오늘 리뷰 할 논문은 Vision-Language Navigation task를 다루는 논문으로 이쪽 분야에 대해서 처음 공부하다보니 모르는게 많아 리뷰 퀄리티가 낮을 수 있다는 점 양해부탁드립니다 허허.
Intro
우선 해당 논문에서 수행하고자 하는 Task는 목적지까지 robot agent가 스스로 길을 찾아서 도달하는 것 입니다. 여기서 현재 agent는 카메라를 통해서 영상을 취득하며 동시에 목적지에 대한 지시(instruction)를 Text 문장으로 받게 됩니다. 즉 “부엌에 가서 물 좀 가져다 줘” 라는 식의 명령을 내리면 로봇이 현재 위치에서 부엌까지 길 찾기를 하는 task라고 생각하시면 됩니다.
이러한 Vision-Language Navigation(VLN)은 초기에 instruction을 매우 세밀하게 쪼개서 입력으로 사용했다고 합니다. 가령 침실을 걸어나와서, 우측으로 돈 다음, 복도를 지나 아래 층으로 내려와”와 같이 차량 네비게이션 같은 세부적인 지시를 agent에게 제공하는 방식을 사용했었다고하네요.
이러한 fine-grained VLN은 detail instruction 덕분에 physical world와 text instruction 사이를 연결(grounding)하는데 있어 훨씬 수월했지만, 지시를 내리는 사람 입장에서는 상당히 답답하고 비효율적이라고 볼 수 있습니다. 그냥 물. 하면 넵. 하고 알아서 주방 갔다오면 좋을텐데 주방까지 가는 길을 하나하나 알려줘야하니 말이죠?
따라서 최근에는 보다 편의성을 중요시 여겨 목적 중심의 지시(goal-oriented instruction)를 입력으로 하는 방법론들이 꾸준히 등장했다고 합니다. 즉 지시문의 형태가 “거실로 가서 상 위에 있는 식물에 물을 줘”와 같은 개념이죠. 이러한 방법론들은 매우 실용적인 방향이지만 길찾기를 수행하는 agent 입장에서는 대략적인 지시문을 실제 물리세상 속 객체와 환경에 grounding하는 동시에 목적지까지 효율적인 길을 찾아야하는 두가지 task를 수행해야하므로, 상당히 힘든 문제를 풀어야만 합니다.
우선 효과적으로 새로운 위치를 찾고, 이전에 판단을 수정하기 위해서 agent는 memory module을 통해 이전 경로에 대한 정보와 판단을 저장해야할 필요성이 있습니다. 허나 이전 방법론들이 주로 사용한 LSTM과 같은 메모리 기반으로 네비게이션 과정을 기록하는 방식은 시간과 공간축으로 구성된 풍부한 데이터를 효과적으로 저장하고 활용하기 어렵다고 합니다.
그리고 이 네비게이션을 잘하려면 결국 지도(map)을 잘 만들어야하는데 이 지도의 경우에는 보통 이전에 방문했던 지역들에 대한 정보 그리고 현재 기준으로 자신이 탐사할 수 있는 지역들에 대한 정보가 담겨있다고 합니다. 이러한 지도를 통해 agent는 효과적으로 긴 시간 동안의 길 찾기 계획을 세울 수 있게 되는데 쉽게 말해 현재 위치에서 목적지까지 이동할 수 있는 모든 지역 정보를 가지고 있으면 그 중에서 가장 최적의 경로가 무엇인지를 계산하여 갈 수 있다는 것을 의미합니다.
이전에 VLN 방법론들은 topological map을 생성하여 길찾기를 수행했는데, 이러한 방법론들에는 2가지 문제점이 있다고 합니다. 저자들 주장으로는 기존 방법론들은 navigiaton memory를 recurrent 구조를 통해 navigation state를 모델링하다보니 탐사를 수행하는데 있어 long-term reasoning을 잘 하지 못한다고 합니다(그림1 중간 graph-based 부분 참고)
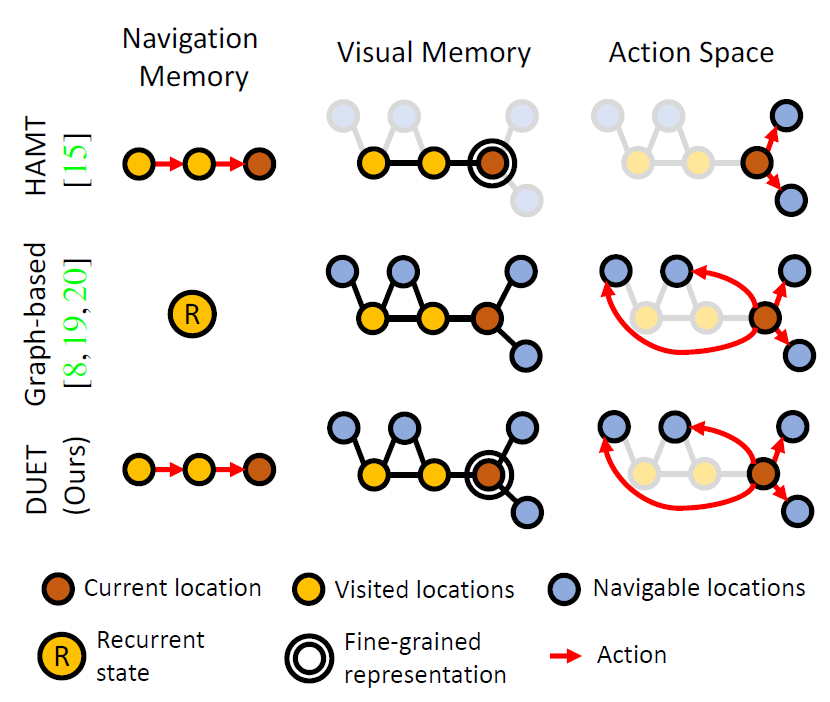
또한 2번째 문제로는 보통 topological map에서 각 노드(location)을 생성할 때 보통 image encoder를 통해 영상의 global feature꼴로 저장을 하게 되는데 이러한 압축된 feature로는 fine-grained 정보가 충분하지 않아 지시문 속 object나 장면에 대한 detail description을 grounding하기 어렵다고 합니다.
정리를 하자면 저자들은 결국 그림1의 맨 아래부분과 같이 Navigation memory를 모델링할 때는 long-term까지 잘 모델링할 수 있도록 transformer를 사용하고, Visual memory의 경우에는 기존과 유사하게 하지만 fine-grained detail까지 잘 살아있는 topological map을 생성하도록 하여 기존 방법론들의 장점들만 취해보겠다고 합니다.
우선 Topological mapping에 대해서는, 새로 관측된 지역에 대한 visual representation을 각 노드에 추가하고 업데이트하게 되고, 지도 상에서 다음으로 이동할 지역을 예측하거나 멈출 것을 판단하는 global action planning 모듈을 구현하였다고 합니다. 저자들이 계속 강조해왔던, instruction 속 detail한 text 정보들을 graph와 효과적으로 grounding하고 추론하기 위해 dual scale로 action prediction을 통합합니다. 즉 현재 위치에 대한 fine-scale representation 정보와 map 내 저장된 coarse-scale representation을 모두 활용한다고 보시면 됩니다.
또한, transformer를 통해 vision-lanugage 간의 관계성을 모델링하여 topology graph의 지식을 도입함으로써 기존에는 단순히 vision model로만 지도를 만들었던것과 달리 instruction에 친화적으로 지도의 인코딩 능력을 향상시켰다고 합니다.
Problem formulation
우선 수행하고자하는 task에 대해서 더 자세히 설명드리고자 합니다. 우선 VLN 방법론들은 모두 discrete environments를 가정하고 있으며, 이는 곧 \mathcal{G} = \{\mathcal{V}, \mathcal{E} \} 로 표현할 수 있습니다. 여기서 \mathcal{V} = \{ V_{i} \}^{K}_{i=1} 는 K개의 이동할 수 있는 node를 의미하며 \mathcal{E} 는 두 노드를 연결하는 연결선입니다.
agent는 카메라와 GPS 센서를 가지고 있다는 가정하에 입력으로 영상과 해당 영상에 대한 gps 정보를 받을 수 있으며, agent의 초기 시작 위치 노드는 이전에 한번도 와보지 못한 unseen 장소라는 가정입니다. agent의 목표는 자연어로 되어있는 지시문을 해독하여 목적 node까지 그래프를 탐사한 뒤 목적지점에 도착 후 지시문에 등장한 object를 찾아내는 것이 목적입니다.
\mathcal{W} = \{ w_{i} \}^{L}_{i=1} 는 L개의 단어로 구성된 지시문에 대한 word embedding을 나타냅니다. 각각의 time step t에서, agent는 현재 위치에 대한 파노라마 형식의 영상과 위치 좌표를 입력으로 받게 되는데 이때 파노라마 영상은 unique orientation과 n개의 image feature vector r_{i} 로 쪼갤 수 있는데 이를 \mathcal{R}_{t} = \{ r_{i} \}^{n}_{i=1} 로 표현합니다.
또한 최종 목적지에 도달하게 되면 그걸로 끝이 아니라 지시문에 해당하는 object를 찾는 것으로 마무리 된다고 했었는데 이를 위해서 bounding box를 통한 object feature \mathcal{O}_{t} = \{ o_{i} \}^{m}_{i=1} 도 정의되어야 합니다. 이때 bounding box는 GT 박스 또는 사전학습된 검출기를 사용한다고 합니다.
또한 agent는 현재 위치를 기준으로 이동 가능한 예상 지점들을 인지할 수 있게 되는데, 이는 현재 t step에서 관측된 노드의 이웃노드로 정의될 수 있으며 \mathcal{N}(V_{t} 로 표현할 수 있습니다. 이러한 \mathcal{N}(V_{t} 은 파노라마 이미지 \mathcal{R}_{t} 의 subset으로 볼 수 있습니다.
또한 모델이 어디로 움직일 것인지에 대한 action에 대하여 possible local action space \mathcal{A}_{t} 는 크게 2가지 현재 노드에서 이웃노드로 움직일 것인지 (즉 V_{i} \in \mathcal{N}(V_{t}) ) 또는 target 위치 ( V_{t} )에서 멈출 것인지로 나뉘어져 있습니다. 만약 agent가 target location에서 멈추기로 결정했다면 그 후에 agent는 지시문에 대응되는 객체를 찾는 과정을 수행하게 됩니다.
즉 지금까지 과정을 정리해보면 VLN에서 agent는 주어진 시각적 정보와 지시문을 통해 탐사를 수행하며 탐사를 마쳤다면 지시문과 현재 영상 정보를 grounding하여 정확한 객체를 찾는 것까지 수행해야만 합니다.
하지만 현존하는 VLN 방법론들은 action 관점에서 local action만을 의존하고 있기 때문에 long-range action planning을 간과하는 경우가 흔하며, fine-grained grounding역시 미흡하다고 저자는 주장합니다. 더 나아가 저자들은 자신들이 제안하는 dual scale representation과 global action planning을 통해 이러한 문제점들을 효과적으로 해결 할 수 있다고 주장합니다.
Method
일단 저자들이 하고자 하는 방법론의 대략적인 전체 프레임 워크는 아래 그림 2와 같습니다.
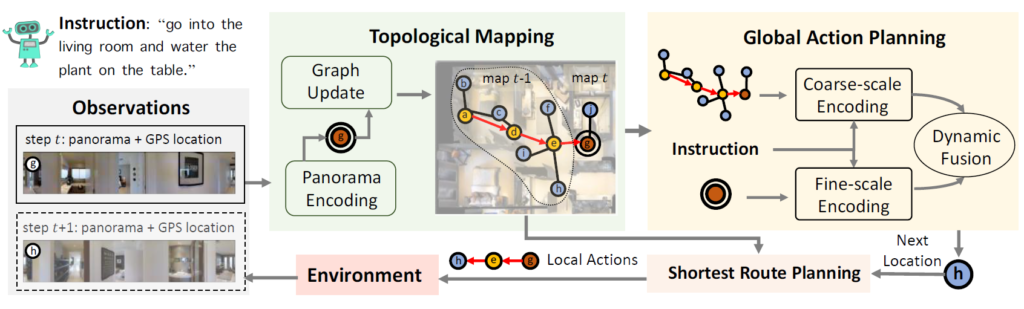
즉 topological mapping과 global action planning이 가장 중요한 step 2가지다라고 일단 이해하시고 이들이 각각 어떻게 수행되는지에 대해서 아래 서술하도록 하겠습니다.
Topological mapping
우선 환경 그래프 \mathcal{G} 는 초기에 agent한테 전혀 정보가 제공되지 않습니다. 즉 agent는 자신이 직접 길을 탐사하면서 점진적으로 자신만의 환경 그래프를 구축해야만 합니다.
우선 아까 그래프는 노드와 엣지 \mathcal{V}, \mathcal{E} 로 구성되어있다고 말씀드렸습니다. 이때 노드는 3가지 type으로 구분을 지을 수 있는데, 그림1에서 legend 살펴보시는 것과 같이 노란색은 방문했던 노드를, 파란색은 이동 가능한 노드, 갈색은 현재 노드를 의미합니다.
agent는 현재까지 방문했던 노드와 현재 노드에 대한 파노라마 영상을 언제든지 접근할 수 있으며, 이동 가능한 노드(파란색 노드)는 아직 탐사하지 않은 노드이기 때문에 그 위치에서 촬영한 파노라마 영상은 없지만 현재 노드에서 그 이동 가능한 노드에 대한 시각적 정보가 부분적으로 존재할 가능성이 높습니다.
각각의 t 단계에 도달하게 되면, topological map을 update를 해주어야하는데, 현재 t 단계에 대한 노드 V_{t} 와 아직 방문하지 않은 현재 기준 이웃 노드들 \mathcal{N}(V_{t} 을 이전 노드 \mathcal{V}_{t-1} 에 추가해주고 엣지를 이어주는 과정을 거치게 됩니다. 말로 하면 좀 복잡할 수 있으니 아래 그림3을 참고하면 좋을 듯 하네요.
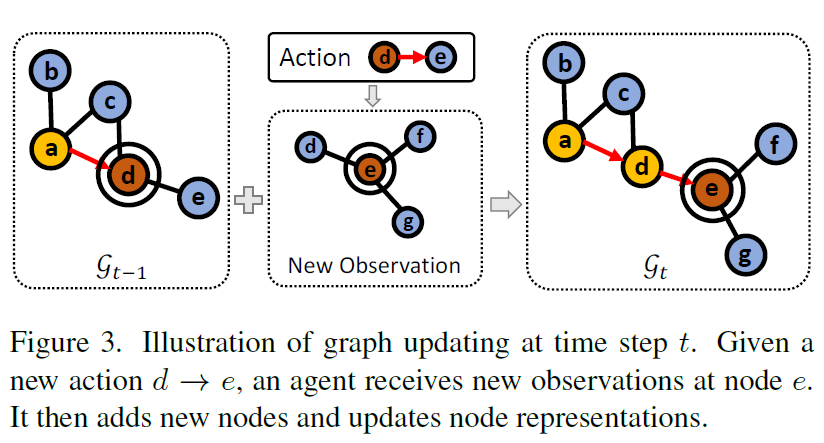
Visual representation nodes
Topological map을 업데이트하기 위해 새로 관측된 노드 V_{t}에 대하여, 이웃 노드와 현재 노드에 대한 visual representation을 계산하는 과정을 수행해야 합니다.
우선 t단계에서 agent는 전체 영상과 영상 내 object feature를 추출하여 취득하게 됩니다. 그리고 저자들은 해당 정보들에 대하여 transformer를 사용해 전체 영상과 object 사이에 spatial relation ship을 modeling하게 됩니다.
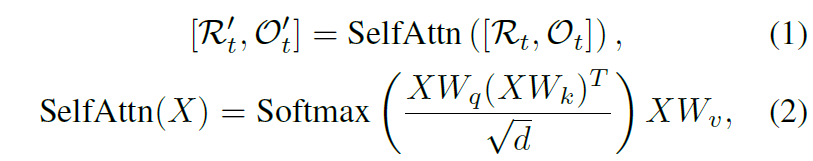
참고로 \mathcal{R}'_{t}, \mathcal{O}'_{t} 는 attention 연산이 다 처리된 인코딩된 임베딩벡터지만 저자들은 편의를 위해 앞으로의 표기에서도 \mathcal{R}_{t}, \mathcal{O}_{t} 로 표기한다고하니 오해없으시길 바랍니다.
아무튼 이렇게 트랜스포머를 통해 인코딩된 영상과 객체 임베딩에 대하여 둘의 평균을 계산하여 현재 노드의 visual representation을 update하게 됩니다. 또한 현재 노드에서도 이웃 노드에 대한 visual information을 부분적으로 취득할 수 있기 때문에, 현재 노드의 영상 임베딩 \mathcal{R} 에 이와 대응되는 탐사 가능한 이웃 노드(파란색 노드)의 visual representation을 누적합한다고 합니다. 만약 현재 노드 기준으로 탐사 가능한 이웃 노드가 2개 이상이라면, 모든 partial view에 대하여 평균을 계산해서 누적합할 때 사용하였다고 합니다.
현재 노드 V_{i} 에 대한 시각정보를 pooling한 결과값을 v_{i} 라고 하였는데, 이러한 pooling feature는 coarse scale의 정보만을 가지고 있기 때문에 그래프의 규모가 클 경우 매우 효율적인 연산을 수행할 수 있게 해주지만, 반대로 detail 정보가 다 사라졌기 때문에 세부적인 지시사항에 대해서 grounding을 수행하는데 어려움을 겪게 됩니다. 따라서 저자들은 \mathcal{R}_{t}, \mathcal{O}_{t} 을 현재 노드에 대한 fine-grained visual representation으로 두고 fine-grained reasoning이 필요로 할 때 함께 사용한다고 합니다.
Global action planning
다음은 global action planning에 대한 내용입니다. global action planning의 전체 프레임워크는 아래 그림 4에서 확인이 가능합니다.
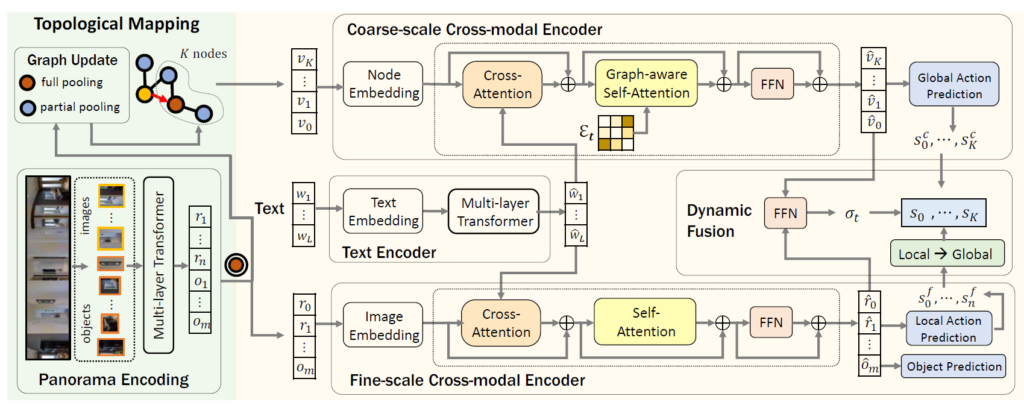
우선 coarse scale의 encoder가 모든 이전에 탐사한 노드를 토대로 대략적인 global action을 예측하게 되는데, 이때 coarse scale의 feature 정보를 사용하다보니 누락된 fine-grained 정보를 보충하고자 현재 node에 대한 fine-grained visual feature 정보를 활용하는 fine-scale encoder를 통해 보다 세밀한 local action을 예측한다고 합니다. 마지막으로 이렇게 예측된 global, local action은 dynamic fusion module을 통해 최종적인 action으로 통합됩니다.
Text encoder
우선 text encdoer은 매우 간단합니다. word embedding에 대해서 positional encoding 과정을 수행 후 multi-layer transformer 모듈에 태워서 최종적인 word feature를 생성하는 과정이 끝입니다. 이러한 지시문에 대한 word vector들은 global action과 local action을 추론하는데 사용됩니다.
Coarse-scale Cross-modal Encoder
Coarse-scale encoder의 역할은 coarse-scale map \mathcal{G} _[t} 와 위에 text encoder를 통해 인코딩된 instruction \hat{\mathcal{W}} 을 입력으로 받아 global action space를 생성하는 것입니다.
Node embedding 우선 노드에 들어있는 visual feature map은 pooling 과정을 통해 압축된 visual feature v_{i} 로, 해당 visual feature에 location encoding과 navigation step encoding이 추가됩니다. 우선 location encoding의 경우 egocentric view에서 본 지도 내 노드의 위치를 임베딩하는 것으로, 현재 노드 대비 상대적인 distance와 orientation을 의미합니다.
그리고 navigation step encoding의 경우에는 방문했던 노드들에 대하여 가장 마지막으로 방문했었을 때의 time step을 임베딩하는 것이며, 탐험하지 않은 노드의 경우에는 0에 값을 부여하게 됩니다. 즉, 방문했던 노드들은 서로 다른 네비게이션 기록들을 인코딩함으로써 지시문에 대한 alignment를 향상시킬 수 있다고 합니다. 또한 저자들은 0번째 step에 대해서는 ‘stop’ 노드로 그래프에 추가한 다음 해당 노드에서는 stop action을 취하도록 하였다고 합니다. 그리고 해당 stop node는 다른 모든 노드들과 연결되어있습니다. 즉 target 지점에 도달한 다음에는 이 stop node로 연결지어 최종 action인 멈춤 행위를 수행하도록 한 것으로 풀이됩니다.
Graph-aware cross-modal encoding
그럼 본격적으로 인코딩된 visual feature node와 instruction word embedding 사이에 관계성을 계산해야하는데 이는 단순하게 transformer를 통해서 수행이 됩니다. 각각의 트랜스포머 레이어는 cross-attention layer를 가지고 있으며 이를 통해 visual feature와 word embedding 사이의 관계성을 모델링할 수 있게 됩니다.
또한 graph-aware self-attention layer는 환경에 대한 레이아웃을 인코딩하는데 사용된다고 하는데, 단순히 그냥 cross-modal attention이 수행된 결과값에 대하여 self-attention을 수행하는 것이 아니라, 결국 이는 그래프이기 때문에 현재 노드 기준으로 이웃노드가 보다 더 밀접한 관련이 있고 거리가 먼 노드들끼리는 관련성이 상대적으로 적어지도록 해야합니다. 즉, 그래프의 연결성을 보다 명시적으로 모델링할 필요가 있다는 것이죠.
이를 위해 저자들은 그래프의 구조를 고려하여 self-attention 연산을 수행하는 방식을 새로 제안합니다.
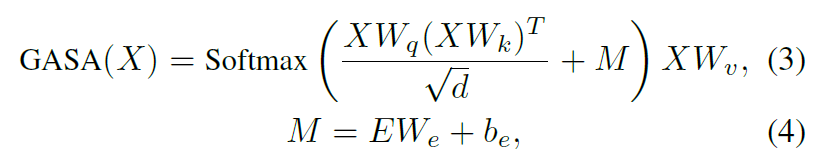
수식은 위와 같은데, attention map을 계산하는 과정에서 수식4와 같이 M을 추가해주는 과정이 추가로 들어가게 됩니다. 이 M은 E에 FC layer를 통과시켜서 계산이 되는데 이 E의 경우 \mathcal{E}_{t} 를 통해 계산한 pair-wise distance matrix라고 합니다.
결과적으로 이렇게 N번의 tranfsormer layer를 통과해서 나온 최종 결과값은 i번째 노드 V_{i} 에 대한 압축된 노드 v_{i} 라고 합니다.
Global action prediction 위의 과정을 통해 노드를 새롭게 인코딩하였다면, 이후에 액션을 추론해야합니다. 액션을 추론하는 과정은 사실 매우 간단합니다. 그냥 아까 Coarse-scale encoder에서 계산한 v_{i} 에 대하여 2개의 FC layer를 통과시켜서 action 값을 예측하는 것 뿐입니다 허허.
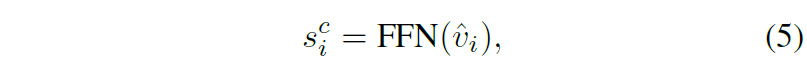
여기서 s^{c}_{0} 의 경우에는 아까 stop node에 대한 action 값으로 stop score를 가지고 있게 됩니다. 또한 대부분의 VLN에서는 agent가 이전에 방문한 노드에 대해서 다시 재방문하는 경우가 드물다고 합니다. 그렇기 때문에 특별히 언급하지 않는 한 이전에 방문한 노드들에 대하여 global action 결과값은 마스킹이 된다고 합니다. (아마 현재 단계 t 기준의 액션결과값만을 최종적으로 활용하게 되는 것 같습니다.)
Fine-scale Cross-modal Encoder
다음은 fine-scale cross-modal encoder에 관한 내용입니다. fine-scale을 다룰 때는 현재 step에 대한 fine-grained visual represenatation만을 사용하기 때문에 \mathcal{R}_{t}, \mathcal{O}_{t} 을 입력으로 사용합니다.
우선 입력이 전체 영상이기 때문에 visual embedding 과정을 거쳐야하는데, 이 임베딩 과정도 2가지로 구분이 됩니다. 첫번째 임베딩 과정은 시작 노드와 현재 노드 사이의 상대적인 위치에 대한 정보를 임베딩합니다. 2번째 임베딩의 경우에는 현재 노드와 이웃 노드 사이에 relative location에 대한 정보를 임베딩합니다. 이것은 인코더가 “우회전하기”와 같은 egocentric direction에 대한 이해를 더 쉽게 해준다고 합니다. Coarse encoder 때와 마찬가지로 제일 첫번째 입력 토큰(즉 ViT의 cls token 개념)은 stop token으로써의 역할을 수행한다고 합니다.
Fine-grained cross-modal reasoning 우선 입력으로는 stop token, image token, object token 3가지 타입의 토큰들이 concat되어서 입력으로 사용됩니다. 그리고 이는 text instruction의 word embedding과 cross-attention 과정을 거치게 됩니다. (Coarse-scale encoder와 유사)
이렇게 cross-modal reasoning을 마치고 난 다음의 feature map은 무난하게 self-attention 연산을 수행해준 뒤 FeedForward Network를 통과해 최종적인 local action을 예측하게 됩니다. 지금 봤을 땐 매우 단순한 구조처럼보이지만 2022년 기준으로는 transformer가 이제 막 vision 분야에서 핫하게 나오던 시기라서 새롭게 느껴졌을지도 모르겠습니다.
Dynamic Fusion
위에 서술한대로 global action과 local action을 모두 예측하였더라면 이제 이 액션결과들을 fusion하는 과정이 필요로합니다. 이 fusion 과정에서 어려운 점은 global action과 local action space가 서로 alignment가 잘 맞지 않는다는 점이 있습니다. 따라서 저자들은 이를 해결하기 위해 local action score s^{f}_{i} \in \{ stop, \mathcal{N}(V_{t}) \}를 global action space로 변환하는 과정을 수행합니다. (다시 말해 현재 노드에 대한 액션값이 stop이거나 또는 탐사가능한 이웃노드로 가야함을 의미하는 경우)</p> <p>우선 현재 액션 값에 대하여 2가지 경우가 존재합니다. 먼저 현재 노드에서 새롭게 갈 수 있는 이웃 노드가 없어 현재 노드와 연결되지 않은 미탐험한 노드로 가야하는 경우입니다. 이 경우에는 agent가 현재 노드 기준 방문했었던 이웃 노드들을 타고 다시 되돌아가야하는 과정이 필요로 합니다. 이러한 관점에서, 현재 노드 기준 이웃 노드 중에 방문 했었던 노드의 score 값을 다 더하게 되고 이를 overall backtrack score [latex] s_{back} 이라고 지칭합니다.
즉 현재 local score가 현재 t 스텝 기준 이동가능한 이웃 노드에 포함되어있다면 그 값을 그대로 사용하고, 만약 이동가능한 이웃 노드로 갈 수가 없는 상황(아마도 현재 노드 기준 연결된 이웃 노드가 없다면)이라면 되돌아가야하기 때문에 backtrack score를 대신 사용한다는 것으로 해석이 됩니다.
따라서 변환된 global action score는 아래와 같이 표현할 수 있습니다.
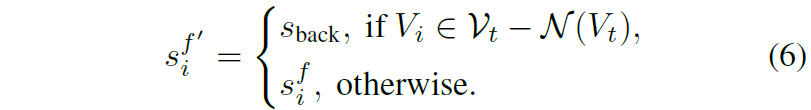
또한 저자들은 corase scale encoder와 fine-scale encoder에서 추출한 stop token에 대하여 아래 연산을 통해 액션 비율을 몇대 몇으로 섞을지를 결정합니다.
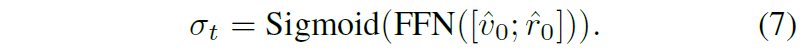
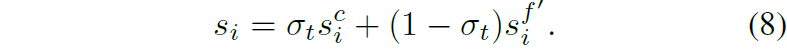
수식 8이 최종적인 action 결과값으로 사용됩니다.
Loss function(업데이트 예정)
이 부분은 제가 논문만 읽고서는 완벽하게 파악을 하지 못해서 추가적인 공부후에 내용 추가하도록 하겠습니다.
Experiments
우선 학습에 사용한 데이터는 REVERIE와 SOON 데이터셋이라고 하고, 평가로는 VLN task에서 널리 사용되는 R2R 데이터셋을 활용했다고 합니다.
Metric 평가 메트릭으로는 아래의 것들을 사용합니다.
- Trajectory Length (TL): average path length in meters;
- Navigation Error (NE): average distance in meters between agent’s final location and the target;
- Success Rate (SR): the ratio of paths with NE less than 3 meters;
- Oracle SR (OSR): SR given Oracle stop policy;
- SR penalized by Path Length (SPL).
추가로 아래 메트릭들은 네비게이션 뿐만 아니라 object grounding을 얼만큼 잘했는지까지 함께 평가하는 메트릭입니다.
- Remote Grounding Success (RGS): the proportion of successfully executed instructions.
- RGS penalized by Path Length (RGSPL)
TL과 NE를 제외한 모든 메트릭은 값이 높을수록 더 좋은 것이며 저 둘은 반대로 낮을수록 좋은것입니다.
Ablation study
저자들이 제안하는 방법론이 얼만큼 효과적인지를 분석하기 위한 ablation study입니다.
Coarse-scale vs Fine-scale encoders
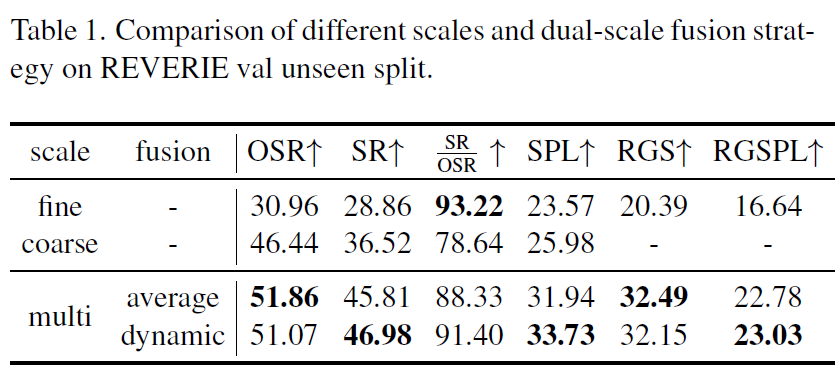
우선 Corase-scale encoder만을 사용하게 될 경우에는 SR/OSR을 제외하고는 대부분 좋은 성능을 보여주게 됩니다. 여기서 SR/OSR 성능은 목적지에 도달했을 때 stop을 잘 수행하는지에 대한 stop action 평가를 다루는 메트릭으로 저자는 이를 통해 fine-scale encoder가 instruction의 detail description을 잘 캐치할 수 있어서 agent가 언제 멈추어야하는지를 잘 판단해줄 수 있게 도와준다고 주장합니다.
하지만 그렇다고 fine-scale encoder만 사용하게 될경우 OSR를 비롯한 대부분의 메트릭에서 상대적으로 좋지 못한 성능을 보여주는데 이는 제한된 action space로 인하여 탐사 능력 자체가 훼손됨을 의미한다고 합니다.
결국 Corase-scale과 fine-scale을 함께 사용해야하만 하는데 이 둘의 action 결과를 어떻게 융합할 것이냐에 대한 실험결과가 표1 아래쪽 행에 존재합니다. 결론부터 말씀드리면 단순히 평균때리는 방식보다는 adaptive하게 합치는 방식이 OSR과 RGS를 제외하고는 더 좋은 모습을 보여주더라입니다. 근데 제가 이 분야가 처음이라서 1~2정도 값이 더 증가한것이 얼만큼 유의미한 것인지에 대해서는 의문이 들긴 하네요.
Graph-aware self-attention
다음은 coarse-scale encoder 내에서 self-attention을 수행할 때 edge정보를 추가해주던 graph-aware self-attention의 효과를 보는 것입니다.
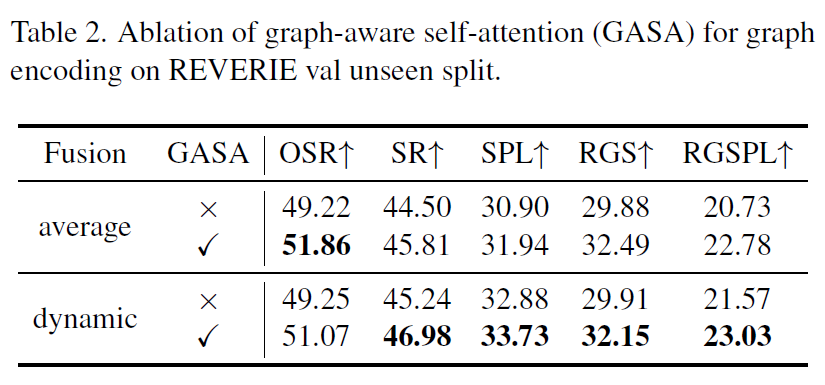
여기서도 fusion 방식으로 또 나눠서 GASA 적용 여부에 대한 실험을 진행하게 되는데, 결과적으로 GASA가 어떠한 fusion 방식을 채택하던지 간에 추가했을 경우 더 좋은 성능을 보여주더라라는 것을 확인할 수 있습니다.
Comparsion with SOTA methods
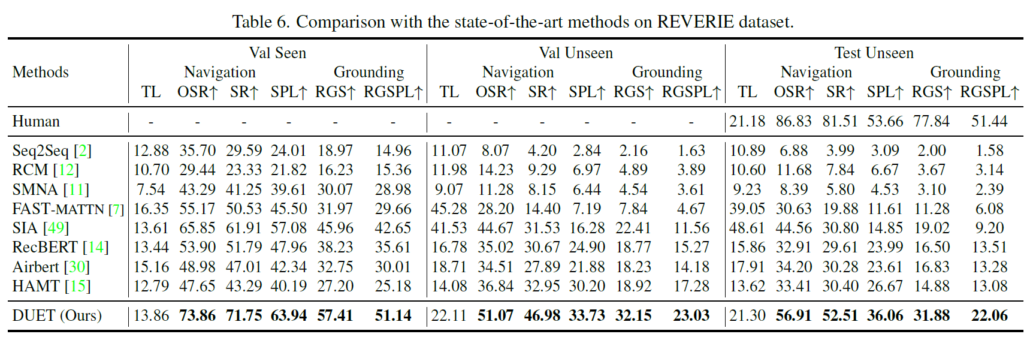
위에 표는 그 당시 SOTA방법론들과의 성능 비교 표입니다. 정말 흥미롭게도 이전의 방법론들과 비교해서 매우 큰 성능 향상폭을 보여주는 모습입니다. 제가 예전 방법론들을 아직 읽지 못해서 모델의 사이즈나 학습에 사용된 데이터 수 등이 동일한지 혹은 DUET이 더 추가적인 학습과정과 데이터를 사용한 것은 아닌지 정확히 구분이 안돼서 단순히 저자들이 제안하는 프레임워크 구조만으로 이정도의 성능 차이를 냈는지는 불분명합니다. 그럼에도 불구하고 성능 향상폭이 매우 커졌다는 점에서는 그 당시 많은 관심을 받았을 것으로 예상됩니다.
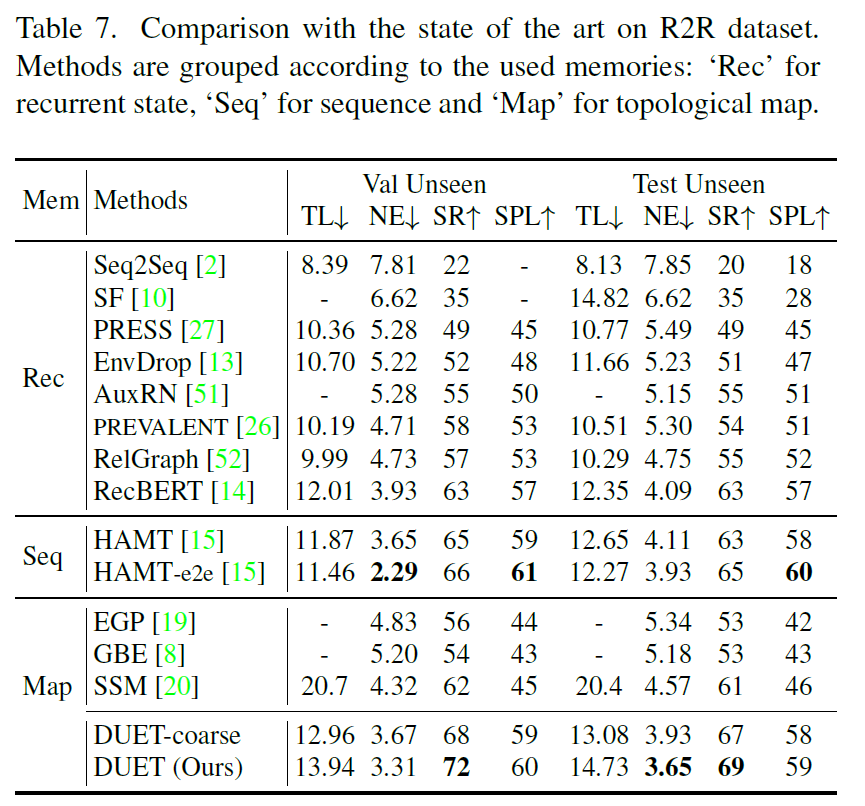
위 표는 R2R 데이터셋에서의 비교 결과인데, 우선 기존의 map based 방법론들(19, 8, 20)의 경우에는 fine-grained encoder를 사용하지 않았습니다. 그래서 저자들이 DUET-coarse 행을 통해 기존의 방법론들과 최대한 fair?하게 비교해보려고 했다는데 저자들 말에 따르면 자신들도 corase한 정보만을 활용할지라도 기존 방법론들보다 모든 메트릭에서 더 좋은 성능을 보이고 있다고 주장합니다.
또한 HAMT-e2e와 비교하더라도 Suceess Rate가 더 높다는 점을 저자는 강하게 어필합니다. 비록 Navigation Error(NE)값은 밀리는 모습이지만 3미터 이내의 오차안에 들어오는 경우는 더 많다는 점에서는 더 이점이 있다는 것 같네요.
결론
VLN의 대략적인 흐름을 이해하는데 있어서는 상당히 읽기 좋은 논문이었던 것 같습니다. 다만 이 분야에 대해 이제 처음으로 읽은 논문이다보니 모델의 output값과 학습 과정에 대해서는 논문만으로 세세하게 이해하기 어려움이 좀 존재해서 아쉽네요. 코드를 한번 찾아보고 더 세부적인 공부를 해볼 수 있으면 좋을 듯 합니다.