안녕하세요, 이번주에는 Real 2 Sim 2 Real 파이프라인을 제시한 논문에 대한 리뷰를 해보려고 합니다. 기존의 관심사가 Sim에서의 조작을 통한 Real 데이터를 최대한 효율적으로 활용하며 Policy의 일반화인 만큼, 저자들이 제시한 Cross Embodiment 뿐 만 아니라 다양한 빛, 심지어 카메라의 위치까지 Gaussian Splatting의 explicit 하다는 이점을 잘 살려서 일반화를 달성한 RoboSplat 파이프라인이 인상깊었습니다. 코드는 아쉽게도 5월에 공개한다고 했지만 아직 올라오지 않은 상태네요,, 리뷰 시작해보도록 하겠습니다.
Introduction
저자는 Imitation Learning이 Robot Manipulation의 유의미한 파라다임 전환에 성공했다고 주장합니다. 하지만 IL을 통한 학습은 언제나 Robustness가 문제였습니다. 이는 사실상 Real World에서 수집하는 데이터의 visual domain이 다양하지 않기 때문인 이유가 큽니다. 따라서 학습 데이터셋의 종류를 늘리는 방법이 이론적으로는 가장 효과적인 방법이긴 합니다. 다만 제가 연구실에서 팀원들과 Imitation Learning용 데이터를 간단한 policy를 위해 수집해본 결과, 로봇을 teleoperation하는 것 뿐 만 아니라, 에피소드가 종료된 후 원래 상태로 돌려놓는 작업 또한 굉장히 많은 인력을 필요로 하는것을 확인할 수 있었습니다. 저자 또한 해당 과정은 time-consuming이고, labor-intensive하다고 합니다. 그래서 저자들은 많은 연구들이 그렇듯 시뮬레이션 된 low-cost 환경에서 synthetic data를 통한 데이터 증대의 방향을 택했다고 합니다. 하지만 이는 근본적으로 시뮬레이터와 Real 환경과의 Domain gap을 메꿔야 하는 과제가 있습니다. 저자들은 많은 이유들 중 단조로운(특정 환경에만 특화된) 데이터만 생성했던 기존 Real to Sim to Real의 방식의 한계를 지목했습니다. 이를 해결하기 위한 데이터 증강 연구들이 있었지만, 새로운 장면을 생성할 때 3D 공간 정보의 부족으로 인해 기하적으로 완벽하지 못 한 구성을 가졌다고 합니다. 이를 3DGS를 활용해 해결한 RoboSplat을 제안했고, 이는 pick and place와 같은 간단한 task부터 long horizon task 까지 평균 57.2%의 성능 상승을 보여주었던 2D정보를 통한 데이터 증강과 비교해 평균 87.8%의 상승을 보였다고 합니다.
뿐만 아니라, 저자들은 일반화 능력을 위해 LLM이나 VLM 모델을 도입해 모델 자체의 일반화 능력을 갖도록 하는 연구보다는 고품질이고 다양한 데이터를 생성하는 과정을 통해 policy 자체에 일반화 능력을 부여하는데 집중했다고 합니다. 저도 물론 결국에는 일반화 능력을 지닌 모델이 등장하는것이 모두가 생각하는 로봇을 만드는 것이라고 생각하긴 하나 과제나 특정 상황을 생각해보면 해당 방향의 연구도 굉장히 가치가 있다고 생각합니다,, 구체적으로 어떻게 해당 연구를 진행했는지 알아보도록 하겠습니다.
Method
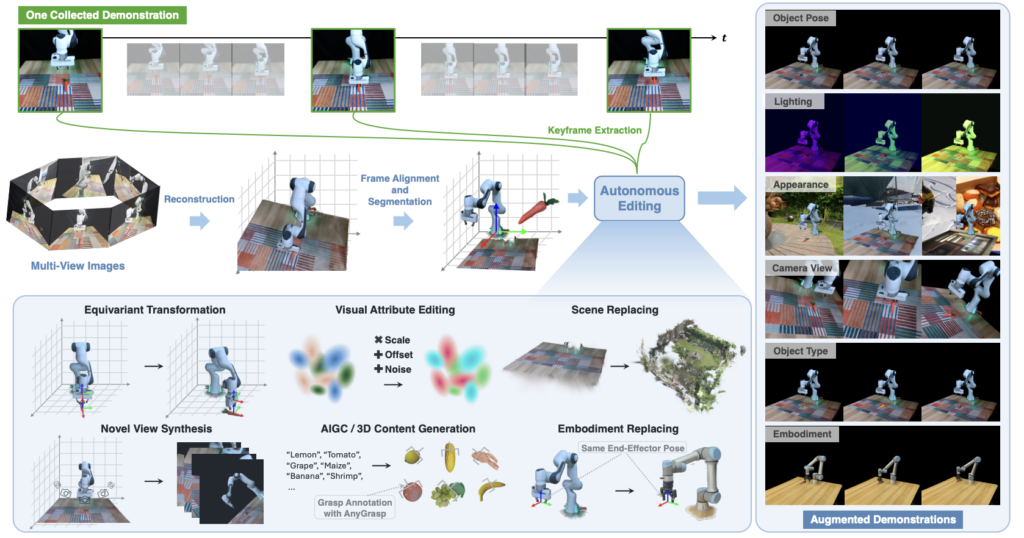
전체적인 Overview를 보자면 우선 input으로는 하나의 인간이 수행한 manual한 영상 데이터와 scene 전체를 담은 multi view 이미지들이 필요합니다. 영상은 전체를 사용하지 않고 task와 밀접하게 연관된 특정 keypoint frame들을 추출해 사용하고, multi view 이미지들은 3D scene reconstruction을 위해 사용한다고 합니다. 3D Reconstruction된 scene에서의 좌표계를 현실과 정렬한 뒤에는 장면을 객체, 로봇, 배경 등 개별 요소로 나누어 처리한 뒤 자동화된 Editing을 수행한다고 합니다. 해당 연구실에서 진행했던 Re3Sim이라는 연구 또한 전경과 배경을 분리한 채로 로봇과 대상 객체의 위치를 랜덤으로 자동화해서 여러 IL용 데이터를 만들었던 만큼, scene 자체를 reconstruct 하고 segment해서 고도화시킨 것 같습니다. Object Pose만 변경 가능했던 Re3Sim과는 다르게 Robosplat에서는 Object pose, Object type, Camera view, Lightning Condition, Scene appearance, Robot Embodiment의 augmetation을 진행한다고 합니다. 각 요소들에 대해 조금 더 자세히 살펴보도록 하겠습니다.
Reconstruction and Preprocessing
우선 scene reconstruction을 위한 high fidelity 이미지들을 static한 scene으로 부터 촬영해줍니다. 로봇을 항상 기본 자세로 고정시켜 둔다고 합니다. 이후로는 다른 3DGS reconstruction 기법들과 마찬가지로 COLMAP을 통한 sparse한 재구성과 카메라 포즈를 얻는 과정을 거치고, Depth정보는 Depth Anything을 통해 구한다고 합니다. 실제로 사용해보진 않았지만 다양한 연구에 활용되는 만큼 Depth Anything도 정말 다양한 scene에서 좋은 성능을 보여주는 것 같습니다. (Scene 자체가 복잡하지 않은 구성이어서 더 활용도가 좋을 수도 있지 않았을까 생각이 들긴 합니다.) 획득한 RGB이미지, 카메라 포즈, depth map을 통해 3DGS를 얻게됩니다. 이 때 로봇에 해당하는 Gaussian들은 G_robot으로 따로 분류한다고 합니다. 이후에는 좌표계 정렬을 진행합니다.
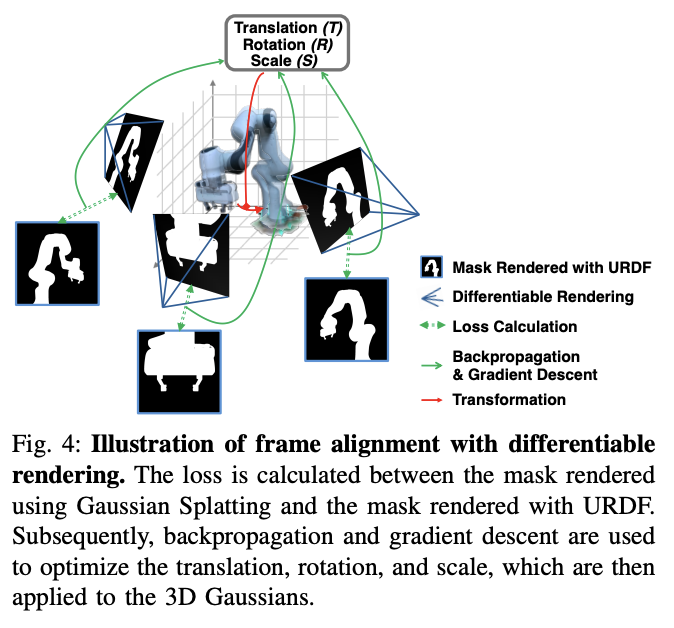
좌표계는 재구성된 scene 자체의 좌표계인 F_scene과 로봇 URDF의 기준 좌표계인 F_URDF를 정렬한다고 합니다. 실제 세계에서는 F_robot, F_URDF, F_real이 모두 정렬되어있기 때문에, F_scene을 F_URDF로 변환해주는 T_URDF,scene을 구하는 것이 핵심이라고 합니다. 이를 위해 기존에는 가장 가까운 점들을 반복적으로 매칭하고, 매칭쌍들을 제일 가깝게 만들어주는 변환행렬을 최적화 하는 Iterative Closest Point (ICP)를 활용했는데, 저자들은 해당 방법을 활용할 시에 scale 요소를 가지고있는 3D Gaussian을 변환할 때 좌표간 misalignment가 발생한다고 합니다. 이는 아래의 Fig.3을 통해 확인해볼 수 있었습니다. 저자들은 이를 해결하기 위해 3DGS의 differentiable rendering요소를 활용했다고 합니다.
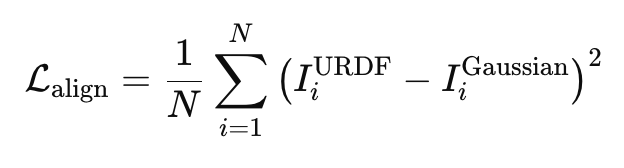
위와 같이 URDF 기반 렌더링에서의 로봇 segmentation 마스크 I_URDF와 재구성된 3DGS의 렌더링으로부터 얻은 로봇의 마스크 I_Gaussian의 MSE를 loss로 활용해 ICP를 통해 얻은 초기의 변환행렬로 정렬된 Gaussian을 추가로 정밀하게 정렬하기 위한 변환행렬 T_rel을 학습시켜 기준좌표계인 F_URDF로 2stage 정렬을 진행한다고 합니다. 결과적으로 아래 Fig3의 오른쪽 처럼 fine-grained optimization이 가능하다고 합니다. 아래 Fig 4를 참고하시면 될 것 같습니다.

Scene을 정렬한 뒤에는 Decomposition 또한 진행합니다. 이전 연구와 다르게 이 과정을 통해 다양한 augmentation을 자동화 할 수 있는 만큼 프레임워크에서 핵심적인 부분이 아닐까 생각하고 있습니다. 우선 Grounded-SAM을 활용해 각 객체들과 로봇 link에 대한 3D Gaussian을 구합니다. 이후 로봇의 경우 URDF를 통한 pointcloud를 생성해 F_URDF로 정렬한 뒤, pointcloud로 부터의 거리를 thresholding해서 Gaussian이 link에 해당하는지를 판단 한 뒤 로봇을 segment한다고 합니다. 객체들은 Grounded-SAM으로 부터 재구성한 pointcloud를 마찬가지로 F_URDF에 정렬시켜 동일한 방법으로 segment한다고 합니다. 대상 객체와 로봇으로 매칭되지 않은 나머지 모든 Gaussian들은 배경으로 정의한다고 합니다.
Frame을 정렬하고 객체와 로봇, 배경을 분리한 이후에는 카메라 포즈를 정렬합니다. Real to Sim의 핵심이 실제 환경과 잘 정렬된 3D scene인 만큼 아래의 SSIM 기반 Loss를 통해 진행한다고 합니다. 이는 해당 환경에서 생성할 새로운 시연 정보들이 실제 환경의 관측처럼 보이게 하는 중요한 단게라고 합니다. 정리하자면 촬영된 데이터에서 획득한 이미지와 3D Gaussian에서 렌더링된 이미지 간의 SSIM을 통해 카메라 포즈를 최적화 해줍니다.
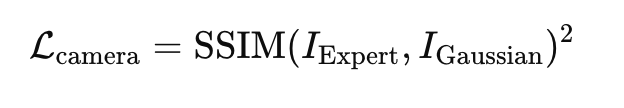
마지막으로는 3D Gaussian에서 렌더링된 로봇의 joint configuration 과정을 거칩니다. 3DGS를 통해 기하적인 요소만 복원이 되어있는 상태이기 때문에, 이전에 로봇인지 아닌지 segment하기 위해 사용했던 robot gaussian들을 로봇의 기본자세로 정렬시키고 특정 링크에 대해 기준 프레임에 대한 상대적인 pose를 forward kinematics로 계산해 아래와 같은 변환 T_fk(q)를 얻고 이를 통해 링크의 Gaussian을 업데이트 한다고 합니다. 이를 모든 링크에 대해 수행해서 로봇의 움직임을 3D Gaussian에 반영할 수 있게 된다고 합니다.
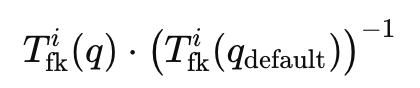
정리를 해보자면, 3D scene을 3DGS로 재구성한 뒤, 좌표계(F_URDF를 기준으로)와 카메라 포즈를 정렬하고, 로봇과 객체를 segment 한 뒤 3DGS 상에서 로봇의 기구학을 구현하기 위한 과정까지 거친다고 보시면 될 것 같습니다.
Novel Demonstration Generation
이제 준비된 scene을 통해 각종 다양한 augmentation을 진행합니다. Object Pose, Object Type, Camera View, Embodiment Type, Scene Appearance, Lightnin Condition 총 6가지의 augmentation을 진행하게 됩니다. 기존에도 각 요소들을 augmentation 하는 방법들은 존재했지만, 이를 3DGS 상에서 직접 augmentation하지 못 했다는 한계가 있었는데, 이를 3D상에서 진행해 더욱 더 효과적인, 자동화된 augmentation이 가능했다고 합니다. 이를 가능하게 해주는 전처리 과정이 해당 기법의 핵심중에 하나인 것 같습니다. 각 요소들을 살펴보도록 하겠습니다.
Object Pose
우선 real demonstration 데이터에서 heuristic한 방법을 통해 키프레임을 추출한다고 합니다. 그리퍼의 동작이 전환되는 순간이나 joint velocity가 0에 가까워진 순간을 전환점으로 여기고 이 시점들에서의 프레임을 키프레임으로 간주하고, 이 때의 end effector pose를 로봇 베이스 프레임을 기준으로 정리해둔다고 합니다. 이후 target object의 좌표들에 대한 rigid transformation을 진행하고, keyframe에서의 end effector pose또한 동일한 transform을 적용해줍니다. 새롭게 변환된 keyframe 사이 사이의 end effector pose들간의 모션 플래닝을 통해 object pose가 변경된 demonstration을 진행한다고 합니다. 모션 플래닝을 활용해 keyframe을 통한 효율적인 변환이 정말 머리를 잘 쓴 것 같습니다. EE의 pose에 동일한 transformation을 적용하는 것으로 계산을 획기적으로 줄일 수 있는 것 같습니다. 실제로 적용해보지 않아서 새롭게 생성된 demonstration에서의 작업이 항상 전문가 시연 데이터처럼 성공하는지는 의문이긴 합니다만, 글로만 접했을땐 굉장히 타당한 방법인 것 같습니다.
Object Type
Object type을 증강할 때는 해당 task를 수행할 때 대체 가능할 것 같은 물체들 50개를 GPT-4를 사용해 구한 뒤, 이를 3D 콘텐츠 생성 모델의 text query로 활용해 해당 객체들의 Gaussian을 생성한 뒤, AnyGrasp를 통해 새로운 객체 기준의 grasp pose를 생성한다고 합니다. 이후에 grasp pose를 keyframe과 조합해 새로운 end effector의 포즈를 확정짓는다고 합니다. Keyframe별로 augmentation이 끝난 뒤에는 앞의 과정과 동일하게 모션플래닝을 수행해 연결해서 demonstration데이터를 생성합니다. Keyframe이라는 요소도 모션 플래닝과 결합돼 다양한 augmentation을 수행한 demonstration 데이터를 자동화 하는것의 핵심인 것 같습니다. 다만 모션플래닝에 많이 의존하는 만큼 모션플래닝 기법이 지니는 한계를 그대로 지닐 것 같긴 합니다. 또 RoboTwin도 그랬듯 데이터 효율을 augmentation을 통해 챙기는 연구들은 3D generation 모델들을 사용하는 것 같습니다. 생성형 모델들이 엄청난 완성도를 보이진 않아도 의미있는 작업 성공률 향상의 측면에서는 충분한 성능을 지닌다고 판단하는 것 같습니다. 이후에 생성형 모델을 그냥 쓰는 것도 고려해볼만 할 것 같습니다. 데이터 증강 측면에서는 생성형 모델들의 inference 시간도 용인이 되지 않을까 하는 생각입니다.
Camera View
3DGS의 임의의 viewpoint에서의 렌더링이 가능하다는 장점을 통해 다양한 카메라 뷰를 통해 데이터를 증강할 수 있었다고 합니다. 다만 조작 장면을 벗어나는 렌더링을 하는 의미없는 viewpoint를 피하기 위해서 카메라가 에피소드가 진행되는 모든 순간에 무조건 응시해야만 하는 목표지점 O_c를 현실 좌표계 상에서 지정해 O_c를 원점으로 구형의 좌표계로 표현된 camera view를 사용했다고 합니다. O_c는 조작장면 자체로 제한하고, 구면 좌표계는 (r,θ,ϕ)로 표현되는 만큼 각각의 매개변수를 randomize 하여 다양한 랜덤한 viewpoint에서 항상 목표 장면을 포착할 수 있도로 구성했다고 합니다.
Embodiment Type
시연데이터에서 가우시안으로 표현된 로봇을 다른 로봇의 gaussian으로 표현함으로써 구했다고 합니다. 데이터의 구성이 keyframe에서의 객체 포즈와 엔드이펙터 포즈로만 구성이 되어있기 때문에 가능했던 것 같습니다. 이렇게 생각하니 로봇을 포함한 scene 전체를 3DGS로 재구성하는 것과 keyframe추출의 아이디어가 정말 획기적인 것 같습니다. 다른 로봇의 URDF를 통해 생성된 gaussian을 통해 갈아끼우고 같은 방식으로 joint에 대한 forward kinematics를 계산해 렌더링을 업데이트 하는 방식으로 새로운 로봇을 데이터에 추가할 수 있었다고 합니다. 역시 motion planning을 통해 trajectory rollout을 진행하며 데이터를 생성하는 만큼 embodiment type을 바꾸는 과정도 큰 어려움 없이 진행될 수 있었을 것 같습니다.
Scene Appearance
다음은 배경 가우시안들에 관한 내용입니다. 저자들은 training하는 시뮬레이션 환경과 실제 환경간의 시각적 차이의 주요 원인을 scene appearance의 불일치로 꼽았습니다. 텍스쳐의 부족과 같이 실제로 카메라에서 보이는 시각적인 요소의 차이를 최소화 하기 위해서 두가지의 방법을 활용했다고 합니다. 먼저 COCO 데이터셋을 활용해 테이블과 같은 전체 장면의 배경을 담당하는 gaussian plane에 이미지 텍스쳐를 부착했다고 합니다. 이를 통해 바닥의 텍스쳐를 획득할 수 있었다고 합니다. 추가적으로 Deep blending for free-viewpoint image-based rendering의 데이터셋 뿐만 아니라 tanks and temples, scannet, mip-nerf 360 데이터셋을 활용해 이들의 3DGS를 수행해서 novel background gaussian을 가지는 장면들을 구성했다고 합니다. 다만 이렇게 대규모 데이터셋을 3DGS로 다 변환해서 배경을 재구성한다는것을 어떻게 한다는건지, 단순히 그냥 배경만 바꾸는 것인지 다른 변수는 없는지 코드를 통해 확인해봐야 할 것 같습니다.
Ligting Condition
많은 데이터 augmentation 연구들에 등장한 lighting condition입니다. 저는 그렇게까지 의미가 있나 싶었지만 생각해보니 언제나 같은 시간에 같은 공간에서만 로봇을 작동시킬수는 없는 만큼 중요한 augmentation 중에 하나인 것 같습니다. 실내에서도 생각보다 다양한 광원과 광량이 존재할 것 같습니다. 저자들은 광원의 색의 대비를 조절하거나 전체적인 밝기를 조절하거나, 카메라 자체에 noise를 추가하는 방법으로 다양한 lighting condition에 대한 변화를 주었다고 합니다. 이 또한 시뮬레이터상에서 간단하게 파라미터의 변화를 통해 이루어 낼 수 있는 만큼 Real 2 Sim의 이점을 살릴 수 있는 요소가 아닌가 싶습니다. 카메라 noise의 경우 gaussian 자체에 노이즈를 부여해 현실적인 센서 노이즈를 구현할 수 있었다고 합니다.
각종 Generated Demonstration의 결과를 아래와 같이 확인해볼 수 있었습니다.

Policy Training
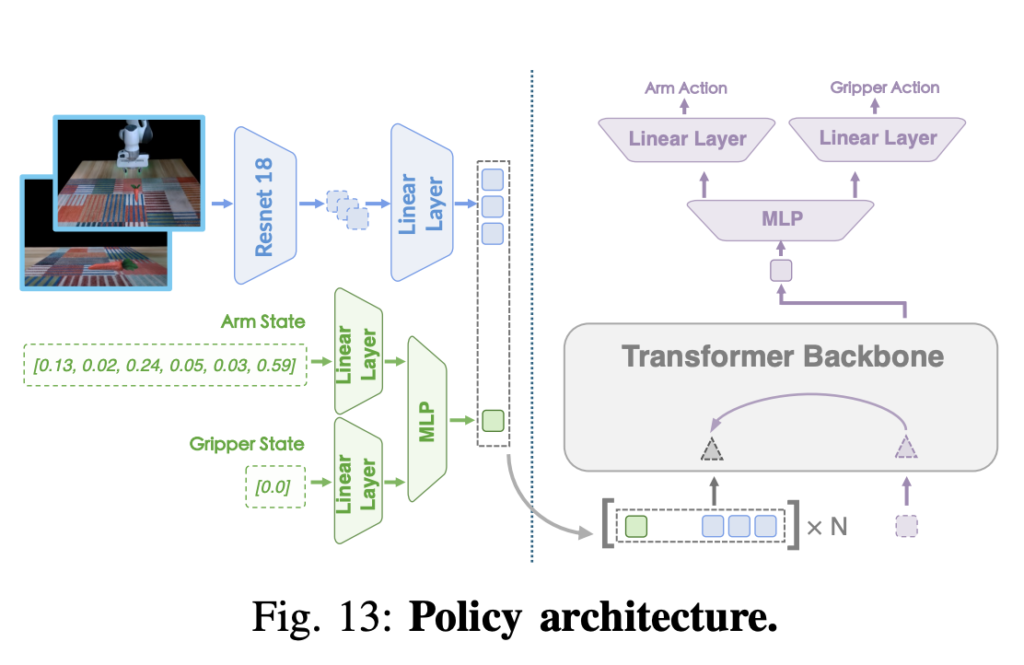
이후에는 augment된 데이터를 통한 검증을 위해 policy training을 진행했다고 합니다. Policy는 Transformer 기반 아키텍쳐인 ACT 모델과 비슷한 구조인 모델을 활용했습니다. RGB 이미지를 ResNet-18을 통해 인코딩 하고, joint state도 MLP를 통해 인코딩 해서 트랜스포머를 통해 출력된 latent가 Action Decoder를 거쳐 최종적인 액션을 생성하는 방식입니다. 자세한 구조는 아래 figure를 통해 확인할 수 있을 것 같습니다. 두개의 eye-on-base의 이미지와 joint state를 입력으로 받게 됩니다. (로봇에 카메라를 달지 않아도 되는 장점 또한 존재하는 것 같습니다.) 256의 batch size로 하나의 RTX4090 GPU를 통해 학습을 진행했다고 하네요. 학습에 걸린 시간에 대한 내용은 확인해볼 수 없었습니다.
Experiments
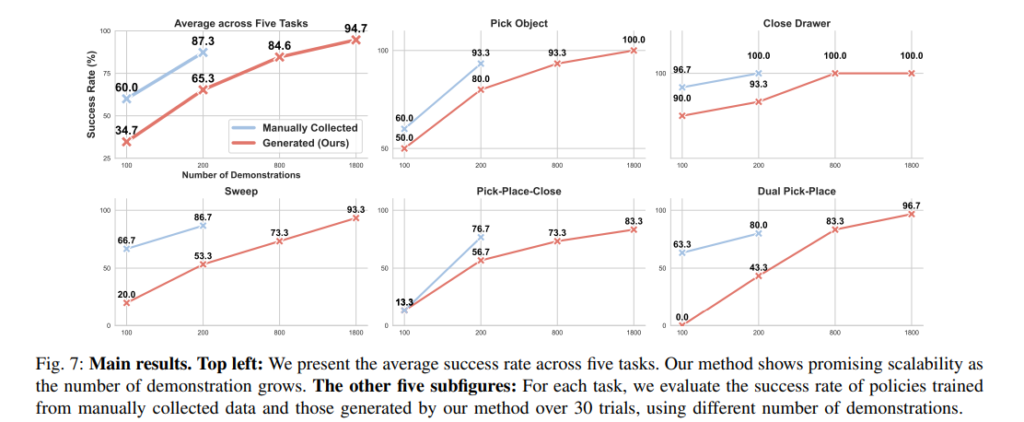
실험또한 실제 환경에서 효과적인지 여러가지 방면으로 진행되었다고 합니다. 단 하나의 One-Shot demonstration 데이터와 multi-view 이미지로 동일하게 실험했고, 실험은 총 네가지 질문들에 답하기 위해 진행됐다고 합니다. 수동 수집대비 얼마나 자동화되고 효율적인가? 수동으로 현실에서 수집한 데이터대비 얼마나 잘 작동하는가? 시연 데이터 양이 증가할수록 성능이 증가하는가? 얼마나 강건한가? 에 대한 답을 제공하는 실험이었다고 합니다. 실험에는 Franka Research 3가 사용되었고, 테이블 위에 고정된 D435i 두대로부터 RGB 이미지만을 받아서 사용했다고 합니다. Real Data는 3D 마우스를 통햏 수집했다고 하네요 (생각보다 3D 마우스를 활용해 teleoperation을 하는 연구들도 많이 보이는 것 같습니다.) 평가 대상의 task는 pick object, close drawer, pick-place-close, dual pick-place(두개의 물체를 연속으로 넣기), sweep 5가지의 task라고 합니다. Long horizon이라고 표현하기는 했지만 비교적 단순한 동작들인 것 같습니다. (쓰읍 pi 0.5도 각 task 자체가 잘 생각해보면 엄청나게 long horizon은 아닌것 같기도 합니다.) 저자들이 아래와 같이 정리해두었습니다. 평가지표로는 30회를 반복한 작업성공률을 사용했다고 합니다.

Efficiency of Augmentation
데이터 증강에는 RTX 4090 PC 8대를 병렬로 사용했고, 시간으로 따졌을 때 사람이 직접 teleoperation 하는 수동적인 수집 대비 29배 이상 빨랐다고 합니다. 당연하겠지만 인간의 개입 없이 자동화된 파이프라인으로 얻을 수 있는 이점을 나타내는 실험이었습니다.

Performance of Policy Trained on Augmented Data
해당 실험은 수동으로 수집한 데이터와 자동 생성된 데이터로 각각 학습한 policy의 성공률을 비교한 실험입니다. 생성한 데이터 수가 증가함에 따라 성능 향상 추이가 어떻게 일어나는지를 보여준 실험이고, 같은 양으로 비교할 수는 없지만, 데이터의 자동 생성으로 다량의 데이터를 만들어 낼 수 있는 만큼 데이터가 늘어나면 늘어날수록 결국 teleoperation한 성능보다 높게 나오는 것을 확인할 수 있습니다. 고품질의 데이터도 중요하지만 결국 일반화 뿐만 아니라 성능을 높이는데는 적당한 수준 이상이라면 데이터의 갯수가 깡패인것을 느꼈습니다..
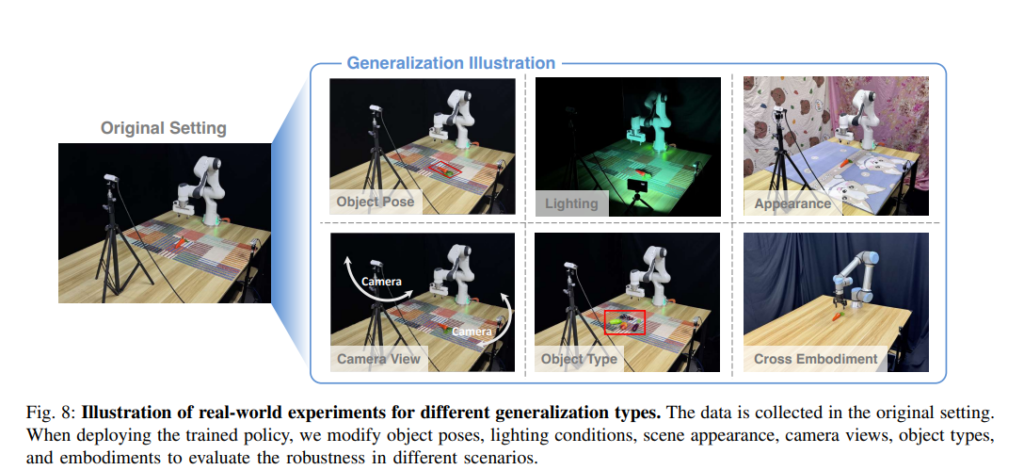
Robustness when Facing Various Deployment Settings
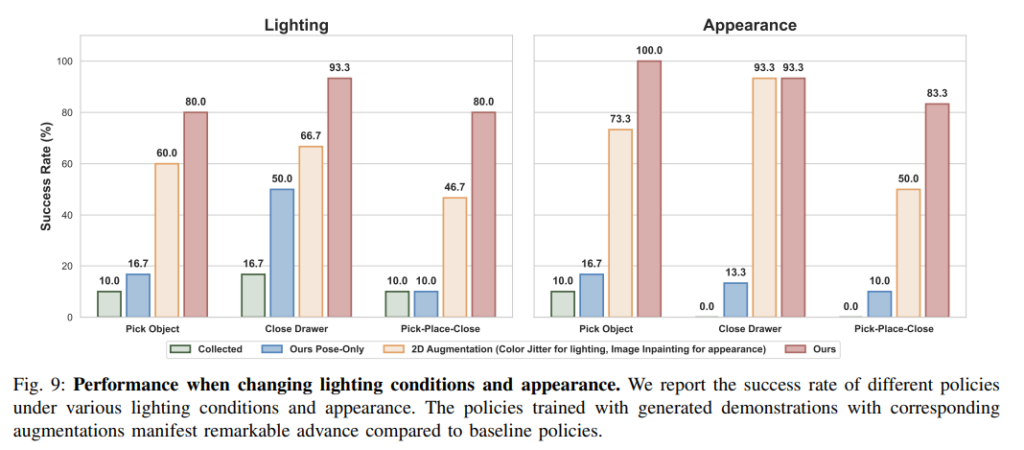
아래 그림과 같이 Lighting, Scene Appearance, Camera View, Object type, Embodiment type을 다양하게 바꿔가면서 robustness를 평가했습니다. Figure 8의 경우 Collected는 수동으로 수집한 teleoperation 200 에피소드, ours pose only는 object pose만 바꾼 데이터 1800개, Color Jitter는 수동으로 수집한 에피소드에 color jitter만 적용한 것이고 마지막 ours는 조명과 object pose를 모두 증강한 데이터 3200개라고 합니다. 왜 갯수가 다 다른지는 의문이긴 합니다,, 성능은 lighting을 변화시켰을때와 배경을 바꾼 appearance의 경우 둘 다 월등히 좋은 성능을 보여줍니다. 다만 수동으로 데이터를 수집한 경우 (배경 증강이 없는 경우) 배경 appearance를 바꿨을 때 작업 성공률이 확 떨어져버리는 모습을 보고 좀 충격먹었습니다,, 이렇게 되면 배경을 바꿔가면서 데이터를 수집해야 하는게 필수적이지 않나 싶습니다..
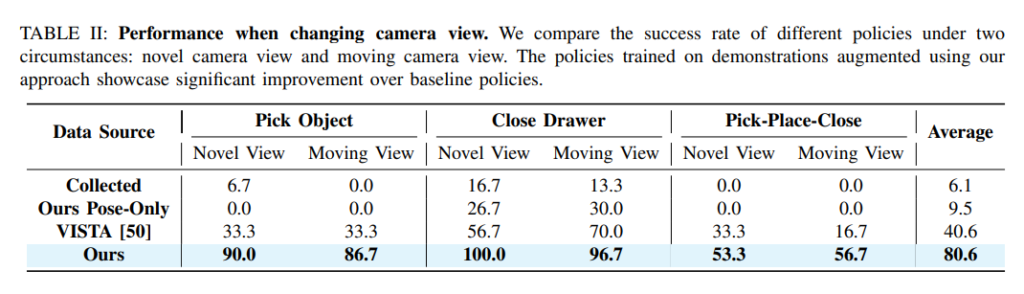
Camera view 같은 경우는 훈련 시점과 다른 30개의 카메라 시점과 카메라를 움직여가면서 실행했을 때를 의미합니다. Collected는 실제 데이터 200개, pose only는 마찬가지로 pose만 증강한 데이터 1800개, VISTA는 VISTA기반의 novel view 증강한 데이터 3200개, 마지막은 전체 파이프라인을 거친 데이터 3200개 입니다. 시점이 바뀌는 경우 역시 데이터 증강은 필수적이라고 느꼈고, VISTA도 여러가지 연구에서 비교군으로 등장하던데 한 번 살펴봐야 할 것 같습니다.
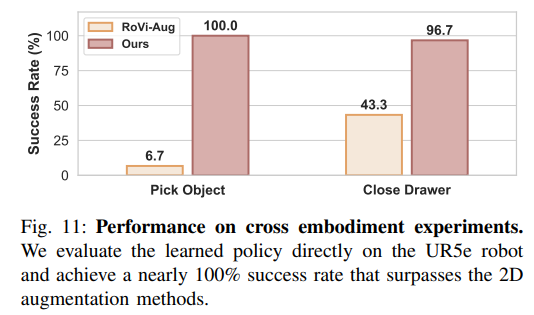
Embodiment Type
UR5e에 robotiq 2F-85 그리퍼를 장착한 채로 작동시키는 실험이었습니다. RoVi-Aug는 시연 데이터에서 로봇의 외형만을 다른 로봇으로 바꿔주는 모델이라고 합니다. Gaussian 자체를 불러오고 정렬해서 Kinematics까지 적용시켜서 업데이트 하고 해당 로봇을 기반으로 trajectory를 만들어 학습하는 만큼 높은 성공률을 보이는 것을 볼 수 있습니다.
Conclusion
여러가지 일반화 측면에서 좋은 성능을 보여주고, 특히 하나의 시연 데이터만으로, 또 증강 자체는 자동화된 프로세스로 가능한 것이 장점인 연구인 것 같습니다. Keyframe을 활용하는 방식이 인상깊었습니다. 다만 3DGS의 구조적인 한계로 인해 deformable object나 physics적인 측면을 고려한 dynamic task에는 부적합하다고 합니다. 다만 최근 3DGS쪽의 연구에서 다양한 physics나 deformable object들이 고려된 연구들이 등장하는것으로 보아 어느정도 해결이 가능하지도 않을까 하는 생각이 들기도 합니다. 또한 이 논문을 보면서 정말 데이터의 다양성과 양이 중요하고, 이를 위해서는 효율을 고려해 Real to Sim이 정말 필요하다는 생각이 더 강하게 들었습니다.
안녕하세요 영규님, 좋은 리뷰 감사합니다.
단순한 태스크에 대한 데이터 수집에 있어 efficiency가 진짜 좋아진 결과를 보니 놀랍습니다. keyframe이 인상깊은데, keyframe 추출하는 방식이 제가 예전에 리뷰한 Q-attention에서의 그것과 heuristic한 방법론이 완전 동일해서 혹시나 본 논문의 citation을 뒤져봤는데 또 Q-attention은 없는 건 의아하네요. 우연히 겹친건가.
아무튼 keyframe이라는 것이 heuristic한 기준으로 추출이 되다보니, 일정한 time step마다 추출되는 것이 아니라 굉장히 time 간격이 먼 keyframe간의 motion planning에 의존 시 해당 추정이 꼬이면 그 다음 pose로의 motion planning도 연쇄적으로 꼬이는 문제가 생길 수 있을 것 같은데요. 그렇게 되면 augmentation 시 noisy한 trajectory가 많이 생성되지 않을까란 생각이 듭니다. 이후 grasp pose와의 연계도 동일하구요. keyframe에서의 휴리스틱한 방식 + motion planning 이외의 다른 방식에 대한 future work가 필요할거라는 언급도 있었나요?
안녕하세요 재찬님 댓글 감사합니다.
저도 그 부분이 살짝 의아하긴 합니다. 기존에 Re3Sim에서는 그런 경우를 방지하고자 모션플래닝을 하고나서 작업을 끝냈을 때 목표 지점과 목표 객체 사이의 거리를 통해서 데이터의 품질을 정하고 일정 수준 이하인 데이터들은 골라냈었던 것 같은데, Re3Sim은 작업의 시작부터 끝까지 한 번에 진행하는 것과 달리 keyframe 사이의 간격이 좁아서 (그리퍼가 움직일 때 이외에도 joint velocity가 낮아지면 keyframe으로 간주합니다) motion planning이 실패하는 경우를 그냥 무시하는 것은 아닐까 생각이 듭니다,, 논문에는 해당 관점에 대한 이야기가 명시적으로 나와있지 않습니다. 어쨌든 잘 되지않냐 하는거 같은 느낌입니다. 코드도 없어서 아직 확인을 못 해봤습니다
안녕하세요 영규님 좋은리뷰 감사합니다.
해당 논문리뷰를 완벽하게 이해한 것은 아니지만 문득 질문할 것이 생각나서 질문드립니다.
로봇 학습에 있어서 일반화 성능을 올리기 위한 여러 augmentation 기법을 연구하고 있는 것 같습니다.
궁금한점은 만약 모든 상황에 대해 전부 학습이 된 상태여도, 로봇이 지금 상황이 학습된 상황과 동일한 상황인지 인지하는 것도 중요하다고 생각하는데, data augmentation으로 학습된 상항과 지금 상황이 동일한 상황이라면 이것을 로봇환경에서 어떻게 판단하나요? 해당 상황에서 주어진 task 를 잘 수행하는지 여부로 학습이 잘 됐는지 판단할 수 있는건가요? 아니면 로봇이 생각하는 현재 환경과 학습환경이 일치하는지 판단하는 다른 기준이나 점수같은게 존재하는지 궁금합니다.
안녕하세요 인택님 댓글 감사합니다.
질문을 여러 augmentation 기법들의 목적이 데이터를 늘려서 새롭게 생성된 data내의 scene과 실제 환경이 일치하는 경우를 만드는 것인데, 로봇이 어떻게 동작시의 실제 scene과 같은 scene을 증강된 데이터들 안에서 찾을 수 있는지를 질문해주신 것일까요?
augmentation 같은 경우는 현재 환경과 완전히 일치하는 장면을 찾아내기 위한 저장소를 만드는 개념은 아니고 분포 전체에 대한 불변성을 학습시켜서 새 환경에서도 올바른 행동을 하도록 일반화 범위를 넓혀가는 과정입니다. 학습된 정책 자체가 카메라로부터의 관측을 통해 어떤 행동을 할지 바로 뱉어내는 과정만 존재하기 때문에 관측이 항상 파라미터화된 분포 안에 충분히 가깝다는 전제로 동작합니다. 기하적인 관계가 같다면 학습한 대로 행동할 수 있습니다.
이해 안 되시는 부분 다시 질문 해주시면 저도 더 찾아보고 이해시켜드리겠습니다,, 하하