오늘 소개 드릴 논문은 제목에서와 같이 Diversity(다양성)와 Representative(대표성)를 동시에 고려하는 고가치 데이터 선별 방법에 관한 논문입니다. 두 지표는 Coresets[arxiv]과 같은 기존 Active Learning 연구에서 자주 등장했던 데이터 가치 산출의 기준이기 때문에 익숙하실 것 같은데요, 이러한 기존 연구와 해당 연구의 차이점과 인사이트가 무엇인지 내용을 통해 소개해보겠습니다. 그럼 리뷰를 시작합니다.
사전지식
# “다양성”, “대표성”기반의 데이터 가치 평가: “다양성”과 “대표성” 기반의 가치 산출은 전체 데이터의 분포를 고려하여 데이터의 가치를 산출하는 방법으로, 전체 데이터(모집단)의 분포를 잘 표현하는 subsets(표본집단)을 선별하는 것이 해당 지표를 기반한 고가치 데이터 선별의 목적이다.
전체적인 Active Learning의 가치 산출 방법 체계를 정리하면 아래와 같다:
Active Learning
├─불확실성 기반 Active Learning (uncertainty based active learning)
└─ 분포 기반 Active Learning (diversity based active learning)
├─ 다양성 기반 선별
└─ 대표성 높은 데이터 우선 선별
기존 연구와의 차별점
기존 연구 키워드: #Semi-supervised Learning(SSL) #Active Learning
논문에서 말하길, 기존 Semi-Supervised Learning(SSL) 연구에서는 데이터 선별을 통해 학습 효율성을 개선하는 고려가 충분하지 않았다고 한다. 한편, 학습 효율 개선을 위해 데이터 선별을 활용하는 Active Learning 연구 중 지도학습에서 SSL로 확장하려는 시도가 존재하지만, 해당 논문은 SSL에 데이터 선별 기법을 적용함에 있어서 기존 Active Learning 프로세스를 따르지 않고자 하는데, 이는 기존 Active Learning 프로세스에 포함된 다음의 두 가지 비효율적 측면을 해소하기 위함이다: (1) 모델의 초기 학습을 위해 Random sampling된 데이터로 학습하는 과정이 필요함 (2) k번의 주기를 반복하여 업데이트 하며, 매 업데이트 마다 고가치 데이터로 산출된 데이터의 라벨링이 요구됨.
정리하면, 본 논문은 SSL의 세팅에서 데이터 선별을 통해 학습의 효율성을 개선하고자 하였고, 데이터 선별을 다루는 기존 연구와 다르게 학습 효율을 최대화 하기 위해 주기 학습을 활용하지 않고 데이터를 한번에 샘플링하여 학습의 효율성을 높이고자 하는 목적에 맞는 새로운 프로세스를 제시했다.
논문의 문제 정의 (소개)
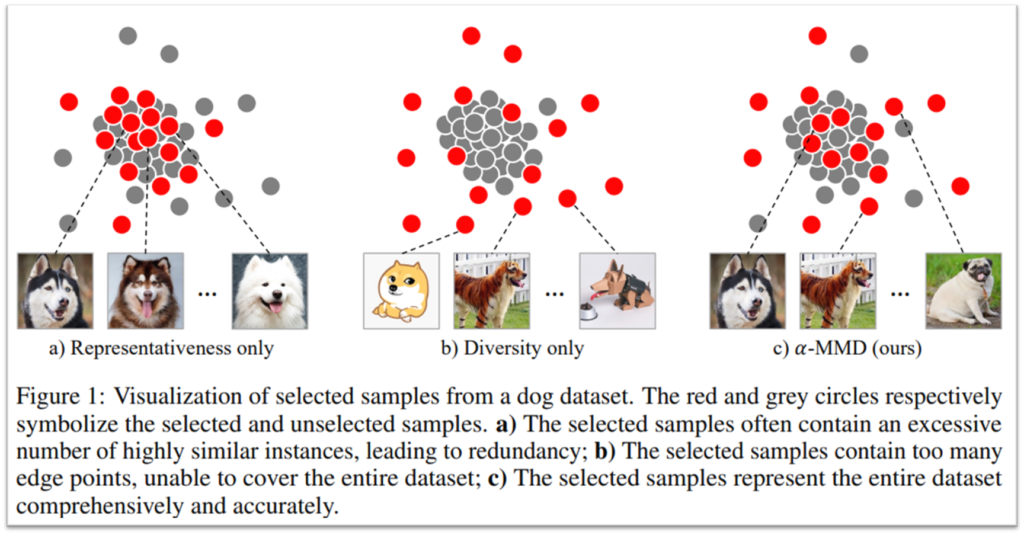
논문은 데이터 선별 방법은 대표성(Representaivness)과 다양성(Diversity)를 모두 고려하여 학습에 활용할 표본 집단을 선별하는 최적하된 방법을 제시하고자 한다. 여기서 대표성과 다양성을 모두 고려해야하는 이유는 Figure1과 같다. 학습 데이터(선별된 표본집단)가 높은 대표성을 지닌 샘플로만 구성될 경우(Figure1, a의 붉은 점)대표성이 낮은 주변 데이터에 대한 특징 값을 학습하지 못해, 모델의 성능이 제한적이다. 한편 다양성 높은 샘플로만 표본집단이 구성될 경우(Figure1, b의 붉은 점) 샘플간의 일관된 정보가 적어, 모델의 학습에 난항을 겪을 수 있다.
본 논문은 전체 데이터에 비해 소량의 표본 집단에서 대표성과 다양성 간의 상충 관계(trade-off)의 균형을 위해 파라미터 α를 도입하고 최적의 α를 구하기 위한 최적화 수식 α-MMD(Alpha Maximum Mean Discrepancy)를 정의한다. 다음으로 샘플 선택 알고리즘인 Generalized Kernel Herding without Replacement(GKHR)를 통해, α-MMD를 최소화하는 표본 집단을 선별하도록 하여, SSL의 학습 효율을 높이는 최적화된 학습 데이터를 선별하는 방법인 Representative and Diversity Sample Selection(RDSS)를 제시했다.
방법론
앞서서 정리하였다시피 제안된 데이터 선별 방법론인 RDSS는 2 단계로 구성된다: (1) α-MMD를 통해 대표성과 다양성을 정량화, 수식화. (2) GKHR을 통해 α-MMD를 최적화하여 모집단(전체 데이터)에서 표본 집단을 선별. 각 방법을 이어서 소개하면 아래와 같다.
- α-MMD (Alpha Maximum Mean Discrepancy)

α-MMD는 대표성(Rep, Representative)과 다양성(Div, Diverse)의 상충 관계를 다루기 위한 파라미터 α를 변수화하기 위한 관계식이다. 두 요소(대표성, 다양성)를 포함한 관계식을 설계하기 위해서는 문제의 최종 목적을 확인해야하는데 이는 [발췌1]과 같다: 논문의 최종 목적은 대표성을 최대화하고 다양성도 최대화 할 수 있는 표본 집단 I_m을 찾는것이다.
즉, 대표성(Rep)과 다양성(Div)을 정량화 하는 수식이 존재한다면, 목적함수(Rep + λ*Div)를 설정할 수 있고, 해당 목적함수를 최적화하는 표본 집단 I_m을 찾으면, 논문이 찾고자 하는 최적의 학습 데이터 설계를 할 수 있다.
본 논문은 대표성의 정량화를 위해 MMD라는 기존 거리 산출 방법(arxiv, 2006)을, 다양성의 정량화를 위해 일반적인 벡터간의 내적값 기반의 유사도 측정 방법인 kernel method를 사용했으며, 아래와 같이 최종 목적함수를 정의하였다.

- GKHR (Generalized Kernel Herding without Replacement)
해당 샘플링 알고리즘은 기존의 Kernel Herding 샘플링 알고리즘을 기반으로 수정된 것으로, 차이점은 subsets을 선택할 때, 중복 없이 선별하며, 최적화 수식으로 제안한 α-MMD을 사용한데 있다.
해당 GKHR의 알고리즘은 아래와 같다: (상) 알고리즘 / (하) α-MMD 수식

위 [알고리즘1]을 보면 샘플을 m개 만큼 순차적으로 선별하며, 정의된 α-MMD 수식을 최적화 하는 샘플을 선정한다. 매 선정마다 데이터 다양성 산축식인 S와 대표성 산출식인 µ를 업데이트하여 선별 과정을 m번 반복한다.
실험
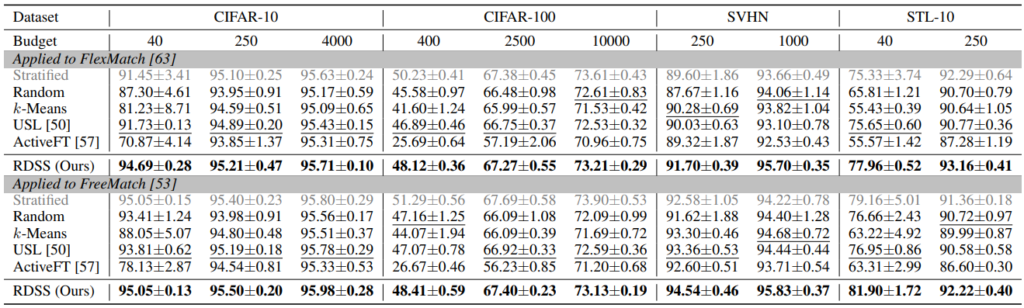
저자들은 제안하는 방법의 효과를 보이기위해, 기존 데이터 sampling method와 성능을 비교하였다. 이때 비교 방법론은 Active Learning 방법이 아닌, 분포등을 고려한 데이터 선별 전략과 비교하였음며, SSL을 위한 학습 방법론은 Flexmatch와 Freematch 를 적용하였다. 논문은 다양한 기존 데이터 선별 방법과 제안 방법의 성능을 비교하였으며, 결과는 아래와 같다.
- 기존 1주기 데이터 선별 방법과 비교
논문은 가장 먼저, 한번에(1주기) 학습 데이터를 선별할 때 사용할 수 있는 기존 방법들과 제안 방법을 비교하였다. Random과 k-means는 모집단을 대표하는 표본 집단을 구축할때 기본적으로 사용되는 방법이며, USL(paper)과 ActiveFT(paper)는 데이터 선별 방법의 SOTA 방법론이다. 해당 접근법을 간단하게 설명하자면, 예를 들어 ActiveFT는 Finetuning시에 최적화된 학습데이터를 구축하기 위해, Active Learning 연구를 접목하여 고가치 데이터를 1 주기만 선별하는 방법이다.
실험은 CIFAR-10, CIFAR-100, SVHN, STL-10 에 대해 적용하였으며 두 SSL 방법론에서 제안하는 방법(RDSS)가 전반적으로 우수한 성능을 보이며 SSL에서 RDSS가 일관성있게 효과적임을 보였다.
- Active Learning과 같은 반복 주기 데이터 선별 방법을 비교
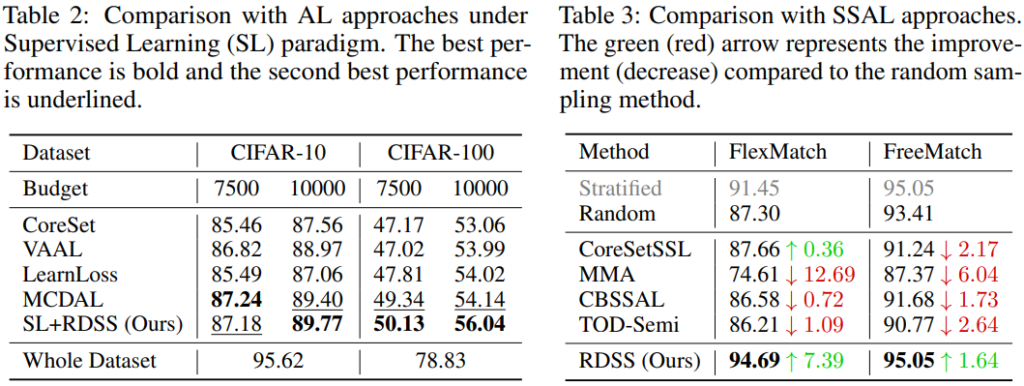
다음은 기존 다양성과 대표성 등 학습 효율이 좋은 데이터를 활발하게 다룬 Active Learning 분야의 데이터 선별 방법론과의 비교이다. 제안 방법과 가장 유사 방법론인 1주기 데이터 선별 방법 연구가 많지 않아, 해당 비교를 진행한 것 같다.
먼저 아래의 Table2는 지도학습(SL)을 위한 잘 알고있는 기존 Active Learning 방법과 제안 방법을 비교한 결과이며, 제안한 방법론이 전체 세팅에서 전반적으로 우수한 성능을 보임을 확인할 수 있다.
다음으로 Table3는 동일 세팅인 SSL을 위한 Active Learning 방법론 연구들과 제안 방법을 비교하였는데, 이때에도 제안 방법론이 전반적으로 우수함을 확인할 수 있다. (이는 CIFAR-10에서 실험되었다.)
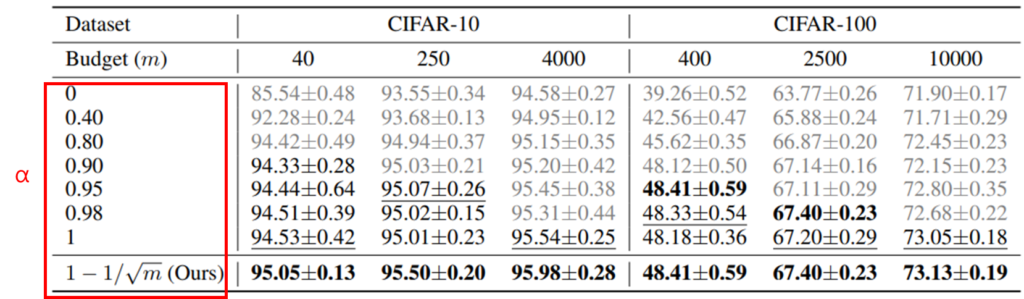
- Ablation Study: the power of parameter α
마지막으로 제안하는 상충 관계 완화 파라미터인 α의 효과를 아래의 실험으로 검증하였다. 기존 연구와 같이 α를 고정된 파라미터로 설정하는 것 보다 제안하는 선별 데이터의 갯수(m)기반으로 세팅되는 변동성 있는 파라미터를 활용하는 것이 효과적임을 보였다. 실험은 SSL 방법론인 Freematch를 기반으로 진행되었으며, CIFAR-10/CIFAR-1000의 다양한 예산(budget, m) 세팅을 고려할 때, 제안 방법론이 일관적으로 우수함을 보인다.
어떠한 데이터가 모델 학습에 효율적인가를 고려할 때, 일반적인 결정론적 딥러닝 모델을 위한 Active Learning에서는 얼마나 모델이 해당 데이터를 어려워하는지를 기준으로 가치를 산출하였고, Bayesian Active Learning 방법에서는 Epistemic uncertainty를 기반으로 가치를 산출하고자 했다. 해당 논문은 소량의 데이터 세팅에서 Semi-Supervised Learning에 효과적인 데이터를 선별하는 방법을 다루었다. 해당 논문을 통해 데이터의 가치를 산출할 때, 단순히 모델의 상태 뿐 만 아니라 budget의 세팅, 학습 방법 등 다양한 점을 고려해야함을 다시한번 상기할 수 있었다. 제안된 방법은 수식으로 정의되어 다양성과 대표성을 고려한 샘플에 대한 직관적인 인사이트를 얻어내기엔 어려웠으나, 수식적으로 증명 가능한 방법론이라는 점이 매력적이다.
황유진 연구원님. 좋은 리뷰 감사합니다. 오랜만에 Active Learning 리뷰네요.
다양성/대표성 기반 방법론이며 특히 기존의 당연한 AL 세팅인 cycle을 활용하지 않았다는 점이 눈에 띕니다. 간단한 질문 남기도록 하겠습니다
대표성과 다양성의 trade-off를 잘 조절하는 알고리즘에서, 대표성의 MMD에서는 샘플링한 표본 데이터의 분포와 전체 데이터의 분포를 측정하여 이 두 분포가 유사하면 표본 데이터가 전체 데이터에 대한 분포성을 띄는 것으로 이해하였으며, S에서 선별한 표본 분포 내 샘플들의 유사도 평균이 작아지는 것을 기준으로 다양성을 측정하는 것으로 이해하였습니다. 이 때, 샘플들 간 유사도 평균은 어떻게 계산하는지 궁금합니다. 유사도 계산 방법 자체도 궁금한데, 모든 샘플들 간 유사도를 계산하면 연산량이 매우 커질 것 같아서 어떻게 수행되는지 궁금합니다.
또한, 해당 방법론 또한 기존의 AL 방법론들처럼 cycle을 돌리며 annotation을 추가하는 시나리오를 구상할 수 있을 것 같은데, 그렇게 하면 더 좋은 결과를 얻을 수 있지 않을까.. 하는 개인적인 생각이 들어 황유진 연구원님의 의견을 듣고 싶습니다.
감사합니다.
안녕하세요 허재연 연구원님 댓글 감사합니다.
우선 본 논문은 Active Learning 연구는 아닌점을 말씀드립니다. 본 논문은 SSL 학습 효율 개선을 위한 데이터 선별 방법이며, 기존 Active Learning 과 교집합은 있지만 동일하게 분류되기는 어렵다고 판단됩니다.
또한 본 논문은 다양성 높은 데이터 선별을 위해 kernel method 기반의 유사도 측정을 하였으며 특히 본 논문에서는 Gaussian kernel function을 활용했습니다.
마지막으로 본 연구에 cyclic 학습은 성능 개선이라는 장점도 있지만, 모델 기반의 데이터 선별 방법은 해석 불가능한 부분이 많으며, 학습 시간도 많이 소요됩니다. 또한, 본 논문이 주장하는 SSL을 위해서 최적의 초기 데이터 구성이 중요하다 를 보이기 위해서는 필수적인 실험이 아니였기에 저는 추가하지 않아도 된다고 생각합니다.
감사합니다.