Video-Language understanding 연구에 대해 리뷰해보겠습니다.

- Conference: CVPR 2023
- Authors: Jingjia Huang, Yinan Li, Jiashi Feng, Xinglong Wu, Xiaoshuai Sun, Rongrong Ji
- Affiliation: Key Laboratory of Multimedia Trusted Perception and Efficient Computing, ByteDance
- Title: [CVPR 2023] Clover : Towards A Unified Video-Language Alignment and Fusion Model
1. Introduction
기존 video-language understanding 연구들은 주로 텍스트-비디오 검색(Text-to-Video Retrieval, TVR)과 비디오 질문 응답(Video Question Answering, VQA) 같은 태스크에 따라 서로 다른 구조를 사용하는 방식을 사용해왔습니다. 예를 들어, TVR에서는 효율성을 위해 비디오와 텍스트를 각각 독립적으로 인코딩하는 dual encoder 구조를 주로 사용하며, VQA에서는 두 모달리티의 상호작용을 학습하기 위해 cross-modal encoder를 활용하였습니다.
Dual encoder는 retrieval 성능에 특화된 구조로, 텍스트와 비디오를 공통 임베딩 공간에 정렬하는 데 집중하여 상대적으로 가볍고 빠른 연산이 가능하다는 장점이 있습니다. 반면, cross-modal encoder는 두 모달리티의 정보를 한 번에 융합하여 보다 풍부한 표현을 생성할 수 있지만, 모든 비디오-텍스트 쌍을 조합해 비교해야 하므로 계산량이 크게 늘어납니다. 예를 들어, 비디오 N개와 텍스트 M개가 있을 때 dual encoder는 O(N+M)의 연산으로 처리 가능한 반면, cross-modal encoder는 한 쌍의 비디오-텍스트가 처리되어야 하다보니 O(N×M)의 연산이 필요합니다. 즉, 전자는 데이터 처리 효율이 높지만 표현의 정밀도는 떨어질 수 있고, 후자는 표현력은 높지만 연산 비용이 크다는 trade-off가 존재합니다.
하지만 이러한 방식은 태스크에 따라 아키텍처를 별도로 설계해야 한다는 한계를 가지고 있습니다. 이를 해결하고자 하나의 모델로 다양한 비디오-언어 태스크를 처리하려는 시도들이 이어졌지만, uni-modal encoder와 multi-modal encoder를 단순히 결합한 naive한 방식은 오히려 성능 저하를 유발한다는 문제가 있었습니다. 논문에서는 이러한 구조를 COMB라고 정의하고, 실제 실험 결과에서도 태스크별로 최적화된 개별 모델에 비해 낮은 성능을 보였습니다.
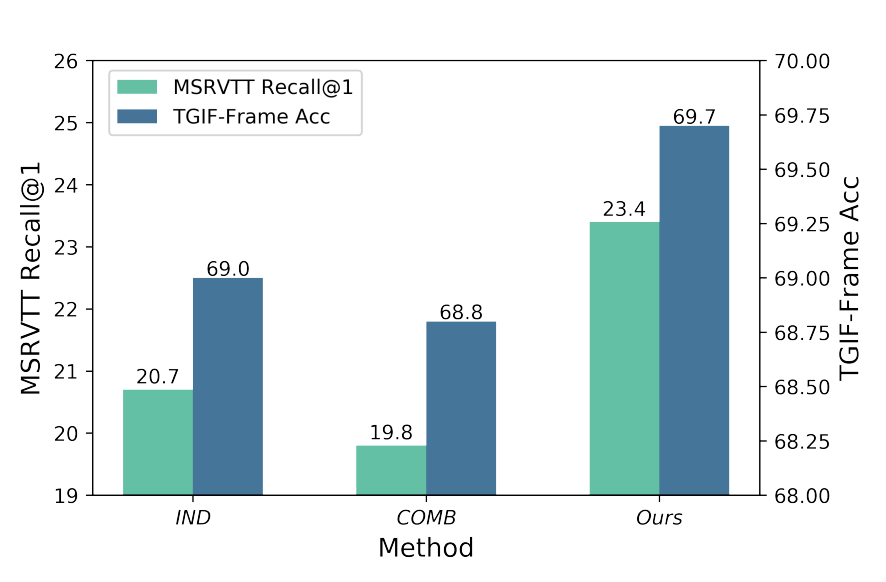
상단 그림이 바로 그 결과인데요, MSRVTT(Retrieval)와 TGIF-FrameQA(VQA)에서 다양한 구조의 Transfer 성능을 비교한 결과입니다. 단순 결합 방식인 COMB는 각각의 태스크에 맞게 설계된 IND (individually) 구조보다도 낮은 성능을 보였으며, Clover는 두 태스크 모두에서 가장 우수한 성능을 보였습니다.
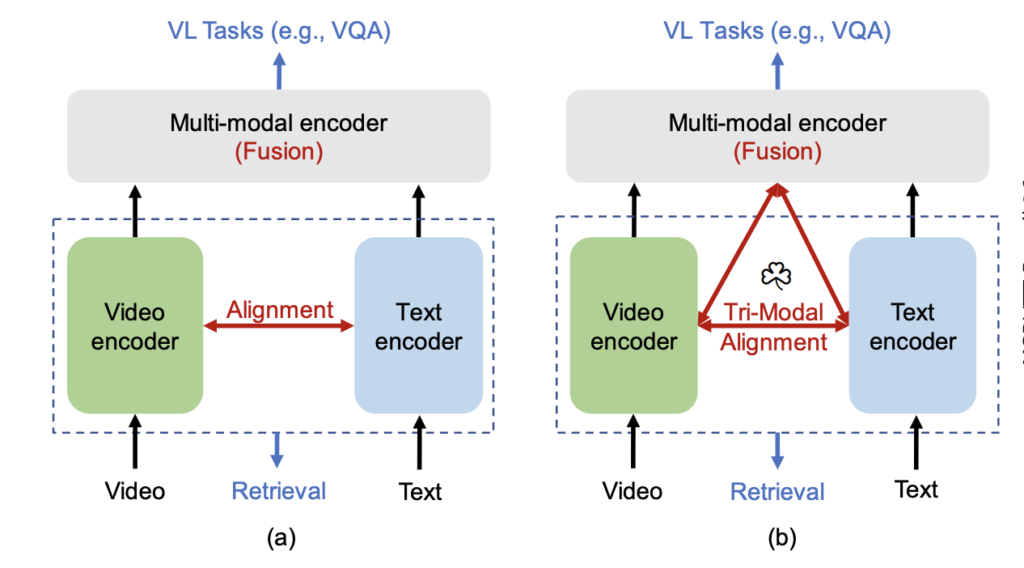
이러한 문제를 해결하기 위해, 저자들은 비디오-언어 간의 정렬(alignment)과 융합(fusion)을 동시에 고려하는 새로운 사전학습 프레임워크 Correlated Video-Language pre-training(Clover)를 제안하였습니다. Clover의 가장 핵심은 상단 그림 (b) 입니다. 기존에는 Video feature와 Text Feature를 정렬하는데에만 집중했다면, 여기서는 Multi-modal feature 까지 총 세가지 feature 사이의 alignment를 고려한다는 점이죠. 본격적인 설명을 시작하겠습니다.
2. Method
Introduction에서 말이 길었지만, 결국 이 논문은 Video-Text Understanding을 위한 Pre-training 기법을 제안한 연구입니다. 기존에는 CLIP 기반으로 비디오까지 이해시키려는 시도가 있었지만, 저자는 CLIP 학습에 필요한 데이터보다 적게, 그리고 성능을 더 좋게 비디오에 특화된 기법을 제안한 것입니다.
Clover의 main contriduction은 총 세 가지 입니다:
(1) Tri-Modal Alignment(TMA)를 통해 비디오, 텍스트, 그리고 멀티모달 표현을 서로 정렬하고,
(2) 의미 있는 요소들(명사, 동사, 형용사 등)을 선택적으로 마스킹하여 학습하는 Semantic Masking,
(3) 마스킹된 샘플과 원본 샘플 간의 의미 차이를 학습에 반영하는 Pair-wise Ranking Loss입니다.
2.1 Architecture
CLIP을 사용하지 않는다는 점이 일단 기존 연구와 가장 큰 차이점이지 않나 싶습니다.
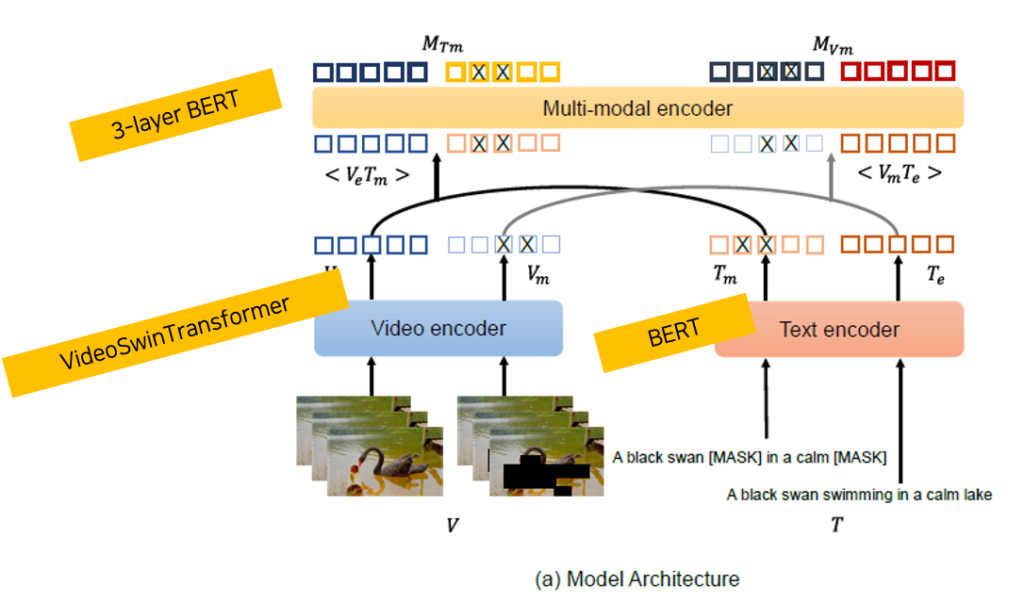
상단 그림처럼 모델 아키텍처는 크게 세 부분으로 구성됩니다. 비디오 인코더는 VideoSwin Transformer를 사용합니다. 텍스트 인코더는 12-layer BERT 기반 구조로, [CLS] 토큰을 포함한 전체 문장 임베딩을 출력합니다. 마지막으로 multi-modal encoder는 텍스트와 비디오 임베딩을 concat하여 입력으로 받아, 세 modality 간의 상호작용을 학습합니다. 이 구조를 통해 Clover는 uni-modal과 multi-modal 표현을 모두 활용할 수 있도록 설계되었습니다.
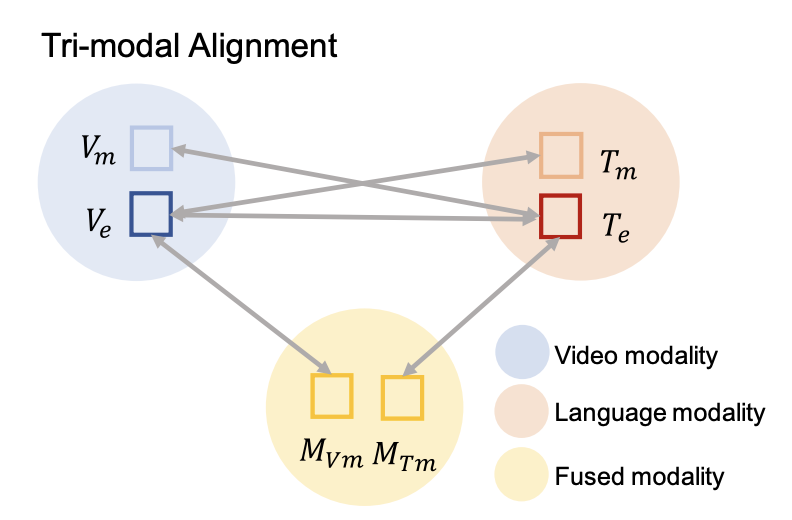
2.2. Tri-Modal Alignment
기존 비디오-언어 사전학습 기법들은 대부분 contrastive learning을 기반으로 하여, 비디오와 텍스트 간의 쌍(pair)을 정렬하는 방식으로 학습을 진행해왔습니다. 하지만 이러한 방식은 두 모달리티 사이의 직접적인 정렬에만 초점을 맞추기 때문에, 정렬이 잘 되더라도 융합된 표현력이 떨어지거나, 반대로 융합에 집중하면 정렬 성능이 나빠지는 문제가 발생할 수 있습니다.
Clover는 이를 해결하기 위해 Tri-Modal Alignment (TMA)라는 새로운 정렬 방식을 제안하였습니다. 핵심은 세 가지 모달리티 ‘비디오, 텍스트, 융합 표현(multi-modal)‘ 간의 관계를 모두 학습하도록 loss 함수를 구성하는 것입니다. 즉, 단순히 V \leftrightarrow T 정렬에 그치지 않고, V \leftrightarrow M , T \leftrightarrow M 관계까지 모두 고려하는 것이죠.
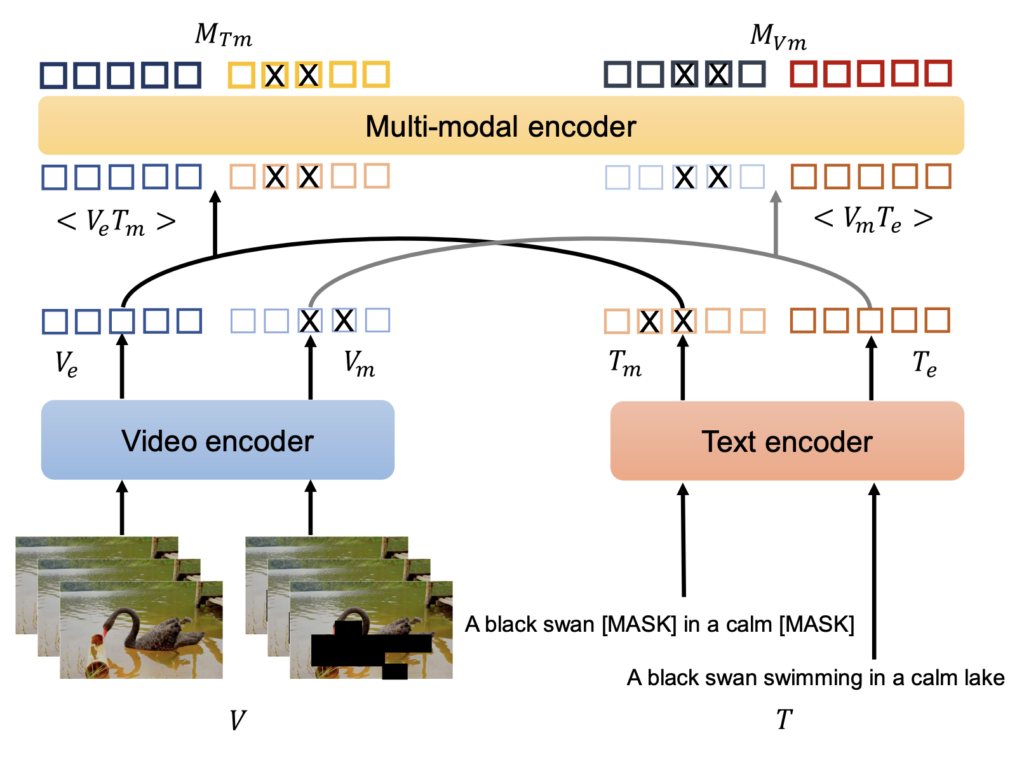
자세한 동작 과정은 상단 그림과 함께 설명드리겠습니다. Clover에서는 입력 비디오 V 와 텍스트 T 를 인코딩한 뒤, 일부 정보를 마스킹한 샘플인 V_m, T_m 도 함께 인코딩합니다. 이후 multi-modal encoder를 통해 두 종류의 masked pair \langle V_m, T \rangle , \langle V, T_m \rangle 를 융합한 임베딩을 각각 M_{V_m} , M_{T_m} 라고 합니다. 여기서 중요한 건, 이 융합된 표현이 단순히 정보를 합치는 수준을 넘어서 중간 매개체의 역할을 한다는 점입니다. 즉, 비디오와 텍스트를 직접 정렬하는 것보다, 융합 표현을 함께 정렬하는 것이 더 안정적일 수 있다는 가정에 기반하고 있다고 합니다. V_m, T_m을 만드는 건 해당 섹션이 종료되면 간단하게 서술해두겠습니다.
이 세 가지 표현들 간의 정렬을 효과적으로 수행하기 위해, 저자는 exclusive-NCE loss라는 새로운 형태의 loss인 아래 수식(2)를 제안하였으며, 이는 하나의 배치 B 내에서 계산됩니다.

여기서 분모의 Z 는 다른 negative 샘플들의 유사도를 모두 더한 값입니다. 해당 Loss는 contrastive loss에 활용되는 것과 동일한데, anchor 비디오 V^i 에 대해, 원본 텍스트 T^i , 마스킹된 텍스트 T_m^i , 그리고 융합 표현 M_{V_m}^i 모두를 positive로 보고 정렬을 계산한다는 점에서 항이 총 3개로 늘어난다는 차이가 있습니다.
다들 아시겠지만, 보통 contrastive loss는 “positive pair는 가깝게, negative pair는 멀게” 만들도록 학습합니다. 그런데 Clover에서는 비디오, 텍스트, 멀티모달 표현 세 가지를 다 정렬 대상으로 사용하다 보니, 하나의 기준(예: 비디오)을 놓고 여러 개의 ‘positive pair’이 존재할 수 있습니다. 예를 들어 아래 세 가지가 모두 비디오 V^i 의 positive pair입니다:
• 원본 텍스트: T^i
• 마스킹된 텍스트: T_m^i
• 멀티모달 융합 표현: M_{V_m}^i
그런데 이들을 한꺼번에 비교하려고 하면, 서로 간섭이 일어나서 학습이 제대로 안 될 수 있습니다. 예를 들어 T^i 를 비디오에 가깝게 하려고 하다 보면, T_m^i 와 M_{V_m}^i 는 반대로 밀려나게 되는 문제가 생길 수 있습니다.
이걸 방지하기 위해 Clover에서는 하나의 positive pair(예: V^i ↔ T^i )를 학습할 때는 나머지 positive pair(예: T_m^i , M_{V_m}^i )는 분모에서 제외해줍니다. 이렇게 하면 서로 밀어내지 않고, 각각을 독립적으로 비디오에 정렬할 수 있게 됩니다.
위에서 본 수식 (2)는 비디오 V^i 를 anchor로 두고, 해당 비디오와 연관된 텍스트 T^i , 마스킹된 텍스트 T_m^i , 융합 표현 M_{V_m}^i 를 positive로 설정한 뒤, 나머지 모든 샘플들과 비교했습니다. 그런데 multimodal 모델은 비디오만 잘 보는 것도, 텍스트만 잘 보는 것도 아닌, 양방향 정렬 능력이 중요합니다. 즉, 비디오 → 텍스트, 텍스트 → 비디오 두 방향 모두 잘 해야 합니다. 이를 위해서는 텍스트 T^i , 마스킹된 텍스트 T_m^i , 융합 표현 M_{V_m}^i를 anchor로 두고 비디오 정렬하는 정도에 대한 Loss도 필요합니다. 바로 이를 위해 수식 (3)이 사용됩니다.
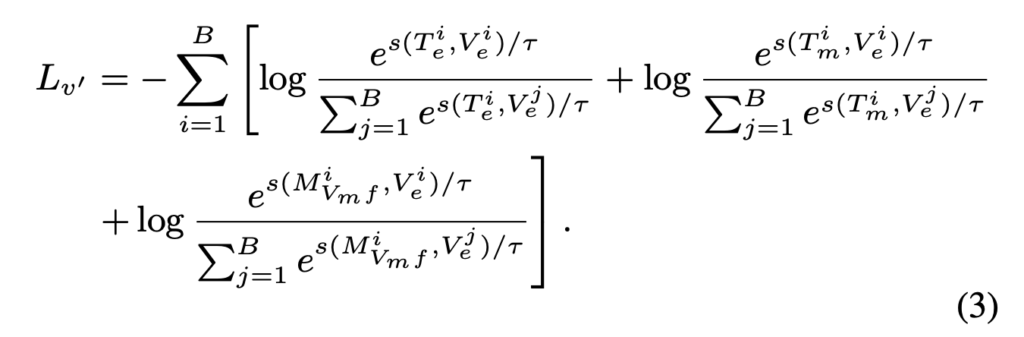
이렇게 수식(2)와 수식(3)을 더해서 최종 Visual feature를 위한 Loss가 정의되었습니다.
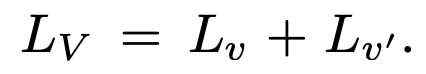
이제 CLIP처럼 Text 에 대해서도 동일하게 Loss를 구해야하는데요. 이번에는 Anchor가 T_e 가 되고, 비교 대상이 V_e, V_m, M_{T_m} 가 되면 됩니다. 헷갈리실거 같으니 상단 그림으로 정리할 수 있을 것 같네요. 이에 대한 Loss를 L_T 라고 하겠습니다.
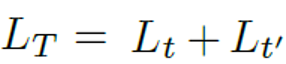
이제 CLIP 처럼 Text, visual feature를 더해서 최종 Loss를 아래와 같이 정의하였습니다.
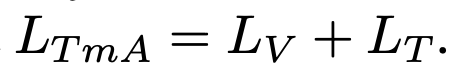
TMA 학습을 위한 비디오와 텍스트 마스킹 방법
- Video-block masking strategy
- 모든 프레임에서 동일한 위치의 패치를 block-wise로 마스킹
- 전체 패치 중 20%를 learnable mask token으로 대체
- Semantic text masking strategy
- 텍스트 의미는 주로 동사, 명사, 형용사에 담겨 있기 때문에 주요 정보인 이 부분에만 마스킹
- 문장에 품사 태깅 적용 (POS tagging)
- 동사구와 명사 중 30%를 [MASK] 토큰으로 대체
- 단, 조동사(have, should, will 등)는 마스킹하지 않음 (의미 왜곡 방지)
2.3. Training Objective
2.3.1 Pair-wise ranking
이 부분은 “마스킹된 쌍도 정답 취급해도 될까?” 라는 문제에서 출발합니다. 예를 들어, “검은 백조가 호수에서 헤엄친다.” 이 문장을 다음과 같이 마스킹 되었다고 가정해봅시다: “검은 백조가 [MASK]에서 [MASK]친다.”
이 문장은 일부 단어가 가려졌지만, 여전히 ‘검은 백조’라는 개념은 남아 있어서 비디오와 어느 정도 일치할 수 있습니다. 즉, 완전한 정답 쌍은 아니지만, 그래도 꽤 가까운 쌍이라고 볼 수 있습니다. 이를 모델에게 알려주기 위해, Clover는 이 쌍도 정렬 대상(positive pair)으로 학습합니다.
하지만 문제는, 이런 마스킹된 쌍이 원래 쌍만큼 의미가 강하진 않다는 점입니다. 그래서 Clover는 단순히 정렬하는 데 그치지 않고, “마스킹된 쌍은 원래 쌍보다 덜 비슷해야 한다” 라는 기준까지 모델이 학습하게 만듭니다.
이를 위해 사용하는 것이 바로 pair-wise ranking loss입니다. 이는 ⟨원본 비디오 V_e, 원본 텍스트T_e⟩ 쌍의 유사도가 ⟨비디오V_e, 마스킹된 텍스트T_m⟩ 혹은 ⟨마스킹된 비디오V_m, 텍스트T_e⟩보다 일정 마진(λ)만큼 더 높게 유지되도록 유도합니다. 이에 대한 수식이 다음 (4)와 같습니다:
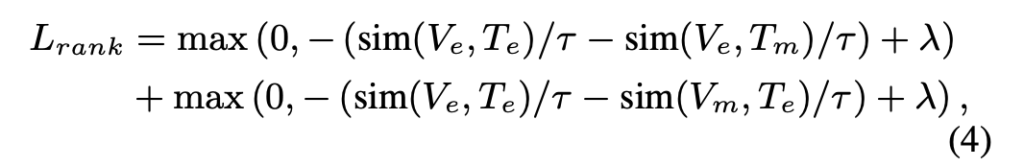
이렇게 하면 모델은 마스킹된 문장도 이해하되, 정보가 빠졌다는 걸 고려해서 약하게 정렬하게 되고, 결과적으로 훨씬 더 세밀한 의미 구분 능력을 갖추게 됩니다.
2.3.2. Semantic enhanced masked language modeling.
이 부분은 Clover가 마스킹된 단어를 어떻게 복원하며 학습하는지에 대한 내용입니다. 기존 BERT처럼, 텍스트 일부 단어(주로 명사, 동사, 형용사)를 [MASK]로 가리고, 모델이 이 자리에 어떤 단어가 들어갈지를 예측하게 합니다. 예를 들어 “고양이가 의자 위에 앉아 있다” 를 다음과 같이 마스킹을 했다고 가정해봅시다: “고양이가 [MASK] 위에 [MASK] 있다”
모델은 [MASK] 자리에 들어갈 단어가 “의자”, “앉아”일 것이라고 맞히는 학습을 합니다. 그런데 여기서 한 가지 문제는, 자주 나오는 단어(예: ‘있다’, ‘하다’)만 너무 잘 예측하게 되는 경향이 있다는 점입니다. 이걸 방지하기 위해 Clover는 focal loss를 사용합니다. 즉, 자주 맞히는 단어에는 학습 신호를 약하게, 어려운 단어(덜 확신 있는 예측)에는 학습 신호를 강하게 주는 것이 의도이죠. 이에 대한 수식은 다음 (5)와 같습니다.
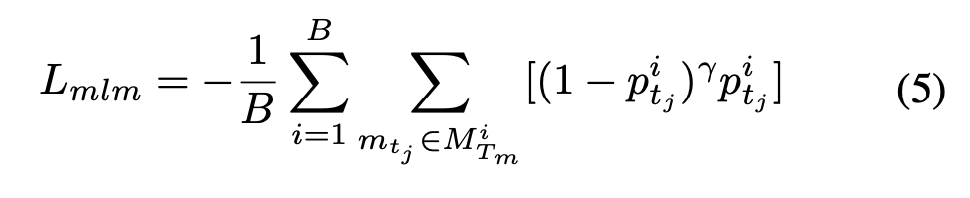
이 방식은 잘 못 맞히는 단어를 더 집중해서 학습하도록 만들고, 다양한 단어에 대한 표현력을 고르게 만들어줍니다. 결국 모델이 텍스트 내의 중요한 단어들을 복원하며 학습할 수 있게 하고, 그 과정에서 멀티모달 정보를 더 풍부하게 이해하도록 도와주는 역할을 합니다.
이렇게 저자가 제안하는 3가지 Loss를 최종적으로 더하여 모델을 업데이트 합니다.
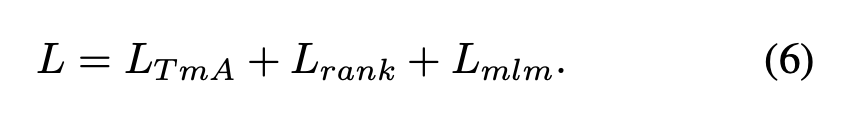
3. Experiment
3.1. Setup
Clover 사전학습에 활용한 데이터
- WebVid2M: 250만 개의 video-text pair
- CC3M (Google Conceptual Captions): 330만 개 image-text pair
- 실제로는 이미지 URL 문제로 280만 개만 사용
- 단, 이미지 데이터는 단일 프레임 비디오처럼 처리
Downstream Task: 사전학습 성능을 평가하기 위한 태스크들
- Text-to-Video Retrieval
- 평가 데이터셋: MSRVTT, LSMDC, DiDeMo
- DiDeMo에서는 문장들을 하나의 query로 연결하여 평가
- 이전 연구들과의 공정한 비교를 위해 GT proposal은 사용하지 않음
- Multiple-choice QA
- 데이터셋: TGIF-Action, TGIF-Transition, MSRVTT-MC, LSMDC-MC
- Open-Ended QA
- 데이터셋: TGIF-Frame, MSRVTT-QA, MSVD-QA, LSMDC-FiB
모델 구조 활용 단계
- Retrieval: Clover의 두 uni-modal encoder만 사용
- 비디오/텍스트 임베딩 추출 → 코사인 유사도 기반 검색
- VQA: Clover의 전체 모듈 사용
- fine-tuning 및 inference 모두 포함
3.2. Comparing to State-of-the-art
Text-to-video retrieval
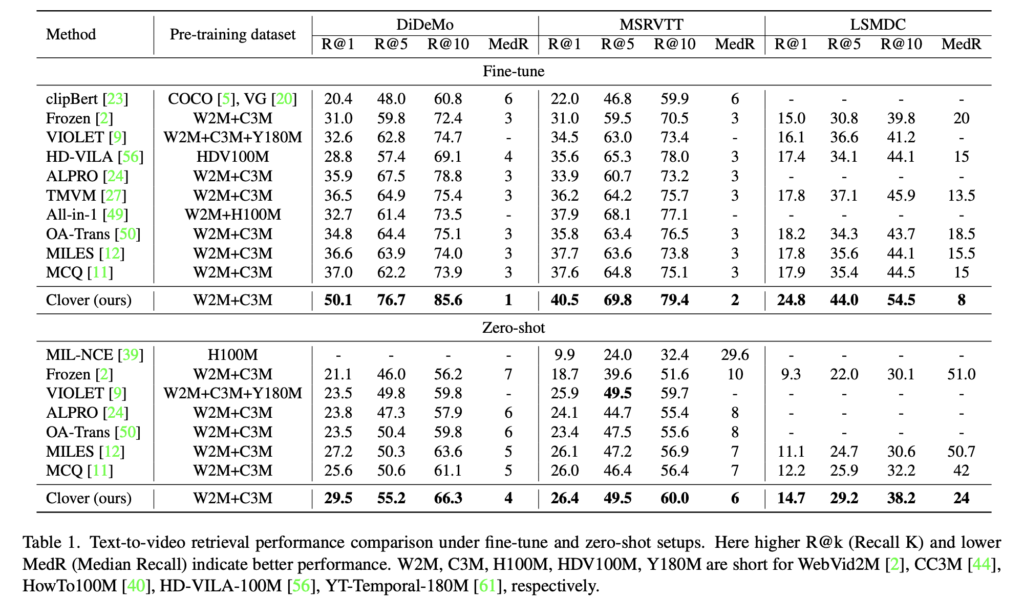
Clover는 DiDeMo, MSRVTT, LSMDC 세 데이터셋에서 기존 방법보다 뛰어난 Text-to-Video Retrieval 성능을 보였으며, 특히 zero-shot 설정에서도 MCQ 대비 평균 R@10 기준 4.9%p 향상된 결과를 기록하였습니다. 더 큰 학습 데이터를 사용한 VIOLET보다도 높은 성능을 보였고, fine-tuning 시에는 평균 8.7%p의 성능 향상을 달성하였습니다. 또한 dual encoder만으로도 효율적인 검색이 가능하다는 장점이 있습니다.
Video question answering
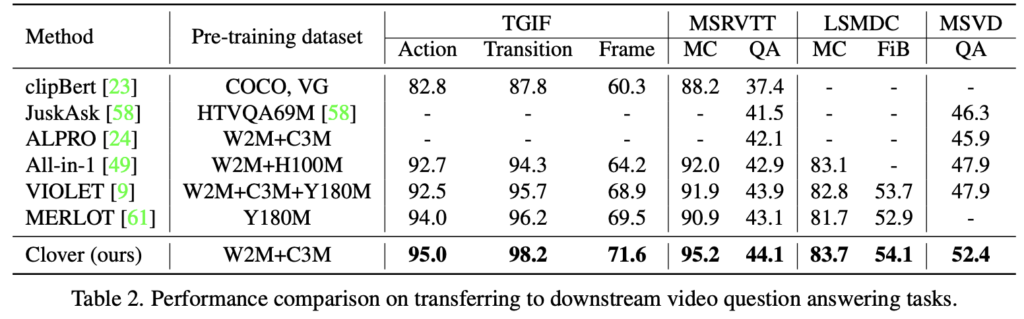
Video QA 실험에서도 Clover는 TGIF, MSRVTT, LSMDC 등 7개 데이터셋에서 MERLOT 대비 1~4.3%p 성능 향상을 보였으며, 훨씬 적은 사전학습 데이터로도 기존 SOTA를 능가하는 결과를 확인하였습니다.
3.3 Analysis
Ablation 실험은 DiDeMo, MSRVTT, TGIF-Frame, LSMDC-MC 네 개 데이터셋에서 수행되었으며, 모든 실험은 WebVid2M에서 100만 개를 샘플링한 WebVid1M으로 pre-train 하여 비교하였습니다.
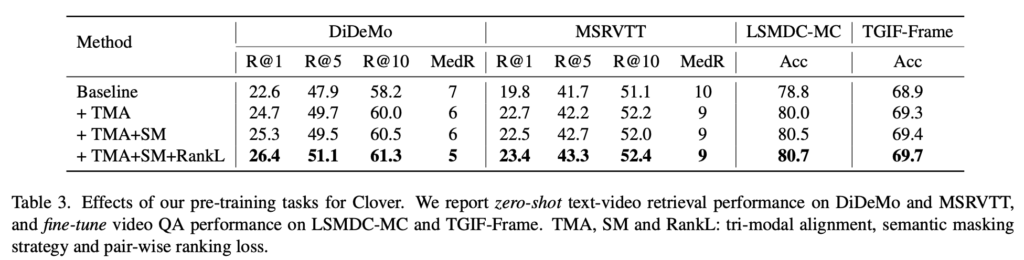
Tri-Modal Alignment (TMA)를 적용한 모델은 baseline 대비 retrieval과 video QA 성능 모두에서 향상된 결과를 보였으며, cosine similarity 분석에서도 정답 쌍에 대해 더 높은 유사도를 부여하고, 오답과의 margin도 더 크게 벌어져 더 명확한 정렬 효과를 확인할 수 있었습니다.
Semantic masking은 특히 하나의 비디오에 여러 정답 문장이 대응되는 DiDeMo와 같은 다양성이 큰 데이터셋에서 성능 향상에 효과적이었으며, 복잡한 장면에서도 핵심 개념을 더 잘 포착하도록 도왔습니다.
Pair-wise ranking loss를 적용한 경우, 마스킹 쌍과 완전한 쌍 사이의 의미 차이를 학습하도록 유도하면서 성능이 추가로 향상되었습니다.
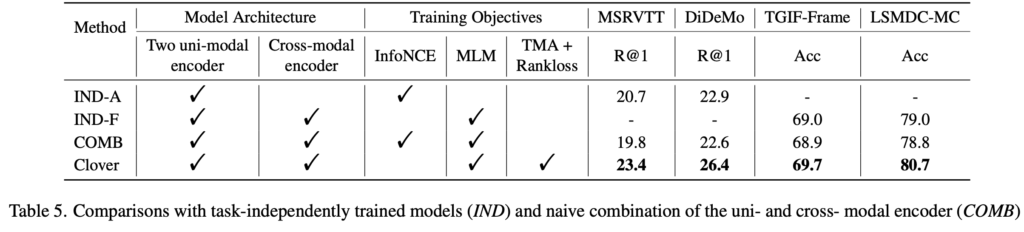
Clover는 cross-modal alignment와 fusion을 서로 보완하도록 설계되어, 두 기능을 동시에 향상시킬 수 있음을 실험을 통해 입증하였습니다. 동일한 모델 구조를 사용하되 학습 목표만 달리한 비교군들과의 성능 차이를 보면, alignment만 학습한 IND-A나 fusion만 학습한 IND-F보다 Clover가 더 우수한 성능을 보였습니다. 반면, 두 학습 목표를 단순히 결합한 COMB는 오히려 성능이 저하되어, naive한 결합은 효과가 없다는 점도 함께 확인되었습니다. 이를 통해 Clover의 통합 학습 방식이 alignment와 fusion 간의 시너지를 효과적으로 이끌어낸다는 점이 드러났습니다.
마지막으로 정성적 결과 첨부하고 마치겠습니다

Summary
Clover는 cross-modal alignment와 fusion을 동시에 강화할 수 있는 unified 비디오-언어 사전학습 프레임워크입니다. Tri-modal alignment, semantic masking, pair-wise ranking 등으로 구성된 학습 전략을 통해 다양한 downstream 태스크에서 기존 SOTA를 능가하는 성능을 달성하였으며, 적은 데이터로도 강력한 일반화 성능을 보여주었습니다.
안녕하세요 주영님, 좋은 리뷰 감사합니다.
세미나 때도 질문을 드렸었는데, 추가로 궁금한 부분이 생겨 답글 남깁니다.
Tri-Modal Alignment에서 tri-modality 간 가능한 5개 조합(Ve-Te, Ve-Tm, Ve-Mvm, Te-Mvm, Tm-Mvm) 중, 논문에서는 주로 Ve-Te, Ve-Mvm, Ve-Tm 이 세 가지 쌍만을 anchor로 삼아 contrastive learning을 수행하는 것으로 이해했습니다. Te-Mvm이나 Tm-Mvm 같은 나머지 조합들은 contrastive learning에 포함되지 않았는지 궁금증이 생겼습니다! 특히 Te-Mvm은 semantic하게 유사한 정보를 포함할 수 도 있지 않을까.? 라는 생각이 들었는데 이를 제외한 것이 해당 쌍이 noise를 유발할 위험이 있어서 제외된 것인지 궁금합니다. 아니면 저렇게 anchor를 video를 중심으로(Ve만 연결된 pair들만)로만 설계한 것이 retrieval이나 VQA처럼 비디오 중심 downstream task를 고려한 설계인건지, 반대로 text중심 downstream task라면 (Te를 중심으로한 pair)들만 contrasitive learning에 사용하게 되는 것인지 궁금합니다! 감사합니다.
1. 왜 Ve-Te, Ve-Tm, Ve-Mvm만 사용했나? 즉, Te-Mvm 같은 쌍은 왜 제외했나?
-> 말씀하신 것처럼 T_e와 Mvm도 semantic하게 연결되어 있을 수 있습니다. 하지만 문제는 Mvm이 불완전하거나 noisy할 수 있다는 점입니다. contrastive learning에서는 “완전히 정답”인 쌍 위주로 학습하는 것이 안정적이기 때문에 일부 불완전할 수 있는 쌍(Te-Mvm, Tm-Mvm)은 제외한 것 같습니다.
2. Ve 중심 anchor 선택은 비디오 중심 태스크 때문인가?
-> 네 맞습니다. Clover는 Text-to-Video Retrieval, Video QA처럼 비디오 중심의 downstream task를 다루고 있습니다. 그래서 anchor를 비디오(Ve)로 고정하여 비디오로부터 텍스트/멀티모달 표현을 찾는 학습에 최적화 한것이죠.
3. Text 중심 downstream task였다면 Te 중심 anchor로 했을까?
-> 넵, 그럴 가능성이 높을 것 같습니다. 예를 들어 텍스트를 주고 비디오를 생성하거나 찾는 것이 아니라 비디오를 설명하는 텍스트를 생성하거나 분류하는 것이었다면, 오히려 Te를 anchor로 하고 Ve, Mvm을 positive로 학습할 수 있을 것 같긴 합니다