적인 성능이 낮은 것을 확인할 수 있습니다. 이런 연유는 IAD task에 대해서 학습을 할 때 고정된 question-answer 형식으로만 학습했기에 overfitting이 일어났다고 해석해볼 수 있습니다. 다만, discrimination 성능에 대해서는 좋은 성능을 보이는데, 이는 이 MMAD에 대해 평가할 때 anomalygpt가 학습했던 그 형식에 맞춰 질문 format을 조정했기 때문이라고 합니다.
3.2. Further Analyses
Can MLLMs effectively utilize template normal image?
다음으로 추가적인 분석 실험을 한 부분입니다. 먼저, MLLM이 normal template을 제대로 활용할 수 있을까? 하는 실험인데요. 보통 Anomaly Detection task에서는 normal 패턴을 이해하기 위해 비교용으로 template image가 큰 도움이 되고는 합니다. anomaly sample과 normal sample을 비교하여 다른 부분을 찾는 식으로 도움이 되는 것이죠. 이런 점이 MLLM 모델들에게도 동일하게 적용될까?를 확인한 실험이라고 보심 됩니다.
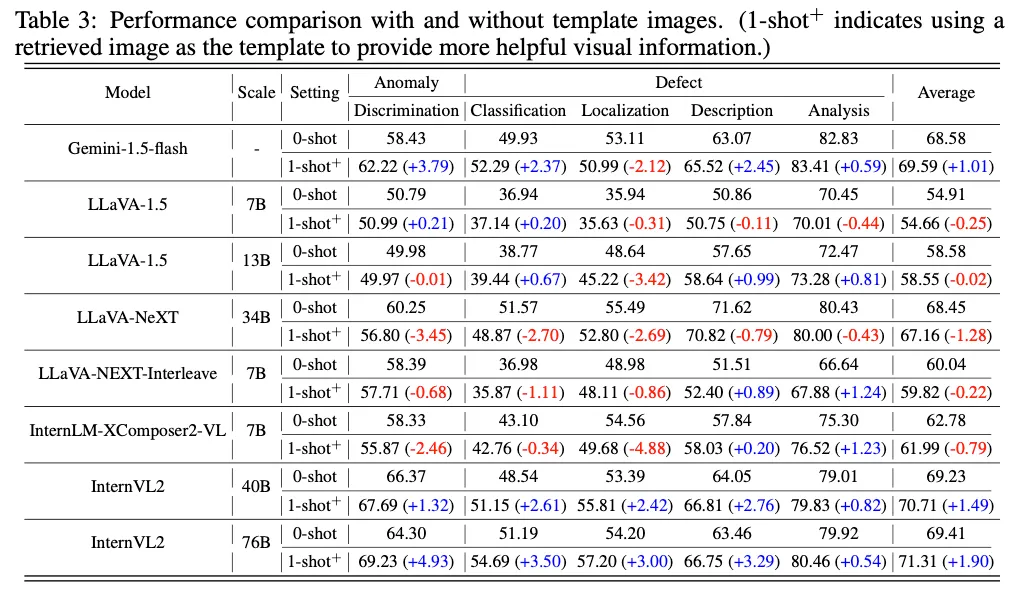
이를 확인하기 위해 표3에서 보이는 것과 같이 0-shot(템플릿 사용 X)과 1-shot+(test image와 가장 유사한 normal image하나를 검색해 template으로 사용) 세팅에서 실험을 수행하였습니다. 실험 결과 대부분 1-shot일 때 오히려 성능이 떨어지는 것을 보아 모델이 template 정보를 제대로 활용하지 못하는 것을 알 수 있습니다. 이 실험에서 상용 모델은 Gemini-1.5 모델 하나만 실험이 되었는데, 이 모델은 template을 사용했을 때 localization을 제외한 나머지 subtasks에서 모두 성능이 향상됨을 보이고 있으며 이를 보아 오픈 소스 모델들이 context 기반으로 이미지를 이해하는 능력이 더 낫다는 점을 시사한다고 볼 수 있겠죠.
How significant is the impact of model scale on performance?
다음으로는 모델 크기가 성능에 얼마나 영향을 주는지에 대한실험입니다.
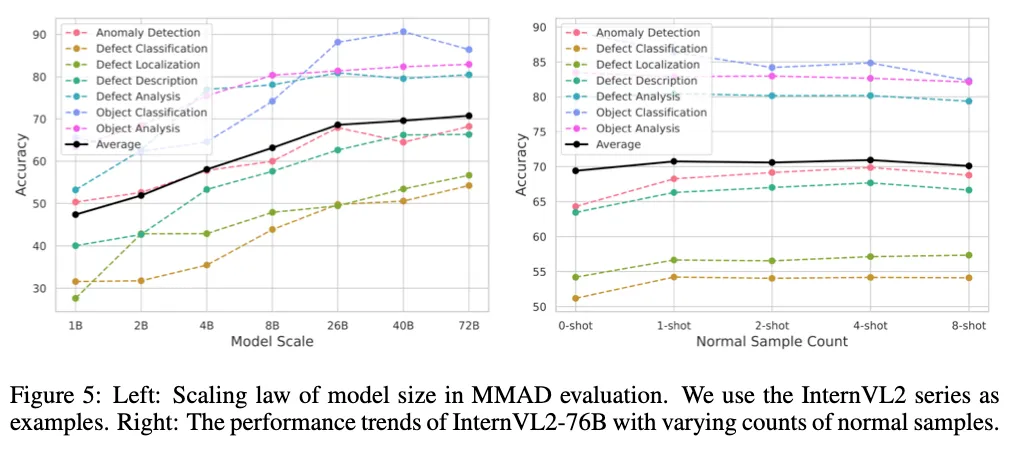
이는 위 그림 왼쪽 그래프에 결과가 나와있습니다. 보시면 모델 크기가 클수록 성능이 눈에 띄게 향상이 되며 가장 작은 모델과 가장 큰 모델 사이에는 20%가 넘는 정확도 차이가 나타난다고 합니다. 특히 차이가 나는 부분은 object classification 부분인 것 같습니다.
Can increasing the number of images further enhance performance?
또 Fig5 오늘쪽을 보시면 input image 수를 늘렸을 때(normal sample) 성능이 좋아지는 지에 대한 실험입니다. 보통 기존 few-shot 기반 IAD 모델들이 normal sample 수가 늘어날수록 성능이 크게 좋아지기에 MLLM 기반 모델들도 여러 장의 normal image를 효과적으로 활용할 수 있는지 여부를 확인하고자 한 실험입니다. 보시면, InternVL2-76B 모델로 실험을 수행했는데, 0shot에서 1shot으로는 성능 향상이 있었지만, 2, 4shot으로 갈수록 성능 개선을 거의 없다고 볼 수 있습니다. 또 오히려 8-shot으로 가면서는 일부 subtasks에서는 성능이 하락했는데, 이는 input image가 너무 많이 들어와서 오히려 정보가 과부하되면서 모델이 혼란을 겪은 결과라고 합니다.
3.3. Exploration
Input Domain Knowledge to MLLMs.
마지막으로 본 논문에서 제안된 MLLM 기반 모델들에 적용하여 성능을 개선할 수 있는 training free 기반 방식을 제안한 부분에 관한 실험입니다.

위 Table4에는 IAD task에 특화된 RAG 방식을 적용했을 때의 성능 차이를 확인할 수 있는데요. 보시면, RAG 방식으로 domain 지식을 추가했을 때 여러 모델이서 MMAD 성능이 크게 향상된 것을 확인할 수 있습니다. 특히 defect classification과 object classification 부분에서 성능 향상이 크게 향상이 되었는데, 이는 domain knowledge안에 그 카테고리에 대한 정보가 많이 포함되어 있기 때문이라고 볼 수 있습니다. 또, localization 성능도 3~4% 정도 향상된 걸로 봐서 text 기반 정보로 image에 대한 perception 능력이 향상시켰다고 볼 수 있겠죠.
Model Collaboration.
마지막으로 expert agent에 대한 실험입니다.
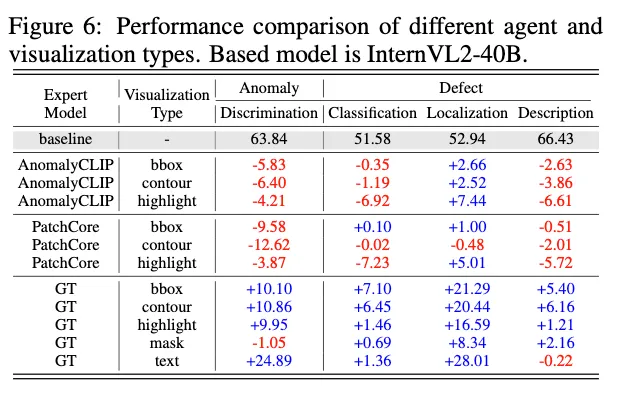
위 Table6에서는 AnomalyCLIP, PatchCore, GT를 expert로 사용함으로써 성능 향상폭을 확인하였습니다. 이때 visualization type도 bbox, contour, highlight 3가지로 두었습니다. 결과를 보시면 AnomalyCLIp과 PatchCore에서는 defect localization에 대한 성능 향상만 있을 뿐 다른 subtasks, discrimination이나 classification에서는 오히려 성능이 떨어지고 있습니다. 반면에 GT를 직접적으로 사용한 경우에는 모든 task에서 성능 향상을 보이며, 특히 localization과 관련된 부분에서 엄청난 성능 향상을 보이고 있습니다. 이를 보아 현재 expert model의 output을 MLLM이 사용하기에는 정확도가 부족하다고 할 수 있습니다. expert model output을 사용했을 때는 성능이 약간 오르거나 대부분 떨어진 반면에 gt를 사용한 경우에는 전반적으로 크게 성능향상이 되는 것을 보면 말이죠.
안녕하세요. 좋은 리뷰 감사합니다.
설명해 주실 부분을 보면 벤치마크 데이터셋만 제안한 것이 아니라 추가적인 기법도 제안한 것으로 보이는데요. 여기서 Expert Agent라고 하는 기법에서 hightlight라고 되어 있는 부분은 expert model의 output으로 나오는 map을 그대로 원본 이미지에 합친 것이라고 보면 되나요? 또 contour라고 되어 있는 부분은 어떻게 동작하는 것인지 궁금합니다.
감사합니다.
댓글 감사합니다.
넵 hightlight 부분은 expert model이 output으로 뱉은 anomaly map을 original image위에 덧씌운 것입니다. 시각적으로 좀 강조하여 MLLM 입력으로 넣는 것이라고 보면 됩니다.
또, contour의 경우에는 anomaly map에서 경계선만을 뽑아가지고 원본 이미지에 표시하는 방식입니다.