오랜만에 robot policy learning 논문을 가지고 왔습니다. 해당 기법은 3D Diffusion Policy와 유사하게 3차원 공간 정보를 활용하여 human demonstration에 대해 diffusion을 이용하여 모방하는 방법을 이용합니다. 두 기법은 유사하지만 3차원 정보를 취급하는 방버에서 둘 사이에 큰 차이가 존재합니다. 먼저, 3D Diffusion Policy는 point cloud를 1D vector로 그대로 활용하는 반면에 3D Diffuser Actor는 3D scene representation token으로 변화시켜 입력시키기 때문에, 장면 변화에 보다 강인하다는 장점을 가집니다. 방법론은 간단한 편이니, 마음 편히 보시면 될 것 같습니다.
Intro
본질적으로 로봇 조작 작업은 멀티 모달에 해당합니다. 작업을 수행하기 위한 경로에 해답은 한 경로만 가지는 것이 아니라 수 많은 경로를 가지게 됩니다. 그렇기 때문에 사람이 직접 데이터를 취득하는 경우에도 다양한 경로로 같은 작업을 표현하게 됩니다. 이런한 경향으로 인해 정책 학습을 distribution learning으로 해석하는 것이 올바른 방법이라고 볼 수 있습니다.
최근 연구에서는 demonstrations으로부터 로봇 조작 정책에 대한 action distribution에 대한 학습을 diffusion을 이용하는 트렌드를 보이고 있죠. 물론, VAE, mixture of Gaussian, energy-based objectives 등 분포를 표현하는 방식을 보이고 있지만, 해당 기법들은 중간 표현 (latent feature)에 대한 모델링이 요구된다는 단점이 존재합니다. 기존 기법들과 대비 latent feature에 대한 모델링이 매우 간단하고 명료한 (기존 데이터에 대한 noise로 표현이 가능한) diffusion을 이용한 방법들이 대세를 이루고 있습니다.
최근에는 RGBD를 이용해서 3D 정보 주입하는 연구들도 대세를 이루고 있습니다. 해당 기법들은 2D robot polices 대비 카메라 뷰포인트나, test time에서의 새로운 카메라 뷰포인트를 추가해도 일반화된 성능을 보여주고 있죠. 이는 어느 뷰포인트를 이용해도 공통된 3D space에서 시각 정보와 액션 정보를 학습하는 반면에 2D robot policy는 잠재적으로 2D를 3D를 맵핑시키는 것을 학습하고 있기 때문에 3D robot policy가 보다 개선되는 경향을 보여주는 것이라고 보입니다.
해당 연구에서는 효율적으로 spatial reasoning을 위한 3D scene representations과 action prediction에 multimodality를 다루기 위한 diffusion을 결합한 3D Diffuser Actor를 제안합니다. 해당 기법은 상단 비디오 같이 새로운 3D denoising policy transfomer로 토큰화된 3D scene representation, language instruction, noised end-effector’s future translation/rotation trajectory을 입력 받아, end-effector의 translation/rotation에 대한 error를 예측하는 구조를 가집니다.
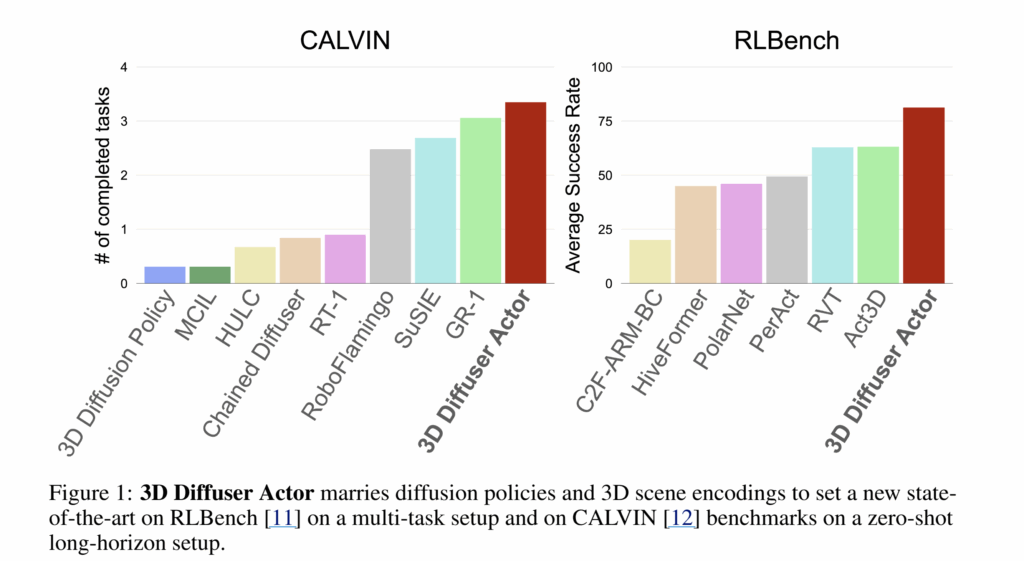
저자는 해당 모델를 평가하기 위해서 시뮬레이션 벤치마크인 RLBench와 CALVIN과 real world에서 평가를 진행했으며, fig1과 같이 모든 환경에서 가장 좋은 성능을 보입니다.
Method
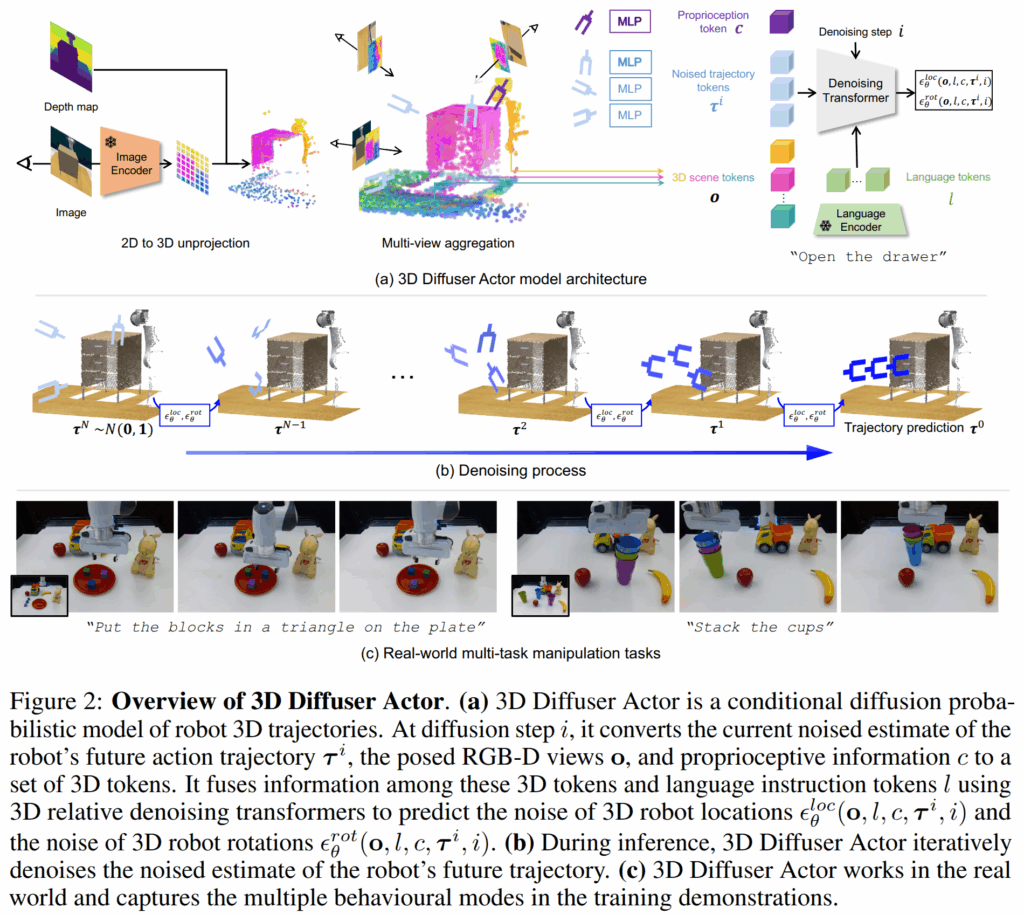
3D Diffuser Actor는 imitate demonstration trajectories {(o_1, a_1), (o_2, a_2),...} 를 달성해야하는 language instruction l을 모방하기 위해 학습합니다. 여기서 o_t 는 visual observation, a_t 는 robot action에 해당합니다. 각 observation o_t 는 하나 또는 그 이상의 posed RGB-D images에 해당하며, 각 a_t 는 end-effect pose로 이를 3D location, rotation, binary (open/close) state로 분해된 정보 a_t = {a^{loc}_t \in \mathbb{R}^3, a^{rot}_t \in \mathbb{R}^6, a^{open}_t \in {0, 1}} 로 구성됩니다. rotation은 6D rotation로 표현 됩니다. 추가로 저자는 notation \tau_t = (a_{loc_{t:t+T}}, a_{rot_{t:t+T}}) 를 trajectory of 3D locations and rotations at timestep t, of temporal horizon T 로 사용합니다. 최종적으로 해당 모데은 각 timesetp t 마다 trajectory \tau 와 binary state a^{open}_{t:t+T} 를 예측하게 됩니다.
전반적인 모델 구조는 fig 2에서 보이는 바와 같으며, 기본적으로 conditional diffusion probabilistic model을 활용하여 visual scene과 language instruction을 입력 받아 trajcetories를 출력 받는 방식이며, 전체 경로를 non autoregressvely 하지 않고 interative denoising하여 한번에 전달 받습니다.
+ 즉, 기존 diffusion 방식과 동일하게 \tau_i = \sqrt{\bar{\alpha}_i}\tau_0 + \sqrt{1 - \bar{\alpha}_i}\epsilon), where (\epsilon \sim N(0, 1) 를 이용한다고 보시면 됩니다.
3D Relative Denoising Transformer. 해당 모델은 3D relative transformer \hat{\epsilon} = \epsilon_{\theta}(\tau_i^t; i, o_t, l, c_t) [latex]에 대한 denoising process의 gradient를 학습합니다. 여기서 [latex] \tau_i^t 는 timestep t와 diffusion step i에 해당하며, conditioning 정보로 language instruction l과 visual observation o_t, proprioception c_t를 받아 noise component \hat{\epsilon} 를 구합니다. 저자는 visual observations o_t, proprioception c_t and noised
trajectory estimate \tau_t^i 를 set of 3D tokens로 샘플링합니다. 각 3D token은 latent embedding과 3D position을 의미하게 됩니다.
3D tokenization. trajectory는 MLP를 통해 임베딩이 되며, 각 영상은 pre-trained CLIP ResNet50을 이용하여 2D feature map F로 사영됩니다. 영상과 같이 주어진 depth map은 내외부 카메라 파라미터를 이용하여 (x, y, z)로 표현되며, 각 패치 내 평균 깊이 값을 이용하여 정규화를 수행합니다. 결과적으로 3D scene token은 H x W로 구성됩니다. proprioception c는 learnable representation이며, 현재의 end-effect pose를 3D positional embedding 가진 3D scene token에 해당합니다. 마지막으로 language task instruction은 pre-trained CLIP text encoder로 임베딩됩니다.
저자의 3D Relative Denoising Transformer은 모든 3D tokens 간의 relative self-attention을 적용하고, language tokens에는 cross-attentions을 적용합니다. 3D self-attentions을 수행하기 위해서 저자는 attention layers에서 상대적인 positional information을 encode하기 위한 rotatry positional embedding을 활용합니다. query q와 key k 사이의 attention weight는 다음과 같이 구성됩니다. e_{q,k} \propto x_q^T M(p_q - p_k) x_k , 여기서 x_q / x_k, p_q / p_k는 각각 feature와 3D position에 대한 query / key를 의미합니다. M은 matrix fuction으로 query와 key 사이의 relative positions을 담고 있습니다. 추후, 최종 trajectory tokens은 MLP에 전달되어 다음과 같이 location에 대한 noise \epsilon_{\theta}^{loc}(o, l, c, \tau^i, i) 와 rotation에 대한 noise \epsilon_{\theta}^{rot}(o, l, c, \tau^i, i) , 그리고 end-effect opening f_{\theta}^{open}(o, l, c, \tau^i, i) \in [0,1]^T 를 예측하게 됩니다.
Training and inference. 학습 동안에는 time step t와 diffusion step i가 랜덤하게 샘플링되고, ground-truth trajectory \tau_0^t 에 noise \epsilon = (\epsilon_{loc}, \epsilon_{rot}) 를 가해져 학습되어집니다. 3D location과 3D rotation은 L1 loss로 end-effect opening은 BCE loss를 이용하여 학습되어집니다. 이는 다음과 같이 정리됩니다.
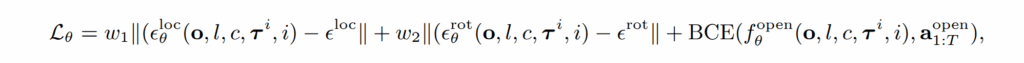
여기서 w_1, w_2는 하이퍼 파라미터로 cross-validation으로 추정했다고 합니다. noise에 대한 sampling은 location은 scaled-linear, roation은 square cosine scheduler를 이용했다고 합니다.
+ noise로부터 정보를 복원하는 방법은 noise schedulers 방식에 따라 다릅니다.
Implementation details. 각 trajectory는 동일한 length T에 따라 샘플되어 학습 및 추론되며, keypose를 예측하고 이어서 다음 keypose를 예측하는 방식을 이용합니다. 각 keypose에 대한 움직임은 sampling-based motion planner를 이용합니다.
Experiments
RLBench
Multi-view setup: 18 manipulation tasks, 2-60 variations (object poses, appearance, semantics), multi-view RGBD (front, wrist, left shoulder, right shoulder)

멀티 뷰에 대한 평가는 Tab 1에서 확인이 가능함. SOTA를 달성한 결과를 보여줌. 특히, long-horizon high-precision tasks에 속하는 stack blocks, stack cups, place cups에서 큰 격차를 보여주는 결과를 보여줌.
Single-view setup: 10 manipulation tasks, Only front RGBD

싱글 뷰의 결과는 tab 2에서 확인 가능함. SOTA 달성
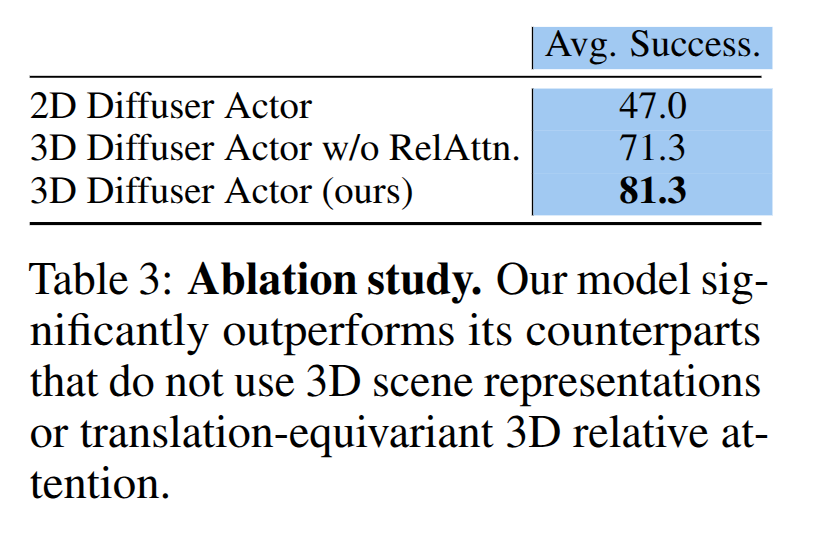
Ablation. Tab 3에서 3D scene token과 relative self attention의 중요성을 보여줌. 2D Diffuser Actor는 각 카메라 뷰 포인트에 대한 인지를 주기 위한 추가적인 learnable weight를 추가하여 학습함
CALVIN
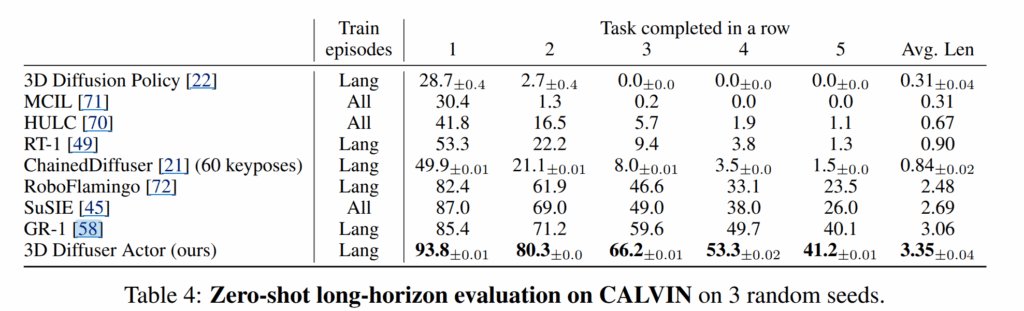
CALVIN은 PyBullet 시뮬레이터 위에서 panda robot으로 설계된 시뮬레이터로 34 tasks와 4 different environments로 구성됨.
(a sliding door, a drawer, a button that turns on/off an LED, a switch that controls a light bulb and three different colored blocks)
또한, CALVIN은 24h tele-operated unstructured play data + annotated language instructs가 제공됨.
해당 시뮬레이션은 zero-shot generalization setup으로 연속된 작업을 5개의 연속된 작업을 전달 받아 수행됨.
결과적으로 3D Diffusion Policy 조차 넘어서며, 이외 다른 기법들은 넘은 성능을 보여줌
Real-World
12 tasks에 대해서 평가를 진행함. 로봇은 Panda robot을 활용. 카메라는 front view의 Azure Kinect RGB-D를 이용함(1280x720 -> 256x256). motion planner로는 ROS의 MoveIt!에 내장된 BiRRT를 활용함.
(tasks: pick one of two ducks to put in the bowl, we insert the peg into one of two holes and we put one of three grapes in the bowl.)
각 task 마다, 15 demonstration을 취득함.

이에 대한 평가 결과는 success rate는 Tab 5와 같음
아직 3D 정보를 활용하는 방법에 대해서 초입부에 해당하는 것 같습니다. 추가적인 정보가 부여될 수록 성능은 향상이 되지만, 추론 속도에 영향을 받기 때문에 이를 고려 가능한 모델이 개발된다면 좋을 것 같네요.