안녕하세요. 이번 논문은 Segmentation 태스크에서 Token Pruning을 수행한 연구로, MLLM은 아니지만 현재 제가 연구하고 있는 분야가 MLLM을 활용한 Segmentation에서의 Token Pruning이기에 “Token Pruning이 Segmentation에 적용될 때는 어떤 고려가 필요할까?”하는 생각에 읽어보게 되었습니다.
Introduction
ViT에서도 Token Pruning에 관련한 연구는 예전부터 이어져오고 있었습니다. 비단 MLLM 이후가 아닌 CNN에서 ViT로 흐름이 넘어가면서도 연구자들은 성능만이 아닌 Efficient AI에 관해 고민해오고 있었습니다. 이전 연구인 DynamicViT는 보조 신경망을 두어 유지할 (Pruning하지 않을) 토큰을 예측해오고, EViT는 [CLS] 토큰과의 Attention score로 비교적 Attention이 낮은 토큰을 Pruning하는 방법을 채택하였습니다. EViT의 MLLM 버전이 FasterVLM으로, 제목부터 “[CLS] Attention is All You Need for Training-Free Visual Token Pruning: Make VLM Inference Faster”인 것을 보면 과거부터 [CLS] 토큰이 중요한 역할을 수행해왔다고 할 수 있습니다. 하지만 저자는 Segmentation 태스크는 Dense Prediction, 픽셀 별 예측이 필요하므로 Attention score가 낮다고해서 객체인 영역의 토큰을 지우게 되는 것은 이전의 방법을 직접적으로 적용할 수 없다고 주장합니다. 또한 23년도 이전까지는 Token Pruning이 Segmentation 태스크에서 적용된 사례는 단 한 연구로, 해당 연구에서는 클러스터링된 토큰을 재구성하는 방식을 활용하였습니다. 이에 저자는 사람이 영역을 분할 시 Coarse-to-Fine 하는 과정을 모방하여 (사견으로 저는 이와 같이 딥러닝이 사람을 따라하고 싶은 궁극적인 목표 아래 사람의 시신경이나, 그 외 사람의 행동 방식 등을 모방하는 동기를 가진 연구를 좋아하지만, 본 연구에서는 그에 대한 타 논문의 레퍼런스가 포함되지 않고 그 방식이 자세히 서술되진 않아, 즉 정말 사람이 그러는지에 대해서는 다소 의문이 들기도 합니다) ViT의 각 단계(레이어)에서 토큰의 난이도를 점진적으로 평가하고, 이를 기준으로 Pruning을 수행합니다. 조금 더 자세히는 방법론에서 살펴보겠지만, 쉽게 예측 가능한 토큰(Coarse)은 초기 레이어에서 예측을 수행한 후 다음 연산부터 제외되고, 어려운 토큰(Fine)들이 다음 레이어를 통과합니다.

Fig 1은 이 과정을 보여줍니다. Stage #1에서는 비교적 예측이 쉬운 토큰들에 대해 예측을 수행한 후 (검은색 영역은 예측이 어려운 토큰을 의미함), 경계 영역, 작은 객체와 같은 비교적 어려운 토큰들은 깊은 레이어 (Stage #2-#3)에서 수행됩니다. 여기서 하나의 힌트를 얻어가네요. 객체의 경계부는 중심부에 비해 Segmentation 시 더 어려운 토큰에 해당한다.
Method
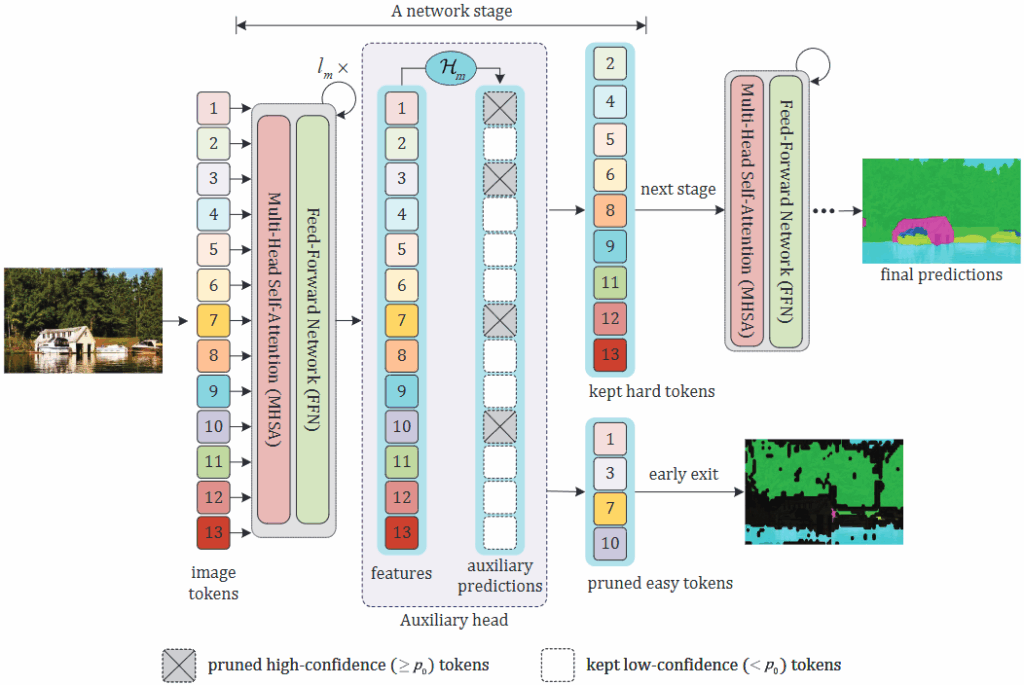
앞서 언급한 단계는 조기 종료(Early exit)라고 불리는 단계로, 쉬운 토큰은 이른 단계에서 예측을 수행한 후 이후 레이어를 통과시키게 하지 않습니다. 물론, 이 예측하는 토큰들이 더 많은 레이어를 통과하면 더 정확한 예측을 수행하겠지만, 지금의 목적은 Efficient이기에 이들을 적절히 제거시킴이 더 중요합니다. 위 Fig 2는 ViT 백본을 M 단계로 분할하며, 각 단계의 마지막 레이어에서는 보조 블록 \mathcal{H}_{m} 을 활용해 토큰의 난이도를 평가합니다. 이 난이도라 함은 본래 토큰 별 예측 결과에 대한 확률값입니다. 이, 해당 토큰 예측 결과 P_m 에 대해 사전에 정의한 Threshold인 0.95와 비교하여 이상의 값을 가지는 것은 쉬운 토큰으로 간주되어 이후의 연산에서 제거되며, 그 외는 어려운 토큰으로 다음 레이어로 계산이 이어집니다. 여기서 저자는 다음의 직관을 주장합니다. “Since a token is a natural representation of an image patch, we can finalize the prediction for easy tokens in adadvance without the need for complete forward computing by mimicking the segmentation process of humans” 번역하자면, image tokens는 image에 대한 자연스러운 표현이므로, easy token을 구별해내는 것은 계산 없이도 사람의 segmentation 과정을 모방하여 사전에 처리할 수 있다고 합니다. 그리고 이 과정을 위에서 말한 조기 종료(Early exit)라고 부릅니다. 그리고 앞서 말한 보조 블록 \mathcal{H}_{m} 은 ViT에 이미 내재한 각 스테이지 마지막의 블록입니다 (새로 학습하는 블록이 아님에 유의). 이 블록은 원래 ViT 기반 segmentation에서는 CNN보다 gradient의 흐름이 느리고 어렵기 때문에 세밀한 정보를 초기 레이어에서 유지시킴이 필요합니다. 따라서 중간 레이어의 출력으로도부터 segmentation prediction을 하여 보조적인 loss를 학습시킵니다. 이는 훈련을 안정화하고 성능향상에 기여하는 역할을 합니다 (단, loss용이므로 inference 시에는 버립니다). 즉, 다시 말해 이는 원래의 ViT 기반 segmentation에 존재하였던 것입니다. SegFormer, SegViT와 같은 방식들이 모두 이러한 auxiliary head를 가지고 있습니다. 그렇기에 m번째 레이어의 출력 Z_{l_m} 으로부터 \mathcal{H}_{m} 을 통과시킨 prediction을 P_m 이라 하며, 이에 대해 특정 토큰이 예측에 대한 confidence score가 높을 시에는 (그 토큰이 어떤 영역에 대해 segmentation 했는지는 당장은 상관없이), 그 토큰은 easy token이기에 다음 레이어에서부터는 제거합니다. 이 때의 Threshold를 0.95로 엄격하게 정의한다는 의미죠 (실험적으로 설정함).
본 프레임워크, DToP에서 각 토큰의 난이도를 평가하기 위한 보조 블록은 다음 두 가지 조건을 만족해야 합니다. 1. 토큰 난이도를 잘 예측할 수 있어야 한다 (쉬운/어려운 토큰을 잘 구분해낼 수 있어야 한다) 2. 그 보조 블록이 무거워선 안된다 (각 레이어마다 포함되기 때문에, 경량 구조여야한다). 이 둘을 위해 저자는 이전 연구 (SegViT)의 Attention-to-Mask (ATM) 모듈을 활용합니다. 해당 모듈은 학습 가능한 클래스 토큰들이 인코더 특징과 트랜스포머 디코더를 통해 정보를 교환(attention)합니다. 출력된 클래스 토큰들은 각 클래스 확률을 예측하는 데 사용되며, 그 클래스 토큰에 대한 어텐션 점수를 활용해 마스크 그룹을 형성하고, 클래스 확률과 마스크 그룹 간의 내적을 통해 픽셀에 대한 예측을 생성합니다. 이 방법을 통해 토큰들은 학습하는 클래스 토큰들로부터 정보를 교환하여 더욱 정확한 예측을 하는 데에 도움이 됩니다 (1번 조건). 저자들은 이 모듈을 활용 시 계산량 절감을 위해 (2번 조건) ATM 모듈의 층 수를 줄였습니다. 추가로, 저자는 ATM 모듈들을 분리된 보조의 Segmentation head로 사용하여 각각 독립적인 클래스 토큰을 가지도록 수정하였습니다. ATM 모듈들을 분리된 보조의 Segmentation head로 사용하였다는 말은 원래의 ATM은 multi-stage로 각 stage마다 연결된 cascade 형식입니다. 여기서는 이 연결을 끊고 (decouple), 각 레이어의 보조 블록 \mathcal{H}_{m} 마다 개별적인 learnable class token을 가지도록 하였습니다. 이렇게 하면 물론 learnable class token 수만큼 효율성은 (아주아주아주/매우매우매우)조금 떨어지겠죠 (2번 조건에 반할 수 있음), 하지만 이렇게 해야만 각 레이어마다 예측을 할 수 있기 때문에 이와 같이 설계하였습니다. 결국 하나의 토큰을 Pruning 하는 것이 그 class token 늘어난 것을 효율성면에서 상쇄시키고도 훨씬 남습니다.
또한 일부 클래스들, 예를 들면 하늘과 같은 클래스들은 모든 토큰이 매우 쉽게 인식되는 경우 (흔히 0.95 이상의 확신도를 가짐)가 있어, 초기 단계에서 해당 범주 전체의 토큰이 제거되어버릴 수 있습니다. 이는 쉬운 클래스들은 대부분이 초기 단계에서만 예측이 수행되어, 물론 최종적으로 연산량을 줄어들지만 그에 비해 정확도가 크게 무너질 수 있습니다. 또한, ViT의 특성 상 그러한 쉬운 클래스들과 관련된 문맥 정보 (contextual information)이 다른 토큰에 전달되지 않는 문제가 발생합니다. 즉, 모델은 하늘이 있는 것을 알지만 다른 객체 (하늘<->건물 / 하늘<->나무 등)와의 관계 정보는 누락됩니다. 이를 해결하고자 저자는 각 레이어의 Pruning 단계에서 각 클래스마다 신뢰도가 높은 상위 K개의 토큰은 단순히 강제로 유지합니다. 이는 저자의 의도 중 하나인 “각 클래스 별 경계부의 어려운 토큰은 다음 레이어로 넘기면서, 쉬운 토큰들은 빨리 처리하는데, 그와 동시에 여전히 성능은 최대한 유지시키고자 쉽다고 선택된 것들을 모두 다 처리해버리면 문제가 되니, 이들을 방지하여 성능을 보존한다”는 목적을 최대한 유지시킵니다.
Experiments
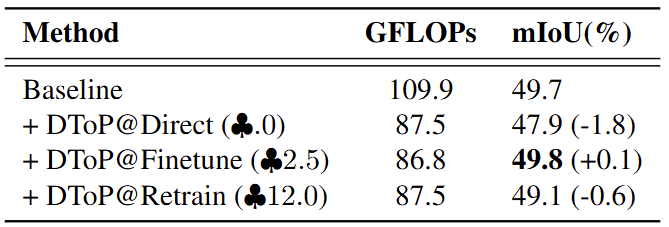
본 방법론은 총 세 가지의 데이터셋 (ADE-20K, COCO-Stuff-10K, Pascal-Context)에서 평가되었습니다. 위 Tab. 1은 ViT에서 제안하는 방법 (DToP)에 대해 학습 여부에 따른 성능 차이를 보입니다. @Direct, @Finetune, @Retrain에 대해선 각각 Training-free, fine-tuning, all-training입니다. 저 세잎클로버는 추가적으로 필요한 학습 시간을 의미합니다. 결과적으로는 전체를 Retraining하는 것 보다, Segmentation head만 fine-tuning하였을 시, GFLOPs도 낮아질 뿐더러 (Fine-tuning하였을 때 더욱 효과적으로 Token Reduction을 수행한다는 의미로 해석 가능함) 성능은 Baseline에 비해 오히려 높아지는 모습을 보입니다.
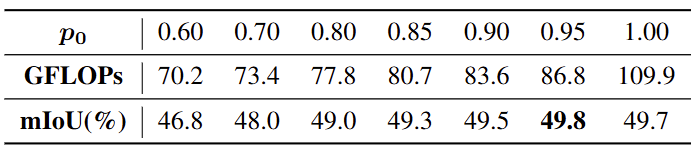
Tab. 2의 실험은 사소하지만, Token Reduction의 기준이 되는 confidence score에 대한 threshold를 몇으로 정하는지에 대한 실험입니다. 앞서 말한 바와 같이 “매우 확실한” 토큰들만 추려내어 다음 레이어를 통과시키지 않도록 합니다. 0.95란 값은 실험적으로 결정되었네요.
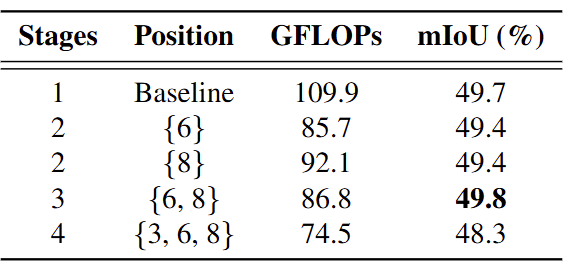
Tab. 3은 어느 위치의 레이어에서 Pruning을 진행할지에 대한 ablation study입니다. 초기 레이어에서 Pruning을 진행할 수록 (3>6>9) 당연히 그 이후 모든 레이어에 영향을 주니 GFLOPs는 확연히 줄어듭니다. 그런데 재밌게도, 왜 {6}과 {8} 단일에서 진행한 것 보다 {6,8} 두 부분에서 진행하였을 때 성능이 오히려 0.4%가 올랐는지입니다. 일반적으로 Token Pruning은 (GFLOPs로 증명되는) 더 많은 부분에서 진행되면 그만큼 성능이 더 줄어들어야할텐데요. 이에 대한 설명이 없어 아쉽고, 이에 대해 제가 예측하기 어려운 것은 {6}과 {8} 단일 레이어에서 진행한 것과 {6,8}에서 진행하였을 때의 살아남은 토큰들이 얼만큼 되는지에 대해서도 나와있지 않기 때문입니다. GFLOPs를 통해 예측하기도 어렵고, 모든 동일 세팅이라면 분명 {6}에서 진행한 것은 적어도 {6,8}에서 진행한 것에 비해서는 높은 성능을 보여야합니다. 토큰의 노이즈와 같은 말을 언급할 수는 있지만, 그렇다면 일반적으로 Token Pruning에서는 상충 관계에 대해서 언급해선 안됩니다. 토큰의 노이즈라면 정말 노이즈 토큰들을 지우면 오히려 지금처럼 성능이 오르는 모습만 보여야합니다. 또한 {6} 단일에서 진행했을 때나 {8}에서 진행했을 때 성능도 올라야겠죠. Token Pruning이 논문들을 보면 특수한 상황에서 분명 Pruning을 진행했을 때도 성능이 높아지는 경우는 있습니다. 하지만 저자들은 그에 대해 분석하고 있지는 않습니다. 일반적으로는 특정 토큰들의 노이즈에 대해 추측해볼 순 있지만, 그것은 Token Pruning의 기본 원칙과는 거리가 멉니다. 하여튼, 이것에 대해서도 분석이 없어 아쉽습니다.
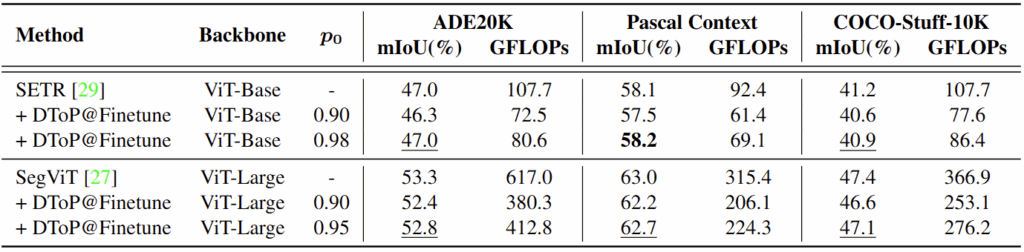
위 Ablation study로부터 하이퍼파라미터 등을 설정한 이후 SETR, SegViT와 같은 다른 ViT Segmentation 모델들에 대해 실험하였을 때도 GFLOPs가 그래도 꽤 유의미하게 줄어드는 모습을 볼 수 있습니다. 성능도 1% 내외로는 항상 보존되어 그래도 성능면에서는 분명 유의미합니다.
안녕하세요. 리뷰 보고 질문 있어서 남깁니다.
SegFormer, SegViT의 경우 기존 CNN보다 gradient 수렴이 느리기 때문에 Encoder의 최종 feature뿐만 아니라 ViT의 각 stage 별 마지막 output도 같이 segmentation을 예측해서 loss를 계산한다고 이해를 했는데 맞나요?
그렇다면 해당 모델은 Segmentation task이니 개별 stage에서 나온 encoder feature도 decoder를 태워서 원본 해상도로 upsampling된 다음에 segmentation 예측을 수행할 것으로 보이는데, 리뷰 내용에서는 Hm? auxiliary head?를 통해서 나온 토큰들 자체가 어떠한 segmentation을 수행하기 위해 카테고리에 대한 확률값을 가지고 있는 것처럼 보여서요. 얘네는 디코더를 타고 나오지 않고 곧바로 ViT의 패치 토큰들에서 대충 Fc layer 한두개 더 통과하여 segmentation 예측을 수행하는건가요?
그리고 결국 easy token은 이러한 각 토큰들이 (어떠한 클래스를 가지더라도 상관없이) confidence 스코어를 통해서 결정된다고 이해했는데 그렇다면 depth estimation이나 다른 vision task의 ViT model들에서는 해당 pruning 방식이 적용하기 어렵다고 이해하면 되나요?
캄사합니다.
안녕하세요. 리뷰 읽어주셔서 감사합니다.
1. Encoder의 최종 feature뿐만 아니라 ViT의 각 stage 별 마지막 output도 같이 segmentation을 예측해서 loss를 계산한다고 이해를 했는데 맞나요? (그 이후 질문에 대해서도)
A. 네 그렇습니다. 바로 다음의 질문에 대해서도 이어질텐데, 이 때 SegViT를 참고했을 때 FCN형태, FC 레이어를 1-2개 추가하여 예측한다고 합니다. 그렇다보니, 마지막 질문하신 것 처럼 다른 ViT model들에 대해서는 해당 방식을 적용하긴 어렵습니다. SegViT와 같이 이미 있는 구조에서, 이미 있는 모듈을 활용하는 Pruning 방식에 해당합니다