안녕하세요 이번주에는 미니 챌린지 도중 3D Gaussian Splatting에 추가적인 feature들을 추가로 넣어서 사용해보고자 feature splatting 논문을 읽어보았습니다.
Introduction
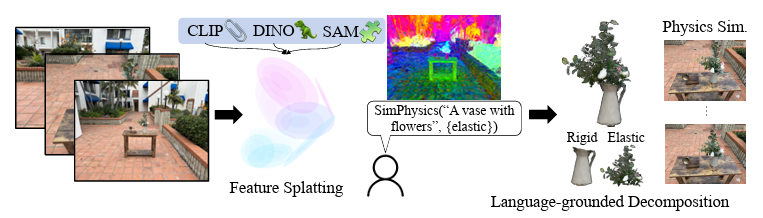
낙엽의 움직임을 통해 보이지 않는 바람의 존재를 시각적으로 나타낼 수 있다는 말을 하면서 시작합니다. 카메라는 바람을 찍을 수는 없지만 간접적으로 낙엽을 통해 바람이 찍힌다는 비유인데요, 낙엽이 가만히 있거나 바로 아래로 떨어지지 않고 양 옆으로 살랑살랑 움직이면 바람의 존재를 인지하는 것 처럼 정지된 상태의 3D scene에 자연어 query를 통해 동적인 느낌을 내는 장면으로 바꿔주는 기법을 제안했습니다. 저자는 이 논문의 핵심 contribution을 정적인 scene에 semantic feature와 언어 기반 물리 시뮬레이션을 추가해 동적 scene으로 변화시키는것, 여러 vision foundation model들의 2D feature를 효과적으로 사용한 것, 언어 기반으로 객체를 삭제하거나 변화시키는 편집 도구를 제안한 것이라고 하네요. 차근차근 살펴보도록 하겠습니다.
Method
Differentiable Feature Splatting
저자는 기존의 3D Gaussian Splatting 기법을 확장하여 가우시안들에 RGBA정보에 더해 semantic feature를 추가하여 최적화 했습니다. 기존의 Gaussian Splatting 방법은 장면을 수많은 3D gaussian primitives로 표현하며, 각 가우시안은 중심점과 타원형의 모양을 정의하는 공분산 행렬, 색상 및 투명도를 가지고 있었습니다. 공분산 행렬은 보통 크기 조정을 담당하는 대각행렬과 회전을 나타내는 행렬 R을 곱하는 형태로 타원 모양을 표현합니다. 또한, 각 가우시안은 시점에 따라 달라지는 색상 정보를 구형 조화함수(Spherical Harmonics)를 이용해 나타내고, 이 함수로 보는 각도에 따라 색상 표현을 다르게 할 수 있다고 합니다.
저자는 기존 Gaussian Splatting 방법의 각 가우시안에 feature vector를 추가 해줍니다. 이 feature는 view-invariant하고, 색상과는 별개로 존재하게 됩니다. 렌더링 과정에서 각 픽셀의 최종 특징 맵은 여러 가우시안에서 투영된 특징 벡터들이 투명도(alpha compositing)를 기반으로 혼합된 형태로 만들어지는데, 이 과정 전체가 미분 가능하기 때문에, 실제 이미지로부터 얻은 feature map과 비교해 각 가우시안을 최적화할 수 있다고 합니다. (사실 미분가능한게 무슨 의미인지 잘 모르겠습니다..)
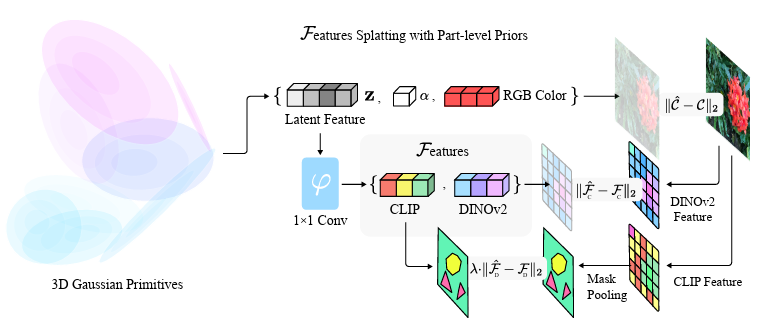
하지만 새로운 feature를 추가할 때 단순히 CLIP과 같은 Visual Language Model에서 얻은 feature map을 그대로 사용하는 것은 노이즈가 많고 품질이 떨어진다고 합니다. 이를 해결하기 위해, 논문에서는 위 figure와 같이 SAM을 통해 segmentation을 진행한 뒤, 각 분할 영역 내에서 CLIP 특징을 평균화하여 노이즈를 제거하고 더 정확한 특징을 생성합니다. 아래 figure를 보면 훨씬 깔끔하게 semantic 한 정보를 담고있는 것을 볼 수 있습니다. 또한, DINOv2 모델을 이용하여 의미적으로 더욱 일관성 있는 특징 맵을 추가로 생성하여, 학습 시 정규화 요소로 함께 사용합니다. 두 가지 특징 맵(CLIP과 DINOv2)을 동시에 최적화하되, 주로 CLIP 특징에 가중치를 두어 의미적 일관성과 정확성을 동시에 챙겨간다고 합니다. 이와 함께, 가우시안을 학습할 때 발생하는 bottleneck을 해결하기 위해, CUDA 커널을 개발하여 메모리 접근을 최적화하고 효율적인 병렬 처리를 진행했다고 합니다.

이러한 과정을 통해 저자는 기존의 Gaussian Splatting 방식에 풍부한 의미적 정보까지 추가한 Multimodal 3D 표현 방식을 실현했다고 합니다. 결과적으로 장면의 시각적 사실성을 유지하면서도, 언어 기반의 직관적인 객체 선택을 가능하게 하는 feature를 얻을 수 있습니다.
Language-guided Scene Decomposition
가우시안에 추가된 semantic feature를 바탕으로 사용자가 입력한 자연어 질의를 통해 장면 내의 객체를 자동으로 선택하고 편집할 수 있게 됩니다. 장면을 분해한다는 것은 특정 텍스트로 표현된 관심 영역에 해당하는 가우시안들의 집합을 선택한다고 말할 수 있는데요, 이 작업은 CLIP 모델의 텍스트 임베딩과 가우시안에 합쳐진 특징 벡터 간의 유사도를 계산해서 진행하게 됩니다. 사용자의 text query가 CLIP 텍스트 인코더를 통해 임베딩 벡터로 변환되고, 각 가우시안이 가진 특징 벡터와 이 임베딩 간의 코사인 유사도를 계산하여, 가장 잘 일치하는 가우시안 그룹을 찾아낸다고 합니다. CLIP feature를 활용해 open vocabulary로 작동할 수 있습니다. 선택된 가우시안들은 이후 장면을 편집하는 데 활용됩니다. 3D gaussian은 NeRF와 달리 직접적이고 간단한 구조를 가지므로 편집 역시 직관적이고 간단하다고 합니다. Removal, Translation, Rotation, Scalingd이 가능합니다.

객체를 삭제할때는 그저 해당 객체로 분류된 가우시안들을 전체 가우시안 집합에서 제거하는 방식으로 진행됩니다. 가우시안의 표현 방법에 따른 이점? 인 것 같습니다. 이동할 떄는 displacement vector b1을 사용하여 중심점을 이동시킵니다. 가우시안은 mean으로 위치를 표현하기 때문인 것 같습니다. displacement vecotr를 더해주면 됩니다. 객체를 회전시킬 때는 공분산 행렬을 변환시켜야 합니다. 가우시안은 공분산 행렬이 회전 R과 크기를 나타내는 S로 이루어져 있는데, 회전을 할 때는 위 설명의 Rotation에 적힌 수식을 통해 가능합니다. 마지막으로 크기 조정인데요, 객체의 크기를 바꾸려면 축이 정렬된 크기 벡터 S1을 통해 진행해야 하고, 중심점의 좌표를 우선 스케일링해서 위치를 바꾼 다음 공분산행렬도 크기 조정 벡터를 통해 변경합니다. 식은 위 설명의 scaling에 적힌 것 과같ㅅ브니다. 정리하자면 가우시안으로 표현된 feature이기 때문에 이렇게 벡터 연산만으로 물체를 다양하게 editing 할 수 있고, 그대로 scene에 반영할 수 있는 것 같습니다. 아래와 같이 scene을 편집할 수 있습니다

Language Driven Physics Synthesis
이 부분에서는 앞서 생성된 정적인 3D 장면에 실제와 같은 물리적 움직임을 더하는 과정에 대해 설명합니다. feature splatting은 정적인 3D 장면에 물리 법칙을 적용하여 객체가 실제 환경처럼 움직이거나 변형되는 동적인 장면을 자동으로 만들어내는 것이 목표입니다. physics scene은 다음과 같은 방법으로 생성됩니다.

먼저 input 이미지들을 사용하여 3d gaussian으로 reconstruction 해줍니다.( 위 figure에 나온 꽃병 그림을 예시로 들겠습니다.) 그 다음 Feature Splatting을 통해 CLIP, DINOv2, SAM과 같은 모델에서 얻은 semantic feature 들을 추가하고 최적화 해줍니다. 이렇게 만들어진 3D Gaussian들은 객체의 기하학적, 의미적 정보를 모두 포함하고 있게 됩니다. 이후 사용자가 자연어 query(꽃이 담긴 꽃병)를 던지면, CLIP정보를 바탕으로 해당 객체를 장면에서 찾아내게 됩니다. 이 과정에서 꽃병꽈 꽃을 더욱 세부적으로 객체를 물리적 특성으로 구분하게 됩니다. 즉, query 안에서도 꽃병과 같은 단단한 부분과, 꽃과 같은 유연한 부분을 별도로 인식하여 나누어주비낟. 이 과정을 자동으로 진행하고, 이후 MPM인 Taichi를 활용해 추가적인 augmentation을 진행할 수 있다고 합니다. 저절로 알고있는 물리적 특성을 등록해주지만, 원한다면 사용자의 추가적인 query를 통해 다른 특성을 부여할 수도 있습니;다.
추가적으로, 물리 시뮬레이션을 위해 필수적인 바닥이나 탁자와 같은 collision을 자동으로 탐지하는 방법을 제시했습니다. 저자는 이러한 collision surface를 찾기 위해 미리 정의된 일반적 단어 (바닥이나 테이블 같이 scene에서 땅을 담당하는 물체들)을 사용하여 장면의 CLIP feature과 비교하여 대응하는 가우시안을 자동 선태갛ㄴ다고 합니다. 선택된 가우시안 그룹에 대해 RANSAC을 적용하여 평면의 기하학적 형상을 추정하고, 이를 시뮬레이션에서 실제 충돌이 일어나는 표면으로 사용합니다. 특히 바닥 표면의 법선 벡터는 중력 방향으로 설정되어, 장면 내의 중력 방향까지 자동으로 결정한다고 합니다.
Taichi
또 일반적인 입자 기반 시뮬레이션 방법인 Material Point Method(MPM)을 직접 가우시안 중심점을 Point Cloud로 취급하여 적용하는 것은 이 방법으로는 시뮬레이션에 문제가 있다고 합니다. 기존의 연구에서도 이와 비슷한 문제가 보고된 바 있는데, 대표적으로 Xie 등은 표면 중심점만을 입자로 다루면 객체가 충돌 시 내부 지지력이 없어 쉽게 무너진다고 합니다. 이 문제를 해결하기 위해 저자들은 Taichi를 이용한 MPM을 활용한 새로운 물리 시뮬레이션 방법을 제안했습니다. MPM은 다양한 재질(강체, 탄성, 모래, 액체 등)을 현실적으로 표현할 수 있는 물리 시뮬레이션 방식이고, 본 논문에서는 기존의 point-based 접근에서 더 나아가 가우시안 표현이 제공하는 특수한 정보를 활용한다고 합니다. 가우시안이 가진opacity 와 공분산 정보들을 이용해 물리적 변형 중에도 정확하게 부피를 보존할 수 있다고 합니다.
이를 위한 첫 번째 핵심 아이디어는 Implicit Volume Preservation 기술입니다. 실제 이미지에서 얻은 객체는 대부분 표면의 정보만 포함하므로, 그대로 물리 시뮬레이션하면 쉽게 찌그러지거나 붕괴될 수 있기 떄문에 저자는 가우시안 표면의 공분산과 투명도를 사용하여 표면을 먼저 고밀도로 샘플링하고, 이렇게 얻어진 점들을 기반으로 객체 내부에 중심에서 표면까지 이어지는 투명한 point들을 추가로 채워 넣어주었다고 합니다. 이 내부의 투명한 입자들은 시각적으로는 보이지 않지만, 실제 시뮬레이션에서 내부 구조를 지지하여 형태가 유지되도록 도와준다고 합니다. (공이 땅에 닿아도 납작하게 찌그러지지 않고 형태가 유지되는 효과를 만들어 낼 수 있게 되는 느낌입니다)
둘째로, 객체 변형 중 발생하는 시각적인 결함을 줄이기 위해 가우시안의 회전을 더 정교하게 추정하는 방법을 제안합니다. Xie 등 기존 연구에서는 변형 기울기를 활용해 가우시안의 공분산 행렬을 갱신하는 방식을 시도했으나, 큰 변형이 발생하는 경우 충분한 성능을 내지 못했습니다. 논문의 저자들은 이를 해결하기 위해 주변 가우시안과의 관계를 활용한 새로운 방법을 제안했다고 합니다. 각 가우시안마다 가장 가까운 이웃 두 개의 가우시안을 찾아서 이들과 함께 구성한 평면의 법선 벡터를 추적하고, 이 법선 벡터가 회전하는 모습을 통해 각 가우시안의 정확한 회전 정보를 추정합니다. 결과적으로, 이 방법은 꽃줄기와 같이 크게 휘어지는 물체의 변형 과정에서도 부드럽고 자연스러운 움직임을 표현할 수 있으며, 기존 방식보다 결함이 훨씬 적게 나타난다고 합니다.
이렇게 저자는 input image를 통해 3D gaussian으로 scene reconstruction을 하고 언어적인 semantic feature를 가지고 있는채로 시뮬레이션 공간을 augmentation 할 수 있는 프레임워크를 제안했다고 합니다.
Experiment
실험에는 Deep Blending 데이터셋과 Mip-NeRF360 데이터셋이 활용됐고 카메라 파라미터와 sparse point cloud도 colmap을 사용하여 계산했다고 합니다. 아이폰 15 프로를 활용한 추가적인 데이터들도 포함시켰다고 합니다. 향후 연구를 위해 이 데이터셋도 공개한다고 하네요,, 물리적인 요소를 편집하는 scene editing의 경우 GT도 존재하지 않고 baseline도 없기 때문에 정성적인 평가를 주로 진행했다고 합니다.
Dynamic Scene Synthesis
Feature splatting을 통해 합성된 장면들의 정성적인 결과들입니다. 탄성이 있게 변형하거나 모래같은 입자, 부피 보존이 중요한 공같은 다양한 물리적 특성을 잘 반영하고 있고, 이러한 특성은 사용자가 제공한 text queyr를 기반으로 미리 정의된 재질 중에서 자동으로 선택된 물리적 특성이라고 합니다.

이렇게 재구성된 scene은 gaussian splatting 처럼 rasterization을 실시간으로 수행할 수 있기 때문에 일반적인 GPU환경(어느정도인지는 잘 모르겠습니다)에서 30fps정도의 성능을 보이고 스플래팅 파이프라인 자체는 계산된 궤적들만 있다면 최대 100 fps의 속도로 진행할 수 있다고 합니다.
Appearance and Geometry
앞서 scene augmentation의 예시로 들었던 object removal, scaling, rotation, translation이 잘 진행된것과 더불어 객체의 외형적인 편집도 간단하게 가능했닫고 합니다. 먼저 특징 스플래팅 기법을 이용하여 장면을 학습한 뒤, 선택된 가우시안 중심점의 SH (Spherical Harmonics, 구형 조화함수) 값만을 업데이트하여 객체의 외형을 바꿀 수 있다고 합니다. 이를 위해 렌더링된 이미지와 CLIP 텍스트 프롬프트로 얻은 feature 와 cosine loss를 사용했습니다. 예를 들어 “A photo of an <Adj> . flower” (Adj에는 형용사를 넣을 수 있습니다)와 같은 자연어 입력을 주면, 장면 내 꽃의 색상이나 스타일이 자연스럽게 수정되는 것을 아래 figure처럼 확인할 수 있습니다. 이렇게 외형을 편집할 때도 배경 부분은 그대로 유지되며, 2,500번 정도의 iteration만으로도 결과를 얻을 수 있다고 합니다.

Ablation
여러 모델을 동시에 사용하기 떄문에 정규화(multimodel regularization)의 효과를 검증했다고 합니다. 그림 (a)의 위쪽 이미지는 원본으로 렌더링된 RGB 이미지를 나타내며, 아래쪽 두 이미지는 feature map을 시각화한 것입니다. 단순히 CLIP 특징만 사용하면, 렌더링된 특징에 노이즈가 많습니다.

그림 (b)는 공분산의 rotation 기법을 비교한 ablation 입니다. b에서는 기존의 변형 기반 회전(deformation-based rotation) 기법과 논문에서 새롭게 제안한 법선 기반 회전(normal-based rotation) 기법을 비교했습니다. 두 방법 모두 작은 변형에서는 성능이 괜찮지만, 객체가 크게 변형되거나 많이 움직이는 경우 기존의 변형 기반 방식은 명확한 시각적 결함을 발생시킨다고 합니다. 뭔가 찌그러진 느낌을 볼 수 있습니다. 반면 주변 가우시안 입자들을 이용하여 normal vector를 계산하여 회전값을 추정하기 때문에, 큰 변형 상황에서도 훨씬 자연스럽고 부드러운 표현이 가능한 것을 볼 수 있습니다.
Conclusion
저자들은 객체 제거나 이동 후에 배경에 대한 인페인팅 처리가 이루어지지 않아서, 이러한 작업 후 배경에 이상한 모습이 발생할 수 있다고 합니다. 이는 기존 연구에서 상대적으로 단순하게 확장이 가능한 문제이나, 현재 구현에서는 인페인팅 기능이 포함되어 있지 않아 특정 상황에서 자연스럽지 못한 결과를 초래할 수 있다고 하는데, 생성형 모델을 사용해서 메꾸는건가? 싶습니다,,
안녕하세요 김영규 연구원님 좋은 리뷰 감사합니다.
처음 접하는 task라 흥미롭게 읽었습니다. 궁금한 점이 몇가지가 있는데 첫번째는 객체를 편집하는 과정에서 CLIP feature를 활용해 해당 객체와 관련된 Gaussian들을 선택한 후 전체 가우시간에서 제거한다고 했는데, 객체와 관련된 Gaussian을 판단하는 방법이 뭔가요? 의자와 크레인을 통한 정성적 결과에서 (b)Removal에서 의자의 그림자가 남아있는데, 의자 위의 공은 삭제되어서 어떤 기준으로 판단하는 지 궁금합니다.
두번째는 물리법칙을 위해서 투명한 내부 포인트를 채워 넣는 것으로 물리법칙을 표현하려고 한 것 같은데 물체의 강도?는 추가하는 포인트의 밀도로 구현하는 건가요? 마지막으로 질문은 아니고 리뷰 초반에 미분 가능하다는게 무슨 의미인지 잘 모르겠다고 언급해주셨는데 미분이 가능하다면 경사 하강법과 같은 최적화 알고리즘 적용이 가능하기 때문에 미분 가능하다는 것은 최적화할 수 있다와 같은 뜻으로 생각됩니다. 본문에서는 실제 이미지의 feature map을 GT삼아 객체를 표현하는 가우시안을 최적화할 수 있다 즉, 가우시안이 이미지의 특징을 표현할 수 있게 학습할 수 있다라는 의미인 것 같습니다.
감사합니다.