지난주 내슈빌에서 열린 CVPR 2025 참관 후기를 작성하고자 합니다.
무슨 이야기를 담으면 좋을까 하다가 학회에서 흥미롭게 봤던 연구 내용들은 세미나 시간에 풀면 될 것 같다는 생각이 들어서요. 그냥 학회 참여하면서 느꼈던 감정과 생각을 작성하고자 합니다.
인생 첫 미국 입국
CVPR은 가끔 캐나다에서 한번씩 열리는걸 빼면 거의 대부분 미국에서 개최했던걸로 기억합니다. 이번엔 미국 남부에 위치한 내슈빌에서 CVPR이 진행되었습니다. 한번에 가면 정말 좋을텐데 안타깝게도 한국에서 내슈빌로 한번에 가는 비행기는 없어서 갈 때 올 때 모두 시애틀에서 한번 경유했었네요.
미국 입국 심사에서 운이 나쁘면 다시 한국으로 돌아갈 수 있다고 하길래 괜히 쫄려가지고 유튜브로 입국 심사 질문들도 찾아보고 서류들도 뽑아가고 그랬네요. 근데 생각보다 많은 사람들을 입국심사를 하다보니 심사관들도 적당히 간단한 질문 몇개만 하고 바로 들여보내주는 것 같습니다.

그래도 숙박이나 미국 입국 목적과 관련된 서류등을 챙겨가면 훨씬 좋긴 하더라구요. 무슨 학회 왔냐고 물어볼 때 그냥 학회에서 제공한 invitation 서류 하나 쥐어주니 바로 입국 허가 해줬습니다 허허.
미국을 한번도 가보지 않았다보니 환상 같은 것들이 좀 있었습니다. 미국이 워낙 부유한 강대국이다보니 다들 미국 가서 성공하려고 하는? 그런 모습도 보이고 해서 다들 잘 사는 줄 알았는데 생각보다 노숙자 형님들도 곳곳마다 보이고 자동차들도 찌그러져서 수리하지도 않은 채 돌아다니는 모습을 보고 적잖이 놀랐네요.
또 하나 걱정했던 점은 항상 뉴스로 미국의 총기사고 같은 내용들을 접하다보니 이거 미국 가다가 총 맞는 건 아닌지 하는 걱정도 있었는데 다행히 그러한 일은 없더라구요. 오히려 너무나 평화로워서 관광오기 좋겠다는 생각을 여러번 했습니다. 특히 시애틀은 날씨도 20도 초반으로 선선해서 한국으로 돌아가기 싫더라구요 허허.

하지만 음식이 그렇게 다채롭지 않고 (맨날 햄버거 샌드위치) 가격도 너무 비싸서 결국 한국이 그립다는 생각은 여행 중간에 계속 났었습니다. 지난번 런던 갔을 때도 그랬지만 결국 돌이켜보면 한국만한 나라가 없구나 라는 생각이 계속 드네요.

CVPR2025
그럼 학회장에서 봤던 것들을 생각나는대로 한번 얘기해볼게요. 우선 학회장 건물이 엄청 컸습니다. 거의 코엑스만했어요. 그만큼 CVPR에 제출한 논문들도 많고 붙은 논문들도 많았기 때문이라고 생각합니다. 제가 기억하기론 accept rate가 22%정도 되는 걸로 알고 있는데 하루에 2번 총 6번 있는 포스터 섹션 각각마다 480편정도 논문을 발표하더라구요.
대충 3000편 정도 되는 논문이 붙은 것 같은데 그럼 CVPR에 제출한 논문만 1만5천편이 넘는다고 볼 수 있겠습니다. CVPR이 탑티어 학회임은 틀림없지만 이렇게 많은 논문들이 제출된 것에 대해서 인공지능도 정말 과열되었구나 라는 것을 몸소 체감할 수 있었던 것 같네요.
포스터 섹션 시간이 2시간정도 진행이 되는데 그때마다 500편이 다되어가는 논문들을 다 볼 수 있는 시간과 제 뇌 용량이 허용되지 않더라구요. 그래서 제목만 보고 계속 지나치다가 관심 있는 분야를 급하게 사진만 찍고 다시 다른 포스터로 달려가고 그랬습니다. 그래서 지금 제 사진첩에 포스터 사진이 덕지덕지 찍혀있는데 언제 다 정리할지 걱정이네요.
포스터 섹션에서 메인이 되는 주제는 Image generation쪽과 reconstruction이었던 것 같습니다. 매 포스터 섹션마다 거의 절반 이상의 논문이 다 이쪽 분야였던 것 같아요. Diffusion이 핫하다는 얘기는 22년도에 들었던 것 같은데 아직도 diffusion이 생성쪽을 꽉 잡은 것처럼 보이고, reconstruction 쪽은 Nerf가 한창 유행했던 걸로 기억하는데 이번 CVPR에서는 Gaussian Splat라는 키워드가 상당히 많이 보였던 것 같습니다.
태주형의 세미나 혹은 x리뷰에서 많이 보았던 키워드들인데 그쪽에 대한 공부를 하지는 않았어서 아 그냥 GS를 통해서 뭔가를 했구나.. 정도로만 이해하고 넘어갔었습니다. 그 분야에 대한 이해도도 많지 않았고 저거 하나하나 다 보면 포스터 섹션 시간이 다 끝나버릴 것 같더라구요.
게다가 네이버 랩스에서 제안한 Dust3r의 엄청난 파급효과?로 인하여 CVPR에서 그의 후속 논문들이 쏟아져나왔습니다. 3D vision쪽 oral section 발표를 들어보면 15편 중 8편 정도가 Dust3r를 보완한 후속 논문에 속했던 걸로 기억합니다.
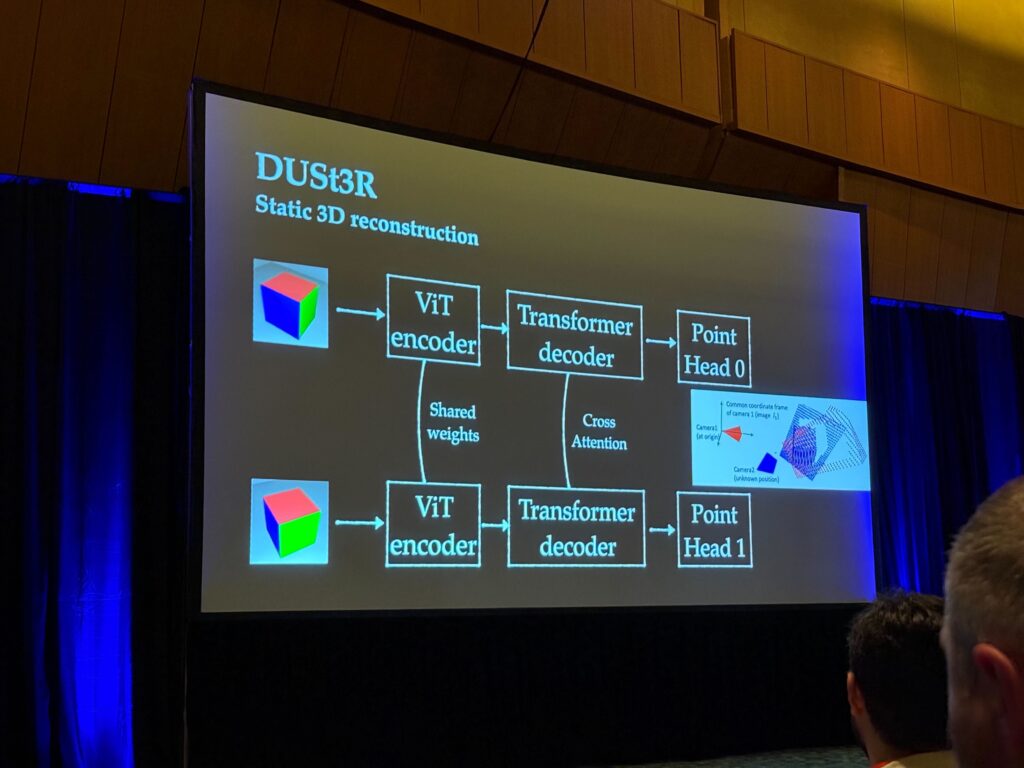
아무래도 SfM을 통해서 map을 만드는 행위는 상당히 많은 과정들이 요구되다 보니 전문가들만 할 수 있는 것이었는데 이제는 이미지 시퀀스와 모델 하나로 이것들이 모두 가능해졌다! 라는 점이 그쪽 분야 연구자들의 가슴을 흥분시키게 만든 것 같습니다.
그리고 비디오 쪽 연구들도 상당히 많은 것 같았어요. video generation, video compression 등등 영상 레벨에서는 할만큼 했다고 생각하는지 비디오 레벨에서 무언가를 하려고 하는 연구들이 대다수였던 걸로 기억합니다.
저에게 친숙한 depth estimation, segmentation과 같은 단순 perception task들은 예전처럼 연구가 활발하게 진행되는 것처럼 보이지는 않았고 이들도 이제는 비디오 레벨로 넘어가서 이미지 시퀀스에 따라 perception 결과물들의 consistency가 잘 유지되도록 하는 연구들이 나오는 것 같습니다.
학회 참관 후 느낀점
결론부터 이야기하면 마음이 무겁네요. 개인적 사정으로 연구를 1년 쉬었다곤 하지만 그럼에도 불구하고 기술의 속도가 너무나도 빠르게 성장한 것 같습니다. 그리고 이러한 기술 속도를 따라잡을 자신이 솔직히 말하면 없어요. 그냥 얘네 기술 사용하면 되는거 아닌가? 내가 저기서 뭘 할 수 있지? 라는 생각이 계속 머물러있더군요.
한가지 예시로 foundation model들이 2년전부터 다 해먹기 시작한 이후로 이제는 진짜 VLM, LLM 기반으로 멀티모달을 사용하던가 또는 vision 모달만 사용하더라도 Dinov2는 꼭 쓰라는 것을 학회장에서 완전히 체감하게 되었습니다. 포스터에서 항상 들어가는 키워드가 LLM 아니면 DINO더라구요.
이는 2년전 KCCV에서 foundation model이 이제 막 본격적으로 나오기 시작할 때 학교에 있는 연구자들은 어떻게 연구를 하면 되는가 라는 질문에 대해서 이 foundation model과 경쟁을 할 생각하지 말고 이들과 공생 관계를 통해 한발자국 더 나아가는 연구를 해야한다는 교수님들의 말씀과 비슷한 흐름이라고 생각합니다.
근데 이번 CVPR에 Oral paper로 나온 논문들을 보니, foundation model들과 공생을 하는 것은 맞아요. 근데 재밌는 점은 foundation model을 이용해서 foundation model을 만들더라구요. 예를 들어 stereo depth estimation을 위한 foundation model이 없네? 그럼 dinov2와 mono depth estimation의 foundation model인 Depth Anythingv2를 기반으로 데이터 더 늘려서 stereo 모델 만드는 거죠.
결국 많은 데이터와 GPU를 필요로하는 연구들이 oral paper나 highlighted를 받는 것을 보고 이들의 generalization 성능을 보면 그들이 그 자리에 있는 것을 부정할 수 없으나 반대로 저 방법론들을 사용하면 되는거 아닌가? 내가 저쪽 연구에서 무엇을 할 수 있지? 라는 생각이 계속 들더라구요.

아무래도 학부 때나 석사과정 때는 학회장에 가면 단순히 논문을 쓸만한 소스를 구하는 것에만 집중하다보니 무언가 마음 편하게 연구의 방법론 위주로 찾아보고, 해당 방법론의 아이디어를 제 논문에 적용할 수 있는지에만 집중했었습니다.
근데 이제 박사과정이다보니 저라는 사람의 내러티브를 어떻게 구성해야할지에 대한 고민이 자꾸만 쌓이더라구요. 주식도 내러티브가 좋으면 오르고 반대로 내러티브가 없으면 떨어지는 것처럼 마찬가지로 박사도 결국은 내러티브가 중요하다고 생각이 드는 요즘 어떤 연구 주제를 잡고 나라는 사람의 이야기를 써내려갈 수 있을지 잘 모르겠네요.
마치며
글을 써보다보니 점점 비관적인? 내용들이 작성된 것 같아서 마음이 아프네요 허허. 마음같아선 자포자기 하고 그냥 백수로 살고 싶지만 그럼에도 앞으로 꾸준히 나아가는게 중요하니깐요.
곰곰이 생각해보면 저는 그동안에 단순히 depth estimation과 같은 비교적 간단한 perception을 위주로 했으며, domain adaptation과 generalization 쪽 분야에 많은 관심을 가지고 그쪽 연구들을 살펴보거나 그랬던 것 같습니다.
그러다보니 더더욱 foundation model의 등장이 너무나도 뼈아프게 느껴졌어요. 그냥 foundation model을 쓰면 segmentation이든 depth estimation이든 그럴 듯하게 다 잘되는 것처럼 보이고, 이들의 generalization performance는 웬만한 모델로는 비빌 수 없었으니깐요.
그렇다고 제가 foundation model을 만들 수는 현실적으로 없다고 생각이 들어버리니 최근 연구 동향을 보면서 더더욱 무기력하게 느꼈던 것 같습니다.
최근에는 교수님의 조언을 받아 navigation 쪽으로 연구 관심사를 확장하고 있는데 그쪽 분야도 제가 아직 자세히 알지는 못하지만 결국 VLA의 압도적인 generalization 성능에 학계에서는 고민이 이만저만 아닌 것처럼 보였습니다. (제가 잘 못 안 걸 수도 있어요ㅎㅎ..)
그러다보니 문득 든 생각이 그럼 특정 문제를 잘 푸는 specialist 모델을 만들어야하나?라는 생각이 들더군요. 즉, generalization이 잘 안되어서 그거 해결하려고 learning 기법을 연구하고 그랬었는데 결국 데이터 많이 넣고 스케일 키우면 다 끝이다는 식으로 연구가 흘러가니깐요.
그쪽에서 제가 할 게 없다면 이러한 foundation model들이 해결하지 못하는 특정 상황들을 잘 해결할 수 있는 연구를 하는 것이 꾸준히 연구할 수 있는 방향이 아닌가라는 생각이 드는 요즘입니다.
물론 어떤 특정 상황과 문제를 풀 것인지, 그리고 이 상황에서 foundation model들이 잘 동작하지 않는 것이 맞는지 등은 아직 잘 모릅니다. 천천히 이들을 찾아가는 과정을 밟아야하지 않을까 싶어요.
아무쪼록 저를 포함해서 연구실 사람들 모두 상당히 빠르게 성장하고 발전하는 연구 흐름에서 흔들리지 않고 자신만의 연구를 잘 해나가면 좋겠습니다.
그리고 CVPR에 참석할 수 있는 기회를 주신 교수님께 다시 한번 감사드립니다.