안녕하세요. 이번엔 LLM에서의 Hallucination 문제를 uncertainty score 개념을 기반으로 인지하고 이를 정량적으로 수치화한 뒤 증상을 완화하기 위한 방법론에 대해 리뷰를 가져왔습니다.
1. Introduction
LLM은 다양한 NLP 태스크에서 뛰어난 성능을 입증하면서 점점 더 많은 다운스트림 응용 분야에서 사용되고 있습니다. 하지만 기존의 LLM들은 hallucination에 취약하여, 종종 사실이 아니거나 조작된 내용을 생성하는 경향이 있습니다.
이러한 문제를 해결하기 위한 방법으로 많은 리소스를 투자하고 소비해서 팩트체킹해내는 방식도 있겠지만, 그런 절차에 의존하지 않고도 사용자 쿼리에 대한 모델의 uncertainty를 측정하여 해당 응답의 사실성을 예측하는 방식이 있습니다. 더불어 생성된 응답에 대한 모델의 confidence를 정확하게 측정할 수 있다면, 불확실성이 높은 응답은 거부함으로써 hallucination은 줄이고 결과로 나온 response에서의 사실성을 향상시킬 수 있는 연구들도 진행되었습니다.
비록 불확실성 정량화(Uncertainty Quantification, UQ)는 머신러닝 분야에서 활발히 연구되어 온 주제이지만, LLM에서의 활용은 여전히 미진한 것 같습니다. 주로 기존의 많은 UQ 연구들은 모델의 내부 상태(예를 들면 logits값)에 접근할 수 있어야 한다는 제약이 있었기 때문이죠. 하지만 GPT-4, Gemini 1.0 Pro, Claude 2.1 같이 블랙박스 LLM들은 API를 통해서만 접근이 가능하기 때문에 내부 과정을 직접 분석하기란 어렵습니다.
또 기존의 불확실성 모델링 연구는 대부분 10단어 이하의 짧은 response를 대상으로 하며, 이는 저희가 실제로 LLM을 활용할 때 더 많이 써먹는 long-form answers와는 괴리가 있습니다. 이런 차이로 장문 생성에 적합한 새로운 UQ 방법의 필요성을 저자들은 시사합니다.
본 연구에서 저자들은 다음의 연구 질문에 답하고자 합니다:
- RQ1: 기존의 UQ 방법은 장문 생성 문맥에서도 여전히 효과적인가?
- RQ2: 그렇지 않다면, 장문 응답에 대한 LLM의 불확실성을 효과적으로 정량화할 수 있는 방법은 무엇인가?
- RQ3: 불확실성 점수를 활용하여 모델 출력의 사실성을 어떻게 향상시킬 수 있는가?
그리하여 최소 100단어 이상의 장문 텍스트 생성에 대한 UQ를 탐색하며, 사실성(factuality)을 모델 성능의 핵심 지표로 설정하는 목표를 세우게 되는데요. 본 논문의 주요 contribution은 다음과 같습니다.
- 기존의 UQ 방법들이 장문 텍스트 생성에 갖는 한계를 조명하고, LUQ(Long-text Uncertainty Quantification, ‘luck’이라고 발음한다고 하네요.)이라는 새로운 UQ 방법을 제안합니다. LUQ는 문장 수준의 consistency를 기반으로 장문 텍스트 내 불확실성을 측정합니다.
- 원래의 FACTSCORE 데이터셋과, 새롭게 제안한 의료 도메인 기반의 FACTSCORE-DIS 데이터셋에서 실험을 수행한 결과, LUQ는 6개의 주요 LLM들에서 생성 응답의 사실성과 일관되게 강한 음의 correlation을 보였으며, 모든 기존 방법들을 능가했습니다.
- 또한 앙상블 모델링 방식을 제안하여, LUQ 불확실성 점수가 가장 낮은 모델의 응답을 선택하는 방식으로 응답을 조합하였고, 이로 인해 전체 사실성 점수가 최대 5% 향상되었습니다. 더불어 selective answering strategy를 구현하여 모델의 불확실성 인식을 강화했습니다.
2. Background
uncertainty와 confidence는 예측을 비롯한 output에 대한 확신 정도를 나타냅니다. 기존 연구에서는 흔히 이 uncertainty와 confidence를 반의어로 보고 서로 혼용해서 상황을 표현하기도 하지만, 본 논문은 일단 개념을 명확히 구분하고자 했습니다. uncertainty는 주어진 입력에 대해 가능한 여러 예측의 분산 정도, 즉 예측이 얼마나 다양하고 불확실한지를 나타냅니다. 그에 반해 confidence는 특정 예측(결과)에 대한 confident한 정도, 즉 한 가지 결과에 대해 얼마나 확신하는지를 의미합니다. 뭐 사실 아 다르고 어 다른 것 같긴하지만, 앞으로 나올 score 계산에 있어 개념적 차이를 두고 싶은 것으로 보입니다. 자연어 생성(NLG)이라는 태스크 관점에서는 uncertainty를 예측의 entropy 값으로 수치화하며, confidence는 생성된 응답 토큰들의 결합된 확률값으로 표현합니다. 이렇게 둘을 구분해서 정의하고 측정하면, LLM의 출력에 대해 더 객관적으로 신뢰성을 평가할 수 있고, 비사실적인(허위) 정보 생성을 줄이고자 하는 연구에서 중요한 기초가 됩니다.
entropy는 보통 다음과 같이 표현되고,
H(Y | x) = −∫p(y | x) \log(p(y | x))dy이는 주어진 입력 x에 대한 예측 관련 불확실성을 뜻한다고 합니다.
그리고 NLG 관점에서 R은 가능한 모든 response를 나타내고 r은 특정 응답인 경우라고 쳤을 때, 보통 컨셉적으로 uncertainty score는 U(x) = H(\mathbf{R} | x) = - \sum_{\mathbf{r}} p(\mathbf{r} | x) \log(p(\mathbf{r} | x))
이렇게 표현될 수 있습니다.
분류 작업에서 특정 예측 y에 대한 신뢰도는 예측된 확률을 사용하여 정량화되며, \hat{p}(Y = y | x) 로 표시됩니다. 마찬가지로 NLG 관점에서 주어진 응답 r에 대한 confidence 점수는 다음과 같이 응답에 있는 토큰의 결합 확률로 표시됩니다. C(x, \mathbf{r}) = \hat{p}(\mathbf{r} | x) = \prod_{i} \hat{p}(r_{i} | r_{<i}, x)
또 단답형 질문은 정확성 또는 정확한 일치와 같은 지표를 사용하여 간단하게 평가할 수 있지만, 이러한 기준은 실제 확률의 복잡성을 고려할 때 긴 텍스트 생성에는 종종 비현실적이라고 저자들은 주장합니다. 실용적 관점에서 불확실성 점수가 모델 성능의 신뢰할 수 있는 지표 역할을 하는 것을 목표로 하고 연구를 수행했다고 합니다. 그래서 저자들이 말하기를 사실성, 일관성 및 창의성을 포함한 여러 차원의 생성 품질을 이 불확실성 점수가 모두 포괄가능한 개념이라고 말하네요. 해당 주장의 근거는 사실 이전 related work들을 더 많이 봐야 알 수 있을 것 같습니다.. 어쨌든 본 논문은 uncertainty가 낮다면 입력쿼리 x일 때 모델이 뱉은 응답 R의 사실성이 높아지도록, 응답의 사실성이 높아지면, 모델의 confidence값이 높아지도록 목표지표에 대한 관계성을 설계하고 싶었다고 합니다.
3. LUQ(Long-text Uncertainty Quantification)
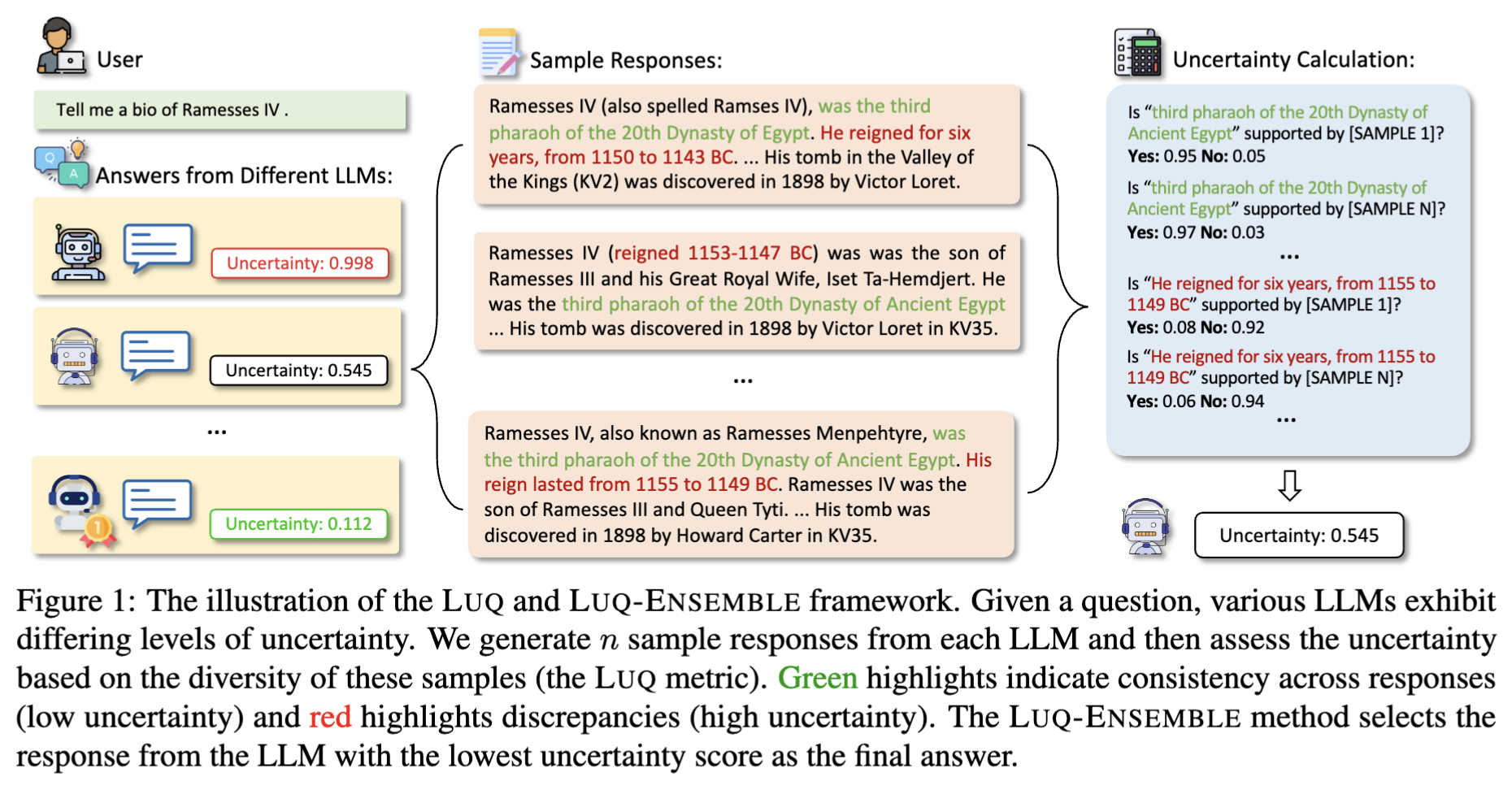
Motivation.
기본적인 가정은 주어진 질문 x에 대한 모델의 불확실성이 클수록 질문 x에 대한 응답이 더 다양해진다는 것입니다. 예를 들어, 그림 1에서 볼 수 있듯이 “이집트 20왕조의 세 번째 파라오”라는 용어는 다른 샘플 응답에서 자주 지지되며, 이는 이 정보에 대한 모델의 높은 신뢰도를 나타냅니다. 그러나 샘플들은 람세스 4세의 통치 기간에 대해 서로 다른 제안을 합니다. 이러한 불일치는 모델의 더 높은 불확실성을 보여줍니다. n개의 응답 생성이후, 짧은 텍스트에 대한 기존 연구에서의 UQ 방법론들은 일반적으로 응답 간의 pairwise 유사성을 계산합니다. 이런 유사도 점수는 응답 쌍 간의 일관성을 나타내면서 이어지는 불확실성 추정에서 중요한 역할을 해왔었는데요.
하지만 “~~에 대해 소개해주세요.”, “~~에 대해 말해주세요.” 같이 특정 질문방식으로 서술해달라는 질문에 대한 답변은 보통 텍스트가 길어지기 마련입니다. 텍스트가 길어지면 이전 방법론 적용했을 때, 모든 응답 쌍에서 예쌍치못하게 높은 유사성이 발생하는 경우도 생길 수 있다고 합니다. 그래서 저자들은 각 응답을 문장 단위로 나눠서 각 문장이 다른 여러 응답샘플들과 비교했을 때, 지지받는 문장인지(즉 다른 응답샘플에서도 많이 등장하는 문장인지) 확인하는 개념을 이전 연구에서 착안하여 좀 더 섬세한 문장 수준 유사성 계산을 통해 LUQ 라는 uncertainty score 측정 방안을 제안한 것입니다.
Notation.
LLM에 대한 사용자 쿼리 x에 대해 생성한 response 즉 응답이 r_a라고 하고,
(R = {r_1, r_2, . . . , r_n}) -> 이것의 경우는 동일한 인풋 쿼리 x를 사용했을 때 LLM으로부터 여러개의 응답샘플을 뽑은 집합을 의미합니다.
(R' = {r_a, r_1, r_2, . . . , r_n}) -> 이것의 경우는 기존 r_a 까지 집합에 추가한 것이구요.
주어진 응답 (r_i ∈ R')에 대해 첫 번째 목표는 다른 샘플에 의해 얼마나 자주 지지(또는 수반)되는지 확인하는 것입니다. 이를 위해 NLI(Natural Language Inference) 분류기를 사용하여 r_i와 각 (r' ∈ R' \ {r_i}) 간의 유사성을 평가합니다. 본 연구에서는 MultiNLI 데이터셋으로 파인튜닝된 DeBERTa-v3-large 모델을 NLI 분류기로 사용합니다. NLI 분류기의 출력에는 일반적으로 entailment(포함), neutral, contradiction(모순) 으로의 클래스 분류와 각각의 로짓 값이 포함된다고 합니다. “neutral”으로 레이블된 문장은 일반적으로 응답의 전체적인 사실성에 영향을 미치지 않으므로 “entailment(포함)” 및 “contradiction(모순)” 클래스에만 집중한다고 합니다. 응답 r 내의 각 문장 s_j에 대한 NLI 점수를 계산한 다음 이러한 점수를 평균을 취하는데, 공식적으로 r_i와 r' 사이의 유사성 점수 S(r_i, r')는 다음과 같이 정의됩니다.
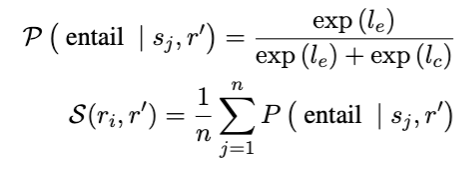
여기서 l_e와 l_c는 각각 “entailment” 및 “contradiction” 클래스의 로짓입니다. 모순되지 않는 응답은 여전히 대부분 관련성이 없을 수 있으므로 P(\text{contradict } | s_j, r') 대신 P(\text{entail } | s_j, r')을 계산하는 것을 선택했다고 합니다.
모델이 응답 r_i에 대해 갖는 confidence와 전체 uncertainty score는 다음과 같이 정의됩니다.
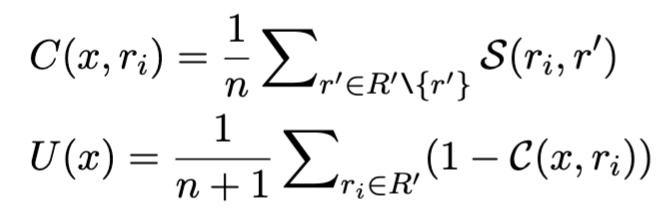
LUQ-ATOMIC의 경우는, 생성된 응답의 일관성을 더 세밀하게 확인하기 위한 기존 LUQ의 변형입니다. 주요 차이점은 ChatGPT를 사용하여 응답 r을 원자적 사실 조각 {a1, a2, …, aj}으로 먼저 분해한다는 것입니다. 그런 다음 LUQ-ATOMIC은 문장 수준 s_j 대신 atomic fact piece level a_j에서 불확실성 점수를 계산합니다.
LUQ-PAIR의 경우는, NLI classifier의 성능이 전제와 가설의 길이에 따라 제한될 수 있기 때문에, 이를 해결하기 위해 r'의 각 문장 s'_j에 대한 entailment 점수 s_j를 계산하고 최대값을 선택합니다.
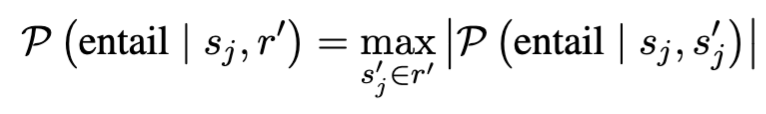
4. Experiments
Dataset.
데이터셋을 선택할 때, 세 가지 주요 기준을 고려했다고 합니다. (1) 데이터셋은 긴 형식의 QA 데이터셋이어야 한다. (2) 잘 설계되고 널리 인정받는 자동 평가 도구가 있어야 한다. (3) 질문은 명확하고 구체적이어야 하며, 객관적인 평가를 위해 명확한 답변이 있어야 한다. 결국은 이 3가지 조건을 충족시킨 데이터셋으로 생성된 텍스트의 사실성을 평가하기 위해 FACTSCORE라는 데이터셋을 사용했습니다. FACTSCORE는 낮은 오류율(2% 미만)로 자동 평가를 제공하여 수동 어노테이션 없이 다양한 LLM에 대한 확장 적용을 가능하게 하는 데이터셋입니다. FACTSCORE annotator가 수행한 신뢰성 테스트가 믿을 만 한지 보완하기 위해, 소규모로 human annotation 연구를 수행했다고 하는데요. 결과로는 FACTSCORE 평가와 인간 기준 사실성 판단 간에 0.88의 꽤나 높은 Pearson Correlation을 보여주어 사실성에 대한 신뢰할 수 있는 데이터임을 확인했다고 하네요.
그리고 원래 FACTSCORE 데이터셋(FACTSCORE-BIO)에는 해당 Wikipedia 항목과 함께 Wikidata의 500명 개인의 전기가 포함되어 있습니다. 근데 저자들은 다양한 도메인에서 UQ 방법의 적용 가능성을 평가하기 위해 질병 개체에 중점을 둔 데이터셋인 FACTSCORE-DIS도 추가로 개발 및 구성했다고 합니다.
Metric.
생성된 각 응답에 대해 FACTSCORE는 사실성 점수(FS)를 계산합니다. 처음 생성된 응답(r_a)에 대해 FACTSCORE를 적용합니다. LLM이 특정 질문에 답변을 거부할 수 있으므로 공정한 비교를 위해 페널티가 적용된 사실성 점수(PFS)와 페널티가 적용된 불확실성 점수(PUS)를 도입합니다. PFS와 PUS를 계산하기 위해 모델이 답변하지 않기로 선택한 질문에 대해 사실성 점수 0점과 불확실성 점수 1점을 할당합니다.
그런 다음 사실성 점수와 불확실성 점수 간의 피어슨 상관 계수(PCC)와 스피어만 상관 계수(SCC)를 모두 계산합니다. 이전 연구가 제안한 기준에 따라 상관 계수를 절대값을 기준으로 5가지 범주로 분류합니다. 0.9 이상은 매우 강한 상관관계를 나타내고, 0.7~0.9는 강한 상관관계, 0.5~0.7은 보통, 0.3~0.5는 약함, 0.1~0.3은 매우 약함, 0.1 미만은 무시할 수 있는 상관관계를 의미합니다.
LLMs.
실험을 위해 Arena Leaderboard(2023) 에서 상위 성능을 보이는 6개의 LLM을 선택했습니다. 접근 권한 내에서 closed-소스(블랙박스) 모델인 GPT-4 , GPT-3.5 및 Gemini 1.0 Pro 와 오픈 소스 모델인 Yi-34B-Chat (2023), Tulu-2-70B (2023) 및 Vicuna-33B (2023)를 선택했습니다.
Baselines for UQ.
- Lexical similarity(LexSim) (Fomicheva et al., 2020),
- Number of semantic sets (NumSets) (Lin et al., 2023),
- Sum of eigenvalues of the graph Laplacian (EigV) (Lin et al., 2023),
- Degree matrix (Deg) (Lin et al., 2023),
- Eccentricity(편심도) (Ecc) (Lin et al., 2023),
- SelfCheckNLI (SCN) (Manakul et al., 2023)이 있습니다.
- 추가로 비교를 위해 세 가지 화이트박스 방법인 최대 시퀀스 확률(MSP), 몬테카를로 시퀀스 엔트로피(MCSE) 및 시맨틱 엔트로피(SE) 실험했다고 합니다.
실험이 좀 많은데요. 하나씩 찬찬히 살펴보겠습니다.
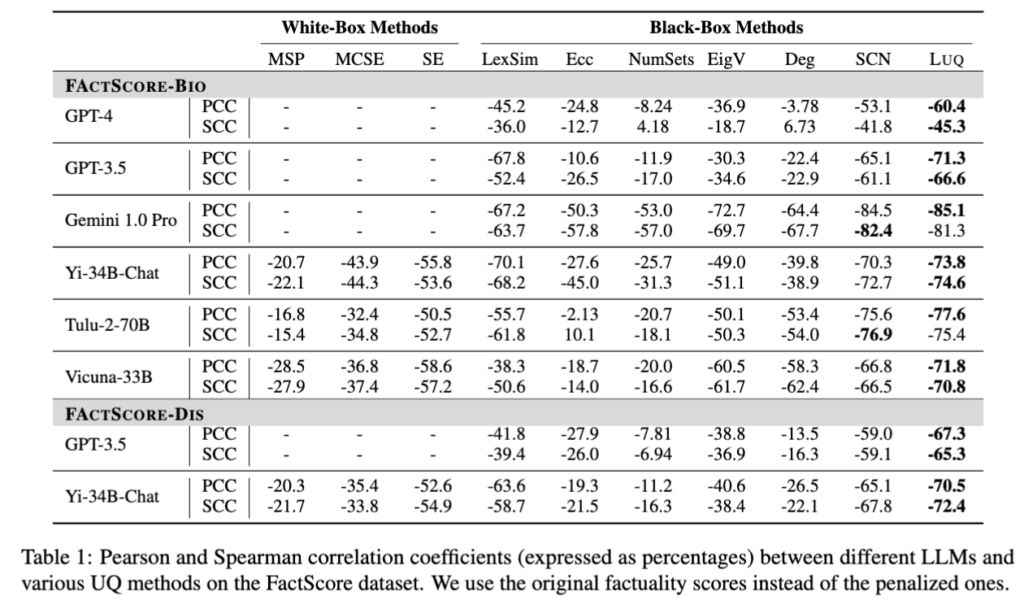
위 table1은 다양한 LLM들의 사실성(factuality)과 uncertainty 사이의 관계를 베이스라인 방법론들에 기반한 다양한 불확실성 정량화(UQ) 기법을 통해 correlation coefficient를 활용하여 평가한 결과입니다. 여기서 PCC와 SCC는 모델의 불확실성 점수와 사실성 평가 점수(팩트 점수) 간의 상관관계를 측정하는 통계 지표입니다. PCC (Pearson Correlation Coefficient)는 선형 상관 계수(피어슨 상관계수) 라고 불리며, 두 변수 간의 선형 관계 강도와 방향을 나타냅니다. +100에 가까울수록 완전한 양의 선형 관계, 0에 가까울수록 선형 관계 없음, -100에 가까울수록 완전한 음의 선형 관계를 의미한다고 보시면 될 것 같습니다. SCC (Spearman Correlation Coefficient)는 순위 상관 계수(스피어만 상관계수) 라고 불리며, 두 변수 간의 단조(monotonic) 관계를 평가합니다. 값 범위는 PCC와 같으며, 값들이 직접적인 선형 관계가 아닐 때도 순위에 따른 관계를 측정할 수 있습니다. 데이터가 비선형이거나 이상치가 있을 때 더 강건한 지표라고 합니다.
저자들이 제안한 LUQ는 GPT-3.5, Gemini 1.0 Pro, Yi-34B Chat 등 다양한 모델에서 사실성과 강한 음의 상관관계(negative correlation)를 가지는 모습을 보여줬습니다. 즉, 사실성이 낮을수록 불확실성이 높다는 것을 의미하므로, LUQ방식이 기존 불확실성 정량화 방법론들인 UQ 방법론들에 비해 효과적으로 불확실성을 표현할 수 있었음을 알 수 있고, 이는 LUQ가 실제 모델의 신뢰도(factuality)에 대해 섬세하게 반영하는 것을 시사한다고 볼 수 있습니다. SCN, Deg, EigV 등 기존 UQ 방법들은 오히려 음수가 아닌 양의 상관관계를 보이는 경우도 있어서, 사실성과 반대 방향으로 작용할 수 있음을 보였습니다.
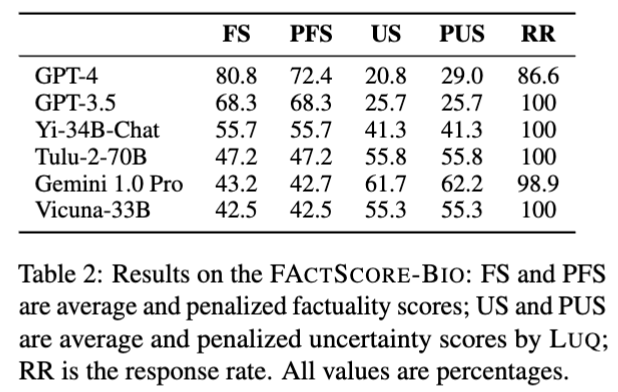
위의 Table2는 다양한 LLM의 응답 신뢰도 평가에서 LUQ 기반 불확실성 측정과 사실성 평가에 따른 결과를 집약한 것으로, LUQ 방법의 효과성과 LLM별 신뢰도 차이를 보여줍니다. notation을 남기자면, FS는 평균 factuality score (사실성 점수), PFS는 Penalized factuality score 로 응답 거부 시 0점 처리를 적용했으며, US는 평균 uncertainty score (불확실성 점수), PUS: Penalized uncertainty score로 응답 거부 시 1점 처리 적용했으며, RR은 Response rate (응답률, %)입니다. 해당 결과에서 GPT-4가 가장 높은 factuality 점수(80.8)와 높은 응답률(86.6%)을 기록하며 가장 신뢰성 높은 응답을 제공하는 모습을 보였고, GPT-3.5는 두 번째로 높은 factuality 점수(68.3)를 가지고 100% 응답률을 유지했습니다. 나머지 모델들은 상대적으로 낮은 factuality 점수와 높은 uncertainty 점수를 가졌는데, 특히 Gemini 1.0 Pro와 Vicuna-33B의 uncertainty 점수가 매우 높아 신뢰도 측면에서 좀 더 불확실한 모습을 보였습니다. 특이한 점은 GPT-4의 경우는 해당 모델들 중 가장 sota 모델이다보니 불확실성 점수가 가장 낮고, 가장 정확한 응답을 선별하여 제공하고 있다는 점이네요.
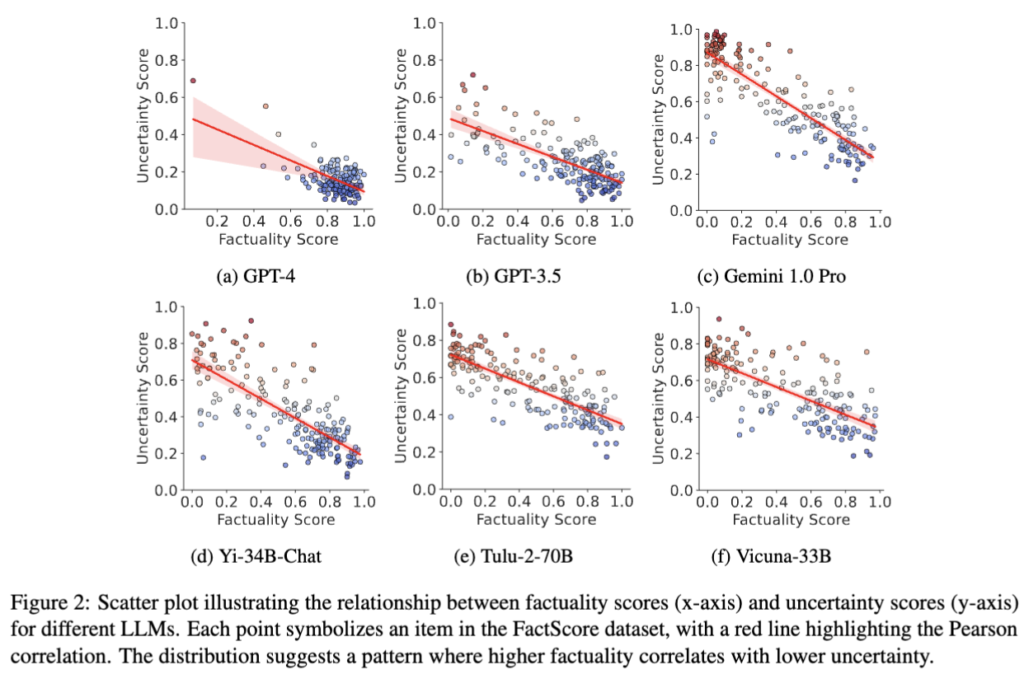
위 Figure2가 이제, Table2에서의 결과랑 조금 연관지어서 보면 의미가 있는데요. GPT-4는 응답하지 않는 경우가 많아서 불확실성이 높은 사례가 적고, (a)에서도 보이듯이 데이터 포인트가 군집화되어 있습니다. 즉 GPT-4에서는 전체적으로 사실성 스코어가 높고 불확실성 스코어가 낮은 분포를 가지며, LUQ의 효과성이 다소 덜 드러난다는 결과를 보이는 것이죠. 저자들이 말하길 GPT-4의 경우는 불확실할 것 같은 경우엔 아예 응답 자체를 회피하는 경향성을 가지고 있는 것으로 판단했다고 합니다.
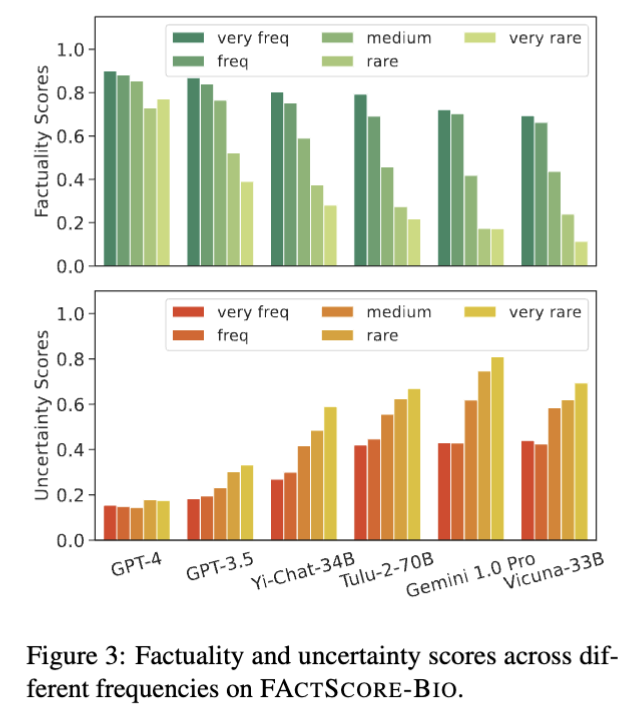
Figure 3은 entity 빈도수에 따른 사실성과 불확실성 스코어 결과입니다. Wikipedia 기반으로 엔티티의 등장 빈도(frequency)를 다음 다섯 가지로 구분했습니다. very frequent > frequent > medium > rare > very rare.
각 LLM에 대해 해당 엔티티 빈도 그룹에 대한 평균 사실성 점수(왼쪽 막대)와 평균 불확실성 점수(오른쪽 막대)를 분석한 것인데, 엔티티의 빈도수가 높을수록 사실성 점수가 증가하고 불확실성 점수는 감소했습니다. 즉, 모델은 자주 등장한 엔티티에 대해 더 정확하고 확신 있는 응답을 할 수 있었습니다. 앞서말했듯이 GPT-4는 빈도에 상관없이 상대적으로 일관된 사실성과 낮은 불확실성을 보여주며, 이는 빈도가 낮은 질문에 대해 아예 응답을 피하는 선택적 전략의 모습을 보이기에, GPT-4는 rare 질문의 약 25%, very rare 질문의 약 30%에 대해 응답하지 않음을 저자들은 언급합니다.
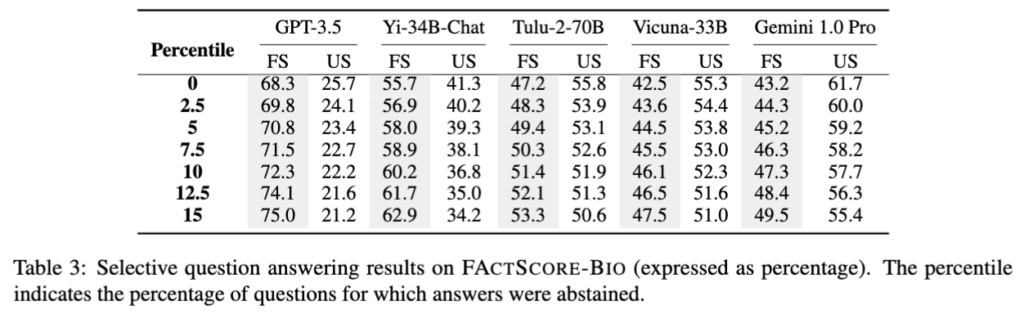
Table 3는 FACTSCORE-BIO 데이터셋에서 LLM들의 선택적 질문 응답 성능을 보여줍니다. Percentile은 모델이 답변을 거부한 질문 비율(%)을 나타내는데, 예를 들어, 0은 전체 질문에 답변, 15은 약 15% 질문에서 답변을 거부하는 것을 의미합니다. FS는 factuality score (정확도 점수), US는 uncertainty score (불확실성 점수)를 의미하고, 전체적으로, 각 모델은 높은 불확실성(US)이 감지되는 경우 답변을 거부함으로써 factuality score를 개선합니다. 예를 들어 GPT-3.5는 0% (모든 질문 응답)에서 68.3%였던 FS가 15%까지 답변을 거부할 때 75.0%까지 상승했습니다. 즉 불확실한 답변을 피할수록 모델의 답변 신뢰도가 올라가는 경향성을 보였습니다.
정리하자면 선택적 질문 응답 전략(멀티모델 불확실도 측정 후 불확실 답변 거부)은 LLM의 factuality 향상에 효과적임을 보인 것으로 보시면 되겠습니다.
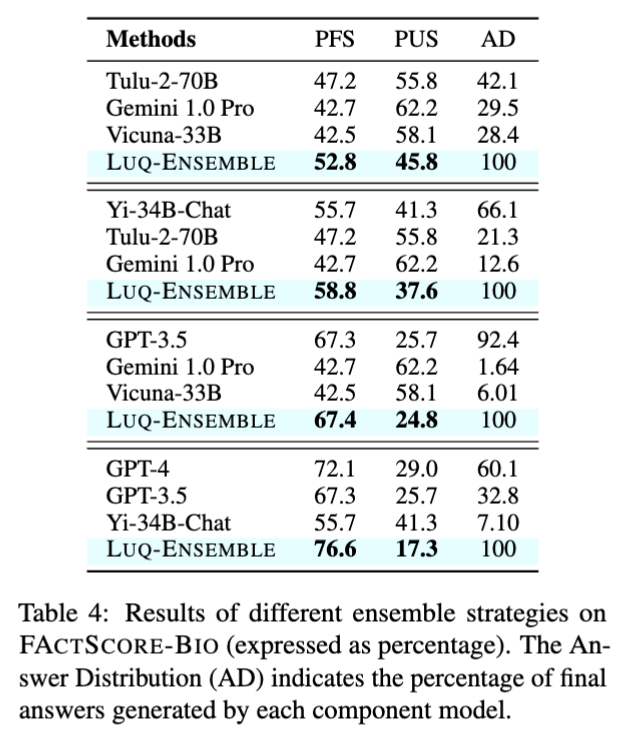
마지막 Table 4는 앙상블 전략으로 접근한 결과입니다. 용어를 좀 정리하자면,
- PFS (Penalized Factuality Score)
모델의 사실성 점수에 노-응답 거부 문제를 반영해서 계산한 점수입니다. 응답 거부 시 사실성 점수를 0으로 처리해, 실제 활용 시 신뢰도를 반영합니다. 높을수록 사실성이 높음을 의미합니다. - PUS (Penalized Uncertainty Score)
불확실성 점수에 노-응답 문제를 반영해서 계산한 점수입니다. 응답 거부 시 불확실성을 1(가장 높음)로 처리합니다. 낮을수록 불확실성이 낮음을 의미합니다. - AD (Answer Distribution)
앙상블에서 최종 선택된 답변이 각 개별 모델에서 얼마나 많이 선택되었는지 백분율로 나타낸 분포입니다. 즉 최종 답변에 기여한 각 모델의 비율(%)입니다. 예를 들어 AD가 100%인 것은 LUQ-ENSEMBLE이 모든 최종 답변을 자체 선택 기준으로 결정하는 것을 의미합니다.
각 LLM들은 같은 질문에 대해 서로 다른 응답을 생성할 수 있는데 과연 이 중에서 어느 응답을 선택해야 할까에 대한 문제가 있으니, 기존 방법에선 모든 응답을 fact-checking 해야 했지만 비용문제가 컸기때문에, 해결책으로써 각 모델의 LUQ score 가 가장 낮은 응답을 선택하는 방식으로 앙상블하는 결과(LUQ-Ensemble)를 보인 것입니다. LUQ-ENSEMBLE은 각각의 모델 조합에서 단독 모델들보다 더 높은 사실성(PFS)과 더 낮은 불확실성(PUS)을 보였는데,
먼저 Tulu-2-70B, Gemini 1.0 Pro, Vicuna-33B 조합에서 LUQ-ENSEMBLE은 PFS 52.8%, PUS 45.8%로 개별 모델보다 개선됨을 보였고, GPT-4, GPT-3.5, Yi-34B-Chat 조합에서는 PFS 76.6%, PUS 17.3%까지 성능이 향상되는 모습으로 특히 불확실성을 강력하게 줄여주는 모습을 보였습니다. 전반적으로 LUQ-ENSEMBLE은 다양한 LLM들의 응답 중 불확실성이 가장 낮은 것을 선택함으로써 출력의 사실성을 크게 향상시키고 불확실성을 줄이는 효과를 가져왔습니다.
안녕하세요. 리뷰 잘 읽었습니다.
흥미로운데, 응답 샘플이 핵심으로 보이는 이 리뷰에서 말씀해주신 내용은 동일한 문장을 LLM에 던져 나온 샘플의 집합으로 이해했습니다. LLM이 동일한 질문을 던져도 매번 다른 응답을 뱉어내니 그럴 수 있다고는 생각이 들지만, 오히려 그 샘플 내에 논문에서 걱정하는 Hallucination이 있을 수 있지 않을까 즉, 그 응답 샘플도 결국 LLM에서 나오는 것인데 믿을 수 있는지에 대해 의문입니다. 이에 대해 어떻게 생각하시는 지 궁금합니다.
안녕하세요 상인님, 리뷰 읽어주셔서 감사합니다.
말씀해주신 것처럼, 오히려 샘플링 자체가 hallucination이 있지 않은가? 에 대해서는 저도 동의합니다.
하지만 본 논문에서 제안한 LUQ 방법론은 오히려 이를 활용하는 경우라고 생각하시면 될 것 같습니다.
본 방법론의 기본 가정은 우선 “높은 불확실성 → 다양한 응답”이고, “낮은 불확실성 → 일관된 응답” 이었습니다.
즉 hallucination으로 인해 다양한 응답이 나오면 결국 LLM 자신이 높은 불확실성으로 일관된 응답을 내고 있지 못했다. 정확히 아는 내용이 아닌 것 같다. 라고 판단하는 기준으로 오히려 활용할 수 있게 됩니다.
하지만 샘플링들이 모두 일관된 답을 뱉었다해도, 일관된 모든 샘플링들 자체가 hallucination일 수도 있을텐데, 상인님은 그 점을 우려하신거라고 봅니다.
결론적으로는 제 생각으로는 LLM hallucination은 절대적으로 해결할 수는 없습니다. 다만 본 방법론에선 LUQ는 샘플들을 단순 비교하는 게 아니라, 문장 단위로 쪼갠 후 이 문장이 다른 샘플들에 의해 어떻게 지지(entailment) 또는 모순(contradiction)되는지를 판단하는 NLI 모델(DeBERTa-v3-large, MultiNLI 학습)을 활용하면서, 단순 sampling간 cos sim 말고 쪼개진 문장단위에서의 의미적인 일관성까지 교차검증을 추가하면서 최대한 sampling에서의 hallucination 영향을 최소화하고 싶었던 것으로 보입니다.
안녕하세요 재찬님, 리뷰 잘 읽었습니다.
해당 논문에서 가장 중요하게 생각든 것이 factuality 를 판단하는 기준이라고 생각합니다.
긴 문장에 대한 답변으로 여러 답변을 하더라도 모두 정답일 수 있기에 그를 판단하는 방법이 존재했었는지 궁금합니다.
리뷰를 읽는 중간 답변을 거부한 비율이 높은거가 최종 결과에 영향을 줄 수 있을거라 생각했는데, 답변 거부시 최대 패널티를 줌으로써 그러한 영향을 아예 배제했음에도 PFS PUS 점수가 개선된 것이 논문의 가설과 LUQ의 방법이 효과적이라는 것은 맞다 생각합니다. 감사합니다.
안녕하세요 인택님, 리뷰 읽어주셔서 감사합니다.
마지막은 뭔가 질문할 듯하면서 꺾어주셨네요 ㅋㅋ
앞 질문에 대한 답변을 드리자면, 우선 factuality를 판단하는 기준으로는 FACTSCORE[EMNLP 23’] 라는 이전의 방법론에서 제안한 평가방식을 그대로 차용합니다. 해당 FACTSCORE 벤치마크의 판단이 신뢰성이 있는가 싶어서 리뷰에 제가 적었듯이 저자들도 human annotator 써서 인간 기준의 사실성 판단과 비교해봤는데 그 둘 간의 0.88 피어슨 상관계수를 보였다면서 신뢰할 수 있다 판단하여 그대로 쓴 것 같네요.
하이요. 리뷰 읽고 질문 몇가지 남겨요.
본인이 하는 연구에서는 LLM을 통해 100단어 이상의 긴 문장의 text를 생성해서 사용하는 경우가 있나요? 본인의 연구주제와 관련해서 해당 논문의 어떤 내용을 참고하고 싶어서 이를 읽었는지 궁금하네요.
그리고 동일한 입력 쿼리 x를 사용했는데 LLM으로부터 여러개의 응답 샘플을 어떻게 받을 수 있나요? 프롬프트로 질문을 할 때 이에 대한 답변을 N가지의 경우로 다양하게 답변해달라고 하는건가요?? Gemini 사용했을 때 동일 질문에 대해서 3가지 정도의 다른 타입의 답변들을 선택할 수 있던걸로 기억하는데 실제로 어떻게 n개의 답변이 나오는지 모델 구조 관점에서 궁금했었거든요.
그리고 특정 질문에 답변을 거부한다는 것은 어떤 상황을 의미하나요? LLM들이 회사의 지침에 따라서 특정 질문에 대하여 답변을 할 수 없는 상황을 고려했다는건가요? 약간 딥시크한테 시진핑에 대해서 물어본다던지 그런 느낌일까요?
감사합니다.
안녕하세요 정민님, 리뷰 읽어주셔서 감사합니다.
1. 제가 하고자 하는 연구에서는, LLM 기반으로 로봇 task를 decomposition 할 때 hallu 영향 좀 줄이자. 의 관점으로 LLM uncertainty 추정을 활용하려고 하고 있습니다. 이 때 로봇에게 요구하는 작업이 길어질수록 decomposed된 sub-task들도 길이가 길어질 수 있을 거라고 생각했고, 더구나 code generation 방식으로 task planning을 진행하기 때문에 code가 길어지는 경우의 uncertainty 추정은 어떻게 해야되나.를 생각해오고 있었습니다. 그래서 text와 code간의 표현은 살짝 다를 수 있겠으나 써먹을 수 있지 않을까 싶어서 리뷰해봤습니다. (결론적으론.. faculty를 판단하는 방식이 사전구성된 엄청 긴 text데이터 벤치마크로 평가하는 것 같길래 활용하긴 쉽지 않을 것 같습니다. 그래도 긴 문장을 잘게 쪼개서도 uncertainty score를 구할 순 있구나의 컨셉만 일단 흡수했습니다.)
2. 제가 주로 사용하기론(+논문 내용으로도) 단순히 API 사용할 때 n번 반복해서 쿼리를 던지고 응답을 받는 방식으로 여러 샘플을 구성합니다. . . . 대부분의 LLM 응답 샘플링해서 어쩌구저쩌구로 uncertainty score 만들어보겠다 하는 방식은 다 n번 반복해서 쿼리하는 것 같습니다.. 개인적으론 비효율적이라고 생각해서 샘플링 기반을 최대한 덜 쓰고 다른 방식으로 현재는 접근해보려고 하고 있습니다.
3. 맞습니다. 딥시크-시진핑 언급 같은 회사 지침 외에도, LLM 스스로가 내부 정보에 대한 불확실성이 커서 모르겠다~, 답변을 제공할 수 없다~ 처럼 모르쇠 하는 경우를 모두 포함하여 예외처리를 하려했다 정도로 이해해주시면 될 것 같습니다.
안녕하세요 재찬님 리뷰 감사합니다.
Figure 3의 entity 라는게 ‘특정 내용’이라고 생각해도 될까요?? 또 엔티티의 등장 빈도가 낮을수록 답을 안 한다고 하는 내용이 LLM이 아무 할 말이 없어서 답을 안 하는 것인가요? 아니면 틀릴바에는 그냥 모른다고 말을 해버린다 인가요??
안녕하세요 영규님, 리뷰 읽어주셔서 감사합니다.
맞습니다. 의미적으로 구분 가능한 명확한 대상 이란 뜻으로 사용되었습니다.
두번째는 “할 말 없어서 암말 안한다”와 “틀릴바엔 모른다” 모두 해당될 수 있을 것 같습니다.
결론적으론 entity 자체가 많이 등장하면 LLM이 확신을 갖고 말하는 경향이 있고, entity 자체가 적게 등장하면 자신없어서 응답회피하는 경우가 많아지는 것으로 이해하시면 될 것 같습니다.