안녕하세요, 61번째 x-review 입니다. 이번 논문은 ICRA 2025에 게재된 TransDiff라는 논문으로, Diffusion을 활용하여 투명한 물체에 대한 Depth Completion을 수행한 논문 입니다.
그럼 바로 리뷰 시작하겠습니다 !

1. Introduction
유리나 플라스틱과 같이 투명한 물체는 일상 생활에서 흔하게 찾아볼 수 있습니다. 사람은 이렇게 투명한 물체더라도 물체에 대한 식별이 가능하지만 로봇에게는 이러한 물체가 굉장히 challenge하게 여겨집니다. 라이다나 RGBD 센서는 일반적으로 depth를 측정해서 데이터를 만드는데, 이러한 센서들이 투명한 물체에 대한 depth를 잘 측정하지 못하고 노이즈를 발생시킵니다. 그래서 로봇이 투명한 물체에 대한 작업이 어렵게 되죠.
그래서 최근 연구에서는 투명하고 거울과 같이 specular한 물체를 처리하기 위해서, 투명한 물체를 재구성할 때 사용하는 이미지 수에 따라 멀티뷰/싱글뷰로 나누어 진행하고 있습니다. 가령, GraspNeRF와 같은 방식은 NeRF 기반으로 단계별로 depth를 계속 refine하게 됩니다. 그러나 이러한 NeRF 기반의, 멀티뷰의 방법론들은 기본적으로 계산 비용이 많이 들고 많은 이미지가 필요하게 됩니다. 또한 벽에 배치되어 있는 물체같이 일반적이지 않은 시나리오에서는 실패하는 경우가 생기죠.
반대로 단일뷰 방식은 단일 이미지로 surface normal이나 투명한 표면의 마스크를 예측해서 글로벌 최적화 알고리즘을 통해 투명한 물체의 3D 표면을 재구성하고 있습니다. 그러나 단일뷰 방식은 일반적으로 초기에 추정한 깊이 정보나 다른 기하학적인 정보에 대한 의존성이 높아서 여러 다양한 시나리오를 처리하기에 한계가 있다고 합니다.
이러한 문제를 해결하기 위해, 본 논문에서는 diffusion 모델을 사용하고자 합니다. 랜덤 depth 분포로부터 depth map을 생성하는 반복적인 denoising 과정을 수행하는 것이죠. 이러한 반복적인 과정을 통해 다양한 스텝에서 한 이미지에 대한 caorse&fine 디테일을 모두 찾을 수 있도록 합니다. 이런 diffusion 기반의 싱글뷰 RGB-D를 입력으로 써서 본 논문은 투명한 물체를 다루기 위한 모델로 TransDiff를 제안하고 있습니다. TransDiff는 denoising 단계를 거쳐서 시각 조건을 이용해 반복하여 refinement를 수행합니다. 여기서 말하는 시각 조건이란 RGB 이미지와 depth map의 feature map 레벨에서 융합하여 만들어진다고 하네요.
여기서 본 논문의 main contribution을 정리하면 다음과 같습니다.
- 반복적인 diffusion의 denoising 과정을 사용하여 투명한 물체에 대해 RGB-D 이미지로 depth completion 수행하는 TransDiff 프레임워크 설계
- featue fusion과 어텐션 기반의 네트워크를 통해 RGB 이미지와 Depth map의 feature를 효과적으로 활용
- 벤치마크 데이터셋인 ClearGrasp와 TransCG에서 효율적인 추론 비용을 가지고 SOTA 달성
2. Method
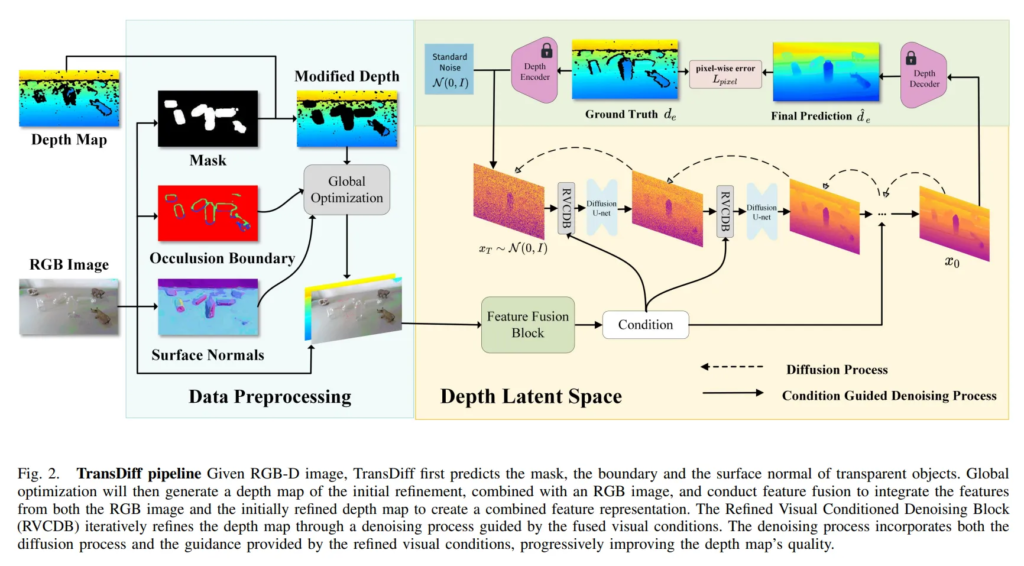
2.1. Problem Statement and Method Overview
모델의 전체적인 프레임워크에 대해 먼저 살펴보도록 하겠습니다.
먼저 투명한 물체가 포함돼있는 단일 RGB-D 이미지가 주어지면, RGB 이미지에는 semantic segmentation으로 물체 마스크를 예측합니다. 이 예측한 마스크를 depth map과 비교하여 depth map에서 투명한 물체로 인해 누락된 물체에 대한 영역을 확실하게 찾습니다. 그 다음에 RGB 이미지에서 엣지 맵과 surface normal을 각각 얻습니다. 그럼 세 개의 결과가 나올텐데, 이때 Fig.2에서 Modified depth와 RGB 이미지를 융합해서 새로운 feature 표현을 생성합니다. 그 다음에 Refined Visual Conditioned Denoising Block(RVCDB)을 통해 앞서 fusion한 feature를 시각 조건으로 활용해서 denoising 과정을 거치고 최종적으로 디코더를 통해 latent space에서 이미지 공간으로 변환하여 depth map을 얻을 수가 있습니다. 이렇게 얻은 depth map을 사용해서 포인트 클라우드로 변환한 다음에, GraspNet과 같은 grpsping pose를 예측하게 됩니다.
2.2. Generative Formulation
간단하게 투명한 물체의 depth를 예측하기 위해 denoising diffusion 과정을 어떻게 다시 정의했는지 살펴보겠습니다. 단순하게 RGBD 이미지에서 depth map을 p(x|d)로 예측하는게 아니라, 랜덤한 분포에서 점점 실제 depth map으로 변환하는 과정으로 설계하였습니다.
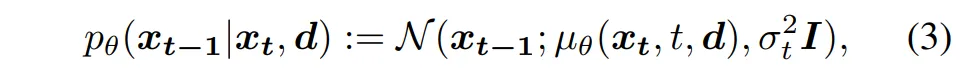
- d : RGB-D 이미지
- x : 최종 예측 목표인 투명한 물체의 depth map
- x_t : 현재 time step의 latent depth
식(3)에서 \mu_{\theta}는 현재 x_t와 time step t, 그리고 조건 d를 입력으로 받아서 x_{t-1}을 예측합니다. 즉 d를 추가로 사용해서, 조건부 확률 분포로 구성되어 매번 이전 단계의 depth 값을 예측하는 것 입니다.
2.3. Network Architecture
이제 Fig.2를 따라 TransDiff를 세 파트로 나누어 살펴보도록 하겠습니다.
첫번째는 데이터 처리 과정 입니다.
데이터 처리는 입력 RGB-D 이미지로부터 초기 개선된 depth map, Fig.2에서 Modified depth map이라고 표현된 depth map을 생성하는 과정을 의미합니다. 여기서 사용하는 정보는 surface normal, Occlusion Boundary, 그리고 마스크 입니다.
surface normal은 투명 물체가 빛의 굴절이나 반사가 이해하기 복잡한 구조를 띄기 때문에 표면의 방향 정보를 알기 위해 사용합니다. 그리고 occlusion boundary는 물체가 겹쳐져 있을 때 하나의 물체가 다른 물체를 가릴 때 경계가 발생하는 것을 나타내는 정보로, 깊이 정보가 불연속적으로 나타나는 영역에 대해 급격하게 달라지는 부분을 명확하게 구분하기 위해 활용한다고 합니다. 마지막으로 RGB 이미지에서 얻은 마스크는 depth map이 투명 물체에서는 정확하게 예측이 안되기 때문에 신뢰할 수 없는 depth 데이터를 필터링하기 위해 사용합니다. 그리고 추가적으로 사용하는 정보가 있는데, refractive flow라는 걸 사용합니다. 투명한 물체를 봤을 때 뒷배경이 투명 물체를 넘어 보이긴 하지만 왜곡되어 보이죠. 이 왜곡이 빛이 물체를 통과할 때 굴절되어 생기는데, refractive flow는 이 굴절로 인한 왜곡을 이미지 상에서의 흐름으로 표현한 것을 의미합니다. 이미지의 픽셀이 실제 위치에서 어디로 이동해서 보이는지를 나타내는 일종의 벡터 입니다. optical flow와 비슷하지만, 여기서는 움직이라기보단 굴절에 의한 시각적인 왜곡을 표현하는 것이죠. 즉 RGB 이미지만을 보고도, 표면이 얼마나 왜곡되어 표현돼있는지를 유추할 수가 있습니다.
그럼 총 4개의 정보를 모아서 global 최적화를 통해 개선된 초기 depth map을 만들 수 있습니다. 왜 글로벌이라고 하냐면, 하나의 픽셀에 대해 4개의 정보에서의 관계를 한꺼번에 고려하여 가장 자연스러운 depth map의 형태를 만들기 때문입니다.
두번째는 RVCDB 모듈인데요, 이는 latent depth를 여러번에 거쳐서 denoising 하는 과정을 의미합니다. 전체적인 흐름은 현재 time step의 latent space인 x_t와 시각 조건 c가 있을 때, 두 정보를 신경망 \mu_{\theta}(x_t, t, c)에 넣어서 다음 단계의 latent depth x_{t-1}을 예측합니다. 그리고 이 과정을 반복해서 최종 depth x_0을 예측하는 것이죠.
시각 조건 계속 나오는데, 이 시각 조건 c는 앞서 말씀드린 것처럼 RGB 이미지와 개선된 depth의 feature를 추출해서 멀티스케일로 fusion한 결과를 의미합니다. 멀티스케일 fusion이라 하면 많은 분들이 아시겠지만, 의도는 글로벌한 정보와 로컬 정보를 모두 포함할 수 있도록 하기 위함입니다. fusion해서 만들어진 시각 조건은 현재 latent depth 표현 x_t와 크기를 맞춰야하기 때문에 local projection layer를 통해 해상도를 변경하는데 이때 feature들 사이의 로컬한 관계를 최대한 잘 보존할 수 있도록 설계하였습니다.
이렇게 사이즈를 맞추고 나면 추가적으로 시각 조건이 self attention을 통과할 수 있도록 합니다. self attention은 투명한 물체 영역에 대해서 depth 추정이 어렵기 때문에 이미지의 각 영역이 다른 영역 픽셀들과 어떤 관계가 있는지를 잘 학습해야 되기 때문입니다. self attention을 통과함으로써 의미 있는 영역, 즉 유리잔이라고 하면 유리잔의 경계와의 관계 등에 더 많은 가중치를 주면서 학습할 수 있는 것 입니다.
self attention까지 통과하고 나면 ResNet 스타일의 BottleNet CNN 구조와 channel-wise attention을 통과해서 중요한 채널을 한 번 더 강조하는 식으로 처리하게 됩니다. 처리한 결과를 denoising을 거쳐 x_{t-1}을 계산하고, 이 과정을 반복하여 최종 결과를 얻는 방식으로 진행됩니다.
세번째는 간단하게 인코더/디코더 구조 입니다.
여느 diffusion 기반 depth 추정 연구들과 동일하게 해당 방법론에서도 VAE 기반의 depth 인코더/디코더 구조로 이루어져 있습니다.
이미지가 입력으로 들어가면 이미지를 latent 공간으로 x_0 \in \mathbb{R}^{H/2 \times W/2 \times d} 형태로 변환합니다. depth map은 동일한데, VAE가 보통 3채널의 입력을 받기 때문에 단일 채널인 depth map을 3채널로 복제하여 RGB처럼 만든 후에 인코더의 입력으로 사용하면 됩니다. 디코더에서는 [0,1] 범위로 정규화하여 depth 값을 생성하는데, 3채널로 복원되기 때문에 본래 depth map에 맞추어 3채널의 평균값을 계산한 최종 depth 값을 출력합니다.
인코더와 디코더는 식(4)와 같이 pixel-wise depth loss를 통해 학습됩니다.
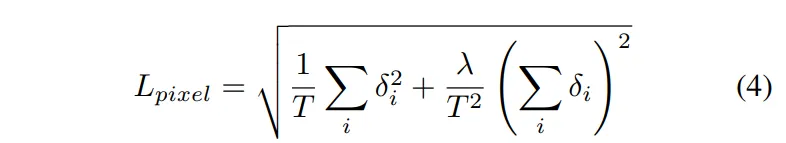
- \delta_i : \hat{d}_e - d_e로, 예측 depth와 GT 사이의 차이
여기에 추가적으로 인코더 타고 나온 latent 표현과 GT latent 간의 L2 loss를 포함한 전체 loss 함수는 식(5)와 같습니다.
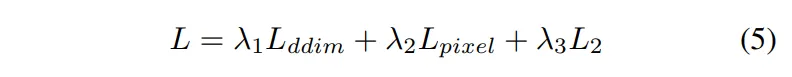
3. Experiments
3.1. Depth Completion Experiments
메인 실험은 ClearGrasp와 TransCG 데이터셋에서 타 방법론과의 비교 실험을 진행하였습니다.
비교 알고리즘은 크게 3가지 입니다.
ClearGrasp라고 해서 합성 학습 데이터를 이용해서 투명한 물체에 대한 depth를 추정한 최초의 알고리즘과 비교하였습니다. 또한 TranspareNet은 투명한 물체의 위치와 depth 정보를 활용해서 투명한 물체의 전체 depth를 추정할 수 있는 알고리즘 입니다. ImplicitDepth는 이전의 depth completion 방법론에서 SOTA 방법론 입니다.
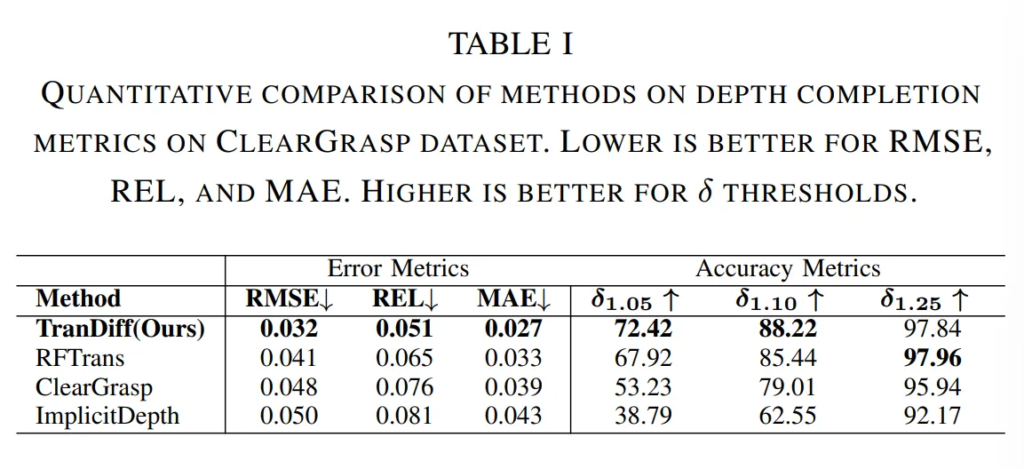
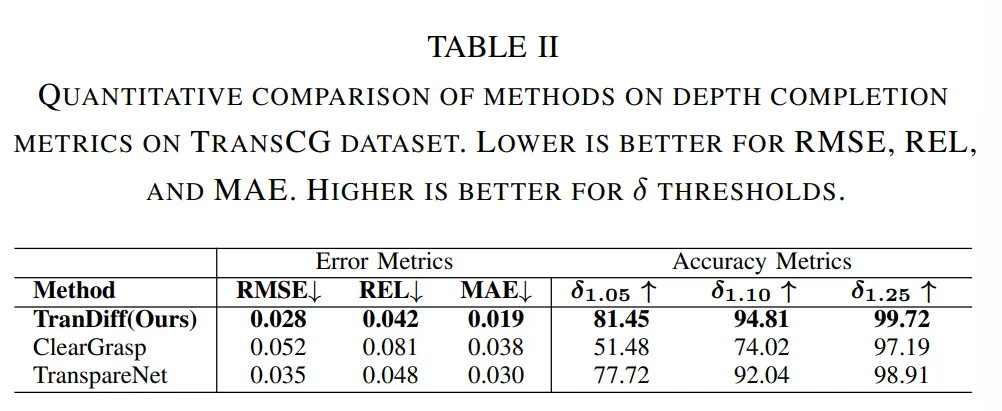
Tab.1과 Tab.2에서 각각 ClearGrasp와 TransCG 데이터셋에 대해 평가하였습니다.
간단하게 분석한 것 같은데요, Tab.1을 보면 TransDiff가 가장 낮은 에러를 달성한 것을 확인할 수 있습니다. Tab.2 역시 TransCG 데이터셋에서 SOTA를 달성하며 diffusion을 활용한 해당 방법론이 투명한 물체에 대한 완전한 depth를 예측하는데 높은 성능을 달성할 수 있음을 보여주었습니다.
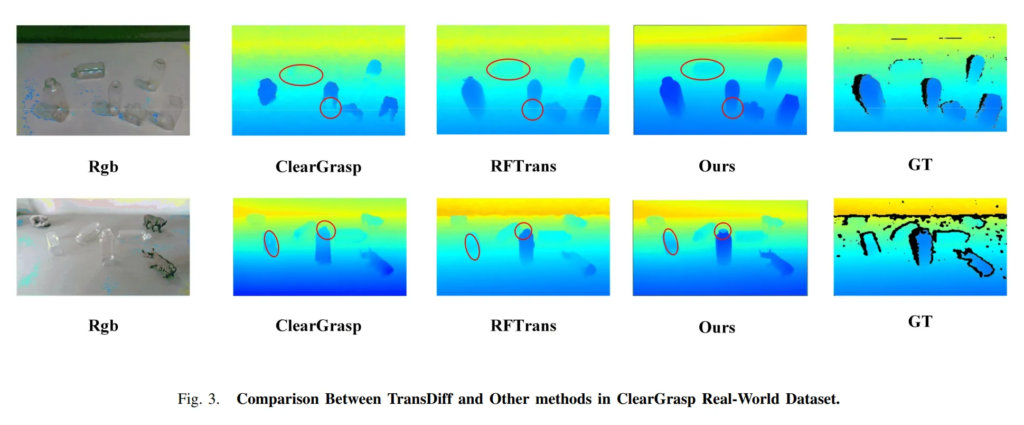
Fig.3은 정성적으로 결과를 보여주는 것으로, 투명한 물체에 대해서 GT depth map을 보면(여기서 sparse depth라고 표현하네요) 일반적인 물체의 depth 표현에 비해 경계가 흐릿하고 명확하게 표현이 되지 않은 것을 알 수 있죠. 빨간색 동그라미로 강조된 부분을 봤을 때, 엣지 부분에 대해 가장 정확하게 구분이 되고 뒤쪽에 위치한 투명한 물체에 대해서도 가장 두드러지게 depth를 표현하고 있는 것을 확인할 수 있습니다.
3.2. Ablation Study
Ablation Study on conditioned denoising block
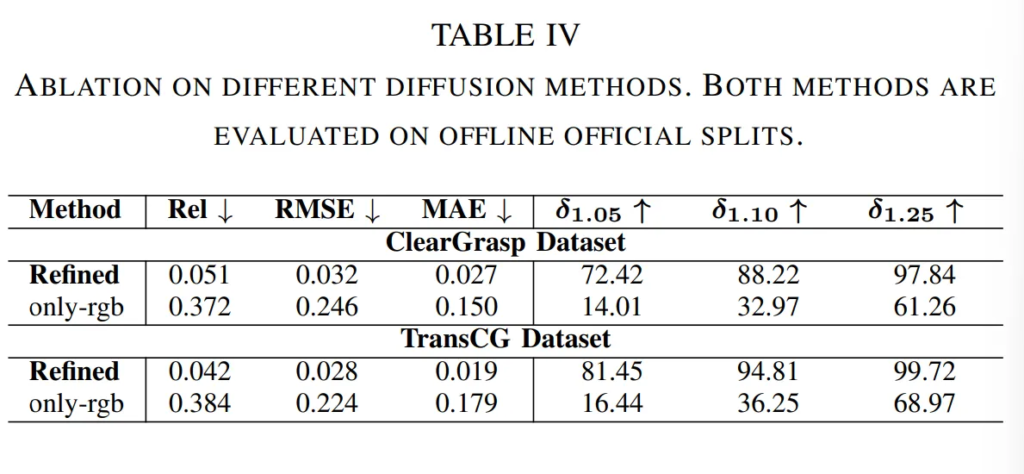
Tab.4는 논문의 main contribution이라고 할 수 있는 RVCDB 모듈에 대한 ablation study 입니다. 최종 TransDiff 모델은 엣지 맵, normal surface, 그리고 마스크를 이용해서 개선된 depth map을 만드는데요, 해당 실험에서는 RGB 이미지에서 추출한 feature만을 사용해서 depth map을 개선하는 식으로 비교를 하였습니다.
최종 모델 성능과 같이 리포팅 돼있어야 비교가 편할 듯 싶지만 .. 실험 테이블은 RGB만을 사용한 버전으로만 구성되어 있습니다. 결과적으로 얘기하면 앞서 얘기한 다른 정보들을 같이 global 최적화를 하였을 때 더 좋은 성능을 보엿다고 합니다. surface normal과 같은 다른 기하학적인 정보들이 RGB만을 사용하는 것보다 투명한 물체의 depth를 추정하는데 중요한 역할을 하기 때문에 그러한 정보들을 시각 조건을 만드는데 사용하는 것이 효과적이었다는 것을 실험을 통해 보였다고 합니다.
Simulation Grasping Experiments
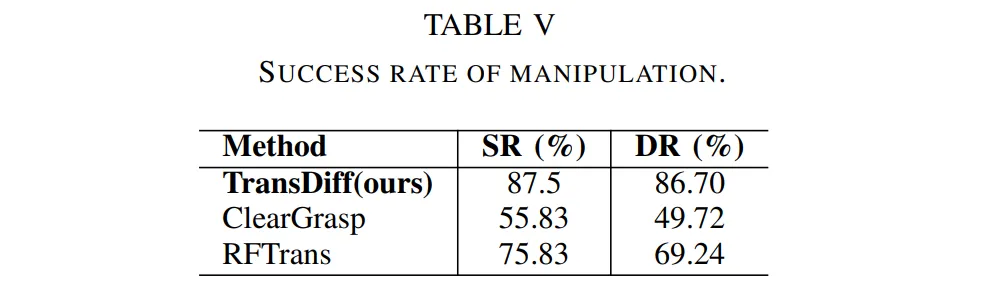
마지막으로 ablation study라기보다는 앞서 인트로에서 실제 manipulation 관점에서 grasping에 대해서도 진행하였다고 했기 때문에 이에 대해 실험을 진행한 결과를 보여주고 있습니다. grapsing task를 시뮬레이션 하기 위해 Pybullet에서 TransDiff를 학습하고 평가하였다고 하네요.
두 가지 평가 메트릭을 사용했는데, 우선 SR은 전체 grasping 시도 횟수에서 성공한 횟수에 대한 비율을 의미합니다. 두번째는 DR(declutter rate)로, 전체 scene의 모든 물체 중에서 로봇이 성공적으로 제거한, 즉 로봇이 집어서 치운 물체의 비율을 나타냅니다. 실제 장애물이나 겹쳐진 물체가 많은 환경에서 로봇이 복잡하게 배치된 물체 중 얼마나 효율적으로 전체 작업 공간을 비울 수 있는지를 알 수 있는 지표라고 합니다.
grapsing을 위해 8개의 유리로 된 물체를 배치하여 평가를 위해 120개의 scene을 사용하였다고 합니다. 각 scene에서는 대략 1-5개 사이의 투명한 물체를 무작위로 배치하여 평가하였고, 로봇은 각 시도마다 GraspNet으로 예측한 pose를 통해 물체를 집을 수 있어야 합니다. 여기 GraspNet에서 사용하는 depth를 바로 TransDiff로 보완한 depth를 사용하는 것이죠.
결과는 Tab.5에 나와있는 것처럼 이전 방법론들에 비해 매우 높은 성공률과 DR를 달성한 것을 확인할 수 있습니다. 이를 통해 단순히 투명한 물체에 대해 depth를 잘 보완하는 것에서 끝나는게 아니라 실제 로봇 grasping task로 확장해서 사용하여도 로봇 작업에 실질적인 도움이 된 다는 것을 증명하고 있습니다.
안녕하세요, 좋은 리뷰 감사합니다.
단순히 depth completion에서 끝나는게 아니라 실제 completion한 depth로 robot grapsing까지 진행한 것으로 이해하였습니다. 그런데 로봇 grasping에 대해서는 실험 결과만 리포팅 되어 있는데 제가 로봇 grasping에 익숙하지 않아서 혹시 더 자세하게 방법론적으로 다루고 있는 부분은 없었을까요?
감사합니다.
안녕하세요, 리뷰 읽어주셔서 감사합니다.
말씀하신 것처럼 메소드 파트에서도 로봇 manipulation에 대해 짧게나마 적혀있긴 합니다.
우선 리뷰에 적은 것처럼 TransDiff로 depth map을 얻고 나서 해당 depth map으로 투명한 물체에 대한 grasping을 진행합니다. 다만 depth map을 포인트 클라우드로 변경하여 grasping planning 알고리즘의 입력으로 사용한다고 합니다. grasp propsal은 에너지 메트릭을 기반으로 평가되며 최적의 grasping을 위해서는 더 낮은 에너지일 수록 안정적으로 가능하다는 식의 설명이 있지만 실험 결과와 직결되는 부분은 어떤 데이터를 넣어서 grasping 알고리즘을 실행하는가인 것 같습니다.
감사합니다.
흥미로운 논문 리뷰 감사합니다.
간단한 질문 하나 남기고 갈게요.
surface normal이랑 depth랑 추정 난이도가 같은 것 같은데… 이걸 어떻게 추론하는지 정보가 없는 것 같아요.
refractive flow을 구하는 방법도 같이 설명해주시면 좋을 것 같습니다.
안녕하세요, 리뷰 읽어주셔서 감사합니다.
말씀해주신 것처럼 투명한 물체에 대해서 surface normal을 바로 계산하면 오차가 생길 수 있는데, 해당 논문에서는 RFNet이라는 이전에 존재하는 논문 방식을 활용해 surface normal을 직접 예측하지 않고 먼저 refractive flow를 먼저 예측합니다.
그 refractive flow를 기반으로 sruface normal을 재구성하는 것인데, 굴절된 정보를 먼저 찾아서 간접적으로 surface normal을 복원하는 방식이라고 합니다.
이때 RFNet에서 refractive flow는 합성 데이터셋에서 GT refractive flow를 만드는데, 굴절된 픽셀의 위치에서 실제 배경 픽셀 위치를 비교해서 flow를 얻는다고 합니다. 굴절된 픽셀이 어디로부터 온 것인지를 매핑해주는 vector를 만들어서 RFNet이라는 네트워크를 태워 학습하게 됩니다.
감사합니다.