안녕하세요. 박성준 연구원입니다. 오늘 리뷰할 논문은 Finetune Like You Pretrain(FLYP)로 대규모 이미지-텍스트 사전학습 모델의 미세조정 방법을 다룬 연구입니다.
Introduction
대규모 이미지-텍스트 사전학습 모델인 CLIP의 등장 이후 zero-shot으로 다양한 이미지 분류 task에서 높은 성능과 강건성(robustness)을 보일 수 있게 되었습니다. 예를 들어, 이미지 분류 task에서 각 클래스 이름에 대한 프롬프트를 작성하고, 입력 이미지의 임베딩과 프롬프트의 텍스트 임베딩 중 가장 유사한 클래스를 예측하는 방식으로 별도의 지도 학습 없이도 이미지를 분류할 수 있습니다. 하지만, 이러한 zero-shot 분류기의 성능을 높이기 위해서 여전히 미세조정(supervised fineuning)이 활용되고 있습니다. 소량의 라벨을 활용하여 사전학습 모델을 추가적으로 미세조정하는 것으로 zero-shot 분류기의 성능을 강화하는 방식입니다. 문제는 이러한 미세조정 기법이 라벨이 소량으로 주어지는 학습 데이터의 분포 내 데이터(in-distribution, ID) 성능은 향상시키는데 유효하지만, 분포가 달라진 테스트 데이터(out-of-distribution, OOD) 성능 및 강건성은 낮춘다는 문제를 가지고 있습니다. 이에 따른 최근 연구들은 미세조정 학습을 거친 최종 분류기가 ID 및 OOD 모두에서 강건하게 작동할 수 있도록 하는 것을 목표로 하고 있습니다. 현 SOTA 모델(논문이 발표되는 2023년 기준)은 zero-shot 모델과 미세조정 모델의 가중치를 앙상블하는 기법을 통해 OOD의 성능을 개선했습니다. 하지만, 이 방법은 CrossEntropy loss 기반의 표준 지도학습에서 약간의 변형을 가한 방식으로 최적의 미세조정 방법이라고 부르기에는 애매한 면이 있었습니다(저자는 위 방법이 모델을 활용하는 방법일뿐, 미세조정 학습 과정이라고 보기에는 어렵다고 주장하고 있는 것 같습니다).
저자는 “Finetune Like You Pretrain”이라는 심플한 모토와 함께 기존의 미세조정 기법과 달리 사전 학습과 동일한 방식으로 미세조정하는 단순한 아이디어 만으로도 기존 방법들을 뛰어넘는 성능과 강건성을 얻을 수 있음을 주장하고 있습니다. 구체적으로 저자가 제안하는 FLYP(Finetune Like You Pretrain)은 downstream 클래스 라벨을 텍스트 프롬프트로 변환하여 CLIP의 사전 학습 과정과 마찬가지로 Contrastive Learning을 미세조정에 그대로 적용합니다. 즉, 이미지-텍스트 쌍을 구성하여 Contrastive Learning을 통해 학습합니다. 저자는 이 FLYP 방법론이 OOD, few-shot, transfer learning 등 다양한 조건에서 일관되게 SOTA에 가까운 성능을 달성하였음을 강조하고 있습니다.
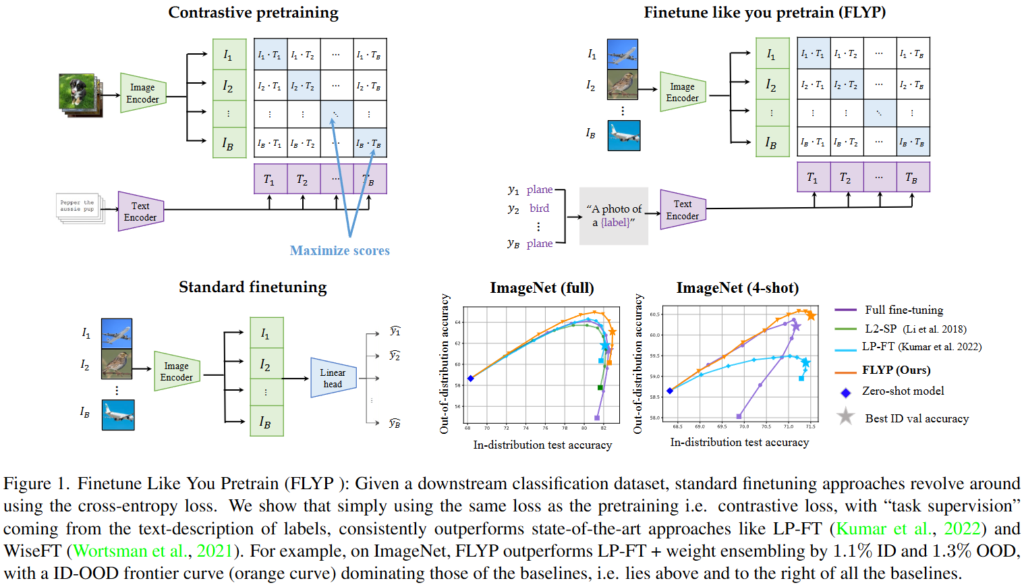
Figure 1.은 저자가 주장하는 바를 잘 보여주고 있는 그림으로 제안하는 FLYP의 구조를 보여주고 있습니다. 왼쪽 하단의 일반적인 미세조정 방식과는 다르게 우측 상단의 FLYP는 Contrastive Learning과 같은 방식으로 미세조정하고 있습니다. 우측 하단의 그림은 ID와 OOD 모두에서 FLYP(주황색)이 가장 좋은 성능을 보이는 것을 확인할 수 있습니다.
Motivation
CLIP은 이미지-텍스트 쌍을 대규모로 수집한 데이터셋에 대해 Contrastive Learning으로 학습된 모델로 주어지는 이미지와 텍스트 캡션을 임베딩 공간으로 매핑하는 이미지 인코더와 텍스트 인코더로 구성되어 있습니다. 사전 학습 시에 미니 배치 내에서 positive 쌍의 임베딩은 가깝게, negative 쌍의 임베딩을 멀어지도록 다음과 같은 infoNCE loss를 통해 학습합니다.
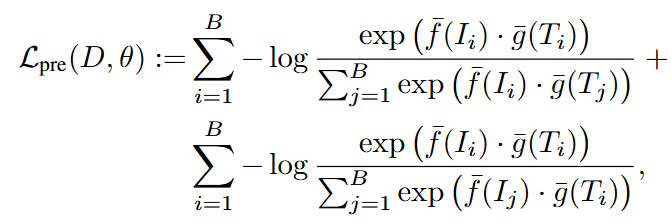
\theta = [\theta_{img}, \theta_{text}]는 각각 이미지 인코더와 텍스트 인코더의 파라미터를 의미합니다. \bar{f}, \bar{g}는 정규화된 임베딩을 의미합니다.
이처럼 학습되는 CLIP은 추가적인 지도 학습 없이 텍스트 프롬프트를 통해 이미지 분류를 수행할 수 있습니다. 예를 들어, k개의 클래스 이름 [c_1,\dots,c_k]에 대해서 “a photo of a {class}”와 같은 미리 정해둔 프롬프트 집합[T_1,\dots,T_k]을 준비하고, 새로운 이미지에 대해서 프롬프트에 클래스가 들어간 텍스트의 임베딩과 이미지의 임베딩 사이의 유사도를 계산하여 가장 높은 유사도를 보이는 클래스를 선택합니다. 위와 같은 방식의 zero-shot 분류기는 상당히 정확한 정확도를 보이는 동시에 데이터 분포 차이에 대한 OOD 강건성이 뛰어납니다.
하지만, dwonstream 과제에서의 성능을 극대화하기 위하여 보통 사전학습 모델인 CLIP을 해당 task의 라벨링된 데이터에 맞춰 파인튜닝하게 됩니다. Figure 1.의 좌측 하단에 있는 그림과 같이 일반적인 미세조정 방식은 Linear Probing입니다. 사전학습된 이미지 인코더의 파라미터는 고정한 채 선형 분류기만을 학습하는 방법과 이미지 인코더의 파라미터까지 모두 학습하는 full finetuning 방법이 있습니다. 일반적으로 CrossEntropy loss를 통해 학습됩니다. 위 두가지 방법 모두 자주 사용되는 미세조정 방법이고 장단점이 존재하지만, 두 방법 사이의 장단점 비교는 우선 넘어가고 두 방법에서 공통적으로 식별되는 문제를 다뤄보겠습니다. Introduction에서부터 계속 강조하고 있는 OOD 데이터의 성능이 낮아지는 문제입니다. 사전 학습 모델이 지닌 일반화 능력이 약해지는 문제입니다.
OOD 데이터의 성능이 낮아지는 문제는 CLIP이 제안된 이후 미세조정 과정에서 계속해서 주목받던 문제로 미세조정 연구에서 연구되어 왔습니다. 논문이 게재될 당시(2023년) OOD 문제를 다룬 대표적인 미세조정 방법으로는 LP-PT와 WisePT가 있습니다.
먼저, LP-PT(Linear Probe the Full Tune)은 먼저, 이미지 인코더의 가중치를 고정한 후에 선형 분류기를 학습합니다(Linear Probe 단계). 이후, 분류기의 가중치를 초기값으로 설정하여 전체 모델을 미세조정(Full Tune 단계)하는 2stage 전략으로 OOD의 강건성을 확보하여 SOTA를 달성하였습니다. 해당 방법론이 왜 OOD에 강건한지에 대한 내용은 질문을 남겨주시면 답변하겠습니다.
두번째로 WiseFT(Weight Ensembling)은 미세조정된 모델 파라미터 \theta'와 사전학습된(미세조정되지 않은) 모델의 파라미터\theta를 가중합으로 섞는 방식으로 \alpha \in [0,1]에 대해 앙상블 가중치 \theta_{we} = \alpha,\theta'_{img} + (1-\alpha),\theta_{img}로 모델을 만듭니다. 적절한 \alpha값으로 조합하는 것으로 ID와 OOD 성능 사이의 trade-off를 조절할 수 있습니다. 하지만, 저자는 기존의 대부분 방법론들은 여전히 CrossEntropy loss 기반의 지도학습 프레임워크 안에서 사전학습 모델에 작은 변화를 가하는 방식이었기에 사전학습 과정 자체를 고려한 새로운 미세조정 패러다임에 대한 탐구는 아니었다고 지적합니다.
FLYP: Finetune like you pretrain
저자가 제안하는 FLYP은 새로운 미세조정 방식으로 사전학습과 같은 Contrastive Learning을 활용하여 CLIP과 같은 zero-shot 모델을 미세조정하는 방법입니다. FLYP의 과정은 다음과 같습니다.
- 분류 데이터셋의 각 클래스 라벨y에 대응되는 하나 이상의 텍스트 프롬프트 집합 T-y를 정의합니다. 예를 들어 클래스가 강아지, 고양이라면, 프롬프트는 “a photo of a small {class}” 등을 사용할 수 있습니다.
- 미세조정과정에서 각 학습 샘플마다 프롬프트 중 하나를 무작위로 선택하여 이미지-텍스트 쌍을 구성합니다.
- 구성된 이미지-텍스트 쌍을 Constrastive Learning을 통해 이미지 인코더와 텍스트 인코더 모두를 학습합니다.
아래의 알고리즘 1은 FLYP 알고리즘의 작동방식을 설명하고 있습니다.

추론 시에는 Contrastive Learning을 통해 학습된 이미지 인코더와 텍스트 인코더를 사용하며, 기존 CLIP의 zero-shot 이미지 분류 방식과 같은 방식으로 추론합니다. 저자는 기존의 미세조정 방식과 자신들이 제안하는 미세조정 방식의 세가지 주요 차이점을 강조하고 있습니다.
- 텍스트 인코더의 학습 여부: 기존의 많은 파인튜닝 방법은 이미지 인코더만 학습하고 텍스트 인코더에는 손대지 않았지만, FLYP는 텍스트 인코더까지 함께 학습합니다. 이는 사전학습 동안 구축된 이미지-텍스트의 joint 임베딩 공간을 유지 및 개선할 수 있는 잠재력을 준다고 설명하고 있습니다.
- 분류기 구조의 차이: 저자는 CrossEntropy loss를 통한 선형 분류기의 학습을 통한 분류가 아니가 클래스 텍스트 임베딩과 이미지 임베딩의 유사도를 기반으로 분류를 수행합니다. 즉, FLYP는 클래스 간 유사도 구조를 통해 분류를 수행하기에 기존의 선형 분류기를 통한 분류와는 차이가 있습니다. 저자는 한 실험을 통해서 CrossEntropy loss에 텍스트 임베딩 기반 분류기를 결합해보았지만, FLYP의 성능은 나오지 않았다는 것을 보여주며 FLYP의 방법이 가장 효과적인 방법임을 주장합니다.
- 프롬프트의 확률적 적용: 저자는 FLYP가 미니배치마다 각 샘플의 텍스트 프롬프트를 무작위로 선택하여 사용하기에 약간의 무작위성(stochasticity)가 추가된다고 설명합니다. 기존의 미세조정은 주어진 이미지에 대한 loss 계산이 항상 동일한 레이블에 기반한다는 한계가 있고 FLYP의 이러한 프롬프트의 확률적 적용은 데이터 증강(data augmentation)과 같은 효과를 낼 수 있습니다.
FLYP는 개념적으로 굉장히 간단하지만, 추가적인 복잡도가 없이도 기존 방법들을 능가하는 성능을 보여준다는 점에서 시사하는 바가 크다고 생각합니다. FLYP자체는 새로운 모델의 구조도, loss도 제안하지 않기에 방법론의 novelty가 없음에도 불구하고 CVPR에 게재되었습니다. 이는 단순하게 놓치고 있던 부분이 실제로 가장 뛰어나다는 것을 입증하였으며, 체계적인 실험을 통해 단순한 방법이 얼마나 효과적인지를 잘 보여주고 있기 때문이라고 생각합니다.
Experiments
저자는 FLYP의 효과를 증명하기 위해서 다양한 벤치마크에서의 평가를 보여주고 있습니다. 사용한 사전학습 모델은 CLIP(ViT-B/16)이며, zero-shot, LP(Linear Probe), FT(Full Fintune), LP-FT, S2-SP(L2정규화를 거친 미세조정), WiseFT와의 비교를 통해서 성능을 검증합니다. ID, OOD에서의 성능, few-shot, transfer learning 총 3가지 task에서의 성능을 평가하였습니다. 데이터셋은 ImageNet, WILDS-iWILDCam, WILDS-FMoW를 포함하는 8가지의 데이터셋을 활용하였습니다.
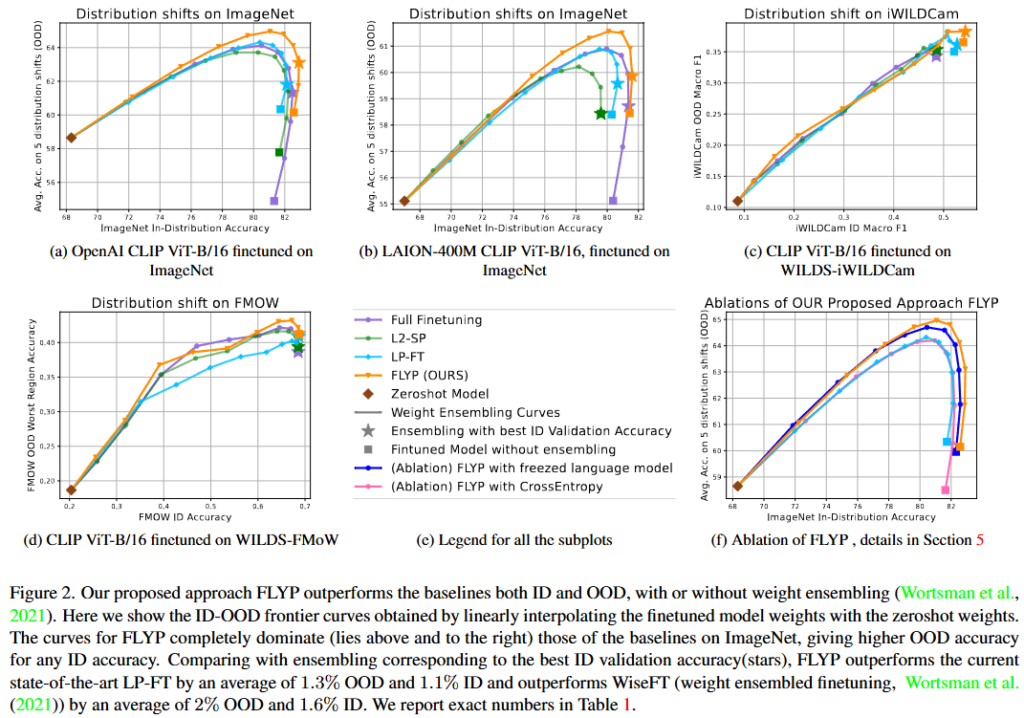
Figure 2.는 FLYP가 OpenAI CLIP, LAION CLIP, WILDS-iWildCam, FMoW 모든 환경에서 기존의 방법들보다 좋은 성능을 보이고 있음을 알려주고 있습니다. 그림에서 보여주다싶이 ID와 OOD 모두에서 높은 성능을 보이며 Contrastive Learning기반의 미세조정이 OOD의 성능을 잘 유지하고 있을 뿐만 아니라 ID에서도 기존의 선형 분류기를 통한 미세조정보다도 더욱 효과적임을 보여주고 있습니다.
아래는 ID와 OOD에서의 정량적 실험 결과를 보여주는 표입니다. ImageNet 데이터셋의 5가지 OOD를 평가하기 위한 변형 데이터셋들과 WILDS 벤치마크 중 iWildCam(카메라 트랩 동물 사진, 환경 변화 OOD 데이터셋)과 FMoW(위성사진, 시간 변화 OOD 데이터셋)을 활용하였습니다.
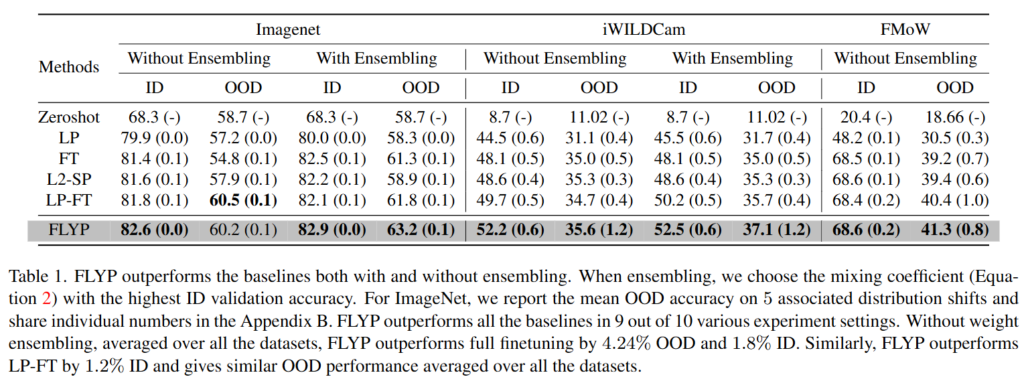
10가지 중 9가지 세팅에서 SOTA를 달성했으며 평균적으로도 다른 방법에 비해 좋은 성능을 보이는 것을 확인할 수 있습니다. WiseFT의 가중치 앙상블을 적용한 경우에는 더욱 향상된 성능을 보이고 있습니다. 비교군들을 거의 모든 데이터셋에서 능가하는 성능을 보이는 것이 인상적입니다.
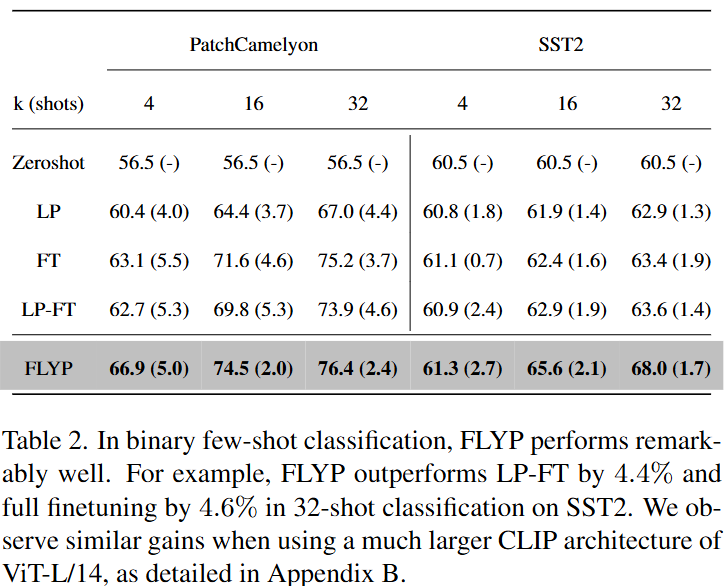
Table 2.는 few-shot 학습에서의 성능을 보여주는 표입니다. 모든 세팅에서 제일 좋은 성능을 보이고 있는 것을 확인할 수 있습니다. 평가에 사용한 데이터셋은 PatchCamelyon(암세포 이진분류)과 SST2(텍스트 감정 분류, 문장을 이미지로 렌더링한 데이터)로 fine-grained의 이미지 분류 데이터셋입니다. 세밀한 이미지 분류에서 few-shot 세팅에서도 높은 성능을 보이는 것을 저자는 실험을 통해 보여주고 있습니다. 다시 한번 FLYP가 효과적인 미세조정 방법임을 보이고 있습니다.

Figure 3.을 확인하면 few-shot의 세밀한 이미지 분류에서는 ID,OOD보다도 비율적으로는 더욱 기존 방법들에 비해 뛰어난 것을 확인할 수 있습니다.
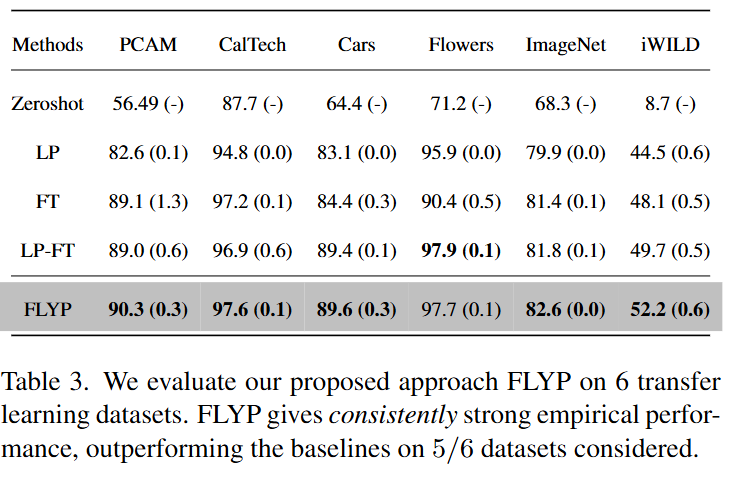
마지막으로 table 3.은 transfer learning 에서의 성능입니다. 마찬가지로 대부분의 데이터셋에서 높은 성능을 보이고 있습니다. Flowers 데이터셋에서는 SOTA가 아니지만, 이미 성능이 꽤나 높기 때문에 SOTA에 준하는 성능을 달성한 것으로 FLYP의 효과를 보여주기에는 충분한 것 같습니다. 일분 데이터셋(Flowers, Cars)에서는 CrossEntropy loss를 통한 FT의 성능이 오히려 떨어지는 것을 확인할 수 있는데 이는 전체 파라미터를 미세조정하는 과정에서 과적합 혹은 기존 지식이 무너지는 단점이 드러난 것으로 저자는 분석하고 있습니다. LP-FT와 같은 복잡한 2stage의 학습 방법이 아니더라도 단순한 FLYP의 접근이 제일 좋은 성능을 보인다는 것을 저자는 강조하고 있습니다.
Ablation Study
저자는 총 4가지 ablation study를 진행하였습니다.
첫번째는 class collision효과를 확인하기 위한 실험으로 contrastive learning은 경우에 따라 미니 배치 내에서 같은 클래스여도 negative 쌍으로 구분하는 경우가 생길 수 있습니다. 이는 class 사이의 충돌을 야기하여 성능에 하락을 야기할 수도 있습니다. 따라서 저자는 동일 클래스인 negative 샘플을 마스킹하는 것으로 class collision 문제를 해결하려 한것인데 결과는 놀랍게도 마스킹을 하는 것이 오히려 1.3% 낮은 성능을 보였다는 점입니다. 저자는 사전학습 과정을 다른 방식으로 바꾸면 득보다는 실이 많다고 설명하며, FLYP에서 발생하는 class collision문제는 문제가 아니라고 설명하고 있습니다. 정리하면, 사전학습에서 사용한 방식을 그대로 사용하는 것이 미세조정을 할 때에 가장 효율적인 방법이라 저자는 주장하고 있습니다.
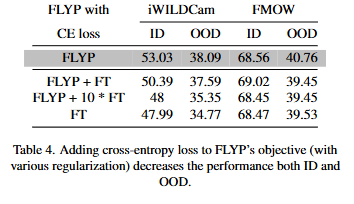
두번째는 CrossEntropy를 통해 텍스트 인코더까지 학습을 하는 것에 대한 ablation study입니다. 저자는 FLYP의 성능향상이 사전학습과 같은 방식을 사용했기 때문인지, 이미지 인코더뿐만 아니라 텍스트 인코더도 학습했기 때문인지를 확실하게 하기 위하여 이미지 인코더만 학습하는 기존의 방법론에 CrossEntropy를 통해 텍스트 인코더도 학습하는 것을 통해 확인하고자 했습니다. Table 4.는 그 실험에 대한 결과를 보여주고 있습니다. 결과는 FLYP의 성능이 2% 가량 더 높았으며 이는 CrossEntropy를 통한 학습이 아닌, 사전학습때에 사용했던 InfoNCE loss를 사용하는 것이 성능이 더 높았으며 다시한번 사전학습에 학습한 방식을 그대로 미세조정에 사용하는 것이 가장 효율적인 방법임을 주장하고 있습니다.
세번째는 텍스트 인코더의 가중치 비중 ablation study입니다. 텍스트 가중치를 freeze하고 실험하는 것으로 저자는 텍스트 인코더의 비중을 확인하고자했고 텍스트 인코더도 같이 학습하는 것이 더 좋다는 결론을 내렸습니다. 약 2.5% 정도 차이가 난다고 합니다.

마지막으로는 프롬프트의 개수입니다. 저자는 프롬프트의 개수를 다르게 하는것으로 성능의 차이가 얼마나 많이 나는지를 확인하고자 했습니다. Figure 4.는 프롬프트의 개수에 따른 결과를 보여주고 있습니다. 결과는 큰 차이는 나지 않았습니다. 프롬프트가 여러개인것은 학습에 무작위성을 추가하는 것으로 데이터 증강의 효과를 가지기에 본질적으로는 큰 차이를 주지못한다고 저자는 주장하고 있습니다.
마지막으로 저자는 이 FLYP의 방법이 기존의 선형 분류기를 통한 미세조정보다 더 좋은 명확한 이유는 잘 모른다고 설명하고 있습니다(?). 그리고 사전학습과 동일한 목표(loss)를 사용하여 미세조정을 하는 것이 가장 좋은 결과를 보인다는 것을 경험적으로 파악했으며, 여러 실험과 ablation을 통해 이를 증명했다고 설명하고 있습니다. 저자는 이러한 결과가 앞으로의 연구에 새로운 방향성을 가져다주기를 기원한다고 설명하며 논문을 마칩니다.
“사전학습할 때 그 방식이 좋았다면, 미세조정할 때도 그 방식을 사용해라” 라는 단순한 아이디어를 저자가 실제 실험을 통해 증명했고, 학습의 일관성의 중요성을 강조하고 있습니다. 단순한 아이디어인데 여러가지 실험을 통해 방법론적인 novelty없이도 SOTA 달성 및 우수학회에 논문 게재된 것이 굉장히 흥미로운 연구였습니다.
감사합니다.
안녕하세요 성준 연구원님 리뷰 흥미롭게 읽었습니다. 감사합니다.
사전학습에서의 학습 방법 그대로 downstream task 학습에서의 파인튜닝과정에서 동일하게 사용한다는 점이 흥미로웠습니다.
읽다가 기존 연구에서는 왜 본 연구의 방법론을 적용해보지 않았을지에 대해서 궁금했습니다. 또한
LP-FT의.방법론이 기존의 파인튜닝 방법과 다른점이 무엇이고 어떻게 OOD에서 강인한지에 대해서 설명해주시면 감사하겠습니다.
안녕하세요 류지연 연구원님 좋은 댓글 감사합니다.
먼저 LP-FT는 2stage 방법론으로 기존의 미세조정(finetuning)에서는 이미지 인코더를 freeze한 후에 이미지 인코더를 통해 추출한 벡터를 입력으로 받아 선형 분류기를 통해 이미지를 분류하는 방법과 이미지 인코더를 freeze하지 않는 두가지 방법이 존재합니다. 순서대로 각각 Linear Probing(LP)와 Full fineTuning(FT)라고 불립니다. LP-FT는 이름에서 유추할 수 있듯이 두가지 방법을 모두 사용하는 방법입니다.
1-stage에서는 LP를 통해 선형 분류기를 학습합니다. 그리고 2-stage에서는 FT를 수행합니다. 이렇게 2단계로 미세소정을 하는 이유에는 두가지 아이디어가 있습니다. 먼저, LP 단계에서 이미지 인코더의 가중치를 freeze하기 때문에 기존 이미지 인코더가 갖고 있는 지식을 보존할 수 있다는 장점이 있습니다. 이후에 FT 단계에서는 분류기가 학습되어 있기 때문에 좋은 초기화(initialization)되어 있는 상태에서 FT를 할 수 있기에 모델의 파라미터가 크게 변하지 않고 말그대로 미세조정할 수 있기 때문에 기존의 지식이 많이 망가지는 것을 방지할 수 있습니다. 결과적으로 기존의 지식을 잘 보존하는 동시에 목표로하는 데이터의 지식도 잘 반영할 수 있기에 OOD와 ID에서 기존의 미세조정 방법보다 모두 개선된 성능을 보일 수 있습니다.
감사합니다.
안녕하세요 박성준 연구원님. 리뷰 잘 읽었습니다.
FLYP 방법은 Contrastive Learning을 그대로 사용하는데, 만약 downstream task가 단순 분류가 아니라 detection이나 segmentation 같은 복잡한 task라면 FLYP 방식을 그대로 적용할 수 있을까요?
안녕하세요 이상인 연구원님 좋은 댓글 감사합니다.
논문에서 이미지 분류에서 더 나아가 detection이나 segmentation으로의 확장에 관련된 내용은 포함되어있지 않습니다. 하지만, detection, segmentation에서도 CLIP과 같은 대규모 사전학습 모델을 활용하는 연구의 경우, 타겟 클래스에 대한 백본의 지식을 강화하기 위해서 FLYP의 방법을 활용할 수 있을 것 같습니다. 결국 논문을 읽으며 제가 파악한 FLYP의 핵심은 사전학습 때에 효과적인 방법이 미세조정 과정에서도 효과적인 방법임을 보여주는 논문이라고 생각하기에 이미지 분류가 아닌 task에서도 FLYP를 적용할 수 있을 것이라 생각됩니다.
감사합니다.
안녕하세요 성준님 좋은 리뷰 감사합니다.
본문의 “FLYP: Finetune Like You Pretrain”에서는 텍스트 프롬프트를 “a photo of a small {class}”처럼 약간 더 디테일한 형태로 구성했습니다. 그런데 이 프롬프트가 실제 이미지의 세부 내용과 정확히 일치하지 않아도 사용될 수 있는 이유를, 일종의 데이터 Augmentation 효과로 생각할 수 있을까요?
감사합니다.
안녕하세요 정의철 연구원님 좋은 댓글 감사합니다.
FLYP의 학습에 활용되는 텍스트 프롬프트는 기본적으로 사전학습 때에 활용한 프롬프트를 그대로 활용하고 있습니다. 실제 이미지의 세부 내용과 정확하게 일치하지 않더라도 의철님이 댓글로 남겨주신 것처럼 일종의 data augmentation 효과로 저자는 프롬프트의 활용을 설명하고 있고, 미세조정 과정에서 ID 데이터에 과적합되어 강건성을 잃어버리는 것을 방지해 일반화 능력을 향상시키는 효과를 내고 있습니다.
감사합니다.
안녕하세요 성준님, 한번 알아둘 필요가 있던 논문인데 구체적인 내용 감사합니다.
LP-FT 방식을 나름대로 생각해봤었는데 위에 답변을 읽고 제 생각과 어느정도 일치한다고 생각했습니다.
결국 목표로 하고자 하는 방식에 따라 여러 방법을 적용할 수 있을 것 같습니다. 해당 논문에서 OOD 의 강건성을 중요하게 생각하는 것이 2stage 방식의 fine tuning 방식을 생각하게 한 것 같습니다. 해당 방식을 적용하기 이전에 ID 와 OOD 의 성능이 둘다 좋게 나올거라고 예측할 수 있었을지는 모르겠으나 좋은 접근이라고 생각합니다.
해당 리뷰를 읽으면서 이해한 부분들과 궁금한점들을 적어보자면
기존 CLIP 을 fine tuning 하는 과정중 이미지 인코더만 학습하고 텍스트 인코더는 동결하는 방식뿐만 아니라 둘다 학습하거나 텍스트 인코더만 학습하는 그러한 ablation study가 존재 했었는지 궁금합니다. 없더라도 둘다 학습하는것도 기본적으로 시도해볼법 하다고 생각하는데, 원하는 task 에 따라서 이미지 인코더만 학습시킬지 텍스트 인코더까지 학습시킬지를 정하는 것이 아닌가 하는 생각을 했습니다. ( 해당 생각이 든 이유는, 이미지 인코더만 fine tuning 하는 것이 이미지-임베딩 벡터 스페이스를 안좋게 만들 수 있다고 생각했는데 그럼에도 이미지 인코더만 fine tuning 하는 이유가 있지 않을까 싶었습니다.)
그리고 OOD와 ID 에대한 개념이 약간 잘 이해가 안되는 것 같습니다.
우선 기본 pre-trained 된 CLIP 의 모델기준으로는 모든 이미지가 OOD인지 궁금합니다.
맞다면 학습하게되는 것들이 ID가 될 거라고 생각했습니다.
이때 드는 의문이 fine tuning 을 하게되는데 어떻게 OOD 의 성능이 더 오를 수가 있는지 궁금합니다. ( OOD 와 ID성능이 trade off 라면 OOD 성능이 원래부터 더 높아 절벽형태로 커브를 그려야하는게 아닌가 싶은 질문입니다.)
답변해주시면 감사하겠습니다.
안녕하세요 신인택 연구원님 좋은 댓글 감사합니다.
저자는 FLYP의 미세조정 방식이 사전학습과 같은 방식이어서 성능이 좋은 건지, 텍스트 인코더도 같이 학습하기 때문인지를 파악하기 위해 ablation study에서 이미지 인코더와 텍스트 인코더를 기존의 선형 분류기를 통한 미세조정 방식으로 학습하여 성능을 비교합니다. 결과적으로 이미지 인코더만 미세조정할때보다는 성능이 개선되었지만, FLYP의 성능에는 못미치는 성능을 보여줍니다. 저자는 이 결과를 토대로 텍스트 인코더를 이미지 인코더와 같이 학습하는 것이 공통된 임베딩 공간에 매핑할 수 있고, 선형 분류기를 학습하는 것보다 FLYP의 방식대로(사전학습과 같은 방식대로) 학습하는 것이 더 효율적임을 실험적으로 증명하고 있습니다.
ID(in-distribution)와 OOD(out-of-distribution)는 단순하게 생각하면 미세조정에 학습하는 타겟 데이터는 ID, 그 외의 데이터는 OOD라고 생각해주시면 될것 같습니다. 즉, CLIP은 대규모 데이터로 학습되었기에 일반적인 객체에 대한 지식을 가지고 있습니다. 만약에 강아지 종 이미지 분류를 위해 웰시코기, 푸들, 진돗개 등의 데이터를 입력으로 미세조정 학습을 하게 된다면, 강아지 종이 아닌 의자, 책상과 같은 데이터는 OOD 데이터가 되는 것입니다. 즉, 기존의 미세조정 학습은 강아지 종 분류를 위해서 학습을 하면 의자, 책상과 같은 다른 데이터에 대한 정보를 잊어버리는 문제가 존재했었는데, FLYP는 그 잊어버리는 정도를 최소화할 수 있습니다.
감사합니다.
안녕하세요 성준님, 좋은 리뷰와 좋은 세미나 감사드립니다.
세미나를 듣고나서 해당 내용이 흥미로워서 성준님 리뷰를 읽게되었습니다.
세미나 당시에 질문을 하려다가 못드린 부분이 있었는데, 이에 대한 질문을 하고자 댓글 드립니다.
현재 해당 논문은 classification 문제에 초점이 맞춰져 있는데, 일반적인 vision-language task에 얼마나 확장 가능할지가 궁금합니다. 예를 들어 FLYP는 더나아가 조금 구조가 복잡해지는 object detection task에도 해당 finetuning 벙법을 적용하여도 성능이 오를지 궁금합니다. 감사합니다!
안녕하세요 안우현 연구원님 좋은 댓글 감사합니다.
저자가 본 연구에서 강조하는 contribution은 사전학습 때에 사용한 학습 방식이 finetuning에서 가장 좋은 학습방식이라는 점입니다. vision-language 분야에서 이 주장을 보여주기 위하여 저자는 vision-language 모델을 활용한 이미지 분류에서 실험을 보였습니다. 논문에서 다른 연구로의 확장에 관한 내용은 존재하지 않지만, 구조가 복잡해지는 object detection task에서도 충분히 활용할 수 있을것이라 생각됩니다. 어느정도 성능이 오를지는 잘 모르겠네요.
감사합니다.