안녕하세요 류지연입니다.
오늘 리뷰하려고 가져온 논문은 RegionCLIP입니다. 랩세미나에서 늘 CLIP이 언급돼서 늘 궁금했었는데요 동기 연구원의 기초교육 일정에 RegionCLIP 논문을 읽는 게 있어서 CLIP연구와 함께 기본이 되는 연구라고 생각이 들어서 선택했었습니다. 기존에 대량의 이미지-텍스트쌍에 대해 학습해 이미지 분류 태스크에서 좋은 성능을 보인 CLIP을 object detection에 적용할 수 있게 확장시킨 연구라고 보시면 됩니다. 본 연구에서는 CLIP을 Object Detection task에 바로 적용하는데의 어려움을 설명하며 이를 보완한 RegionCLIP을 제안합니다.

1. Introduction
본 연구 이전에도 vision-language representation을 학습하는 모델로 대표적인 CLIP, ALIGN이 있었습니다. 이미지와 그에 매칭되는 캡션을 매칭하는 방법으로 이미지-텍스트간의 관계를 학습했었는데요 여러 비전 task에 적용이 됐었고 특히 이미지 분류에 있어서 높은 성능을 보였었습니다. 자연스럽게 이를 Object Detection에도 적용해볼 수 있을지를 궁금해하는 사람들이 생기고 본 논문의 저자또한 이 부분을 확인하고자 해당 연구를 진행했었습니다.

이미지와 텍스트 쌍으로 사전학습한 CLIP을 가져와 R-CNN기반의 object dector를 만들어 이미지의 일부 영역을 crop한 후 텍스트와 매칭하도록 학습하고 실험해본 결과 분류 task에 비해 성능이 저조했습니다. (우측 막대 차트 참고) 실제 detection을 확인해보아도 (좌측 이미지 참고) 남자아이에 대한 좁은 영역의 바운딩 박스내에서 55%의 확률로 boy라고 예측하지만 이보다 더 큰 영역에서도 65%의 확률로 객체를 boy로 예측했다는 것을 확인할 수 있습니다. 이는 CLIP이 이미지 속 세부 영역에 대해 정확한 representation을 학습해서 boy라고 검출하는 거라고 볼 수 없습니다. 저자는 image-level의 캡션을 이미지 전체에 대해 매칭하도록 학습하기 때문에 캡션 내의 토큰 마다 가리키는 객체가 이미지에서 어디에 위치하는지 같은 region에 대한 정보는 학습되지 않는 게 문제의 원인이라고 설명합니다. 본 연구는 이를 보완하고자 이미지의 region-level의 representation 또한 학습해 Object Detection에서도 분류에서만큼의 좋은 성능을 얻을 수 있는 RegionCLIP을 제안하고 COCO, LVIS 데이터셋에 대해 Object Detection task에서 SOTA의 성능을 보였습니다.
본 연구의 contribution을 요약하자면 이미지의 region과 이와 매칭되는 region 기반의 캡션을 추가적인 annotation 작업 없이 만들고 이를 학습해 사전학습 모델이 Object Detection 작업에서 중요한 regional 한 representation을 학습하도록 한 것입니다.
2. Related Work
간단히 visual representation을 학습해 이미지 분류나 객체 검출을 수행하는 모델에 대한 기존 연구들이 어떤 과정으로 발전해왔는지에 대해 얘기하겠습니다.
이미지 분류나 객체 검출에 대해 초기에는 사람이 이미지마다 레이블을 단 데이터셋을 가지고 학습했다고 합니다. 라벨링된 데이터로 잘 학습된 모델을 가지고 라벨이 없는 데이터에 pseudo label을 붙이고 학습 시키는 semi-supervised learning이 제안됐었고요. 이후 annotation에 대한 비용부담으로 부터 자유로울 수 있는 방법인 self-supervised learning이 제안됐었습니다. 각 vision task에 대해 필요한 visual representation을 학습하도록 pretext task를 정의하고 이미지 내의 representation을 학습시킨 후 사전학습된 모델을 transfer해 원래의 타겟 task를 수행하도록 하는 방법입니다. 최근까지 진행되고 있는 연구로는 인터넷으로 부터 가져온 대량의 이미지-텍스트 데이터를 가지고 vision-language representation에 대한 사전학습을 시키는 방법입니다. 하지만 해당 연구는 보통 모델이 image-level의 representation만을 학습한 이미지 분류에 특화된 연구가 대부분입니다.
3. Method
본 연구의 목표는 visual encoder가 image region을 인코딩할 수 있게 하고 language encoder로부터 인코딩된 region description을 매칭할 수 있게 하는 것입니다.
다음으로 본 연구에서 제안하는 방법론에 대해 설명을 드리도록 할게요. 아래 Figure 2.는 본 연구의 Method의 overview를 나타낸 것입니다.
Visual region representation
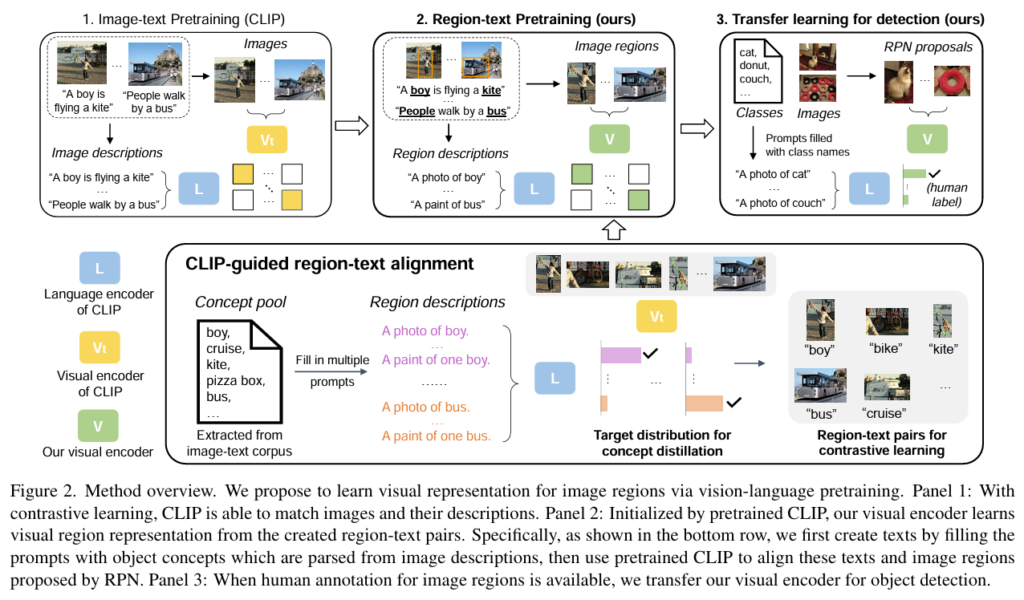
데이터셋의 이미지들은 object localizer로 객체가 있을 법한 곳에 대한 region을 뽑아냅니다. 본 연구에서는 RPN을 사용합니다. 총 N개의 region이 propose된다고 했을 때 region 집합은 다음과 같이 나타낼 수 있습니다. \{ r_i\}_{i=1, ..., N} 그리고 모든 region을 CLIP의 visual encoder에 통과시켜 각 region r_i 마다 visual representation을 v_i 뽑습니다.
Semantic region representation
보통 하나의 이미지에는 여러 객체가 있습니다. 어떤 데이터셋은 또 여러 category의 데이터로 구성된 이미지로 이뤄져 있고요. 데이터셋의 모든 이미지에서 각 객체마다 label을 다는 것은 비용이 큽니다. 사람이 수작업으로 anntation을 하지 않고도 이미지의 각 region 마다 캡셔닝하는 방법을 저자가 새롭게 제안한 것이 본 연구의 contribution 중 하나였는데 그 방법은 다음과 같습니다.
데이터셋에 있는 모든 이미지 캡션에 대해서 parsing을 해 각 캡션에서 명사처럼 문장 속 중요한 의미를 갖는 단어들을 (논문에서는 object concepts라고 합니다.) 가지고 cocept pool을 만듭니다. 그리고 region description 즉 하나의 영역에 대한 표현으로 사전에 정의된 템플릿에 각 concepts를 넣어 description을 만듭니다. 예를 들어 ‘a boy holding a kite’라는 캡션이 어떤 이미지에 대해 매치되었었다면 boy와 kite라는 단어가 각각 object concept로 concept pool에 속하게 되고 그 중 kite에 대해서만 봤을 때 ‘a photo of kite’라는 region descriptor가 만들어지게 되는 것입니다. language decoder에 통과시켜 각 region description을 하나의 semantic embedding으로 변환합니다. C개의 concepts가 있다고 했을 때 \{ r_i\}_{i=1, ..., N}의 semantic embedding이 도출됩니다. concept pool로 부터 semantic embedding을 생성하는 과정은 Figure 2.에서의 아래 panel에 해당됩니다. 이후 CLIP과 같은 teacher encoder에 (앞서 Visual region representation 단계에서 각 이미지마다 추출했던) image region 에 대한 visiual 임베딩과 region descriptor 임베딩을 align 시킵니다. 논문에서 제안하는 visual encoder는 contrastive learning과 distillation의 방법으로 이 region-region descriptor 쌍을 매칭하도록 학습합니다. 이렇게 사전학습한 모델을 가지고 Zero-shot과 OVOD가 가능합니다.
Alignment of region-text pairs
visual encoder (teacher encoder)를 가지고 image region과 region descriptor을 임베딩한 concept embedding간의 correspondence를 학습합니다. 해당 부분은 Figure 2.의 두번째 panel에 나타내져 있습니다. 각 image region과 concept embedding은 Mathching score는 코사인 유사도로 계산됩니다. 이 코사인 유사도 값은 -1과 1사이의 값으로 1에 가까울 수록 유사도가 높은 임베딩 쌍이됩니다. 해당 식은 다음과 같습니다.
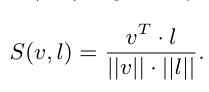
코사인 유사도가 높은 쌍에 대해 묶이게 되는데요 이렇게 도출된 region-text 쌍에 대해서 \{v_i, l_m\} pseudo label이 만들어집니다. 이후 이 pseudo label을 가지고 사전학습이 진행됩니다.
Our Pretraining scheme
사전 학습은 새롭게 만든 region-text 쌍과 기존의 데이터인 image-text 둘다에 대해 학습이 진행됩니다. region-text 쌍에 대해 contrastive loss와 distillation loss가 정의되고 이에 대해 학습이 됩니다. contrastive loss는 다음과 같이 정의되는데요. 알맞은 쌍이 잘 매칭되도록 학습시키는 방법입니다.
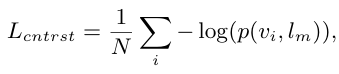
여기서 p(., .)는 또 아래와 같이 정의됩니다. 다음은 region v_i가 알맞은 semantic embedding l_m과 매칭될 확률을 나타냅니다. 위의 식을 다시 살펴 보면 p()의 값을 최대화하는 방향으로 (contrastive loss를 줄이는 방향으로) 학습합니다.
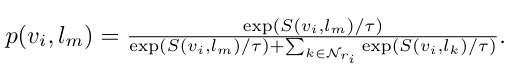
distillation loss는 다음과 같이 정의됩니다. teacher encoder로 부터 도출되는 분포와 본 연구에서 제안하는 visual encoder의 KL divergence를 구해 둘의 분포가 비슷하도록 하는 역할을 합니다.
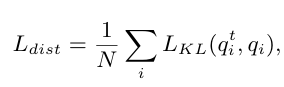
$L_{K L}$은 KL divergence loss를 의미합니다. q는 각 encoder에서 도출되는 모든 concept semantic embedding에 대한 softmax값이 됩니다. 예를 들자면 concept pool이 다음과 같이 구성될 때 [“cat”, “dog”, “laptop”, “boy”, “bus”, …] q는 [0.01,0.05,0.02,0.85,0.03,…]이 될 수 있겠지요. teacher encoder에서의 예측과 같도록 학습하는 것 뿐만 아니라 모든 concepts에 대해 예측하는 정도 즉 분포를 따르도록 학습시킨다고 보면됩니다.
pretraining model 학습에 사용되는 최종적인 loss는 다음과 같습니다. L_{cntrst-img} loss는 기존의 image-text 쌍에 대한 contrastive loss입니다.
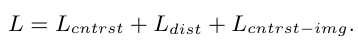
Transfer Learning for Object Detection
다음은 RegionCLIP으로 사전학습한 모델을 Object detection에 활용하는지에 대한 내용입니다. RegionCLIP을 object detector의 backbone으로 사용합니다. RPN으로 이미지의 region을 뽑은 후 각 region의 feature를 RegionCLIP에 통과키고 텍스트 임베딩과 매칭해서 해당 영역에서 객체를 classify 하도록 합니다.
4. Experiments
다음은 본 논문에서 제안한 RegionCLIP의 object detection에 대한 성능을 확인한 실험 결과입니다.
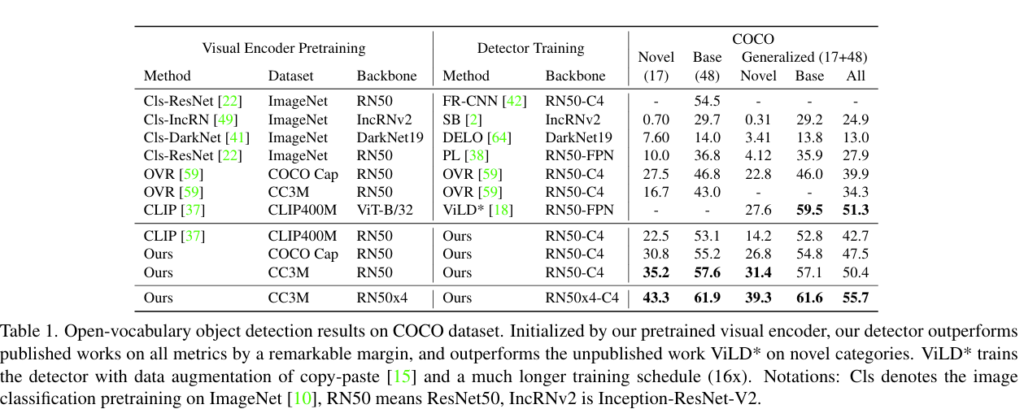
COCO 데이터셋에 대해서 OVOD에 대해 실험한 결과이고요 기존의 SOTA인 OVR의 방법론 보다 더 나은 결과를 보입니다.
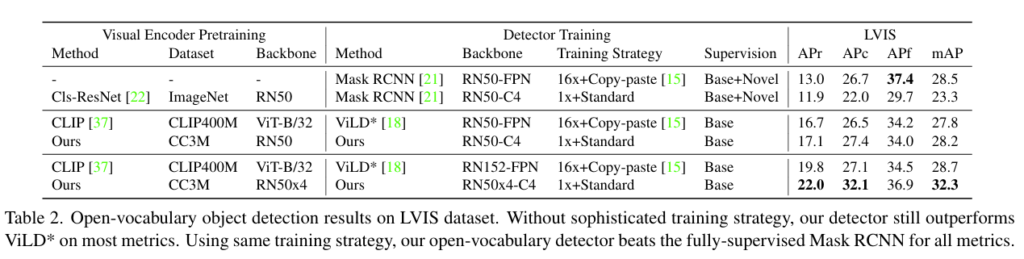
다음은 LVIS 데이터셋에 대해 OVOD를 수행한 것에 대한 실험 결과입니다. 대부분의 지표에서 기존의 SOTA였던 ViLD의 성능을 outperform하는 것을 확인할 수 있습니다. 위 두 실험 결과를 통해 논문에서 제안하는 사전학습 method가 이미지에서 region-level의 representation 학습을 가능케 했고 결과적으로 OVOD에 대해 성능 향상에 영향을 주었음을 확인할 수 있는 실험이라고 볼 수 있겠습니다.
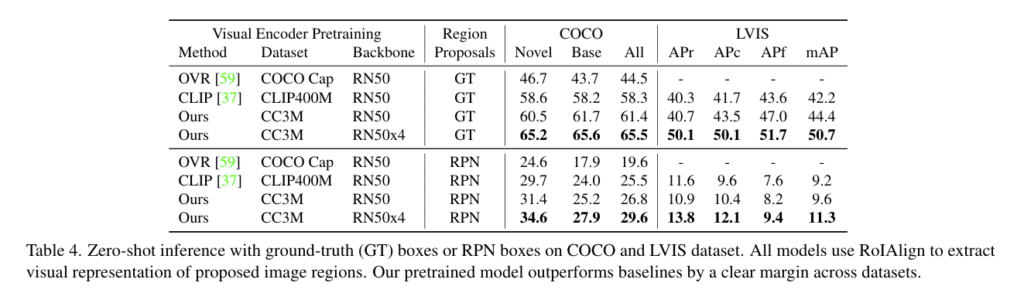
다음은 두 데이터셋에 대해서 Zero-shot inference에 대한 실험 결과입니다. CLIP 기반의 베이스라인의 성능을 능가하는 결과를 보임을 알 수 있습니다. 실험 결과, region-text alignment를 진행하는 Ours의 방법론이 이미지 region에 대한 인식 성능을 향상시킨다는 것을 확인할 수 있는 실험이었습니다.
5. Conclusion
image-level에서의 image-text representation을 학습하는 사전학습 모델 CLIP으로는 region-level의 representation을 이해하고 사용하는 게 중요한 Object dection에서는 아쉬운 결과를 보였는데요. Object Detection에 대해서도 이미지 분류만큼의 성능을 내도록 하기 위해 image region과 이에 대한 text를 align해 학습하는 모델인 RegionCLIP을 제안한 연구였습니다. 그리고 본 연구에서 image의 각 객체가 포함된 region에 대한 캡션을 사람이 직접 달지 않고도 생성할 수 있는 방법을 제안한 것도 하나의 contribution이였습니다. 본 연구에서 제안한 방법으로 OVOD와 Zero-shot Inference에 대해서도 기존 SOTA 모델을 능가하는 성능을 보였습니다.
안녕하세요 지연님 리뷰 감사합니다.
CLIP은 이미지 단위로 학습이 된건데, 그걸 RPN을 통해서 Region에 대한 representation을 하는건가요? 이걸 가능하게 하는 Loss 들에 대해서 조금 더 자세히 설명해주실 수 있으실까요? Distillation Loss가 분포를 같게 한다고 하는데, Contrastive Loss 외에도 Distillation Loss가 필요한 이유가 무엇인지 궁금합니다!!
김영규 연구원님 답변 감사합니다.
1) 네 설명해주신 게 맞습니다. 우선 이미지 전체를 CLIP에 통과시키고 나서 얻은 feature map에 대해서 RPN으로 일부 영역의 ROI를 뽑고 각 영역의 representation을 구합니다.
2) 제 설명이 미흡했던 것 같습니다. 죄송합니다. RegionCLIP은 총 3가지의 loss를 더해 학습합니다. L-contrast는 region-text 쌍 중 positive한 쌍은 가깝도록 negative한 쌍은 멀어지도록 학습시킵니다. 기존 CLIP과 달리 local level에서의 매칭을 가능하게 합니다. L-contrast-img는 기존 CLIP 모델에서 사용한 loss로 image-text 즉 image 전체와 텍스트간의 매칭을 학습시킵니다. L-Distillation은 teacher encoder가 region에 대한 예측한 분포를 student encoder가 따르도록 하기 위해 사용하는 loss입니다.
3) Contrastive loss 말고도 Distillation loss가 필요한 이유는 Contrastive loss로는 하나의 positive한 text caption에 대해서만 집중하고 이를 맞추는 데에만 집중돼 있는데요 다른 비슷한 의미를 가지는 텍스트를 모두 고려할 수 있도록 하기 위해서 teacher encoder의 예측 분포를 따르도록 하는 distillation loss를 사용하는 것입니다!
답변이 늦어 죄송합니다. 감사합니다.
류지연 연구원님, 좋은 리뷰 감사합니다.
CLIP 및 RPN 을 기반으로 OVOD를 수행할 수 있게 만든 방법론이네요. 리뷰 읽다 궁금한 점들이 있어 간단한 질문 남기겠습니다.
1. Figure 2의 아래에 보면 region description을 생성하고 이를 RPN region 영역과 유사도를 측정해서 contrastive learning을 위한 image-text pair를 만들게 되는데요, 기존의 CLIP이 한 장의 이미지 전체로 학습을 하다 보니 RPN으로 자른 각각 객체에 정확히 region description을 매핑할 수 있을지 의문이 듭니다. region과 description 간 매핑 과정에서 어느 정도 노이즈가 들어갈 수 있을 것 같은데 관련해서 논문에서 어떻게 서술되어있나요?
2. distillation loss에서 teacher 와 student가 각각 정확히 어떤 인코더인지, distillation loss를 추가한 목적이 무엇인지 헷갈려서 이에 대해 알려주시면 감사하겠습니다.
3. experiment에 OVOD 및 zero-shot 성능밖에 없나요? CLIP의 localization 능력에 대한 문제 제기를 한 논문이기에 RegionCLIP의 localization 성능을 보이기 위해 추가적인 시각화나 ablation study 같은 건 없는지 알고 싶습니다.
감사합니다.
질문 감사합니다.
1. 네 논문에서도 해당 내용이 서술돼 있는데요 region-text 가 noisy 하다고 서술하면서 그럼에도 regional한 representation을 학습하는 데 유용하다고 합니다. 데이터셋이 많아 일부 쌍이 올바르지 않더라도 평균적으로는 모델이 positve한 쌍은 가까워지도록 negative 한 쌍은 멀어지도록 학습이 된다고 합니다. 또한 positive 한 쌍보다 negative 쌍의 개수가 훨씬 많은데요 그래서 일부 positve 쌍으로 예측한 것이 false positive 이어도 다른 true negative로 올바르게 학습이 되기 때문에 크게 문제가 되지는 않는다고 합니다.
2. 네 distillation loss에 대해서 논문에서 ablation study로도 그 필요성을 강조하였는데요. 보통 contrastive loss로만 학습하는 경우에는 positive 한 쌍 만을 정답으로 학습하는 반면 distillation loss는 정답은 아니지만 정답인 것과 비슷한 의미를 갖는 후보들에해서도 모두 고려가 되면서 학습이 되기 때문에 유사도에 대한 정보가 풍부하게 학습된다는 장점이 있습니다.
3. 네 질문 주신대로 논문에서 localization 성능을 확인하기 위한 시각화 자료와 ablation study가 함께 작성되었습니다. figure 3, 4 는 다른 데이터셋에 대해 CLIP과 RegionCLIP zero-shot inference 결과를 시각화한 자료입니다. RegionCLIP 이 비교적 region 에 대한 예측을 정확하게 함을 확인할 수 있는 자료입니다. 다음은 논문에서 진행된 ablation study들을 일부 요약한 것입니다.
– region-text 말고도 image-text 쌍에 대해서 L-contrast-img 으로 학습이 되는데요 image-text 쌍을 함께 학습했을 때의 성능 개선 여부를 확인하는 실험입니다. 실험한 결과, 두 pair를 동시에 사용했을 때의 성능이 좋았습니다.
– 이미지에서 region을 제안하는 방법이 inference 성능에 영향을 미치지는 지를 확인한 실험입니다. random box 보다 RegionCLIP이 따르는 방법인 RPN을 사용했을 때의 성능이 더 좋았습니다.
– 앞서 두번째 답변때 언급했던 distillation loss에 대한 ablation study도 있습니다. 결론을 얘기드리자면, 두가지 loss를 같이 사용하는 게 성능이 좋았습니다. 저자는 두 loss 마다 맡는 역할이 다르다고 둘 다 모두 필요하다고 서술합니다.
감사합니다. 덕분에 확실하게 이해하고 넘어갑니다!
안녕하세요 류지연 연구원님, 좋은 리뷰 잘 읽었습니다.
저도 얼마 전에 RegionCLIP 논문을 읽었었는데, 지연님 리뷰를 통해 제가 놓쳤던 부분들을 다시 점검할 수 있는 좋은 기회가 되었습니다. 감사합니다.
논문을 읽으면서 개인적으로 궁금했던 부분이 하나 있었는데, 혹시 지연님께서도 비슷한 의문을 가지지 않으셨을까 하는 생각에 댓글을 남깁니다.
저는 해당 논문을 읽을 때 Teacher의 output 확률 분포를 Student가 그대로 distillation하는 부분에서 의문이 생겼습니다.
Teacher로 쓰는 CLIP은 전체 이미지를 학습한 encoder인데, Student는 부분 영역(region) 을 input으로 받는 encoder로 알고있습니다. Input의 수준(전체 혹은 부분) 자체가 다른데, 이렇게 단순히 distribution matching(KL divergence)만 해도 괜찮은 건지, 예를 들어 teacher가 global context를 본다면, student는 local context만 보는데, 둘을 똑같은 분포로 강제하는 게 과연 옳은 접근인지 궁금했습니다. 혹시 지연님께서는 이 부분에 대해 어떻게 이해하고 계신지 설명해주시면 감사하겠습니다. 감사합니다.
안녕하세요 우현 연구원님
좋은 의문점을 던져주셔서 감사합니다.
저는 RegionCLIP에 대한 이해 정도가 부족해서 우현님이 제기하신 의문을 궁금해하는 단계까지 가지는 못했었는데요 덕분에 한번즈음은 꼭 짚고 넘어가야 했던 부분을 저도 생각해볼 수 있지 않았나 싶습니다.
질문에 대해 답을 드리자면, teacher encoder인 CLIP을 사전학습하는 과정에서 ROI가 추출돼서 각 영역과 description을 매칭하도록 contrastive loss를 가지고 학습이 진행됩니다. 물론 student encoder와 다르게 전체 이미지를 input으로 받아 global한 feature들을 바탕으로 예측이 되고 학습이 되겠지만.. description과의 매칭은 student에서 처럼 객체 영역에 대해서 이뤄진다고 합니다. 그렇기 때문에 distillation loss로 student가 teacher encoder의 예측 분포를 따르도록 학습하는 게 완전히 잘못된 접근 방법은 아니라는 얘기인 것 같습니다.
하지만 student encoder는 context한 정보 없이 region에 대한 매칭을 진행해야한다는 점에서 이는 여전히 한계로 남을 것 같습니다.
감사합니다.