안녕하세요, 쉰 여섯번째 X-Review입니다. 이번 논문은 2024년도 ACM MM에 올라온 Focus, Distinguish, and Prompt: Unleashing CLIP for Efficient and Flexible Scene Text Retrieval논문입니다. 바로 시작하도록 하겠습니다. ?
1. Introduction
오늘 리뷰하는 논문은 text spotting, detection, recognition 논문이 아닌 retrieval 논문입니다. 제목에도 나와있는 본 눈문의 task인 Scene Text Retrieval에 대해 간략하게 설명드리자면, 말 그대로 scene내에서 text를 검색하는 것입니다. Text detection이 영상 내에서 text가 어디 있는지 찾는 것이고, recognition은 그 찾은 텍스트가 뭔지 인식하는 것이고, spotting은 이 둘을 한번에 하는 것이라면 STR(scene text retrieval)은 입력으로 query text를 넣었을 때 이미지 갤러리라는 곳에서 해당 text가 들어있는 영상을 찾아내는 것이 목표입니다.
지금까지의 STR 방법론들은 거의 OCR 기술에 의존하여 발전해왔다고 볼 수 있는데요, 일반적으로 영상 내에서 text를 검출하고 인식한 다음 이 recognition해서 나온 text 결과를 query text와 비교하여 유사도를 계산하는 방식으로 동작한다고 보면 됩니다. 이런 방식들은 정확하긴 했는데 아무래도 속도가 느리다는 단점이 존재합니다.
본 논문의 저자는 이런 2-stage로 동작하는 기존 STR 모델들에는 두 가지 한계점이 있다고 하는데, 첫 번째는 방금 언급한 것처럼 정확도와 속도 사이의 trade-off가 있다는 것입니다. 아래 Fig1를 보시면, 파란 동그라미들이 기존 모델들인데 성능이 약간 좋은 것들이 inference 속도가 느리고, inference 속도가 빠른 것들은 약간 성능이 떨어지는 것을 확인할 수 있습니다.

두 번째 한계점으로는, 다양한 query text에 대해 유연하게 동작하지 못한다는 점입니다. 실제로 사람이 ext를 입력으로 이미지를 검색하려고 할 때 입력되는 query text는 단어 하나가 아닐 수 있는데(school bus, no smoking 등등) 기존 모델들은 단어 하나를 입력으로 하여 이미지를 검색하도록 학습되었기 때문에 여러 단어로 된 query text로는 제대로 retrieval하기 어렵다는 의미입니다.

Fig2에 이에 대한 그림이 나와있는데, (a)를 보면 phrase-level로 query가 들어왔을 때 기존 str model은 제대로 retrieval하지 못하고 있습니다. 또 (b)를 보시면 attribute-aware 이라고 하여 query의 속성까지 이해하여 검색해야 하는 경우로 빨간색으로 써진 welcome을 찾아야 하는 경우이지만 그냥 welcome이라고 써진 이미지를 잘못 찾고 있습니다.
아무튼, 본 논문은 이런 두가지 한계점을 해결하는 모델을 제안하고자 하였습니다. 이때, CLIP을 사용하고자 하였는데요. 몇 논문에서는 CLIP이 OCR task를 수행하도록 학습하지 않아도 어느정도의 ocr이 가능함을 보였었는데, 이는 CLIP이 이미지 내의 텍스트를 어느 정도 인식하고, 그 의미를 파악하는 능력이 있다는 것을 시사하겠죠. 그래서 본 논문의 저자는 이런 점을 보아 CLIP이 STR(scene text retrieval)에도 활용해볼 수 있을지를 확인해보았습니다.
먼저, 저자들은 사전 학습된 CLIP을 별도의 fine-tuning 없이 STR에 적용해보았는데, 기존 STR task에 맞춰 학습된 일부 모델들보다 더 높은 성능을 보였으며 속도도 훨씬 빠른 결과를 보였습니다. 그래도 저자는 STR에 CLIP을 그대로 적용하기에는 두가지 한계점이 존재한다고 합니다. 첫 번째로는 text perceptual scale의 제한인데요,, 풀어 말하자면 CLIP은 224×224의 고정된 해상도의 이미지를 입력으로 받도록 되어 있는데 이런 점은 이미지 분류 task에는 적절할 수도 있는데, STR의 경우에는 문제가 되게 됩니다. 왜냐면 실제 scene text image에 들어있는 text의 경우에는 image 전체 영역중에 아주 작은 영역만을 차지하는 경우가 꽤 많은데, 224×224로 해상도를 낮추면 text를 제대로 인식조차 하기 어렵기 때문입니다.
두 번째는, CLIP 내부에서 visual 정보와 semantic 정보가 얽혀있다는 문제인데요, CLIP은 영상 내에 존재하는 시각적인 요소랑 그 semantic한 요소를 동시에 학습해왔기 때문에 이미지 내에서 text가 존재할 때 그걸 단순 ‘text’로 받아들이는게 아니라 그 글자의 개념으로도 받아들이곤 합니다. 예를 들어서 영상 내에 ‘hotel’이라는 단어가 있으면 CLIP이 그걸 그냥 text로 보는 것이 아니라 호텔이라는 장소로 인식한다는 것입니다. 이런 특성으로 인해서 CLIP이 ‘coffee’나 ‘hotel’처럼 명확한 의미를 갖는 content word에 대해서는 강한 representation을 보이지만 ‘and’나 ‘with’같은 function word에 대해서는 성능이 엄청 떨어지게 됩니다. 또, CLIP이 단어들의 의미 정보를 기반으로 학습을 하다보니 뜻이 비슷한 단어들끼리 embedding space 에서 엄청 가깝게 붙어있다는 문제도 있죠. 예를 들어 ‘advise’나 ‘advice’같은 경우는 단어 철자도 비슷하고 뜻도 유사하다 보니 거의 비슷하다고 인식할텐데 STR task에서는 이 둘이 엄연히 다른 단어이기 때문에 이런 점이 문제가 됩니다. 요약하자면 결국 이 visual 정보와 semantic 정보가 얽혀있다는 특성으로 인해, CLIP을 그대로 STR에 쓰려고 하면 function word에는 약하고, 비슷한 단어들의 구분에 어려움이 생기는 것입니다.
본 논문에서는 앞서 언급한 모든 문제들을 해결하는 FDP라는 모델을 제안합니다. FDP는 “Focus, Distinguish, and Prompt”의 약자로 이 각각의 세 단계를 통해 STR을 수행하는 것이라고 보시면 됩니다. Method에서 자세히 설명드리겠지만 그 전에 앞서 각 단계에 대해 간략히 설명하자면, 먼저 Focus는 CLIP이 text에 attention을 잘 못하는 문제를 해결하기 위한 썸띵을 제안한 것이며, Distinguish 단에서는 query로 들어온 text가 의미가 있는 content word인지 혹은 기능만 있는 function word인지 구분하는 단계입니다. 두 종류의 단어들이 CLIP내에서 다르게 작동하기에 그에 맞는 적절한 retrieval을 수행하기 위함이죠. 세번째 Prompt단에서는 비슷한 단어들을 정확하게 구분하는 능력을 키우기 위해 입력으로 들어온 query를 바로 단순하게 CLIP에 입력하는 것이 아니라 semantic-aware prompting이라는 방식으로 처리하는 것입니다. 그럼 아래 method에서 자세히 설명드리도록 하겠습니다.
2. FDP Method
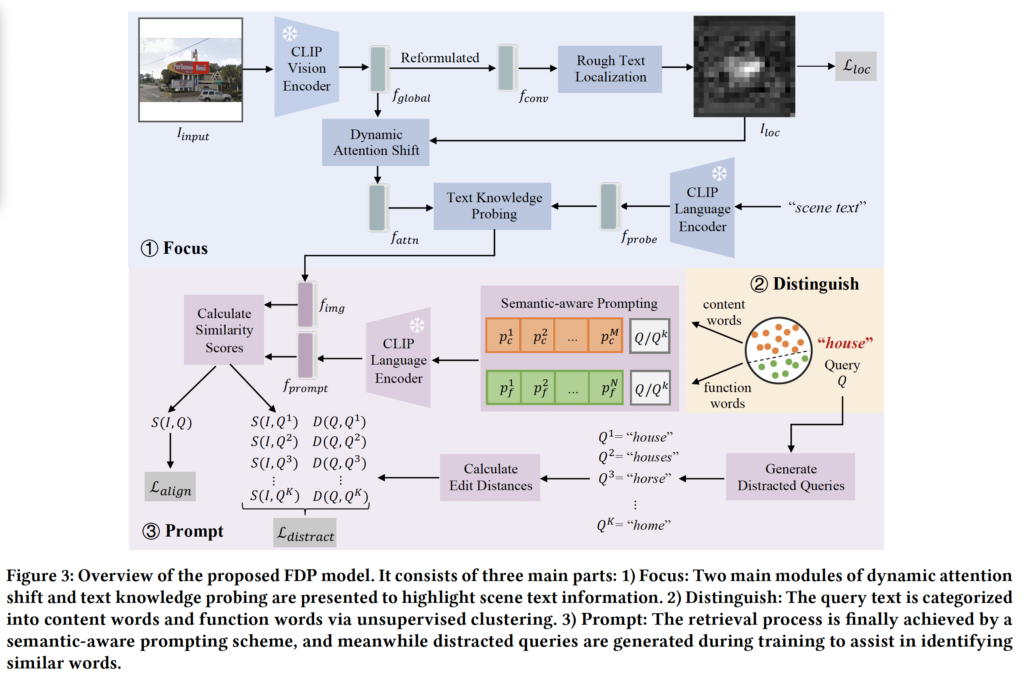
위 Fig3은 제안하는 모델 FDP의 전반적인 프레임워크 그림입니다. Intro에서 언급한 것처럼 Focus, Distinguish, Prompt 부분이 들어가 있습니다.
2.1. Focus
먼저, Focus 단계의 목적은 말 그대로 CLIP이 영상 내에서 텍스트를 보다 더 잘 보게 만드는 것입니다. 이를 위해서 Dynamic Attention Shift라고 하는 것과 Text Knowledge Probing을 제안하였습니다. 먼저, CLIP은 224×224 크기의 고정된 영상을 입력으로 받게 됩니다. 이 과정에서 영상의 일부가 잘려 나가는 문제가 있을 수 있죠. 이를 방지하기 위해 여기서는 모든 영상을 정사각형 형태로 변형하였습니다. 다시 말해, 가로와 세로 중 더 짧은 쪽에 zero-padding을 적용한 것이죠. FIg3의 맨 윗부분에 그려진 것과 같이 이 영상에 대해 CLIP의 resnet 기반의 vision encoder를 태워 global image feature f_{global} ∈ R^{C \times H \times W}를 추출해 냅니다. 이 feature를 기반으로 Dynamic Attention Shift와 Text Knowledge Probing을 적용하게 되는데요.
Dynamic Attention Shift
먼저 적용되는 dynamic attention shift같은 경우는 영상 내에 text가 차지하는 영역이 작다는 점에 착안하여, text가 있을 법한 영역에 attention을 하는 방식입니다. 이를 위해 lightweight한 text localization network를 학습한 다음, 이 네트워크를 통해 각 location이 text일 확률을 나타내는 normalized probability map I_{\text{loc}} \in \mathbb{R}^{H \times W}을 생성해냅니다. 이렇게 생성한 map은 CLIP의 average pooling 이전에 attention mask로 사용함으로써, text가 있을 가능성이 높은 영역에 더 많은 가중치를 부여하게 됩니다. CLIP은 feature map을 1D sequence로 flatten하여 multi-head attention을 수행하기 때문에 동일하게 이 probability map도 flatten하여 spatial attention weight로 작용하도록 합니다. 이 Localization network은 아래 식1의 cross entropy loss로 학습되는데, 식에서 Y는 gt localization map입니다.

또, B의 경우는 아래와 같이 계산됩니다.

text가 존재하는 pixel과 존재하지 않는 배경 pixel 비율을 반영한 가중치라고 보시면 되겠습니다.
이 과정을 통해 attention이 반영된 feature f_{\text{attn}} \in \mathbb{R}^E를 얻게 되며, 이는 텍스트 영역에 attention하는 representation을 갖는다고 볼 수 있습니다.
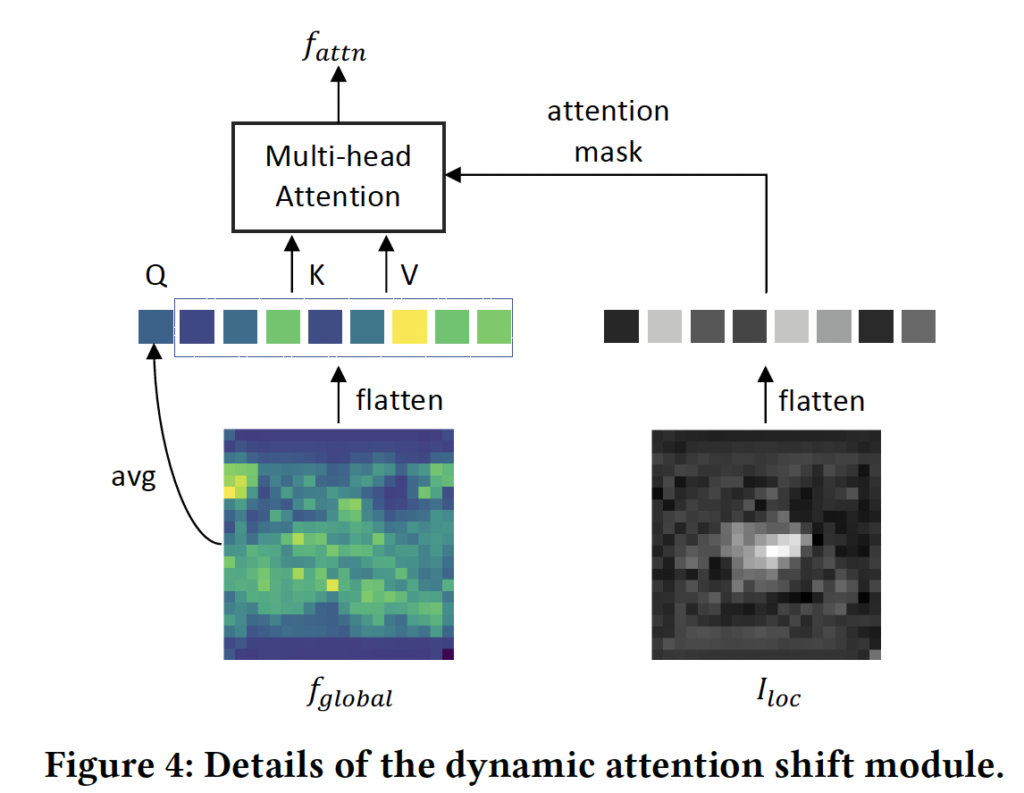
방금 설명드린 과정은 위 Fig4에 모사되어 있습니다.
Text Knowledge Probing
다음으로 Text Knowledge Probing은 CLIP이 단어 그 자체보다는 단어의 컨셉에 더 sensitive하다는 점을 보고 제안한 모듈입니다. 예를 들어 “house”라는 query text를 입력했을 때 CLIP이 “house”라는 text가 적혀 있는 영상이 아니라 실제로 집이 그려져 있는 image를 찾아낼 가능성이 높다는 것이죠. 당연하게도 CLIP의 vision encoder가 local보다는 image 전체의 global한 feature를 학습하였기 때문에 개별적인 text보다 object level의 semantic에 더 크게 반응하기 때문입니다. 그래서 이 CLIP 내부에 있는 text와 관련된 knowledge를 꺼내기 위한 probing 방식을 제안한 것이라고 보시면 되는데요.
이는 CoOP 논문에서 사용된 zero-shot classification용 prompt인 “a photo of [CLS]”에서 착안하여 “scene text”라고 하는 고정된 prompt를 사용하는 것입니다. 그림3에서도 모사되어 있듯이 이 “scene text”를 language encoder에 입력으로 넣어 뽑은 embedding을 probe feature f_{\text{probe}} \in \mathbb{R}^E라고 합니다. 이 probe feature는 이전 dynamic attention shift을 통해 얻어낸 text에 attention한 feature인 f_{\text{attn}}과 상호작용하게 되는데요. 구체적으로 말하자면, 그냥 CLIP의 multi-head cross attention을 태우는 것입니다. f_{\text{attn}}은 query로, f_{\text{probe}}는 key와 value로 두고 아래 식3과 같이 MHCA를 적용하여 최종 image feature f_{\text{img}}를 생성해 냅니다.

식3에서 덧셈은 residual connection을 의미하며, f_{\text{img}}는 보다 text에 sensitive하게 조정된 최종 image feature인 것이죠.
2.2. Distinguish
다음은 Distinguish 부분입니다. 여기서는 CLIP이 text의 의미에 따라 서로 다른 bias를 갖게 되고, 이로 인해 retrieval 성능이 단어 종류(content word vs function word)에 따라 달라진다는 점을 분석하고, 그에 따른 query 유형을 구분하여 다른 방식으로 처리하는 방식을 제안합니다.
CLIP은 image와 text간의 alignment 능력이 뛰어난 모델이지만, Parrot Captions Teach CLIP to Spot Text 에 따르면 CLIP은 시각적으로 보이는 text에 대해 내재적인 bias를 갖고 있습니다. 예를 들어 강아지가 그려진 영상에다가 ‘cat’이라는 글자를 합성해 넣으면 CLIP이 그 강아지 영상을 ‘cat’이라고 인식할 수 있다는 것이죠. 이런 연유는 CLIP이 pre-training 과정에서 image 안에 적혀 있는 text와 대응되는 caption을 반복적으로 학습했기 때문인데요(위 리뷰 참고), 이렇게 CLIP이 이미지 속에 어떤 단어가 적혀 있으면 그 단어 자체가 이미지의 의미다라고 학습하게 됨으로써 CLIP이 image 안에 있는 visual text와 그 text가 의미한느 semantic한 concept을 동일한 것으로 착각하는 경향이 있다는 것이죠. 본 논문의 저자들은 이 bias가 단지 visual text의 문제라기보다는 본질적으로 visual 정보와 semantic한 concept이 서로 얽힌(entanglement) 문제라고 합니다.
이를 분석하기 위해 MLT라고 하는 데이터셋에서 가장 많이 등장하는 단어 500개를 선택한 다음, 이 단어들의 CLIP language embedding을 뽑아 K-Means clustering을 수행해보았습니다. (이때 k=2로) 이 결과를 t-SNE로 시각화한 것이 아래 Fig.5(a)인데요. 보시면 두 cluster가 뚜렷하게 나눠져 있는 것을 확인할 수 있습니다. 이때 한 cluster는 ‘hotel’이나 ‘coffee’같이 단어 자체에 의미가 있는 content words이고 다른 한 cluster는 ‘and’와 ‘of’ 같은 function words입니다. 생각해봤을 때 content words의 경우에는 뚜렷한 의미를 갖고 있어서 이 단어가 의미하는 object 옆에 시각적으로 text가 함께 적혀있는 경우가 많아 visual 정보와 그 content가 강하게 연결되어 있겠죠. 반면, function word의 경우에는 문장 내에서 접속사처럼 쓰이기 때문에 특정 사물이나 어떤 개념과 직접적으로 연결되지 않아 시각적으로 대응되는 concept자체가 없습니다.
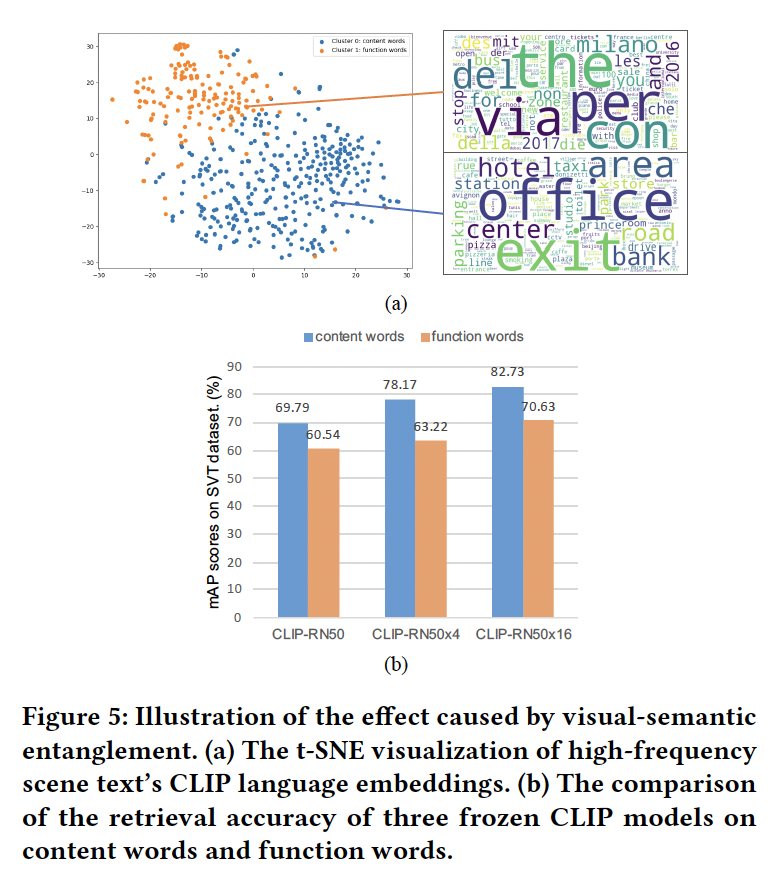
이런 단어의 특성이 STR의 성능에 어떤 영향을 미치는지 검증하기 위해, SVT라는 데이터셋에서 세 가지 CLIP 모델을 가지고 각각 content word와 function word에 대한 retrieval을 수행해보았는데요. Fig.5 (b)를 보시면 그 결과가 나와있는데, 세 모델 모두 content word에 대해 훨씬 높은 mAP score를 보이며 function word에 대해서는 성능이 낮게 나오는 모습을 보입니다. 이는 이 단어 즉, query가 content word인지 function word인지에 따라 retrieval을 다르게 수행할 필요가 있다는 점을 시사하고 있죠. 따라서 본 논문에서 제안한 FDP에서는 retrieval을 수행하기 전에, 주어진 query가 content word인지 function word인지 먼저 구분하는 절차를 추가하였습니다(distinguish). 이는 앞서 수행한 unsupervised clustering 방식 즉, query text의 embedding이 어느 k-means cluster에 속하는지 봄으로써 간단히 수행할 수 있습니다.
2.3. Prompt
마지막으로 FDP의 prompt단계를 설명드리도록 하겠습니다. 이 Prompt단은 CLIP의 language encoder에 단순 query만 넣는 것이 아닌, semantic-aware prompt를 구성하여 query의 의미에 따라 절한 representation을 갖도록 하며, Distracted Queries Assistance를 통해 CLIP이 비슷한 단어들을 잘 구분하도록 학습하는 부분입니다.
Semantic-aware Prompting
앞서 distinguish 단에서 content word와 function word를 구분했었고, 이를 다르게 처리할 것이라고 했었습니다. 본 논문에서는 prompt tuning을 도입하여 이 각각의 word 모두에 대해 효과적으로 retrieval을 수행하기 위한 semantic-aware prompting을 제안하는데요. CoOp의 아이디어에서 영감을 받아 각 단어(content vs function)에 대응하는 두 learnable한 context vector set을 도입하였습니다. 수식으로는 아래 4, 5를 보시면 됩니다.

여기서 P_c와 P_f는 각각 content word와 function word에 대한 프롬프트이며, p_i^c, p_j^f는 learnable한 context vector, Q는 query text를 의미합니다. 간단히 말해 기존 입력 query text에 learnable vector를 붙였다고 보심 됩니다. 이렇게 구성한 prompt를 CLIP language encoder를 태워 f_{\text{prompt}}를 뽑게 되겠고, 이후 앞서 생성했던 이미지 feature f_{\text{img}}와 코사인 similarity scoreS(I, Q)를 계산합니다. 이 score가 이미지 I와 쿼리 Q간의 alignment 정도를 나타내게 되며, 학습 과정에서는 matching된 image-text pair를 맞추는 contrastive learning 방식의 symmetric cross-entropy loss\mathcal{L}_{\text{align}}를 사용해 최적화됩니다.
Distracted Queries Assistance
이와 함께, CLIP이 글자 단위의 미세한 구별 능력이 부족하다는 문제를 해결하고자 distracted queries assistance 모듈을 제안하였는데요. 이 모듈은 모델이 학습 중에 헷갈릴 수 있는 비슷한 단어들을 가지고 contrastive learning하는 방식을 통해 구별 능력을 기르도록 하였습니다. 구체적으로, 주어진 query Q에 대해 edit distance가 가장 짧은 단어들 Q_1, Q_2, …, Q_K을 생성한 다음 이들을 distracted query로 간주하였습니다. 이 distracted queries 모두 prompt로 변환하여 CLIP의 language encoder에 입력이 되고 이후 각 query에 대해 image와의 similarity score S(I, Q_k)를 계산해냅니다. 동시에 각 Q_k와 원래 쿼리 Q 간의 edit distance D(Q, Q_k)도 함께 계산이 됩니다. 이후 이 두 값들을 각각 확률 분포로 정규화한 다음 이 둘 사이의 KL divergence를 계산함으로써 \mathcal{L}_{\text{distract}} loss로 사용하였습니다. 정리하자면 이 loss는 edit distance가 가까운 distracted query일수록 similarity score가 높고, 멀수록 낮아야 한다는 기준을 모델이 학습하도록 유도하는 것이죠. 결과적으로 이 모듈을 통해 CLIP이 유사하게 생긴 단어들을 보다 정교하게 구별하도록 학습함으로써 retrieval 성능을 올리고자 한 것이라고 볼 수 있습니다.
2.4. Optimization
마지막으로 전체 loss는 아래 식6과 같습니다.

여기서 L_{loc}은 text localization loss이고, L_{align}은 image와 text pair의 alignment 학습을 위한 loss겠구요, L_{distract}은 비슷한 query간의 구분을 학습하기 위한 loss입니다.
3. Experiments
마지막으로 실험 살펴보고 마무리하겠습니다. .
3.1. Comparison with Existing Methods
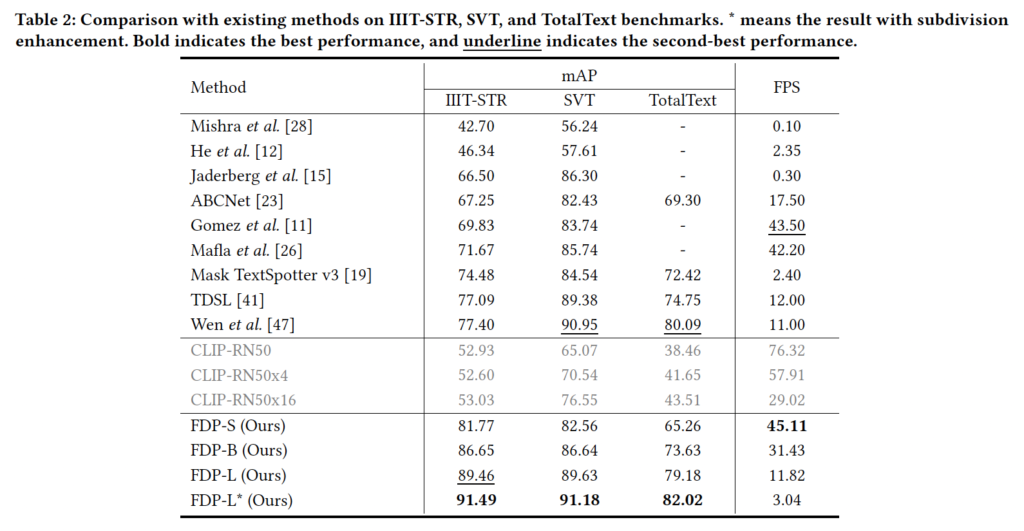
본 실험에서는 본 논문에서 제안한 모델인 FDP와 기존 STR 모델들은 비교하고 있습니다. STR은 실제 application단에서의 응용을 목표로 하는 task인만큼, inference speed도 매우 중요한 성능 지표인데 기존 STR모델들은 이 정확도와 속도 간의 trade-off 문제가 있었죠. 이 관점에서 표를 보도록 하겠습니다. 먼저, 그냥 CLIP을 아무런 추가적인 학습 없이 성능을 확인한 실험도 리포팅되어 있는데 꽤나 높은 성능을 보이고 있으며 또 일부 STR 모델 성능보다 더 좋은 성능을 보이기도 합니다. 게다가 76.32 FPS라는 엄청 빠른 속도도 리포팅되어 있네요. 그럼 본 모델 FDP-S를 보면 CLIP-RN50을 기반으로 하는데 52.93에서 29%정도 성능을 향상시켜 거의 82%의 성능을 달성하였습니다. 속도도 45.11로 꽤나 빠르죠.

정량적인 결과 외에도 위 FIg6(a)에서는 정성적인 비교를 보이고 있습니다. 보시면 “adobe”라는 query가 주어졌을 때 기존 모델인 TDSL의 경우에는 character composition에 전적으로 의존하기 때문에 image속 text가 좀 흐리거나 작으면 오인식하기 쉽습니다. 반면 FDP는 image의 visual 정보를 사용하여 이런 경우에도 정확하게 영상을 찾아내고 있습니다.
3.2. Ablation Study

다음은 ablation study입니다. 위 Table3을 보시면 되는데 먼저, 가장 단순하게 learnable한 position embedding만을 사용하여 학습한 경우 (맨 윗 행), 75% 79%의 mAP를 보입니다. 이를 바탕으로 제안된 각 모듈들을 하나씩 추가해가면서 성능 변화를 확인해보고 있습니다. 가장 먼저 Focus 단계에서 제안된 dynamic attention shift와 text knowledge probing 모듈인데요. 이 둘은 모두 영상 내에서 text에 attention하도록 하는 역할을 하는 모듈이었죠. 보시면 각각 2.6%, 0.5%의 성능 향상을 보였습니다. IIIT-STR 데이터셋에서 특히 성능이 많이 오른 것을 볼 수 있는데, 이 IIIT-STR 영상에는 아예 텍스트 자체가 포함되지 않은 이미지가 많기 때문에 Focus 단계를 더함으로써 효과를 본 것입니다.
다음으로 Prompt 단의 효과를 보자면, 기존의 CoOP 방식처럼 단 하나의 learnable한 prompt만을 사용하는 경우 (4행) 80.07%, 81.03% mAP를 기록했지만 본 논문에서 제안된 semantic-aware prompting 즉, query단어가 content word인지 function word인지 먼저 구분한 다음 이데 따라 각가 다른 prompt를 적용하는 경우 81.27%, 81.94%로 더 높은 성능을 보입니다. 마지막으로 distracted queries assistance를 통해 최종 81.77, 82.56% mAP를 달성하고 있네요.
3.3. Extending to More Retrieval Settings
마지막으로 FDP의 확장성을 검증하는 실험 부분입니다. Intro에서 짧게 기존 STR은 phrase-level(2개 이상의 단어) retrieval과 attribute-aware retrieval에 잘 대응하지 못한다고 했었는데, 이에 대한 실험이라고 보시면 됩니다.
Phrase-level scene text retrieval

먼저, phrase-level retrieval부분인데요. 생각해보면 실제로 사람이 검색을 한다고 할 때 실제 검색하는 단어는 단순 단어 하나보다는 ‘ice cream’이나 ‘do it yourself’처럼 여러 단어로 구성된 phrase인 경우가 많습니다. 이를 반영하여 본 논문의 저자는 PSTR(Phrase-level Scene Text Retrieval)이라는 벤치마크에서 FDP의 성능을 평가하였는데, 같이 비교하고 있는 STR 모델 표의 저 두 모델은 query를 단어 단위로만 처리할 수 있는 모델이기에 각 phrase를 단어로 분리한 다음 각 단어에 대해 retrieval을 수행하고, 그 결과의 similarity score를 평균 내는 식으로 처리하였습니다. Table5에 그 결과가 나와있는데 FDP는 이런 기존 STR 모델들 보다 phrase-level retrieval에서 훨씬 좋은 성능을 보이며 빠른 inference speed도 보이고 있습니다. 표의 2행에 나와있는 TDSL이라고 하는 모델은 이렇게 구를 단어로 쪼개 평균내어 성능을 뽑았음에도 89정도의 높은 성능을 보이는데, 좀 위에 올려둔 FIg6(b)부분을 보시면 “no smoking”이라는 query에 대해 “no engine”이나 “no softener”과 같은 유사하긴 하지만 의미가 전혀 다른 영상들을 뽑고 있기도 합니다. 게다가 inference speed가 좀 낮긴 하죠.
Attribute-aware scene text retrieval

마지막으로 attribute aware retrieval부분인데, 앞선 phrase level에서와 마찬가지로 실제 검색을 할때 사람들은 단순 단어를 검색하는 것뿐만 아니라 color나 position 등등과 같은 속성(attribute)를 포함하여 더 정확한 검색을 원할때가 있습니다. 본 논문에서는 이를 고려하여 FDP가 attribute-aware STR로 확장할 수 있는지 여부를 실험해보았는데요. 이를 위해 IIIT-STR이라는 데이터셋에서 attribute와 관련된 query를 선별해 실험해보았습니다. 위 Fig7을 보시면 FDP는 실제로 attribute를 만속하는 image를 잘 찾고 있는 것을 볼 수 있는데, 이는 CLIP이 pre-training 단에서 color나 font, position 등등 다양한 visual-language concept을 학습했기에 가능한 것이겠죠. 반면 기존 OCR을 기반으로 설계된 STR 모델들은 단순 text만 인식 가능할 뿐 text의 스타일이나 attribute 정보를 표현할 수 없어 이런 유형의 retrieval은 불가능하다고 볼 수 있습니다.
안녕하세요. 리뷰 잘 읽었습니다.
1) Dynamic Shift Attention 과정이 Text가 있을 법한 Localization에 대한 Probability map을 통해 Attention하고자 하는데, 그럼 GT로 그 Localization 정보가 존재하는건가요?
2) Distinguish 과정에서 제 생각에는 보통 문장은 Function word에 따라 Content word 쌍의 의미가 달라질 수 있다고 생각하는데, 이들을 구분함이 어떤 효과가 있을까요?
댓글 감사합니다.
1) 넵 localization gt 정보가 존재합니다. 기존 데이터셋의 bbox나 polygon annotation 정보를 이용해 2d probability map형태의 gt localization mask를 만들어낸거라고 보면 되겠습니다.
2) 본 task가 text query로 문장을 넣는 것이 아닌 word-level query이기 때문에 content word의 의미가 달라지는건 크게 관련이 없을 것 같습니다. 물론 phrase-level라면 얘기가 달라지겠지만요.. 그럼에도 이들을 구분하는 이유는 function word는 text 자체로 표현되어 있는 경우가 적기도 하고, 있다고 하더라도 CLIP이 잘 encoding 하지 못해 오히려 retrieval 성능이 안좋았기에 각각을 구분하여 처리함으로써 semantic한 confusion을 줄일 수 있다고 봅니다 ..
안녕하세요. 좋은 리뷰 감사합니다.
distracted queries assistance과정에서 edit distance가 짧은 단어들을 생성하여 뽑은 feature와 image feature와 similarity와의 KL divergence를 loss로 사용하는 것으로 이해했는데, edit distance가 짧은 단어들이라는 것이 말 그대로 편집 거리를 의미하는 것인가요? 또 edit distance가 각각 다른 query들을 생성하는 것인지 혹은 일정 범위 내에 랜덤으로 생성하는 것인지 궁금합니다.
감사합니다.
댓글 감사합니다
edit distance는 편집 거리가 맞습니다. 두 단어가 있을 때 한 단어에서 다른 단어와 일치시키기 위해서 수행되는 삽입 / 삭제 / 치환이 기준이라고 보시면 됩니다. 예를 들어 “house”에서 “horse”는 가운데 u를 r로 바꾸면 되니까 edit distance가 1이 되겠죠.
또, 이 query들은 랜덤으로 생성하는 것이 아니라 dictionary안에 있는 단어 전부를 대상으로 해서 edit distance를 계산한 다음 가장 가까운 5개를 선별한 것입니다.
안녕하세요 정윤서 연구원님 질문이 있어 댓글 남깁니다!
1. Text Knowledge Probing에서 “scene text”라는 단일 프롬프트를 사용하는데, 이 프롬프트의 선택이 성능에 얼마나 영향을 미치는지 ablation이 궁금합니다. 혹시 prompt choice에 대한 실험이 있었을까요?
2. Distracted Queries Assistance에서 edit distance를 기반으로 distractor를 생성했다고 했는데, 의미는 다르지만 철자가 비슷한 단어는 잘 걸러질 것 같습니다. 그런데 반대로 철자는 다르지만 발음이나 의미가 유사한 경우(e.g., “café” vs “coffee”)에 대해서도 robustness가 있을까요?
댓글 감사합니다
1. 넵 실험에서 prompt choice에 대한 실험이 존재합니다. 실험에서는 “text”, “word” “a set of text instances”을 prompt로 두고 ablation study를 수행했는데 어떤 prompt를 사용하느냐에 따라 최대 2.2% 정도의 성능 차이를 보였으며 이중 “scene text”가 가장 높은 성능을 보여 CLIP의 학습 데이터셋에 이 문구와 관련된 표현이 자주 등장했을 것이라고 보아 이를 최종 prompt로 선택하였습니다 !
2. 음 예시 들어주신 부분은 현재 방식으로는 robust하지 않을 것 같습니다,, 이 distracted queries assistance는 edit distance 기준으로 distractor를 생성하기 때문에, 발음이 비슷한 이 단어는 스펠링 차이가 커서 edit distance top-k에 포함이 안될것이고 결국,,,, 이 robust하게 동작하지 못할 것으로 보입니닷
안녕하세요 윤서님, 이에 대한 좋은 세미나와 리뷰 감사합니다.
세미나 때, 몇몇 연구원 분들께서 text localization network(rough text localization)에 대한 질문을 하셨는데, 해당 질문들을 듣고 저도 추가적으로 생겼던 궁금증에 대한 답을 얻고자 댓글을 남깁니다!
text localization network의 학습 방식에 대해서 의문점이 생겼습니다!
Dynamic Attention Shift에서 사용하는 localization network는 supervision signal로 GT localization map을 사용한다고 이해를 하였습니다.
그렇다면 해당 GT는 어떻게 얻어지는지에 대한 의문점이 생겼는데 알려주시면 감사하겠습니다! 혹은 제가 잘못 이해한 부분이 있다면 알려주시면 감사하겠습니다!
댓글 감사합니다.
본 논문에서 gt localization map을 생성하는 과정에 대해서는 자세히 언급되지 않습니다만, 기존 데이터셋의 bbox나 polygon annotation 정보를 이용해 2d probability map형태의 gt localization mask를 만들어낸거라고 보면 되겠습니다. 단순하게 생각한다면 이 text bbox(혹은 polygon) 외의 pixel들은 다 0으로 두어서 만들수도 있겠구요. 아무래도 soft한 probability map을 만들기 위해 gaussian blur 처리를 하거나 soft label처리를 했을 수도 있겠습니다.