이번 리뷰 논문은 DUST3R이라는 dense feature matching 기법으로 획을 그은 DUST3R라는 연구의 2장 이상의 영상들로 재구성을 수행했을 때의 시간 문제를 해소하기 위해서 제안된 기법입니다. 해당 기법을 통해 현실적이고 높은 성능을 가진 3D 재구성이 가능해질 것으로 전망됩니다.

Intro
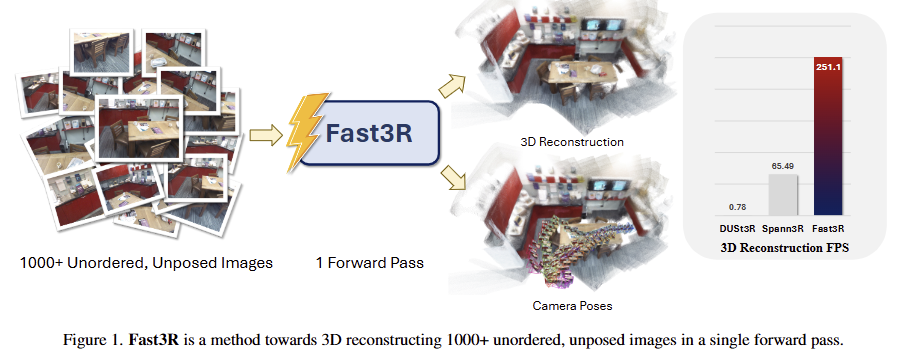
Multi-view 3D reconstruction은 로보틱스, 자율주행, 그래픽스 등 3D 비전을 이용하는 어플리케이션에서는 매우 중요한 기술에 해당합니다. 해당 기법은 전통적인 기법인 Structure from Motion (SfM)과 Multi-View Stereo (MVS)와 같이 3D scene을 구성하는 데에 있어 카메라 기하학을 이용하는 기법들이 주류였습니다. 최근 DUST3R의 등장으로 새로운 패러다임이 등장합니다.
새로운 패러다임에 설명하기 앞서서 기존 기법들을 모르시는 분들을 위해서 간단하게 설명하고 넘어가도록 하겠습니다. 먼저, SfM은 COLMAP이라는 기법을 대표적인 기법에 해당하는 방법론으로 연속된 영상으로부터 카메라 파라미터와 포즈를 구하면서 point cloud를 동시에 추정하는 기법이라고 보시면 됩니다. 파이프라인에 대해서 설명하는 것이 연구원들 분에게 조금 더 친숙할 것 같네요.
SfM 파이프라인 [1. 특징 검출 및 매칭, 2. 매칭쌍의 관계를 이용하여 essential/fundamental matrix 추정으로 상대적인 카메라 pose 추정, 3. 삼각 측량 기법을 이용해 3D point cloud의 위치를 추정, 4. bundle adjustment를 이용하여 카메라 파라미터 및 포즈를 최적화.]
영상에서 매칭된 포인트만을 이용하기 때문에 sparse하다는 낮은 단점을 가지고 있으며, 연속된 영상 간의 오버랩되는 영역의 품질에 영향을 크게 받는 다는 문제점이 있었습니다.
MVS는 SfM이 sparse한 문제점을 해결하는 기법으로 SfM으로 추정된 카메라 파라미터를 기반으로 픽셀 혹은 패치 단위의 매칭을 통해 깊이 정보를 추정하여 dense한 3D point cloud를 추정하는 것이 목적입니다. 해당 기법은 dense한 3D point cloud를 추정 가능하지만, 오버랩 품질과 testureless한 영역에서 저조한 성능을 보인다는 것과 사전 계산된 카메라 파라미터와 카메라 포즈에 의존적인 한계가 존재합니다.
DUSt3R에서는 위와 같은 문제들을 해결 가능한 패러다임을 제시합니다. 기존 전통적인 기법들이 2D 영상으로부터 매칭 쌍을 기반으로 하며, 카메라 파라미터와 카메라 포즈를 알기 위한 사전 정보를 요구하거나 정확도에 영향을 받는 것과는 다르게 no-calibration, no-pose 2D 영상들을 입력 받아 강인한 3D reconstruction 결과를 보여주었습니다.
방식은 생각보다 단순한데요. “각 영상들을 개별적으로 global coordinate에서의 3D point map을 추론해서 합치면 끝”입니다. 학습 방법도 단순한데요. global coordinate의 point cloud를 추론하기 위해서 메인 카메라에서 관찰된 영상에서의 coordinate를 기준으로 각 시점의 영상들의 point cloud를 직접 회귀하여 학습을 진행하는 방식을 이용합니다.
+ 이처럼 단순한 방법으로 학습이 가능했던 이유는 CroCo (신정민 연구원이 리뷰한 글 참고)가 백본으로 사용됨이 가장 큰 이유라고 봅니다. CroCo는 두 영상 간의 기하학적 일관성을 포착하는 데에 큰 기능을 함으로써, 직접적으로 coordinate를 일치 시키는 함수를 모델링 하지 않아도 암시적으로 두 시점 사이의 좌표를 일치 시킬 수 있는 능력을 가져 가능했던 것으로 보입니다.
++ global coordinate에서의 n 시점의 3D point map은 ICP를 이용하여 다시 한번 최적화를 수행합니다. 해당 과정 중에 각 시점의 camera pose 추론도 가능합니다. (이와 유사하게 point cloud를 영상에 사영시켜 포토메트릭 에러를 기반으로 카메라 파라미터에 대한 추론도 가능합니다.)
no-calibration, no-pose에다가 dense point cloud를 예측하며, 오버랩된 시점이 적어도 예측이 가능한 DUSt3R의 등장으로 3D reconsturction에는 큰 반향을 일으켰습니다. 두 영상 간의 매칭만 end-to-end만 가능했던 DUSt3R에 이어 다중 뷰를 동시에 추론 가능한 MASt3R도 등장하게되었습니다. 허나, 두 기법들은 영상의 수가 증가함에 따라 VRAM이 급격하게 증가하며, 이에 따라 추론 속도가 크게 증가하는 문제가 있었습니다.
저자는 다중 뷰를 한번에 end-to-end로 예측 가능하며, 빠르고, 연산 효율적인 FASt3R을 제안합니다. 해당 기법에서는 MASt3R과 유사하게 global coordinate에서의 point cloud를 예측하는 global head와 local coordinate에서의 point cloud를 예측하는 local head를 추가할 것을 제안합니다. global head에서는 2D-3D geometry + global로 변경하는 rigid transform을 최적화 해야만 하는 것에 반해, local head는 pixel 당 point cloud만을 예측하면 되기 때문에 복잡도가 낮아져 학습 효율성을 높이는 효과를 보인다고 합니다.
+ MASt3R에서는 local matching을 수행하는 head를 추가하는 방식을 이용합니다.
또한, 1000장의 영상들까지 확장이 가능하되, 적은 수의 영상(<30)으로 학습이 가능하도록 하기 위해서 Image index positional embedding을 제안합니다. 마지막으로 효율적인 연산을 하기 위한 model parallelism, data parallelism, FlashAttention…과 같은 기성 기법들을 사용했으며, 이에 대한 효과를 보여줍니다.
+ (model parallelism, data parallelism, FlashAttention…)은 Hugging face, DeepSpeed와 같은 라이브러리에서 제공하는 기능을 사용했다고 합니다. 새로운 기법을 적용한 것은 아니고 여러 학습과 추론 효율성을 위해서 최신 기법을 사용했다고 합니다.
++ 저자의 소속이 Meta인데 이와 유사하며 같은 meta에서 출판한 MV-DUSt3R는 CVPR 2025 oral을 받고 해당 논문은 못 받은 이유는 효율성을 위한 방법이 새로운 기법은 없고 테크닉하다는 측면이 약한 기여도로 인정 받아 못 받은 건 아닐까 싶습니다.
Method
intro에서 말이 길었는데요. 사실 기법은 아주 간단합니다. 디테일한 내용들은 DUSt3R로 넘기는 경향이 있어서 가능한 빨리 DUSt3R에 대한 리뷰를 작성하도록하겠습니다.
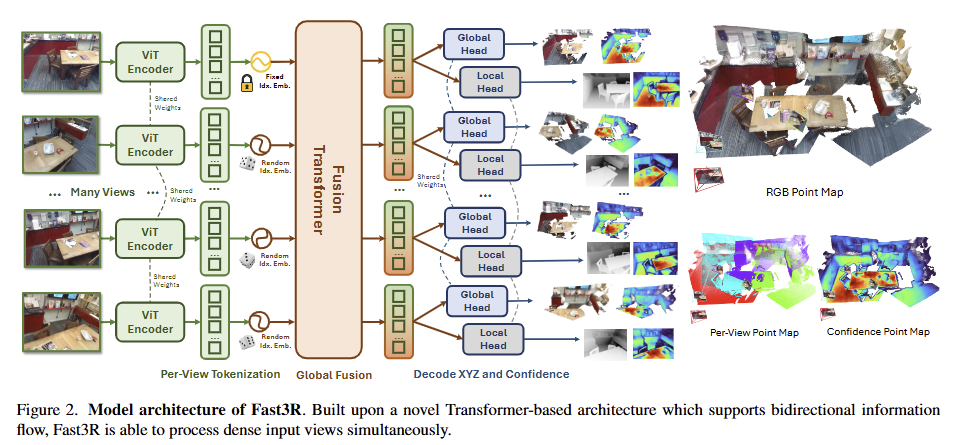
전반적인 모델 구조는 fig 2와 같은 구조를 가지고 있습니다. Fast3R은 transformer-based model이며, unordered/unposed images를 입력으로 받아 3D point map을 예측하는 것을 목적으로 합니다. 저자는 1000장의 영상들로도 확장이 가능하되, 학습 중에는 image masking하여 적은 수의 영상만으로 학습 하는 것을 목적으로 합니다.
Problem definition
먼저, N 장의 unordered/unposed images I \in \mathbb{R}^{N \times H \times W \times 3} 를 입력으로 받습니다. 그럼 이에 대응되는 point map X \in \mathbb{R}^{N \times H \times W \times 3} 를 출력하는 것이 목적입니다. 각 point map은 image I 내 인뎅싱된 3D location들로 이를 이용하여 camera pose, depth, 3D structures를 도출 할 수 있습니다.
Fast3R은 두 point maps을 예측합니다. local point map X_L 와 global point map X_G 그리고 이에 대응되는 confidence maps \sigma_L, \sigma_G [latex]로 구성됩니다. 그럼 전반적인 Fast3R은 N 장의 RGB images를 N local and global point maps으로 맵핑하는 구성입니다. 여기서 global point map은 첫 번째 카메라의 좌표계로 구성되며, local point maps은 각 영상의 카메라 좌표계에서 구성됩니다.</p> <p><strong>Training Objective</strong></p> <p>Fast3R의 예측인 [latex] (\hat{X}_L, \hat{\Sigma}_L, \hat{X}_G, \hat{\Sigma}_G) 는 DUST3R의 loss를 기반으로 한다고 합니다.
전체 loss는 global and local point map을 위한 point maps losses로 구성되며 다음과 같습니다.
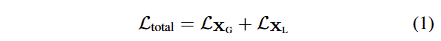
이는 confidence-weighted가 가해진 normalized 3D point-wise regression loss에 해당합니다.
Normalized 3D pointwise regression loss. point maps X에 대한 normalized regression loss는 Dust3R 혹은 monocular depth estimation [e.g. InstanteSplat, Depth anything]의 multi-view 버전으로 보시면 됩니다. 이는 mean Euclidean distance로 normalized predicted pointmaps와 normalized target pointmaps 사이의 L2 loss로 다음과 같습니다.
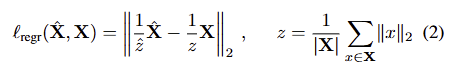
주의할 점이 예측값과 targets은 각각 독립적으로 정규화를 진행합니다.
Pointmap loss. DUSt3R와 동일하게 confidence-weighted loss를 사용합니다. 이는 다음과 같습니다.
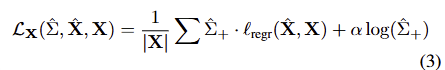
수식 3의 log term은 confidence score가 positive이도록 유도하는 수식으로 \hat{\Sigma}^+ = 1 + exp(\hat{\Sigma}) 을 사용합니다. 여기서 confidence weighting은 모델이 label noise에 강인하도록 하는 것을 목적으로 합니다. 예를 들어 glass나 얇은 구조를 가진 경우에는 GT로 사용하는 laser scans으로도 재구성하기가 어렵습니다. 혹은 컬러 값과 3D point cloud 간의 misalignment로 에러가 누적되는 경우가 있을 수 있습니다. 이에 강인함을 가져가기 위함이라고 합니다.
Model architecture
Fast3R은 3가지 구성, image encoding, fusion transformer, point map decoding으로 설계되어 있습니다. 해당 구성은 fig 2에서 확인 할 수 있습니다. 저자는 Fast3R은 영상을 정렬하지 않고, 순차적으로 예측하지 않고 한번에 입력한다는 점을 강조합니다.
Image Encoder: Fast3R은 각각의 영상 I_i 을 입력 받아 feature extractor F에 인코딩하여 patch features H_i 를 출력합니다. 이를 정리하면 다음과 같습니다.
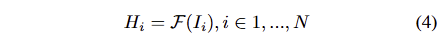
여기서 f는 DUSt3R과 동일하게 CroCo ViT를 이용합니다.
image patch features H를 fusion transformer에 입력하기 전에 position embeddings으로 images index positional embeddings을 추가합니다. Index embeddings은 fusion transformer가 patch들이 같은 영상인지, 첫번째 프레임의 영상의 정보인지... 즉, global coordinatex frame에 대한 정의에 중요한 작용을 합니다. 또한, 모든 영상으로 생성된 tokens에 대한 순열 불변성과 결합되어 암시적인 camera pose를 추론하는데에 작용하게 된다고 주장합니다.
Fusion Transformer: Fast3R의 대부분의 연산은 해당 모듈에서 발생한닥 합니다. 해당 모듈은 ViT-L과 유사한 24-layer transformer를 사용한다고 합니다. 해당 모듈은 모든 시점의 영상을 서로 고려하기 위해서 all-to-all self-attention으로 구성됩니다. 해당 operation은 모든 시점의 영상들이 서로의 정보들을 고려하여 쌍으로만 제공되던 정보를 모든 시점의 전체적인 맥락을 제공하는 기능을 하게 됩니다.
Pointmap Decoding Heads: 마지막으로 Fast3R은 두 개의 분리된 DPT decoding heads를 이용하여 local and global point maps, confidence maps을 예측합니다.
+ DPT는 depth anything에서 제안된 decoding으로 대체로 depth anything v2에서 공개한 weight를 불러와서 사용합니다.
Image index positional embedding generalization: 저자는 해당 모델이 학습에 사용된 시점의 수보다 추론에서 더 많은 시점 수를 받아 재구성하기를 원했습니다. 이를 위해서 시점에 대한 embedding을 학습 때와 추론 때도 일치 시키기 위해서 동일한 Spherical Harmonic (SH) frequencies*로 시점을 임베딩하여 학습을 수행합니다. 추가로 더 많은 영상을 사용하기 위해서 많은 문맥을 이해해야 하는 ~ 가변이 큰token을 입력 받아야 하는 LLMs에 영감을 받아서 postion interpolation을 적용합니다. 저자는 N=1000을 사용하여 수집 받는 token의 최대 수를 고정합니다. 학습 중에는 N'<30의 영상만 사용하고 1000 이내에서 랜덤하게 index를 부여해 token을 채웁니다. 나머지는 zero padding을 하여 masking을 하여 적용합니다.
* SH는 NeRF나 3D GS에서도 컬러 정보를 고차원으로 임베딩 시켜 안정화 시키기 위한 수단으로 사용됩니다. 여기서는 6차원을 가진 시점을 보다 높은 차원으로 임베딩 시켜 차원 저주를 완화 시키는 것이 목적이라고 생각하시면 될 것 같습니다.
Memory-Efficient Implementation
해당 파트는 연산 효율성을 확보하기 위해서 사용한 기술들에 대한 설명이 있습니다만... 기성 기법들을 사용해서 model parallelism, data parallelism, tensor parallelism, FlashAttention 등을 사용했다고 합니다. 궁금하신 분들은 논문을 참조해주시길 바랍니다.
Experiments
Training Data. 학습을 위해 real-world object centric and scene scan data를 섞어 구성했다고 합니다. 데이터 셋은 CO3D, ScanNet++, ARKitScenes, Habitat, BlendedMVS, MegaDepth로 구성됩니다.
Architecture Details. 아래 캡쳐본 참고

Training Details. 영상들은 가장 긴 길이가 512가 되도록 resize함. 174K steps을 AdamW로 0.0001로 cosine annealing schedule을 이용함. DUSt3R과 다르게 staged training을 하진 않았다고 합니다. (아마 체크포인트를 가져다가 사용해서 가능했던 것 같습니다.) GPU는 128개의 A100-80GB로 6.13 days를 학습에 사용했다고 합니다.
+ multi-view dataloaders에 대한 정보와 효율적인 학습을 위한 FlashAttention, DeepSpeed ZeRO 사용법에 대한 적용 방식에 대한 설명도 있습니다. 관심 있으신 분들은 참고 부탁합니다.
Inference Efficiency
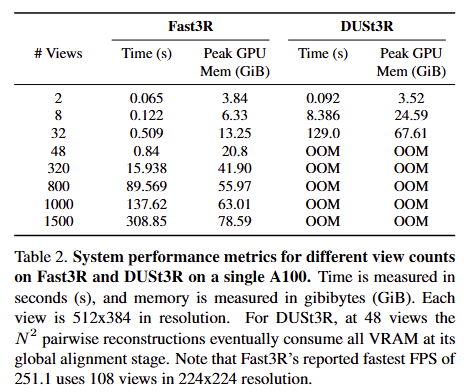
기존 DUSt3R은 48부터 OOM이 발생한 것에 반해 Fast3R은 1500장 이상에서도 잘 동작하는 결과를 보여주며, 추론 속도 또한 많은 차이를 보여줍니다. 모든 실험은 A100 한장에서 진행되었습니다.
+ 이와 별개로 tensor parallelism을 사용하는 방법에 대해서 작성되어 있으나, 테크닉한 내용이라 관심있으신 분은 논문 참조
Camera Pose Estimation
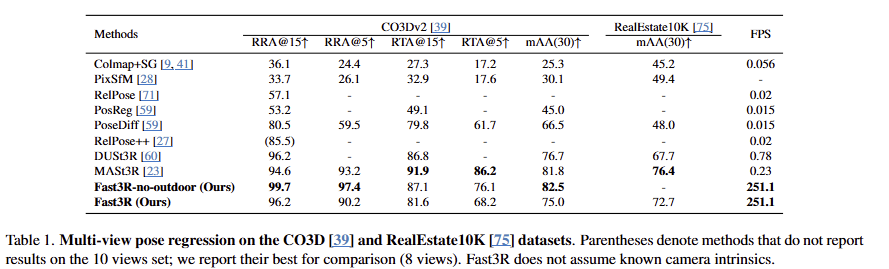
DUSt3R와 동일하게 예측된 point maps에 대해 RANSAC-PnP를 적용하여 focal length, camera rotation, camera translation 예측이 가능합니다. (confidence가 상위 15%인 point만 이용) tab 1에서 15도 까지의 Relative Rotation Accuracy (RRA) and Relative Translation Accuracy (RTA)과 30도 에서의 mean Average Accuracy (mAA) 비교를 통한 camera pose에 대한 정확도를 보여줍니다. 또한 FPS도 같이 보여줍니다.
베이스인 DUSt3R 뿐만이 아니라 DUSt3R에 multi-view를 고려한 Mast3R 조차도 뛰어넘는 성능을 보여주는 것 뿐만이 아니라 FPS도 1000배 가까이 빠른 속도를 보여줍니다.
3D Reconstruction

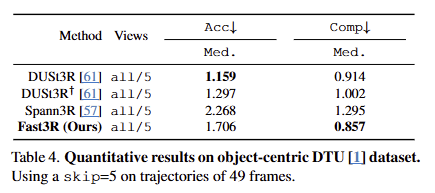
3차원 재구성 성능 또한 scene data인 7-Scenes, NRGBD (tab 3), object-centric DTU (tab 4)에서 베이스라인 대비 뛰어넘거나 준하는 성능을 보여줍니다.
Ablation Studies
Scaling the number of views

fig 4에서는 다른 기법 대비 카메라 포즈의 정확도가 시점의 수에 대한 영향을 덜 받는 것을 볼 수 있습니다. 이를 통해서 index position embedding과 fusion transformer의 이점을 증빙
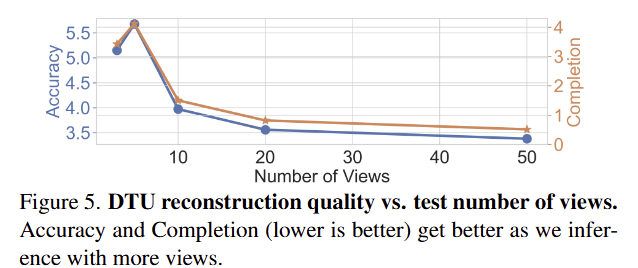
fig 5에서 시점의 증가로 DTU에서의 재구성 품질이 향상됨을 확인 가능함... 많은 뷰를 사용해도 강인하게 작동 되는 것을 실험적으로 증빙함
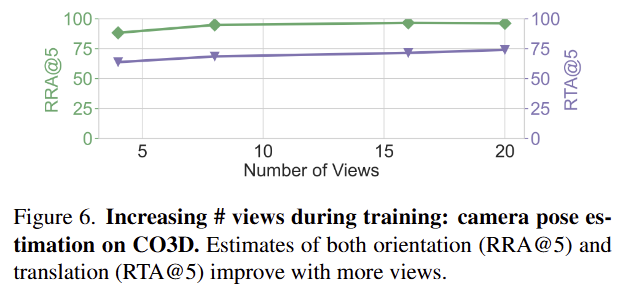
fig 6에서는 학습 중 사용한 시점의 수에 따른 성능 차이로 저자가 추측하길 학습에서 더 많은 뷰를 학습 할 수 있다면 성능이 더 향상 될 것 이라고 합니다.
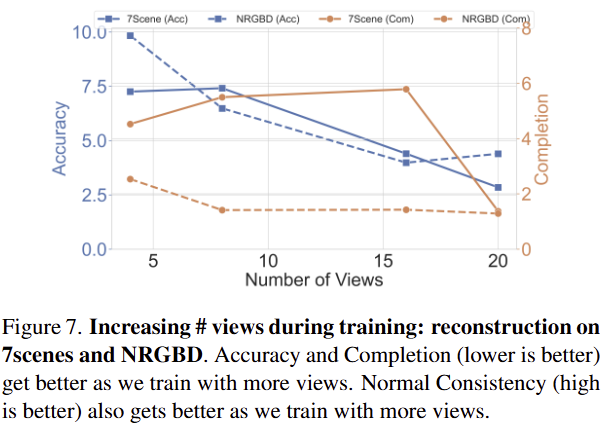
fig 7은 7-scene과 NRGBD에서 학습에 사용된 뷰에 따른 성능 차이로 앞서 분석한 바와 동일하게 학습 시점이 많아질수록 성능이 향상되는 결과를 보여줌
Training without position interpolation
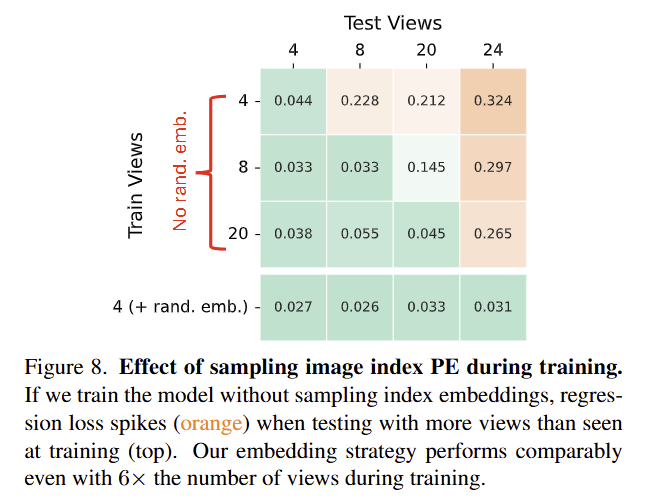
개인적으로 가장 흥미로운 실험 결과로 fig 8에서 image index PE를 사용하지 않고 정직하게 학습을 사용했을 때의 결과입니다. 모든 결과에서 학습한 시점의 수 이상을 적용한 경우, 성능이 하락하지만 image index PE를 사용한 경우에는 성능이 거의 유지되는 결과를 보여줌
Inference without local head
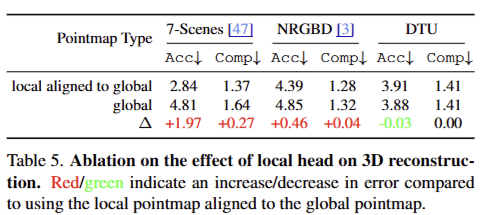
tab 5는 해당 기법에서 Dust3r과 다르게 local을 추가하였는데 이에 대한 이점을 실험한 결과로 보시면 됩니다. 저자가 주장하길 첫번째 frame의 카메라 시점으로 좌표계를 맞추기 위해서 2D-to-3D geometry와 rigid tranfomers를 수행해야 하는 global 보다 영상 내 픽셀에서 바로 point를 예측하는 local이 추론에 대한 복잡도가 낮기 때문에 보다 빠르게 학습 정확도와 불변성을 확보 할 수 있었다는 주장을 했습니다. 실험 결과도 이러한 추측에 대한 경향을 보여줍니다.
+ DTU에서는 이러한 경향이 두드러지지 않는데 이는 object centric인 데이터 셋이기에 상대적으로 local과 global에 대한 복잡도가 낮아 이러한 경향이 보이지 않았나 추측합니다... 저자가 따로 설명을 안했어요 ㅜ
실험이 방대하고 성능도 매우 우수했지만 기술적인 참신성은 떨어지는 부분이 있는 논문인 것 같습니다. 허나, 성능 측면에서 매우 우수하기 때문에 적용해보는 것을 고려하고 있습니다. 코드도 생각보다 깔끔해서 관심 있으신 연구원들은 한번 검토해보시는 것도 좋을 것 같습니다.
안녕하세요 좋은 리뷰 감사합니다.
Image index positional embedding generalization과정에 질문이 있는데요, 학습에 사용된 시점의 수보다 추론에서 더 많은 시점 수를 받아 재구성하기를 원했기에 학습중에는 30개 이하의 장면으로 학습하고 추론시에는 1,000개 이하의 장면으로 하나의 point cloud를 구성한다고 이해하였습니다. 한 공간에 대해 1,000개 정도의 장면이 존재하는 학습 데이터의 활용에 있어서 다양한 정보를 활용하지 않는것이 학습에 최적 성능 달성에 악영향을 끼칠 가능성에 대해 궁금합니다.
둘째로는 속도 측면에서 강점을 둔 논문으로 이해했는데, 연산량을 줄히는 기법으로는 기존의 방법론을 도입한 반면, 추론에 활용하는 장면의 장 수는 기존 기법대비 많게하여 성능을 높인것 같은데, 그렇다면 속도 측면의 강점이 줄어들지 않을지 궁금합니다.
감사합니다.
Q1. 한 공간에 대해 1,000개 정도의 장면이 존재하는 학습 데이터의 활용에 있어서 다양한 정보를 활용하지 않는것이 학습에 최적 성능 달성에 악영향을 끼칠 가능성에 대해 궁금합니다.
A1. 1000장에 대해 추론하는데에 그 이하로 학습하면 성능이 떨어지겠죠. 그래도 우린 다른 기법보다 나아와 더 많이 학습해야됨을 fig 4~7에서 보이고 있습니다.
Q2. 둘째로는 속도 측면에서 강점을 둔 논문으로 이해했는데, 연산량을 줄히는 기법으로는 기존의 방법론을 도입한 반면, 추론에 활용하는 장면의 장 수는 기존 기법대비 많게하여 성능을 높인것 같은데, 그렇다면 속도 측면의 강점이 줄어들지 않을지 궁금합니다.
A2. 아니… 원래는 2장만 매칭되는 DUSt3R을 N 장의 영상들을 end-to-end로 한번에 3차원 재구성하는 방법을 제시한 것이 해당 논문의 메인 컨트리뷰션이고… 거기다가 속도와 연산량도 효율적이게 만들었다가… 부가적인 컨트리뷰션임다… 반대임