안녕하세요, 쉰 네번째 X-Review입니다. 이번 논문은 2025년도 TPAMI에 게재된 VimTS: A Unified Video and Image Text Spotter for Enhancing the Cross-domain Generalization 논문입니다. 바로 시작하도록 하겠습니다. ?⬛
1. Introduction
본 spotting 논문은 cross-domain에서의 spotting을 다루고 있는 논문입니다.
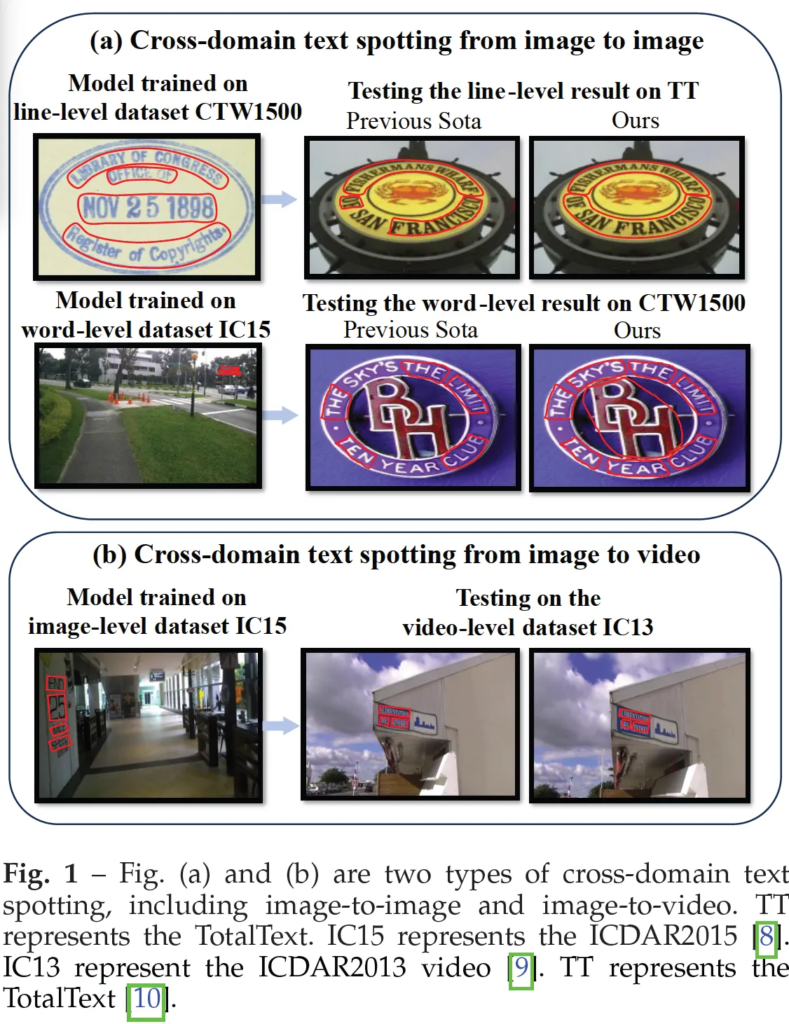
크게 이 논문에서 다루고 있는 cross-domain은 image-level과 video-lavel 시나리오로 각각 그림1의 a, b에서 확인할 수 있습니다. (a)는 Image-to-image에서의 cross domain으로 그림의 예로는 CTW1500데이터셋으로 학습하고 TT 데이터셋에서 테스트하는 식이죠. 반면 (b)의 image to video는 이미지 레벨에서 학습한 뒤 비디오 레벨에서 테스트 하는 식의 cross domain입니다.
Image-level에서의 cross domain spotting은 서로 다른 벤치마크 간의 다양한 스타일, 글꼴, 배경으로 인해 모델이 학습 데이터 외에서도 잘 일반화해야 한다는 어려움이 있습니다. 또, 추가적인 어려움으로는 데이터셋마다 서로 다른 어노테이션 형식을 사용한다는 점인데요. 예를 들어 위 Fig1-(a)를 보시면 위쪽은 line-level이라고 적혀있고 아래 IC15데이터셋에서 학습하는 부분에서는 word-level이라고 적혀 있습니다. 이렇게 라인 단위로 어노테이션이 되어 있는 경우와 단어 단위로 어노테이션이 되어있는 경우로 형식이 상이하기 때문에 이걸 동시에 통합해 학습하는 것은 어렵겠죠. 이런 형식 차이는 단순 학습 과정을 어렵게 하는 것뿐만 아니라, 모델이 서로 다른 어노테이션 방식에 적응하는데 어려움을 겪어 결국 성능 저하로 이어지게 됩니다.
또, video-level에서의 cross domain spotting은 정적인 영상에서 spotting 모델을 학습한 후, 이걸 단순히 비디오의 프레임별로 적용하면 간단하다고 생각되는데요.
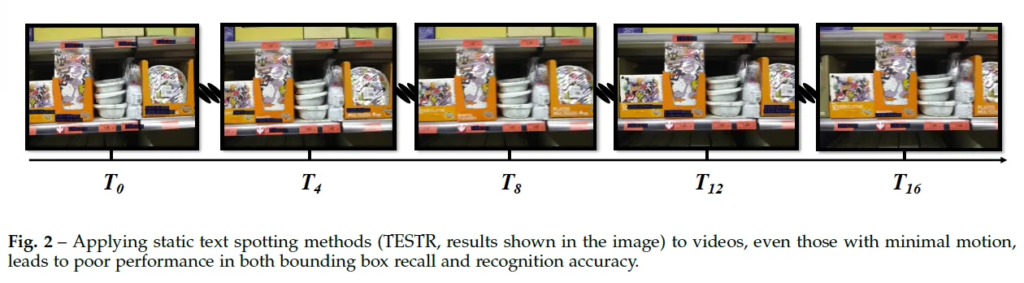
하지만 위 그림2에서 볼 수있듯이 static한 영상에 최적화된 모델들은 video 세팅에서 성능이 저하되고, 꽤 많은 텍스트를 검출하지 못하는 문제가 있다고 합니다. 이에 따라 비디오 세팅에서도 좋은 성능을 보이는 spotting모델이 필요하지만 video text data는 image보다 상대적으로 부족합니다. 본 저자는 video spotting에서도 static image에서 사전학습할 때 사용되는 데규모 데이터셋인 SynthText와 같은 합성 데이터가 필요하다고 주장하며 VTD-368k라고 하는 합성 비디오 텍스트 데이터셋을 제안합니다. 이 합성 데이터셋을 구축하는 방식에 대해 한 페이지 이상의 분량으로 설명되고 있으나,, 본 리뷰에서는 이 이상 언급하지 않겠습니다 , ,
다시 본론으로 돌아와 이 논문에서는 word-level과 line-level을 둘 다 다룰 수 있을 뿐만 아니라 video-level의 spotting까지 수행할 수 있는 VimTS 프레임워크를 제안합니다. 이 세 task를 모두 수행하는 VimTS는 서로 다른 task간의 시너지 효과를 활용하였으며, 특정 task에 대한 데이터가 부족한 경우에도 다른 task와 함께 최적화하는 방식으로 cross domain 성능을 향상시키고자 하였습니다.
특히, 서로 다른 task간의 시너지를 극대화하기 위해 두 가지 interaction 기법을 제안합니다. 첫 번째로 기존 text spotter 모델인 ESTextSpotter의 아이디어을 착안하였습니다. 이 ESTextSPotter은 DETR based spotter로 기존 query를 각각의 detection, recognition task 맞춤 query로 나눠 학습하는 구조를 취하였고, 이에 영감을 받아 본 VimTS는 detection과 recognition, tracking(비디오를 위한..) 쿼리로 나눠 학습함으로써 서로 다른 task들이 명시적으로 상호작여용할 수 있도록 하였습니다. 두 번째로는 word-level, line-level, video-level text spotting간의 상호작용을 가능하게 하는 Prompt Queries Generation Module(이하 PQGM)을 제안하였습니다. 또 추가로 Task-aware Adapter를 도입하여 각 task에 적잘한 feature를 선택하도록 하였습니다. 결과적으로 이 PQGM과 task-aware adapter를 사용한다면 기존 모델을 freeze해놓고 적은 수의 파라미터만을 추가하여 이미지와 비디오 spotting을 모두 처리할 수 있는 multi-task model이 되게 됩니다. 아래 method 단에서 이 VimTS의 구조에 대해 더 자세히 살펴보도록 하겠습니다.
2. Methodology
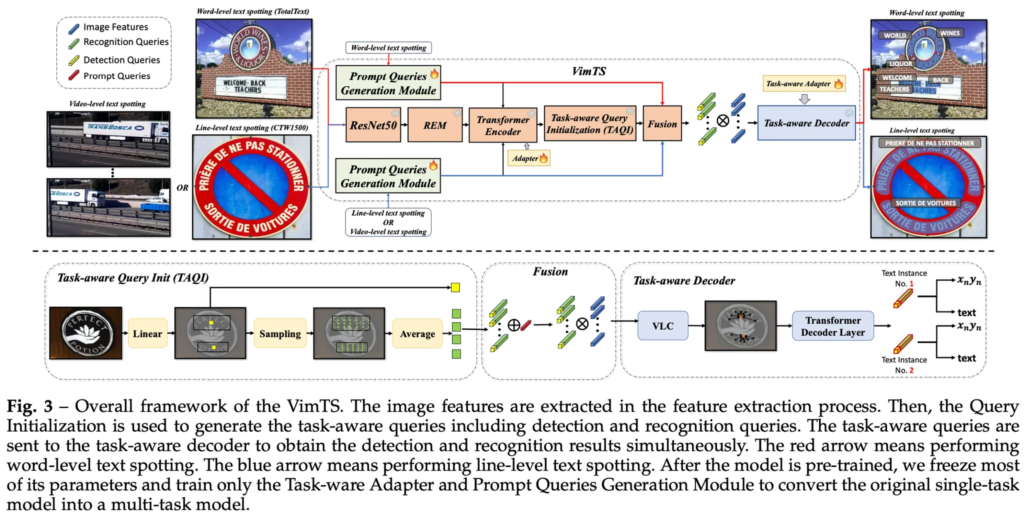
VimTS의 전체적인 구조는 그림3에 보이는 것과 같습니다. 이 VimTS 자체가 앞서 intro에서 짧게 언급했던 ESTextSpotter의 아이디어를 착안하여 제안된 모델인데요. 그림에서 보시는 블럭 대부분이 freeze 되어 있는 것을 확인할 수 있는데 이게 ESTextSpotter 모델으로 추정됩니다. 이 ESTextSPotter의 아이디어를 기반으로 VimTS도 다양한 task를 representation할 때 task-aware 쿼리를 사용하게 됩니다.
구조를 살펴보면 먼저 ResNet50과 REM(Receptive Enhancement Module), Transformer 인코더를 거쳐 feature를 추출하게 되구요 이 feature를 사용해 Task-aware Query Initialization 모듈에서 task별 쿼리를 생성하게 됩니다. 이 task 별 쿼리는 detection 쿼리, recognition 쿼리, tracking 쿼리에 해당하겠죠.
이렇게 생성된 task 별 쿼리는 다음으로 task-aware decoder(파랑 블럭)의 입력으로 들어가 text detection, recognition 및 tracking을 동시에 수행할 수 있도록 상호작용적이면서 각 task에 변별력 있는 feature를 학습하게 됩니다. 이때 초록 블럭인 Prompt Queries Generation Module(PQGM)과 노랑 블럭인 Task-ware Adapter를 활용해 word-level, line-level spotting 뿐만 아니라 video-level의 spotting task간의 상호작용을 가능하게 하는 것입니다.
구체적으로, 어떤 작업을 수행할건지에 대한 prompt(line level spotting 등등)를 PQGM에 입력으로 넣으면 PQGM이 prompt query를 생성하게 되고 이렇게 생성된 prompt query가 transformer 인코더와 task-aware decoder로 함께 들어가게 되어 모델이 이 task를 수행하도록 유도하는 것입니다.
이제 전체적인 동작과정을 살펴봤으니 세부적인 구조에 대해 아래에서 설명드리도록 하겠습니다.
2.1. Query Initialization
먼저 쿼리를 초기화하는 방식에 대해 말씀드리자면,, transformer encoder를 타고 나온 feature를 linear layer를 사용해 초기 bounding box 좌표와 그에 대한 확률을 뽑게 되고 이 확률을 기반으로 상위 N개의 초기 bounding box 좌표를 선택하게 됩니다. 그 다음 이 해당 N개의 bounding box 좌표 내에서 recognition query(보통 detr based 모델에서의 content query)와 detection query를 생성하게 됩니다.
2.2. Decoder
앞서 설명한 query 초기화 방식이나 decoder 같은 경우 모두 ESTextSpotter의 초기화 방식, 디코더를 그대로 사용하였습니다. Decoder는 크게 vision-language communication 모듈과 transformer decoder layer로 구성되어 있고 이때 detection, recognition, tracking과 관련된 여러 종류의 task-aware query를 입력으로 받게 됩니다.
먼저 detection과 recognition query는 vision-langauge communication module을 통해 서로 정보를 주고 받은 후, transformer decoder layer에서 intra-group self-attention과 inter-group self-attention을 수행하게 되고 이 때 inter-group self-attention은 detection recognition query간의 상호작용 뿐만 아니라 tracking query간의 correlation을 강화하는 역할도 합니다.
2.3. Prompt Queries Generation Module
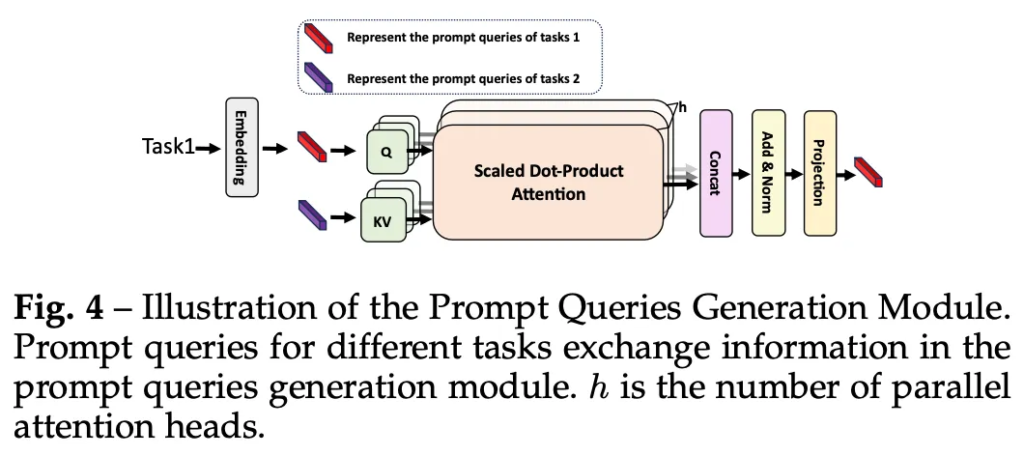
이제 저자가 제안한 모듈에 대해 하나씩 살펴보겠습니다. 먼저 Prompt Queries Generation Module입니다. 이 PQGM은 모델이 여러 task를 효과적으로 수행할 수 있도록 돕기 위해 제안된 모듈로 이 PQGM을 통해 prompt query를 생성하고 이를 활용하는 식입니다. 즉, PQGM은 우선 prompt query를 생성하는 모듈이다 라고 보면 되는 것이죠.
위 FIg4에서 볼 수 있듯이 특정 task에 대한 prompt를 먼저 PQGM의 입력으로 넣게 됩니다. 이때 prompt는 word-level text spotting이나 line-level text spotting 등이 될 수 있겠죠. 무튼 이렇게 task prompt를 입력하게 되면 먼저 embedding layer를 통해 이를 prompt query로 변환합니다. 이후 이렇게 생성된 prompt query는 다른 task query들과 attention을 통해 상호작용하게 되고 이후 feature extraction과정에서 추출된 feature(ResNet과 REM을 거쳐 뽑힌)와 합쳐져 transformer encoder로 들어가게 됩니다.
이때 prompt query가 task 별 feature를 학습할 수 있도록 transformer encoder 내에 adapter를 도입하였습니다. 또, 이 prompt query의 효과를 극대화하기 위해 query init단계에서 생성된 task-aware query들과 추가적으로 fusion하여 decoder로 들어가도록 함으로써 모델이 수행해야 할 task를 더 명확하게 유도하도록 설계하였습니다. 그림3에서도 PQGM을 통해 생성된 query들이 transformer encoder와 fusion단계에서 사용되는 것을 확인해볼 수 있습니다.
2.4. Task-aware Adapter
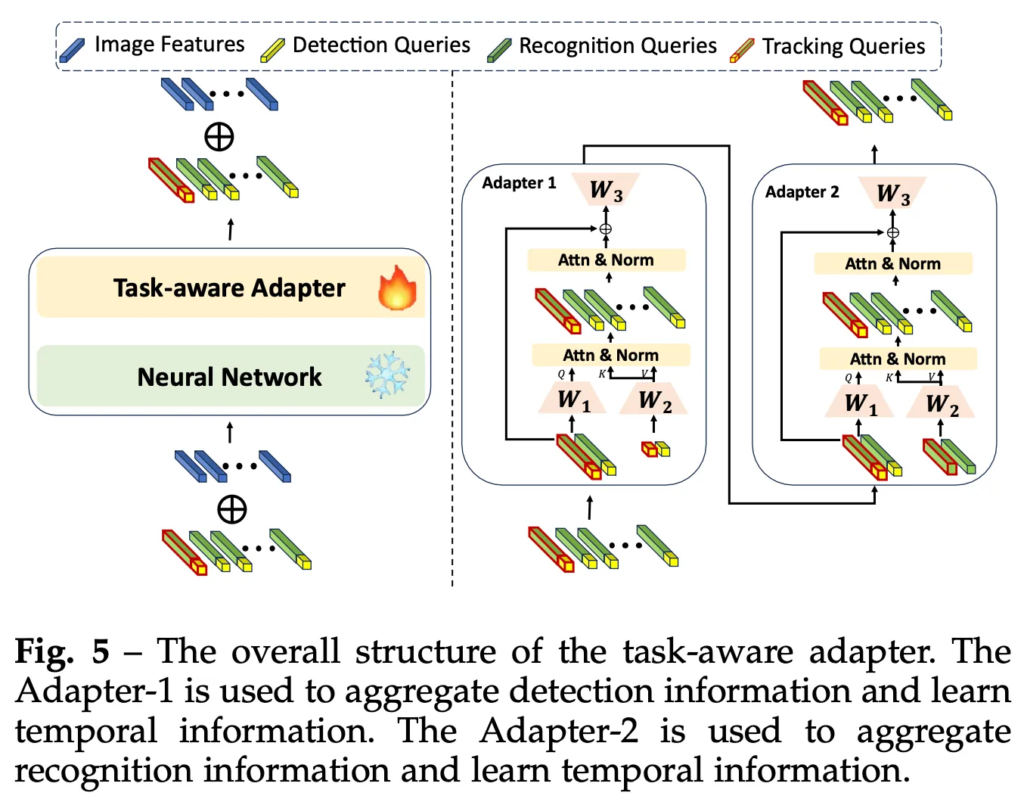
다음으로는 PQGM과 함께 기존의 단일 task만 수행하던 text spotting 모델을 multi task model로 확장하기 위해 설계된 task-aware adapter입니다. 이 adapter는 위 그림5에 전반적인 구조가 모사되어 있는데 보시면 adapter1, 2로 구성어 있습니다. 이중 adapter1은 detection 정보를 학습, adapter2는 recognition 정보를 학습하는데 사용됩니다. 이 adapter는 기존 transformer layer(freeze) 중간에 삽입하여 각 task에 적합한 feature를 학습하는 역할을 합니다. 이 adapter를 통해 image task 뿐만 아니라 video에서 temporal 정보를 효과적으로 학습하게 되는 것이죠.
2.5. Tracking Queries
앞서 짧게 이 VimTS는 detection query, recognition query 뿐만 아니라 tracking query를 도입해 image 뿐만 아니라 video level에서의 spotting을 수행가능하게 한다고 했었습니다.
구체적으로 tracking query에 대해 설명드리자면, 먼저 video의 첫 번째 frame에서는 detection과 recognition 쿼리만을 사용해 text instance를 검출하고 인식한 뒤 이를 decoder에 입력으로 넣어 feature를 aggregation하고 detection 및 recognition 결과를 동시에 decoding하게 되죠. Fig3아래 부분에 이 부분이 자세히 그려져 있습니다. 무튼 이렇게 생성된 query는 text의 content 정보와 location 정보를 포함하고 있을테고, 이후 frame에서는 tracking 쿼리를 사용해 동일한 text instance를 tracking하는 것입니다. 새로운 text가 등장하게 된다면 첫번째 frame에서 했던 것처럼 detection과 recognition 쿼리를 통해 검출 및 인식하게 되는 것이구요.
2.6. Optimization
마지막으로 Loss 설명하고 실험파트로 넘어가도록 하겠습니다. 이 VimTS는 DETR 기반 방법론인 ESTextSpotter를 기반으로 설계되었기 때문에 고정된 개수의 output을 gt와 매칭하는 set prediction 문제로 볼 수 있습니다. 즉, 아래 식1과 같이 헝가리안 알고리즘을 활용해 prediction과 gt 사이의 matching cost를 최소화하도록 설계되었죠.
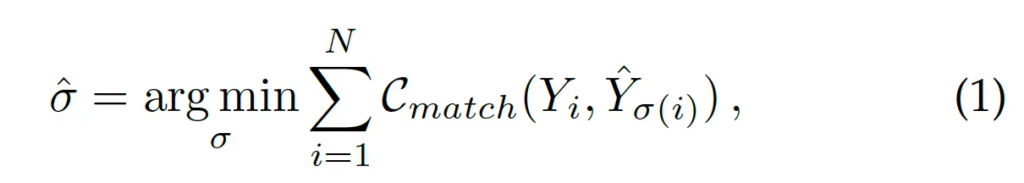
matching cost를 계산하는 식은 아래에서 살펴볼 수 있습니다.
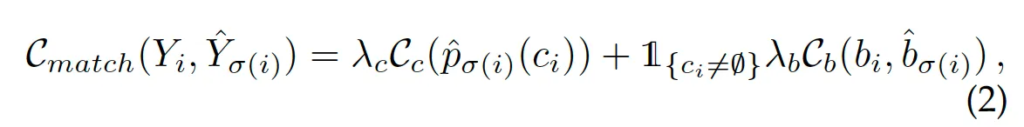
각각 classification과 bbox에 대한 matching cost를 가중합하여 계산됩니다.
이후 matching cost가 가장 작도록 gt와 prediction이 1:1 매칭되게 된 후 계산되는 최종 loss는 아래 식과 같습니다.
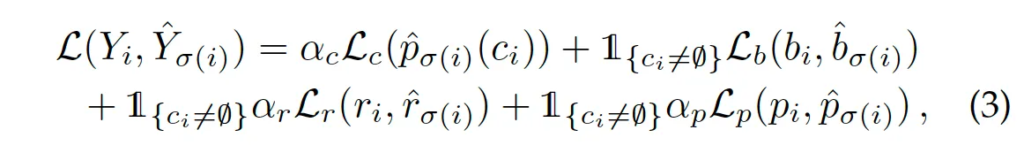
각각 classification, bbox, polygon, recognition loss를 가중합하고 있습니다. classification loss는 focal loss를 사용하고 있으며 bbox loss는 L1 loss + GIoU loss, polygon loss는 L1 loss, recognition loss는 CrossEntropy loss를 사용합니다.
3. Experiments on Image Text Spotting
실험은 크게 Image Text Spotting과 Video Text Spotting으로 나눠 수행되었습니다. 먼저 Image Text Spotting 실험들에 대해 살펴보도록 하겠습니다.
3.1. Comparison with State-of-the-arts Methods
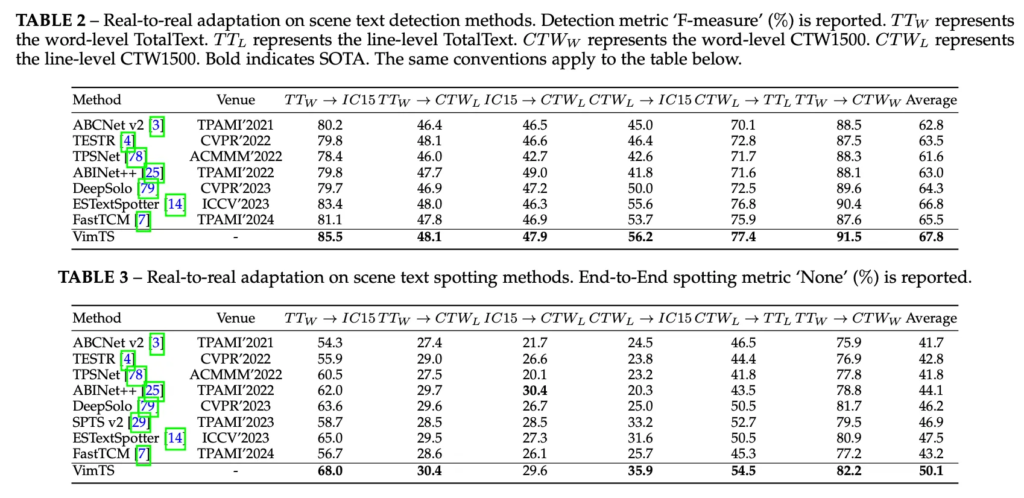
먼저 VimTS의 Cross-domain text spotting 성능을 평가하는 실험은 multi-oriented text 환경과 Arbitrarily-Shaped text 환경으로 나눠볼 수 있습니다. Arbitrary text는 curved된 text 등의 여러 shape을 갖는 text를 의미합니다.
실험은 위 표에서 살펴볼 수 있습니다. 먼저 multi-oriented 실험은 ICDAR2015 데이터셋에서 수행되었는데, 이때 word level 데이터셋인 tt에서 학습한 모델을 IC15에서 평가한 경우와 line-level 데이터셋인 CTW1500에서 학습한 모델을 IC15에서 test 한 경우 둘 다 리포팅 되어 있습니다. Table2는 detection 성능 table3은 spotting 성능을 담고 있습니다. 먼저 Tab2를 보면 TT로 학습한 경우 85.5% 성능을 보이며 base로 삼은 ESTextSpotter 모델(기존 sota) 보다 2% 높은 성능을 보입니다. 또 tabl3의 spotting 성능을 봤을 때도 전반적으로 sota를 달성하며 VimTS의 일반화 성능을 입증하고 있습니다.
3.2. Ablation Study
다음은 ablation study입니다.

서로 다른 format의 annotation을 포함하는 데이터셋을 함께사용하는 경우에 대한 실험입니다. VimTS에서는 이를 PQGM을 통해 여러 format에 대해 학습 중 시너지를 발휘하고자 했었는데요, 이 PQGM없이 word-level과 line-level spotting을 하나의 framework에서 그냥 통합하려고 하면 위 table4의 두번째 행에서 볼 수 있듯이 성능이 오히려 베이스라인보다 하락하는 (크게는 14%까지) 것을 확인할 수 있습니다.
이를 해결하기 위해 제안된 PQGM을 도입한 결과 없던 경우보다 5%부터 크게는 17%까지의 성능 향상을 보이고 있죠. (3행) 이런 결과를 보아 제안된 PQGM이 두 task간의 시너지를 향상한다는 점을 입증한다고 볼 수 있겠습니다. 또 기존 방식으로 모델을 특정 데이터셋에 fine-tuning하게 되면 맨 오른쪽에 보이는 것과 같이 3.5시간 정도가 소요되지만 PQGM과 task-aware adapter를 사용하여 일부 파라미터만 tuning할 경우 성능도 더 향상될 뿐 아니라 fine-tuning 시간을 140분 정도로 단축할 수 있습니다.
4. Experiments on Video Text Spotting
4.1. Zero-shot Transfer from Image to Video
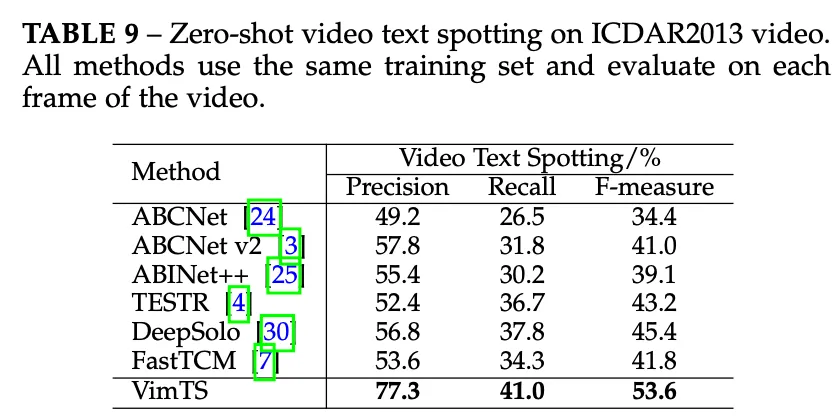
다음은 video에서의 실험을 살펴보도록 하겠습니다. 먼저 Image to video zero shot 성능평가 실험으로 IC13 이미지 데이터셋에서 학습하고 비디오셋으로 평가하였습니다. 위 표9를 보시면 VimTS는 F-measure 53.6% 정도의 성능을 보이며 기존 image기반 spotting sota 모델 대비 약 8% 더 높은 성능을 보이며 VimTS가 비디오 텍스트 spotting에서 좋은 일반화 성능을 보임을 시사합니다. 이외에 sota방법론들과 비교하는 실험이 존재하는데, image set에서와 마찬가지로 전부 sota를 달성하였습니다.
4.3. Visualization and Analysis
마지막으로 정성적 결과 살펴보고 마무리하도록 하겠습니다.

위 그림은 VimTS의 zero shot을 기존 sota 모델인 TransDETR(video model)과 TESTR(image model)과 비교한 결과를 보이고 있습니다. 보시면 반사가 심하거나 흐릿한 text가 있는 경우의 결과를 보이고 있는데 두번째 행의 TransDETR은 이런 환경에서 모든 text를 정확하게 검출 및 인식하지 못하고 있지만 마지막 행의 VimTS는 모든 text를 정확하게 검출 인식 및 tracing하고 있습니다. 이는 TransDETR이 연속된 frame간의 detection 정보만 활용하는 모델인 반면에 VimTS는 detection 정보 뿐만 아니라 contextual 정보까지 활용해 detection, recognition, tracing 성능을 향상시켰기 때문입니다. 또, 맨 윗 행의 TESTR과 비교해보았을 때도 VimTS가 더 정확한 결과를 보이고 있습니다.

추가적으로 prompt query가 실제로 task별 feature를 잘 학습하는지 확인하기 위해 prompt query별 image feature에 대한 attention map을 확인해보았습니다.
위 Fig10을 보시면 word-level query를 사용했을 때 (b) attention map은 개별 word feature에 attention하고 있는데요. TOWNE와 MANOR를 개별적으로 잘 인식하고 있습니다.
반면에 line-level 쿼리를 사용했을 경우에는 (c) TOWNE과 MANOR를 하나의 연속적인 text line으로 묶어 처리하는 것을 확인할 수 있죠. 이를 통해 VimTS가 prompt query를 사용해 서로 다른 task의 feature를 효과적으로 학습할 수 있음을 직관적으로 확인할 수 있습니다.
안녕하세요, 좋은 리뷰 감사합니다.
Fig3에서 Task-aware Decoder 부분에 있는 VLC는 vision-language communication 모듈인건가요? 이 VLC가 어떤 구조로 되어 있고 무슨 역할을 하는지 궁금합니다. 그리고 모델이 multi-task learning을 하는 것으로 이해했는데 이때 word-level text spotting은 항상 고정으로 training하는 것이고 line과 video 둘 중 택1하여 학습하는 것인가요?
감사합니다.
1. 넵 VLC는 vision-language communication 모듈입니다. VLC는 decoder 첫 단계로써, detection recognition tracking query간의 cross-task interaction을 수행하는데요. 구체적으로 각 task로 intra group sefl attn을 수행한 후 task간 inter group self attn을 수행하게 됩니다.
2. 아뇨. VimTS는 항상 Word, Line, Video 모두 학습할 수 있도록 설계되어 있습니다. 학습할 때 각 task에 해당하는 prompt query를 넣어 해당 task만 selective하게 학습하는 것이라고 생각하시면 됩니다.