
논문: Frustum PointNets for 3D Object Detection from RGB-D Data
ImVoteNet[1] 리뷰[2]를 하면서 2D 이미지와 3D point clouds를 사용하는 방법에 대한 아이디어를 알게 되었고, 관련 연구 목록에서 찾은 Frustum PointNets를 소개하려고 합니다.
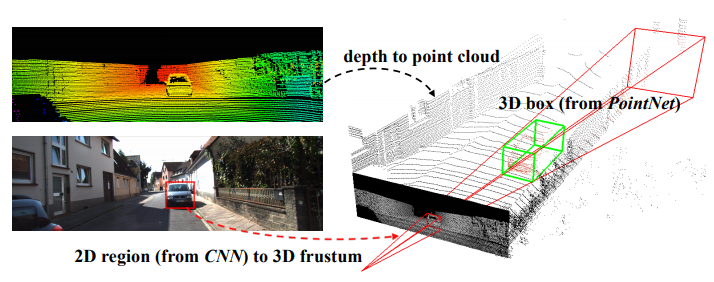
이 논문의 아이디어는 그림1(커버 이미지)를 보면 직관적으로 알 수 있습니다. 2D와 3D 데이터가 있고 2D에서 3D로 좌표를 변환하는 camera projection matrix가 있다는 가정이 필요합니다. 1) 2D 이미지에서 object detection을 수행하고, 2) 2D object가 3D 공간으로 projection 시킨 영역만 집중적으로 살펴보고 3D object box를 찾는 것입니다.
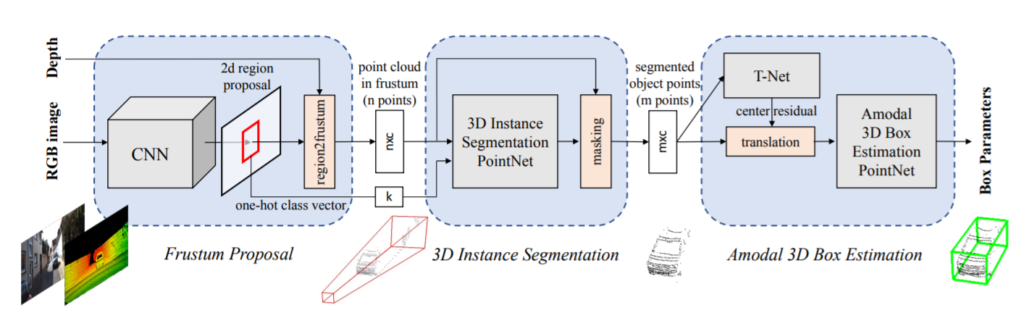
논문은 크게 3개의 파트로 나누어져 있는데 1) 2D object detection을 실행하여 target object를 3D로 투영시켜 frustum 형태로 추출, 2) frustum 영역 내의 point clouds에서 해당 object의 확률값(score)를 계산, 3) frustum 내의 object centroid에서 실제 object의 centroid로 변환 (T-Net)해준 후 3D box의 center (c_x, c_y, c_z) , size (h, w, l) , angle \theta 값을 계산으로 이루어져 있습니다.
Frustum Proposal
2D object detection 모델은 ImageNet을 pretrained한 VGG[3] 모델 중 SSD[4]에서 사용한 구조에 COCO[5] object detection datasets와 KITTI[6] 2D dataset을 학습시킨 것이 backbone입니다. 2D region proposal을 위해 FPN[7]을 사용하였습니다.
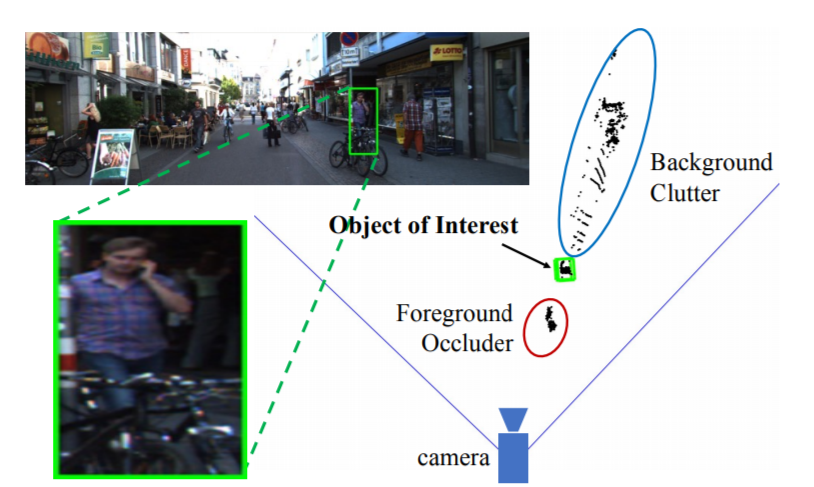
3D Instance Segmentation
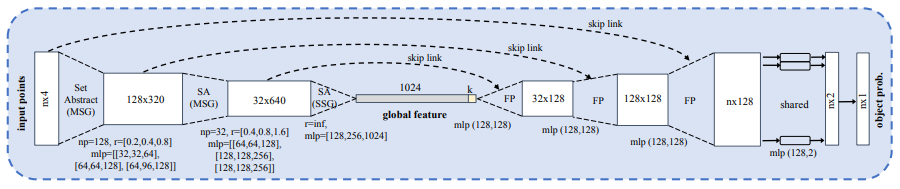
Frustum proposal를 통해 검색할 영역이 줄어들었지만(sampled) 그림 3과 같이 실제 우리가 찾고 찾고 싶은 points 이외의 다른 요소들이 포함되어 있습니다. 그래서 sampled points 중에서 관심 있는 것을 찾기 위해 PointNet++[8]을 사용하여 관심 points를 찾아내게 됩니다.
Amodal 3D Box Estimation
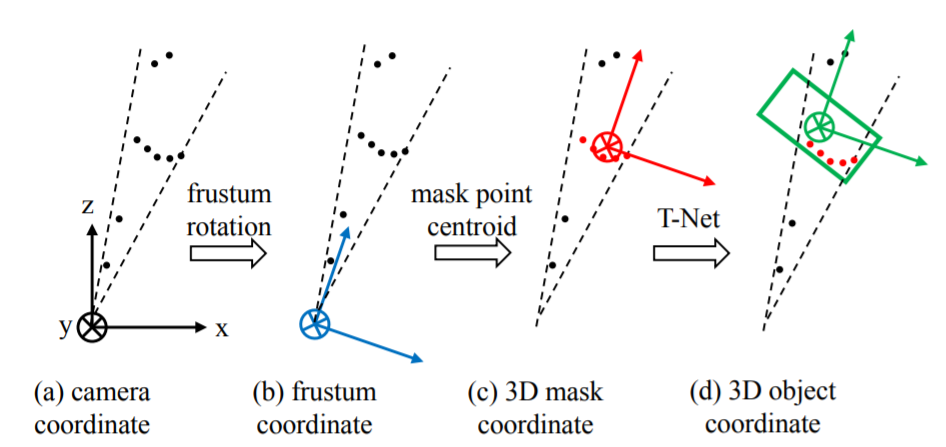
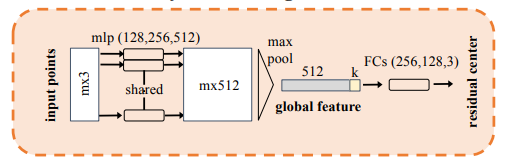
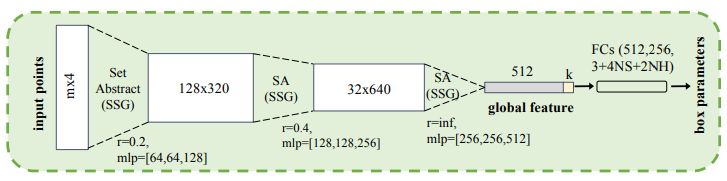
위의 두 과정을 거치면서 공간 좌표계는 (a)에서 (c)로 변환되어 왔습니다. 그런데 (c)의 centroid는 frustum 영역내에서의 centroid지 실제 object의 centroid는 아닙니다. 따라서 그림 6의 T-Net을 제안하여 (d)와 같이 centroid가 이동할 수 있도록 residual을 학습하게 됩니다. 그러면 그림 2의 segmented object points와 residual을 적용한 centroid 값을 적용하여 그림 7과 같이 3D box의 center (c_x, c_y, c_z) , size (h, w, l) , angle \theta 를 출력해줍니다. 참고로 그림 7의 fully connected 출력 크기 중 NS와 NH는 각각 미리 정의된 size templete과 angle(heading)이 균일하게 분할된 bin을 뜻합니다. 또한 4NS 의 경우 centroid에 score를 얻기 위해 4이며, 2NH 의 경우 heading 값과 score를 얻기 위해 2입니다.
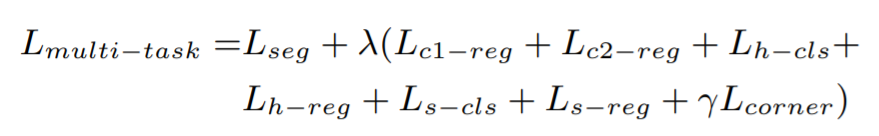
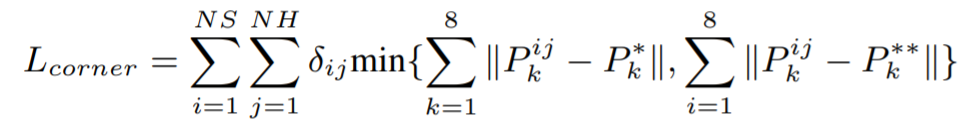
학습은 식 1과 같이 위에 소개된 모든 network의 loss에 weight를 적용하는데요. \lambda 는 1, \gamma 는 10의 값을 주고 학습합니다. L_{seg} 는 3D instance segmentation loss이고, L_{c1-reg} 은 T-Net의 loss, L_{c2-reg} 는 center regression loss, L_{h-cls} 와 L_{h-reg} 는 heading angle loss, L_{s-cls} 와 L_{s-reg} 는 box size loss이며, L_{corner} 는 3D box의 IoU metric loss를 뜻합니다.


이 논문에서는 매우 다양한 abilation study 뿐만 아니라 class 별 분석을 하고 있지만 본 리뷰에서는 논문 발표 당시 KITTI 3D object detection leader보드에서 1등을 달성한 표 1의 결과를 공유해 드립니다. 또한 그림 8에서 알 수 있듯이 비교적 정확하게 3개의 class를 찾는 것을 확인할 수 있습니다.
KITTI 3D datasets에는 stereo camera datasets도 있습니다. 따라서 이를 이용하여 depth map을 구하면 3D object detection을 할 수 있습니다만 2D object detector에 크게 종속되는데다가 거리별로 편차가 심한 편입니다. 그리고 3D raw data인 point clouds는 데이터가 매우 sparse하여 object detection을 하기 위해 region proposal이 힘듭니다. 이 논문은 앞서 언급한 두 가지 방법의 단점을 희석시키기 위해 각자 잘하는 것을 적용한 것인데요. 3D object detection을 위해 search region area를 줄이는 것은 매우 좋은 방법으로 생각합니다.
실세계의 데이터는 3D(혹은 4D+)로 구성되어 있습니다. 그리고 2D 이미지는 사람이 이해할 수 있는 많은 정보를 주기 때문에 완전히 무시할 수 없는 정보이면서 동시에 너무 의존하기에는 depth와 같은 정보가 없어져 버리기 때문에 3D object detection을 하기 위해 어려움이 있습니다. 실시간으로 task를 수행하기 위해서는 더 어렵겠죠. 따라서 다양한 센서를 이용하는 것이 필요하다고 생각됩니다.
참고:
[1] ImVoteNet: Boosting 3D Object Detection in Point Clouds with Image Votes
[2] ImVoteNet 리뷰
[3] Very Deep Convolutional Networks for Large-Scale Image Recognition
[4] SSD: Single Shot MultiBox Detector
[5] Common Object in Context
[6] KITTI datasets
[7] Feature Pyramid Networks for Object Detection
[8] PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space
https://github.com/open-mmlab/mmdetection3d 관심이 있으시다면 심심하실 때 한번 가지고 놀아보시는 것도 좋을 듯합니다.
감사합니다. 하반기 중에 튜토리얼로 3D를 할 생각이었는데 큰 도움이 될 것 같습니다.