1. 서문
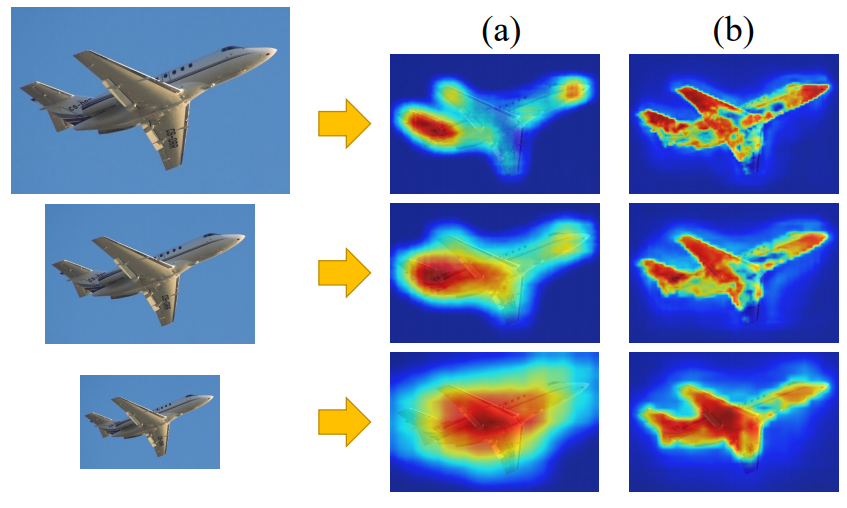
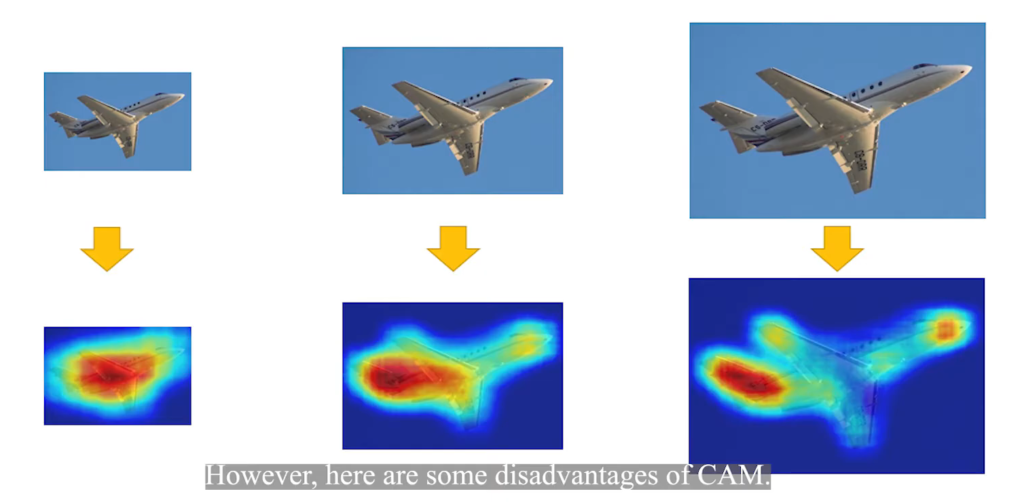
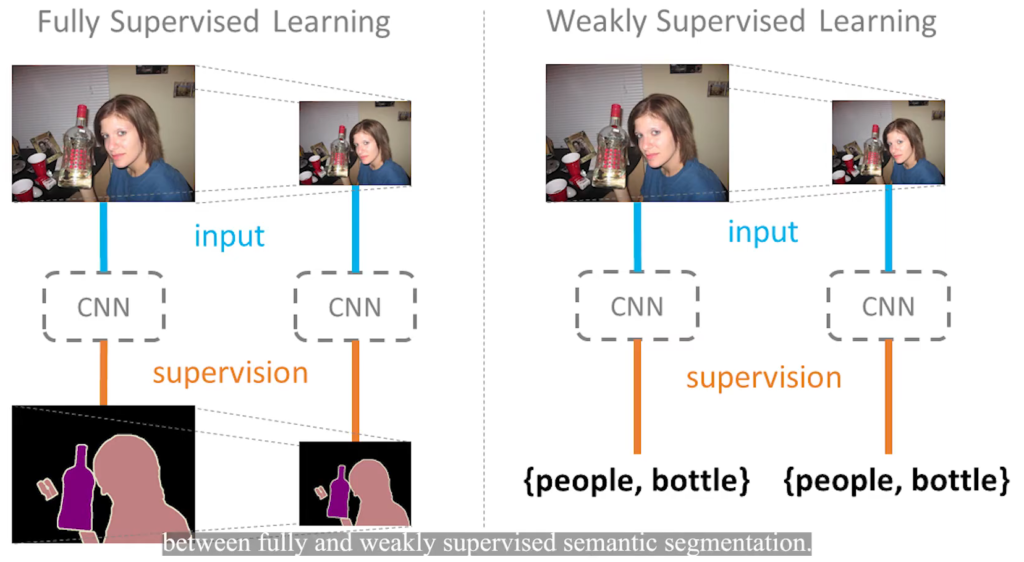
Image-level의 weakly supervised semantic segmentation은 cost가 큰 segmentation dataset을 사용하지 않아도 된다는 장점이 있어 연구 주제로써 인기가 있다. 최근에 관련한 방법으로서 class activation map(CAM)기법이 알려져 있다. 그러나 그림 1에서 확인할 수 있듯이 CAM은 항상 가장 discriminative regions을 활성화시키고, boundary가 정확하지 않으며, 다양한 spatial 변환에 일관성이 없다. 논문에서는 이러한 disadvantages의 원인을 full supervision 과 weakly supervision gap으로 분석한다. Supervisoin Gap이란 기존의 full supervision 방식의 pixel leval segmentation은 data agmentation(예를 들어 그림1과 같은 크기 변환)시에 GT에도 같은 변환을 주지만, weakly supervision 방식에서는 이미지에 포함된 물체의 라벨만을 제공하므로, 이러한 변환의 영향을 받지 않는다는 차이이다.(그림2 참고) 이 논문에서는 self-supervised equivariant attention mechanism (이후 SEAM) 을 통하여 supervision gap을 줄이고자한다.
2. 제안하는 방법
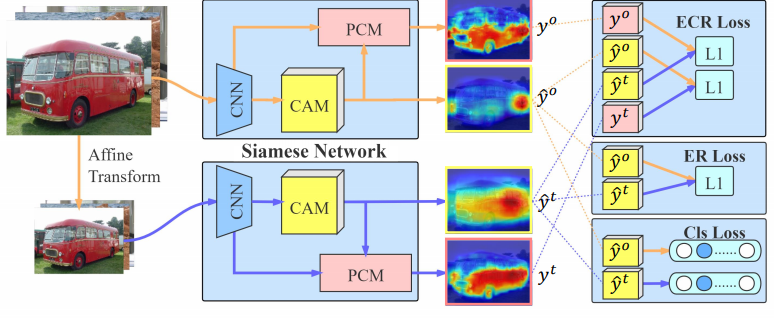
Supervision Gap 문제를 해결하기 위하여, 논문에서는 그림3과 같은 network를 제안하였다.
1) Equivariant Regularization(ER) Loss
저자들이 소개한 Supervison gap을 직접적으로 이용한 Loss로 affine 변환을 A(), segmentation function을 F(), 이미지를 I라 하였을 때, 수식 1과 같다.
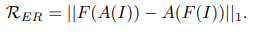
2) Pixel Correlation Module(PCM)의 이용
PCM은 context information과 pixel leval의 prediction을 refine에 효율적인 self-attention 기법에서 영향을 받은 것으로, 그림3에서 확인할 수 있듯이 CAM output과 CNN의 output인 feature를 통해 CAM을 수정한다.
3) Cls Loss와 ECR Loss
Cls Loss에는 일반적인 CAM 알고리즘 처럼 global average pooling(GAP)를 이용하여 classification label과의 Loss 를 구한다. 식은 수식2와 같다.
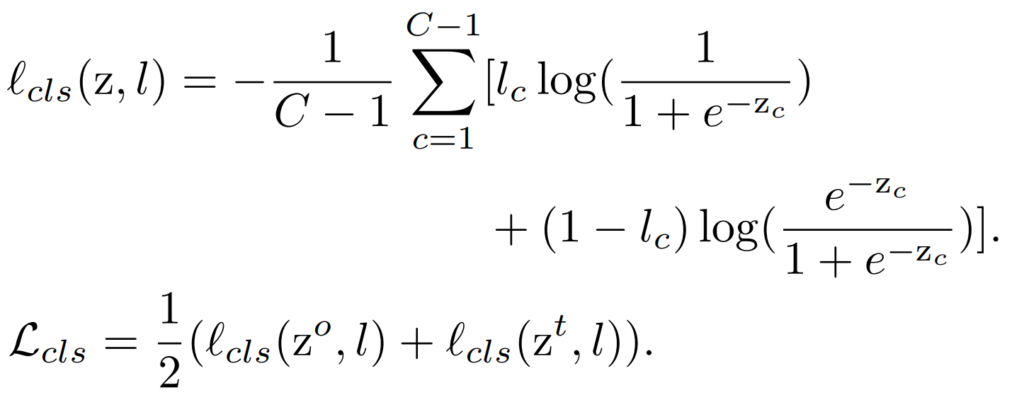
다음으로 equivariant cross regularization (ECR) Loss는 수식 3과 같다. ECR Loss를 사용하지 않은 실험에서는 PCM의 output map의 Loss가 하나의 클래스로 예측되는 Local minimum으로 빠르게 수렴하는 문제가 있어서 ECR Loss를 사용했다고 한다.
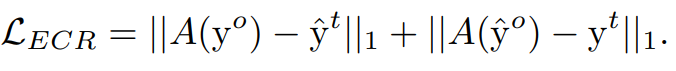
제안하는 총 Loss는 L = L_{cls} + L_{ER} + L_{ECR} 와 같다.
3. 실험


질문있어서 남깁니다.
본문 내용 중에
“PCM은 context information과 pixel leval의 prediction을 refine에 효율적인 self-attention 기법에서 영향을 받은 것으로…” 라는 내용이 있는데 여기서 leval은 level의 오타인건가요??
그리고 prediction을 refine에 효율적인 self-attention… 이 부분이 잘 읽히지가 않아서 무슨 내용인지 감을 잡기가 어렵습니다. PCM에 대해서 추가적인 설명을 해주실 수 있나요?
PCM의 역활은 그림 3에서 볼 수 있듯이 attention하는 부분을 더 refine 하여 경계가 더 세부적이 되도록 CAM이미지를 개선시키는 것입니다!
본인이 실험한 결과는 없나요?
답변이 늦어 죄송합니다! 정리 당시에는 실험이 완료되지 않았고, 빠르게 추가하겠습니다! (세미나 발표자료에 추가 이후 위 내용에 추가하지 않았습니다 죄송합니다..)