안녕하세요, 예순 네번째 X-Review입니다. 이번 논문은 2024년도 arXiv에 올라온 Char-SAM: Turning Segment Anything Model into Scene Text Segmentation Annotator with Character-level Visual Prompts입니다. 바로 시작하도록 하겠습니다.
1. Introduction
본 논문은 scene text 연구들 중 segmentation에 관한 논문입니다. 이 scene text segmentation 모델을 학습하기 위해 필요한 annotation은 당연히 pixel-level이기에 labeling cost가 많이 들 뿐더러, high-quality 데이터셋도 부족한 상황입니다. 이로 인해 학습 때 종종 pseudo annotated 데이터셋을 사용하기도 하는데, 예를 들어서 COCO_TS나 MLP_S라는 원래 text detection용 데이터셋을 사용해 semi-supervised 기반 방식으로 학습할 때는 종종 text mask가 조각조각 나있거나 text가 아닌 영역이 잘못 라벨링되는 등에 문제가 존재합니다.
또, 본 논문에서는 segmentation foundation model인 SAM을 그대로 scene text segmentation에 적용할 경우에 몇 가지 문제가 존재한다고 말합니다. 그 중 첫 번째는 prompt의 정밀도가 부족하다는 점입니다.

위 Fig1의 (a)와 같이 SAM에 word-level의 bbox를 입력으로 주면, 개별 text를 구분하기보다는 전체 word를 하나의 덩어리로 처리해버리는 것을 확인할 수 있습니다. 즉, 정확하게 text를 segmentation하지 못하고 있죠. (b)의 word-level이 아니라 character-level로 prompt를 넣은 결과를 보아 SAM에는 character-level의 bbox가 필요하다는 것을 확인할 수 있습니다.
또, 두 번째 문제점은 over/under segmentation입니다. 이는 Fig1 (c), (d)를 보면 확인할 수 있는데, character level bbox를 사용한다고 하더라도, 문자 내부에 빈 공간이 있는 경우(예를 들어 D나 A 등등)에 그 빈 공간과 배경을 구분하지 못해 내부 hole까지 text로 처리해버리고 있습니다. 또, 반대로 일부 문자 영역을 제대로 segmentation하지 못하는 경우도 존재합니다. 특히 이 under-segmentation 케이스는 이미지에서 text 크기가 클 수록 더 자주 발생하는 문제라고 합니다.
방금 언급한 이런 문제들을 해결하기 위해 본 논문에서는 character level의 visual prompt 기반 SAM을 기반으로 한 Char-SAM이라는 프레임워크를 제안합니다. 크게 Character Bounding-box Refinement (이하 CBR) 모듈과 Character Glyph Refinement (이하 CGR) 모듈로 구성이 되어 있으며, 각각 word level annotation을 좀 더 정교한 character-level annotaion으로 변환하고, character 카테고리에 따른 glyph 정보를 활용해 over/under segmentation 문제를 해결하고자 설계된 모델로 training-free로 동작합니다. 제안된 프레임워크와 관련해서는 아래 method 단에서 자세히 다루도록 하겠습니다.
2. Method
2.1. Framework
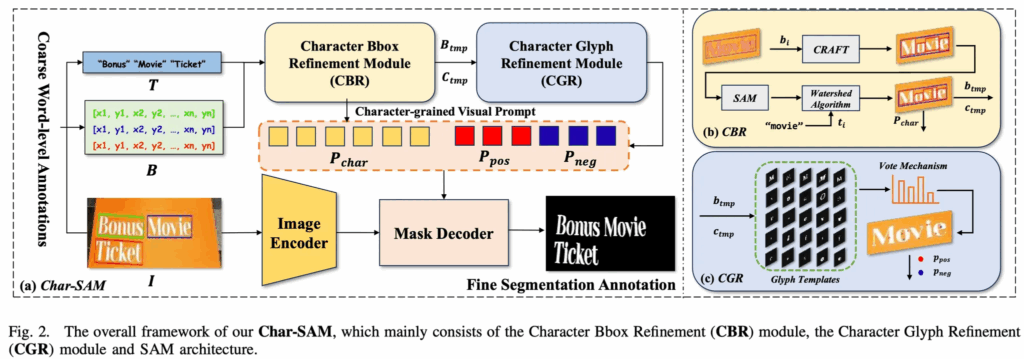
Char-SAM은 scene 이미지에 주어지는 word-level annotation을 pixel-level annotation으로 refine하는 것이 목표입니다. 전체 프레임워크는 위 Fig2에서 확인해볼 수 있는데 처음에 입력으로는 Image와 word-level bounding box B =
{b_i}<em>{i=1}^{n}과 이에 대응되는 text transcription 정보 T =
\{t_i\}</em>{i=1}^{n}로 구성됩니다. b_i. t_i는 각각 i번째 word의 bbox, transcription을 의미하구요.
보시면, CBR(Character Bounding-box Refinement) 노란색 모듈을 먼저 타게 되는데 이 모듈은 word-level annotation을 보다 정밀한 character level bbox B_{tmp}로 변환하고, 이에 대응하는 character 카테고리 C_{tmp}를 output으로 내게 됩니다. 이후, 이들을 입력으로 해서 CGR(Character Glyph Refinement) 하늘색 모듈을 타게 되는데, 이 모듈은 glyph 정보에 기반하여 positive point prompt P_{pos}와 negative point prompt P_{neg}를 생성하는 모듈입니다. 그림에서도 positive prompt가 빨간색 블럭으로, negative prompt가 파란색 블록으로 표시된 것을 확인할 수 있습니다.
그 후 마지막으로 input image와 refine된 prompt들 P_{char}, P_{pos}, P_{neg}를 SAM에 입력으로 넣어서 보다 정밀한 character level의 segmentation mask를 생성하는 식으로 동작합니다.
각 CBR, CGR 모듈에 대해서는 아래에서 설명드리도록 하겠습니다.
2.2. Character Bounding-box Refinement Module
먼저 CBR 모듈입니다. 이 CBR 모듈은 word-level의 prompt만으로는 SAM이 정확하게 text segmentation을 수행하지 못한다는 점을 해결하기 위해 character level의 bbox로 refinement하는 역할을 하는 모듈입니다. Fig2 우상단(b)에 이 CBR 모듈의 동작과정이 그려져 있는데요, 보시면 먼저 CRAFT라고 하는 character level 기반으로 동작하는 text detection 모델을 사용해 초기의 character 영역을 검출해냅니다. 하지만, 종종 그림에 나와있는 예시 “Movie” 처럼 가까이 위치한 문자들이 완전히 하나의 문자로 분리되지 않는 경우가 존재하는데요. (”vi”를 한 문자로 검출한 것처럼) 이런 경우에는 하나의 bbox에 두개 이상의 문자가 포함되어 있어서 이후헤 사용한 Glyph 정보를 정확하게 활용할 수 없게 됩니다. 여기서 Glyph란 글자(font)에서 문자의 시각적인 형태를 의미하는 것으로 생김새 정도로 보시면 될 것 같습니다.
무튼, 이렇게 한 box에 한 문자가 아닌 여러 문자가 포함되어 있는 경우 이에 대해 처리를 해주는 과정이 필요합니다. 여기서는 CRAFT 모델로 나온 bbox 영역들을 뽑아내어 text recognizer에 넣어 character들을 뽑아내게 되구요. box 자체를 나누기 위해서는 이 영역을 SAM에 넣고 나온 segmentation 결과를 watershed 알고리즘으로 잘게 분리한다음 각 글자마다 연결된 pixel 덩어리들을 찾아 character level의 bbox를 추출해냅니다. 이 과정에서 v와 i가 각각의 box를 갖게 되겠고, 이후 앞서 recognizer로 뽑아놓은 character label과 bbox가느이 이분 매칭을 통해 최종적으로 character level의 bbox와 label 정보를 얻게 됩니다.
2.3. Character Glyph Refinement Module
이제 정확한 text segmentation을 수행하기 위한 character level의 bbox는 얻었지만 앞서 언급한 것처럼 이 character level의 bbox를 prompt로 SAM에 넣었을 때도 여전히 over segmentation이나 under-segmentation 문제가 발생합니다. 이런 문제는 특히 문자 내부에 구멍이 있는 ‘D’나 ‘A’같은 문자에서 자주 보이는 문제였는데, 여기서는 이런 문제를 해결하기 위해 CGR 모듈을 제안한 것입니다. 본 논문에서는 영어 문자가 사용하는 폰트나, 어떤 방향과 관계없이 동일한 문자 category라면 고정된 glyph를 가진다는 점에 착안하여, 여러 다양한 폰트를 수집하면서 문자별 glyph 템플릿을 생성하였습니다. Fig2 그림에 우하단 부분에서 glyph 템플릿을 확인할 수 있습니다. 이 glyph 템플릿은 ImageDraw나 ImageFont 라이브러리를 통해 생성할 수 있고, 이 각 문자 카테고리에 대해서 glyph 템플릿 이미지를 생성했다면, 이 glyph 이미지 pixel들을 foreground와 hole pixel로 분류 해볼 수 있습니다. 그리고 각 pixel 위치에 대해 이 pixel이 자주 등장했는지 여부를 확인하는데요. 예를 들어 어떤 a폰트에서의 ‘A’와 b폰트에서의 ‘A’가 있다고 할 때 한 픽셀이 이 두 폰트의 ‘A’에 공통으로 존재하는 pixel이라면 그 pixel은 정말 ‘A’의 중요한 구조일 확률이 높습니다. 따라서 모든 glyph 템플릿 이미지들을 겹처봐서 각 pixel이 몇 번 등장했는지를 확인하는 과정을 거쳐 일정 비율 이상 나온 pixel만 thresholding을 통해 남기게 됩니다. 즉, 정말 공통적인 부분만 남기고, 각 스타일마다 달라지는 미세한 디테일은 없애는 과정이라고 보면 됩니다. 여기서 hole pixel들은 false point prompts P_{neg}가 되겠구요, foreground pixel들은 positive point prompts P_{pos}로 처리 됩니다. 이렇게 생성된 P_{pos}와 P_{neg}는 각각 문자 내부의 주요 구조와 hole 영역을 명확히 구분해주는 시각적 프롬프트로 사용되며, character-level의 bbox P_{char}와 같이 SAM에 입력으로 들어가게 되어 더 정밀한 mask를 뽑아내는 역할을 합니다.
3. Experiments
다음으로 실험 살펴보도록 하겠습니다. 실험에서 사용한 데이터셋은 TextSeg, COCO_TS와 MLP_S 이 세 데이터셋을 사용하였습니다.
3.1. Comparison with SOTA Approaches
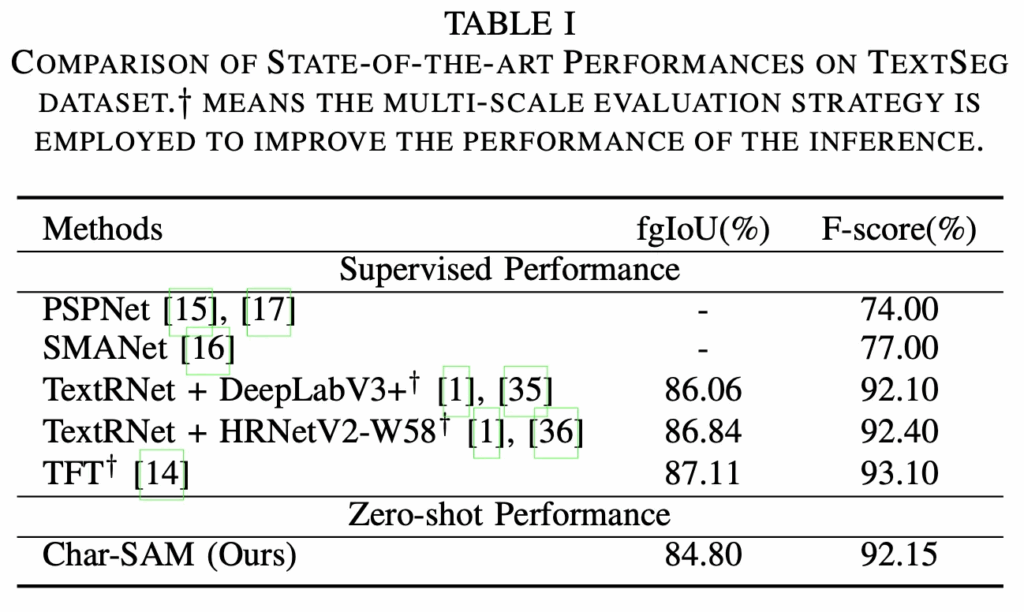
먼저 벤치마크 table인데 여기서는 TextSeg 데이터셋에 대해서만 수행되었습니다. 위 Table1 결과를 보시면 Char-SAM은 학습 없이 동작하는 방식이며, single scale input resolution만 사용했음에도 multi-scale을 사용한 supervised 모델과 유사 성능을 보입니다. (dagger 표시가 multi scale). 특히 F-score 측면에서 보면 기존 SOTA인 TFT보다 약 1% 떨어지는 성능을 보이고 있습니다. 이는 Char-SAM이 학습 없이도 scene text segmentation을 위한 auto augmentation pipeline임을 보이는 실험이지만,,, 베이스로 삼은 SAM모델에 대한 리포팅이 되어 있지 않아 본 테이블에서 SAM과의 비교는 어려운 점이 아쉬운 것 같습니다.
3.2. Ablation Study
Key modules
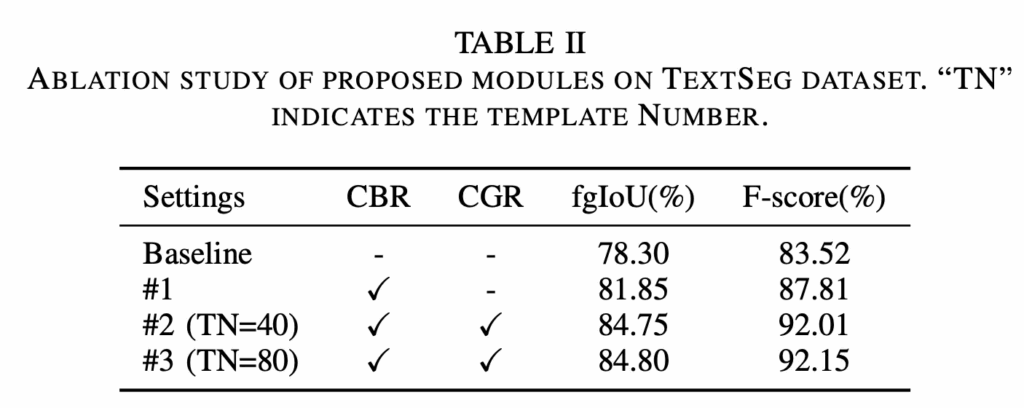
다음은 ablation study로 우선 본 논문에서 제안된 두 모듈, CBR과 CGR 모듈의 효과를 확인하고자 수행된 실험입니다. 먼저 baseline과 비교했을 때 CGR 모듈만 추가한 경우 두 평가지표에서 3%이상의 성능 향상을 보여주면서 word-level의 bbox를 그대로 사용하는 것보다는 character-level의 bbox로 정제해서 사용하는 과정이 실제로 segementation을 수행하는데 더 도움이 된다는 점을 보이고 있습니다. 또 #1과 #2(CGR을 함께 사용하는 경우)를 비교해보면 CGR 모듈은 glyph 정보를 기반으로 좀 더 정교한 visual prompt를 생성해서 fgIoU 기준 약 3%, F-score 기준 약 4% 더 성능 향상을 가져온 것을 확인할 수 있습니다. 또 #2, #3은 두 모듈을 다 사용하는 경우에서 TN 차이가 존재하는데, 이는 glyph 템플릿에 사용한 폰트 수를 의미합니다. 즉, 폰트 수를 40개 사용하는 것보다 80개로 늘려 사용하면(#3) 미세하긴 하지만,, 성능이 좀 더 향상된 것을 확인할 수 있는데 이는 폰트가 다양할수록 문자의 구조를 보다 정확하게 모델링하는 데 도움된다고 해석해볼 수 있겠습니다.
Prompt granularity
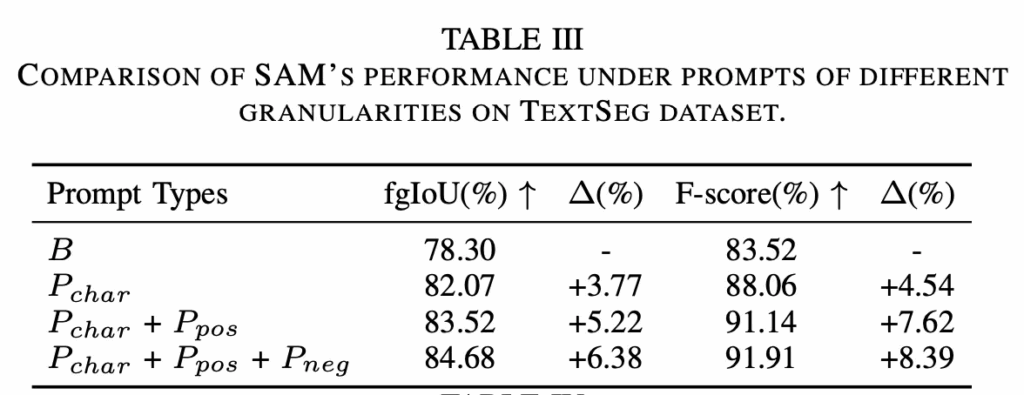
다음은 prompt를 좀 더 세분화하는 것이 segmentation 성능에 미치는 영향을 확인하는 실험입니다. 위 Table3에서 확인할 수 있듯이 맨 위에 있는 B는 word-level의 bbox만을 사용하는 경우인데, 이보다는 그 아래 P_{char} character-level box를 사용하는 경우 앞서 table2에서 본 것 과 같이 성능 향상을 보이고 있습니다만, 표2의 #1과 동일한 실험이라고 생각되는데 성능이 다른 점에 대해서는 언급이 없는 점이 수상합니다. 이후, 이 character level box에 더해서 positive point prompt를 함께 사용할 경우에 base 대비 추가적인 성능 향상을 보이고 여기에 negative point prompt까지 사용하면 약간의 성능 향상을 더 보이는 것을 확인할 수 있습니다. 다만 이 역시 table2의 #2혹은 #3과 유사 실험이라고 보이는데 성능이 미세하게 다릅니다.
Datasest quality
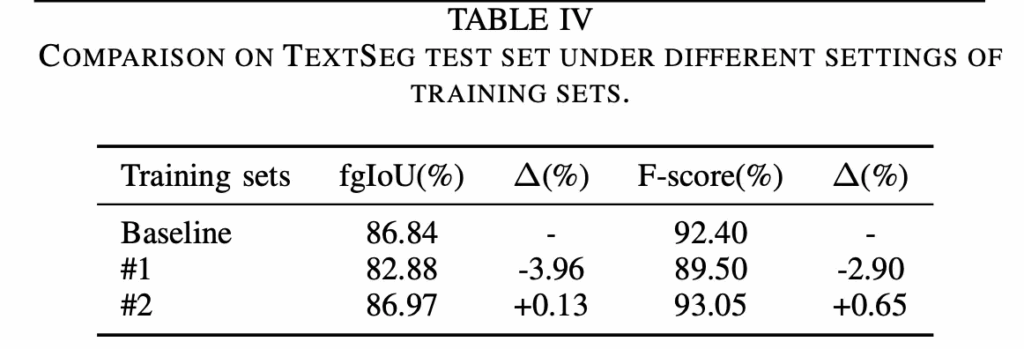
이전까지는 TextSeg데이터셋을 사용해 실험을 수행했는데요. 이 TextSeg 데이터셋은 pixel level의 mask가 다 들어있는 데이터셋이지만, COCO_TS, MLT_S 데이터셋은 각각 COCO-Text와 MLT17이라고 하는 데이터셋으로부터 weakly supervised 방식을 통해 생성된 좀 quality가 낮은 annotation입니다. 이 실험은 본 논문에서 제안된 프레임워크 Char-SAM으로 생성한 text segmentation annotation이 기존 semi-supervised 방식으로 만든 COCO TS나 MLT S보다 더 좋은 quality를 갖는 다는 점을 입증하고자 수행되었습니다.
Table에 있는 #1에서는 COCO TS와 MLT S에서 각 1000개의 sample을 샘플링해서 baseline 학습에 추가한 경우이고, #2는 동일한 샘플에 대해서 char-SAM이 생성한 annotation을 baseline 학습에 추가한 경우입니다. 결과를 보시면 기존 좀 low quality annotation을 그대로 사용할 경우 오히려 성능 하락이 발생하며, 모델이 좀 부정적인 영향을 미치는 반면에 동일한 데이터에 대해 Char-SAM을 이용해 생성한 annotation을 사용하면 baseline보다 약간의 성능이 향상되는 것을 확인할 수 있습니다. 이는 Char-SAM의 auto annotation 방식이 실제 학습 성능 향상에도 도움되는 좀 더 나은 퀄리티의 어노테이션을 생성할 수 있음을 시사합니다.
3.3. Visualizations

마지막으로 시각화 결과입니다. 위 Fig3은 Char-SAM으로 생성한 pixel level annotation과 기존 COCO TS, MLT S annotation을 비교하고 있는데. 보시면 육안으로 보기에도 Char-SAM이 생성한 mask는 전체적으로 text 경계가 좀 부드럽다구 볼 수 있고, foreground와 background 간의 구분도 명확합니다.
안녕하세요, 좋은 리뷰 감사합니다.
제안하는 프레임워크가 training-free라고 하셨는데, 그럼 베이스 모델인 SAM 말고 다른 segmentation 모델에도 적용가능한 거 아닌가요? 다른 모델은 베이스 삼아 비교한 실험은 없는지 궁금합니다. 또 벤치마크표에 비교하는 모델이 4종류밖에 없는거 같은데 text segmentation 방법론이 애초에 많이 없는건지 궁금합니다. 마지막으로 table2에 적혀있는 baseline이 그냥 SAM으로 보면 되는걸까요?
감사합니다.
댓글 감사합니다.
넵 맞습니다. 이론적으로는 SAM말고 다른 segmentation 모델에 적용가능합니다. 다만 본 논문에서 제안된 CBR, CGR 모듈이 SAM 기반으로 설계되었기에 적용에 한계가 있을 것 같기는 합니다. 또, 논문에서는 다른 segmentation 모델에 적용한 실험도 없습니다.
또, 비교 모델이 4종류밖에 없는건 애초에 text segmentation 방법론이 많이 없는게 아니라, 여기서 많이 안넣은 것으로 보입니다. 아카이브 논문임을 고려하면 이해될 것 같습니다… 마지막으로 table2에 적힌 baseline은 word-level bbox prompt만 입력으로 넣는 기존 SAM이 맞습니다.