이번 Badge 교육의 일환인 Faster R-CNN의 구현을 위해 R-CNN 계열의 논문들을 읽어보게 되었고, 논문들의 연결성에 집중하여 요약해보도록 하겠습니다.
R-CNN
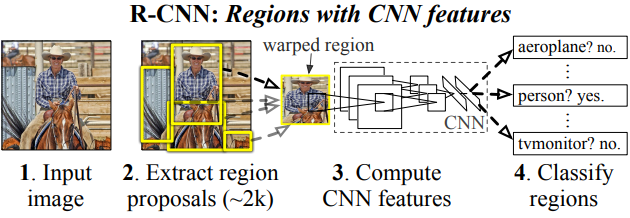
하나의 이미지 input이 들어오면 selective search(이하 SS) 를 이용하여 region(~2k)들을 뽑아내어 이를 하나씩 뽑아서 모두 동일한 사이즈로 resize해준뒤 CNN에 넣어주어 마지막 나온 feature를 SVM에 넣어 class를 구분하고 regression하여 box위치를 찾게됩니다.
위 내용에서 resize를 해주는 이유는 CNN의 FC layer의 input size에 맞추기 위함인데 이러한 과정을 동시에 처리하지 못하고 region을 하나씩 처리해야되서 CNN을 2k번 돌려야 한다는 큰 단점이 있었습니다.이를 Fast R-CNN에서 효과적으로 해결할 수 있습니다.
Fast R-CNN
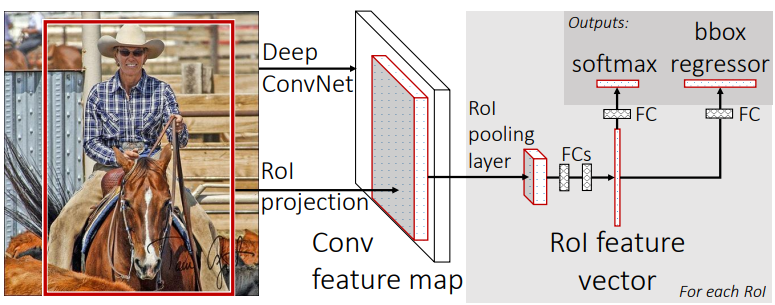
기존방식인 SS에서 얻어진 region각각을 CNN에 넣는 방식이 아니라 이미지를 바로 CNN에 넣기 때문에 기존 2k번에 걸쳐 처리하던 것을 1번으로 줄였습니다.이는 RoI projection,RoI pooling을 통해서 가능하게 되었습니다.SS에서 얻어진 region을 CNN에서 나온 feature map에 투영시키고(이는 input image와 feature map의 spatial resolution이 동일하다고 가정했기 때문에 가능한것입니다.)이후 feature map을 RoI Pooling을 해주어 고정된 output size로 되어 FC layer에 대입이 가능해집니다.즉,이미지를 동일 size로 resize하지 않더라도 FC layer의 바로 전단계에서 모든 인풋의 shape이 동일해지는 것이지요.
2K에 걸쳐서 하던것을 1번으로 줄여서 굉장히 빨라졌긴 했지만 CPU에서 돌아가는 SS방식이 굉장히 오래걸리기 때문에 아직도 speed면에서 단점이 있었고 이를 다시한번 개선한 것이 Faster R-CNN입니다.
Faster R-CNN
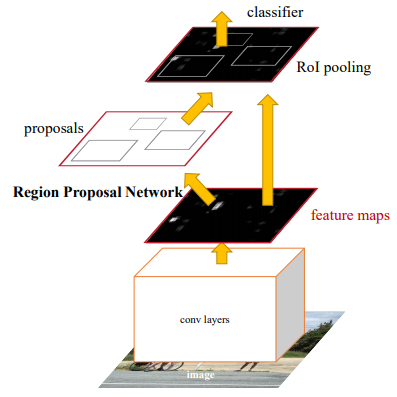
SS를 이제 RPN이라는 Network로 대체함으로 써 speed문제를 해결했습니다.이때 image로 부터 나오는 Feature map을 공유함으로 써 end-to-end방식을 할 수 있게끔 하였습니다.Fast R-CNN과 달라진 부분은 SS->RPN으로 바뀌었다는 점인데요,RPN을 학습하기 위해서 anchor를 도입합니다.이때 anchor는 다양한 실험을 통해 최종 scale[128*128,256*256,512*512]와 ratio[1:2,1:1,2:1]로써 하나의 anchor당 3*3=9개의 anchor box들이 나오게 됩니다.따라서 feature map size가 (C,H,W)라고하면 H*W*9(~2000)개의 anchor boxes들을 가지고 학습을 시작하게 됩니다.그러나 실제 학습을 할때는 cross-boundary를 제거한 6000개 정도의 박스들로 학습을 진행하게 됩니다.
본문에서 “이때 anchor는 다양한 실험을 통해 최종 scale[128*128,256*256,512*512]와 ratio[1:2,1:1,2:1]로써 하나의 anchor당 3*3=9개의 anchor box들이 나오게 됩니다.”라는 내용이 있었습니다. 이 부분에서 최종 scale과 ratio는 반복적인 실험을 통해 얻은 정량적 최적값이라고 생각하면 되나요?
RPN 학습시 train data가 이미지에대한 anchor boxes들이 된다고 이해하면 되는건가요?
실제 R-CNN에서 Faster-RCNN까지 변하면서 성능이나 속도가 어떻게 개선됐는지에 대한 지표도 함께 제시해주시면 좋을것 같습니다!