안녕하세요 오늘 소개드릴 논문은 “Towards Automated Movie Trailer Generation” 입니다. 본 논문의 테스크는 Movie Trailer Generation(영화 예고편 생성) 입니다. 저희 연구실에서는 생소할 수도 있는 주제인데요, 단순히 비디오 요약으로 이해하기에는 어려움이 있는 예고편 생성을 해당 논문에서 어떻게 해결했는지 알아보겠습니다.
테스크 소개: “영화 예고편 생성”이 왜 중요한가요?
영화 예고편 생성은 긴 영상을 맥락과 흐름을 고려하여 매력적인 요약본을 생성하는 것 입니다. 이때, 스포일러등을 제외하며 매력적이며 맥락적으로 중요한 장면들을 선별해야하며, 장면 순서의 재배치를 통해 몰입도라는 추상적 요인을 고려해야합니다. 따라서 예고편 생성이란 영상에 대한 완벽한 이해를 기반으로 인공지능이 추상적인 테스크를 수행할 수 있는가?에 대한 해답이 되는 태스크 중 하나입니다.
이러한 예고편 생성 프로세스는 일반적으로 2단계로 됩니다. 첫번째 단계는 영상을 파악한 작업자가 shots을 선정하고 순서를 배치하는 것입니다. 다음으로 두번째 단계는 대사와 사운드를 포함한 세밀한 편집을 진행합니다. 본 논문은 첫번째 단계의 shot selection 작업을 간소화하는것이 목적입니다.
Related Works
예고편 생성은 인공지능의 능력을 증명할 지표가 된다는 점에서 뿐 만 아니라, 일반적으로 수행하는데 비용이 많이 필요한 과제이기 때문에 자동화를 위한 인공지능 도입 방안이 꾸준히 연구되어 왔습니다. 기존의 방법론의 경우 전체 영상을 입력으로, 각 프레임이 예고편에 포함 여부를 이진분류(classification)하는 방식으로 해결되었는데, 오디오와 비전 정보를 잘 융합 임베딩한 feature를 SVM(support vector machine)으로 이진 분류[31]하거나, 영상에 대한 descriptions, subtitles 를 포함한 메타데이터를 기반으로, 이와 유사한 의미를 갖는 shots을 찾는 방법으로 다뤘습니다.
반면 해당 논문은 추가적인 정보 없이 오디오 정보나 메타데이터 없이 movie sequence 만을 입력으로 요약을 생성한다는 점에 차별성이 있습니다. 가장 유사한 접근법으로, 기존 연구인 CCANet[38]이 있지만 해당 연구의 경우 하나의 장르(TMDD, 직접구)에만 성능이 검증되었는데, 제안 방법론의 경우는 MovieNet, MAD와 같은 더욱 다양한 장르를 포함한 데이터셋에 대해 성능이 검증되었습니다.
Problem Formulation: “automatic trailer generation (ATG)”
방법론의 소개에 앞서 사용될 기호와 이를 기반한 문제정의를 정리하겠습니다.
Problem: automatic trailer generation (ATG)
- M: a movie sequence
- M = {U_1, U_2, … U_n} (U_x: a movie shot, n: the number of trailer shots)
- T: its corresponding trailer sequence
- T = {V_1, V_2, … V_m} (V_x: a trailer shot, m: the number of trailer shots)
학습 데이터로 i번째 movie-trailer pair {M_i, T_i}를 입력으로 합니다. 한편, 추론시에는 movie sequences(M)만을 입력으로 받습니다. 해당 태스크의 목적은 입력으로 부터 생성된 trailer seqences T’가 GT인 T와 유사하도록 모델을 학습하는 것 입니다.
Architecture: 모델의 구조는 어떠한가?
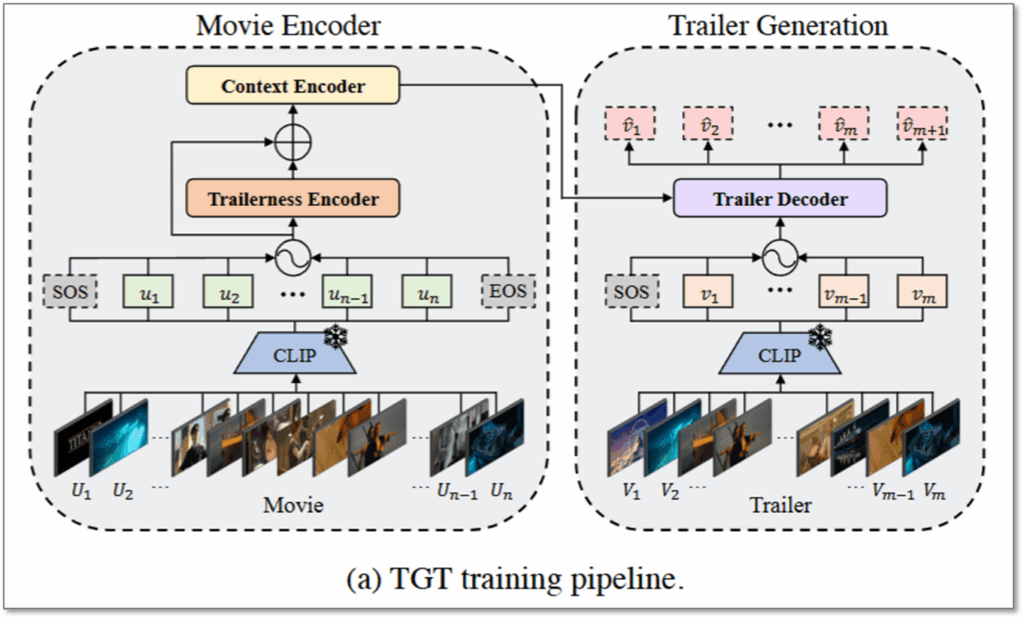
모델의 구조는 그림1과 같이 Movie Encoder와 Trailer Generation으로 나누어집니다. 더 자세하게 살펴보자면, Model Encoder에서 Trailerness와 Context가 충분히 고려되어 임베딩된 feature가 Trailer Decoder의 입력이 되며, 요약하면 예고편을 생성하는 sequence-tosequence 구조로 이해할 수 있습니다.
Movie encoder를 먼저 살펴보자면, 모델의 입력인 M의 경우 SOTA shot-boundary detector인 [35]를 통해 n개의 shots으로 분할하게 됩니다. 또한, 분할된 shot(U_i)들의 경우 pretrained CLIP을 통해 feature space로 임베딩(그림1, 녹색 u_i)됩니다. 이렇게 CLIP을 통해 임베딩된 영상의 sequence는 Trailerness Encoder와 Context Encoder로 맥락화 되는데요, 각 인코더에 대해 나누어 알아보겠습니다.
Trailerness Encoder: Trailerness Encoder의 경우 입력된 n개의 shot에 대해 trailer 일 가능성이 높은 정도를 score로 환산하여 예측(t)하도록 합니다. 구조의 경우 아래의 수식과 같이 self-attention layer인 A와 linear layer f, 점수 예측을 위한 Sigmoid layer s의 조합으로 구성되었습니다. (σi는 positional encoding)
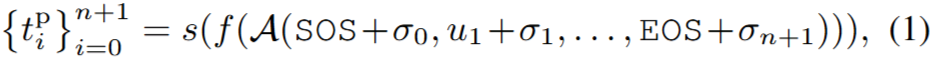
한편 trailerness socre의 경우 데이터셋에서 제공하지 않는데요, 전체 movie sequence(M)와 trailer(T)를 통해 trailerness socre를 정의하는 방법은 아래와 같습니다. 즉, trailer와 유사도를 측정했을때, 가장 유사도가 높은 trailer shot과의 유사도가 t^GT로 정의됩니다.
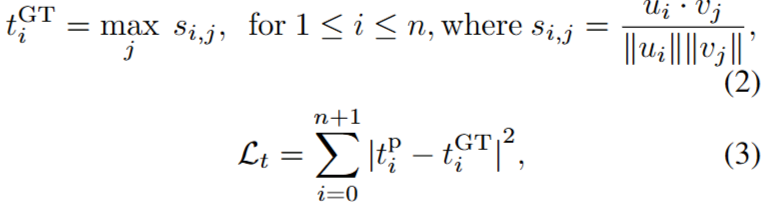
최종적으로 위와 같이 정의된 t^GT를 활용하여 Trailerness Encoder의 예측이 이와 같아지도록 학습(위 수식(3) 참조)하게 됩니다. 해당 Encoder로 trailerness를 score로 환산하여 movie sequence embedding에 주입하므로서 trailerness가 강한프레임이 강조되게 됩니다.
Context Encoder: 해당 encoder는 trailerness encoding(t_i)이 주입된 입력 sequence(u_i)를 기반으로 맥락 정보를 강화한 임베딩을 생성하기 위한 것입니다. multi-head self-attention 구조로 설계되었으며, positional embeding을 더한 입력에 대해 C라는 movie sequence(M) 전체에 대한 임베딩을 출력(아래 수식(4) 참조)하게 됩니다.

앞서서 M에 대한 전체 임베딩 C를 생성화는 과정을 설명하며 Movie Encoder의 구조를 알아보았습니다. 이어서 C를 통해 Trailer를 생성하는 과정을 통해 Trailer Decoder에 대해 알아보겠습니다. 일반적인 encoder-decoder구조와 마찬가지로 임베딩된 값(C)과 right-shifted 된 target sequence(trailer sequence, v_1~(j-1))를 입력으로 현재 시간(j) trailer shots에 대한 임베딩(v_j)을 생성하게 됩니다. Decoder의 구조는 transformer decoder와 같습니다. 최종적으로 디코딩된 feature와 movie trailer의 clip 임베딩 시퀀스에 대해 Nearest Neighbor retrieval 방식으로 가장 가까운 feature를 찾아 output trailer frame으로 선정하게 됩니다.
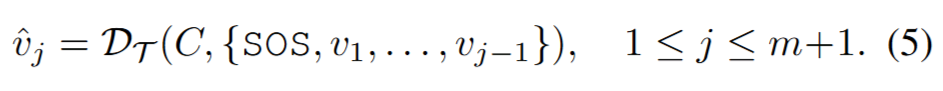
Training Loss

최종 목적함수는 단순합니다. 그림1의 TGT encoder-decoder 구조로 생성된 v^이 ground truth인 예고편 영상 (v)와 유사해지도록 reconstruct loss(L2 Loss)와 KL divergence loss를 조합한 것입니다. L_t는 위에서 trailerness encoder의 가이딩을 위한 목적함수입니다.
Proof
논문은 제안한 아키텍쳐(TGT)와 학습방식에 대해 우수성을 보이기 위하여 MAD와 MovieNet 데이터셋에 대한 실험을 진행하였습니다. 평가는 F1-score와 Levenshtein distance(LD), Sequence length difference(SLD)로 진행되었는데, F1-score는 정답으로 선택된 shot과 실제 정답 shot의 유사도를 보이는 지표로 높을수록 유사하게 잘 생성했음을 의미합니다. 한편, LD는 입력이 타겟과 같아지려면 몇번의 연산이 진행되어야 하는지 거리를 나타내는 지표로 실제 예고편과 순서적으로 유사한 정도를 측정할 수 있으며, 작을수록 우수한 성능을 의미합니다. 마지막으로 SLD의 경우 예측한 예고편과 실제 예고편 사이의 길이 차이로 값이 작을수록 우수한 성능을 의미합니다. 우선 기존 방법론과의 비교성능은 아래의 Table1과 같으며, 이 외의 테이블은 분석을 위한 실험이 다수입니다.

해당 연구와 입력과 제약 조건이 가장 유사한 기존 방법론인 CCANet과 SOTA video summerization 방법론인 CLIP-It를 비교로하여 성능을 리포팅하였으며, 제안한 방법론이 가장 우수한 성능을 보였음을 확인할 수 있습니다. CCANet와 비교하였을때 큰 차이로 성능향상으로 general한 장르에 대해 확장하였음을 보였으며, classificatio 구조가 아닌 sequence-to-sequence 구조로 매우 긴 영화에서 주요한 소량의 프레임을 선별하는 해당 테스크에서 이러한 양적 편향에 대한 영향이 줄어들었기 때문이라고 분석했습니다. 특히 LD와 같은 지표의 매우 큰 개선을 통해 CCANet과 같은 trailer moment detection에 집중한 방법론과의 차별성을 명확히 하였습니다. 다음으로, CLIP-It[22]의 경우 F1/Precision/Recall과 같은 단순 유사도 지표에서는 CCANet보다 오히려 우수했습니다. 반면 LD나 SLD 지표에서 TGT와 큰 성능 차이를 보였는데 이는 shot classification 방식으로 shot의 순서를 고려하지 않고 전체 생성된 영상의 길이도 고려되지 않는 video summerization 기반 접근법의 한계로 이해할 수 있습니다.
*~*~*~*~*~*~*~*~*~*~*~*~*
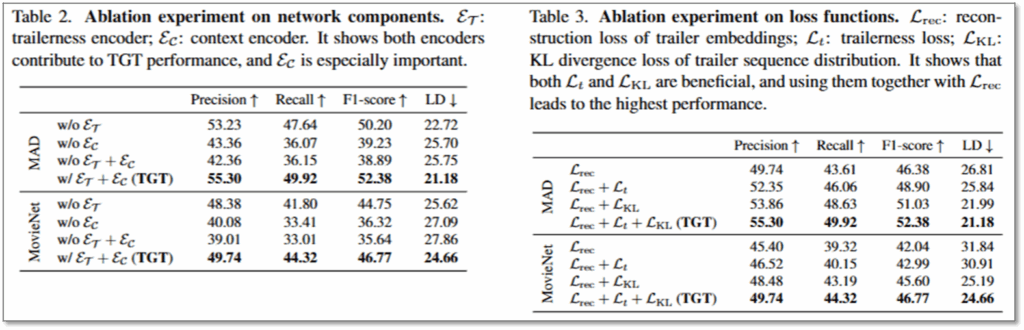
아래의 실험은 본 논문(TGT)에서 제안한 구조에 대한 Ablation 실험에 해당합니다. 먼저 Table2는 아키텍쳐에 대한 실험으로, trailerness encoder와 context encoder을 제거하였을때 성능 하락을 보이며 제안한 구조가 가장 효과적임을 보였습니다. 또한 trailerness encoder 만을 제거하였을때 성능 하락이 비교적 적은것을 통해, 해당 모듈을 제거하면 context encoder가 trailerness 정보를 일부 학습할 것으로 예측된다고 밝혔습니다. Table3는 각 데이터셋에 대해 제안한 Loss가 모두 효과적이였는지를 확인할 수 있습니다. 실험 결과 loss term을 추가할 수록 순차적으로 성능 개선을 확인할 수 있으며 최종적으로 제안된 TGT 의 목적함수가 가장 효과적임을 확인할 수 있습니다.

*~*~*~*~*~*~*~*~*~*~*~*~*
이후에 소개되는 실험은 TGT에 대한 추가적인 분석 실험에 해당합니다.
① Text-Controlled Trailer Generation: TGT는 얼마나 더 좋아질 수 있나요?
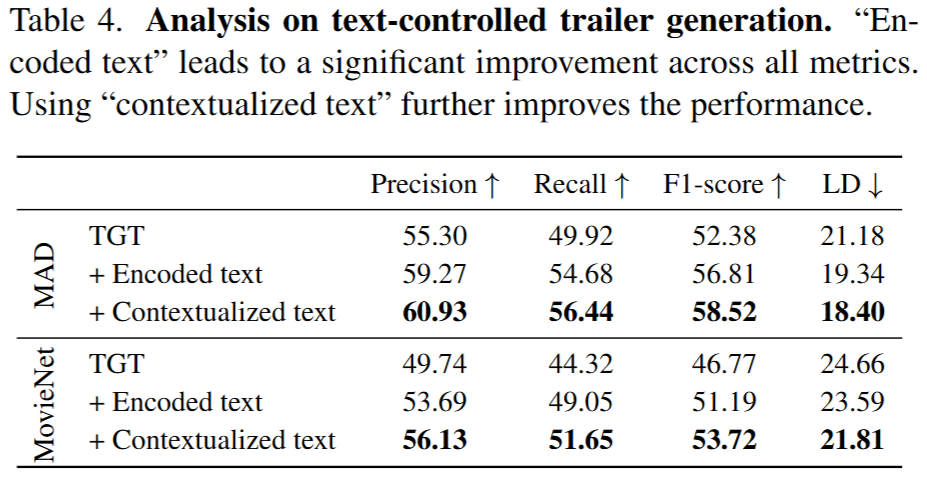
기존 trailer generation 방법론의 경우 영화외의 subtilte등 메타 데이터에 정보를 활용하여 예고편을 생성했었습니다. 제안한 방법론은 이와같이 부가적인 정보를 활용했을때, 제안한 TGT의 성능개선이 어느정도인지에 대해 Table4를 통해 분석했습니다. 먼저 Encoded text의 구현방법으로는, 영화 정보를 검색할 수 있는 IMDb[1]에서 영화의 메타데이터를 크롤링한 후, 사전학습된 RoBERTa 모델을 통해 임베딩하여 context encoder의 출력(C)에 단순하게 합했다고 합니다. 다음으로 개선된 입력에 대해 Contextualized text의 경우 Transformer encoder layer를 추가하여 text-controlled 입력의 맥락을 개선한 것입니다. 실험 결과 유의미한 성능 개선으로, 제안한 TGT가 외부 정보를 활용할 수 있다면, 다양한 지표에서 더욱 개선된 성능을 보일 수 있음을 확인할 수 있습니다. 이러한 분석은 차후 추가적인 정보를 네트워크에 주입할 수 있음을 보이는 유의미한 결과에 해당합니다.
② Shot Selection: TGT는 얼마나 정확한가요? 아쉽~게 틀린 예측도 평가에 고려해주세요.
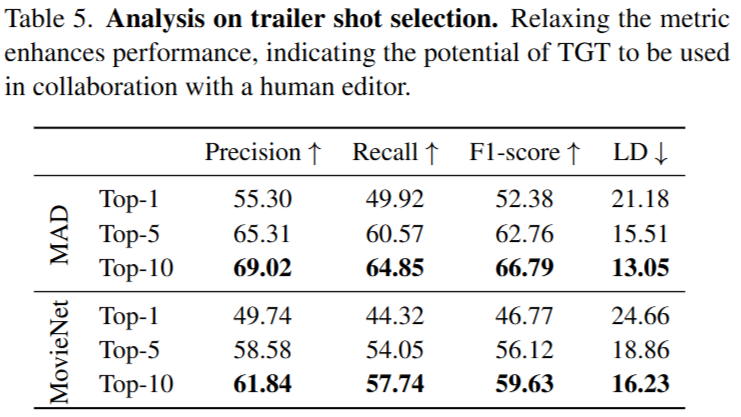
Table5에서는 TGT의 정확한 역량을 분석하기 위해 decoded 된 feature와 trailer embeding 유사성 검색을 하는 단계에서 top-5개, top-10개의 matching shots을 평가에 고려할 수 있도록 한 결과이다. 실험 결과 저자들의 예상과 동일하게 허용하는 후보군 크기가 커질수록 성능향상을 보였고, 예측 실패 사례에서 아쉬~운 실패가 다수 있었음을 고려하면, TGT가 move trailer generation의 가장 어려운 테스크인 shot selection를 생각보다 더 잘 수행하고 있음을 알 수 있습니다.
③ Scaling Effect: 데이터셋이 많아지면 성능 개선이 있을까요?(당연하지만 검증해야하는..)
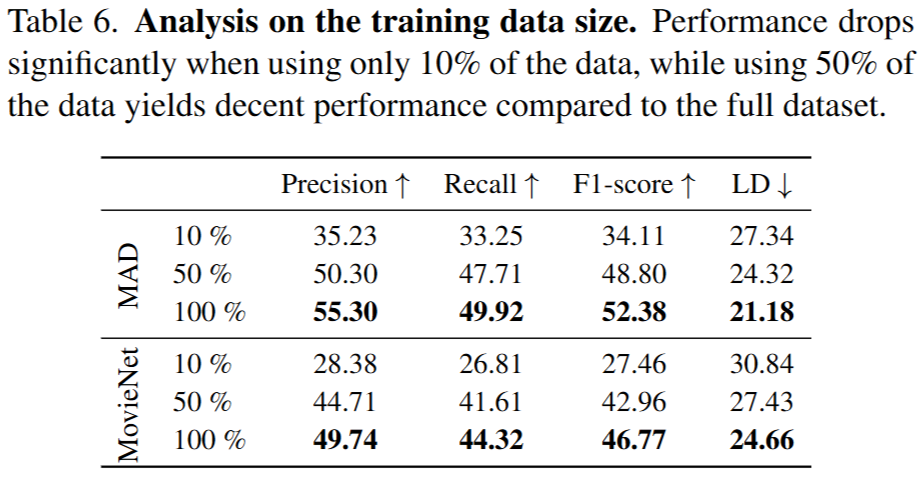
Table 6의 실험을 통해 데이터셋의 스케일과 성능의 높은 연관관계를 확인할 수 있는데요, 이는 데이터셋이 증가할수록 다양한 패턴과 영화-트레일러간의 다양한 관계를 학습할 수 있기에 발생하는 직관적인 결과에 해당합니다. 논문은 해당 실험에 대해서도 다양한 지표에 대해 검증을 수행했습니다.
*Reference
[31] ACM2006, Automatically selecting shots for action movie trailers
[38] ECCV2020, Learning trailer moments in full-length movies with co-contrastive attention
[35] ACM2024, Transnet v2: An effective deep network architecture for fast shot transition detection
[22] NeurIPS2021, Clip-it! language-guided video summarization
[1] Imdb. https://www.imdb.com/. Accessed: March 15, 2023. 5, 7
* Reference의 순서는 논문의 순서에 따름
이상으로 리뷰를 마치겠습니다. 감사합니다.
안녕하세요 좋은 리뷰 감사합니다.
리뷰해주신 논문은 영화 예고편 생성을 위해 trailerness와 context를 고려한 shot-level sequence-to-sequence 구조로,
CLIP 기반 shot 임베딩과 트레일러 유사도 학습을 통해 요약이 가능하게 한 것 같습니다
한 가지 궁금한 점이 있는데, 왜 trailer-generation을 위한 모델인 CCANet보다 CLIP-It가 F1 score 측면에서 우수한 성능을 보이는건가요?
안녕하세요 리뷰 읽어주셔서 감사합니다.
우선 CCANet은 2020년 논문으로 CLIP-IT 보다 앞서서 발표된 성과입니다. 이러한 이유로 기존 video summerization의 주요 테스크에 중복되는 trailer moment detection를 더 잘 수행한 것으로 이해할 수 있을 것 같습니다.
그러나 두 방법론 모두 LD, SLD 지표에서는 제안 방법과 큰 격차로 차이가 납니다. 이를 통해 trailer의 중요 요인 중 하나인 배치, 길이 등에 대해 트레일러 생성을 위해 설계된 본 논문은 유의미한 개선이 있었음을 확인할 수 있습니다.
감사합니다.
안녕하세요 유진님 좋은리뷰 감사합니다.
메타데이터가 없어도 우선적으로 해당 task를 할 수 있고 심지어 이전 논문들보다 성능이 좋다는게 대단합니다.
제가 약간 궁금한점이 있는데 이러한 video summarization task 에서 일반적으로 사용되는 평가방식인지가 궁금한데, 결국 영화를 요약하고 기존에 존재하는 트레일러와의 비교를 통해 얼마나 비슷한지를 평가지표로서 사용하는 것 같습니다. 물론 이러한 방식이 아니면 그다지 다른 평가방식들이 떠오르진 않지만, 일반적으로 사용되는건지? 혹은 생각해보신 다른 평가방식이 존재하는지 여쭤보고싶고, 이러한 방식은 결국 인간이 일반적으로 만들어온 트레일러의 의도가 어느정도 학습이 될 것 같은데, 좀 더 창의적이거나 독특한 구성방식으로 트레일러를 만들고 싶다면 그건 생성형 모델이 해야할 일인건지 흠.. 그런 것들이 궁금합니다. 말이 좀 추상적이라 편하게 답해주시면 감사하겠습니다!
안녕하세요 리뷰 읽어주셔서 감사합니다.
먼저 video summarization task에서 일반적인 평가방식의 경우 모델의 요약 결과와 정답간의 유사도인 F1-score로 측정하는 것이 일반적입니다. 그러나 해당 논문의 경우 모델 추론 결과와 정답간의 “길이”와 “clip의 순서”를 추가적으로 검증하기 위해 지표 LD, SLD를 추가로 사용한 것입니다.
창의적이고 독특한 방식이라는 것이, 영화 트레일러의 측면에서는 시간순서의 재배치, 중요 프레임 위치 선정 등으로 구현되는데요, 그런경우는 해당 논문과 같은 seq2seq로 해결할 수 있습니다. 다만, 씬 자체를 바꾸고 싶다면 (예를 들어 실사 영화를 애니메이션 트레일러로 생성) 말씀하신대로 생성형 모델이 필요할 것 같네요 =)
질문에 대한 이해가 잘못되었다면 추가질문 부탁드립니다
감사합니다.
안녕하세요 유진님 좋은 리뷰 감사합니다.
해당 Trailer Generation은 예고편 생성 작업자가 shots을 선정하고 순서를 배치하는 일을 간소화하는 일이라고 이해를 했습니다. 그렇다면 실제로 2시간짜리 영화에서 예고편을 생성한다고 할 때, 모델에는 입력 영상이 어떤 방식으로 들어가게 되나요? 만약 영화 전체를 미리 특정 단위로 나누어서 들어가게 된다면 전체 context 정보나 스토리 흐름 전체를 고려못하는 것 아닌지가 궁금해서 질문 드립니다.
감사합니다!
안녕하세요 리뷰 읽어주셔서 감사합니다.
모델은 전체 영화가 입력되게 됩니다. 논문의 해당 부분에서 확인할 수 있는데요, 영화 M을 전체 n개의 sequence로 나누어 입력을 하게 됩니다. (그림1 참조)
M denotes a sequence of movie shots {U1, U2, . . . , Un}
이때 영화를 sequence로 분할하는 방법은 Transnet v2[35]에 따르며, 평균적인 n의 크기 등은 아쉽게도 공개되지 않았네요.
감사합니다.