안녕하세요, 허재연입니다. 오늘 리뷰할 논문은 ECCV 2024에 게재된 논문으로, Visual Relationship DetectionI(VRD)를 open-vocabulary로 수행하는 Scene-Graph ViT라는 방법론을 제안한 논문입니다.
Visual Relationship Detection은 장면 이해를 수행하기 위한 하위 task중 하나로, 주어진 이미지에서 물체들을 검출하여 그들 간의 관계(relationship)을 추론해 <subject-predicate-object> triplet형태로 기술하게 됩니다. 이들 관계를 성공적으로 탐지하면 이를 기반으로 Scene Graph를 생성할 수 있으니, 넓게 보면 Scene Graph Generation과 유사한 task로 생각하시면 됩니다. 각 물체들 간의 관계를 잘 탐지하고 이들을 조합해 Scene Graph를 잘 생성할 수 있다면 주어진 이미지에 대해 보다 복잡한 의미적 정보를 활용할 수 있으니, 보다 고차원적인 application에 활용할 수 있겠죠. 직관적으로는 image retrieval이나, robot의 보다 정교한 planning을 수행하기 위한 정보로 활용할 수 있을 것입니다.
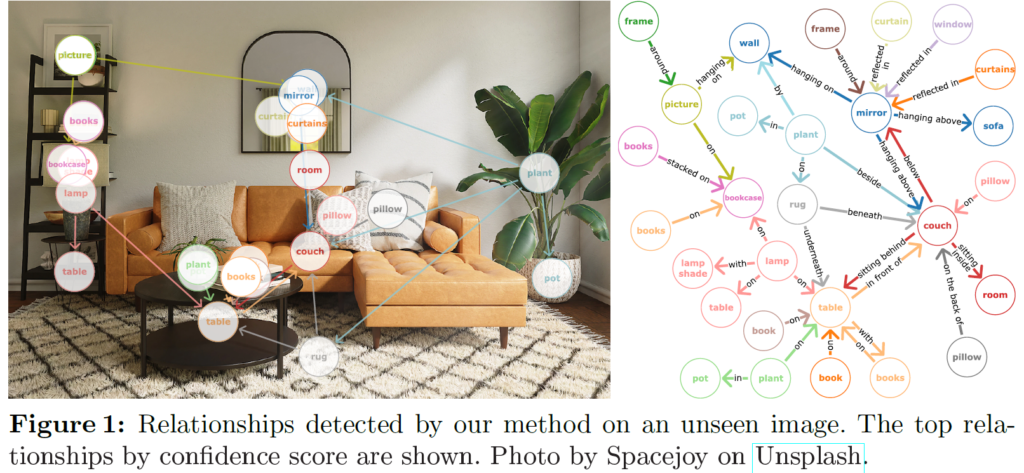
<subject-predicate-object>를 만드는데 필요한 정보는 주어, 목적어가 될 각 object를 찾는 object detection과, 이들 간의 relation 관계일 것입니다(일반적으로 이 relation에 해당하는 predicate도 classification으로 훈련됩니다). 이 때 기존의 많은 방법론들은 object detection과 relationship detection을 분리하여 수행하였습니다. Faster RCNN같은 detector로 일단 주어진 이미지/장면 내의 object들을 검출하고, 검출된 object 간의 relation을 모델링하는 식으로 완전히 별도의 단계로 나누어 수행하거나, 객체 간 상호작용을 모델링하는 별도의 relationship decoder를 통해 수행하였습니다.
저자는 이렇게 object와 relation을 결정하는것을 분리하는 것이 VRD task 학습을 할 때 end-to-end 최적화를 어렵게 만든다고 하여, 이미지 인코더만을 사용해 object와 relation을 동시에 통합적으로 모델링하는 모델 구조를 제안합니다. 제안하는 구조는 open-vocabulary relation detection을 수행할 수 있으며, object detection과 relationship detection의 임의의 annotation 조합에 대해 end-to-end 학습이 가능하게 하였습니다. 기존에 object detection와 relation detection을 한번에 end-to-end로 학습하는 방법론들이 없었던것은 아니었는데, 기존 방법론들의 경우 object와 relation의 embedding을 예측하기 위해 transformer decoder를 사용하였습니다. decoder의 경우 query embedding을 적절히 초기화시키기 어렵고 불안정하거나 최적화가 느린 문제가 있었기에(DETR계열의 object query를 생각해보시면 될 것 같네요), 저자들의 경우에는 decoder를 사용하기 않고 encoder-only 구조를 설계하였습니다.
제안하는 모델은 OWL-ViT를 기반으로 하여 이미지 인코더 출력 토큰이 직접 object proposal을 나타내도록 하였습니다. 이 토큰들을 활용하여 클래스 임베딩과 bounding box를 디코딩 할 수 있죠. 이미지 인코더 내의 self-attention 연산이 이미 모든 object proposal 토큰 간의 상호작용을 모델링하고 있기에저자들은 이 구조가 relation 추론을 위한 별도의 모듈 없이도 이미지 인코더 내에서 객체 간 관계를 직접 학습할 수 있는 좋은 구조라고 생각하였습니다.
이러한 두 토큰 사이 관계에 대한 정보를 활용하기 위해 저자들은 subject token과 object token에 해당하는 임베딩을 결합하는 새로운 relationship attention layer를 도입하였습니다. 이 때 모든 조합 가능한 객체 쌍에 대해 relation embedding을 계산하는건 연산량 측면에서 너무 비효율적이기에, 이 조합 수를 줄이기 위해 confidence가 가장 높은 <subject-object> 쌍을 선택하는 self-supervised hard attention 매커니즘을 도입해 연산 cost를 단일 self-attention layer 수준으로 낮출 수 있었습니다.
저자들이 제안하는 구조는 추론 과정에서 object name들을 relationship predicates로부터 분리할 수 있다는 장점이 있다고 합니다. 기존의 open-vocabulary 방법론들과 달리, 저자들이 제안하는 모델은 object와 predicate text를 별도로 임베딩 할 수 있으며, 가능한 모든 <subject-predicate-object> 조합에 대해 효율적으로 confidence score를 계산할 수 있다고 합니다.
저자들이 주장하는 contribution을 요약하면 다음과 같습니다:
- 우리는 open-vocabulary Visual Relationship Detection을 위한 효율적인 구조를 제안하엿다
- 해당 구조는 object와 relatioship detection 학습을 single-stage로 함께 수행할 수 있다
- 추론 시 object와 relationship을 효율적으로 분리하였다.
제안하는 구조는 Visual Genome dataset 및 large-vocabulary GQA 벤치마크 에서 Visual Relationship Detection SOTA성능을 달성하였습니다. 기존 방법론들보다 그 구조가 간단하면서도 성능이 좋아서 좋게 받아들여 진 것 같습니다. 이제 Method를 살펴보겠습니다.
Method
저자들은 OWL-ViT구조를 기반으로, 기존의 OV-SGG들처럼 object와 relation을 탐지하는 단계를 구분하거나 학습 및 추론에 트랜스포머 디코더를 활용하지 않고, 인코더만을 활용하여 객체들과 이들 간 관계를 모두 동시에 처리하는 구조로 확장하였습니다.
Encoder-Only Open-Vocabulary Object Detection
우선 제안하는 모델의 기반이 되는 OWL-ViT에 대해서 간단하게 살펴보고 시작하겠습니다. OWL-ViT는 2022년 ECCV에서 소개된 open-vocabulary object detection을 수행하는 방법론입니다.
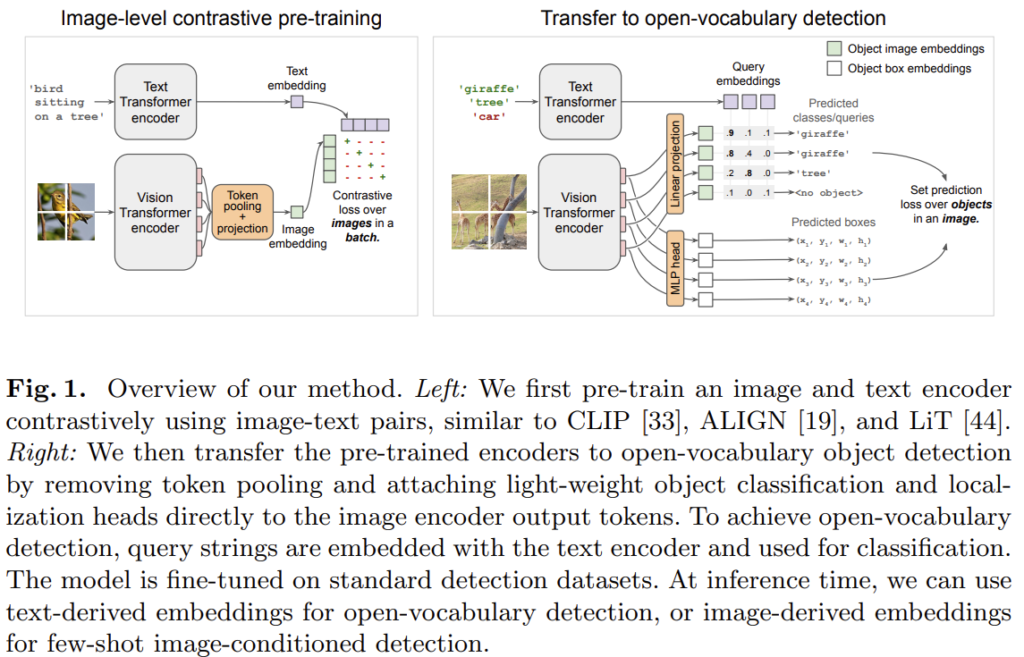
위 Fig. 1.은 OWL-ViT 논문에서 발췌한 것입니다. 기본적으로 트랜스포머 기반 이미지 인코더, 텍스트 인코더로 구성되며 대규모 이미지-텍스트 쌍 데이터로 contrastive learning으로 사전학습 하였습니다. CLIP이나 ALIGN의 사전학습을 생각하시면 됩니다. 이후 이미지 인코더에 최종 토큰 풀링 계층을 제거하고 출력 토큰으로부터 직접 bounding box와 class embedding을 예측하는 가벼운 head를 추가합니다. 이후 class prediction head에서 계산된 embedding을 object description에 대한 text encoder embedding과 비교하여 open-vocabulary object detection을 수행하게 됩니다. 그 구조가 굉장히 간단한데, OWL-ViT는 open-vocabulary object detection에서 좋은 성능을 보였으면서도 DETR처럼 인코더-디코더 구조 기반으로 object detection을 수행하는 일부 모델들이 겪는 학습 불안정성 문제도 겪지 않는다고 합니다.
Extension to Relationship Prediction
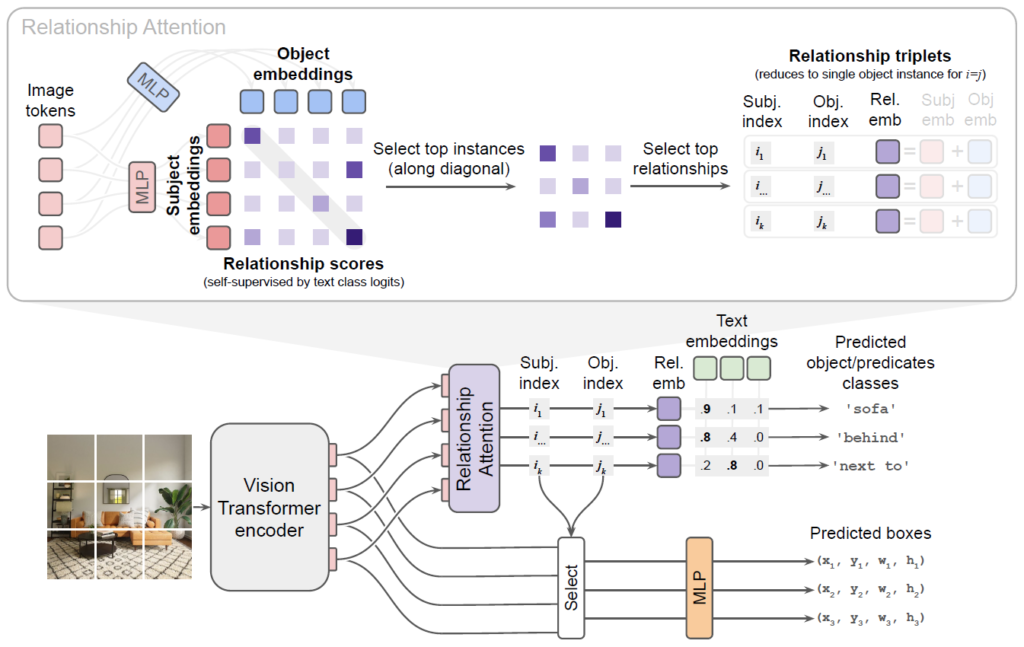

앞서 설명한 OWL-ViT 구조에서, 각 이미지 인코더 토큰은 각 object의 정보를 포착하는 object proposal을 의미합니다. 인코더가 트랜스포머 기반으므로 self-attention 연산이 수행되는데, 이 계층의 연산 과정에서 각 토큰 pair 간 정보 상호작용이 수행됩니다. 저자들은 여기에서 객체 간 relation 정보 역시 이미지 인코더 내부에서 직접 학습될 수 있다고 가정하였습니다. 이 정보를 <subject-predicate-object> triplet으로 추출하기 위해 두개의 MLP를 추가하여 vision encoder의 출력 토큰들을 주어 임베딩 {s}_{i}와 목적어 임베딩 {o}_{j}로 변환하게 됩니다(그림 2 참고). 이때, 이후 처리 과정에서 주어와 목적어의 대칭성을 깨기 위해 서로 다른 MLP를 사용하였다고 합니다. 만약 동일한 MLP를 사용하여 주어와 목적어의 representation을 projection한다면 모델이 “person riding horse”와 “horse riding person”을 구분하지 못하게 되겠죠. 실제로 appendix의 추가적인 실험에서 subject와 object의 MLP를 동일하게 설정하였을 때 성능이 크게 하락하였다고 합니다.
이후 두 object proposals(인코더 토큰들) 사이 relationship을 나타내는 embedding은 간단하게 해당 객체들의 <subject> 임베딩과 <object> 임베딩을 element-wise addition하여 계산합니다. 하지만 이 때 N개의 object proposal에 대해 {N}^{2}개의 모든 주어-목적어 쌍에 대한 relation embedding을 계산하는것은 연산량이 너무 많아지므로, 여기에 Relationship Attention 층을 도입하여 가장 relation을 형성할 가능성이 높은 <주어-목적어>쌍을 선택하는 hard attention을 수행합니다. 해당 계층에서는 어텐션 유사 점수 {p}_{i,j} = {s}_{i}{o}^{T}_{j}를 계산합니다. 여기서 {s}_{i}, {o}_{j}는 각각 <subject> i와 <object> j의 임베딩 벡터입니다. {p}_{ij}는 이 둘 사이에 관계가 존재할 가능성(likelihood)를 나타내게 됩니다. 이 점수를 모든 주어-목적어 쌍에 대해 계산하여 N×N 행렬을 만든 뒤 이 중 top k개의 pair를 선택합니다(그림 2의 위쪽 Relation Attention 참고). 이렇게 선택된 k개 쌍에 대해 relation embedding을 {r}_{ij} = LayerNorm({s}_{i}+{o}_{j})로 계산합니다. 이후 각 쌍의 relation를 분류하기 위해, 이들의 relationship embedding을 relationship predicates의 text embedding과 비교하게 됩니다. 이 때 주어와 목적어가 동일한 경우의 relation embedding은 object instance를 나타내는데 사용하여, 이를 통해 object class를 예측합니다. box들은 대응되는 image encoder 출력 토큰들을 사용하여 예측하게 됩니다.
따라서 Relation Attention 층은 <subject> 임베딩을 쿼리로, <object> 임베딩을 key로 사용하여 hard attention을 계산하여 relation 분류에 집중해야 할 객체 쌍을 식별하게 됩니다. 하지만 이 hard selection 연산은 미분이 불가능해서 관계 예측 단계에서 발생한 gradient를 해당 계층의 학습에 직접적으로 사용할 수 없기에 관계 점수를 관계 분류 단계에서 해당 쌍에 대해 예측될 최대 predicate 클래스 확률을 스스로 예측하도록 self-superivsed learning 방식으로 학습시켰다고 합니다. 이어서 설명드리겠습니다.
Training
제안 모델의 이미지, 텍스트 인코더는 대규모 image-text pair를 활용한 contrastive learning으로 사전학습된 VLM(CLIP)을 활용하여 초기화됩니다. 이후 Relation Attention과 object bounding box 예측 head와 class 예측 head를 추가한 뒤 object, relation detection dataset 데이터를 함께 활용하여 학습하게 됩니다. 이제 학습을 어떻게 하는지 보겠습니다.
Bipartite Matching
DETR이후 굉장히 자주 등장하는 Bipartite matching을 사용합니다. object classification loss와 bounding box 예측 loss로 구성된 cost를 기반으로 object 예측값({r}_{i=j})과 GT값 사이 Bipartite matching을 수행하게 됩니다. 하나의 relation은 이를 구성하는 주어와 목적어 각각의 인덱스로 구별할 수 있기에 때문에, 이런 objects 간 매칭은 예측된 predicate과 GT predicate간 매칭도 함께 정의됩니다. 매칭되지 않은 예측값들은 모든 클래스에 대해 낮은 점수를 예측하도록 학습되며, box에 대한 loss는 계산되지 않습니다. Box prediction loss는 detector 학습 loss에서 자주 활용되는 L1 및 GIoU(generalized intersection-over-union)가 사용됩니다.
Object and Predicate Classification Loss
object category와 predicate classification 학습은 분류이므로 OWL-ViT와 같이 sigmoid cross-entropy loss를 사용합니다. 이는 relation attention 계층에서 선택된 relation embedding {r}_{i,j}과 class name의 텍스트 임베딩 간 내적으로 계산하여 얻은 logit과, GT class 간의 차이로 계산됩니다. 이 때 개별 객체에 해당하는 임베딩(i = j)의 경우 클래스 이름은 object category 또는 description이고, relationship에 해당하는 임베딩(i != j)의 경우, predicate text를 클래스 이름으로 사용하였다고 합니다. 이는 <주어-술어-목적어> triplet description을 사용하는 기존 방법론들과 다른 점이라고 합니다. 이런 접근법은 object category와 predicate name을 분리해서 각각의 object category와 predicate text를 개별적으로 임베딩 할 수 있어 더욱 효율적으로 추론이 가능하다고 하네요.
Relationship Score Loss
가장 높은 가능성의 임베딩들만 이후 처리 과정으로 넘기기 위해 relation attention 계층에서 점수 {p}_{ij}/latex]를 예측합니다. 앞에서 언급했듯 이 점수는 i와 j가 다른 경우 해당 <주어-목적어> 쌍이 relation을 형성할 가능성(likelihood)을 나타내고, i = j이면 해당 객체가 이미지 내애 존재할 가능성을 나타냅니다. 이 점수는 모델 자체에서 제공되는 target값과 sigmoid cross-entropy loss로 학습되어 relationship score는 잠재적인 임베딩 {r}_{ij}/latex]을 실제로 계산하고 분류를 수행하기 전에 클래스 확률을 예측하도록 학습됩니다. 이 loss는 최종적으로 후처리 대상으로 선택된 object, relation에 대해서만 계산됩니다. 최종 loss는 (1) classicication loss, (2)L1 box loss, (3) GIoU box loss., (4)relatioshiop score loss를 합하여 계산됩니다.
Experiment
저자들은 Visual Genome, VG150, GQA200, HICO, Object365 데이터셋들을 다음 비율로 혼합해서 학습했다고 합니다. 또한 평가에 사용되는 이미지가 학습에 사용된것과 중복되지 않도록 하기 위해 모든 학습 데이터셋을 한번 더 필터링해서 사용했다고 하네요.

일반적으로 Scene Graph Generation, Visual Relation Detection의 경우 평가지표로 Recall@K를 자주 사용합니다. 여기서 K는 <subject-predicate-object> triplet 중 recall을 계산할 수를 의미합니다. 하지만 일반적으로 데이터셋 내부의 predicate의 분포가 상당히 편향되어 있어 Recall@K를 그대로 사용할 경우 이런 편향에 영향을 받을 수 있기에, 최근 접근법들은 mean Recall@K를 사용해서 테스트 데이터 등장하는 각 <predicate>클래스별로 Recall@K를 개별 계산한 후 평균을 낸다고 합니다.
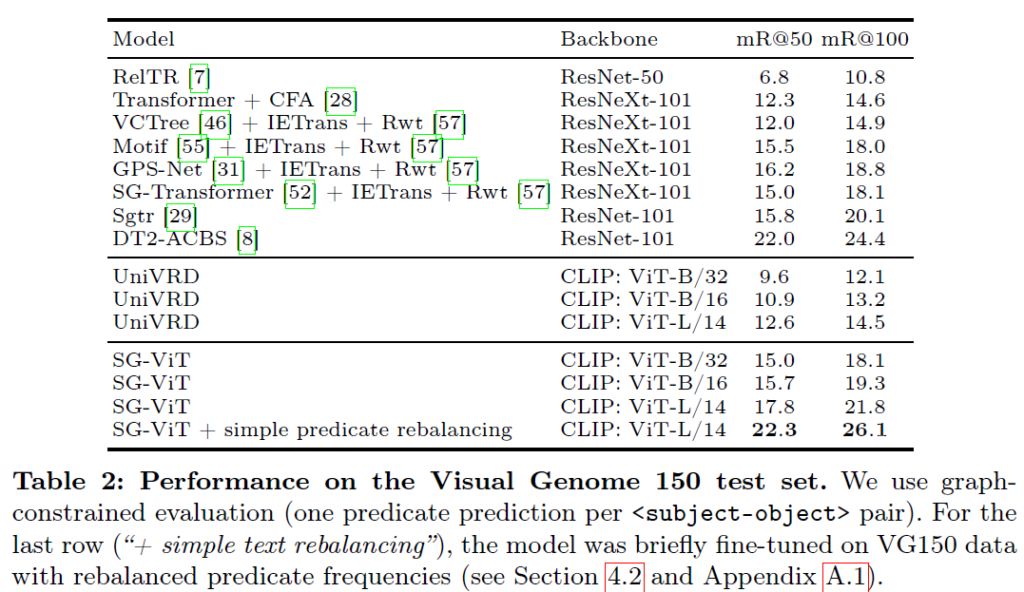
relation detection에 대한 메인 벤치마크 실험은 Visual Genome 150에서 수행되었습니다. 기존 연구들은 기본 모델 구조 + 데이터 분포 편향(skewed distribution)을 보정하기 위한 특수 기법을 결합하여 성능을 끌어올리는 경우가 많은데 저자들이 제안한 SG-ViT의 경우 딱히 skewed predicate distribution에 대한 추가적인 처리를 하지 않고도 굉장히 좋은 결과를 보여주었습니다. 맨 아래 simple predicate rebalancing의 경우 predicate anootation의 빈도 분포를 재조정한 데이터로 간단히 fine-tuing을 수행한 것이라고 하네요. 이미 강력한 성능을 보이기에 이후 추가적인 재조정+보정 기법을 결합하면 추가적인 성능 향상 여지가 있다고 강조합니다. 동일하게 트랜스포머 디코더 기반 relation module을 추가한 UniVRD와 성능 차이가 큰 것이 눈에 띕니다. 저자들은 이에 제안 모델이 UniVRD 대비 향상된 성능을 보이는 이유가 모델 구조 차이 때문인지, 학습 데이터의 차이 때문인지 확인하기 위해 B/32기반 SG-ViT 모델을 UniVRD와 동일한 데이터 혼합으로 학습시킨 뒤 평가하였고, 그 결과 여전히 큰 성능 차이를 보였다고 합니다. 이를 통해 저자들의 encoder-only 구조가 기존의 디코더 기반 방법론들보다 VRD에 더 적합함을 의미한다고 강조합니다.
Scaling to Large Vocabularies
predicate triplet은 그 분포가 상당히 편향되어 있기에, VRD분야에서는 long-tail 문제를 계속 극복하고자 시도하였습니다. 일반적으로는 복잡한 손실함수를 써서 디바이어싱(loss debiasing)하거나 데이터 증강(data augmentation) 기법을 활용해서 이를 해결하고자 하였죠. 저자들은 이에 tail쪽 희귀한 클래스에 대한 특별한 별도 처리 없이 잘 동작하는 것을 확인하는것이 중요하다고 주장합니다(자신 있으니까 강조하겠죠?)
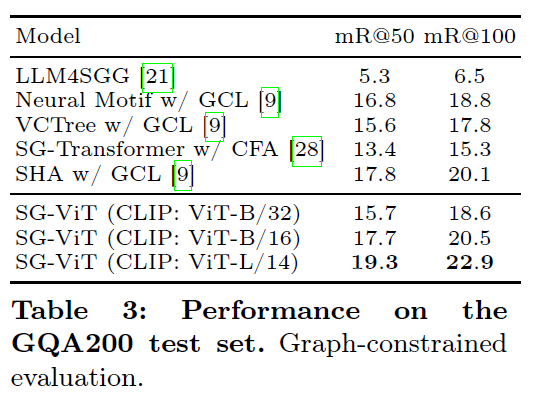
희귀한 클래스를 포함한 대규모 object, predicate vocabulary를 갖는 환경에서 평가하기 위해 GQA (Graph Question Answering) 데이터셋을 사용하였습니다. 이 데이터셋은 VG을 기반으로 클래스와 anotation 수를 더욱 확장한 것이라고 합니다. GQA200은 200개의 객체 클래스와 100개의 술어 클래스를 가진 간소화시킨 저자들의 혼합 데이터셋 중 하나라고 하네요. 표 3을 보면 일부 기존 방법들이 데이터 분포에 특화된 처리를 적용한 반면, 제안하는 방법은 그런 처리 없이도 GQA200 테스트 셋에서 기존 방법론들보다 좋은 결과를 보여줍니다.
이후 Table 4에서는 전체 GQA 데이터셋(1,703개의 object class, 311개의 predicate class를 포함한 더 큰 데이터)에서 는 Scene Graph Classification에서 벤치마킹된 기존 방법론들과 Scene Graph Generation에서 평가한 제안 방법론을 비교하였ㅅ브니다. 여기서 scene graph classification은 GT box가 주어진 상황이고, scene graph generation은 주어지지 않은 더 어려운 상황이라고 합니다. 동일한 세팅으로 비교할 수 있지 않았었나? 하는 생각이 들긴 하는데 더 어려운 task에서 더 잘 동작한다는것을 어필하고 싶었던 것 같습니다.
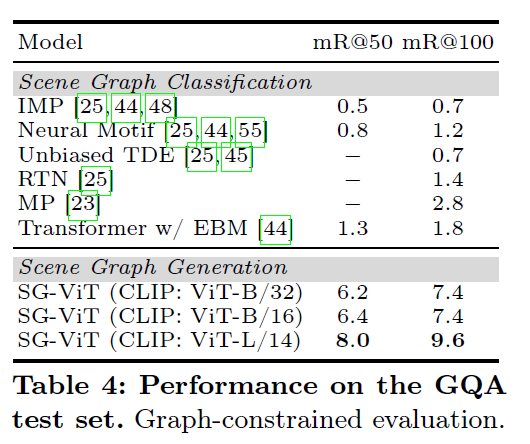
저자들은 open-vocabulary setting에서 제안하는 모델이 좋은 성능을 보이는 이유에 대해, 1. 모델 설계가 간단해 사전학습된 VLM 백본으로부터 semantic knowledge transfer가 원활이 잘 되었기 때문이라고 합니다. 단순히 가벼은 head만을 추가했었죠. (디코더를 사용하면 사전학습 representation을 잊어버리는 문제를 유발할 수 있다고 하네요)

Table 5에서는 HICO 라는 벤치마스헤서 Human-object interaction이라는 task에서 평가하였습니다. HICO의 경우 데이터셋이 VG나 GQA보다 훨씬 좁고 특화된 어휘 범주를 가진다고 합니다. 사전 정의된 600개의 triplet만을 평가한다고 하는데, 이는 VG보다 훨씬 작은 규모입니다. 이렇게 특화된 task에서는 사전학습된 representation의 전이 효과가 충분히 그 힘들 발휘하지 못할 수 있고, task-specific한 학습 데이터 양이 성능을 제한할 수 있다고 합니다. SG-ViT는 Swin-L백본의 RLIPv2를 제외한 방법론들 대비 우수한 결과를 보였습니다.
정성적 결과 살펴보고 리뷰 마무리하도록 하겠습니다.

Figure 4에는 어려운 edge case를 강조하기 위해 정성적 결과를 시각화하였다고 합니다. 모델의 출력이 GT와 달라도 객체의 category가 정답과 다르거나, 옳게 예측했지만 anootation에 포함되지 않는 경우처럼 출력이 제법 그럴싸하게 나온 경우들이 있습니다. 예를 들어 (b)에서 light on bus에 대해 유리창에 빛이 반사된 부분이 아닌 버스의 전조등을 선택하였습니다. c에서는 snow on hill이라는 relation에서 mountain과 hill 사이 구분보다 on이라는 술어에 더 집중했네요.

그림 5는 동일한 의미 범주의 객체 인스턴스들이 다수 존재하는 장면을 나타내었습니다. “banana outside bowl”이라는 텍스트 쿼리에 대해 인접한 그릇이 아닌 선반 위에 있는 그릇을 잡아내서 실패하거나, 주어나 목적어에 단수 표현이 사용되면 모델이 동일 한 클래스 의미를 갖는 복수 instance 그룹 전체에 bounding box를 치는 경우가 있었다고 합니다. 이는 CLIP embedding에서 단어와 복수형 표현 간 유사성 및 VG 데이터에서 annotator들이 단수와 복수를 자주 혼동했다는 점 때문인것으로 보인다고 합니다.
OWL-ViT구조를 기반으로 SGG , VRD를 수행한 SGG-ViT를 살펴보았습니다. open-vocabulary SGG의 경우 기존의 잘 동작하는 VLM / OVOD 모델을 잘 활용하는것이 기조인 것 같습니다. 이만 리뷰 마무리하도록 하겠습니다.
감사합니다.