이번에 들고 온 논문은 로봇 분야를 선도하고 있는 그룹은 Physical intelligence에서 공개한 VLA 모델 중 하나인 pi-zero의 후속 논문 FAST입니다. high-frequency를 가진 action을 효율적으로 학습하기 위한 tokenizer를 제안한 논문 입니다.
해당 연구의 정성적인 결과가 궁금하신 분들은 FAST 프로젝트 페이지를 확인해주세요.
Intro
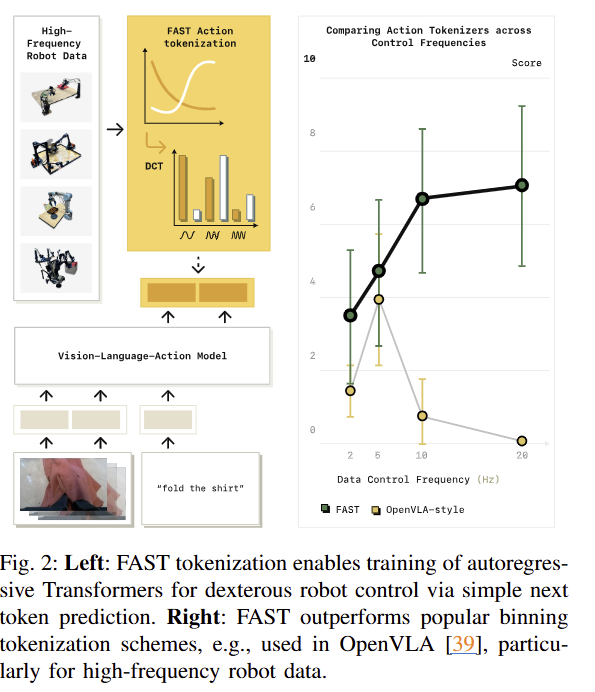
최근 인터넷 스케일로 학습된 VLM과 Foundation Model을 결합함으로써 사람의 명령어와 실시간 영상을 입력으로 받아 로봇이 직접 제어하는 VLA이 등장하여 큰 파장을 주었습니다. 해당 모델들은 다양한 태스크와 일반화된 태스크에서 좋은 성능을 보여주고 있죠. 대부분의 VLA 모델들은 기존 VLM과 Foundation model에 영향을 받아 Transformer 구조를 따르며, 연속적인 액션을 추론하기 위해서 auto-regressive 구조를 따릅니다. 이러한 구조를 가진 방법론들은 연속적인 action을 transformer에 입력하기 위해서 token tokenizer를 수행해야만 합니다. 기존 VLA에서는 per-dimension, per-timestep에 맞춰 bin에 따라 token을 구분하는 naive tokenization을 이용합니다. 해당 방식은 low-frequency action (<10Hz)에서는 높은 성과를 보여줍니다만, fig 2를 보시면 high-frequency action (>10Hz)에서는 저조한 성능을 보여줍니다.
저희 연구실 분들은 왜 high-frequency action이 필요한지? high-frequency action에서 왜 성능이 하락하는가? 가 궁금하실 겁니다. 먼저, high-frequency action은 로봇의 동작이 복잡해 질 수록 순간적이 움직임이 큰 영향을 끼치게 됩니다. 그렇기 때문에 높은 빈도로 세밀한 동작을 지시해야만 합니다. 또한 부드러운 움직임을 위해서도 필요하겠죠. 다음으로 왜 기존 방법론에서 사용하는 naive tokenization을 사용할 경우에 high-frequency action을 예측할 때, 낮은 성능을 보여주는 이유인데요. 이는 auto-regressive model의 특징에서 발견할 수 있습니다. 모델이 이전에 예측한 출력을 다시 예측하는 구조를 가진 auto-regressive의 특성, 이전 값과 차이가 작으면 작을 수록 학습에 대한 신호가 작아지게 됩니다. high-frequency action이 담긴 데이터들은 복잡한 모션이 아닌 구역에서는 무의미한 반복적인 정보들이 생성될 수 있습니다. 해당 값들은 이전 값과 차이가 미비한 구조를 가지고 있기 때문에 유의미한 학습 신호를 전달이 어렵기 때문에, 학습을 더 어렵게 만들고 로컬 미니마에 빠지게 만들 수 있죠. 실험적으로 기존 기법들을 high-frequency action이 담긴 데이터로 학습을 진행하고 추론을 진행하면 이전 값들을 복사하는 형상을 보입니다.(이는 fig 3에서 확인 가능).
저자는 이러한 한계를 극복하고 autoregrssive VLA가 high-frequency action을 학습 가능하도록 하는 새로운 tokenization 전략 Frequency-space Action Sequence Tokenization (FAST)을 제시합니다. 해당 기법의 동기는 학습 전 연속적인 toekn을 “압축”하는 것으로부터 시작됩니다.(이는 NLP, CV 분야의 tokenization 연구에서 얻은 통찰이라고 밝힘), 이를 위해서 저자는 language models에서 많이 활용하는 Byte-Pair Encoding (BPE)에 영감을 얻은 방법을 제시합니다. 그러나 robotic action은 연속적이기에 대응 압축을 수행하기 위해서는 이를 고려해야만 합니다. 저자는 이를 해결하기 위해서 연속적인 signal을 처리하기 위해서 많이 활용(e.g. JPEG compression)되는 Discrete Cosine Transform (DCT) encoding을 활용합니다.
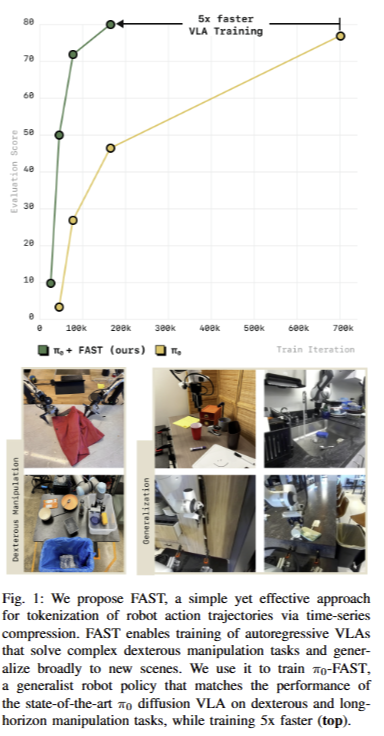
해당 기법은 아주 간단한 방법으로 학습 효율성을 높고, tokenization이기에 다른 기법에 적용하기 쉽다는 장점을 보입니다. 저자는 이를 증명하기 위해서 pi-zero와 openvla에 적용한 실험 결과를 보입니다. 또한, DROID dataset을 처음으로 학습에 활용하여 unseen environments에서 zero-shot 실험을 처음으로 선보입니다. 또한, FAST를 기반으로 다양한 로봇과 태스크를 수행한 1M real robot action으로부터 학습된 universal robot action tokenizer인 FAST+을 제시합니다. 마지막으로 SOTA인 diffusion 기반의 방법론에 준하는 성능을 보이며, 5배 이상 빠른 학습 속도를 보입니다. 이는 fig 1에서 확인 가능합니다.
Method
PRELIMINARIES
Problem formulation. 해당 기법의 목적은 policies \pi(a_{1:H} | o) 를 observation o를 sequence of future robot action a_{1:H}에 맵핑이 가능하도록 학습 시키는 것입니다. 즉, 모델은 태스크에 따라 H 크기의 일련의 action “action chunk”를 예측한다고 가정합니다. Action tokenization의 목적은 연속적인 액션을 n개의 discrete tokens T_a: a_{1:H} \rightarrow [T_1, \ldots, T_n] 으로 맵핑하는 함수를 찾아내는 것입니다. 여기서 n은 text tokens이 제시된 문장에 따라 길이가 가변되는 것과 동일하게 액션의 크기에 따라 가변된다고 보면 됩니다.
Binning-based action tokenization. 기존 VLA에서는 연속적인 action을 token화 하기 위해서 간단한 binning을 활용합니다. 대체로 학습 데이터 셋에서 분석된 액션에 대한 범위를 기반으로 N개의 uniform bins으로 나눕니다. 대부분은 N=256을 사용한다고 합니다. 해당 방법은 아주 간단하게 생성 가능하지만, action chunk의 크기에 따라 token의 수도 같이 커지는 문제가 발생합니다. 이는 학습을 어렵게 만들고 추론 속도를 높이는 요소로 동작하게 됩니다.
+ action chunk는 명령어가 들어가고 이를 수행하는 일련의 행동들이라고 보시면 됩니다.
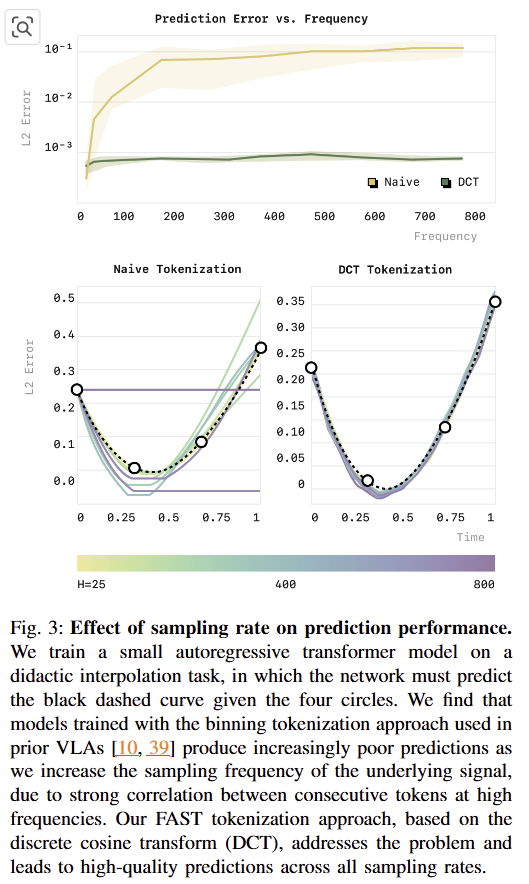
CASE STUDY: HOW DOES TOKENIZATION AFFECT VLA TRAINING?
저자는 tokenization이 VLA의 학습에 어떤 영향을 주는지 확인하기 위해서 fig 3과 같이 간단한 실험을 진행합니다. 해당 실험에서는 랜덤하게 생성된 4개의 포인트를 보간하는 cubic spline 예측하는 것을 목적으로 가상의 시계열 데이터 셋을 생성하여 평가(fig 3)를 진행합니다. 해당 실험에서 naive tokenization은 bin=256으로 구성하고 각각 다른 25~800 timesteps per sequnce로 서로 다른 sampling rates에서 간단한 auto-regressive transformer를 학습 시키고 출력된 결과물에 대한 평가를 집행합니다. 실험 결과, naive tokenization은 낮음 sample rate에서는 꽤 괜찮은 결과를 보여주지만, sample rate가 증가하면서 급격하게 에러율이 증가하며, 최종적으로는 처음 액션을 복사하는 형상을 보여줍니다. 저자는 해당 문제는 데이터 셋 자체의 문제가 아니라는 점을 강조합니다.
저자는 해당 문제는 auto-regressive model이 이전 tokens을 기반으로 다음 tokens을 예측하는 방식에서 발생한다고 합니다. 두 tokens 사이의 차이는 per-timestep을 기반으로 하는 naive tokenization을 활용할 경우, control frequency가 증가할 수록 marginal information은 zero에 근접하게 됩니다. 이는 학습을 어렵게 만들고 local minma에 빠지게 만듭니다.
EFFICIENT ACTION TOKENIZATION VIA TIME-SERIES COMPRESSION
이전 실험에서 high- frequency action에서 중복성이 높아져 action token이 갖는 low marginal information 가지게 되어 학습 성능이 저하된다는 점을 보았습니다. 저자는 이를 해결하기 위해서 중복되는 action signal을 압축하여 적은 수의 high-information toekns만 남도록 해야 한다고 주장합니다. 저자는 이를 구현하기 위한 방법을 제시합니다.
Time-Series Compression via Discrete Cosine Transform. 저자는 이를 위해서 Discrete Cosine Transform (DCT)를 기반의 압축 알고리즘을 제시합니다. DCT는 연속적인 신호를 다양한 주파수의 코사인 요소들의 합으로 나타내는 주파수 공간 변환이라고 보시면 됩니다. 해당 공간에서 low frequncies는 신호에 대한 전반적인 형상을 나타내며, high frequencies는 급격한 변화를 나타낸다고 보시면 됩니다. DCT는 JPEG compression에서 활용되는 기법으로 중복되는 pixel ~ low weight를 가진 정보들은 방출하는 방식으로 압축을 수행합니다.
+ 또 다른 압축 방식으로 vector quantization ~ VQ-VAE 방식이 있습니다. 해당 기법은 stable diffusion에서도 많이 쓰이는 방식입니다. 저자는 해당 VQ 방식과도 비교한 실험을 담고 있습니다만, 해당 기법은 학습이 필요하며, 학습된 데이터 편향에 많이 탄다는 점에서 DCT가 아주 간단하고 빠르면서 보편적으로 활용 가능하다고 주장합니다.
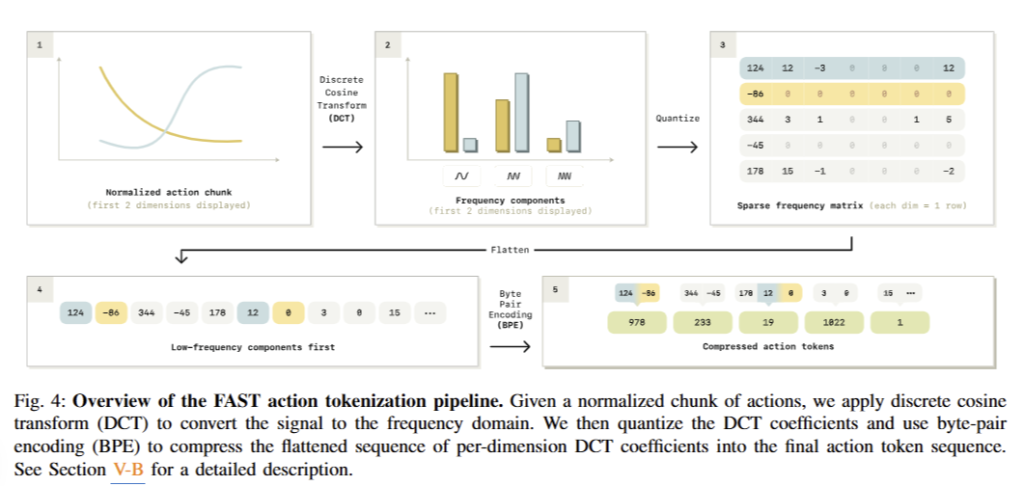
The FAST Tokenization Algorithm. 해당 섹션에서는 FAST를 적용한 전반적인 구조를 설명합니다. 이는 fig 4에서 확인 가능합니다. 먼저 raw action을 정규화 합니다. 여기서는 학습 데이터의 1st and 99th 사분위로 정규화를 수행합니다. 정규화를 수행된 값의 범위는 [-1, … , 1]를 가지게 됩니다. 해당 작업은 다양한 액션 스케일을 가진 cross-embodied datasets을 특정 범위로 가져와 일반화를 수행하는 데에 큰 역할을 합니다. 또한, 저자는 quantile을 적용한 이유로 outliner action에 대해서 강인성을 가지게 위해서라고 하네요. 정규화 이후에는 각 액션 차원에 DCT를 적용합니다. 여기서 scale-and-round operation을 수행합니다. 여기서 scaling coefficient는 하이퍼 파라미터로 손실과 압축률에 대한 trade-off를 조절하는데에 사용됩니다. rounding operation 이후의 DCT coefficient matrix는 희소한 특징을 가집니다. 대부분은 영으로 채워져 있고, 희소하게 중요한 coefficients만 남아있게 됩니다. 실질적으로 압축을 수행하기 위해서 sparse한 구조를 dense tokens으로 변경하는 작업을 진행합니다. 행렬을 정수 타입의 1-dim vector로 flatten을 수행합니다. 여기서 BPE tokenizer를 통해서 zero valued components와 반복적으로 등장하는 action 요소들을 “squashes”를 합니다.
+ BPE를 DCT 이후에 적용하는 방법을 적용한 이유에 대해서 저자는 VLM에서 가장 많이 활용되는 기법이기 때문이라고 하네요.
또한 저자는 flatten을 수행할 때에 order가 policy 성능에 큰 영향을 줄 수 있다고 합니다. matrix를 order하는 데에 있어 크게 column-first flattening과 row-first flattening 방식으로 구분할 수 있습니다. column-first flattening은 각 차원에서 lowest-frequency components을 처음으로, row-first flattening은 single action dimension을 처음으로 구성하는 방식입니다. 저자는 column-first flattening을 선택한다고 합니다. 전반적인 구조에 대한 정보를 가진 low-frequency 먼저 예측하고 이를 기반으로 auto-regressive하게 예측하는 것이 보다 안정적인 예측으로 이끈다고 합니다.
해당 tokenizer은 쉽고 빠르게 detokenization이 가능하다고 합니다. 또한 하이퍼파라미터는 두개만 존재하는데 하나는 DCT에 rounding 전에 가해지는 scale과 BPE에 적용되는 vocabulary size라고 합니다. 두 파라미터는 아주 예민하지 않아서 모든 실험에서 동일한 값을 사용했다고 합니다. (rounding scale 10, BPE vocabulary size 1024)
A Universal Robot Action Tokenizer
저자가 제안한 Tokenizer인 FAST에서는 학습이 필요한 요소는 BPE만 필요합니다. 그렇기에 새로운 데이터 셋에 대해서는 BPE를 수행해야만 하죠. 물론 몇 분만 필요하지만 FAST를 적용하기에는 불편하긴 합니다. 저자는 이러한 문제를 극복하기 위해서 어떠한 로봇에도 적용 가능한 universal action tokenizer를 학습 시키는 것을 목적으로 합니다. 이를 위해서 single-arm, bi-manual, mobile manipulation robots과 joint 와 EE space와 다양한 control frequnecies를 담은 1M의 1-second action chuncks로 학습을 진행합니다. 저자는 이렇게 학습된 tokenizer를 FAST+라고 지칭합니다. 이후 실험에서는 해당 tokenizer의 성능도 같이 평가합니다. 또한 해당 tokenizer는 아래 코드를 통해 쉽게 사용 가능합니다.


Experiment
실험에서는 FAST를 실험하기 위해서 두 VLA, pi-zero와 OpenVLA를 활용합니다. 또한 SOTA인 flow-mathcing (diffusion) VLA와 비교를 합니다.
Experimental Setup
Policy implementation: pi-zero (PaliGemma-3B), OpenVLA (Prismatic 7B) -> fine tune VLA without weight freezing
Evaluation tasks
– Libero: simulated benchmark
– Table bussing (20Hz): UR5 single-arm robot needsto clean a table, 12 objects into a trash bin
– T-Shirt folding (50 Hz): Bi-manual ARX robot, fold various shirts
– Grocery bagging (20 Hz): a UR5 single-arm robot, to pack seven objects from a table into a grocery bag, taking care to not topple or rip the bag in the process.
– Toast out of toaster (50 Hz): bimanual TrossenViper-X robot. remove two slices of bread from a toaster and place them on a plat
– Laundry folding (50 Hz): bi-manual ARX robot. to take shirts and shorts from a basket flatten themon a table, fold and stack them
– Zero-shot DROID tabletop manipulation (15 Hz): various table-top manipulation task. picking and placing objects, wiping, opening and closing drawers -> test unseen environment
+ … 정량적인 평가는 없음. 정성적 평가도 확실하게 보여주지 않아서 zero-shot에 대해서는 ?? 임
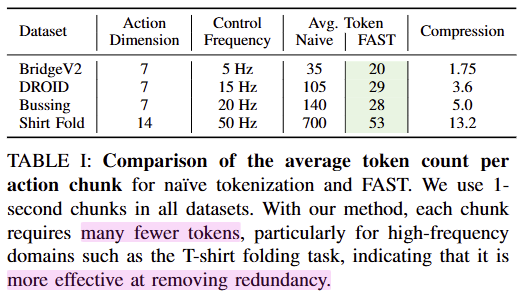
먼저, Tab 1에서 보이는 바와 같이 Naive tokenizer에 비해서 큰 폭의 압축력을 보여줌.
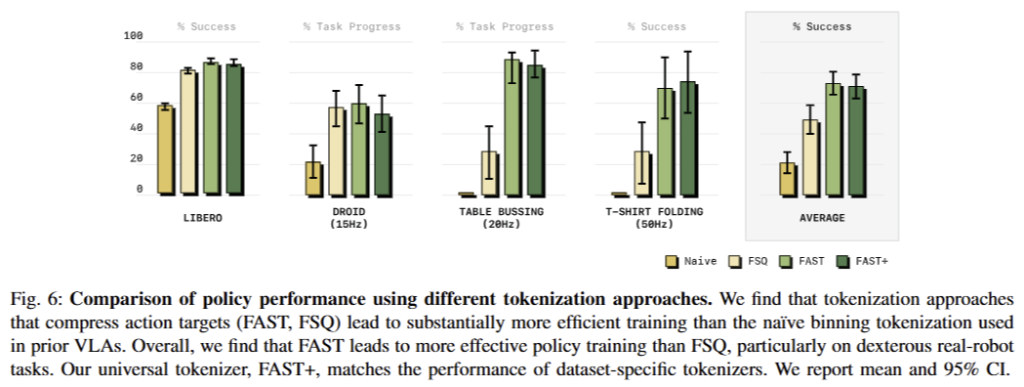
Fig 6에서는 비교적 낮은 frequncy를 가진 LIBERO에서는 naive도 어느 정도 성능을 보여주나 high-frequency를 요구하는 이외의 태스크에서는 낮은 성능을 보여주는 것이 반해 FAST는 일관되게 좋은 성능을 보여주고 있음. 또한 FSQ는 token을 생성하기 위해서 VQ-VAE를 학습한 방식보다 더 좋은 성능을 보여주고 있음. 또한 universal robot tokenizer인 FAST+도 FAST에 준하는 성능을 보여주고 있음.
+ task progress: success rate보다 완화된 평가 지표. 일부 성공하더라도 부분 점수를 부여하는 방식

fig 8에서는 single arm 뿐만이 아니라, Dexerous (손 형태의 그리퍼), UMI, Humanoid, Nav (Waymo~자율주행 차량)에서도 효율적으로 압축하는 결과를 보여줌
Ablation studies
저자는 2가지를 분석함. FAST는 VLA 백본에 독립적인가?와 BPE는 얼마나 중요한가?
먼저 FAST는 VLA 백본에 독립적인가?는 아래 그림을 통해 확인 가능함.
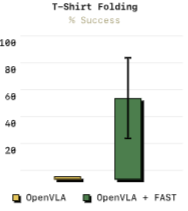
pi-zero가 아닌 OpenVLA에 FAST를 적용해보니 high-frequency를 요구하는 T-shirt Folding에서 매우 향상된 성능을 보여줌
BPE는 얼마나 중요한가?는 아래 그림과 같음
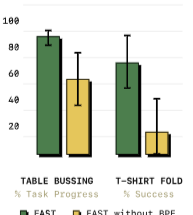
물론 DCT 만으로도 좋은 성능을 보여주고 있으나, 위 성능을 통해서 BPE는 중복된 정보를 제거함으로써, 학습 신호를 개선 시킴을 보임
Comparing FAST to Diffusion
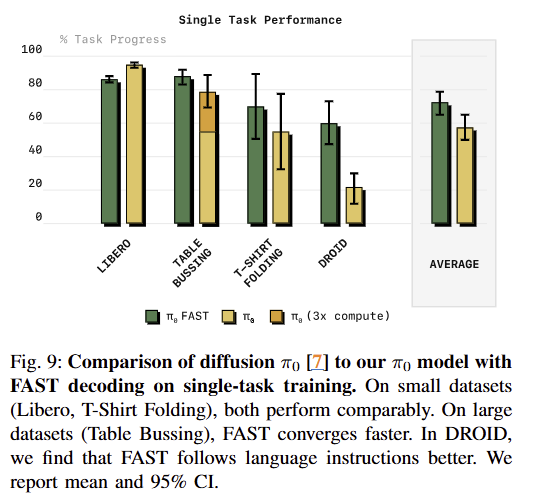
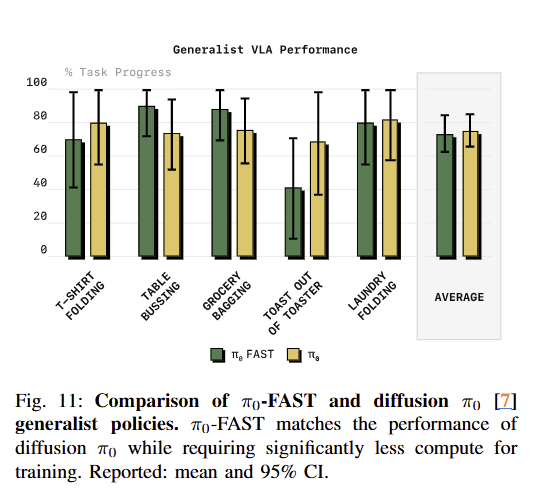
fig 10~11에서 보이는 바와 같이 low-frequency에서는 Diffusion 방식이 우세하나, high-frequency인 태스크에서는 FAST가 더 나은 성능을 보임. DROID는 15hz임에도 diffusion보다 더 좋은 성능을 보임. 이는 diffusion pi-zero model이 language instructions을 종종 무시하는 문제가 있다고 합니다. 이러한 특성이 성능에 큰 영향을 주었다고 합니다.