7월 27일 세미나시 발표한 PSPNet과 DeepLab을 정리한 내용입니다.
##PSPNet : Pyramid Scene Parsing Network
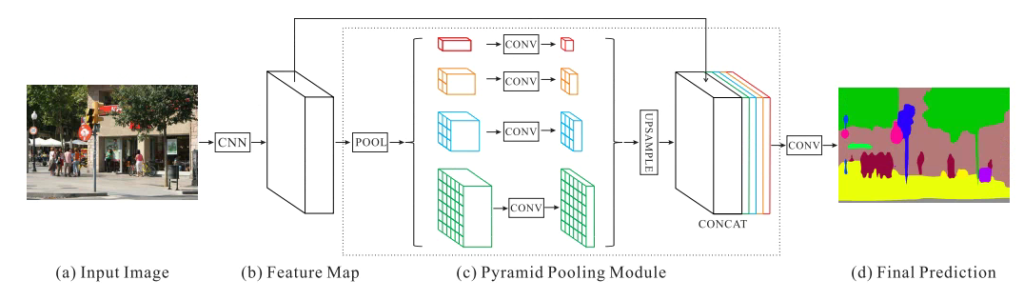
PSPNet은 피라미드 구조를 적용하여 모델이 주변의 정보를 이용해 더 정확하게 예측할 수 있게 하였다. 이는 그림1을 통해 가장 직관적으로 이해할 수 있다.

(푸른색 마스크:car, 옅은 녹색 마스크:boat)
PSPNet의 네트워크는 간단하게 그림2와 같다. 이러한 pytamid pooling은 뒤에 deeplab에서 multiple scales 문제를 해결하기 위하여 또 사용된다.
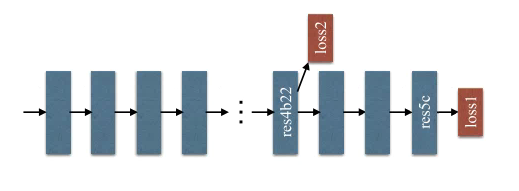
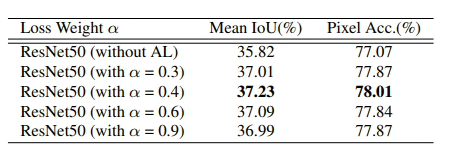
또한 논문은 Deep pretrained network가 얕은 network보다 비교적 좋은 성능을 내지만, 학습시에 gradient의 손실 등의 이유로 추가적 조치를 취해야하는 것에 대하여 기존의 ResNet의 해결방식인 Skip connection 이 아닌 보조 loss를 이용하는 방식을 제안하였다.
## DeepLab : Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs
먼저 DeepLab 은 다양한 버전이 있지만, 세미나에서 중심으로 다루었던 내용은 V2에 관한 것이였다. 논문에 제목에 나와있듯이 DeepLab v2의 제안하는 내용은 3가지인데 정리하면 다음과 같다.

위의 내용에 대해 보충설명 하자면 다음과 같다
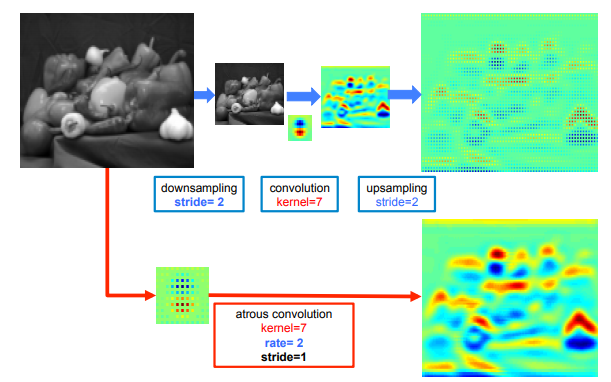
(1) feature resolution를 향상하기 위하여 논문은 Atrous convolution을 제안하였다. (이는 종종 dilated convolution이라고도 불린다 ) 연산 방식은 그림4와 같다.
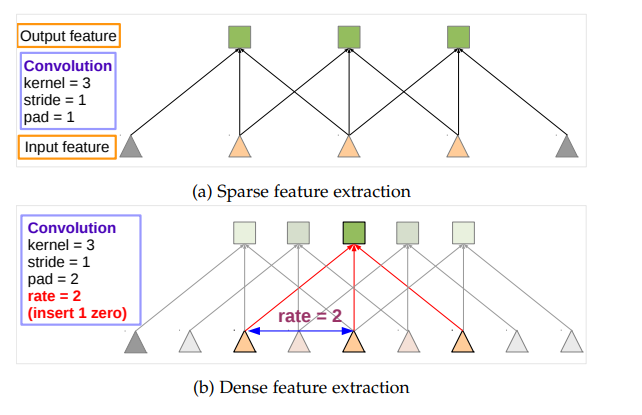
이는 첫째로는 receptive field를 위한 추가적 연산이 줄어들어 연산량이 줄어들 뿐만 아니라, down-sampling 이후 up-sampling 하는 것 보다 정보량 손실이 적음을 그림 5에서 확인할 수 있다.
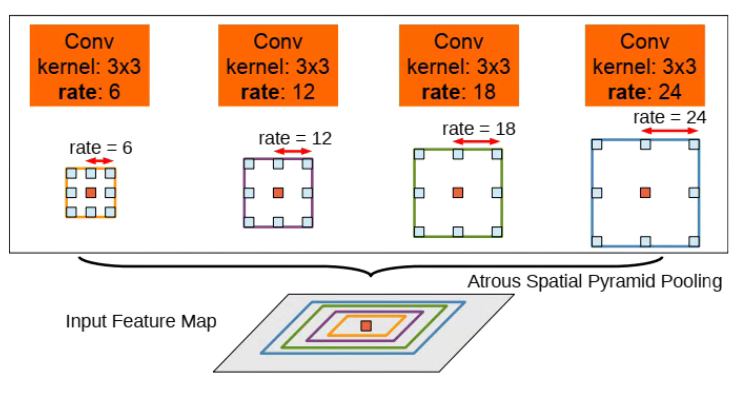
(2) multiple scales에 강인한 모델을 위한 Atrous Spatial pyramid pooling(ASPP)
앞서 PSPNet에서 언급했듯이 DeepLab 또한 Pyramid Pooling 아이디어를 이용하여 scales에 관련한 문제를 해결하려 하였다. 이때 제안하는 Atrous convolution을 이용하여 연산량을 좀 더 효율적으로 구현하였다.
(3) Conditional Random Field(CRF)를 이용한 후보정
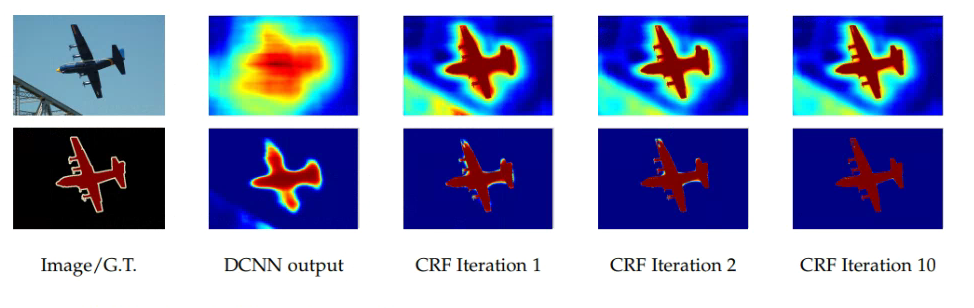
DCNN의 결과를 단순히 양선형보간을 통하여 dense prediction을 진행하면 앞선 FCN 에서도 알 수 있듯이 영상이 매우 단순하다. DeepLab은 이를 해결하기 위하여 CRF 방식을 이용하였다.
보조 loss를 배치하는 위치에 대한 ablation study 결과나 혹은 Res4b22 layer에 위치한 이유가 있을까요?
그리고 Atrous convolution의 연산 방식이 convolution filter 중에서 일부만 연산한다고 이해하면 될까요?
좋은 글 감사합니다.
해당 글을 읽으면서 궁금한 점이 있는데, 깊은 네트워크에서 gradient 손실을 해결하고자 ResNet의 skip connection이 아닌, 보조 loss를 사용했다고 말씀하셨습니다.
여기서 보조 loss에 대해 잘 와닿지 않아서 혹시 간략하게 설명을 해주시면 감사하겠습니다.
그리고 추가로 skip connection이 아닌 보조 loss를 왜 사용했는지에 대해 논문에서 언급한 내용도 있었나요??