안녕하세요. 이번 리뷰도 태스크별 대규모 로봇-액션 데이터를 이용한 학습이나, 환경 모델에 기반한 강화학습없이, VLM+LVM 를 활용하여 free form language instruction이 들어왔을 때 python action code generation 기반의 Robot Manipulation을 보이기 위한 연구입니다. 제목에서도 언급되는 것처럼, 시공간적 추론을 하는 데 있어서 keypoint 가 활용되는 것을 눈치챌 수 있는데 과연 이것들을 어떻게 활용해먹었는가 한번 살펴보도록 하겠습니다.
들어가기에 앞서, 우선 저는 몇 주전 KRoC 2025에서 서베이 논문 포스터발표를 하고 왔습니다. 해당 서베이 논문의 주제와 동일하게 저의 현재의 관심연구분야는 “LLM 및 VLM 기반 로봇 매니퓰레이션 제어 정책 연구” 입니다. 근데 이 ReKep 논문,, Wenlong Huang 이라는 분이 1저자이신데 심상치 않습니다. 위에 이 분 개인 홈페이지를 들어가보시면 더 자세히 알 수 있는데, 제가 서베이논문에 담았던 그 굵직한 랜드마크같은 논문들(Code as Policies, VoxPoser, Inner Monologue 등)에도 1저자를 담당하던 핵심인물이었습니다. 이 분야에 있어 한 획을 그을 것 같은데 좀 유심히 지켜봐야될 것 같습니다. 잡설이 좀 길어졌습니다. 논문 리뷰하도록 하겠습니다.
1. Introduction
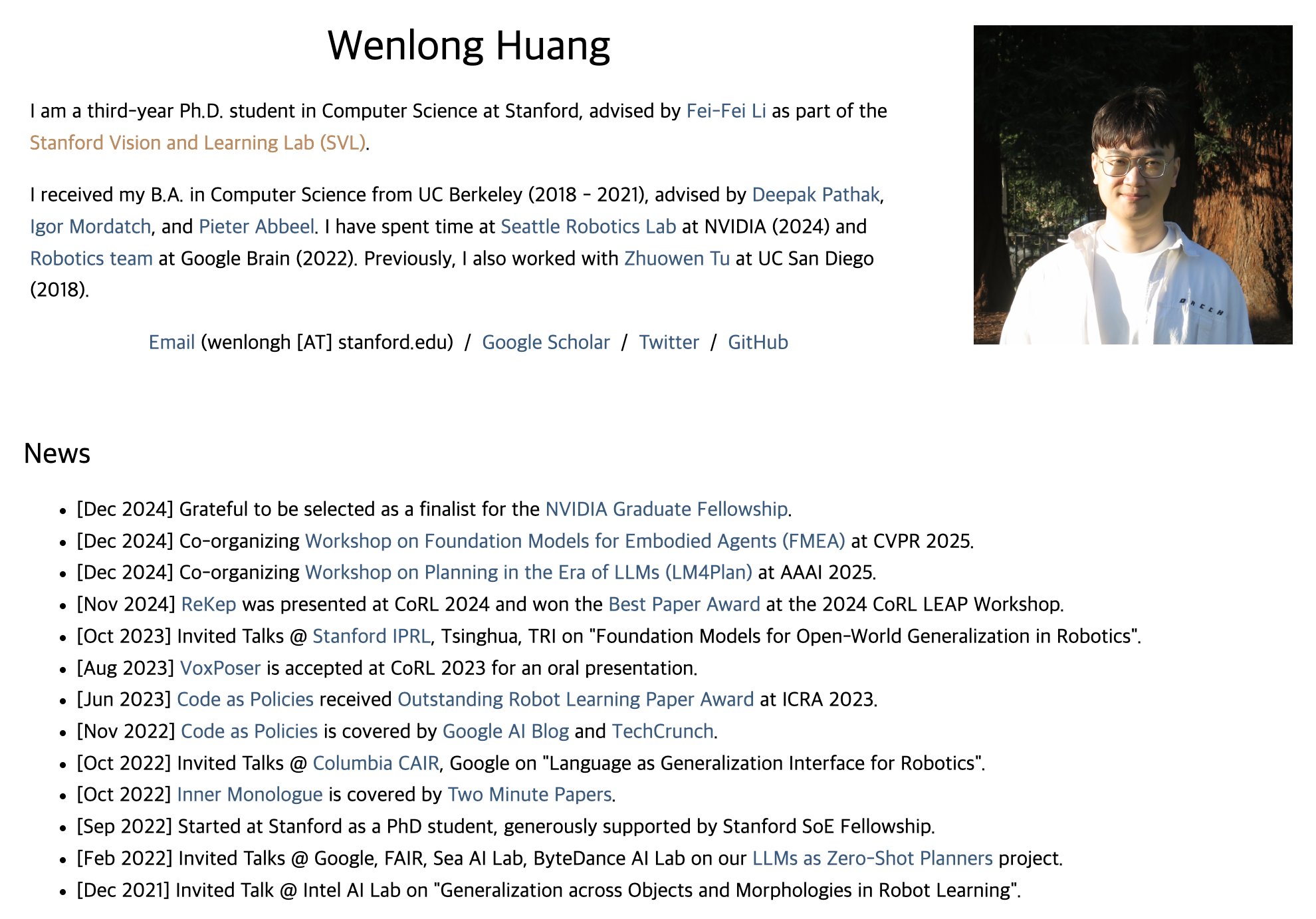
Robot Manipulation은 작업 환경 내의 물체와 복잡한 상호작용이 기본적으로 수반됩니다. 이를 다시 말하면 작업 시에 공간적-시간적 제약을 꽤나 고려해야 된다는 것이죠. 위의 Figure 1처럼 컵에 차를 따르는 작업을 예시로 설명해보겠습니다. 1. 주전자 손잡이를 잡는다.(grasping) 2. 주전자 이동할 때 수평을 유지한다.(carrying) 3. 주전자 주둥이와 따라야 할 컵에 대해 수직 align을 맞춘다.(aligning) 4. 적절한 각도로 기울여 붓는다.(pouring) 의 sub-task로 나뉠 수 있겠는데요. 이런 하위 목표 하나하나는 공간적 위치 관계 뿐만 아니라, 동작의 순서와 타이밍 같은 시간적 요소도 함께 고려되어야 하기 때문에 공간적-시간적 제약이라고 할 수 있는 것입니다.
하지만 다양한 real-time manipulation 작업에 있어 이런 제약 조건을 효과적으로 통제하며 어떤 하나의 규율 내지는 정책으로써 통일시켜 만들어내기란 어려움이 있었습니다. 기존 접근법들은 로봇-객체 간 상대적 pose 기반 접근법, data-driven 접근법 등이 있었는데요. 둘 다 한계가 있었습니다.
먼저 로봇과 물체 간 상대 pose(위치, 방향)를 통해 제약 조건을 정의하는 접근법은 꽤나 직접적이고 널리 사용되어왔으나, rigid-body transformation은 세밀한 기하학적 특징(물체 세부 디테일, 변형 가능성) 등을 놓치기 쉽고, 사전에 객체 CAD모델 등이 있어야 하고, 비정형물체(옷, 음식재료 등)에는 적용하기가 쉽지 않았습니다.
data-driven 접근법은 visual space 내에서 제약을 학습하게 하여 더 유연하고 적응적으로 동작할 수 있겠으나, 다양한 객체, 다양한 작업들 각각에 맞게 제약 조건을 효율적으로 수집하기란 쉽지 않습니다. 객체 종류와 작업의 수가 늘어날 수록 학습해야 할 제약조건 데이터는 기하급수적으로 증가하게 되죠.
결국 저자들은 다음과 같은 3가지 요구 사항을 만족하는 제약 표현 방법이 필요하다고 생각합니다.
- multi-stage, in-the-wild, bimanual, reactive 동작 같은 다양한 작업에 적응할 수 있고,
- Foundation Model의 발전을 통해 완전 자동화의 가능성을 지니면서,
- Off-the-shelf solver로도 효율적으로 풀 수 있어 복잡한 manipulation 동작을 real-time optimizable하게 만들자. 입니다.
그래서 ReKep(Relational Keypoint Constraints)을 제시하는데, 제약으로써 python 함수 형태로 표현하고, 이 함수는 한 집합의 keypoint들을 입력받아서 수치화된 어떤 cost값을 출력하도록 합니다. 각 keypoint는 scene 내에서 작업별로 의미가 부여된(semantically meaningful) 3차원 좌표로써 표현됩니다. 여기서 하나의 함수는 nonlinear한 산술 연산들을 통해 keypoint들 간의 어떠한 relation을 인코딩하게 되고, 이 keypoint들은 로봇 팔, 물체의 특정 부위(affordance라고 할 수 있겠죠?), 혹은 다른 에이전트(다른 로봇팔이나 사람 팔) 등 서로 다른 entity들을 표현하게 됩니다. 각 keypoint는 월드 자표계에서 3D Cartesian 좌표로만 구성되지만, 여러 keypoint들 간의 rigidity를 유지하면(두 개 이상의 점을 서로 고정된 거리나 상대적인 배치로써 묶어주면), 선, 면, 3D rotation(회전축이나 각도) 같은 요소로도 구체화할 수 있다고 합니다. 즉 점이 여러개 모이면 선을 이루고 면을 이루듯이, 단순한 3차원 위치 뿐만 아니라 좀 더 복잡한 기하학적 특징을 표현해 낼 수 있게 되는 것이죠.
기존 연구에서의 어떤 키포인트 제약은 수작업 정의 기반이었습니다.(kPAM, 해당 방법론은 제가 몇 주전 리뷰한 또 다른 키포인트 기반의 MOKA라는 방법론에서도 활용했던 기법입니다.) 하지만 ReKep은 LVM(DINOv2), VLM(GPT-4)에 의해 이런 키포인트 제약을 자동화될 수 있게 만들었습니다. RGBD 인풋과 free-form instruction으로부터 scene 내의 의미 있고 세밀한 keypoint를 제안해낼 수 있도록 LVM을 사용하고, 이렇게 제안된 keypoint가 오버레이된 시각 정보를 바탕으로 VLM(GPT-4)을 이용해서 파이썬 함수 형태의 제약을 작성토록 합니다. 이 부분에서는 어떻게 보면 키포인트를 활용한다는 컨셉에서는 MOKA와 유사하고, 결국 code generation을 활용한다는 점에선 Code as Policies, Voxposer의 컨셉과 유사하다고 볼 수 있을 것 같습니다. 최종적으로는 생성된 코드 기반 제약을 바탕으로, 추적된 keypoint 정보를 반복적으로 평가하면서, off-the-shelf solver(별도의 맞춤형 알고리즘이 아닌 오픈소스 최적화 라이브러리 사용, 여기선 Scipy에서 제공하는 Dual Annealing과 SLSQP(Sequential Least Squares Programming) 알고리즘)를 이용해 로봇 동작을 도출할 수 있게 되는 것입니다.
이 큰 파이프라인을 정리하면, 먼저 전체작업을 여러 sub-task로 나누고, 각 단계의 목표를 달성하기 위한 일련의 waypoints를 계산 -> 이 waypoints는 로봇 end-effector의 3D pose -> 각 sub-goal에선 receding-horizon control 문제를 해결하고 -> 이는 짧은 time horizon 내에서 최적의 행동 시퀀스를 계획하고, 이를 계속 갱신하며 실행하는 방식 -> 이런 최적화 문제를 적절히 설정하면 최종적으로 약 10Hz 주기로 재계산하며 동작. 이라고 표현할 수 있겠습니다.
Contribution은 다음과 같았습니다.
1) Relational Keypoint Constraints를 통해 매니퓰레이션 작업을 계층적 최적화 문제로 수립합니다.
2) 대형 비전 모델과 비전-언어 모델을 사용하여 keypoint와 제약을 자동으로 지정하는 파이프라인을 고안합니다.
3) 실제 로봇 플랫폼(바퀴 달린 단일 팔 로봇과 고정된 이중 팔 로봇)에 대한 시스템 구현을 제시하며, 자유형 언어 지시와 RGB-D 관찰만으로 다단계, 자연환경(in-the-wild), 양손(bimanual), 반응형(reactive) 작업을 포함한 다양한 매니퓰레이션 작업을 수행함을 보입니다. 이는 작업별 데이터, 고차원 제약조건, 환경 모델을 전혀 사용하지 않고도 가능하다는 점을 보여줍니다.
2. Related Works
<Structural Representations for Manipulation>
구조적 표현이라함은, 어떤 모듈들의 구성 방식이라고 할 수 있겠습니다. 그간 연구들에서 이 구조적 표현의 종류들은 다음과 같았습니다. 먼저 Rigid-body pose가 있고, Data-driven 방식이 있습니다. Rigit-body pose 의 장점은 자유 공간에서 강체의 운동에 대한 풍부한 이해와 물체 간의 장거리 의존성을 모델링하는 데 효율적라는 것입니다. 그래서 널리쓰여왔습니다. 하지만 환경 기하학과 동역학을 사전에 모델링해야되고, 비정형물체는 다루기 어렵다는 문제가 있었습니다. Data-driven 방식 중에는 object-centric 표현, particle-based 동역학 표현, keypoint / descriptor 표현 등이 있었습니다. 이 중 keypoint 방식이 해석 용이성, 효율성, 인스턴스 변화 측면에서 일반화 능력이 있고, 강체와 비정형물체 모두 모델링할 수 있다는 점에서 큰 가능성을 보였습니다.(kPAM 논문). 근데 기존 방법은 주어진 태스크마다 수작업으로 keypoint를 annotation 해야된다는 점이 있어, 오픈월드 시나리오에서의 확장성은 부족함이 있었습니다. 그래서 본 논문은 keypoint 기반의 구조적 표현을 채택하면서도 이런 annotation 수작업 문제를 해결하고자 했습니다. (이전에 리뷰한 MOKA의 경우도 결국엔 이런 사전정의된 키포인트에 대한 한계가 있었던 것으로 보면 정말 좋은 문제정의 같습니다.)
<Constrained Optimization in Manipulation>
앞에서부터 계속 제약, 제약 이 언급됐는데, 이쯤와서 제가 이해한 제약은 결국 로봇에 원하는 동작을 부여해줄 때 사용할 가이드라인/힌트 정도로 쉽게 이해하면 될 것 같습니다. 먼저 Motion Planning 같은 경우는 기하학적 제약으로 장애물을 회피하면서 목표를 달성할 수 있게 끔 trajectory를 계산하는 방식입니다. 다음 Contact 제약 같은 경우는 힘이 필요한/접촉이 많이 요구되는 동작을 계획하는 데 사용되는 방식입니다. 그런데 저자들이 해결하고자 하는 Sequential 한 manipulation 작업에 있어서는 TAMP(Task and Motion Planning, symbolilc하고 이산적인 Task Planning과 geometric하고 연속적인 Motion Planning을 동시에 고려!)라는 기법이 널리 쓰이는 프레임워크로, Constraint Satisfaction Problem으로 공식화되어서 연속적인 기하학 문제를 subroutine으로써 취급하는 방식을 취한다고 합니다. 뭐 등등등 저자가 언급한 다른 constrained optimization 방법들이 있었지만,
본 논문에서는 “Sequence-of-constraints mpc”라는 연구에서 영감을 받아, Sequential Manipulation 작업을 통합된 연속 수학 프로그램으로 공식화하고, 이를 반복/순차적으로 푸는 재시도방식(receding-horizon)으로 접근합니다. 다만 ReKep이 그 연구와 다른 점은 Foundation Model로 자동화하여 제약을 생성하도록 했다는 것입니다.
<Foundation Models for Robotics>
본 논문은 LVM인 DINOv2를 활용해 세밀하면서 의미 있는 keypoint를 제안하고, VLM인 GPT-4o를 활용해 코드 형태(파이썬)로 visual reasoning을 수행하여, VLM이 가진 단점(caption 중심의 사전학습 탓에 이미지 내 세밀한 정보는 파악하기 어렵다. 즉 gpt4o 가 visual grounding 같은 건 잘 못한다.) 과 LVM이 가진 단점(Open-World semantic 정보는 VLM에 비해 부족하다.)을 상호보완적으로 활용하고자 했습니다. 이 때 기존 연구들처럼 visual prompting을 적극 활용했다고 합니다. (해당 reference에 MOKA가 있었습니다. 아래 논문들이 visual prompting 방식을 활용한 논문들인데, 나중에 제가 참고해서 읽어보고자 좀 흔적을 남겨봤습니다.)
- Copa: General robotic manipulation through spatial constraints of parts with foundation models. arXiv preprint arXiv:2403.08248, 2024.
- Moka: Open-vocabulary robotic manipulation through mark-based visual prompting. arXiv preprint arXiv:2403.03174, 2024.
- Pivot: Iterative visual prompting elicits actionable knowledge for vlms. arXiv preprint arXiv:2402.07872, 2024.
- Robopoint: A vision-language model for spatial affordance prediction for robotics. arXiv preprint arXiv:2406.10721, 2024.
- Affordance-guided reinforcement learning via visual prompting. arXiv preprint arXiv:2407.10341, 2024.
3. Methods
저자들은 크게 4가지 논점으로 설명합니다.
- Relational Keypoint Constraints (ReKep)이란? (3.1절)
- 어떻게 매니퓰레이션 작업을 ReKep을 이용한 제약 최적화 문제로 수립? (3.2절)
- 실시간으로 이 최적화 문제를 해결하기 위한 알고리즘 구현 방식은 무엇? (3.3절)
- RGB-D 관찰과 언어 지시로부터 자동으로 ReKep을 생성하는 절차는 무엇? (3.4절)
<3.1. Relational Keypoint Constraints (ReKep)>
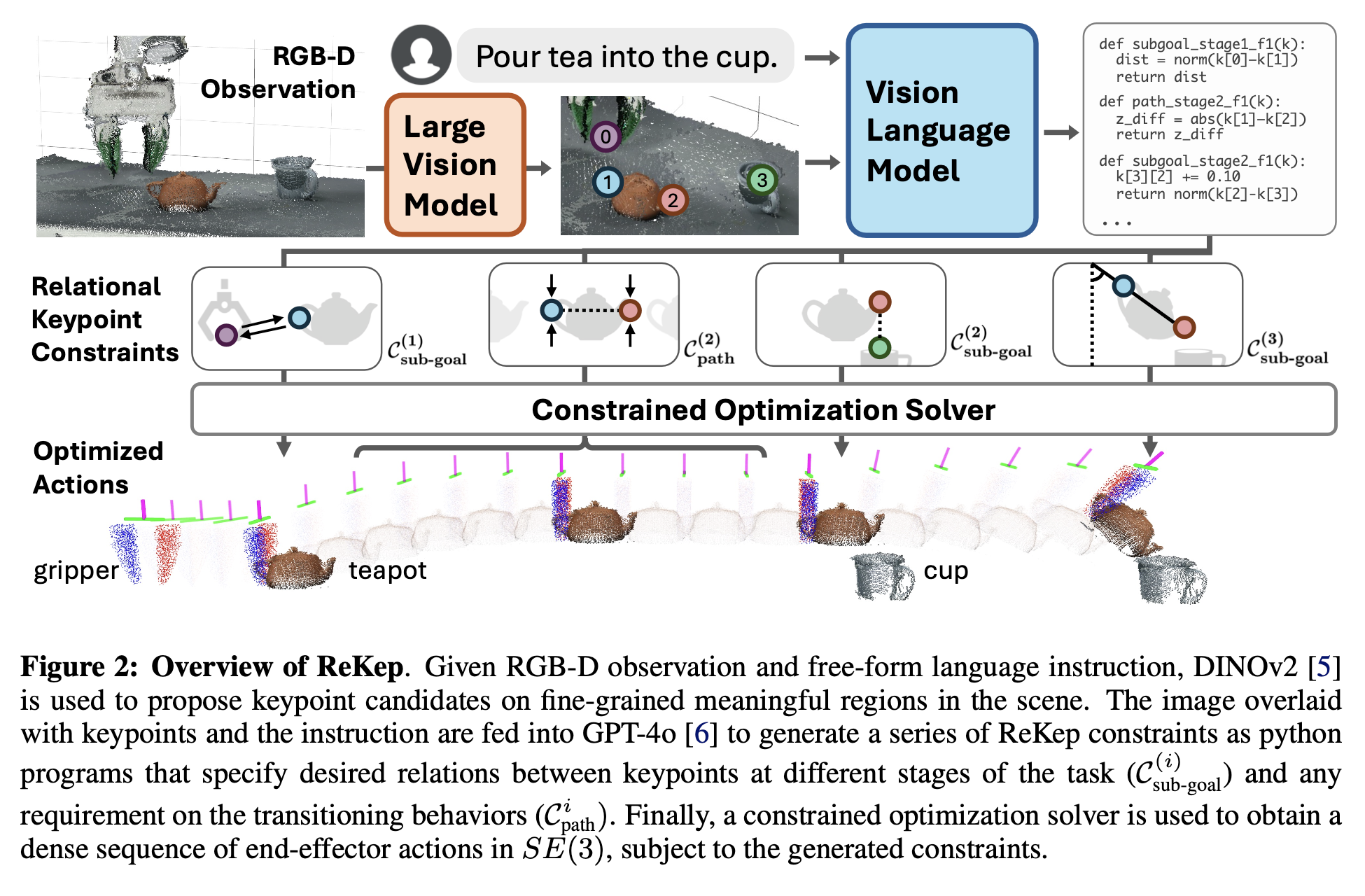
특정 작업에 대해, K개의 keypoint가 있다고 가정합니다. k∈R^{3K} 형태가 되겠습니다. 각각의 keypoint는 3차원 월드 좌표계에서 특정위치 (x,y,z)를 나타냅니다.
ReKep은 함수 f:R^{K×3}→R 형태로 정의됩니다. 즉 keypoint들의 벡터 k를 입력으로 받고, cost 스칼라값을 출력합니다. 함수 f(k)≤0이면 해당 제약이 충족되었다고 볼 수 있습니다. 결국 이 함수는 python numpy 연산으로 구현되고, numpy는 nonlinear, nonconvex 연산들이 구현 가능하므로, keypoint 간의 복잡한 기하학적, 물리학적, 공간적 관계를 자유롭게 정의할 수 있다고 합니다.
즉 introduction과 위 Figure 2.에서 보이는 것처럼, 각 sub-task는 서로 다른 ReKep 제약 함수를 가지며 공간적-시간적 의존성을 결국 keypoint와 numpy 등의 함수로 모델링하게 되고, 다음과 같이 예시를 들 수 있게 되는 것입니다.
- Stage-1 Sub-goal constraint: 로봇 엔드이펙터를 주전자의 손잡이(keypoint) 위치로 끌어가도록 제약함.
- Stage-2 Sub-goal constraint: 주전자의 주둥이(spout)와 컵의 입구를 정렬하도록 제약함.
- Stage-2 Path constraint: 이동 중에 주전자를 세워서 기울어지지 않도록(즉, 차가 새지 않도록) 제약함.
- Stage-3 Sub-goal constraint: 주전자를 적절히 기울여 차를 붓는 각도를 만들도록 제약함.
<3.2. Manipulation Tasks as Constrained Optimization with ReKep>
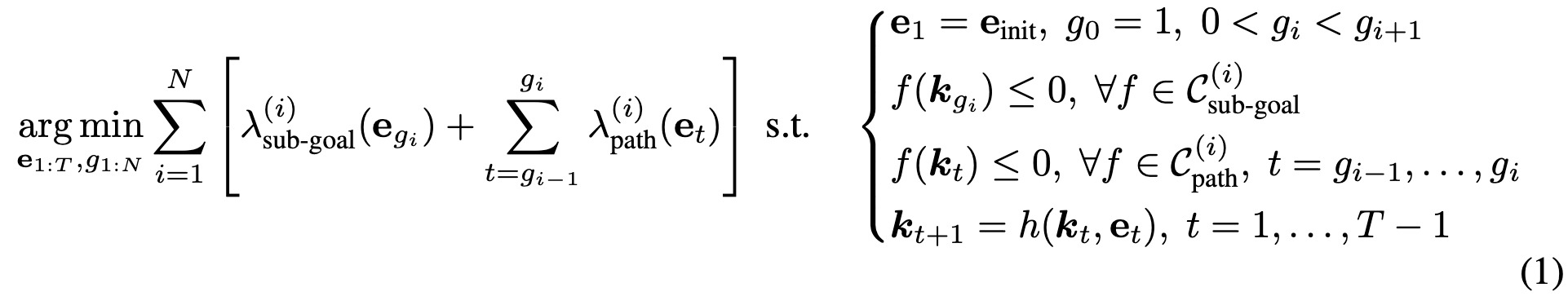
3.1.에선 제약 조건을 만들었으니, 이제 매니퓰레이션 작업을 위해 제약 최적화 문제로 나아가야합니다. 이제 여기서 로봇의 end-effector pose e(예: SE(3) 공간에서 위치+회전)를 T시간 동안의 이산 시간(discrete-time) pose 시퀀스인 e_{1:T} 로 풀어서 찾아야합니다. 작업을 N단계라고 했을 때, 각 i단계는 해당 단계가 끝날 때 반드시 만족해야하는 Sub-goal constraints C^{(i)}_{\text{sub-goal}}과 해당 단계 동안 계속 만족해야 하는 Path constraints C^{(i)}_{\text{path}}를 가지며, 이를 동시에 만족하는 end-effector 경로를 찾아야 합니다.
즉, “어떤 시점에 주전자를 잡고, 어떤 시점에 컵 위로 가져가고, 어떤 시점에 기울여 붓는지”를 결정하는 동시에, 매 시점에서 keypoint들이 주어진 ReKep 제약을 만족하도록 해야 합니다.
위 식(1)을 조금만 살펴보면,
\sum_{i=1}^{N} \Bigl[ \lambda_{\text{sub-goal}}^{(i)}\bigl(e_{g_i}\bigr) + \sum_{t=g_{i-1}}^{g_i} \lambda_{\text{path}}^{(i)}\bigl(e_{t}\bigr) \Bigr]왼쪽의 목적함수에선 단계마다 람다로 표현되는 서브-골 비용과 경로 비용을 합산합니다. 예를 들면, 충돌 회피, 에너지 사용 최소화, 경로의 부드러움, 그리핑(grasping) 품질 향상 등이 있겠습니다. 그런 다음 s.t. 옆의 맨 윗줄이 초기조건이 되겠고, 2번째줄은 sub-goal constraints, 3번째줄은 path constraints, 4번째줄은 keypoint forward model이 되겠습니다. 해당 수식의 모든 제약 조건을 동시에 만족하는 목적함수를 최적화시키는 해를 찾아내는 것이죠.
<3.3. Decomposition and Algorithmic Instantiation>
해당 절에서는 저자들이 위 절의 수식을 실시간으로 풀기 위한 방식을 설명합니다. 문제 전체를 한꺼번에 풀기보다는, 각 단계의 서브-골과 그 서브-골에 도달하는 경로를 분리하여, 두 서브-문제를 반복적으로(실시간으로) 해결하는 방식을 취하고, 이를 실시간(약 10Hz)으로 반복 업데이트하는 방식을 큰 틀로 가지고 있습니다. 모든 최적화 문제는 SciPy를 이용하고 decision variable을 [0,1]로 normalize하여 풀었으며, 초기에 SLSQP라는 local optimizer와 Dual Annealing 최적화기법을 사용하고, 순차적으로 local optimizer만 풀어나갔다고 합니다…

위는 수도코드 알고리즘입니다.
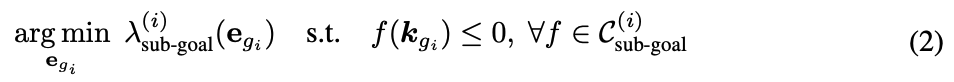
먼저 현재 i단계에서 e_{g_i}를 얻기 위해 sub-goal problem를 풀고, sub-goal 비용 람다는 부가적인 제어 cost들을 포함하는데, 예를 들면 장면 충돌 회피, 도달 가능성, 자세 정규화, 해 일관성, self-collision 등이 있을 수 있습니다. 다시 말해서 식 (2)는 sub-goal constraints인 C^{(i)}_{\text{sub-goal}}를 만족시키면서, 이런 부가 cost들을 최소화하는 서브-골 e_{g_i}를 찾는 것입니다. 해당 단계가 grasping을 다루는 단계라면 본 논문에선 AnyGrasp라는 grasp metric 방법론을 사용했다고 합니다.
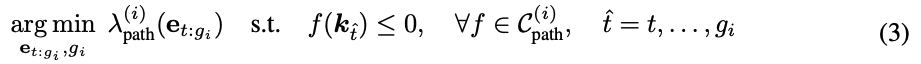
위 식 (2)에서 서브-골 e_{g_i}를 구한 뒤, 현재 end-effector 자세 e_t 에서 e_{g_i}로 가는 궤적 e_{t:{g_i}}를 구하기 위해, 위 식 (3)을 풀어야 합니다. 여기서 람다 path는 위의 수식 (2)에서도 언급한 부가적인 cost들을 포함합니다. 만약 e_{g_i}와의 거리가 작은 오차 이내라면 다음 단계 i+1로 넘어간다고 합니다.
다음 Backtracking과정이 있는데, 이는 “서브-골 문제와 경로 문제는 단일 단계 내에서 발생하는 외부 교란(external disturbances)에 대응하기 위해 실시간 주기로 풀 수 있지만, 이전 단계의 서브-골 제약이 더 이상 유효하지 않을 경우(예: 차 붓는 작업에서 컵이 그리퍼 밖으로 벗어나는 상황), 여러 단계에 걸쳐 재계획이 가능해야 하는 것을 의미합니다. 구체적으로, 매 제어 루프마다 C_{\text{path}}^{(i)}의 위반 여부를 확인하고, 위반이 발견되면, 그것이 만족되는 이전 단계 j로 단계적으로(backtrack) 되돌아가는 것이라고 합니다.
마지막으로 초기에는 Dual Annealing(전역 탐색) + SLSQP(국소 탐색)으로 서브-골과 경로 문제를 풀어 1초 정도에 해를 구하고, 이후부터는 이전 해를 초기값으로 하여 로컬 최적화만 수행함으로써 약 10Hz로 재계산합니다.로봇은 매 제어 루프마다 현재 단계(i)와 경로 상에서의 위치(t)를 갱신하여, 제약 조건을 만족하도록 동작을 조정한다고 합니다.
<3.4. Keypoint Proposal and ReKep Generation>
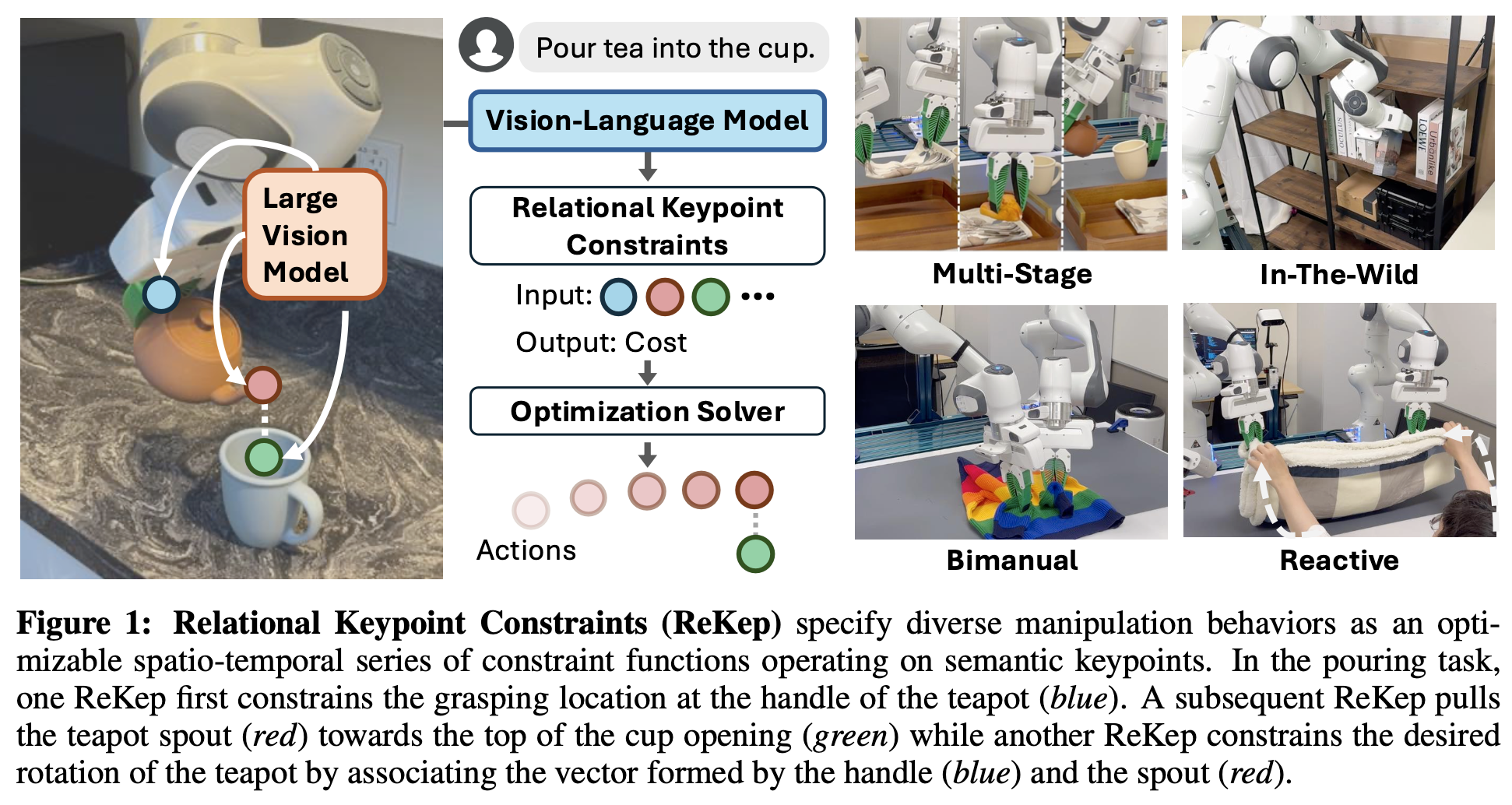
시스템이 in-the-wild 환경에서 자유형 언어 지시만으로 작업을 수행할 수 있도록 하기 위해, DINOv2, SAM, GPT-4o 등을 활용해 RGB-D 영상과 언어 지시만으로 keypoint 후보를 생성하고, 해당 keypoint 간의 제약 함수를 파이썬 코드로 생성하는 파이프라인을 취합니다. 크게 두 단계 Keypoint Proposal과 ReKep Generation으로 나뉘어 설명할 수 있습니다.
먼저, Keypoint Proposal 은 다음과 같습니다. RGB 이미지 R \in \mathbb{R}^{h \times w \times 3}가 주어지면, DINOv2 를 사용해 패치 단위 특징 F_{\text{patch}} \in \mathbb{R}^{h' \times w' \times d}을 추출합니다. 그런 뒤, bilinear interpolation을 수행하여, 해당 특징을 원본 이미지 크기인 F_{\text{interp}} \in \mathbb{R}^{h \times w \times d}로 업샘플링합니다. scene 내 모든 관련 객체를 커버하기 위해, SAM을 사용해 마스크 M = {m_1, m_2, \dots, m_n}를 추출하고, 각 마스크 m_j에 대해, F_{\text{interp}}[m_j] 내의 특징을 cosine similarity를 기준으로 k-means(k=5)를 적용해 클러스터링합니다. 이렇게 얻은 클러스터들의 centroids는 키포인트 후보로 사용되고, 이후 calibrated RGB-D 카메라 정보를 활용해 이들 centroids를 3차원 월드 좌표계 \mathbb{R}^3로 투영한다고 합니다. 이 과정에서 물체 내부에서 세밀하고 의미론적으로 중요한 영역을 상당히 높은 비율로 잘 포착한다는 점에서 유용함을 확인할 수 있었다고 합니다.
다음 ReKep Generation은 다음과 같습니다.
키포인트 후보를 얻은 뒤, 우리는 이를 원본 RGB 이미지에 숫자 마킹으로 오버레이합니다. 그리고 작업에 대한 언어 지시와 결합하여, visual prompting를 통해 GPT-4o에 질의하여, 필요한 단계 수와 각 단계의 서브-골 제약 C_{\text{sub-goal}}^{(i)}, 경로 제약 C_{\text{path}}^{(i)}을 생성하도록 합니다. 프롬프트는 기본적으로 PoT 방식과 초기 Instruction 방식을 취했습니다.
핵심은 이 제약 함수들이 키포인트의 수치값을 직접 다루지 않는다는 점이 있는데, 대신, GPT4o의 능력을 활용하여, 키포인트 간의 \ell_2 거리나 내적(dot product) 같은 산술연산으로 공간적 관계를 해석할 수 있게 만듭니다. 이 산술 연산은 실제로는, 전용 3D 트래커가 추적한 실제 키포인트 위치가 주어졌을 때에만 인스턴스화된다고 합니다.
추가로, 키포인트 집합에 대해 산술 연산을 사용하는 중요한 이점은, 충분한 점이 주어지고 해당 점들 사이에 강체가 적용된다면, 이를 통해3D 로테이션을 \mathrm{SO}(3) 전 범위로 명시할 수 있다는 점이 있습니다. 다만, 이는 작업의 의미적 특징에 따라 필요할 때만 수행된다고 합니다. 이렇게 하면 VLM이 3차원 카르테시안 공간에서 산술 연산만으로 3D 회전을 추론할 수 있게 되므로, 기존의 3D 회전 표현(예: 오일러 각, 쿼터니언 등)을 따로 다룰 필요나 추가적인 수치 연산을 수행할 필요가 사라진다고 합니다.
4. Experiments

위 Fig 3은 실제 실험 장면에서 (1) 서브-골이 계산되는 모습, (2) 경로가 만들어지는 모습, (3) 로봇이 해당 경로를 따라 실제로 동작하는 모습 등이 순서대로 시각화되어 있습니다. 이 과정에서 ReKep 제약(키포인트 기반)이 주어진 목표나 경로를 어떻게 형성하는지 태스크별로 정성적으로 확인할 수 있습니다.
우선 저자들은 ReKep을 두 가지(모바일 싱글암, 고정형 듀얼암) 실제 로봇 플랫폼에서 실험합니다. 평가 메트릭은 작업성공률로, 작업별 총 10번의 시도를 진행합니다. Auto의 경우 이 논문에서 제안한 방식대로, VLM&LVM을 사용해 자동으로 ReKep 제약을 생성하는 방식이고, Annot의 경우 사람이 직접 ReKep 제약을 설정한 경우입니다.
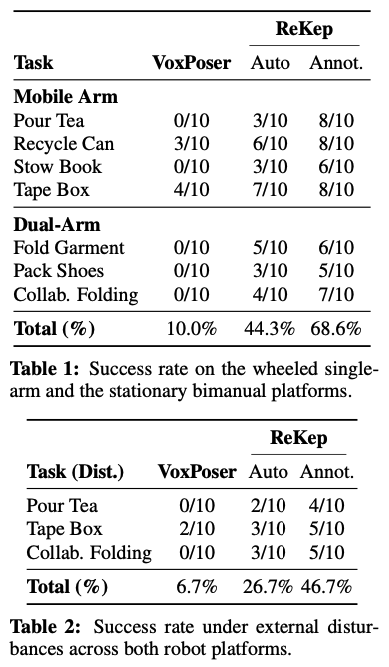
VoxPoser를 baseline으로 삼았는데요. VoxPoser보다 월등히 높은 성공률을 보여준다는 점에서 인상깊습니다. Table2는 Disturbance 테스트라고 해서 실험 도중 객체의 pose를 인위적으로 변경함으로써 시스템의 반응성과 replanning 능력을 확인하고자 했던 실험세팅이라고 합니다. 해당 실험세팅에서도 ReKep은 좋은 성능을 보였습니다. 특히 Tape Box나 Pour Tea 등의 작업은 multi-stage나 reactive한 환경임에도 효과적인 동작이 가능했음을 보입니다.
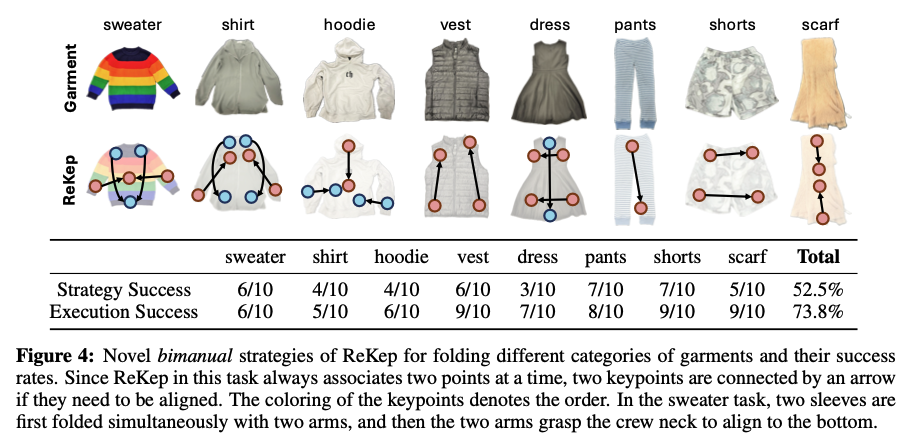
더불어 ReKep은 Fig4에 보이는 것처럼, 듀얼암을 사용한 위의 옷 개기 태스크에서도 좋은 모습을 보입니다. 구조화되지 않은 환경에서 꽤나 사람이 옷을 개는 것과 유사하게 올바르게 제약을 수립하고 이를 실행하기 위한 keypoint 역시 보이는데, 하나 의문인 점은 DINOv2와 SAM을 이용해 Keypoint 후보를 뽑아낼 때, 마스크를 k=5개 만큼 클러스터링하고 그것의 중심점으로 keypoint를 삼았는데, 해당 방식으로 어떻게 위와 같은 옷을 접을 때 필요한 핵심 부위들을 저렇게 잘 집어낼 수 있는가는,, 이건 진짜 코드를 보지 않으면 모를 것 같습니다. voxposer 논문도 약간 논문과 demo상으로는 되게 거창하게 표현했는데, 사실 알고 보니 simulator 코드의 구조만 좀 복잡하고 실제 voxposer의 개념에 해당하는 voxel map과 규제 맵 등은 꽤나 심플하게 코드가 이루어져있었습니다. 그런 것처럼 해당 ReKep 논문도 리뷰가 끝나고 코드를 좀 뜯어봐야할 것 같습니다.
아 이외에 ReKep의 조금 특이한 능력은 바로 듀얼암을 사용할 때의 협동 동작과 인간이 개입하여 human-robot collaboration에서도 적응적으로 협동 동작을 수행할 수 있다는 점이 있습니다. 10Hz의 속도로 real-time 동작을 위해 키포인트를 반복 추적하는 과정을 거치면서, 제약도 반복적으로 평가하는 과정이 있기 때문에 외부 교란(disturbance)라고 볼 수 있는 사람의 개입도 빠르게 재계획하여 대응할 수 있는 것이라고 저자들은 언급하네요.

Fig 5는 시스템의 실패 사례 중에서 error가 일어난 모듈에 대한 비율을 다룬 분석입니다. 다르게 말하면 시스템이 각각 모듈화되어 있어 error를 추적하기 용이하다는 장점이 있습니다. 위 그림에서는 Point Tracker가 가장 많은 오류를 유발하는 것으로 나타났는데, 이는 관찰 도중 간헐적인 occlusion이 keypoint 추적을 어렵게 만들기 때문이라고 합니다. 반대로 Optimization의 경우에는 error 비율이 상당히 낮은 것을 볼 수 있는데, 이는 대부분의 작업에 대해 수학적으로 계산 가능한, 유효한 해가 대체로 다양하게 존재할 수 있기 때문이라고 합니다. 결론으로는 Occlusion 문제를 해결하는 것이 해당 태스크의 가장 큰 병목이 아닐까 생각합니다.

위 Fig 8은 키포인트 제안을 위해 사용되는 여러 visual feature extractor로써 LVM을 어떤 것을 사용하냐에 따른 정성적 결과물인데, 일단 marking prompting 방식이 눈에 확 들어오구요.(이 쯤 되면 마킹 visual prompting은 이제 GPT4o 에게 grounding을 맡기기 위한 일반화된 과정이 된 게 아닌가 싶습니다.) 위 그림은 3가지 장면 각각에 대해 각 모델에서 추출된 feature map을 RGB 공간으로 투영한 결과와 이 특징들을 클러스터링하여 얻은 키포인트 후보들을 시각화해놓은 것입니다. 눈여겨볼 점은, SAM이 없이 진행될 경우엔 객체가 아닌 부분에도 클러스터 포인트가 생기거나 객체 경계가 불분명해지는 모습을 보이는 것으로 보아, SAM이 내뱉는 어떤 객체성을 지닌 마스크는 특징 맵에서 노이즈를 줄이는 데 매우 중요하다는 것을 보입니다. 그리고 CLIP과 ViT와 비교해봤을 땐 DINOv2가 역시 세밀한 객체 정보를 잘 이해하고 있음을 보입니다. 개인적으로는 객체의 affordance에 조금 더 초점을 맞추어 point proposal을 뱉을 수 있는 방식이 절충되어 개선될 수 있다면 좋을 것 같다는 생각도 듭니다!
5. Conclusion
본 논문에서는 Relational Keypoint Constraints (ReKep) 라는 새로운 구조적 표현 방식을 제안했습니다. 로봇과 객체간 공간적-시간적 관계를 키포인트와 제약함수로써 정의하고 이를 sub-task 단계별로 계층적으로 최적화하는 방식으로 planning을 진행합니다. 하지만 저자들이 말하기를 한계점으로는 현재의 저자들이 적용한 최적화 파이프라인은 물체를 잡고있는 키포인트가 로봇 end-effector와 강체 관계에 있으며, dynamic하게 접촉이 많아야하는 태스크에서는 해당 과정이 부정확해져 궤적 추적에 오차를 많이 일으킬 수 있다고 합니다. 또한 키포인트 추적에 있어서도 앞서 언급했듯이 Occlusion 문제가 있고, 이로 인한 오차가 가장 큰 걸림돌이 되고 있습니다. 마지막으로는 현재 태스크들은 작업마다 정해진 단계만큼의 순서를 사용하는데, 만약에 작업 도중 단계의 구조 자체가 더 크고 복잡하게 세분화되고 변경된다면 키포인트 후보 생성과 VLM 호출에 있어 latency 문제때문에 큰 계산 비용이 든다는 단점이 있다고 합니다.
안녕하세요 재찬님 리뷰 감사합니다.
사람의 손이 필요없이(?) 키포인트를 생성하고 키포인트 간의 관계를 python 함수로 정의해서 제어할 때 사용한다고 이해했는데요, Voxposer와 비교했을 때 행동 자체를 관계성을 활용해서 위치와 관계없이 더 잘 이해하고 있다고 생각하고 그래서 비교했을 때 훨씬 우수한 성능이 나온 것 같은데요, 혹시 시간적인 비용은 어떻게 차이가 날까요? 관계성을 계속 이해하면서 진행하면 연산량이 많을 것 같습니다. 또 환경에 따라 keypoint가 찍힌 물체가 가려질 수도 있을 것 같은데 이런 경우는 어떻게 처리하는지 궁금합니다!
안녕하세요 영규님, 좋은 질문 감사합니다.
1. 좋은 작업 성공률에 대비, 관계성을 고려해주는 것으로 인한 시간적 비용이 있나요?
–> 약 10Hz 주기로 관계성을 지속적으로 최적화하기 위해 재계산하며 동작한다는 논문의 언급으로 보아, 영규님의 생각처럼 실시간성에서 어려움이 있지 않을까 생각했었고, 실제로 해당 논문의 프로젝트 페이지에서도 영상에 2배속,4배속을 걸어 real-world manipulation을 보여주었는데요. 사실 저희가 이번 미니챌린지에서 voxposer 를 Real환경에 직접 테스트해봤듯이, 로봇의 실시간성을 체크해보는 것은 실제 코드를 통해 동작하는 게 아닌 이상 계속 의심하고 문제정의로 갖고 있는 것이 맞을거라는 생각이 있으나, 주로 실내환경에서 동작할 일반화된 매니퓰레이터 작업이라는 점에서 최신 논문들 또한 속도 측면에서의 어려움은 어느 정도 눈 감고 가고있는 게 아닐까란 생각도 듭니다.
2. 환경에 따라 keypoint가 찍힌 물체가 가려지는 문제는 어떻게 처리하나요?
–> 제가 리뷰에서도 언급했지만,,,, 이 occlusion이 진짜 작업 실패에 있어서 가장 큰 문제가 아닐까 생각합니다.
그래서 이건 본 논문에서도 Limitation으로 잡고 있는 부분인데요. 특히 키포인트 정확성, tracking을 놓치는 문제로 인한 오류율이 많다는 점, 해당 부분도 결국 perception과 reasoning과 결부해서 가장 큰 역할을 하고 있다는 점에서 꽤나 중요한 문제 사항이라고 생각합니다. 이것에 대한 짧은 저의 생각을 적어보자면,,,, keypoint 자체가 2d 이미지에 다시 마킹되어 gpt에 입력쿼리로 들어가 reasoning에 사용되기 때문에, 만약 gpt가 3d keypoint marking 정보를 이해하는 시기가 온다면 해결이 가능한 거 아닌가……. 혹은 그냥 Keypoint가 마킹된 씬을 앞 뒤 두 장 이상으로 세팅하여 gpt에게 reasoning을 시키면 되지 않을까…. 라는 순수한 생각을 해봅니다.
감사합니다.