Abstract
일반적으로 네트워크는 accurate(정교함)와 robust특성을 함께 갖을 수 없다고 알려져있다. 예를 들어 adversarial example에 robust한 특성을 갖기 위하여 clear한 input에 어려운 예제를 학습시켜 네트워크의 margin을 키운다. 이러한 방법은 robust 하지만, clear한 예제에 잡음을 추가시킴으로서 정교함이 더 떨어질 것이다. 또, 모델의 robust를 증가시키는 방법 중 하나인 gradient masking는 비파괴적인 방법이라고 불린다. 이는 gradient를 읽지 못하게 하는 방법으로 많은 adversarial 공격 모델이 추론과정에서 gradient를 관찰하여 이루어짐에서 착안되었다. 이는 gradient quality와 adversarial robustness의 관계에 대해 다시한번 강조한다. 이러한 점에 대해 논문은 ReLU가 non-smooth한 특성 때문에 adversarial 학습에 좋지 않다는 것을 밝힌다. 또한 새로운 활성함수 smooth adversarial trainng(SAT)를 소개하여 ReLU의 문제점을 해결하고자 한다. SAT는 더 어려운 훈련 샘플을 제공할 수 있고, gradient update 계산을 더 잘 할 수 이으므로, adversarial training 결과를 향상시킨다. 논문은 실험을 통해 SAT가 adversarial robustness를 추가적 계산이나, 정확성 저하 없이 성능을 향상시킴을 보인다.
ReLU Weakens Adversarial Training
ReLU가 어떻게 학습을 약화시키고, SAT가 어떻게 학습을 강화시키는지 알기위해 gradient 계산의 역방향(backward pass)를 통과하여 제어실험을 진행한다.
3.1 Adversarial Training
Adversarial Training은 다음을 목적으로 한다.
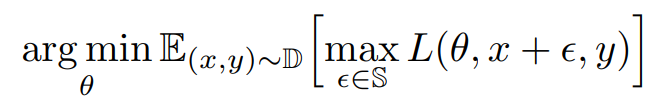
L(. . .) : Loss function
theta: network parameter
epsilon : adversarial 잡음
x : 학습 sample data
y : 학습 sample label
따라서 Adversarial Training은 Adversarial 예제를 만드는 내부 최대화 과정과, parameter update를 통한 외부최소화 과정으로 이루어진다.
3.2 어떻게 Gradient quality가 Adversarial Training에 영향을 미치는가?
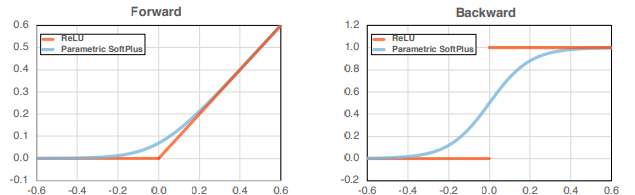
ReLU는 그림 1에서 확인할 수 있듯이 불연속적인 변화를 갖는다 논문은 이러한 non-smooth 특성이 training process를 해친다고 가정하였다. 특히 Adversarial Training은 이러한 미분과정을 2번 거치기 때문에(내부 최적화 , 외부 최적화) 이러한 영향을 더 크게 받는다 여겼다.
이러한 문제를 해결하기 위하여, 논문은 먼저 parametric softplus (: f(a,x)=\frac{1}{\alpha}log(1+exp(ax)) ) 를 사용하였다.
hyperparameter \alpha 는 cure의 모양을 결정한다.
이는 미분햐여 연속이며 \alpha=10 일 때 ReLU를 잘 근사한다고 경험적으로 밝혔다.(실험시 명확한 효과를 벤치마킹하기위해, forward pass의 ReLU는 유지하고 backward pass의 ReLU만을 대체하였다)

2행 내부최적화에 smooth도입
3행 외부최적화에 smooth 도입
4행 내부,외부 최적화에 smooth 도입
여기서 smooth도입이란 앞서 말하였듯이 backward pass에만 smooth 활성함수를 적용한 것이다.
Improving gradient quality for the adversarial attacker.
표1에서 확인할 수 있듯이 단순히 parametric softplus를 이용하였을 때는 정확도가 감소하며 trade-off 관계임을 다시한번 보여주었다.
논문은 모델의 adversarial robustness가 학습 중의 더 어려운 예제 때문이라는 가설을 세웠다. 즉, 내부 최적화 단계의 더 나은 gradient는 공격자를 강화시킨다는 가설이다. 이 가설을 증명하기 위해 두 ResNet-50 모델을 하나는 standard training을 다른 하나는 adversarial training을 진행한다. robustness는 PGD attacker를 사용하였다. 실험 결과로는 더 좋은 gradient일 때 PGD-1 attacker 또한 모델에 더 상처를 입혔다.
Improving gradient quality for network parameter updates.
adversarial attacker의 gradient를 개선하였을 때와 다르게 이 방법은 adversarial robustness를 다른 손실이나 추가 연산 없이 향상시켰다. 그 결과는 표 1의 3행을 보면 확인할 수 있다. 흥미로운 점은 더 나은 gradient update는 standard training을 향상시켰다.(즉, ResNet50에서 더 나은 gradients는 정확도를 향상시켰다)
3.3 ReLU의 Gradient Issue 말고 다른 향상 방법이 있는가
attack iteration 증가
attack iteration을 늘리면 더 hard case인 사례를 생성할 수 있다고 알려져 있다. 논문에서는 실험을 통해 PGD attacker를 더 학습시켰을 때 마치 개선된 gradients를 이용한 것 처럼 동작했다고 한다. 즉, 정확성은 손실되고 robustness는 증가하는 결과가 도출되었다
Training Longer
오래 학습시키는 것 또한 training loss를 낮춘다고 알려져 있다. 이 실험결과도 위와같은 trade-off 관계를 보여주었는데, 훈련기간이 길수록 정확도는 상승하지만 robustness는 감소하였다. 이를 통해 training longer 방법은 ReLU의 outer step의 문제를 해결하지 못함을 추측할 수 있다.
위 두 방법의 결과
ReLU의 gradient 문제는 backward pass를 다른 smooth approximation으로 바꾸는 것 뿐이란걸 시사한다.
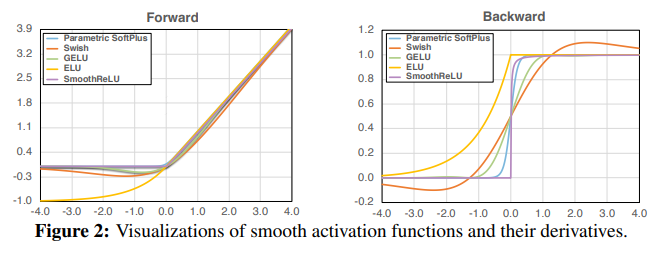
4 Smooth Adversarial Training
위에서 보였듯이 ReLU gradient 를 개선하는 것은 attacker의 성능과 gradient updates를 모두 개선한다. 그럼에도 불구하고 foward pass와 backward pass의 불일치 덕분에 차선책이 될 수 있다.
따라서 더 나은 개선을 위해 논문은 구조의 smooth activateion을 통해 smoothness를 강화시키는 Smooth Adversarial Training(SAT)를 제안한다.
의문점
더 나은 gradient의 개념이 이해가 어렵다. 아마 gradient masking 논문을 통해 확인해야할 것 같다 [관련]
1. Adversarial attack을 학습할 때 내부 최적화와 외부 최적화가 GAN을 예로 든다면 생성자와 판별자를 말하는 건가요?
2. 논문의 요지는 활성화 함수를 미분 불가능한 ReLU 대신 미분가능한 것을 사용하는 것이 좋다는 것 같네요. 그러면 figure2에 제시된 활성화 함수를 사용하는 것을 권장한다고 보면 되나요?
참고)
활성화 함수: https://en.wikipedia.org/wiki/Activation_function
SmoothReLU: https://software.intel.com/content/www/us/en/develop/documentation/daal-programming-guide/top/algorithms/analysis/math-functions/smooth-rectifier-linear-unit-smoothrelu.html