
6년 전에 처음으로 나왔지만, 이번 video retrieval task 를 하며 자세히 읽게 되어 리뷰를 하게 되었습니다. 이전이나 현재까지도 주로 Convolution Network, input에 움직이는 방향이 2D인 (w x h) kernel 을 사용해 연산하는 2D ConvNets을 사용하였습니다. 그러나 본 논문에서는 움직이는 방향이 3D인 (w x h x d) kernel을 사용한 3D ConvNets을 제안하였으며 제안될 당시에 SOTA를 달성하였습니다. 논문에서 제안하는 3D ConvNets에 대한 내용을 자세하게 설명해드리겠습니다.
1. Learning Features with 3D ConvNets

1.1. 3D convolution and pooling
위에서도 잠깐 언급했지만 사실 3D ConvNets의 아이디어는 간단합니다. Convolution 연산에서 kernel이 움직이는 방향을 1-dimension 추가해 주어서 temporal 한 정보를 얻을 수 있게 한 것이 3D ConvNets의 주된 아이디어 입니다. 주로 2D ConvNets 에서는 여러 channel의 input으로 Fig 2.(b) 와 같이 kernel도 input의 channel 에 맞게 설정하여 convolution 연산을 하게 됩니다. 그러나 Fig 2.(c)에서 3D ConvNets에는 kernel의 channel이 input의 channel 보다 같거나 작게 설정되어 temporal 하게도 연산하는 것을 확인할 수 있습니다. 즉, kernel은 3x3x3 크기와 같은 크기를 지니게 됩니다.
사실 이해를 돕기 위해 방금은 kernel의 channel이 2D ConvNets과 3D ConvNets의 차이라고 설명을 들었는데 사실을 channel이 아닌 새로운 개념이 들어가게 됩니다. Kernel에 depth 라는 개념이 추가되게 됩니다. Kernel의 크기는 depth x k x k로 나타낼 수 있으며 사실 일반적으로 2D ConvNets에서 kernel의 크기를 channel x k x k 로 생각해왔던 것에 depth라는 개념이 붙으면 depth x k x k 크기에 depth가 1인 channel 개의 kernel로 표현을 할 수 있게 됩니다. 이처럼 3D ConvNets에서의 kernel의 크기는 depth x k x k 로 나타낼 수 있으며 이 kernel이 channel 개 있어 (총 input의 channel) = (kernel의 depth) x (kernel의 channel) 라는 조건을 만족하게 됩니다.
저자는 이와 같은 3D kernel을 Convolution 뿐만 아니라 Pooling layer 에도 적용하여 spatiotemporal한 연산이 가능하도록 하였습니다.
1.2. Exploring kernel temporal depth

이러한 3D kernel의 temporal한 depth를 어느 정도로 정하는게 성능이 좋을까에 대한 의문에 저자는 실험을 통해 다음 결과를 보여주었습니다. 실험은 Fig 3. 과 같이 8개의 3D Convolution layer에 5개의 3D Pooling layer, 그리고 두개의 fc layer로 구성된 C3D network에 UCF101 데이터 셋으로 진행하였습니다.
우선적으로 모든 3D Convolution의 kernel depth가 d로 같은 상황에서 d=1,3,5,7 일 때, 실험을 진행하였고 Fig 4.에서 볼 수 있는 것 처럼 d=3일 때 가장 성능이 좋은 것을 확인하였습니다.
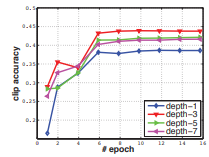
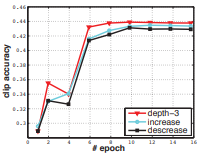
또한, kernel의 depth의 d가 첫번째부터 다섯번째 Convolution layer로 가면서 커지는 것(d=3-3-5-5-7)과 동일한 것(d=3-3-3-3-3), 그리고 작아지는 것(7-5-5-3-3)에 대해 실험을 하였을 때 Fig 5.에서 볼 수 있듯이 동일했을 때 가장 성능이 좋은 것을 확인하고 모든 Convolution layer의 kernel 크기가 3 x 3 x 3일 때 효율적이라는 것을 실험적으로 증명하였습니다.
1.3 C3D video descriptor
제안된 C3D는 주로 temporal한 정보를 가지는 video를 input으로 얻게 되며 video를 통해 학습을 하고 난 뒤, action recognition을 위해 linear SVM을 사용하였다고 합니다. SVM을 학습시키기 위하여 video 내의 여러 clip에 대해 C3D의 모든 layer를 통과 시켜 나온 output이 아닌, Fig 3.의 fc6에서 얻을 수있는 4096-dim의 descriptor를 L2 normalize 하고 여러 clip에 대해 평균을 취해 해당 영상의 descriptor로 사용하였다고 합니다.
2. Experiments
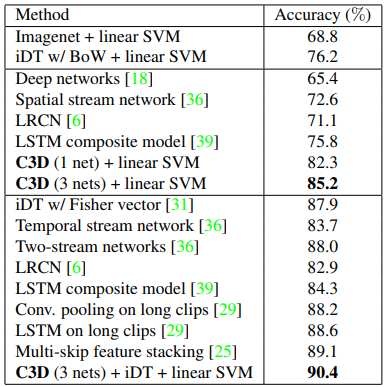
제안한 C3D에 linear SVM을 붙여 UCF101 데이터 셋에서 SOTA를 달성하게 되었습니다. Table 1.에서 보여지는 C3D (3 nets)은 각각 I380K 셋으로 학습된 C3D와 Sports-1M 셋으로 학습된 C3D, 그리고 I380K 셋으로 학습하고 Sports-1M 셋으로 finetuning한 C3D에서의 descriptor를 concat한 후 L2 normalize하여 사용하였을 때 성능 입니다. 저자는 이러한 C3D (3 nets) 과 전통적인 방식 iDT, linear SVM을 사용하였을 때 LSTM보다 좋은 성능을 내어 3D ConvNets의 효용성을 입증하게 되었습니다.
그럼 이번 에트리에서는svm 이전 descritor로 리트리벌 ㅈㅣㄴ행한건가요?
그렇습니다.