오늘은 연산량과 추론속도 해결에 집중한 Text-Video Retrieval 논문에 대해 리뷰해보겠습니다.

- Conference: ICLR 2025
- Authors: Leqi Shen, Tianxiang Hao, Tao He, Sicheng Zhao, Yifeng Zhang, pengzhang liu, Yongjun Bao, Guiguang Ding
- Affiliation: School of Software, Tsinghua University, BNRist, Tsinghua University, Hangzhou Zhuoxi Institute of Brain and Intelligence, JD.com, GRG Banking Equipment Co., Ltd., South China University of Technology
- Title: TempMe: Video Temporal Token Merging for Efficient Text-Video Retrieval
1. Introduction
이제는 다들 아시겠지만, 멀티모달(영상-언어) 이해 분야에서 텍스트-비디오 검색(Text-Video Retrieval)은 주어진 질의 문장(Query)에 대응하는 비디오를 찾거나, 반대로 비디오에 대응하는 문장을 찾는 중요한 태스크 중 하나 입니다. 최근에는 해당 분야에서는 CLIP과 같은 대규모 텍스트-이미지 사전학습 모델을 활용하여 Fine-tuning 하는 연구가 주류에 해당하죠. 하지만 CLIP 기반 방식은 추론 속도가 느리고 GPU 메모리 소모가 커 실제 서비스 적용에는 어려움이 있다고 합니다. 예를 들어, 가장 대표적인 CLIP4Clip을 학습하는 데만 70.1GB의 메모리와 6.5시간이 소요된다고 합니다.
따라서 저자는 연산량 증가에 대한 대응으로 Token Compression 기법을 사용하고자 하였습니다. 이는 이미지 내 유사한 토큰을 병합하여 연산 효율을 높이는 연구입니다. 하지만 기존 방식은 이미지 내 공간 정보(spatial redundancy)를 줄이는 데 집중하지, 비디오의 특성인 연속된 프레임 간 발생하는 중복 정보(temporal redundancy)는 고려하지 않는다는 문제가 존재하였죠. 이를 그림과 함께 살펴보겠습니다.
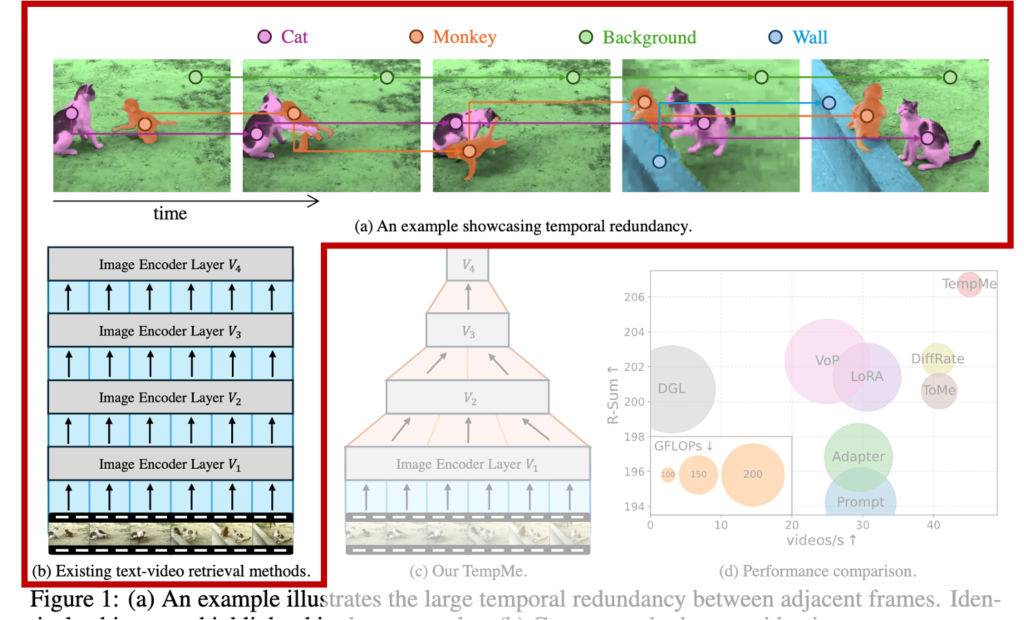
상단 그림 1(a)는 이러한 시간적 중복(temporal redundancy) 문제를 보여줍니다. 고양이와 원숭이가 등장하는 예시 비디오에서, 인접한 프레임들이 거의 동일한 객체(동일 색으로 표시됨)를 포함하고 있어 사실상 같은 정보가 반복되고 있습니다. 그림 1(b)에서는 기존 방법들이 비디오를 단순히 여러 프레임의 시퀀스로 처리하면서 많은 토큰을 생성하게 되어, 복잡도가 크게 증가하는 구조라는 걸 나타냅니다.
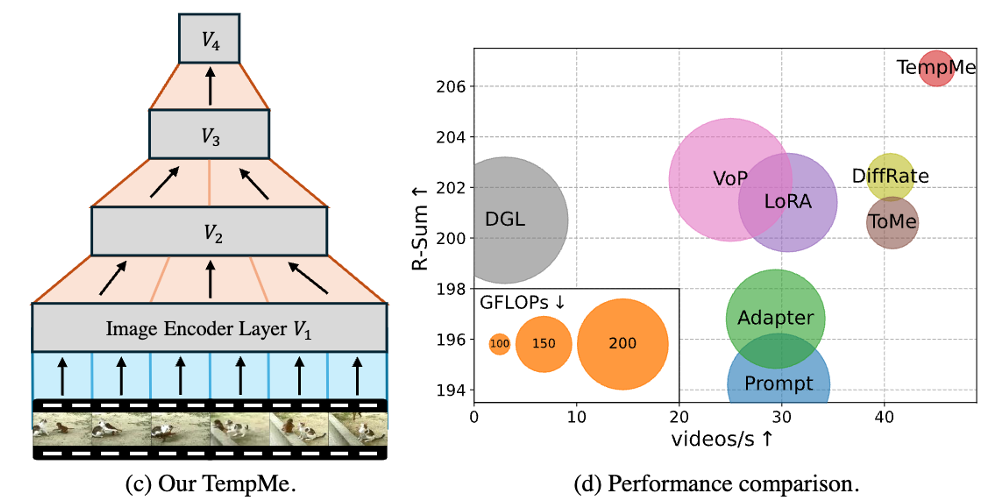
이에 대응하여, 저자가 제안하는 TempMe 가 어떻게 이 문제를 해결하는지를 그림 1(c)에서 확인할 수 있습니다. TempMe는 인접한 비디오 클립 사이의 중복 토큰을 점진적으로 병합(merging)하여 전체 토큰 수를 줄이는 동시에, 더 넓은 시간 범위에서 의미 있는 정보를 통합할 수 있도록 설계되었습니다. 그림 1(d)에서는 실제 방법론과의 연산량을 비교함으로써, TempMe가 기존 방법들보다 훨씬 적은 연산량/추론속도로 더 높은 검색 성능을 보였다고 합니다. (원의 크기가 GFLOPs, x축은 추론속도, 그리고 y축은 성능을 의미)
상단 그림 1(c)에서 표현한 것처럼, 저자는 Token Compression에서 착안한 Temporal Token Merging (TempMe)라는 모델을 제안하였습니다. 즉, 인접한 비디오 클립에서 발생하는 중복 토큰을 점진적으로 병합하는 방식으로, 연산량과 추론속도 문제를 대응하고자 하였습니다. 본격적인 설명 시작하겠습니다.
2. Method
2.1 Preliminaries
CLIP 기반 Text-Retrieval에서는 보통 텍스트는 문장 단위, 비디오는 각 프레임을 독립적으로 각각의 인코더로 처리합니다. 이 과정에서 프레임 수가 늘어날수록 입력 토큰 수도 선형적으로 증가하게 되고, 결과적으로 연산량과 복잡도가 커지게 되죠.
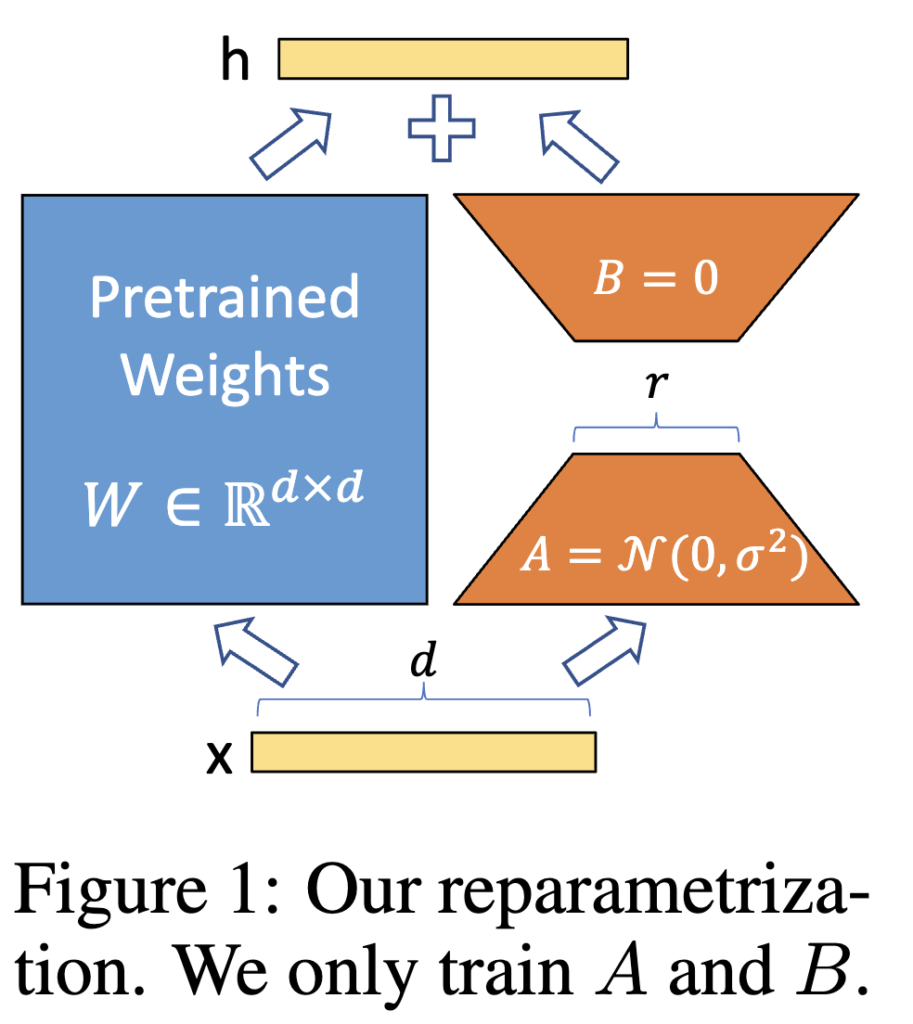
저자는 이러한 구조 위에 LoRA(Low-Rank Adaptation)를 얹어 파라미터 효율적인 학습을 수행하였습니다. 많이들 아시겠지만, LoRA는 기존 Transformer의 파라미터를 고정한 채 소수의 학습 파라미터만 추가하여 효율적인 fine-tuning을 가능하게 한 연구입니다. 특히, LoRA는 학습 이후에는 간단하게 기존 weight에 병합 가능하기 때문에 추론 시 latency 증가 없이 사용할 수 있다는 장점이 있죠. 이 파트가 굳이 있는 이유는 TempMe의 성능 향상이 LoRA 때문이 아니라는 점을 명확히 하기 위해서 같습니다
(참고로 이 논문은 전체 모델 구조 위에 LoRA를 얹어 학습 효율을 높였지만, 논문의 진짜 핵심은 LoRA가 아니라 시간 축의 중복을 줄이는 TempMe 구조입니다. LoRA는 다른 기존 방법들과의 비교를 위한 baseline으로 사용된 것이며, 실험 결과에서도 LoRA 단독보다 TempMe 구조가 성능을 더 크게 향상시킴을 확인할 수 있습니다.) 이제 본격적으로 저자가 제안한 TempMe 구조에 대해 살펴보겠습니다.
2.2 Temporal Token Merging
앞서 언급했듯이 비디오의 각 프레임은 독립적으로 처리되기 때문에, 시간적으로 유사한 프레임 사이에도 동일한 객체나 배경이 반복되면서 중복 토큰이 다수 발생합니다. 이러한 시간적 중복을 줄이기 위해 제안한 구조가 바로 TempMe입니다.
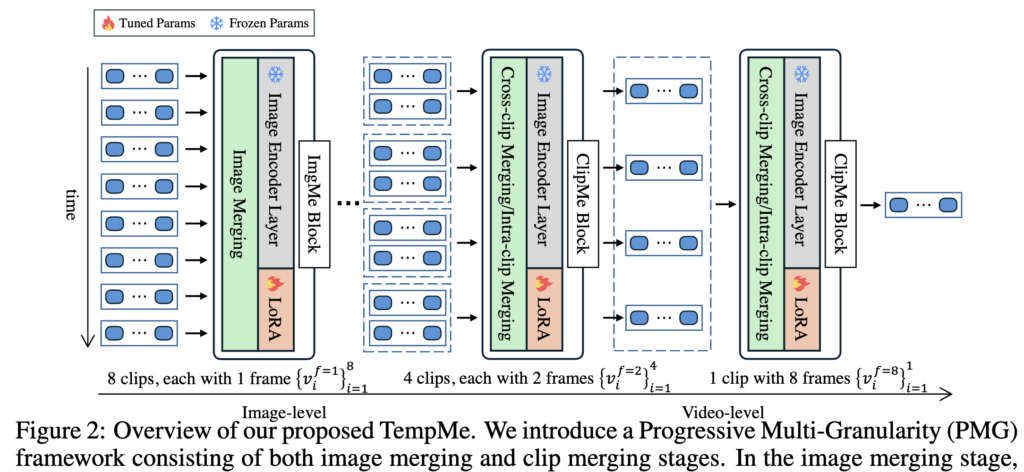
TempMe는 Progressive Multi-Granularity (PMG) 구조를 기반으로 합니다. 이는 이름 그대로 점진적으로(Progressive) 다양한 시간적 범위에서(Multi-Granularity) 토큰을 병합하는 방식입니다. 이는 두 가지 단계로 나뉩니다: (1) ImgMe Block (2) ClipMe Block.
우선 첫 번째 단계는 ImgMe Block입니다. 여기서는 각 프레임을 독립적으로 처리하면서, 동일한 프레임 내에서 유사한 토큰들을 병합하게 됩니다. 이렇게 하면 공간적인 중복(spatial redundancy)을 줄일 수 있고, 동시에 사전학습된 이미지 인코더의 표현력을 그대로 활용할 수 있다는 장점이 있다고 합니다.
그다음 단계는 ClipMe Block입니다. 여기서부터가 본격적인 시간 축 병합(temporal merging)에 해당합니다. ClipMe는 여러 프레임을 짧은 클립 단위로 묶고, 인접한 클립들 간 유사한 토큰을 점진적으로 병합하면서 더 긴 클립으로 확장해갑니다. 예를 들어 상단 그림2에 나오는 예시처럼, 처음에는 1프레임짜리 클립 8개를 시작으로 → 2프레임짜리 클립 4개 → 4프레임짜리 클립 2개 → 최종적으로 8프레임짜리 하나의 클립으로 병합하는 식이죠.
이렇게 공간적 → 시간적 정보를 처리하는 두 가지 블락을 통해, 중복 정보를 제거하면서 전체 비디오에 대한 통합적인 정보는 attention구조로 통합하였다고 합니다. 결국 PMG은 세밀한 이미지 수준 정보에서 시작해, 점점 더 추상적이고 종합적인 비디오 표현으로 확장해가는 방식이라 볼 수 있겠네요
2.2.1 ImgMe Block
먼저 프레임 단위에서의 공간 중복(spatial redundancy)을 줄이기 위한 모듈로 ImgMe Block에 대해 알아봅시다. 이 구조는 기존 이미지 모델에서 연산 효율을 높이기 위해 제안된 *ToMe (Token Merging) 에서 영감을 받았다고 합니다.
*[ICLR 2023] Token Merging: Your ViT But Faster
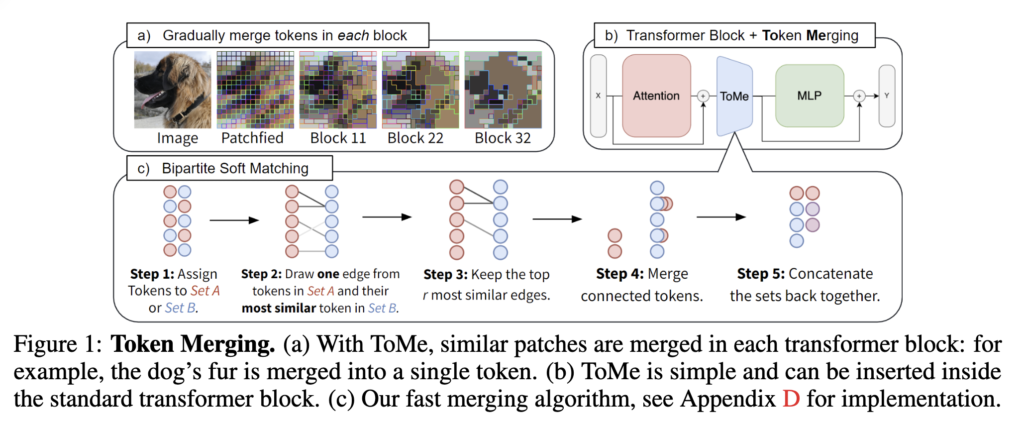
ToMe의 핵심은 바로 상단 그림 1(c)의 Bipartite Soft Matching입니다.
- 토큰을 교차로 Set A와 Set B로 나눕니다.
- Set A의 각 토큰은 Set B에서 가장 유사한 토큰을 하나씩 선택합니다. (코사인 유사도 기준)
- 이 중에서 유사도가 높은 상위 r개의 쌍만 선택하여 병합합니다.
- 연결된 토큰 쌍은 평균을 내어 하나로 합치고,
- 마지막으로 나머지 토큰들과 함께 다시 전체 토큰 시퀀스를 구성합니다.
이러한 병합 과정을 각 프레임의 Transformer Block 내부(Multi-Head Self-Attention과 Feed-Forward Network 사이)에서 반복하며, 토큰 수를 점차 줄여나가는 구조가 ImgMe Block입니다. 수식적으로 보면, 입력 토큰이 N개이고 K개의 ImgMe Block을 통과한다면, 최종적으로는 N – r×K 개의 토큰으로 줄어듭니다.
단, 지나친 병합으로 인해 중요한 이미지 정보가 손실되지 않도록, 논문에서는 r 값을 작게 설정하였습니다. 실제 실험에서는 CLIP-ViT-B/32에선 r=2, B/16에선 r=10을 사용하였습니다. 그러나, 이렇게 프레임 단위로 공간적인 중복을 줄이더라도, 결국 비디오에서는 다수의 프레임을 처리해야 하기 때문에 모델의 복잡도는 여전히 높습니다. 이 문제는 뒤에서 설명할 ClipMe Block을 통해 추가적으로 해결하게 됩니다.
2.2.2 ClipMe Block
앞서 설명했듯이, ClipMe는 여러 프레임을 클립 단위로 묶고, 인접 클립 간의 중복 정보를 제거하는 구조입니다. 이 과정은 두 단계로 나뉘는데, 바로 cross-clip merging과 intra-clip merging입니다.
(1) Cross-Clip Merging
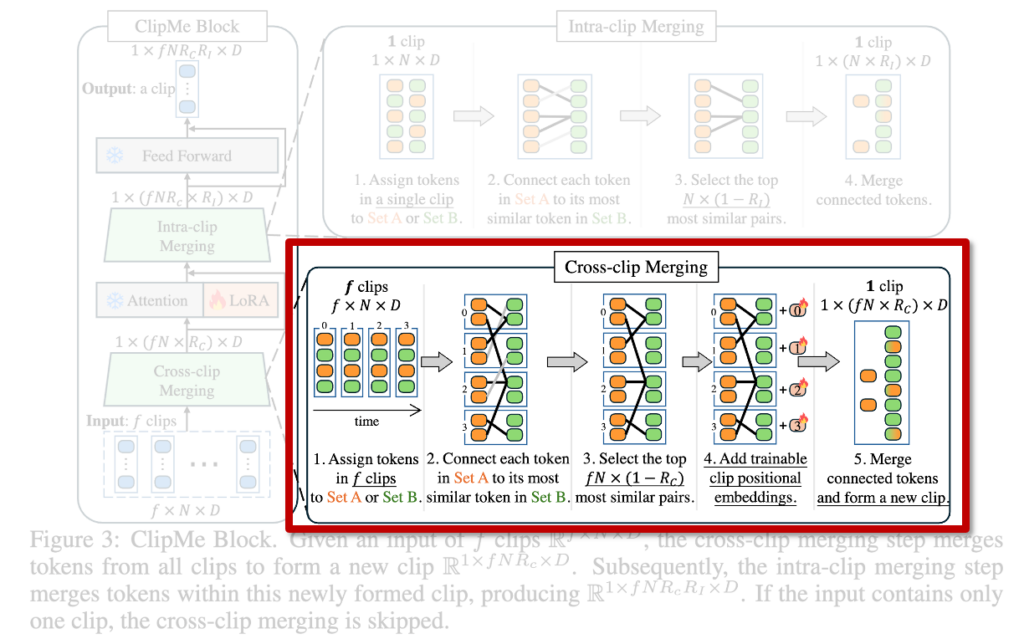
먼저 cross-clip merging 단계에서는 인접한 클립들을 받아, 서로 유사한 의미를 갖는 토큰들을 병합하게 됩니다. 여기서 중요한 점은 병합 대상이 단일 프레임 내 토큰이 아닌, 여러 프레임에 걸쳐 나타나는 같은 객체 또는 배경이라는 것입니다. 이를 위해 입력 토큰들을 교차로 Set A와 Set B로 나누고, 각 Set A 토큰마다 Set B에서 가장 유사한 토큰을 찾습니다. 이 과정은 앞서 본 ImgMe Block 이미지 내 병합 방식과 유사하지만, 병합 비율은 훨씬 높다고 합니다. 시간 축에서의 중복이 공간보다 더 빈번하게 발생하기 때문입니다.
실제로 병합에 사용되는 토큰 쌍의 수는 전체 클립 토큰 수의 약 1 - Rc 비율이고, Rc는 병합 후 유지할 토큰 비율입니다. 이때 모든 토큰에는 clip positional embedding이 추가되어, attention이 시간 정보를 인식할 수 있게 설계하엿다고 합니다. 이렇게 병합된 토큰들과 병합되지 않은 토큰들이 함께 하나의 새로운 클립을 구성하고, 이 클립은 이후 Multi-Head Self-Attention 를 거쳐 시간-공간 정보를 통합하게 됩니다.
(2) Intra-Clip Merging
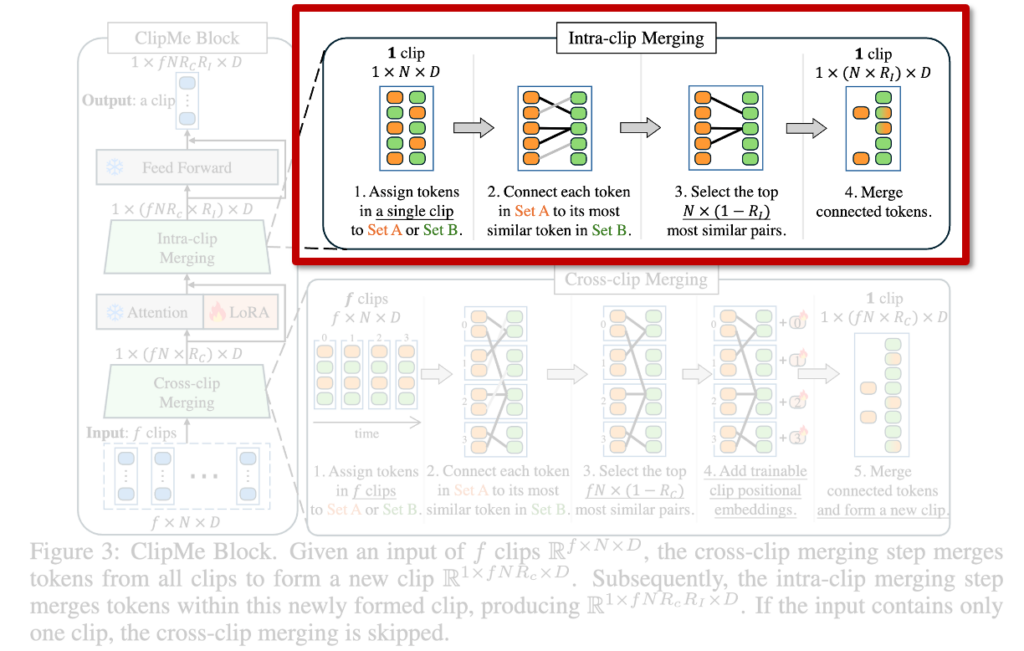
그다음은 intra-clip merging 단계입니다. 이 단계에서는 새롭게 생성된 클립 내부의 토큰들 중에서도 여전히 중복되는 정보를 압축합니다. ImgMe에서는 작은 수의 토큰만 병합했던 반면, intra-clip merging에서는 전체 토큰의 더 큰 비율을 병합합니다. 이로 인해 입력 크기 R₁×N×D는 R₁×(N×RI)×D로 줄어들며, RI는 병합 후 유지할 토큰 비율입니다. 즉, 시간 축 정보가 정제된 상태에서 한 번 더 압축하는 과정이라 볼 수 있습니다.
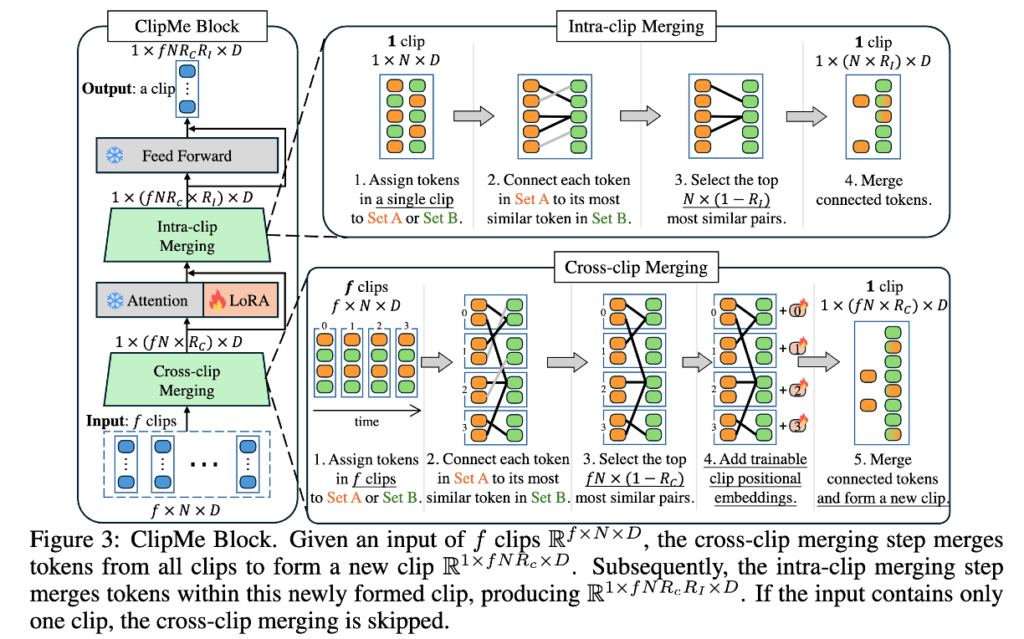
결국 ClipMe Block은 시간 축 전체를 따라 압축을 수행하며, Clipme Block 전체 그림인 상단 그림을 통해 이 구조가 attention block 및 병합 연산과 어떻게 통합되는지를 확인할 수 있습니다. 이 구조로 중요한 정보는 유지한 채, 전체 토큰 수를 단계적으로 줄이면서도 성능 저하 없이 비디오 표현을 생성할 수 있었다고 합니다.
2.3 Complexity

상단 Table 1은 TempMe의 연산 효율성을 ToMe와 비교한 결과를 보여줍니다. (MSR-VTT, ActivityNet에서 프레임 수 12와 64로 고정하여 실험, Backbone CLIP-ViT-B/32와 B/16을 사용)
결과적으로 TempMe는 ToMe보다 30% 이상 더 많은 토큰을 줄이면서도, 성능은 더 높게 나타났습니다. 특히 MSR-VTT + CLIP-ViT-B/16 (12프레임) 에서는 입력 토큰의 단 5%만 유지, GFLOPs는 57%, R-Sum은 5.3% 향상되며 가장 큰 효율성을 보였다고 합니다. 즉, 단순한 토큰 압축을 넘어 실질적인 시간 축 중복 제거의 효과를 확인할 수 있었다고 합니다
3. Experiments
3.1 Dataset & Evaluation Metric
- MSR-VTT
- DiDeMo
- ActivityNet
- LSDMC
- Recall at K (R@1, R@5, and R@10), the sum of these recalls (R-Sum), and Mean Rank (MnR)
3.2 Comparisions with SOTA
Table 2 – Text-to-Video Retrieval (MSRVTT)
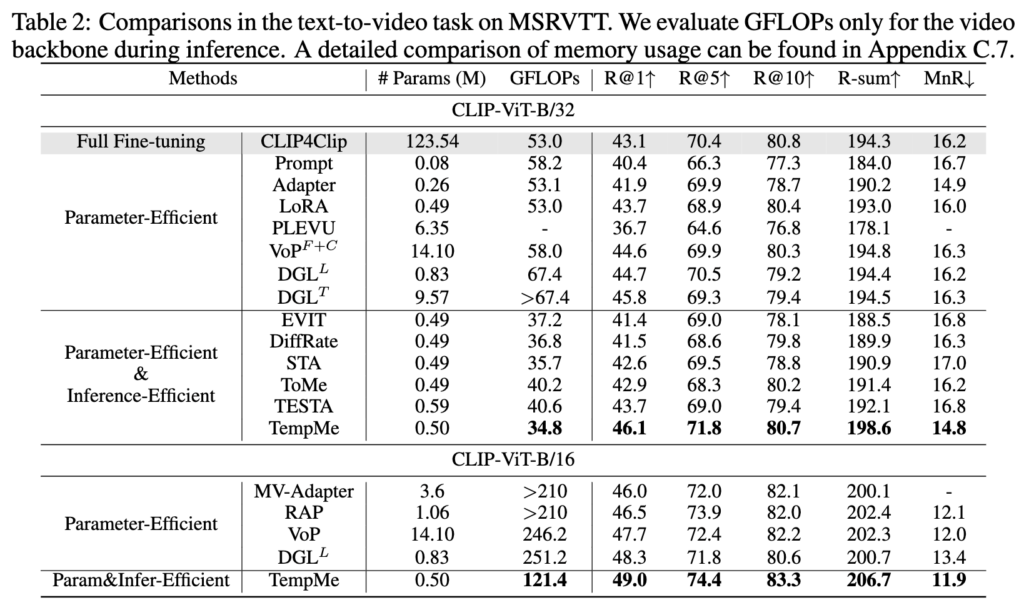
Table 2는 MSR-VTT에서의 텍스트-비디오 검색 성능을 비교한 결과입니다. TempMe는 기존 방식 대비 ViT-B/32에서 3.8%, ViT-B/16에서 4.3% R-Sum 향상을 보이면서, GFLOPs는 최소 수준으로 유지하였습니다.
Table 3 – Text-to-Video Retrieval (ActivityNet, DiDeMo, LSMDC)
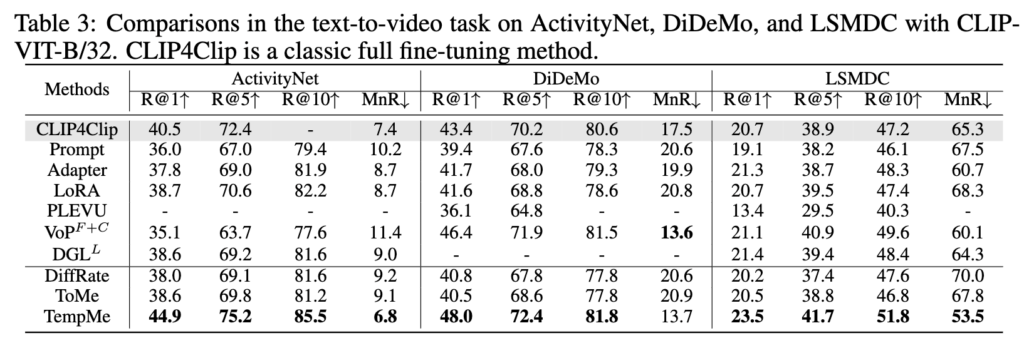
Table 3에서는 ActivityNet, DiDeMo, LSMDC 데이터셋에서의 성능으로, 모든 벤치마크에서 SOTA 방법들을 안정적으로 상회하는 성능을 보였습니다.
Table 4 – Computational Overhead (MSRVTT)
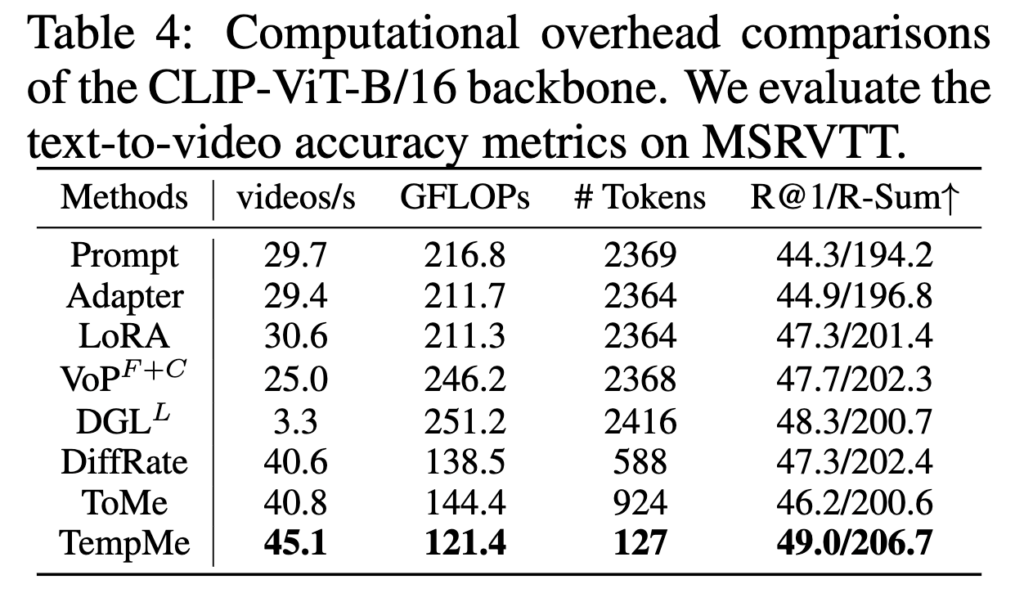
Table 4는 MSR-VTT에서 CLIP-ViT-B/16을 사용하여 성능, 연산량, 추론 속도를 비교한 실험입니다. ToMe는 LoRA 대비 프레임당 토큰 수를 39% 수준으로 줄였지만, 성능은 약간 하락했습니다. 반면 TempMe는 토큰 수를 5%까지 줄이면서도 R-Sum 은 오히려 5.3% 상승하였습니다.
추론 속도도 TempMe이 뛰어난데, VoP 대비 1.8배, DGL 대비 13.7배 빠른 속도, GFLOPs는 51% 절감, 동시에 성능(R-Sum)은 4.4% 증가하였습니다. 즉, TempMe에서 성능을 유지하거나 향상시키면서도 연산 효율을 낮춘 것을 확인하였습니다.
Table 5 – Generalization analysis of full finetuning (MSRVTT)
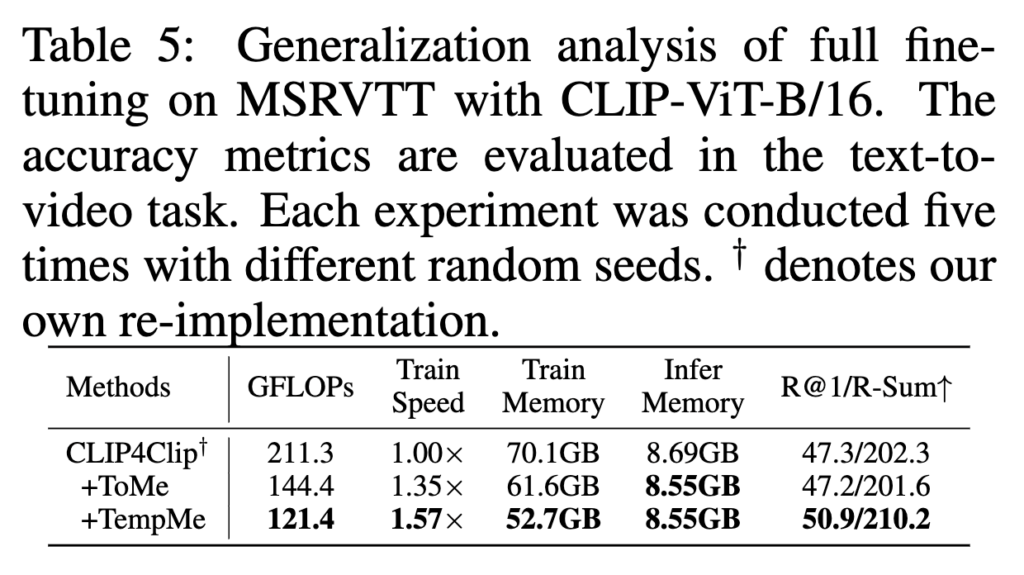
저자는 대표적인 Full fine-tuning 모델인 기존 Clip4Clip에 제안하는 모듈을 붙혔을 때의 효율성도 확인하였습니다. 이는, 모든 프레임이 개별적으로 이미지 인코더를 통과하기 때문에, GPU 메모리 소모와 학습 시간이 매우 커지는 상황이죠.
이 때 단순한 Token Compression을 붙혔을 때인 ToMe는 공간 중복만 줄이기 때문에 속도는 향상되지만, 성능이 소폭 하락합니다. 반면 TempMe는 시간 중복까지 줄이면서도 비디오 수준의 표현을 학습할 수 있어, 1.57배 빠른 속도 R-Sum 7.9% 향상이라는 큰 성능 이득을 보였습니다. 즉, TempMe는 파인튜닝 전반에서도 효율성과 성능을 동시에 확보할 수 있는 구조임을 보여줍니다.
Table 8 – Ablation study (MSRVTT)
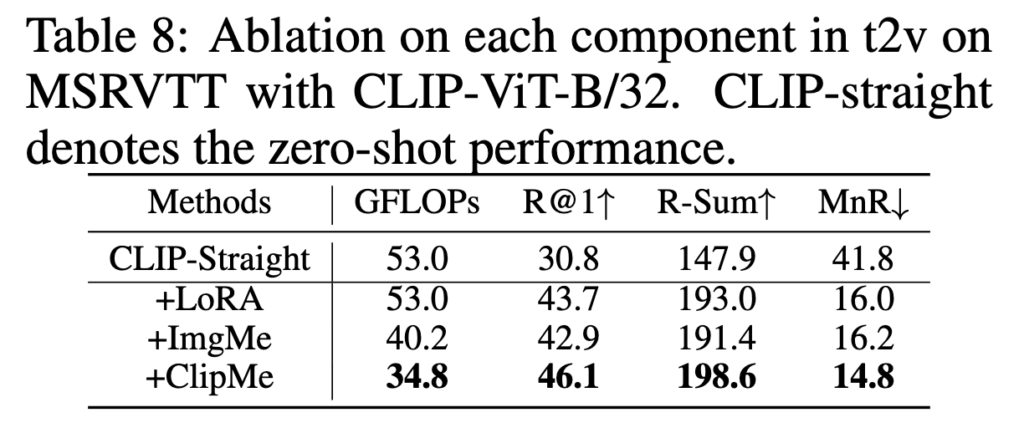
Table 8은 TempMe를 구성하는 두 블록, ImgMe와 ClipMe 각각의 영향을 확인하였습니다. CLIP-straight는 zero-shot CLIP 성능, LoRA는 efficient fine-tuning baseline입니다.
ImgMe는 프레임 내 공간 중복을 줄여 성능 향상을 도왔고, ClipMe는 짧은 클립들을 긴 클립으로 병합하면서, 시간 축 학습과 중복 제거를 동시에 수행했습니다. 최종적으로 TempMe는 LoRA 대비 R-Sum을 5.6% 향상시키고, GFLOPs도 18.2 감소하며 두 측면에서 모두 개선된 결과를 보일 수 있었다고 합니다.
4. Summary
지금까지 텍스트-비디오 검색에서 연산 효율과 성능을 동시에 개선하고자 제안된 TempMe라는 방법론을 살펴보았습니다.
기존 방법들이 시간적으로 중복되는 프레임 정보를 그대로 처리함으로써 비효율적인 연산과 느린 추론 속도를 야기했던 반면, TempMe는 Progressive Multi-Granularity 구조를 통해 프레임 간 유사한 토큰을 점진적으로 병합하며, 연산량을 줄이는 동시에 의미 있는 비디오 표현을 효과적으로 학습하였습니다. 제안된 구조는 공간 중복을 줄이는 ImgMe 블록과 시간 중복을 줄이는 ClipMe 블록으로 구성되며, 전체 토큰 수를 최대 95%까지 감소시키면서도 R-Sum 기준 성능은 오히려 향상되었음을 다양한 실험을 통해 확인할 수 있었습니다.
처음에는 구조 자체가 간단해 보여서 contribution이 다소 약하지 않을까 우려했는데, 실제로 논문을 읽어보니 제가 리뷰에서 다룬 것보다 훨씬 더 다양한 실험과 정교한 분석이 포함된 고봉밥 논문이지 않았나 싶습니다. 리뷰어들의 피드백을 성실히 반영하여, 결국 ICLR에 게재될 수 있었던 이유가 아닐까 싶네요.
안녕하세요 좋은 리뷰 감사합니다.
디테일하게 설명해주셔서 이해가 빨리 되었는데, 한가지 궁금한 점이 생겨 질문 남깁니다.
Video Retrival을 위한 압축 방식이라고 제목이 지어졌는데, 학습 과정중에는 비디오 검색을 수행하지 않는것 같아서요,
해당 압축방법 사용시에 비디오 검색 성능이 향상되었기에 이러한 제목이 지어진 것일까요?
아니면 학습 과정중에 비디오 검색 테스크도 같이 학습하는지 궁금합니다.
감사합니다.
안녕하세요 좋은 질문 감사합니다.
TempMe는 Text-Video Retrieval 태스크를 그대로 유지하면서 비디오 인코딩 과정을 효율화한 방법입니다. 즉, TempMe에서 제안한 ImgMe와 ClipMe 블록은 모두 이미지 인코더 내부에서 작동하며, 텍스트 인코더는 기존 CLIP처럼 문장 전체를 하나의 벡터로 인코딩하는 구조입니다.
전체적인 처리 흐름은 기존 Text-Video Retrieval 구조와 거의 동일합니다:
(1) 텍스트는 텍스트 인코더를 통해 문장 벡터로 인코딩되고,
(2) 비디오는 프레임 단위로 이미지 인코더에 입력되어 각 프레임을 인코딩한 후,
(3) 텍스트-비디오 간 코사인 유사도를 계산하여 ranking을 수행합니다.
TempMe 논문이 (2)의 비디오 인코딩 단계에서 연산량을 줄이는 부분에 초점을 맞추다 보니, 제가 리뷰에서 retrieval을 수행하는 뒷단 구조에 대한 설명이 부족했던 것 같습니다. 질문 덕분에 중요한 부분을 짚고 넘어갈 수 있었습니다. 감사합니다~!
안녕하세요 주영님, 좋은 리뷰 감사합니다.
구체적인 설명으로 이해하기가 수월했습니다.
리뷰를 보고 든 궁금점은 연산량 측면에서 ClipMe 방식은 어떤 영상이 들어오더라도 각 프레임당 비슷한 장면이 있을 것으로 생각되어 시간적 정보를 압축하는데 중요할 것 같습니다.
ImgMe가 약간 궁금한점인데, 만약 작은 새가 존재하는 영상에서 새를 찾는 캡션을 입력으로 넣었을때, ImgMe 방식이 작은 새를 찾는 것에 도움이 될지 아니면 방해가 될지 궁금합니다. 새의 정보가 조금 사라져서 안좋아질지 아니면 해당 논문의 성능처럼 주변정보도 어느정도 사라져서 오히려 새를 잘 찾을지? 정답이 있는건 아닐테고 어떻게 생각하시는지 궁금해서 질문드립니다.
좋은 질문 감사합니다!
우선, ImgMe는 토큰을 삭제하는 게 아니라 유사한 토큰끼리 병합하는 구조입니다. 그래서 “작은 새”처럼 뚜렷한 객체는 배경 토큰과 유사하지 않기 때문에 병합 대상에서 제외될 가능성이 높습니다. 오히려 주변 배경이 정리되면서 더 잘 드러날 수도 있죠.
뿐만 아니라 저자 역시 작은 새와 같은 중요 객체 정보가 손실될 것을 우려하였, 중요한 객체 정보는 학습 과정에서 보완되도록 설계하였습니다. 병합된 토큰의 비율을 작게 설정하는 식으로 말이죠!
안녕하세요 주영님, 좋은 리뷰 정말 감사드립니다.
세미나와 리뷰 덕분에 TempMe 구조에 대해 한층 더 쉽게 이해할 수 있었던 것 같습니다. 감사합니다!
읽다 보니 한 가지 궁금한 점이 생겼습니다. 제가 아직 Set A와 Set B를 나누는 방법론에 대한 지식이 부족한 터라 조금은 부족한 질문을 드려봅니다.
ImgMe Block에서 프레임 내 토큰들을 단순히 교차로 Set A와 Set B로 나눠서 중복된 토큰을 제거하는 것으로 이해하였는데,
이때 두 set을 어떻게 나누느냐에 따라 결과의 차이가 있을 것 같다는 생각이 들었습니다.
왜냐하면 SetA 내부에 있는 친구들 끼리는 서로 중복 검사가 되지 않기 때문에, Set A 안에 유사한 토큰이 몰려 있게되면 성능에 결과가 조금 미치지 않을까라는 의문이 들었습니다.
ClipMe Block의 경우는 여러 번 수행되기 때문에 다음 스텝에서도 또 SetA,B로 나눠지면서 이런 중복이 점차 해소될 수 있을 것 같지만 ImgMe는 프레임 별 맨처음 한번만 수행되기 때문에 SetA,B를 잘 나누는게 중요할 것 같다는 생각이 들었습니다!
혹시 이러한 부분에 대해서 논문에서 언급된 부분이 있는지 궁금합니다! 혹은 이러한 부분이 전반적인 성능에 미치는 영향이 어느정도 일지도 살짝 궁금합니다!
감사합니다.
해당 질문은 토큰을 두 세트로 나눌 때 어떻게 나누었는지에 대한 질문같습니다.
TempMe 에서는 [ICLR 2023] ToMe 에서 사용한 기법을 그대로 적용하였기 때문에,
ToMe 에서 두 세트를 어떻게 나눴는지에 대한 설명으로 답변드립니다.
우현님이 질문주신 내용을 ToMe에서도 실험으로 다뤘습니다. 토큰을 두 세트로 나누는 방식은 간단하게 3가지 방식이 존재합니다
– sequential: 순차적으로 A를 채운 후 B를 채움
– alternating: A, B, A, B 형태로 번갈아가며 나눔
– random: 랜덤으로 분할
이에 대한 실험 결과는 아래와 같습니다.
이 중 alternating 방식이 가장 높은 정확도와 속도를 보여 이 방식으로 실험을 진행했고, 이는 A와 B가 다음 레이어에서 서로 다른 위치의 정보를 비교할 수 있도록 유도하는 효과가 있었다고 하네요.