오늘 소개드릴 논문은 multimodal summarization 논문입니다. 논문이 말하길 기존 연구의 경우 멀티모달의 동시성있는 정보를 잘 활용하지 못했고, 데이터 내제적인(본질적인) 정보의 활용이 부족했다고 합니다. 본 논문은 이러한 기존 한계를 극복하기 위해 transformer-based의 멀티모달 입력을 잘 attention하고 aligne 할 수 있는 방법으로 Align and Attend Multimodal Summarization(A2Summ)을 제시했는데요, 그럼 리뷰를 시작하겠습니다.
소개
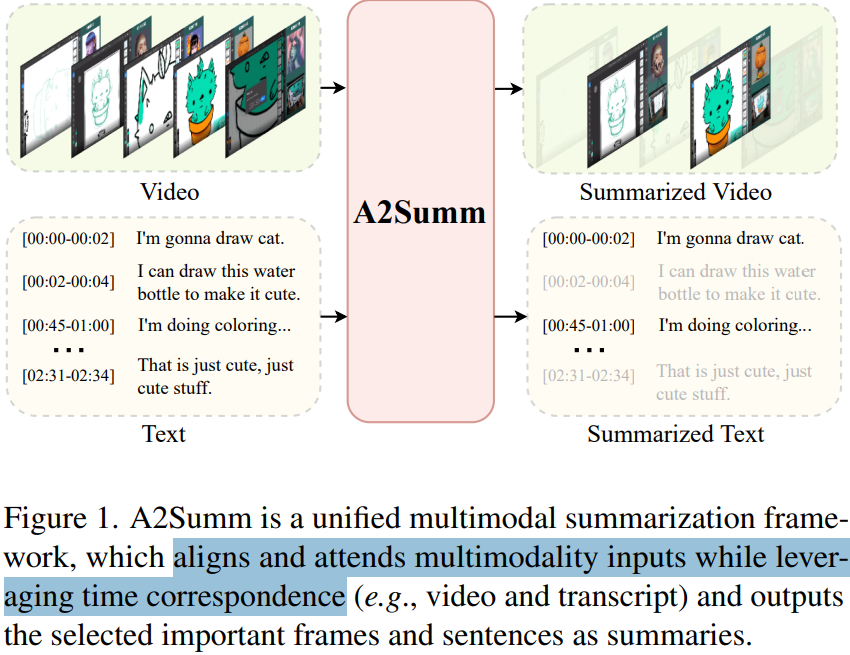
논문이 제시한 구조인 A2Summ의 입출력 구조는 Figure 1과 같습니다. 시간순으로 맵핑된 멀티모달 정보(영상, 텍스트)를 입력받고, 멀티모달의 동시적 이점과 맥락을 잘 활용해 중요한 시점의 프레임과 스크립트를 출력하는 것입니다. 구조적으로는 단순하고 특별할게 없다고 느껴질 수 있습니다. 그렇지만 기존 multi modal summarization 연구는 main modality summary만 생성했다고 했습니다. 즉, 비디오 요약 측면에서 텍스트를 활용하여 비디오(프레임)기준의 요약을 생성하거나, 텍스트 기준의 요약 생성에 있어 영상을 활용하는 것이 일반적이였습니다. 그러나 제안 방법은 Multimodal Summarization with multimodal output (MSMO) 연구라는 이점이 있습니다. Figure 1에서 알 수 있듯이 비디오와 텍스트에 대해 별도로 요약을 생성할 수 있는 것을 확인할 수 있습니다.
A2Summ에 따르면 최근에는 MSMO 구조가 몇몇 발표되고 있다고 합니다. 그러나 기존 연구는 sequence modeling(RNN등 선형 연산 구조)에 attention 연산을 더한 구조로 모달리티 간의 정보를 잘 활용하지 못했다고 합니다. 이를 극복하기 위해 A2Summ은 transformer 기반의 모델을 개발했습니다. 특히 동시성 있는 모달리티 데이터 간의 정보 융합을 높이기 위해 alignment-guided self-attention module 구조를 제시했으며, 비디오 내부적(intrinsic, 본질적) 정보의 강화하고 비디오 간 구별력을 높이기 위해 dual contrastive losses를 학습에 도입했습니다.
지금까지 논문이 제안한 A2Summ에 기존연구대비 이점을 간단하게 소개했는데요, 해당 구조 외에도 긴 멀티모달 비디오의 요약 테스크를 위한 livestream(생방송) video datasets을 구축하여 공개했습니다.논문이 말하길 livestream 영상의 중요도가 높아지는 반면 해당 도메인에 최적화된 데이터셋이 공개되지 않았으며, short videoes로 구성된 비디오 요약 데이터셋만 공개되고 있는 점을 문제로 하였습니다. 따라서 기존 영상보다 길고(몇 분이아닌 몇시간), 맥락적 변화가 느린 livestream 도메인을 위한 데이터셋인 Behance LiveStream Summarization(BLiSS)를 구축하여 공개했습니다.
정리하면 논문은 A2Summ이라는 구조와 BLiSS 데이터셋을 공개했습니다. A2Summ을 통해 기존에 MIMO 연구에서 입력 데이터에 대해 시간적 동시성을 충분히 활용하지 못한 점을 개선하여 다양한 벤치마크(TVSum, SumMe, Daily Mail, CNN)에서 SOTA를 달성했으며, livestream 도메인을 위한 데이터셋을 구축했다는 점에 의미가 있습니다.
A2Summ
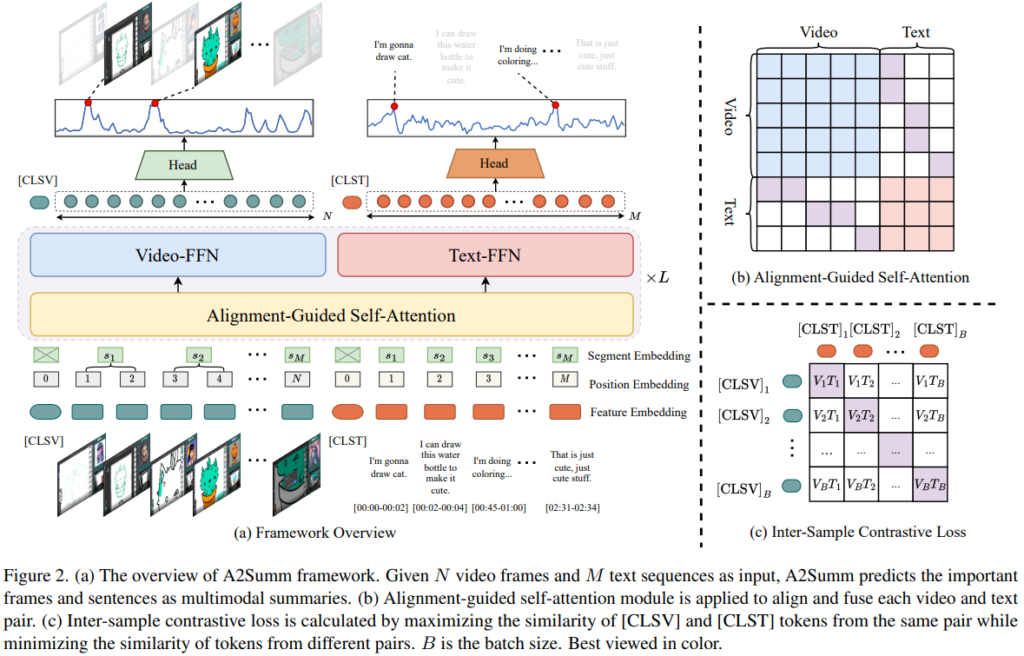
A2Summ에 대해 알아보기 위해 프레임워크 설명해보겠습니다. Figure2의 (a)가 A2Summ의 프레임워크 도식입니다. 해당 프레임워크의 입력은 2개의 모달리티로, N개의 프레임과 M개의 sentense 입력임을 확인할 수 있습니다. 가장 먼저 입력에 대한 임베딩 방법을 소개하겠습니다.
먼저, 입력 임베딩은 사전학습된 feature extraction model(GoogleNet, RoBERTa)가 활용되었습니다. 사전학습 모델로 임베딩된 특징값들은 FC-layer를 거쳐 C-차원 공간에 투영되며 Figure2(a)의 Feature Embeding에 해당합니다. 또한 BERT의 구조에 따라 position embedding을 함께 사용했으며, 서로다른 모달리티의 동시에 발생한 정보에 대해 효과적인 융합을 위해(즉, 멀티모달리티 데이터의 융합을 위해) segment embedding을 새롭게 도입했습니다. segment embedding는 timestep 기준으로 생성했습니다. 일반적으로 특정 sentense는 1개 이상의 프레임에 해당하기 때문에(M<=N), 프레임의 경우 중복될 경우 동일한 segment embedding을 공유했습니다.(예를 들어 1번, 2번 프레임의 segment embeding은 s_2로 같음) 이렇게 두가지 임베딩을 모두 더해서 최종적인 input embeding의 shape은 (M+N)*C 입니다. (C는 특징의 차원)
다음으로 멀티모달을 잘 고려한 요약 생성을 위해 입력에 alignment와 attention을 잘 수행하는 방법을 소개하겠습니다. 이를 위해서 Alignment-Guided Self-Attention기법이 제안되었습니다. 본 논문은 멀티모달리티 간의 정보 융합을 위해 트렌스포머 구조를 도입했습니다. 그러나 비디오 요약 테스크의 특성에 따라 입력이 주제와 무관한 영상이 많이 포함된 untrimmed 상태라는 특징이 있어, global self-attention을 반복 수행하는 트렌스포머 구조를 바로 도입하는데 어려움이 있었습니다. 이러한 한계를 개선하기 위해 self-attention 구조의 일부를 수정한 것이 해당 기법입니다. 간단하게 말하면, attention 연산에 Figure2(b)와 같은 마스크를 도입한 것입니다. 이는 같은 모달리티 내에서는 서로 모든 정보를 확인할 수 있도록 하고, 다른 모달리티(video, text)간에 연산에서는 동일한 segment embedning을 갖는경우 만 attention 연산을 할 수 있도록 하는 가이딩 마스크로, 그림의 색칠된 영역(파란색, 보라색, 주황색)만 1로 채워진 마스크 입니다. 이러한 마스크를 아래의 수식(2)에서 붉은 영역에 곱한 상태로 self-attention 연산을 수행하게 되어 noise가 될 수 있는 멀티모달 정보를 융합에 반영하지 않도록 안전성을 개선했습니다.
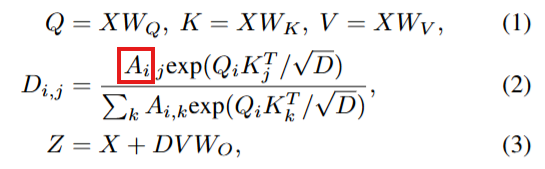
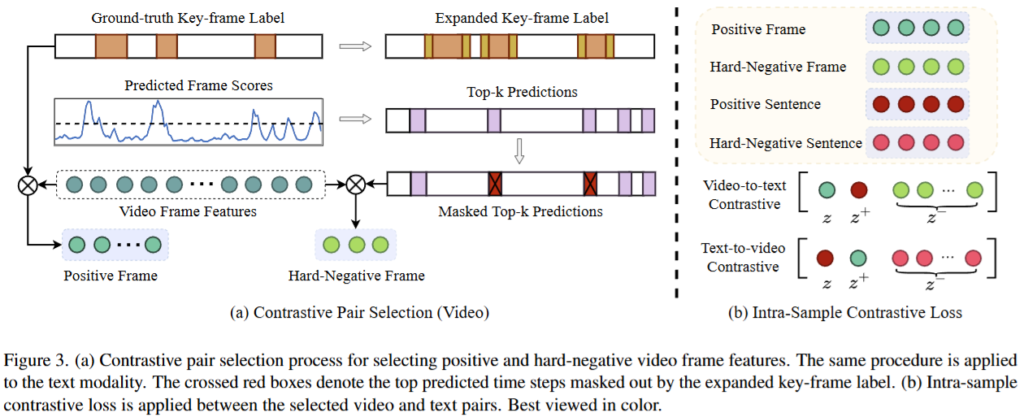
마지막으로, 컨텐츠의 내재적 정보를 잘 반영한 표현을 학습하기 위한 학습 목적함수를 추가적으로 설계하였습니다. 목적함수는 classification loss와 2 type의 contrastive loss(inter-sample contrastive loss와 intra-sample contrastive loss)의 결합으로 구성됩니다. classification loss는 t시점의 입력 프레임이 요약에 포함될지 여부를 분류하기 위한 기본적인 목적함수입니다. 본 논문의 제안한 설계는 그 다음인 dual contrastive loss에 해당합니다. 먼저 특정 비디오 샘플을 다른 비디오 샘플과 비교하여 구별력 있도록 네트워크 설계를 위한 목적함수인 Inter-sample contrastive loss는 Figure2(c)와 아래의 수식6을 참고하면 이해할 수 있습니다. 배치B내에서 j번째 비디오의 positive(z+)로 유사도가 높은 j번째 텍스트를, negative(z-)로는 pair가 아닌 feature로 하여 contrastive learning을 수행했습니다.
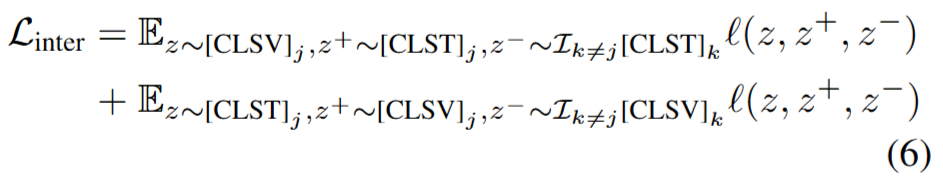
한편, 비디오의 내재적 정보의 응집성을 높이는 표현 추출을 위한 네트워크 설계를 위해서는 Intra-sample contrastive loss가 도입되었습니다. 이는 하나의 비디오에서 hard negative 시점과 positive 시점을 찾아 contrastive loss를 도입하는 방법입니다. positive pair는 GT를 통해 구성했으며, negative pair의 경우 아래의 Figure3(a)에서 확인할 수 있듯이 Predicted Frame Scores를 기준으로 중요도가 높다고 예측된 프레임 중, GT와 곂치지 않는 영역을 사용했습니다.
BLiSS Datasets
본 연구에서는 628개의 livestream 비디오를 대본과 메타데이터와 함께 수집했으며, 각 비디오를 5분 단위로 나누어 사람이 key sentence를 선택하고, text 요약을 하여 학습데이터로 가공을 진행했습니다.
해당 데이터셋은 기존의 SumMe, TVSum, Daily Mail, CNN보다 크다는 장점을 갖는다고 합니다. 정확하게는 13,303개의 데이터 샘플로 구성되며 총 1,109 시간의 비디오를 포함한다고 합니다. 비교군: TVSum (3.5 hours), Daily Mail (44.2 hours). 또한 텍스트 도메인에서도 5.4M의 스케일로 비교군 대비 크다는 특징을 지녔습니다. 비교군: Daily Mail(1.3M), CNN(0.2M).
실험
실험은 video summarization dsatasets(SumMe, TVSum)과 multimodal summarization datasets(Daily Mail, CNN), 직접 구축한 BLiSS dataset에 대해 수행되었습니다.
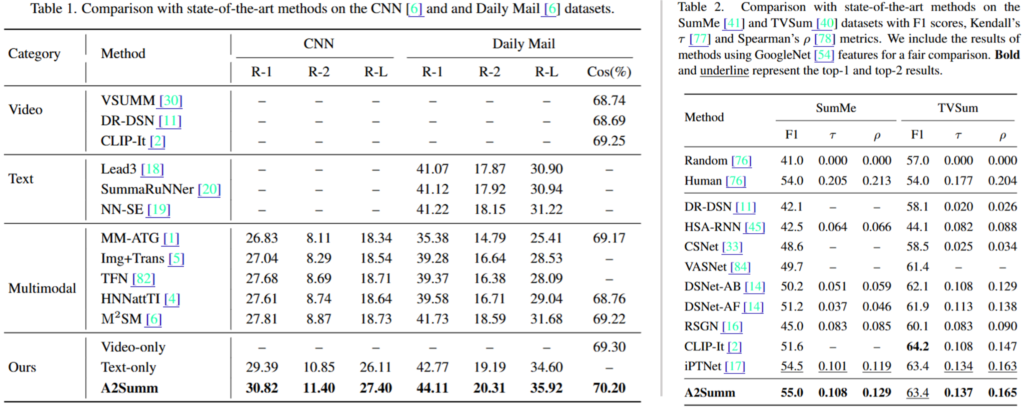
먼저 Table1은 multimodal summarization의 수행 결과로 text summarization에서 주로 사용되는 ROUGE(Recall-Oriented Understudy for Gisting Evaluation) score: ROUGE-1(R-1), ROUGE-2(R-2),ROUGE-L (R-L) 로 평가되었습니다. (정답과 얼마나 overlap 하는지 평가하는 지표) 또한 맥락적으로 요약이 잘 되었는지 평가하기 위해 요약된 비디오 이미지와 정답 이미지의 cosine image similarity를 측정하는 기존 방법을 활용하여 추가적 성능평가도 진행했습니다. 그 결과 제안한 A2Summ이 기존 방법 대비 우수함을 확인할 수 있었습니다. 또한, Table 2의 video summarization 결과는 기존 평가방식에 따라 F1, Kendall, Spearman score로 평가되었는데, 제안한 방법이 대부분 기존 방법론 대비 우수함을 통해 multimodal 요약 뿐 만 아니라 비디오 요약에도 효과적임을 확인할 수 있었습니다.
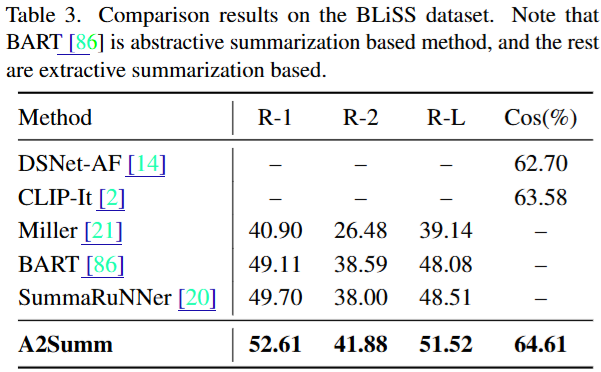
아래의 Table3은 기존 데이터셋보다 길이가 길고 중복되는 프레임이 많은 livestream video에 대한 요약 성능을 검증하기 위해 BLiSS 데이터로 평가를 진행한 것입니다. 실험 결과 제안한 방법이 기존의 video summarization(DSNet-AF, CLIP-It)와 text summarization(Miller, BART, SummaRuNNer)와 같은 특화된 네트워크 대비 전반적으로 높은 성능을 보임을 통해 멀티 모달 정보를 잘 활용하여 좋은 요약을 만들었음을 확인할 수 있었습니다.
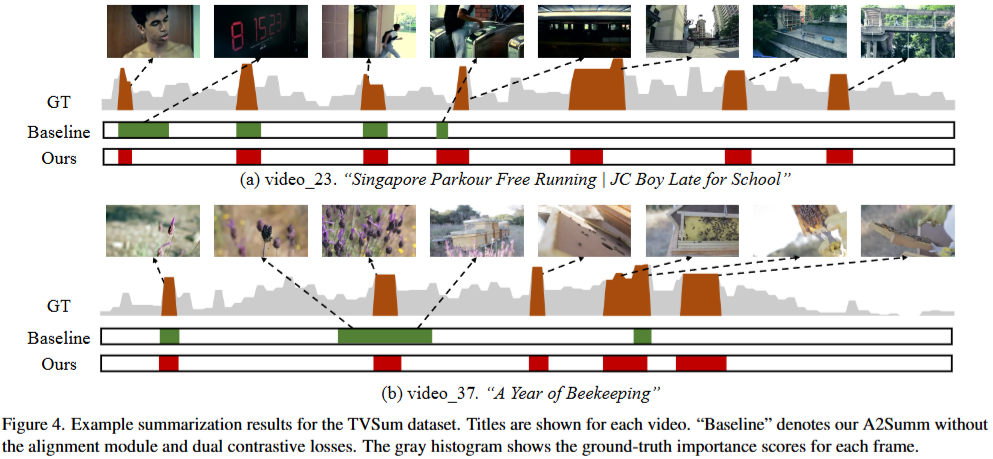
마지막 정성적 실험 결과로 리뷰를 마치겠습니다. Figure4에서 볼 수 있듯이 제안하는 방법이 중복되는 영역 없이, 모든 중요 정보를 잘 요약해냄을 볼 수 있었는데요, 비디오의 내제적 정보와 noise를 줄인채로 attention을 수행하는 A2Summ 구조의 이점이 잘 드러나는 결과입니다. 이상으로 리뷰를 마치겠습니다. 감사합니다.
안녕하세요 황유진 연구원님.
생소한 분야지만 덕분에 흥미롭게 읽었습니다!
질문을 하나 드리자면 여러 frame과 대응되는 text의 경우 inter contrastive loss가 어떻게 수행되는지 궁금합니다.
그리고 intra 대조학습의 경우 positive sample은 실제 GT 키프레임/텍스트와 일치하는 영역에 대한 것인가요?
안녕하세요 질문 감사드립니다.
우선 inter contrastive loss의 경우 동일한 내용이 아닌 영역을 마스킹하고 self-attention을 수행하는 방식으로 진행됩니다. 마스킹의 단위가 프레임 단위가 아닌, sequence 별로 나누어져 있길래 여러 frame과 대응되는 text의 경우에도 문제 없이 수행할 수 있습니다.
다음 질문의 경우 이해하신 대로 positive와 negative 쌍을 생성할 때 GT를 사용합니다.
감사합니다.
좋은 리뷰 감사합니다.
비디오 데이터의 처리와 관련해서 궁금한 점이 있는데요,
비디오 데이터는 구체적으로 어떻게 처리되어 Alignment-Guided self-attention 계층으로 넘어가게 되나요? feature extractor로 Googlenet을 사용한다고 되어 있는데 이미지 데이터를 처리하는 GoogLenet으로 어떻게 temporal 정보를 가진 비디오를 처리하는지 궁금합니다. 또, GoogLeNet이 요즘에는 잘 쓰는 CNN구조가 아닌데(보통 ResNet이나 ConvNeXt계열 쓰는 것으로 알고 있습니다) GoogLeNet을 사용한 특별한 이유가 있나 궁금합니다.
안녕하세요 질문 감사드립니다.
우선 GoogLeNet이 활용되는 이유는, 해당 분야에서 실험한 데이터셋을 전처리하는 통상적인 방법에 따른것입니다. 해당 전처리된 임베딩의 경우 그 자체로 temporal 정보를 갖는것은 아니며, 제안된 구조에서 self-attention 등을 통해 temporal 정보를 포함한 임베딩을 생성한다고 이해하시면 좋을 것 같습니다.
감사합니다.
안녕하세요 유진님 좋은 리뷰 감사합니다.
segment embedding은 timestep을 기준으로 생성이 되었다고 했는데 timestep이 없는 데이터셋은 어떻게 하는지 궁금합니다.
일반적으로 Video Summarization의 태스크를 위한 데이터셋에는 timestep가 기본적으로 포함되어 있는건가요?
안녕하세요 질문 감사드립니다.
우선 timestep가 없는 데이터도 존재하는것으로 알고있습니다.
해당 방법론에서는 segment를 나누는데 있어서 해당 정보를 활용했지만, 해당 정보가 없다면 TransNet과 같은 자동 segment 생성 방법론을 활용하는 경우도 있습니다. 그러나 해당 방법에서는 이러한 접근까지 확장하지는 않았습니다.
감사합니다.